

В данной статье я расскажу о своём опыте "заворачивания" Laravel-приложения в Docker-контейнер да так, что бы и локально с ним могли работать frontend и backend разработчики, и запуск его на production был максимально прост. Так же CI будет автоматически запускать статические анализаторы кода, phpunit-тесты, производить сборку образов.
"А в чём, собственно, сложность?" — можешь сказать ты, и будешь отчасти прав. Дело в том, что этой теме посвящено довольно много обсуждений в русскоязычных и англоязычных комьюнити, и почти все изученные треды я бы условно разделил на следующие категории:
- "Использую докер для локальной разработки. Ставлю laradock и беды не знаю". Круто, но как обстоят дела с автоматизацией и запуском на production?
- "Собираю один контейнер (монолит) на базе
fedora:latest(~230 Mb), ставлю в него все сервисы (nginx, бд, кэш, etc), запускаю всё супервизором внутри". Тоже отлично, прост в запуске, но как на счёт идеологии "один контейнер — один процесс"? Как обстоят дела с балансировкой и управлением процессами? Как же размер образа? - "Вот вам куски конфигов, приправляем выдержками из sh-скриптов, добавим магических env-значений, пользуйтесь". Спасибо, но как же на счёт хотя бы одного живого примера, который я бы мог форкнуть и полноценно поиграться?
Всё, что ты прочитаешь ниже — является субъективным опытом, который не претендует быть истиной в последней инстанции. Если у тебя будут дополнения или указания на неточности — welcome to comments.
Для нетерпеливых — ссылка на репозиторий, склонировав который ты сможешь запустить Laravel-приложение одной командой. Так же не составит труда его запустить на том же rancher, правильно "слинковав" контейнеры, или использовать продуктовый вариант docker-compose.yml как отправную точку.Часть теоретическая
Какие инструменты мы будем использовать в своей работе, и на что сделаем акценты? Первым делом нам понадобятся установленные на хосте:
docker— на момент написания статьи использовал версию18.06.1-cedocker-compose— он отлично справляется с линковкой контейнеров и хранением необходимых environment значений; версия1.22.0make— возможно ты удивишься, но он отлично "вписывается" в контекст работы с докером
Поставитьdockerнаdebian-like системы можно командойcurl -fsSL get.docker.com | sudo sh, а вотdocker-composeлучше ставь с помощьюpip, так как в его репозиториях обитают наиболее свежие версии (aptсильно отстают, как правило).
На этом список зависимостей можно завершить. Что ты будешь использовать для работы с исходниками — phpstorm, netbeans или трушный vim — только тебе решать.
Дальше — импровизированный QA в контексте (не побоюсь этого слова) проектирования образов:
Q: Базовый образ — какой лучше выбрать?
A: Тот, что "потоньше", без излишеств. На базе
alpine(~5 Mb) можно собрать всё, что душе угодно, но скорее всего придётся поиграться со сборкой сервисов из исходников. Как альтернатива —jessie-slim(~30 Mb). Или же использовать тот, что наиболее часто используется у вас на проектах.
Q: Почему вес образа — это важно?
A: Снижение объёма трафика, снижение вероятности ошибки при скачивании (меньше данных — меньше вероятность), снижение потребляемого места. Правило "Тяжесть — это надёжно" (© "Snatch") тут не очень работает.
Q: А вот мой друг
%friend_name%говорит, что "монолитный" образ со всеми-всеми зависимостями — это самый лучший путь.
A: Давай просто посчитаем. Приложение имеет 3 зависимости — PG, Redis, PHP. И тебе захотелось протестировать как оно у тебя будет себя вести в связках различных версий этих зависимостей. PG — версии 9.6 и 10, Redis — 3.2 и 4.0, PHP — 7.0 и 7.2. В случае, если каждая зависимость это отдельный образ — тебе их потребуется 6 штук, которые даже собирать не надо — всё уже готово и лежит на
hub.docker.com. Если же по идеологическим соображениям все зависимости "упакованы" в один контейнер, тебе придётся его ручками пересобрать… 8 раз? А теперь добавь условие, что ты ещё хочешь и сopcacheпоиграться. В случае декомпозиции — это просто изменение тегов используемых образов. Монолит проще запускать и обслуживать, но это путь в никуда.
