

Я намеренно употребил в прошлом предложении словосочетание “микроэлектронный продукт” вместо слова “микросхема”, потому что речь в этой статье пойдет как раз о том, что внутри корпуса CPU или GPU может находиться вовсе не один кристалл, а целая система из нескольких чипов, так и называемая: система в корпусе или system in package.
Термин “система в корпусе” гораздо менее на слуху, чем родственный термин “система на кристалле”, которым очень любят козырять разработчики чего угодно. При этом сейчас практически любой чип (кроме самых простых) так или иначе является системой на кристалле, а времена микропроцессорных комплектов и даже отдельных чипов южного и северного мостов уходят в прошлое. Преимущества систем на кристалле довольно очевидны: меньше корпусов на плате, меньше площади (а значит дешевле), меньше паразитных индуктивностей и емкостей (а значит, продукт будет работать лучше и быстрее), проще для пользователя (удобнее внедрять и меньше пространство для ошибки), дешевле в производстве (вместо нескольких специализированных микросхем можно выпускать одну более универсальную).
Но у систем на кристалле есть и свои подводные камни.
Во-первых, пытаясь впихнуть на один кристалл все сразу, вы рискуете получить чип такого размера (и с таким количеством ножек), что он не влезет ни в один корпус. Кроме этого (как подсказывает в комментариях профессиональный технолог), совсем большой чип рискует не влезть в размер поля фотолитографического сканера. Обойти это ограничение можно, но очень сложно технически и, соответственно, очень дорого.
Во-вторых, чем больше размер чипа, тем меньше процент выхода годных, особенно если для производства нужно сшивать между собой несколько окон на фотошаблоне. И это, разумеется, тоже влияет на стоимость.
В-третьих, если ваша система состоит из разнородных компонентов, то объединять их все на одном кристалле может быть слишком сложно, слишком дорого или слишком плохо для качества работы системы. Например, DRAM требует наличия специальных конденсаторов, добавление которых в “обычный” техпроцесс может быть неразумно дорого для фабрики (которая из-за этого будет вынуждена повысить цены для клиентов). Радиочастотные или силовые компоненты на кремнии могут обладать существенно худшими параметрами, чем на А3В5-материалах (арсениде галлия и его аналогах), а соединение на одном кристалле цифровой и аналоговой частей создает проблему шумов.
Сочетание всех вышеозвученных факторов привело к тому, что тренд «разместим все-все-все на одном кристалле» сменился более взвешенным подходом, а также к бурному развитию технологий упаковки кристаллов в корпус.
Производительность и выход годных
Первый пример, который приходит в голову — это, конечно же, микропроцессоры AMD (см. КПДВ). Системы в корпусе для многоядерных продуктов считаются одной из важных причин недавнего подъема компании, проходящего на фоне проблем Intel с запуском нового техпроцесса из-за низкого выхода годных на огромных чипах.

На рисунке — 28-ядерный чип Intel Xeon. Размер этих процессоров достигает сумасшедших 456 квадратных миллиметров, в то время как предельный размер чипов AMD — около 200 квадратных миллиметров для восьмиядерного чипа, а продукты с бОльшим количеством ядер собираются из нескольких одинаковых кристаллов на двухслойной печатной плате, расположенной в корпусе процессора.

На этом рисунке вы можете увидеть конструкцию платы внутри корпуса процессоров EPYC и Threadripper (он же на КПДВ). На двухслойной плате расположены четыре восьмиядерных кристалла. В случае с Threadripper — c половиной отключенных ядер. Почему так нерационально используются кристаллы?
Во-первых, выпускать один тип кристалла может быть дешевле, чем несколько разных.
Во-вторых, то же самое относится и ко всей остальной обвязке — отключить ненужное может быть дешевле и технологичнее, чем разрабатывать и производить несколько разных моделей.
В-третьих, процент выхода годных для 200-миллиметрового чипа, скорее всего, тоже не идеален, а такая конструкция конечного продукта позволяет использовать кристаллы, в которых работают не все ядра. Intel поступает точно так же, но их проблемы с выходом годных гораздо сильнее из-за кристаллов большего размера.

А вот еще более интересный пример, и тоже от AMD. AMD Fiji — это GPU со встроенной высокоскоростной памятью, расположенной прямо в корпусе. Почему это важно? Потому что гораздо более короткие линии от процессора к памяти позволяют добиться больших скоростей, а значит и большей производительности. В отличие от предыдущего примера, кристаллы внутри корпуса разные. Более того, их не пять, как может показаться на первый взгляд, а гораздо больше — двадцать два. Вот разрез структуры:
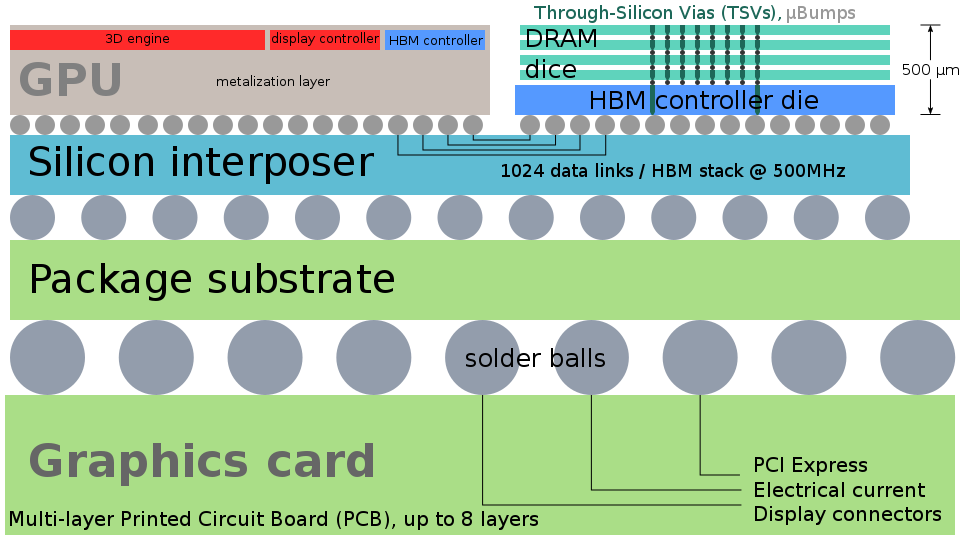
Верхний слой — это собственно чип GPU и “этажерка” из нескольких (в данном случае четырех) чипов памяти, соединенных при помощи TSV (through-silicon-via) — проводящих столбиков, идущих сквозь кристалл на всю толщину.
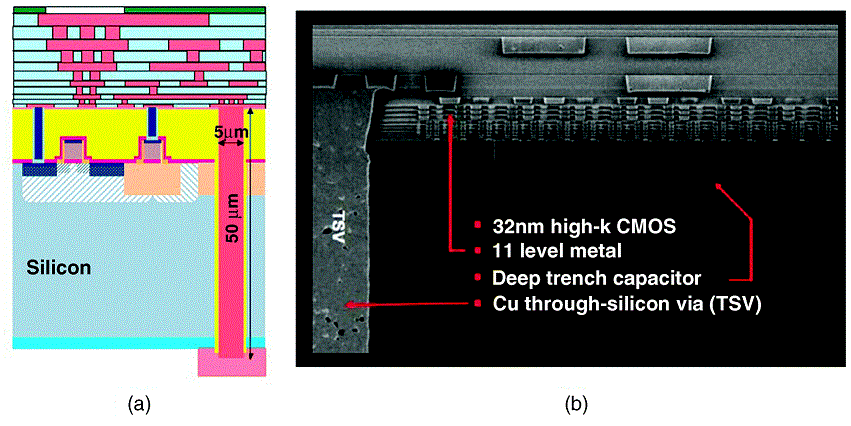
TSV выглядят примерно так, схематично и в реальном масштабе.
