
Всем привет!
Компания Netсracker уже много лет разрабатывает и поставляет enterprise-приложения для мирового рынка операторов связи. Разработка таких решений достаточно сложна: в проектах участвуют сотни людей, а количество активных проектов исчисляется десятками.
Раньше продукты были монолитными, но сейчас мы уверенно двигаемся в направлении микросервисных приложений. Перед DevOps появилась достаточно амбициозная задача — обеспечить этот технологический скачок.
В итоге мы получили удачную концепцию сборок, которой хотим поделиться в качестве передовой практики. Описание реализации с техническими деталями будет достаточно объёмным, в рамках данной статьи мы не будем этого делать.
В общем случае сборка — это превращение одних артефактов в другие.
Кому это будет интересно
Тем компаниям, которые поставляют готовое ПО совершенно сторонней организации и получают за это деньги.
Вот как может выглядеть разработка без внешней поставки:
- IT-департамент на заводе разрабатывает ПО для своего предприятия.
- Компания занимается аутсорсом для иностранного заказчика. Заказчик самостоятельно компилирует и эксплуатирует этот код на собственном веб-сервере.
- Компания поставляет ПО внешним заказчикам, но под open source лицензией. Большая часть ответственности, таким образом, снимается.
Если вы не сталкиваетесь с внешней поставкой, то многое, написанное ниже, покажется лишним или даже параноидальным.
На практике всё должно быть выполнено с соблюдением международных требований к используемым лицензиям и шифрованию, иначе возникнут как минимум юридические последствия.
Пример нарушения — взять код от библиотеки с лицензией GPL3 и встроить его в коммерческое приложение.
Появление микросервисов требует изменений
У нас накоплен большой опыт в сборке и поставке монолитных приложений.
Несколько Jenkins-серверов, тысячи CI job, несколько полностью автоматизированных сборочных конвейеров на базе Jenkins, десятки выделенных release-инженеров, своя экспертная группа по конфигурационному управлению.
Исторически подход в компании был такой: исходный код пишут разработчики, а конфигурацию сборочной системы придумывают и пишут DevOps.
В итоге у нас было две-три типовых сборочных конфигурации, рассчитанные на функционирование в корпоративной экосистеме. Схематично это выглядит так:
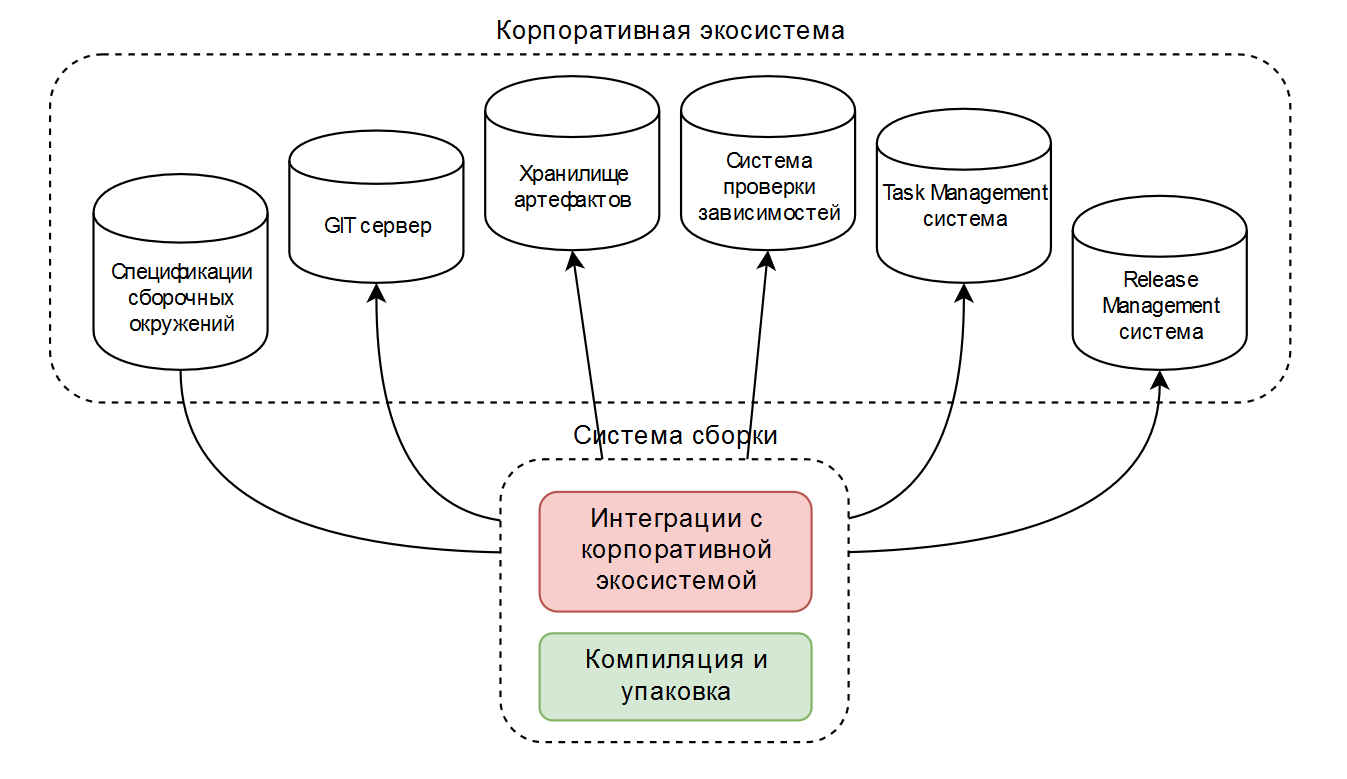