Q: Почему супервизор в контейнере — это зло?
A: Потому что
PID 1. Не хочешь обилия проблем с зомби-процессами и иметь возможность гибко "добавлять мощностей" там, где это необходимо — старайся запускать один процесс на контейнер. Своеобразными исключениями являетсяnginxсо своими воркерами иphp-fpm, которые имеют свойство плодить процессы, но с этим приходится мириться (более того — они не плохо умеют реагировать наSIGTERM, вполне корректно "убивая" своих воркеров). Запустив же всех демонов супервизором — фактически наверняка ты обрекаешь себя на проблемы. Хотя, в некоторых случаях — без него сложно обойтись, но это уже исключения.
Определившись с основными подходами давай перейдём к нашему приложению. Оно должно уметь:
web|api— отдавать статику силамиnginx, а динамический контент генерировать силамиfpmscheduler— запускать родной планировщик задачqueue— обрабатывать задания из очередей
Базовый набор, который при необходимости можно будет расширить. Теперь перейдём к образам, которые нам предстоит собрать для того, что бы наше приложение "взлетело" (в скобках приведены их кодовые имена):
PHP + PHP-FPM(app) — среда, в которой будет выполняться наш код. Так как версии PHP и FPM у нас будут совпадать — собираем их в одном образе. Так и с конфигами легче управляться, и состав пакетов будет идентичный. Разумеется — FPM и процессы приложения будут запускаться в разных контейнерахnginx(nginx) — что бы не заморачиваться с доставкой конфигов и опциональных модулей дляnginx— будем собирать отдельный образ с ним. Так как он является отдельным сервисом — у него свой докер-файл и свой контекст- Исходники приложения (sources) — доставка исходников будет производиться используя отдельный образ, монтируя
volumeс ними в контейнер с app. Базовый образ —alpine, внутри — только исходники с установленными зависимостями и собранными с помощью webpack asset-ами (артефакты сборки)
Остальные сервисы для разработки запускаются в контейнерах, стянув их с hub.docker.com; на production же — они запущены на отдельных серверах, объединенных в кластеры. Всё что нам останется — это сказать приложению (через environment) по каким адресам\портам и с какими реквизитами необходимо до них стучаться. Ещё круче — это использовать в этих целях service-discovery, но об этом не в этот раз.
Определившись с частью теоретической — предлагаю перейти к следующей части.
Часть практическая
Организовать файлы в репозитории предлагаю следующим образом:
.
+-- docker # Директория для хранения докер-файлов необходимых сервисов
¦ +-- app
¦ ¦ +-- Dockerfile
¦ ¦ L-- ...
¦ +-- nginx
¦ ¦ +-- Dockerfile
¦ ¦ L-- ...
¦ L-- sources
¦ +-- Dockerfile
¦ L-- ...
+-- src # Исходники приложения
¦ +-- app
¦ +-- bootstrap
¦ +-- config
¦ +-- artisan
¦ L-- ...
+-- docker-compose.yml # Compose-конфиг для локальной разработки
+-- Makefile
+-- CHANGELOG.md
L-- README.mdОзнакомиться со структурой и файлами ты можешь перейдя по этой ссылке.
Для сборки того или иного сервиса можно воспользоваться командой:
$ docker build --tag %local_image_name% -f ./docker/%service_directory%/Dockerfile ./docker/%service_directory%Единственным отличием будет сборка образа с исходниками — для него необходимо контекст сборки (крайний аргумент) указать равным ./src.
Правила именования образов в локальном registry рекомендую использовать те, что использует docker-compose по умолчанию, а именно: %root_directory_name%_%service_name%. Если директория с проектом называется my-awesome-project, а сервис носит имя redis, то имя образа (локального) лучше выбрать my-awesome-project_redis соответственно.