Технология TSV, изначально появившаяся как раз для массивов памяти (ведь памяти много не бывает, правда?), сейчас находит все большее распространение, в том числе благодаря следующему кристаллу, находящемуся под GPU и памятью.
Silicon Interposer — это заменитель многослойной печатной платы, сделанный из кремниевого кристалла и содержащий несколько слоев металлизации и TSV для связи чипов наверху и корпуса. Использование кремния позволяет получить существенно меньшие размеры элементов (единицы микрон), чем печатная плата, но при этом проектные нормы могут быть достаточно грубыми для того, чтобы этот соединительный чип имел высокий выход годных и доступную цену. Меньшие размеры элементов означают меньшее влияние паразитных параметров соединений, а уже упоминавшиеся TSV гораздо компактнее переходных отверстий на печатной плате и позволяют без проблем на протащить через интерпозер сотни или даже тысячи контактов к корпусу. Наряду с МЭМС, такие чипы для интерконнекта — важный новый рынок для устаревающих фабрик с пластинами 100-150 миллиметров диаметров.
Лирическое отступление: на схеме выше есть небольшая, но важная неточность, противоречащая фотографии. Какая?
Еще один пионер 3D-интеграции — фирма Xilinx. Технологически ее ПЛИС близки к продуктам AMD (особенно те, которые со встроенной памятью), и мотивы также схожи: ПЛИС — это рыночная ниша, где ранний переход на новый техпроцесс может дать серьезное преимущество над конкурентами. По разными оценкам, на раннем этапе жизни технологии уменьшение размера кристалла на три-четыре раза способно поднять выход годных в два-три раза, с пары десятков процентов до больше, чем половины. Более того, ПЛИС — это регулярная структура, на которой удобно отслеживать технологические дефекты. Поэтому производители ПЛИС — типичные “первые клиенты” для новых техпроцессов, и Xilinx за счет того, что в их продуктах стоит несколько небольших кристаллов вместо одного полноразмерного, может выводить новые модели на рынок на несколько месяцев быстрее, чем конкуренты.

Вот разрез внутренностей ПЛИС Xilinx. Верхний чип — это собственно часть ПЛИС с очень маленькими (40-45 мкм) контактами к интерпозеру, соединяющему несколько чипов вместе, и внизу — основание корпуса, имеющее десяток слоев собственных металлических межсоединений.

Для сравнения — ПЛИС Altera на одном огромном кристалле. Пятьсот шестьдесят квадратных миллиметров, Карл! Если вдруг этот пост читают технологи микроэлектронного производства, позаботьтесь, чтобы у них не случилось сердечного приступа.
Впрочем, Intel/Altera, разумеется, не сидит на месте, наблюдая за успехами конкурентов. Их свежая разработка в области систем в корпусе — Embedded Multi-Chip Interconnect Bridge (EMIB). Посмотреть на него удобно на примере ПЛИС Intel Stratix 10.
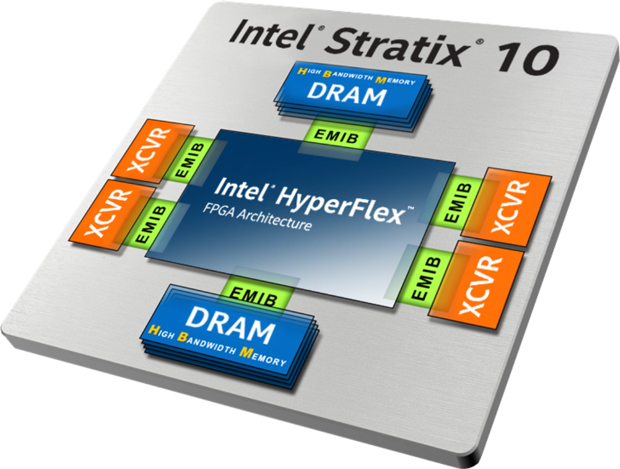
Как видите, EMIB соединяет между собой (один!) чип ПЛИС, память (и тут многоэтажные конструкции) и периферийные кристаллы. Так что же такое этот EMIB? Чуть выше я написал про silicon interposer, что он за счет более грубого техпроцесса имеет гораздо меньшую цену, чем аналогичный по размеру чип, сделанный по тонкой технологии. И тем не менее, интерпозер — огромный. Можно ли сделать его поменьше?
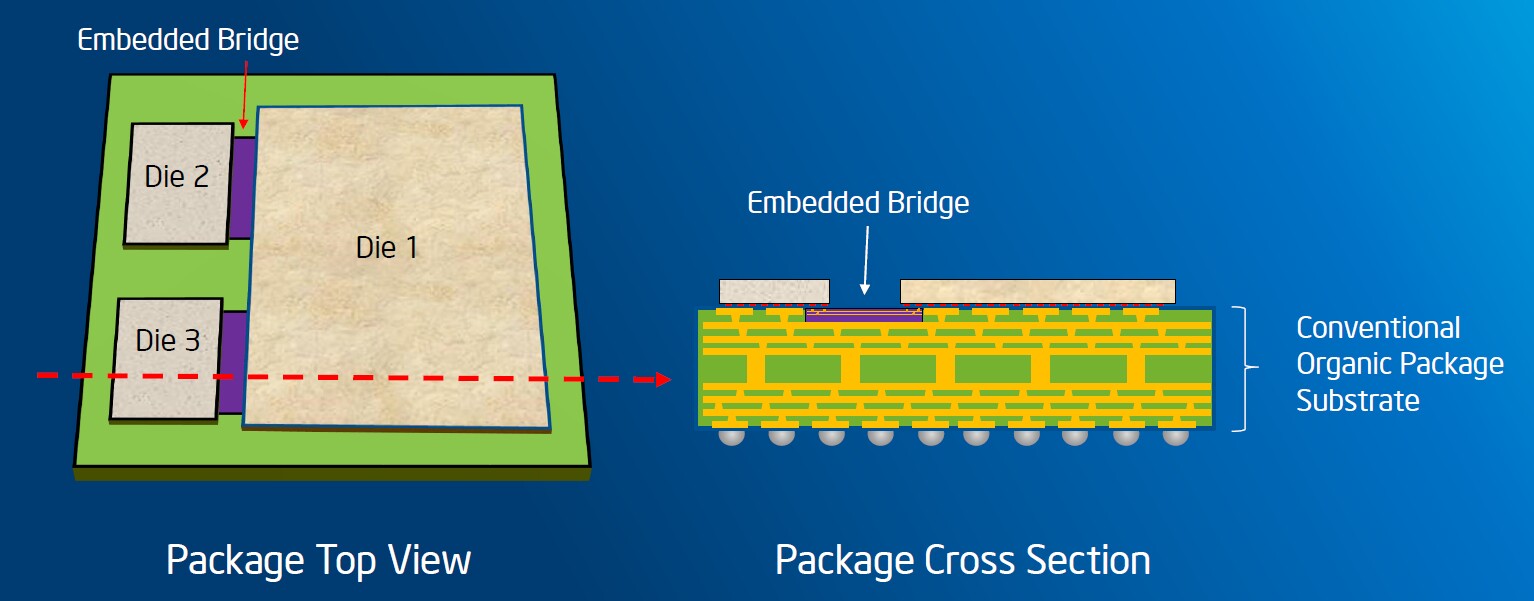
Ответ Intel — да, можно. Идея EMIB в том, чтобы вместо одного большого интерпозера использовать несколько маленьких, и их, в свою очередь, встроить прямо в подложку корпуса.