В качестве инструмента сборки обычно выступает ant или maven, и что-то реализовано общедоступными плагинами, что-то дописано самостоятельно. Это хорошо работает, когда в компании используется узкий набор технологий.
Микросервисы отличаются от монолитных приложений в первую очередь разнообразием технологий.
Получается очень много сборочных конфигураций как минимум под каждый язык программирования. Централизованный контроль становится невозможным.
Требуется максимально упростить сборочные скрипты и дать возможность разработчикам править их самостоятельно.
Кроме простой компиляции и упаковки (на схеме зелёным цветом), эти скрипты содержат много кода для интеграции с корпоративной экосистемой (на схеме красным цветом).
Поэтому было решено воспринимать сборку как «чёрный ящик», при котором «умное» сборочное окружение может решить все задачи, кроме непосредственно компиляции и упаковки.
В начале работы было непонятно, как получить такую систему. Принятие архитектурных решений для DevOps-задач требует наличия опыта и знаний. Как их получить? Возможные варианты ниже:
- Поиск информации в Интернете.
- Собственные опыт и знания DevOps-команды. Для этого хорошо составлять эту команду из программистов с разносторонним опытом.
- Опыт и знания, получаемые за пределами команды DevOps. Многие разрабочики в компании имеют хорошие идеи — надо их услышать. Коммуникация полезна.
- Изобретаем и экспериментируем!
Нужна ли автоматизация?
Для ответа на этот вопрос нужно понять, на каком этапе эволюции находятся наши подходы к сборкам. В общем случае задача проходит следующие уровни.
- Уровень «неосознанный»

Нужно выпускать одну сборку в неделю, наши ребята отлично справляются. Это естественно, зачем об этом говорить?
- Уровень «ремесленник», со временем трансформирующийся в уровень «ловкач»

Надо выпускать две сборки в день стабильно и без ошибок. У нас есть Вася, он круто это делает, и никто, кроме него, на это время не тратит.
- Уровень «мануфактура»

Дело зашло далеко. Необходимо 20 сборок в день, Вася не справляется, и вот уже сидит команда из десяти человек. У них есть начальник, планы, отпуска, больничные, мотивация, тимбилдинги, тренинги, традиции и правила. Это специализация, их работе надо учиться.
На этом уровне задача отделяется от конкретного исполнителя и тем самым превращается в процесс.
Результатом будет чёткое, отработанное, обкатанное и подправленное сотни раз описание процесса текстом.