Для ускорения процесса сборки можно сказать докеру использовать кэш ранее собранного образа, и для этого используется параметр запуска--cache-from %full_registry_name%. Таким образом демон докера перед запуском той или иной инструкции в Dockerfile посмотрит — изменились ли она? И если нет (хэш сойдётся) — он пропустит инструкцию, используя уже готовый слой из образа, который ты укажешь ему использовать в качестве кэша. Эта штука не плохо так бустит процесс пересборки, особенно, если ничего не изменилось :)
Обрати внимание наENTRYPOINTскрипты запуска контейнеров приложения.
Образ среды для запуска приложения (app) собирался с учётом того, что он будет работать не только на production, но ещё и локально разработчикам необходимо с ним эффективно взаимодействовать. Установка и удаление composer-зависимостей, запуск unit-тестов, tail логов и использование привычных алиасов (php /app/artisan > art, composer > c) должно быть без какого либо дискомфорта. Более того — он же будет использоваться для запуска unit-тестов и статических анализаторов кода (phpstan в нашем случае) на CI. Именно поэтому его Dockerfile, к примеру, содержит строчку установки xdebug, но сам модуль не включен (он включается только с использованием CI).
Так же дляcomposerглобально ставится пакетhirak/prestissimo, который сильно бустит процесс установки всех зависимостей.
На production мы монтируем внутрь него в директорию /app содержимое директории /src из образа с исходниками (sources). Для разработки — "прокидываем" локальную директорию с исходниками приложения (-v "$(pwd)/src:/app:rw").
И вот тут кроется одна сложность — это права доступа на файлы, которые создаются из контейнера. Дело в том что по умолчанию процессы, запущенные внутри контейнера — запускаются от рута (root:root), создаваемые этими процессами файлы (кэш, логи, сессии, etc) — тоже, и как следствие — "локально" с ними ты уже ничего не сможешь сделать, не выполнив sudo chown -R $(id -u):$(id -g) /path/to/sources.
Как один из вариантов решения — это использование fixuid, но это решение прям "так себе". Лучшим путём мне показался проброс локальных USER_ID и его GROUP_ID внутрь контейнера, и запуск процессов с этими значениями. По умолчанию подставляя значения 1000:1000 (значения по умолчанию для первого локального пользователя) избавился от вызова $(id -u):$(id -g), а при необходимости — ты всегда их можешь переопределить ($ USER_ID=666 docker-compose up -d) или сунуть в .env файл docker-compose.
Так же при локальном запуске php-fpm не забудь отключить у него opcache — иначе куча "да что за чертовщина!" тебе будут обеспечены.
Для "прямого" подключения к redis и postgres — прокинул дополнительные порты "наружу" (16379 и 15432 соответственно), так что проблем с тем, чтоб "подключиться да посмотреть что да как там на самом деле" не возникает в принципе.
Контейнер с кодовым именем app держу запущенным (--command keep-alive.sh) с целью удобного доступа к приложению.
Вот несколько примеров решения "бытовых" задач с помощью docker-compose:
| Операция | Выполняемая команда |
|---|---|
Установка composer-пакета |
$ docker-compose exec app composer require package/name |
| Запуск phpunit | $ docker-compose exec app php ./vendor/bin/phpunit --no-coverage |
| Установка всех node-зависимостей | $ docker-compose run --rm node npm install |
| Установка node-пакета | $ docker-compose run --rm node npm i package_name |
| Запуск "живой" пересборки asset-ов | $ docker-compose run --rm node npm run watch |
Все детали запуска ты сможешь найти в файле docker-compose.yml.
Цой make жив!
Набивать одни и те же команды каждый раз становится скучно после второго раза, и так как программисты по своей натуре — существа ленивые, давай займёмся их "автоматизацией". Держать набор sh-скриптов — вариант, но не такой привлекательный, как один Makefile, тем более что его применимость в современной разработке сильно недооценена.