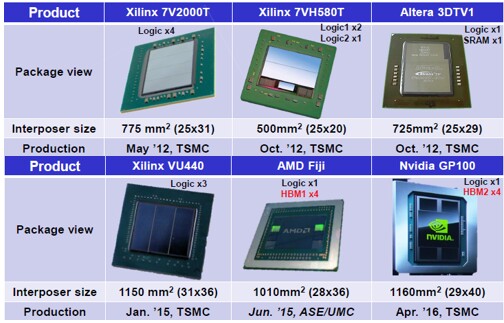
Вот небольшая подборка продуктов, созданных с использованием кремниевых интерпозеров. Обратите внимание на их колоссальные по микроэлектронным меркам размеры и на то, что, как мы и обсуждали выше, у Xilinx боевые чипы разбиты на несколько небольших кусков.
Больше, чем просто производительность
На рисунке ниже — внутренности корпуса АЦП компании Analog Devices и принципиальная схема. Выглядит как совершенно обычная печатная плата для АЦП, только поменьше, правда? Все так, это она и есть, только за счет использования бескорпусных компонентов уменьшились связанные с паразитными элементами погрешности, а то, что плата разработана в Analog Devices, позволяет им сэкономить кучу времени клиентов и заодно быть уверенным, что пользователь не накосячит, выбрав не те компоненты или плохо разведя плату.

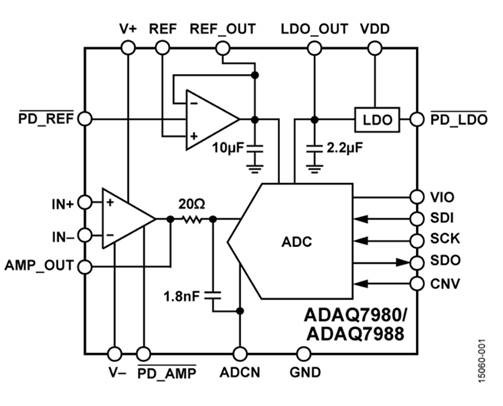
Впрочем, есть на рисунке выше и небольшая хитрость: видите уложенные в два этажа кристаллы? Верхний кристалл — это чип с активными компонентами собственно АЦП и (видимо) сдвоенного операционного усилителя, а нижний кристалл — это пассивные компоненты (конденсаторы и резисторы). Исполнение на отдельном кристалле позволяет сделать их намного больше размером (а значит уменьшить погрешности) без увеличения (а значит удорожания) основного кристалла.
Все то же самое можно сделать и на одном чипе (что, собственно, не редкость, особенно для АЦП, встроенных в микроконтроллеры), но такой чип будет гораздо больше (а значит, как мы выяснили, есть риск уменьшения процента выхода годных), а технология для него должна будет поддерживать все нужные дополнительные опции. Кроме того, объединение разных блоков на одном кристалле приведет к необходимости позаботиться о том, чтобы они не влияли друг на друга (например, как-то избавиться от шумов по подложке кристалла).
Дополнительные функции корпуса
Как мы уже выяснили, упаковка разнородных элементов (в том числе пассивных SMD-компонентов) в одном корпусе позволяет существенно уменьшить габариты конечного продукта и даже повысить скорость его работы. А что, если использовать сам корпус как функциональный элемент устройства?
В 2013 году в процессорах Intel (микроархитектуры Haswell) был реализован интегральный регулятор напряжения (FIVR — fully integrated voltage regulator), в котором активная часть регулятора была реализована на кристалле процессора, а пассивная (конденсаторы и индуктивности) — интегрирована в корпус.
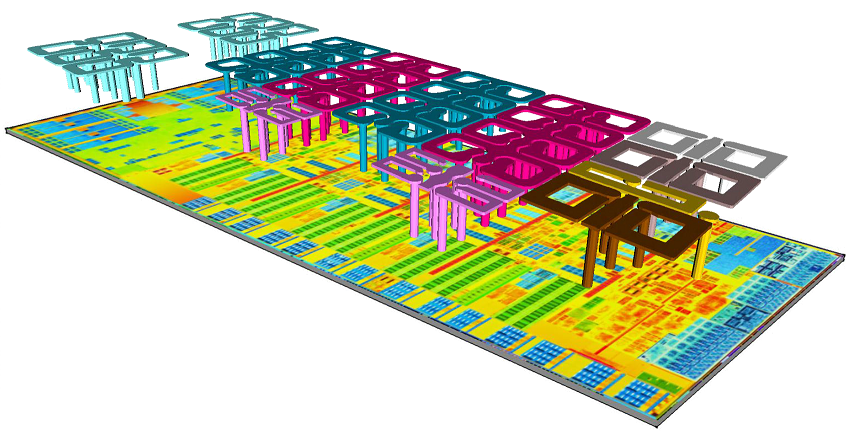
Интегральная индуктивность — головная боль всех разработчиков микросхем, потому что катушки на кристалле получаются не только с не самыми лучшими параметрами, но еще и огромные (а значит, очень дорогие, особенно на тонких технологиях). И это речь идет о сигнальных катушках без сердечника, ни о какой передаче мощности речи вообще нет. Intel успешно обошли эту проблему, интегрировав в корпус микропроцессора десятки паралельно стоящих небольших катушек, работающих на частоте 160 МГц. Так они смогли существенно упростить требования к питанию микропроцессора.
Впрочем, с этой разработкой что-то пошло не так, и в следующих за Haswell поколениях процессоров Intel FIVR уже не было. С тех пор ходили слухи, что к FIVR еще вернутся, но пока что они так и остались слухами.
Впрочем, и без Intel направление интеграции пассивных компонентов в корпус активно развивается, например, в корпусах типа LTCC (низкотемпературная керамика). Там, разумеется, есть свои ограничения и подводные камни (связанные, например, с точностью номиналов), но эта технология востребована и активно развивается. Многослойный LTCC-корпус выглядит примерно вот так:
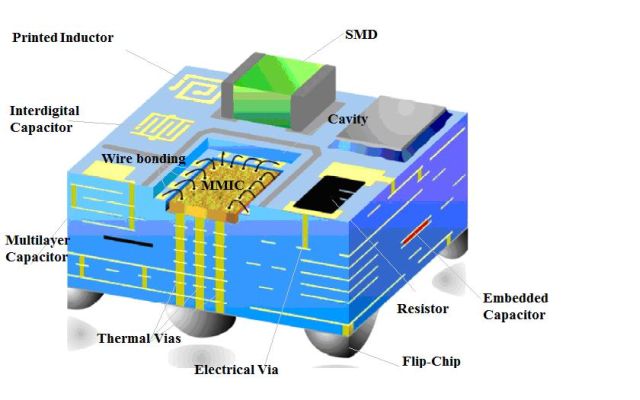
На рисунке видны все типы пассивных элементов, выполненные в многослойной керамике, и даже металлический теплоотвод (это корпус для мощной СВЧ-схемы). По сути, это смесь корпуса с керамической печатной платой. Такие штуки очень популярны для радиочастотных модулей, а еще они относительно дешевы в мелкосерийном производстве.