- Уровень «автоматизированное производство»

Современные требования к сборкам растут: всё должно быть быстро, безотказно, в день надо обеспечить 800 сборок. Это критично, потому что без таких объёмов компания будет терять конкурентные преимущества.
Происходит затратная автоматизация, и уже пара квалифицированных DevOps могут поддерживать процесс в рабочем состоянии. Дальнейшее масштабирование уже не является проблемой.
Не всякая задача должна дойти до последней стадии автоматизации.
Зачастую один умелец с командной строкой решит проблемы легко и эффективно.
Автоматизация «замораживает» процесс, удешевляет эксплуатацию и увеличивает стоимость изменений.
Сразу перейти к автосборкам можно, но система будет неудобной, не будет успевать за требованиями бизнеса и в итоге морально устареет.
Какие бывают сборки и почему задача не решается готовыми сборочными системами

Мы используем следующую классификацию для определения уровней агрегации сборок.
L1. Маленькая самостоятельная часть большого приложения. Это может быть один компонент, микросервис или одна вспомогательная библиотека. L1 сборка — это решение линейных технических задач: компиляция, упаковка, работа с зависимостями. С этим отлично справляются maven, gradle, npm, grunt и другие сборочные системы. Их сотни.
L1 сборку нужно делать при помощи готовых third-party инструментов.
L2+. Интеграционные сущности. L1 сущности объединяются в более крупные образования, например в полноценные микросервисные приложения. Несколько таких приложений могут поставляться в связке как единое решение. Используем знак «+», потому что в зависимости от уровня агрегации сборки может быть присвоен уровень L3 или даже L4.
Пример таких сборок в мире third-party — подготовка Linux-дистрибутивов. Метапакеты там же.
Кроме достаточно сложных технических задач (как, например, эта: ru.wikipedia.org/wiki/Dependency_hell). L2+ сборки часто являются конечным продуктом и поэтому имеют много процессных требований: система прав, закрепление ответственных людей, отсутствие юридических ошибок, снабжение различной документацией.
На уровне L2+ процессные требования приоритетнее автоматизации.
Если автоматическое решение не будет работать так, как это удобно заинтересованным людям, оно не будет внедрено.
L2+ сборки скорее всего будут выполняться проприетарным инструментом, заточенным именно под процессы компании. А вы думаете, пакетные менеджеры в Linux просто так придумывают?
Наши лучшие практики
Инфраструктура
Постоянная доступность железа
Вся сборочная инфраструктура находится на закрытых серверах внутри корпоративной сети. В некоторых случаях возможны коммерческие облачные сервисы.
Автономность
Во всех CI-процессах Интернет недоступен. Все необходимые ресурсы зеркалируются и кэшируются внутри компании. Частично даже github.com (спасибо тебе, npm!) Большинство таких вопросов решает Artifactory.
Поэтому мы спокойны, когда удаляют артефакты с maven central или закрывают популярные репозитории. Есть такой пример: community.oracle.com/community/java/javanet-forge-sunset.
Зеркалирование существенно сокращает время сборок, освобождает корпоративный интернет-канал. Меньшее количество критичных сетевых ресурсов повышает стабильность сборки.
Три репозитория на каждый тип артефакта
- Dev — репозиторий, в который каждый может публиковать артефакты любого происхождения. Тут можно экспериментировать с принципиально новыми подходами, не адаптируя их к корпоративным стандартам с первого дня.
- Staging — репозиторий, наполняемый только сборочным конвейером.
- Release — единичные сборки, готовые к внешней поставке. Наполняется специальной операцией переноса с ручным подтверждением.
Правило 30 дней
Из Dev- и Staging- репозиториев удаляем всё, что старше 30 дней. Это помогает обеспечить всем равные возможности публикации, затратив конечный объём серверных дисков.
Release хранится вечно, при необходимости делается архивация.