Полный русскоязычный мануал по нему ты сможешь найти по этой ссылке.
Давай посмотрим как выглядит запуск make в корне репозитория:
[user@host ~/projects/app] $ make
help Show this help
app-pull Application - pull latest Docker image (from remote registry)
app Application - build Docker image locally
app-push Application - tag and push Docker image into remote registry
sources-pull Sources - pull latest Docker image (from remote registry)
sources Sources - build Docker image locally
sources-push Sources - tag and push Docker image into remote registry
nginx-pull Nginx - pull latest Docker image (from remote registry)
nginx Nginx - build Docker image locally
nginx-push Nginx - tag and push Docker image into remote registry
pull Pull all Docker images (from remote registry)
build Build all Docker images
push Tag and push all Docker images into remote registry
login Log in to a remote Docker registry
clean Remove images from local registry
--------------- ---------------
up Start all containers (in background) for development
down Stop all started for development containers
restart Restart all started for development containers
shell Start shell into application container
install Install application dependencies into application container
watch Start watching assets for changes (node)
init Make full application initialization (install, seed, build assets)
test Execute application tests
Allowed for overriding next properties:
PULL_TAG - Tag for pulling images before building own
('latest' by default)
PUBLISH_TAGS - Tags list for building and pushing into remote registry
(delimiter - single space, 'latest' by default)
Usage example:
make PULL_TAG='v1.2.3' PUBLISH_TAGS='latest v1.2.3 test-tag' app-pushОн очень хорош зависимостью целей. Например, для запуска watch (docker-compose run --rm node npm run watch) необходимо что бы приложение было "поднято" — тебе достаточно указать цель up как зависимую — и можешь не беспокоиться о том, что ты забудешь это сделать перед вызовом watch — make сам всё сделает за тебя. То же касается запуска тестов и статических анализаторов, например, перед коммитом изменений — выполни make test и вся магия произойдет за тебя!
Стоит ли говорить о том, что для сборки образов, их скачивания, указания --cache-from и всего-всего — уже не стоит беспокоиться?
Ознакомиться с содержанием Makefile ты можешь по этой ссылке.
Часть автоматическая
Приступим к финальной части данной статьи — это автоматизация процесса обновления образов в Docker Registry. Хоть в моём примере и используется GitLab CI — перенести идею на другой сервис интеграции, думаю, будет вполне возможно.
Первым делом определимся и именованием используемых тегов образов:
| Имя тега | Предназначение |
|---|---|
latest |
Образы, собранные с ветки master. Состояние кода является самым "свежим", но ещё не готовым к тому, что бы попасть в релиз |
some-branch-name |
Образы, собранные на бранче some-branch-name. Таким образом мы можем на любом окружении "раскатать" изменения которые были реализованы только в рамках конкретного бранча ещё до их сливания с master-веткой — достаточно "вытянуть" образы с этим тегом. И — да, изменения могут касаться как кода, так и образов всех сервисов в целом! |
vX.X.X |
Собственно, релиз приложения (использовать для разворачивания конкретной версии) |
stable |
Алиас, для тега со самым свежим релизом (использовать для разворачивания самой свежей стабильной версии) |
Релиз происходит с помощью публикации тега в гите формата vX.X.X.