Что еще?
Потенциальных применений у систем в корпусе очень много, и перечислить их все практически невозможно; более того, постоянно появляется что-то новое, в том числе благодаря тому, что эти технологии существенно доступнее, чем 10-7-5-3-нанометровые транзисторы.
Хороший пример новых применений и свойств, которые открывает интеграция разнородных чипов в одном корпусе — это разнообразные оптические системы, где SiP позволяют собрать вместе приемник или излучатель (обычно изготавливаемые не на кремнии), и схему их питания и управления. На иллюстрации ниже — прототип оптического линка на 400 Гбит/c (а обещают до терабита), собранный в бельгийском исследовательском институте IMEC.

Кроме этого, в качестве перспективных применений для систем в корпусе рассматриваются такие вещи, как интерпозеры со встроенными капиллярами для жидкостного охлаждения (не только игровых процессоров, но и силовых ключей, и лазеров), интегрированные в корпус МЭМС-блоки и много чего еще интересного и не укладывающегося в узкие рамки закона Мура. Кроме того, важным рынком для систем в корпусе считается вездесущий интернет вещей, где важны малые размеры, отсутствие потерь (в первую очередь энергии, а не времени) на паразитных элементах и возможность интегрировать в корпус микросхемы пассивные компоненты, например части радиотракта.
Комментарии (66)

clawham
18.07.2018 11:15-5заголовок — мешанина желтизны и неразберихи.
Закон мура, кол-во транзисторов и вычислительная мощность — все в кучу.
Давйте так — вы приведете пример повседневной задачи обычного пользователя ПК которую не в состоянии «потянуть» обычный устаревший Core I5-2550 например! Это процессор не топовой линейки досктопных решений начала 12 года. ему уже 6 лет! Но в нем есть 3.8 гигагерца(а нередки экземпляры работающие на 4.5) в нем есть 8 метров кеша, в нем 4 чесных ядра без гипертрейдинга, в нем есть MFX с адовым ускорением конвертации видео, в нем теплопакет всего 95 ватт, а самое главное и замечательное — у него под крышкой ПРИПОЙ!
Так вот скажите мне какие такие мои аппетиты может обеспечить i5-7600k которых не может дать 2550к?
Заранее отвечу — никаких преимуществ нет. Вот вообще. нуль. только долбатся с термопастой под крышкой и проблемы с отводом тех же титанических 95 ватт не с 216 мм2 а со всего лишь 115, потовина из которых это графическое ядро а на сами ядра приходится по 14 мм квадратных. каждое ядро выдает по 20 ватт тепла. медь уже не справляется в таким тепловым потоком! Да сам кремний не справляется!
Так что статье низачод!amartology Автор
18.07.2018 11:25+1Давйте так — вы приведете пример повседневной задачи обычного пользователя ПК которую не в состоянии «потянуть» обычный устаревший Core I5-2550 например!
А я где-то говорил о том, что все это нужно для повседневных задач обычных пользователей? Все те ухищрения, о которых написана эта статья, в первую очередь предназначены для решения промышленных и коммерческих задач.
Так вот скажите мне какие такие мои аппетиты может обеспечить i5-7600k которых не может дать 2550к?
Мои рабочие аппетиты прямо сейчас обеспечивает довольно большой многопроцессорный сервер, расчеты на котором зачастую длятся часами. А есть люди, для удовлетворения рабочих аппетитов которых приходится строить суперкомпьютеры.clawham
18.07.2018 11:32-2Тем не менее, это уменьшение не приходит даром, а аппетиты пользователей растут быстрее, чем возможности разработчиков микросхем
Вы не пользователь и к серверным фермам это не относится никак — вам как пользователю такого вычислительного блока глубоко фиолетово 6 нм там процы и 10 серверов или 32 нм и 20 серверов — вы платите за мипсы в вашем распоряжении и время. надо больше — заплатили больше — арендовали весь серверный банк в какихто нидерландлах на 1800 машин по 24 ядра в каждой и делов-то.
Опять же — стремление покорить 6+ нм — чистый маркетинг и немного энергосбережения. частот выше 4 гигагерц не будет, дешевой оперативки не будет, дешевых ssd не будет, мощных ядер на один поток чтоб выдавали больше — тоже не будет. дело только за ростом вширину — набор команд ждя аппаратного ускорения каких-то тяжелых специфических вычислений — мы это уже давно видим с перегонкой видео н264 н265 — пока что даже 24 ядерный ксеон с сумарной площадью кристалла 518 мм2 не может тягаться с мелким 42 мм2 модулем MFP от того же интела по скорости перегонки видео. Вот и весь сказ. Оптимизация. она всеравно пришла к нам и всеравно приходится при написании мощных программ думать — что лучше один раз умножить с использованием аппаратного умножителя чем 900 раз суммировать софтверно но зато на бешеной частоте и в 24 потока.amartology Автор
18.07.2018 11:50вам как пользователю такого вычислительного блока глубоко фиолетово 6 нм там процы и 10 серверов или 32 нм и 20 серверов — вы платите за мипсы в вашем распоряжении и время
Вы же понимаете, что если в сервер вместо Х процессоров по Y MIPS каждый просто поставить X*2 процессоров по Y MIPS каждый, то производительность сервера вырастет существенно меньше, чем в два раза? И что производительность суперкомпьютеров давно уже определяется эффективностью интерконнекта, а не только и не столько процессорами?
Опять же — стремление покорить 6+ нм — чистый маркетинг
Для ПЛИС и их пользователей — нет. Для тех, кто проектирует системы охлаждения дата-центров — нет. Для людей, которые арендуют мощности дата-центров за деньги — важно, за сколько денег это можно сделать.
А еще статья — не о стремлении покорить 6- нм, а о корпусировании. В приведенном мной примере АЦП только один чип ниже 180 нм, а остальные хорошо если 600 нм.DaylightIsBurning
18.07.2018 13:03производительность суперкомпьютеров давно уже определяется эффективностью интерконнекта
Всё несколько сложнее. Есть очень узкий круг задач, где есть смысл и дальше увеличивать скорость интерконнекта. Остальные задачи либо плохо параллелятся вообще и не выходят за пределы 1-10 нод ни при каких условиях, либо параллелятся очень хорошо и тогда интерконнект не нужен, ethernet на 10Gb (если не 100Mb) более чем достаточно — то есть датацентр/облако предпочтительнее суперкомпьютера, особенно с учётом цены. Криптовалюты — известный пример, но их очень много таких. Драйвером для индустрии суперкомпьютеров (в противовес датацентрам) отчасти является распил и PR. Сейчас, правда некоторый уклон в сторону датацентров и «гибридных» суперкомпьютеров пошел, когда к СК прикручивают сбоку «boost units» — фактически обычный массив нод, связанных по 1-10GB ethernet.
xRay
18.07.2018 11:39+1Так вот скажите мне какие такие мои аппетиты может обеспечить i5-7600k которых не может дать 2550к?