Чистое сборочное окружение
Часто после сборок в системе остаются вспомогательные файлы, которые могут повлиять на другие сборочные процессы. Типичные примеры:
- самая частая проблема — это кэш, испорченный одной некорректной сборкой (как быть с кэшами, описано ниже);
- некоторые утилиты, например npm, оставляют в $HOME-директории служебные файлы, которые влияют на все дальнейшие запуски этих утилит;
- конкретная сборка может потратить всё дисковое пространство в каком-нибудь /tmp разделе, что приведёт к общей недоступности окружения.
Поэтому лучше отказаться от единого окружения в пользу docker-контейнеров. В контейнерах должно находиться только необходимое для конкретной сборки ПО с фиксированными версиями.
DevOps поддерживает коллекцию сборочных docker-образов, которая постоянно пополняется. Сначала их было около шести штук, потом стало под 30, потом мы наладили автоматическую генерацию образа по списку ПО. Теперь просто указываем требования типа require('maven 3.3.9', 'python') — и окружение готово.
Самодиагностика
Нужно не просто организовать поддержку пользователей по обращениям, надо самим анализировать поведение собственной системы. Постоянно собираем логи, ищем в них ключевые слова, показывающие проблемы.
На «живой» системе достаточно написать 20-30 регулярных выражений, чтобы по каждой сборке можно было сказать причину её падения на уровне:
- отказ сервера Git;
- там-то закончилось место на диске;
- ошибка сборки по вине разработчика;
- известная бага в Docker.
Если что-то упало, но ни одна известная проблема не обнаружена — это повод для пополнения коллекции масок.
Потом идём к пользователю и говорим, что у него падает сборка и это можно исправить таким-то образом.
Вы удивитесь, о скольких проблемах пользователи не сообщают в поддержку. Лучше чинить их заранее и в удобное время. Часто незначительную ошибку публикации игнорируют две недели, а в пятницу вечером выясняется, что это блокирует внешнюю выдачу.
Внимательно выбираем, от каких систем зависит сборка
В идеале вообще обеспечить полную автономность сборки, но чаще всего это невозможно. Для java-based сборок нужен хотя бы Artifactory для зеркалирования — см. выше про автономность. Каждая интегрированная система повышает риск сбоя. Желательно, чтобы все системы работали в приличном HA-режиме.
Интерфейс сборочного конвейера
Единый интерфейс для вызова сборки
Мы производим любой вид сборок одной системой. Сборки всех уровней (L1, L2+) описаны программным кодом и вызываются через одну Jenkins job.
Однако такой подход не идеален. Лучше использовать механизмы автогенерации Jenkins job: например, 1 job = 1 git repository или 1 job = 1 git branch. Это позволит достичь следующего:
- логи от разнотипных сборок не путаются в одну историю на странице Jenkins job;
- фактически получаются комфортные выделенные job на команду или на разработчика; ощущение уюта можно усилить, настроив графики результатов junit, cobertura, sonar.
Свобода выбора технологии
Запуск сборки — это вызов bash-скрипта «./build.sh». А дальше — любые сборочные системы, языки программирования и всё, что ещё потребуется для выполнения бизнес-задачи. Это обеспечивает подход к сборке как к «чёрному ящику».
Умная публикация
Сборочный конвейер перехватывает публикации из «чёрного ящика» и кладет их уже в корпоративное хранилище. Для этого автоматически решаются скучные вопросы типа генерации имён docker-образов, выбора правильного репозитория для публикации.
В staging- и release-репозиториях всегда порядок. Требуется поддерживать специфику публикаций разных типов: maven, npm, файловых, docker.
Дескриптор сборки
Build.sh описывает, как собирать код, но для сборочного контейнера этого мало.
Необходимо также знать:
- какое сборочное окружение использовать;
- переменные среды, доступные в build.sh;
- какие публикации будут выполнены;
- прочие специфические опции.
Мы выбрали удобный способ описания этой информации в виде yaml-файла, отдалённо напоминающего .gitlab-ci.yaml.
Параметризация сборки
Пользователь может без выполнения команды «git commit» прямо при запуске сборки указать произвольные параметры.
У нас это реализовано через определение переменных окружения непосредственно из интерфейса Jenkins job.
Например, мы выносим в такой параметр сборки версию зависимой библиотеки и в некоторых случаях переопределяем эту версию на некую экспериментальную. Без подобного механизма пользователь должен был бы каждый раз выполнять команду «git commit».
Переносимость системы
Необходимо иметь возможность воспроизводить сборочный процесс не только на главном CI-сервере, но и на компьютере разработчика. Это помогает в отладке сложных сборочных скриптов. Кроме того, вместо Jenkins иногда будет удобнее использовать Gitlab CI. Поэтому сборочная система должна быть независимым java-приложением. Мы реализовали её как gradle plugin.
Один артефакт может публиковаться под разными именами
К публикации есть два противоположных требования, которые могут возникнуть одновременно.
С одной стороны, для долгосрочного хранения и релизного управления нужно обеспечить уникальность имён публикуемых артефактов. Это как минимум защитит артефакты от перезаписи.
С другой стороны, иногда удобно иметь один актуальный артефакт с фиксированным именем вроде latest. Например, разработчику не нужно каждый раз точно знать версию зависимости, можно просто работать с самой свежей.
Артефакт в таком случае публикуется под двумя и более именами, кому как удобно.
Например:
- уникальное имя с меткой времени или UUID — для тех, кому нужна точность;
- имя «latest» — для своих разрабочиков, которые всегда забирают последний код;
- имя «<major version>.х-latest» — для соседней команды, которая готова забирать последние версии, но только в рамках определённой мажорной.
Что-то подобное maven делает в своём подходе к SNAPSHOT.
Меньше ограничений по безопасности
Сборку запустить может каждый. Это не нанесёт никому вреда, так как сборка только создаёт артефакты.
Соблюдение юридических требований
Контроль внешних взаимодействий сборочного процесса
Сборка не может использовать ничего запрещённого в процессе своей работы.
Для этого реализована запись сетевого трафика и доступа к файловым кэшам. Мы получаем лог сетевой активности сборки в виде списка url с sha256 хэшами полученных данных. Дальше каждый url проходит валидацию:
- статический whitelist;
- динамическая база допустимых артефактов (например, для maven-, rpm-, npm- зависимостей). Каждая зависимость рассматриватся индивидуально. Может сработать автоматическое разрешение либо запрет на использование, также может начаться долгая дискуссия с юристами.
Прозрачное содержимое публикуемых артефактов
Иногда поступает задача — предоставить перечень third-party ПО внутри какой-нибудь сборки. Для этого сделали простенький анализатор состава, который анализирует все файлы и архивы в сборке, опознаёт third-party по хэшам и делает отчёт.
Выданный исходный код нельзя удалить из GIT
Иногда может потребоваться найти исходный код, смотря на бинарный артефакт, собранный два года назад. Для этого надо отводить теги в Git автоматически при внешней выдаче, а также запретить их удаление.
Логистика и учёт
Все сборки хранятся в базе данных
Мы используем файловый репозиторий в Artifactory для этих целей. Там лежит вся вспомогательная информация: кто запустил, каковы были результаты проверок, какие артефакты опубликовались, какой git-хэш использован и т. д.
Знаем, как воспроизвести сборку максимально точно
По результатам сборки мы храним следующую информацию:
- точное состояние кода, который собирали;
- с какими параметрами был произведён запуск;
- какие команды вызывались;
- какие обращения к внешним ресурсам происходили;
- использованное сборочное окружение.
При необходимости мы можем достаточно точно ответить на вопрос, как это было собрано.
Двухсторонняя связь сборки с JIRA ticket
Обязательно нужно уметь решать следующие задачи:
- для сборки сформировать список включённых в неё JIRA tickets;
- в JIRA ticket написать, в какие сборки он включён.
Обеспечивается жёсткая двухсторонняя связь сборки с git commit. А дальше из текста комментариев можно уже узнать про все ссылки на JIRA.
Скорость
Кэши для сборочных систем
Отсутствие maven-кэша может увеличить время сборки на час.
Кэш нарушает изоляцию сборочного окружения и чистоту сборки. Эту проблему можно решить, определяя для каждого кэшированного артефакта его происхождение. У нас каждый файл кэша ассоциирован с https-ссылкой, по которой его когда-то скачали. Дальше обрабатываем чтение кэша как сетевое обращение.