Для ускорения сборки используется кэширование директорий ./src/vendor и ./src/node_modules + --cache-from для docker build, и состоит из следующих этапов (stages):
| Имя этапа | Предназначение |
|---|---|
prepare |
Подготовительный этап — сборка образов всех сервисов кроме образа с исходниками |
test |
Тестирование приложения (запуск phpunit, статических анализаторов кода) используя образы, собранные на этапе prepare |
build |
Установка всех composer зависимостей (--no-dev), сборка assets силами webpack, и сборка образа с исходниками включая полученные артефакты (vendor/*, app.js, app.css) |
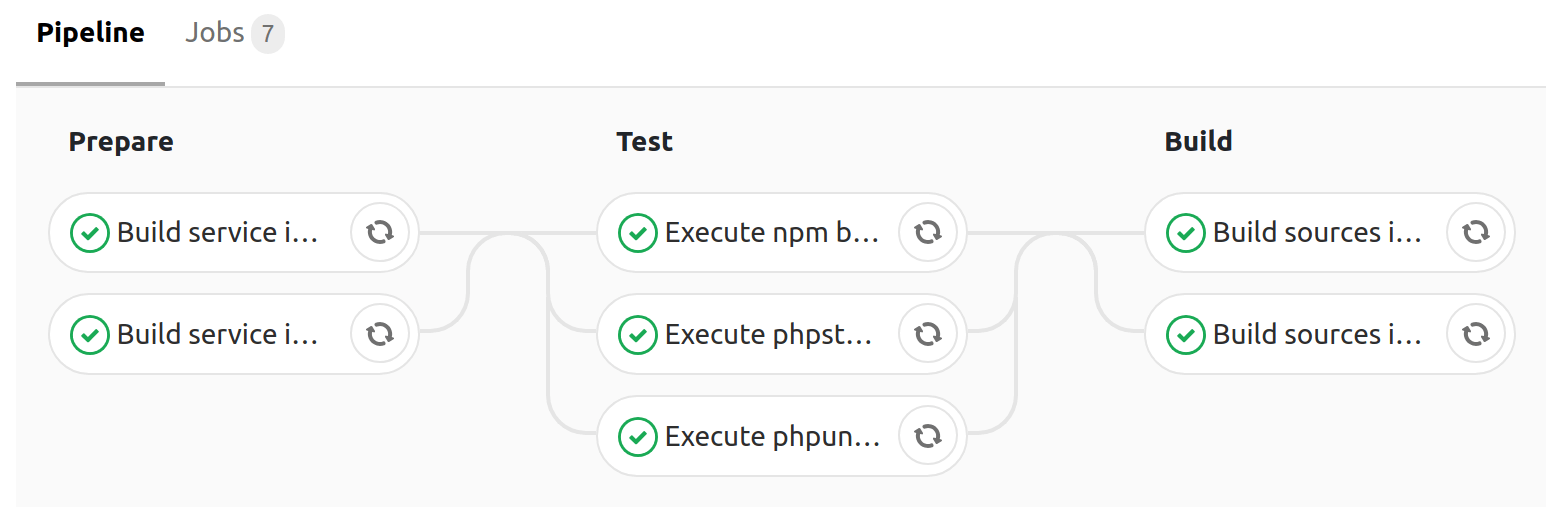
Сборка наmaster-ветке, производящаяpushс тегамиlatestиmaster
В среднем, все этапы сборки занимают 4 минуты, что довольно хороший результат (параллельное выполнение задач — наше всё).
Ознакомиться с содержанием конфигурации (.gitlab-ci.yml) сборщика можешь ознакомиться по этой ссылке.
Вместо заключения
Как видишь — организовать работу с php-приложением (на примере Laravel) используя Docker не так то и сложно. В качестве теста можешь форкнуть репозиторий, и заменив все вхождения tarampampam/laravel-in-docker на свои — попробовать всё "в живую" самостоятельно.
Для локального запуска — выполни всего 2 команды:
$ git clone https://gitlab.com/tarampampam/laravel-in-docker.git ./laravel-in-docker && cd $_
$ make initПосле чего открой http://127.0.0.1:9999 в своём любимом браузере.
… Пользуясь случаем
В данный момент я работаю TL на проекте "автокод", и мы ищем талантливых php-разработчиков и системных администраторов (офис разработки находится в г. Екатеринбург). Если ты относишь себя к первым или вторым — напиши нашему HR письмо с текстом "Хочу в команду разработки, резюме: %ссылка_на_резюме%" на электопочту hr@avtocod.ru, помогаем с релокацией.
Комментарии (23)

Fantyk
02.10.2018 15:03Огромное спасибо за статью, очень актуально!