PCI Express 3.0, Intel AVX2, Intel VT-d, тех.процесс 14 nm (вместо 32 nm)
Для сравнения 2550к и процессоры 7-го и 8-го поколений https://ark.intel.com/ru/compare/65647,97144,126685clawham
18.07.2018 11:52-2ещё раз — смотреть котиков в ютубе, серфить сайты, перегонять видики для устройств, играть в игры, работать в компиляторах под 99% платформ, симулировать схемы в протеусах и прочем — все прекрасно легко и один-в-один по скорости что у 2 поколения что у 8-го. только в 8-м в i3 всунули 4 ядра а в i5 — гипертрейдинг врубили. скорости это никак не добавило. а те 5-10 % легко компенсируются разгоном.
old_bear
18.07.2018 13:12Если производители софта, который вы используете, не сделали поддержку AVX2, то это только ваша беда, а не производителей процессоров. Этот AVX2 временами вдвое ускоряет всякое там моделирование. Если поддержка в софте есть.
clawham
18.07.2018 18:21-1а я это же и написал! некуда расти уже ни по частоте ни по ядрам — только в наборы специнструкций чтоб какие-то определенные сложные вычисления делать одной командой аппаратной. примером привел интеловский же quickSync — просто шедевральный пример как +20% транзисторов и площади кристалла к обучному 4-ядернику добавили ему 20 кратно производительности — но только в одной узкоспециализированной задачи — перегон 264 видео. так и ваши векторные инструкции. с какого поколения интелов они появились? 4 поколение нуок ш3 4370. 2-е поколение я привел просто потмоу что сижу на работе за 2- i5 а дома i5-7600k — разницы нету от слова вообще. да немного быстрее перегонка видео и в синтетике выигрывает на 10% новый но в том же винраре скорость упаковки 10 гиговой базы что там что тут +- в пределах погрешности. и там и тут стоят pcie ssd patriot hellfire 240 гб выдающая 3.3 гига в секунду чтения и 2.4 записи. вот она реально сильно увеличила производительность. ну а вам тогда дорога в 2011 и опять менять материнку ибо интел опять ради одинаковых архитектор но другого рыночного сегмента — поменяла сокет :)
Gryphon88
18.07.2018 19:29некуда расти уже ни по частоте ни по ядрам — только в наборы специнструкций
Не-не-не, уже проходили этот бугурт с CISC vs RISC, хватит, всё равно большую часть инструкций использовать не будут, а место на кристалле сожрётся. Зачем ПЛИС ставят рядом с процом — я ещё понимаю, но вот раздувание набора инструкций — совсем лишнее.Cenzo
19.07.2018 00:42Для некоторой достаточно стандартной функциональности аппаратное ускорение инструкций просто спасение. Сравните скорость шифрования и нагрузку на проц с AESNI и без него.
Gryphon88
19.07.2018 01:49Я просто к тому, что нельзя плодить инструкции, в том числе по требованиям вендоров и сообщества. Я не против часто используемых (и поддержку которых в компиляторы не очень сложно добавить), те же шифрование и хэширование используют много где, а вот аппаратный кодек H264, если вдруг меня кто спросит, уже не стал бы добавлять.
Уже сейчас можно писать оптимальный по скорости и размеру код, используя векторизацию, GPU и мозг, но этим обычно не занимают — это не является конкурентным преимуществом в домашних применениях.
gospodinputin
18.07.2018 16:28+4Смузихлебы каждый день рожают по сотни фреймворков, где хеловорд запросто сожрет любые ресурсы.
holomen
18.07.2018 19:15+2Это у вас просто задачки простенькие не дальше котиков и схемки мелкой в протеусе.
А у меня вотпрямщяс открыт проект в альтиуме с несколькими сотнями компонентов и эта плата передана в солид в котором вокруг этой платы проектируется корпус и прочее присоединительное. Да, они нужны открытыми одновременно. Ну и конечно вот всякие хабры, музычка и прочее… И разница совсем не 5-10%, а прям видна.
GloooM
18.07.2018 11:42+3А если подойти с другой стороны, оставив за рамками нужный только совсем упоротым оверклокерам припой, то эволюция технологий позволяет вместо i5-2550 купить i3-8100 и получить производительность даже выше, так еще и на треть меньший TDP и все это за в два раза меньшую стоимость. И термопаста под крышкой один из факторов снижения цены, технологически она сильно проще.
clawham
18.07.2018 11:55припой это долговечность. термопаста это 99+ градусов на чипе, термоперекосы, трещины и т.д. 2-3 года и привет. пошел покупать «новый» «лучший»… выманивание денег.
Сугубейше могучий недостаток этит субстратов — память например часто дохнет. обычную ты взял и переткнул планку, а в этом девайсе на подложке? или пример с xbox fat был какой? на одной подложке чипсет, видеокарта и их мостик — мелкий кристаллик pciexpress мостика. он сдыхает и все — весь xbox в мусорку так ка кперепаять его нет никакой возможности в то время как на материнской плате замена такого мостика цена вопроса — 50 уе с работой.encyclopedist
18.07.2018 12:01+32-3 года и привет
память например часто дохнетМы с вами определённо живём в разных вселенных.
Upd: хотя учитывая что вы писали про разгон, всё ясно
zerg59
18.07.2018 13:34+9Сугубейше могучий недостаток этит субстратов — память например часто дохнет. обычную ты взял и переткнул планку,
Папаня как-то рассказывал про доводы борцов с микросхемами в СССР: Как же так — один транзистор в микросхеме сдохнет — и всё выбрасывать всю микросхему? Нерациональненько!
oldbie
18.07.2018 12:29+1И термопаста под крышкой один из факторов снижения цены, технологически она сильно проще.
Да какая экономия. На фоне остальных тех. сложностей и умопомрачительных ухищрений (в т.ч. из этой статьи) решение использовать термопасту выглядит как экономия на спичках. Кроме того сами представители Intel в различных интервью в попытках объяснить\оправдать такой шаг как будто не имеют единого мнения. И порой даже говорят не про экономию, а что такое охлаждение оправдано технически: мол более эффективный отвод тепла припоем приводит к большим перепадам темпеартуры что негативно сказывается… ИМХО это обычное маркетинговое свинство. Но что меня больше всего изумляет, так это люди-покупатели которые вроде как совсем не против. Им же продают товар худшего качества, но они не то что не возмущаются, а даже оправдывают intel и рьяно приветствуют такие вот повороты.
Ну а то что прогресс оправдан, пусть и небольшой относительно, я с Вами соглашусь.GloooM
18.07.2018 13:23+2Термопасту намазал, шлепнул крышку и готово, припой же во первых сам значительно дороже, во вторых имеет некую агрессивность и нужны соответствующие покрытия что чипа, что крышки, а еще его таки наверняка сложнее в поточном производстве нанести и все такое.
Я конечно понимаю что припой это прям круто и все такое, но для 95% юзеров он не нужен и лучше чтоб цена снизилась. Вот у меня сейчас 8400 стоит под 700 рублевым кулером, в простое 35 градусов, под нагрузкой может до 65 подняться и меня вполне устраивает термопаста под крышкой, никакого криминала не вижу.
Для всяких гоночных процов конечно понимаю возмущение, что за такую цену они туда припой не положили.
lokkiuni
18.07.2018 14:28В определённый момент 35 превратится в 65, а 65 — в 105+ и троттлинг. Так было с АМДшными процами с пастой, нВидиевскими видеокартами с пастой, со старыми интеловскими процами с пастой. И если скажем в пне или и3 это приемлемо, то в и5-и7 уже не очень-то, а уж в workstation-линейке совсем свинство.
