
У классических свёрточных нейронных сетей есть недостатки. Внутреннее представление данных сверточной нейронной сети не учитывает пространственные иерархии между простыми и сложными объектами. Так, если на изображении в случайном порядке изображены глаза, нос и губы для свёрточной нейронной сети это явный признак наличия лица. А поворот объекта ухудшает качество распознавания, тогда, как человеческий мозг легко решает эту задачу.
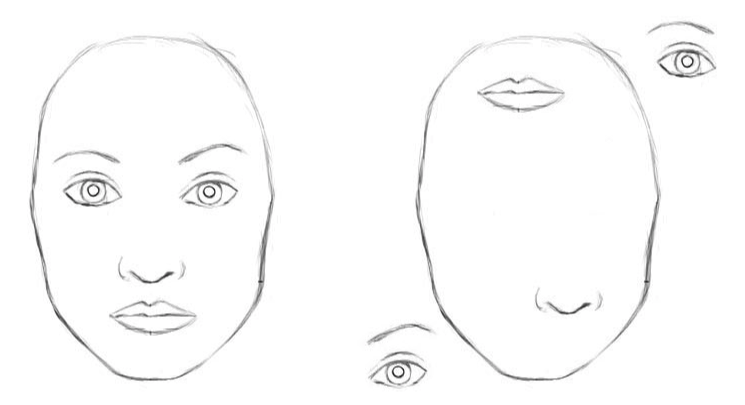
Для свёрточной нейронной сети 2 изображения схожи [2]

Для обучения распознавания объекта с различных ракурсов CNN понадобятся тысячи примеров.

Капсульные сети снижают ошибку распознавания объекта в другом ракурсе на 45%.
Назначение капсул
Капсулы инкапсулируют информацию о состоянии функции, которую обнаруживают в векторной форме. Капсулы кодируют вероятность обнаружения объекта как длину выходного вектора. Состояние обнаруженной функции кодируется как направление, в котором указывает вектор («параметры создания экземпляра»). Поэтому, когда обнаруженная функция перемещается по изображению или состояние изображения изменяется, вероятность остается неизменной (длина вектора не изменяется), но ориентация меняется.
Представим, что капсула обнаруживает лицо на изображении, и выводит 3D-вектор длиной 0,99. Затем, перемещаем лицо по изображению. Вектор будет вращаться в своем пространстве, представляя изменяющееся состояние, но его длина останется фиксированной, потому что капсула уверена, что обнаружила лицо.

Различия между капсулами и нейронами.[2]
Искусственный нейрон можно описать тремя шагами:
1. скалярное взвешивание входных скаляров
2. сумма взвешенных входных скаляров
3. нелинейное скалярное преобразование.
Капсула имеет векторные формы вышеуказанных 3 шагов, в дополнение к новому этапу аффинного преобразования ввода:
1. матричное умножение входных векторов
2. скалярное взвешивание входных векторов
3. сумма взвешенных входных векторов
4. векторная нелинейность.
Еще одним нововведением, которое представлено в CapsNet, является новая нелинейная функция активации, которая принимает вектор, а затем «выдает» его длину не более 1, но не меняет направление.

Правая часть уравнения (синий прямоугольник) масштабирует входной вектор так, что вектор будет иметь длину блока, а левая сторона (красный прямоугольник) выполняет дополнительное масштабирование.
Конструкция капсулы строится на устройстве искусственного нейрона, но расширяет его до векторной формы, чтобы обеспечить более мощные репрезентативные возможности. Также вводятся весовые коэффициенты матрицы для кодирования иерархических связей между особенностями разных слоев. Достигается эквивариантность нейронной активности в отношении изменений входных данных и инвариантности в вероятностях обнаружения признаков.
Динамическая маршрутизация между капсулами