Возникло несколько вопросов:
— Почему не разделены образы для dev/prod (xdebug и composer не нужны)?
— Меня отчасти смущает то, что в gitlab-ci.yml дублируется сцераний создания образа (тот же composer install). Ведь, в принципе, у нас уже есть Dockerfile, который собирает образ и для него можно запустить тесты.
— Можете подробнее рассказать о запуске очередей, что в принципе для этого нужно, как вы решали проблемы (вижу скрипты в docker/app, это с ними связано)?cmepthuk Автор
02.10.2018 16:04Почему не разделены образы для dev/prod (xdebug и composer не нужны)?
С целью и упрощения. Если возникнет необходимость на
stagingокружении сделатьcomposer-dump— у тебя всё под руками. Да и тестироватьprodобраз отдельно — очень не хочется. А модульxdebug— не загружается, просто образ чуть толще, это да
дублируется сцераний создания образа
В
.gitlab-ci.ymlпришлось немного дублировать по причине отсутствия на столько гибких условий запуска job-ов. Был второй вариант — проверять что в$CI_COMMIT_REF_NAMEв секцииscript, но он оказался ещё хуже (если я правильно понял ваш вопрос, но не уверен)
Можете подробнее рассказать о запуске очередей
Слушателей очереди — это процесс
artisan queue:work, которые на rancher запускаются в количестве 20..30 экземпляров. Подробнее о том, как работают очереди в Laravel хорошо написано в документацииgecube
02.10.2018 16:56Есть мнение, что артефакт не имеет права меняться между stage. Т.е. если мы собрали тестовый артефакт в ветке, то после прохождения тестов он должен уйти в прод. Таким образом мы можем ТОЛЬКО навешивать на один и тот же единожды собранный docker-образ разные теги. Это существенно сложнее, чем пересобирать образ каждый раз, НО! Докер не ГАРАНТИРУЕТ, что если мы делаем apk add <имя пакета> (даже с указанием конкретной версии) или npm install (конкретный пакет и его конкретная версия), что в образы попадут бинарно идентичные версии этих пакетов. Это потенциальная очень глубокая дыра. Решать в каждом случае индивидуально — стоит ли на это заморачиваться или «и так сойдет»
ErickSkrauch
02.10.2018 18:03Здравстуйте. Спасибо за статью.
Скажите, не возникает ли в данной конфигурации проблем с деплоем новой версии? Если я правильно понимаю, то т.к. используются volume для обобщения кода между php-fpm и nginx контейнерами, после первого деплоя (т.е. когда volume был пустым) код уже не переписывается из контейнера в него, а наоборот: на новый контейнер накатывается старый код из volume. Я пока так и не смог решить эту проблему, оставив всё на docker-compose 2 и volumes_from и при деплое приходится пересоздавать как php-fpm контейнер, так и nginx. Но сейчас всё же нарастает необходимость в использовании swarm, а посему вариант заворачивать frontend и всю статику в nginx контейнер кажется всё более и более логичным.
cmepthuk Автор
02.10.2018 20:11Не возникает, так как деплой происходит с даунтаймом (минимальным, но всё же). Т.е. "вытягиваются" свежие образы полным набором, после этого текущий стек гасится, и тут же поднимается со "свежим" тегом. Есть ещё не лучшее решение с миграциями (надо запускать контейнеры в определенном порядке), но так как оно "не лучшее" — в статье его не описывал.
brunen9
03.10.2018 11:23Я вот как раз надеялся, что увижу в статье, как управляетесь с миграциями. Код с зависимостями отправили на сервер, ок. А если разработчик добавил новую миграцию?
cmepthuk Автор
03.10.2018 12:17Говорю же — пока то что есть, не очень нравится. Как "созреет" то решение, которым можно поделиться — прям сюда и плюхну ссылочку на него

genteelknight
03.10.2018 19:54+1Решение уже есть — это Kubernetes. Большинство проблем уже решено. Например, проблема с даунтаймом решается так, что в процессе обновления старый деплоймент продолжает работать и отвечать на запросы и не будет остановлен, пока не заработает обновленный. Миграции же следует запускать при запуске контейнера.