GloooM
18.07.2018 14:43+1Что-то вы слишком категоричны накидывая 40 градусов, вот как раз хотел свой опыт с GTX570 описать недавний, после скальпирования и замены родной термопасты температура упала аж на целых ого-го 5 градусов. Но эта видеокарта за 7 лет уже морально устарела так, что это я делал just 4 fun, и этого орущего вентиляторами монстра, требущего 500Вт+ БП уделывает по производительности GTX1050 без доп питания и кулером с ладошку. А еще у всех этих высохших термопаст есть общее то, что они стояли на изначально горячих кристаллах, где в простое было под 60, а в нагрузке 80+, понятно что там оно теряет свойства быстрее, но применительно к 8400 я думаю проблемы высыхания вообще не встанет в разумных сроках.
Производители конечно злодеи что делают запланированное устаревание, но эти железки в плане производительности устареют много раньше чем физически сломаются.lokkiuni
18.07.2018 14:53Ну у каждого своя выборка, далёкая от статически значимой, это раз. Мне попадались ещё актуальные железки с уже мёртвым ТИ.
Два, если бы при этом в 8600-8700 и 2066 был припой — никаких как раз таки вопросов бы и не было.
clawham
19.07.2018 08:46мой i5-7600k без разгона в штатном режиме тротлил через 2 секунды после запуска винрара. ну а при запуске OCCT — тупо умирал до 2.8 гигагерц! температура при этом в простое и в ютубах была 60 а вот любая малейшая нагрузка и привет 99 — тоесть верхний порог его тротла. кулер у меня на 5 тепловых трубках размером с пол материнки и продувается отлично но с коробки этот проц его никогда никак не нагревал — можно было выключить вентиляторы и всеравно кулер был ледяной. после скальпинга и нанесения жидкого металла (вот это кстати именно жм требует спецпокрытий и агресивен так как растворяет собой алюминий) в простое стало 65 а под нагрузками 75. ну а под occt 85/ при этом трубки кулера всеравно не были до 85 нагреты — на них реально было 50 как и на крышке проца — тоесть даже жидкий металл не способен от крошечного по площади ядра отвести 20 ватт тепла. это проявлялось и в загрузке только одного ядра — на нем было 82 а на соседних трех по 60. в то же время на рабочек проце на более хреновом техпроцессе с огромной площадью ядер и припоем — нагрузка одного ядра приводит всего к 5 градусам разбегу между нагруженным и простаивающим ядром. меньше техпроцесс — это не только меньше потребления(они это потребление назад накрутят нарастив частоты) но и меньшая площадь отвода тепла
amartology Автор
19.07.2018 08:55тоесть даже жидкий металл не способен от крошечного по площади ядра отвести 20 ватт тепла.
Так чем больше ядро, тем проще отводить тепло. Надо же смотреть не на полное тепловыделение, а на удельное, и на температурное сопротивление теплоотвода.
В силовых микросхемах, где мощности выделяется относительно много, а активного охлаждения нет, обычно часть дна корпуса, на которой сидит кристалл, металлическая (медная) и дальше припаивается к большому металлическому полигону на плате, который отводит тепло дальше. Смотрите предпоследний рисунок, там показаны thermal vias в корпусе.clawham
19.07.2018 09:08вы правда считаете что олово проводит тепло лучше чем массивная медная пластина за которой 5 тепловых трубок через mx-4?
мы тут ведем речь о том что когдато intel припаивал кристалл к медной крышке от которой потом уже достаточно легко отвести тепло т.к. она достаточно большая по площади. в отличие от изрыгающего тепло кристалла а точнее маленького участка в 125*0,78/2/4 = 12 мм квадратных. и с этой площади надо снять ажно 95/4(хотя реально проц жрет 120 но пусть будет по шиту — 95) 23 ватта тепла! это два ватта с мм2
если взять старый 32 нм техпроцесс то там цыфра получается всего в 0.7 вт/мм2 тоесть тепловыделение на квадратный милиметр увеличилось в 2,85 раз и они вместо припоя(который намного более стабилен во времени и естественно намного лучше проводит тепло от кристалла к крышке) налили дешевой никудышней термопасты(потому что если её заменить на обычную КПТ-8 то результаты уже лучше — на 3 градуса ниже в простое и на 5 градусов ниже под небольшой нагрузкой(винрар)!!! И всеравно находится целый клан людей которые утверждают что это — лучшее техрешение на сегодняшний день и что им припой под крышкой не надо!!! вот что странно и страшно!
clawham
19.07.2018 09:17Простая аналогия — берем силовой транзистор IRF4410 и растворяем его компаунд в кислоте. видим кристалл площадью «всего» 20 мм2 он намертво припаян к медному основанию за которое его уже прикручивают к теплоотводу. теперь представим что вместо припаять кристалл они тоже долбанулись и налили термопасты
открываем даташит — там четко указано термосопротивление кристалл-подложка — 0.61 градус на ватт! открываем лучшие термопасты и что мы видим? 8 градусов на ватт, 16. лучшие 4 градуса на ватт. ничо не смущает?amartology Автор
19.07.2018 09:35Так я про то и говорю, что лучшее решение — кусок меди, прицепленный прямо к кристаллу.
clawham
19.07.2018 09:44опять же возникает вопрос через что? если через припой то круто но вот люди пишут нет — круче термопаста а припой дорого долго и невкусно :) Странные они :)
naviastro
18.07.2018 12:18+1А зачем для обычого пользователя в повседневных задачах проц с буковкой «к», разгоном развлекаться? Тогда да, сендибридж может и интереснее, но тогда встаёт и вопрос о повседневности таких задач и обычности такого пользователя). И статья вроде не про то.
Разница, например, может быть в производительности на Ватт, за 6 лет эта разница стала очень существенной, ещё — в аппаратной поддержке новых интерфейсов (PCIe 3 vs 2, макс. объём/частота оперативы, и т.д.) и расширений CPU/GPU (AVX2, VT-d, новые DirectX/OpenGL, 4K). У меня так получилось, что сендик намного шумнее работает по сравнению со скайлейком, не смотря на то, что у последнего кулер сильно проще и дешевле (оно меньше греется? и это на вычислит. задачах?). Кремниевым разработчикам и производителям приходится очень повыёживаться для движения вперёд, однако коммерческий спрос на это есть. И также очевидно, что далеко не для всех накопленная за несколько лет разница будет реально достаточным стимулом вкладываться в новое железо, я Вас в этом плане понимаю.JC_IIB
18.07.2018 12:50А зачем для обычого пользователя в повседневных задачах проц с буковкой «к», разгоном развлекаться?
Тоже обратил внимание… «я весь такой обычный пользователь с котиками, мне всего хватает, но процессор я куплю с буковкой К, и да, там же ПРИПОЙ!!»
Ну припой. И чего? Вы обычный пользователь или у вас он 24х7 нагружен на все ядра? Котиков смотреть — температура небольшая.
p.s. ну когда же уже там 32-ядерный проц от AMD в продажу поступит…lokkiuni
18.07.2018 14:30Котиков смотреть — температура небольшая
Всё бы ничего, но она высыхает со временем. И да, потом приходится снимать крышку и т.п., т.к. процессор перестаёт работать в штатном режиме, просто перегревается под незначительной нагрузкой.JC_IIB
18.07.2018 14:37А быстро она высыхает?
lokkiuni
18.07.2018 14:49Годы, дальше — в зависимости от условий и собственно термопасты. Атлоны64 под АМ2 массово попадаются высохшие (но там младшие были с пастой, старшие — с припоем), видеокарты 4х0-5х0 массово попадались высохшие лично мне примерно во время выхода 780ти, т.е. оставаясь вполне себе актуальными, и это именно игровая эксплуатация. На счёт интела — случаи слышал, насколько часто и т.п. — не знаю. Мой и5-760 лет так несколько назад тоже просил замены термопасты, но ещё не на столько чтобы прям пора — градусов так 5-10 можно было скинуть, но мне было не нужно, разгона почти не было, а водяное охлаждение осталось (по другим соображениям).