Алгоритм динамической маршрутизации[1].
В первой строке говорится, что эта процедура принимает капсулы на нижнем уровне l и их выходы u_hat, а также количество итераций маршрутизации r. Последняя строка говорит, что алгоритм будет выдавать вывод более высокого уровня капсулы v_j.
Во второй строке присутствует новый коэффициент b_ij, который мы не видели ранее. Этот коэффициент является временным значением, которое будет итеративно обновляться, и после завершения процедуры его значение будет сохранено в c_ij. В начале обучения значение b_ij инициализируется в нуле.
Строка 3 гласит, что шаги в 4-7 будут повторяться r раз.
Шаг в строке 4 вычисляет значение вектора c_i, который является всеми весами маршрутизации для капсулы i более низкого уровня.
После того как веса c_ij рассчитаны для капсул нижнего уровня, переходим к строке 5, где смотрим на капсулы более высокого уровня. Этот шаг вычисляет линейную комбинацию входных векторов, взвешенных с помощью коэффициентов маршрутизации c_ij, определенных на предыдущем шаге.
Затем в строке 6 векторы последнего шага проходят через нелинейное преобразование, что гарантирует сохранение направления вектора, но его длина не должна превышать 1. Этот шаг создает выходной вектор v_j для всех более высоких уровней капсулы.[2]
Основная идея заключается в том, что сходство между входом и выходом измеряется как скалярное произведение между входом и выходом капсулы, а затем изменяется коэффициент маршрутизации. Лучшей практикой является использование трех итераций маршрутизации.
Заключение
Капсульные нейронные сети — перспективная архитектура нейронных сетей, которая улучшает распознавание изображений при изменяющихся ракурсах и иерархической структурой. Обучение капсульных нейронных сетей осуществляется с помощью динамической маршрутизации между капсулами. Капсульные сети снижают ошибку распознавания объекта в другом ракурсе на 45% в сравнении c CNN.
[2] Understanding Hinton’s Capsule Networks. Max Pechyonkin
Комментарии (8)

roryorangepants
15.07.2018 11:07Лучше бы вместо этого сжатого пересказа серии статей вы бы сделали нормальный перевод.
Это уже второй раз за две недели, когда ваша статья оказывается не более, чем плагиатом на англоязычную статью.kirillkosolapov Автор
15.07.2018 11:15-5Уважаемый roryorangepants, в статье указаны ссылки на источники, на основе которых написана статья, ваш комментарий не совсем корректен. Но буду рад, если вы подробно изложите пожелания по будущим статьям в личном сообщении, я обязательно их учту при написании статей. Конструктивная критика и обратная связь всегда полезны.
roryorangepants
15.07.2018 12:06+4У вас текст — это сжатый пересказ чужой статьи, в котором нет ничего нового. Даже формулировки и примеры не придуманы, а переведены.
Хабр же вроде как предназначен для оригинального контента.
При этом от того, что вы сжали материал нескольких частей статьи в одну, качество и понятность сильно пострадали.
smer44
15.07.2018 21:18статья не поясняет ничего. Поосле прочтения хорошей статьи о свёрточной сетке, я смог её сам сделать на С с нуля для учёбы. После прочтения этой статьи непонятно даже что это такое
iroln
16.07.2018 09:42+1Эта статья бессмысленна, потому что создаёт только информационный шум и больше ничего. Она бесполезна и для тех, кто в теме и для тех, кто не в теме.
Спойлер, напримерДве сылки зачем-то под спойлером и даже без гиперссылок. Ну ладно.
zaleslaw
16.07.2018 12:42-2Спасибо, в ворохе шума, как-то пропустил этот тип архитектуры. Статья обзорная, но поможет тем, кто занимается машинным обучением в проде, применяя разные подходы, а не является диванным архитектором нейросеток, читающим все новинки.
kenoma
Для неофитов статья бесполезная, понять из нее чем принципиально отличаются капсульные сети от обычных сверточных можно только узнав, чем отличаются эти сети друг от друга в другом источнике.