Кэши для сетевых ресурсов
Рост компании в географическом плане приводит к необходимости передавать файлы по 300 МБ между континентами. Тратится много времени, особенно если делать это приходится часто.
Git-репозитории, docker-образы сборочных окружений, файловые хранилища — всё надо аккуратно кэшировать. Ну и, конечно, периодически чистить.
Сборка — максимально быстро, всё остальное — потом
Первый этап: делаем сборку и сразу, без лишних телодвижений, отдаём результат.
Второй этап: валидация, анализ, учёт и прочая бюрократия. Это можно сделать уже отдельной Jenkins job и без жёстких ограничений по времени.
Что в итоге
- Главное — сборка стала понятна разработчикам, они сами могут её развивать и оптимизировать.
- Создан фундамент для построения бизнес-процессов, зависящих от сборки: установка, управление выдачами, тестирование, релизное управление и т. д.
- DevOps-команда больше не пишет сборочные скрипты: это делают разработчики.
- Сложные корпоративные требования превратились в прозрачный отчёт с конечным списком проверок.
- Любой человек может собрать любой репозиторий, просто вызвав build.sh через единый интерфейс. Ему достаточно просто указать git-координаты исходного кода. Этим человеком может быть менеджер команды, QA/IT-инженер и т. д.
И немного цифр
- Затраты по времени. Небходимы дополнительные 15 секунд от вызова Jenkins job до непосредственной работы build.sh. За эти 15 секунд стартует сборочный docker-контейнер, включаются сетевые мониторы, подготавливаются кэши. Остальные временные затраты ещё менее заметны. Типовая сборка у нас занимает примерно три минуты.
- Количество сборок. Уверенно подходит в среднем к одной тысяче в день. В некоторые дни доходило до 2200 штук. Большая часть — это on-commit-сборки.
- На данный момент обрабатывается около 300 git-репозиториев, и их число постоянно растёт.
- В день публикуется в среднем 30 ГБ уникальных артефактов, большая часть (25 ГБ) — это docker.
- Ниже список технологий и сборочных инструментов, которыми мы на сегодня пользуемся:
- glide, golang, promu;
- maven, gradle;
- python & pip;
- ruby;
- nodejs & npm;
- docker;
- rpm build tools & gcc;
- сборка Android с помощью ADT;
- коммерческие утилиты;
- утилиты для наших legacy-продуктов;
- самодельные сборочные скрипты.
Комментарии (4)

vektory79
28.08.2018 14:42Ваши требования по безопасности и лицензионной чистоте звучат как показания к JFrog X-Ray. Смотрели в эту сторону? И если смотрели, то что не устроило?
mister_reg Автор
28.08.2018 16:27Для контроля thirdparty зависимостей у нас сейчас используется самописная система. В отличие от JFrog XRay она
- Позволяет анализировать не только лицензии артефактов, но и соблюдение ими экспортных ограничений в страну заказчика. Речь про en.wikipedia.org/wiki/Export_Administration_Regulations
- Поддерживает npm, dep и apk пакеты в дополнение к возможностям JFrog. NPM очень важен
- Интегрирована с корпоративной JIRA
- Решает кое-какие внутренние проблемы с maven зависимостями в наших legacy продуктах (длинная история)
- Появилась на свет раньше
Система эта довольно простая и не требует к себе много внимания.
JFrog XRay для нас сейчас выглядит как перспективный security-сканер, он может искать разные уязвимости и анализировать составы собранных артефактов. Сейчас есть активность по подключению инстанса JFrog XRay к регулярным сборкам, но это ещё начинается и результатов пока нет.
Если бы XRay появился лет 5 назад, то может быть мы его и адаптировали бы под свои нужды. Думаю что это вполне возможно. Сейчас такой потребности просто нет.
ievgen
Глава пособия для ИТ-менеджера?
mister_reg Автор
Если когда-то такое пособие будет и оно не потеряет актуальность к тому времени — это вполне может стать главой про сборочный процесс.