JC_IIB
18.07.2018 14:55Странно, Athlon II x3 64 несколько лет отработал безупречно.
Впрочем, если высыхание занимает «годЫ» — я не стану беспокоиться.
clawham
19.07.2018 08:36-1обратили внимание и маладцы. родной штатный 7600к саморазгоняется 3.8-4.2 я просто зафиксировал его в биоче на уровне 4.5 это не разгон по меркам многих но зато на одно ядро я всегда получаю все на что способен проц.
аналогично и на работе 3.6-3.9 штатный разгон — ну я оставил его на 4.2. он то работает и на 4.5 и на 4.8 даже и тесты стабильности по 10 часов проходят но у меня разгон не самоцель.
Да когда я за ним — то смотрю котиков и сериальчики а ночью и днем пока я на работе — переганяются фотки cr2 в jpg с постобработкой скриптами, переганяется видео, рендерится склейка в премьере. и таки мне реально всеравно займет оно 4 часа или 3.5 — для меня разницы нет — и так и сяк — оставлять наночь. а вот перегонка quicksync ом это сила — вместо 8-ми минут тот же ролик в то же качество переганяется за 20 секунд. это реальный прирост. такого уже не получить никаким кол-вом ядер — проверял на серверном ксеоне — не смог. частоты в 8 гигагерц тоже пока не светят так что реальность такова что дальнейший рост в разы невозможен. +10-20% в общих задачах и до 10-20 раз в узкоспециализированных когда появится соответствующий апаратный блок. это намного более плодотворная почва для работы
DarkNews
19.07.2018 08:13Эм, как бы — играть в игры.
4 ядерный процессор уже не справляется с современными играми на максимальных настройках, статтеры, фризы, и далее по списку.
И чего вы сравниваете с 7600 то, а не с 8600?
Или +2 ядра это так, фигня?clawham
19.07.2018 08:26это все связано с шиной к карте и производительностью на одно ядро. не знаю игр которые бы грузили на все 100% все 4 ядра. гипертрейдинг не дополнительные ядра. Речь о том что 24 ядра или 16 ядер любой игре пофик.Играм и 99% всех задач нужна производительность на одно ядро побольше а собственно ядер для рядового пользователя 2 а для продвинутого 4.
Примером могу привести статистику за полтора года владением 4ядерником — больше 75% загрузки проца (тоесть больше 3-х полностью загруженных ядер) я использовал всего 120 секунд!!! это из около 150 000 секунд аптайма! Я и фильмы перегоняю и в премьере работаю, фотошоп, вижуал студии три штуки разных версий, солидворкс, симуляторы схем, трассировщики, архиваторы само собой. ну и пара игр. 120 секунд. и из них секунд 30 — это пара тестов и пара ошибок с потоками в прогах — они тупо зажирали весь проц сколько бы нибыло ядер по ошибке бесполезно. Так и вопрос — зачем мне 6 8 12 ядер когда 80% времени я использую всего полтора ядра?!?!
С 8600 я не сравниваю т.к. не сидел за i5-8600 — только i3 и он не показал ни разгонного потенциала ни какой бы то нибыло прибавки на один поток. А шел он на 1С сервер для мелкой фирмы(7 пользователей) и там важна была производительность именно на одно ядро. Сложно было ему подобрать хорошую память чтоб и 3600 было и тайминги не 15 и обьем 16 гиг. Вот с памятью сейчас реально проблемы — реально хорошей ddr4 пока что можно урвать только волею случая. в отличие от ddr3 — да она на все 4 ядра уже бутылочное горлышко но зато с нормальными таймингами и частотами её полно — отработанный техпроцесс.DarkNews
19.07.2018 12:16Какой гипертрендинг еще? Вы в теме не пробовали разобраться сначала? У i5 8 поколения нет его, у них просто 6 ядер.
И да, современные игры грузят 4 ядра на 100%.
Все 4 ядра, гуглите тесты любых современных игр.
И с шиной к карте это никак не связано.
И даже больше скажу, даже старые игры так делали, например 3 крайзис во многих сценах, например в эпизоде с полем и большим количеством растительности.
P.S Только что на 6 ядернике запустил архивирование файла в 7zip, с ультра сжатием, все 6 ядер на 100%.
Да да. нет задач.clawham
19.07.2018 14:27дадада 7zip это скорее исключение чем правило т.к. всеравно дольше пакует и таки да… не заметил что в i5 они впихали ещё два ядра но зато снизили базовую тактовую до 3.6 :) а турбобуст до 4. тоесть мой 7600 к в общем-то на одно ядро выиграет и на два выиграет и на 3 и на 4 тоже выиграет а вот на 6 — ну хз я ж говорю — небыло у меня в руках i5-8xxx потому ничего говорить не буду. И странное дело — техпроцесс тот же, ядер больше частоты +- те же а TDP не изменился… трындят где-то в интеле походу. но мне и 3 ядра было не надо 99.9% времени.
DarkNews
19.07.2018 15:55Во первых турбобуст в 8 поколении выше, чем в 7.
Смотрите спецификации.
Во вторых, из за этого буста, и большего кеша даже в производительности на одно ядро 8600k лучше, чем 7600k
greentechreviews.ru/wp-content/uploads/2018/01/21-1.png
Я уже молчу о поддержке DDR 4 с более высокими частотами.
В третьих — 7zip не исключение, а правило, любое приложение которое умеет в многопоточность, при сложной задаче грузит 6 ядерник на 100%.clawham
19.07.2018 16:04у вас в руках есть 8600k?
можете показать winrar на один поток и на 6?
ну и приведите память какая, частоты и тайминги — и сравним ок?
судя по офиц данным — не больше у него буст и базовая частота не больше
ark.intel.com/products/97144/Intel-Core-i5-7600K-Processor-6M-Cache-up-to-4_20-GHz
ark.intel.com/ru/products/126685/Intel-Core-i5-8600K-Processor-9M-Cache-up-to-4_30-GHz
7600k
Processor Base Frequency
3.80 GHz
Max Turbo Frequency
4.20 GHz
8600k
Базовая тактовая частота процессора
3,60 GHz
Максимальная тактовая частота с технологией Turbo Boost
4,30 GHz
или вы будет едоказывать что 100 мегагерц к тактовой дало вдвое повышение производительности?
Стойтека. а чо ж вы тогда не на тредрипере сидите? там сколько потоков? пока что интел по именно многоядерности и по производительности этой многоядерности амдшкам и сливает… но как сливает +-10% я не считаю ни сливом ни вином. вот где амд реально сливает так это в латентности памяти и производительности на одно ядро. это да и потому я на интелле и сижу — мне очень важна производительность на одно ядро!DarkNews
19.07.2018 16:08Есть, но сделать это я смогу только вечером, когда буду дома.