Так же Docker — не просто средство запуска веб-сервера, а средство упаковки проекта со всеми зависимостями для простоты дальнейшего запуска. Монтирование папки с исходным кодом отлично подходит для разработки. Но в продакшн следует собирать полноценный Docker образ, в который на этапе сборки устанавливаются все зависимости (composer и пр.) и копируются исходные файлы проекта.
cmepthuk Автор
03.10.2018 22:56Чем на ваш взгляд не так хорош подход монтирования директории с исходниками хоть через хост, хоть через
docker volume? Исходники, среда и сервисы — это три разные сущности. И не смотря на то, что первые две можно перемешать — стоит ли?gecube
03.10.2018 23:00Потому что исходник является компонентом версионирования кода. Просто пример. Положим, что мы изменили базовые зависимости в основном образе, а исходник подкинули от предыдущей версии, которая хочет ДРУГУЮ версию зависимости. Получается, что они должны обновляться связанным образом.
Это более характерно для python с его requirements.txt, чем для nodejs. Но тем не менее — все сломается.
Исходники, среда и сервисы — это три разные сущности.
Докер за тем и нужен, чтобы среда и сервисы были отделены. Исходник — всего лишь сырье для сборки сервиса.
Повторюсь, что для машины разработчика — да, подключение исходников через volume удобно. Но как только код ушел в репозиторий — я настаиваю на своей точке зрения.gecube
03.10.2018 23:09и, да, с миграциями вообще отдельная история, т.к. на организационном уровне нужно запретить миграции, которые что-то ломают. И писать код, который может одновременно работать с несколькими схемами БД.
cmepthuk Автор
03.10.2018 23:41писать код, который может одновременно работать с несколькими схемами БД
Давайте возьмем в качестве примера миграцию, которая изменяет тип некоторого поля в таблице.
С использованием добротной абстракции над данными реализовать проверку на актуальное состояние типа поля, конечно, можно довольно "элегантно" и в едином месте, но так как "php создан, чтобы умирать" — нужно или каждый раз перед обновлением данных выполнять дополнительный запрос на проверку "поле, какого ты сейчас типа?", или кэшировать крайнее состояние, инвалидируя кэш при релизе. Довольно таки громозко, как мне кажется, да и мертвый код… Не лучше ли придерживаться идеи, что версия кода просто должна соответствовать версии схемы?
gecube
04.10.2018 00:00Я имел в виду, что мы вводим мораторий на изменения типа полей. По крайней мере, которые могут привести к проблем. Столбец добавить — ок, можно. Новый код его знает, сможет с ним работать. Работоспособность же старого кода — неизменится. Удалить столбец? Нет, нельзя. Это можно будет сделать через несколько релизов, когда мы стабилизируем кодовую базу и когда это можно будет безопасно сделать и т.п.
cmepthuk Автор
03.10.2018 23:23Само собою, они и обновляются связанно — при свежем релизе мы получаем все три (в нашем примере) свежих образа с одним тегом, например —
v1.2.3(алиас которого —stable). Перед раскаткой делаетсяpullобразов (если не прошел — релиза не будет; скачаются лишь обновленные слои, так как те что не изменились с предыдущего релиза — сойдутся по хэшам).
После этого стек гасится (пользователи видят страницу-заглушку, что отдаёт хостовойnginx), и поднимается новый стек. При поднятии нового стека выполняется конкурентная операция — накатка миграций (при их присутствии), прочие "сервисные штуки", и лишь после поднимаются остальные контейнеры —nginx,fpmи так далее. Если миграция по какой-либо причине не прошла — поднимается старый стек, с отправкой нотификаций матерного содержания инициатору релиза.
Ни в коем случае не считаю вашу точку зрения не верной, не подумайте. Лишь интересны примеры из практической эксплуатации, когда доставка кода отдельным контейнером доставляла проблемы
Arik
02.10.2018 20:411. что посоветуете, если проектов много и все нужно в запущенном состоянии держать на слабеньком тестовом VPS? Задача есть, но совсем еще не брался. Пока вижу проблемы с оперативкой и занятые порты.
2. php-cli (artisan) запускается под той же версии php что php-fpm?
3. если только для production нужно свои настройки nginx, то выходит нужно какой балансировщик свой впереди ставить, чтоб dev не отвалился? Допустим https c переадресация http->https.
Если на проект зайти под другим HTTP_HOST, то он запустит приложение?cmepthuk Автор
02.10.2018 21:08- Смотря какие проекты, какую роль выполняют (к каким ресурсам требовательны), и что вы хотите получить в итоге. Иногда лучше ничего не менять (изменения будут не оправдано дорогими по человеко-ресурсам). Оверхед по памяти — да, есть, но совсем не большой если смотреть в целом. Порты — если в пределах одного хоста запускается не тысячи контейнеров — не думаю что есть смысл об этом беспокоиться.
- Да, так проще в управлении и внесении изменений.
- Тут не совсем понял. Если есть возможность, можете более подробно описать свой вопрос?
Arik
03.10.2018 13:101. Простые сайты визитки (php, mysql). Можно сказать что нужно тестовый хостинг для них, но все контейнерах. Думал может какие-то общие сделать контейнеры с указанием хостов и папок. По сути выходит контейнеры для виртуальных хостов.
2. Выходит php-сli запускается из контейнера php-fpm? composer тоже? были проблемы что некоторые скрипты смотрят на /usr/bin/env
3. Наверно рано спросил, пока не юзаю автоматические интеграции, просто думал что на продакшн nginx поднимается с 80 портом, если я начну править конфиги контейнера для продакшн, то это скажется и для devcmepthuk Автор
03.10.2018 23:12Если опять-таки правильно понял, то решение напрашивается само собой:
- Для разработки каждого проекта используется свой compose-файл, который поднимает всё своё окружение (так каждый проект в своём роде атомарен, не имеет зависимостей от хоста)
- На продуктовом (или
staging— не важно) сервере — поднимается лишь контейнер со средой (app), исходниками (sources), и фронтом (nginx), в БД все дружно ходят в одну, локальную, или стоящую рядом - Так же на сервере ставится
nginx(с ssl и прочими), который "разводит" запросы, приходящие на домены, делаяproxy_passна внешний портnginxконтейнера нужного приложения - Через env каждому приложению сообщается, на каком базовом uri оно запущено, что бы оно генерировало корректные абсолютные ссылки
staging(илиdev) окружение — это полная реплика продуктового, но только у него роль — быть пре-продактом, "на живую" обкатывать перед релизом.
При разворачивании нового приложения — необходимо лишь в DNS резольвить адрес сервера, где стоит "фронтовой"
nginx, написать для него конфиг сproxy_pass, и поднять стек приложения. Из очевидных плюсов — изоляция, индивидуальные настройки под каждый проект, простота в эксплуатации, и безграничные возможности для автоматизации :) Как ещё один вариант — это пускать контейнеры в облаках. На то они и контейнерыgecube
03.10.2018 23:16Уточните, пожалуйста — compose или docker-compose?
Мне не очень нравится путаница, связанная с существованием нескольким совершенно разных продуктов, но с очень сходными именами (да хоть вспомнить sphinx, который может быть поисковым движком и чем-то совершенно другим )))
gecube
Последние рекомендации: ставить docker-compose через curl с оф.сайта. Устанавливается небольшой единый бинарник, которому python, уф, не нужен.
Ещё игрался с вариантом запуска docker-compose через docker-контейнер. Это прекрасно вписывается в CI-среды, но я был сильно опечален тем, что с какой-то версии у них сильно потяжелели образы и есть сложности с прокидыванием переменных среды (если используется интерполяция в docker-compose.yml)