Хотя смысла в этом если честно ровно 0, этих тестов по всему интернету полным полно, и главное — сделаны они в равных условиях.
Вот например многопоток:
greentechreviews.ru/wp-content/uploads/2018/01/4-5.png
Где 7600k сливает более чем на треть.
Fandir
19.07.2018 13:52+1Что бы сидеть в ВК, все описанное абсолютно не нужно, а вот уже что бы управлять марсоходом возможно и пригодится… SiP в космос активно начинает проникать и даже в наш…
amartology Автор
19.07.2018 14:05Космос — это вообще отдельная большая история. То, что SiP сейчас в каждом втором мобильнике — даже более показательно)
{kind=link}
{kind=link}
bagamut
18.07.2018 11:52+1Теперь еще добавилась хитрость как все это богатство выбора под крышкой корпуса собрать. А с уменьшением технорм, увеличением количества контактов и количества различных чипов, это становится все более непросто.
SergeyMax
18.07.2018 20:03проходящего на фоне проблем Intel с запуском нового техпроцесса из-за низкого выхода годных на огромных чипах
Про проблемы с выходом годных чипов у Intel я слышу все последние двадцать лет, начиная с Pentium Pro. Что забавно, в этой статье двадцатилетней давности тоже объясняется, почему кэш второго уровня следует вынести на отдельный чип)
hardegor
18.07.2018 22:50Вы несколько переборщили с натягивание новых терминов на известные технологии — уже более полста лет известны гибридные микросхемы. Наверное процессоры нельзя к ним отнести, но СВЧ и АЦП — однозначно.
Увидеть можно на www.155la3.ruamartology Автор
19.07.2018 00:10Это не я натягиваю, это отрасль натягивает. Гибридные схемы давно известны, это факт, и все новое — в какой-то мере забытое старое, это тоже факт. Можно назвать все системы в корпусе гибридными ИМС, но термин СвК уже пришел и прижился, и сейчас как раз возврат к старому термину станет натягивание совы на глобус.
И в любом случае, пассивные элементы, интегрированные внутрь корпуса СВЧ-модуля (с СВЧ МИС, а не отдельными транзисторами) — это шаг вперёд по сравнению с гибридной схемой, и сборка из нескольких функционально сложных чипов, составляющая АЦП — тоже шаг вперёд.hardegor
19.07.2018 09:22Вот SoC на каждом шагу упоминают, а термин СвК первый раз слышу, но выглядит как обычный пиар. Тот же IBM уже лет -дцать назад делал процессоры на нескольких кристаллах, еще у кого-то были, сейчас просто улучшились технологии.
Первые гибриды, да, были на одних дискретных элементах, но как только появились кремниевые чипы, они сразу стали ставится в гибридные микросхемы.
Про СВЧ вы видимо вы «не в теме» — практически все делаются по такой технологии, потому что большинство из СВЧ микросхем продается в виде кристаллов и только меньшая часть(обычно низкочастотные) корпусируется производителем, потому что кристалл проще согласовать и уменьшить потери — там каждый дБ на счету.
Аналогично с цифро-аналоговыми микросхемами, тот же Analog Devices начинал с гибридных микросхем и некоторые названия не прекращают выпускать до сих пор, плюс добавились приведенные вами созданные по новым технологиям.amartology Автор
19.07.2018 09:47Про СВЧ я действительно только мимо проходил, но повышение степени интеграции МИС наблюдаю.
Что касается термина «СвК», то «SiP» в активном использовании уже лет десять так точно — во многом, разумеется, в пику SoC. Разумеется, в переименовании гибридок есть доля маркетинга, но есть и то, что сначала большие системы собирались на плате или как гибриды, потом было довольно много лет, когда главным трендом было упихать вообще все на один кристалл, а теперь гибриды возвращаются, с новым именем и новыми технологиями.
beeruser
19.07.2018 03:48Размер этих процессоров достигает сумасшедших 456 квадратных миллиметров
Площадь GV100 — 815 мм?
amartology Автор
19.07.2018 08:27Поэтому в ней к 80 работающим ядрам (точнее, SM-блокам по 64 ядра) сразу прилагаются четыре запасных)
Такой размер кристалла — это, конечно, просто «безумству храбрых поем мы песню». И, кстати, стеки с памятью в том же корпусе у GV100 тоже есть.
Спасибо, загуглила про самый большой чип в истории я что-то сам не догадался.
PS Второе место у одной из моделей Итаниума.

denis-19
19.07.2018 08:42Десять лет назад разводка ПЛИС Ксайлинкс и Альтера в Protel Altium была очень простой, делал вручную без авторутера. А вот сейчас все более плотнее и слойнее.
Nubus
19.07.2018 19:21Корпус вокруг всех систем выполняет так-же и экранирующую роль. Я работал в компании где надо усиливать 2 IR аналоговых сигнала двумя разными схемами и температурный дрифт должен совпадать. Заказали в TI сначала matched безкорпусные схемы, так на тестовом стенде иногда шкалы подстройки нехватало для совмещения графиков. Потом заказали в TI обычные, но с корпусом и они мало того что в 2 раза дешевле, так и дрифт у них совпадает намного лучше в 10-15 раз в среднем.
amartology Автор
19.07.2018 21:15Корпус и температурный дрифт аналоговой схемы — это тоже отдельная тема. Характеристики меняются при корпусировании из-за термических и механических нагрузок, и у корпусированной схемы температурные характеристики могут быть вообще не такими, как у голого чипа. Поэтому, например, современные источники опорного напряжения подстраивают после корпусирования, а не на пластине, благо подстройкв прошивкой OTP этому способствует.
У вас скорее всего была такая же история — matched bare die разматчились в процессе размещения на плате.Nubus
20.07.2018 04:35Они зеркально расположены на схеме. Просто при нагреве около 60+ градусов они начинали свою свистопляску, плюс сигналы разные по силе. Хотя возможно и вы правы, но после пробы корпусированных схем мы отказались от bare die в принципе.
CorneliusAgrippa
Тут основное ограничение не размер корпуса, а поле зрения фотолитографического сканера, который печатает чипы. Его максимальный размер — примерно
Чтобы сделать кристалл больше нужно будет сшивать несколько проходов сканера — а это жуткий геморрой.
amartology Автор
Ага, спасибо, сейчас добавлю этот момент в текст.
sstas
А что мешает увеличить поле зрения?
amartology Автор
Усложнение оборудования удорожает его, особенно в ситуации, когда какие-то части оборудования приходится разрабатывать заново (а это почти наверняка так в этом случае). Постройка современной микроэлектронной фабрики и так стоит порядка десяти миллиардов долларов, куда еще дороже-то?
CorneliusAgrippa
Увеличить поле зрения мешает размер линзы, которую можно изготовить с отсутствием искажений. Ну и как сказал amartology — больше = сильно дороже, а это никому особо и не нужно. Как сверхзвуковые пассажисркие перевозки.
amartology Автор
В комментариях ниже (и небольшой гуглежке) передают, что максимальный размер ретикла — 835 мм2, а самый большой из существующих логических чипов — это Volta из NVIDIA GV100 — 815 мм2 на 12 нм технологии.

Также сшивка окон — обычная процедура для создания фотоприемников (обычно по старым техпроцессам, так как им нужны большие пиксели), и там размеры чипа бывают совсем адовые. Сенсор от камеры Kodak Kaf39000 (2006 год) имеет размер 2000 мм2 и выглядит примерно вот так: