
Раньше на Авито можно было найти нужный товар, используя фильтрацию по ключевым словам или навигацию по дереву категорий. Этот способ, хоть и казался привычным, был не всегда удобен — чтобы найти товар или услугу, нужно было сделать большое количество кликов. Более года назад у нас появилась релевантность, благодаря которой поиск стал лучше, и найти товар или услугу теперь проще и удобнее даже на главной странице. С этим нововведением в выдачу перестали попадать неподходящие, откровенно «мусорные» товары. И это только один из шагов, чтобы сделать поиск лучше. Мы постепенно изменяем инфраструктуру, что позволяет нам работать над качеством поиска более интенсивно, быстрее улучшать его и выкатывать новые фичи, приносящие пользу продавцам и покупателям на Авито.
В статье я расскажу, как менялся поиск на Авито: с чего начинали и как мы сейчас движемся по пути к улучшению жизни наших пользователей, поделюсь нашими нововведениями как в продукте, так и в его начинке — технической части. Совсем хардкорного мяса здесь не будет, но, надеюсь, вам понравится.

Немного вводных: Авито — самый популярный сервис объявлений в России. У нас каждый день размещается более 450 тысяч объявлений, а ежемесячное количество уникальных посетителей достигает 35 миллионов, которые каждый день совершают более 140 миллионов поисковых запросов.
Типичный сценарий поиска раньше
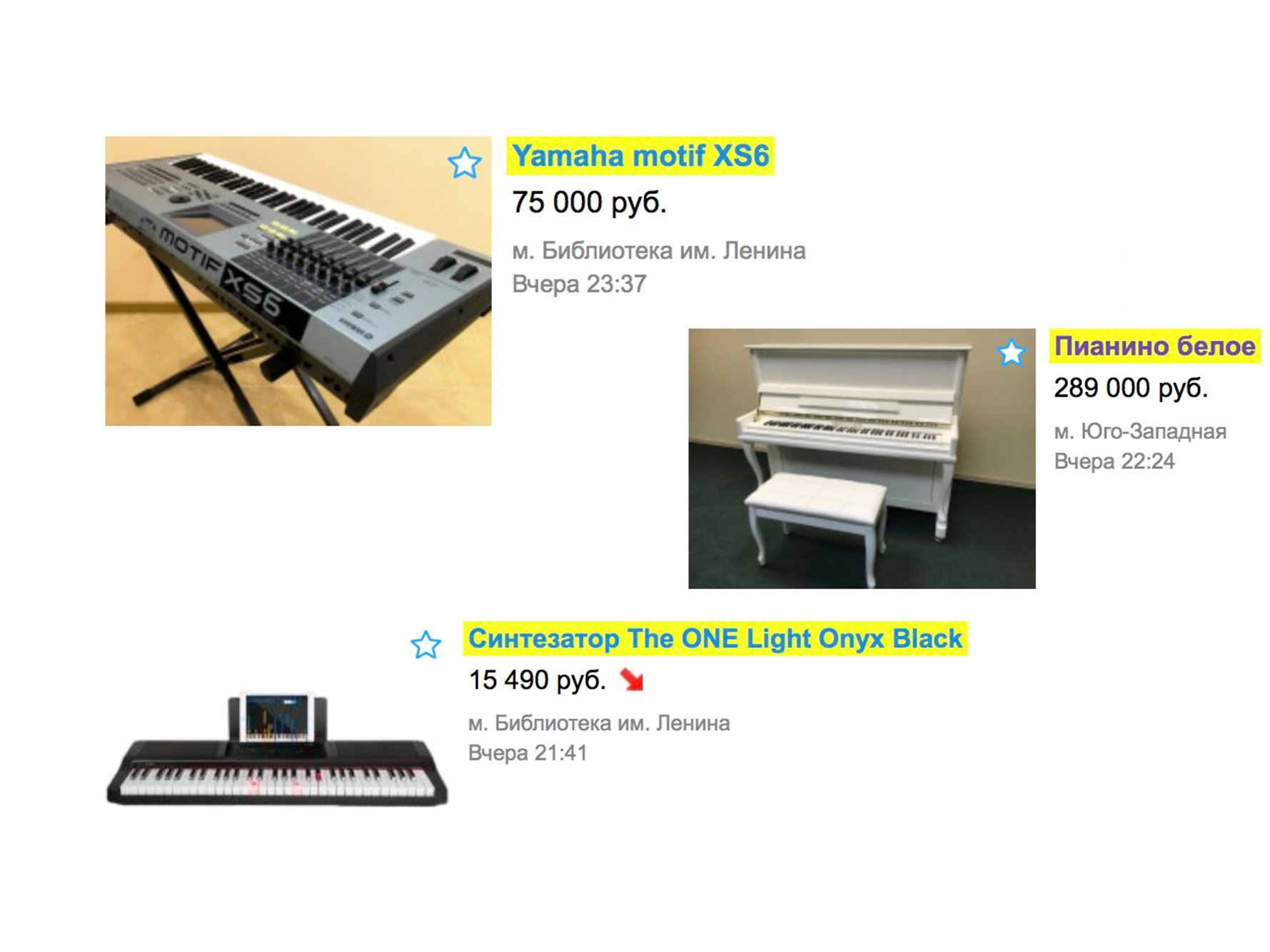
Рассмотрим простой пример, как работал поиск более года назад. Предположим, что вам нужно пианино (ну, а почему нет?). Заходим на главную страницу, набираем «пианино».
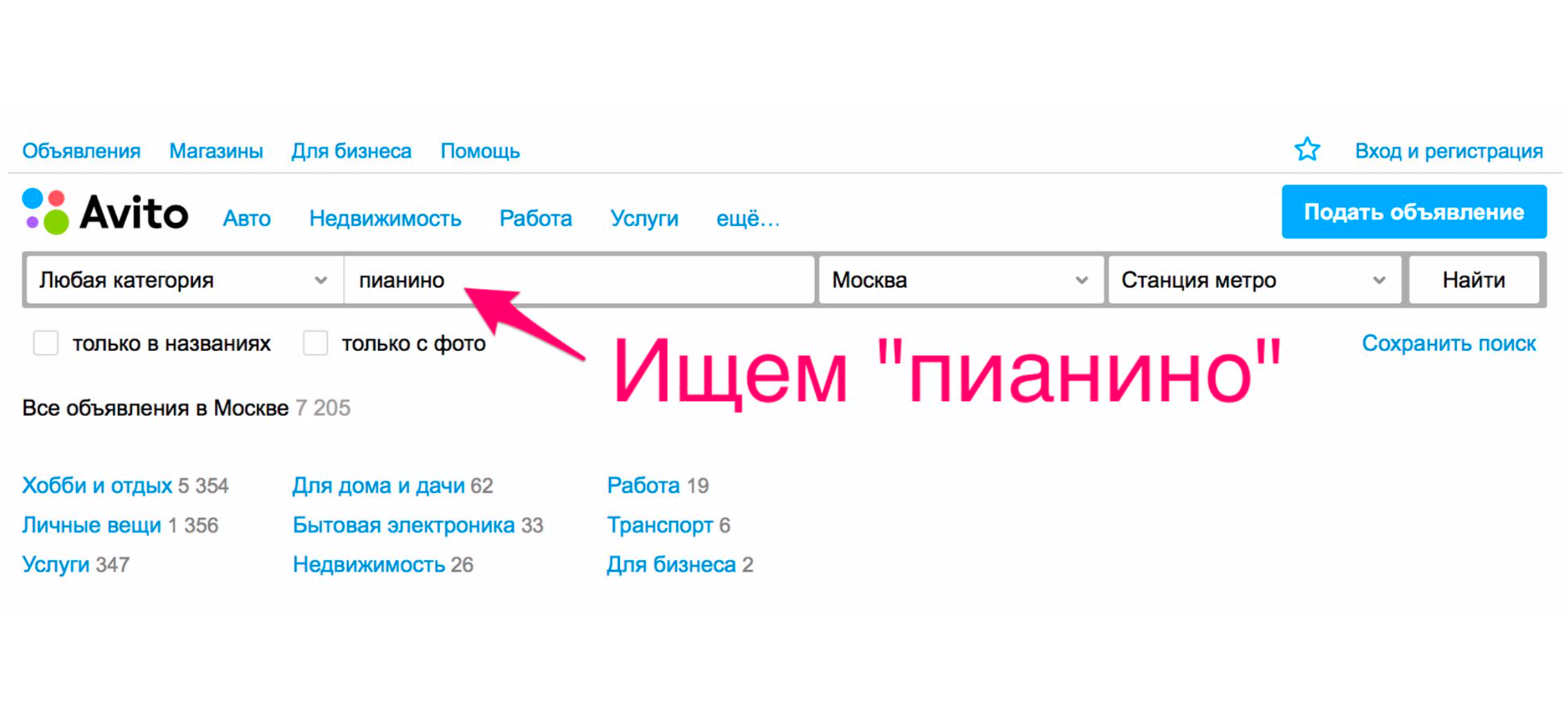
В выдаче вы, скорее всего, получите грузчиков, услуги по перевозке пианино или что-то похожее, но не музыкальный инструмент.

Это происходит, потому что у нас будет сортировка по дате размещения — а эти услуги размещают чаще всего.
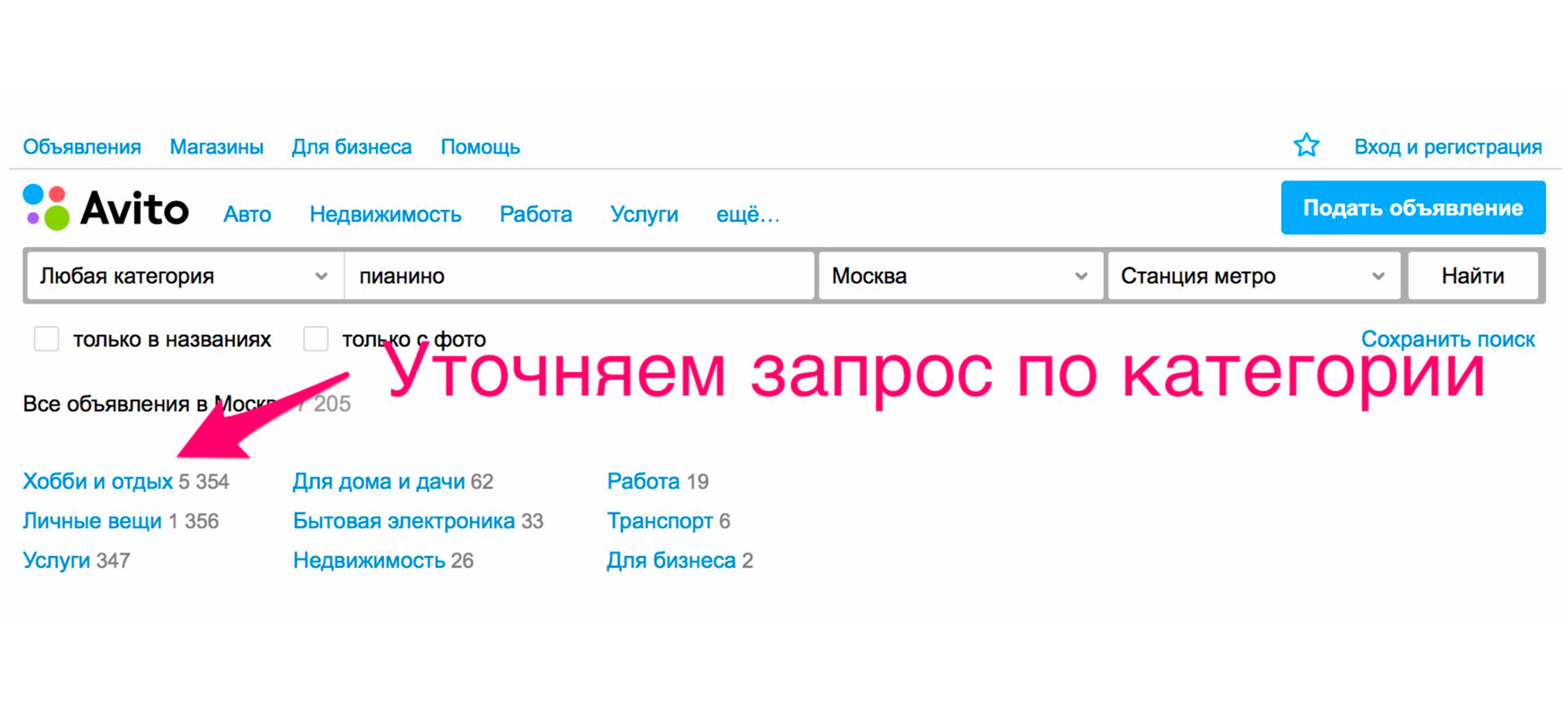
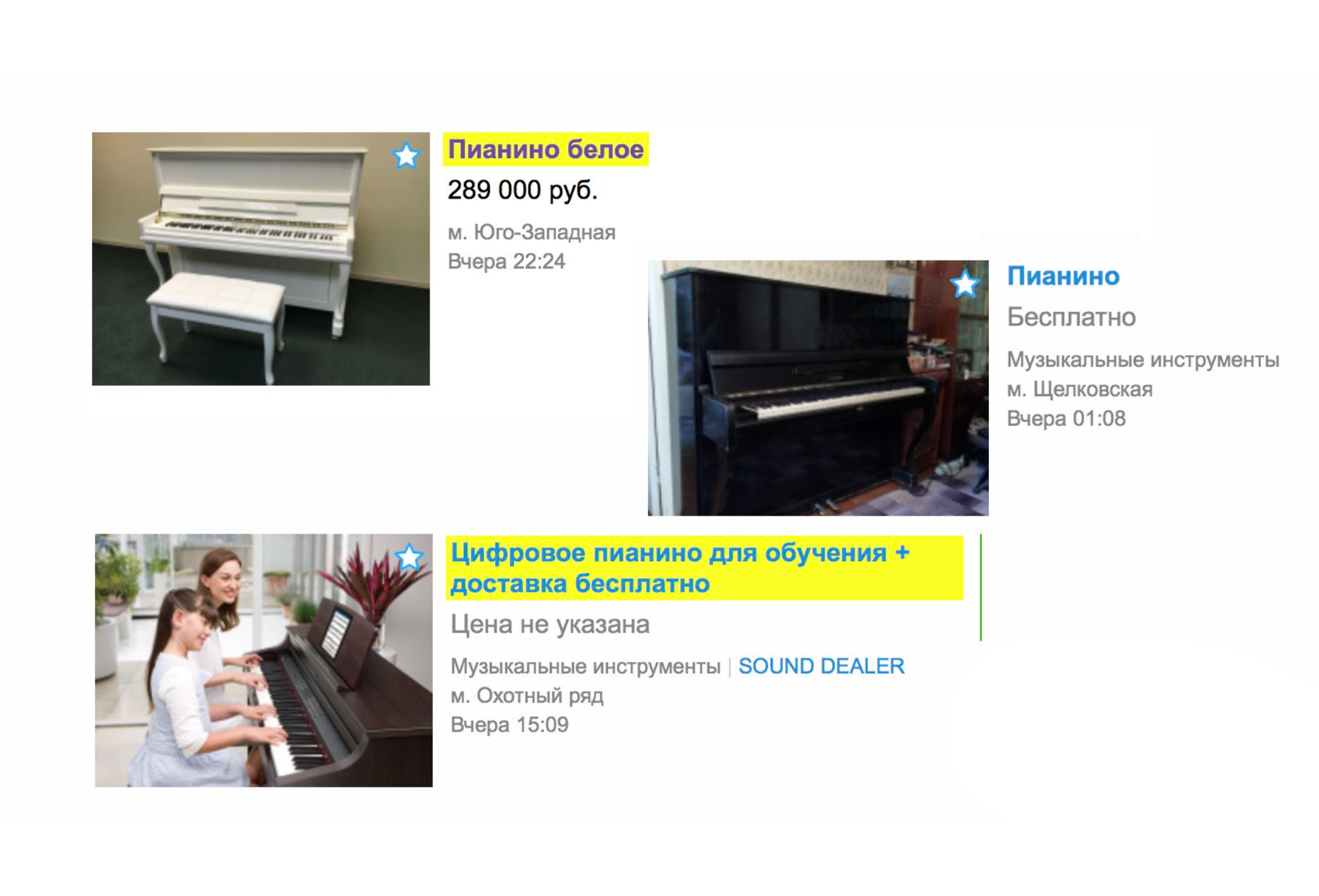
Чтобы увидеть пианино, надо уточнить категорию. Кликаем на рубрикатор «Хобби и отдых», спускаемся по дереву категорий в «Музыкальные инструменты», затем «Клавишные инструменты».
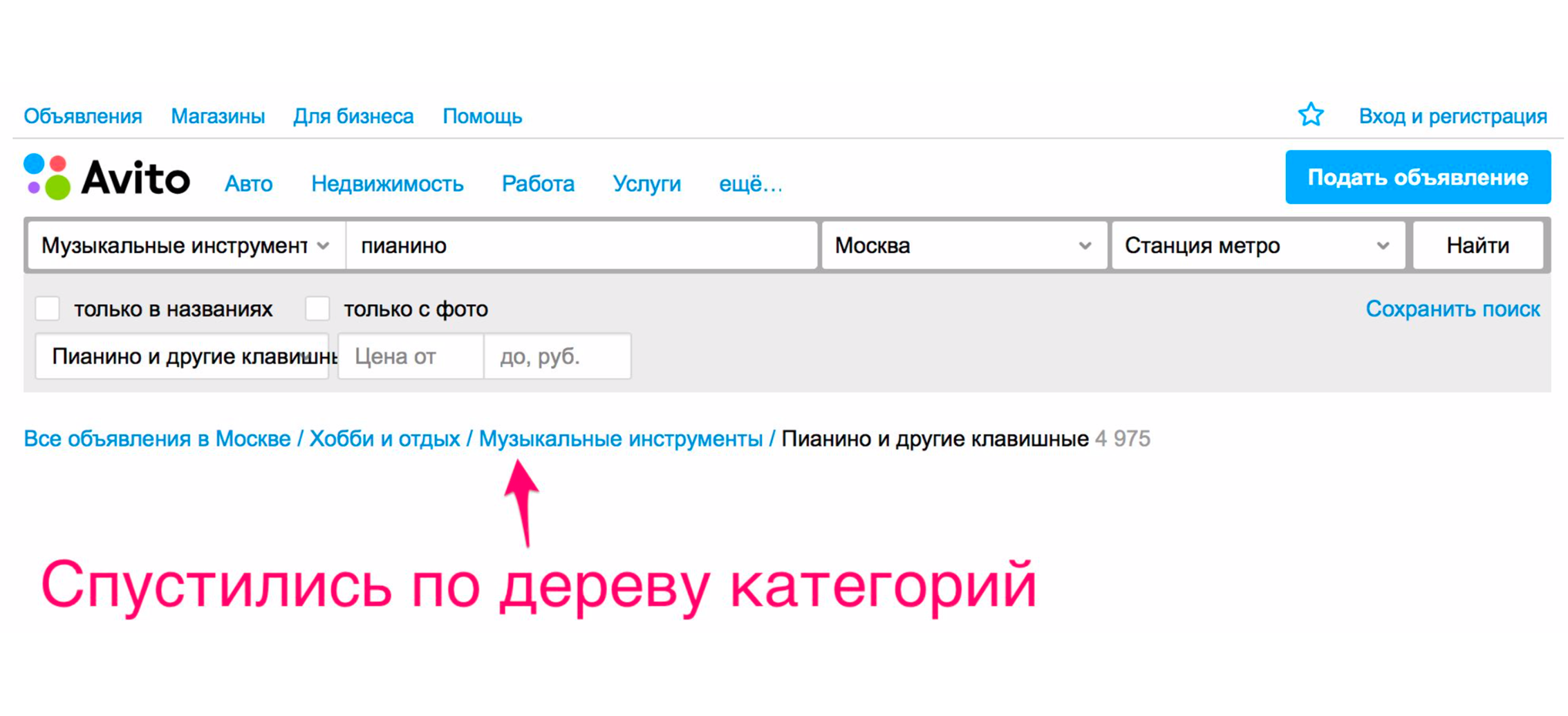
И только после этого видим пианино, которое искали.
Получается, чтобы найти нужное объявление, были следующие возможности:
- уточнение категории при поиске по ключевым словам,
- сортировка по свежести и цене,
- фильтры,
- поиск только по названию.
Что изменилось благодаря релевантности
Благодаря релевантности в выдачу перестали попадать объявления, которые совсем не подходят. Теперь если вы ищете пианино с главной страницы, в выдаче вы, скорее всего, не увидите услуги грузчиков, которые помогают его перевезти, а сразу увидите желаемый вами музыкальный инструмент. При этом добавилась новая сортировка — «По умолчанию». Она формируется по двум показателям: релевантности объявления текстовому запросу и свежести.

В топе вы видите самое свежее из релевантных.
На Авито за дополнительную плату вы можете поднять свое объявление. И с введением релевантности платные поднятия работают эффективнее. Они сработают, прежде всего, если ваше объявление релевантно текстовому запросу.
Введение релевантности не означает, что мы полностью отказались от переходов по дереву категорий. Просто для большинства случаев мы сократили количество кликов до нужного объявления при поиске с главной страницы. Если вам всё-таки нужны услуги по перевозке, хотя вы в поиске набрали просто «пианино», — переходите по дереву категорий и вы найдёте эти объявления. Поиск также стал работать эффективнее и внутри категории, например, «Личные вещи» и «Бытовая техника».
Как найти нужный товар в три клика
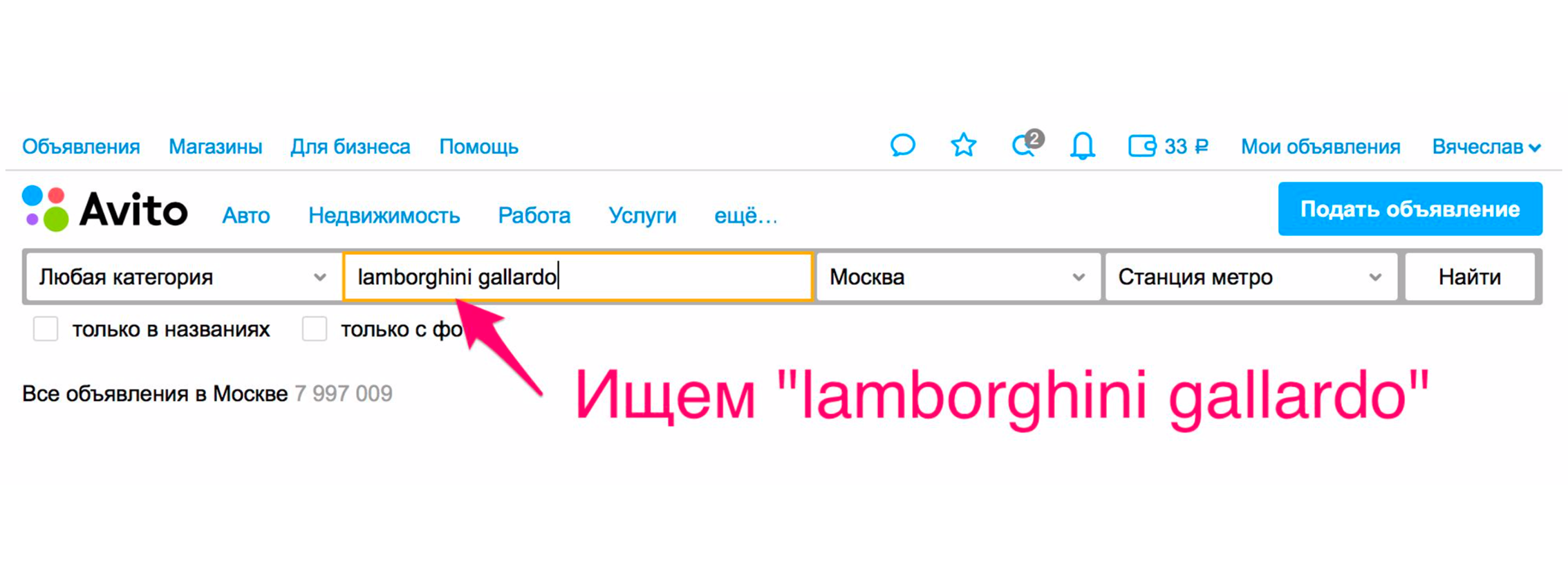
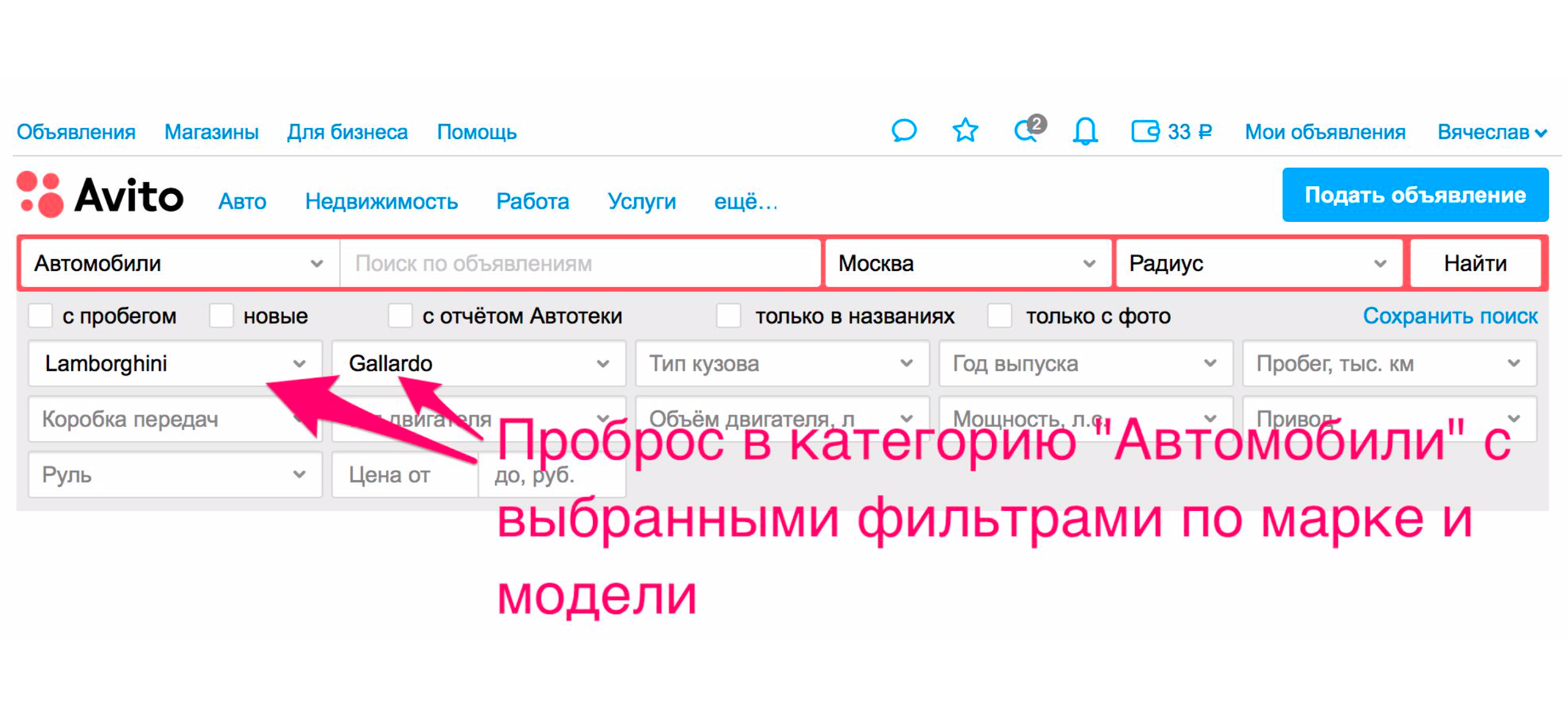
Поиск становится удобнее для пользователей не только благодаря качеству выдачи. Есть и другие способы его улучшить. Один из них — проброс в категорию. Например, мы ищем Ламборгини Гаярдо (да, вы любите играть на пианино и хотите ездить на Ламборгини). Чтобы добраться в категорию автомобиля определенной модели, нужно совершить два лишних клика. С релевантностью, скорее всего, вы получите, что хотите.
Но есть дополнительный способ, который вас сразу пробросит в автомобили. Выдача будет сужена, будет выбран нужный автомобиль в фильтрах, и вы получите в выдаче действительно автомобили.

Ещё один способ — расширяющие теги. Например, когда вы вводите слово «куртка», у вас появляются подсказки.
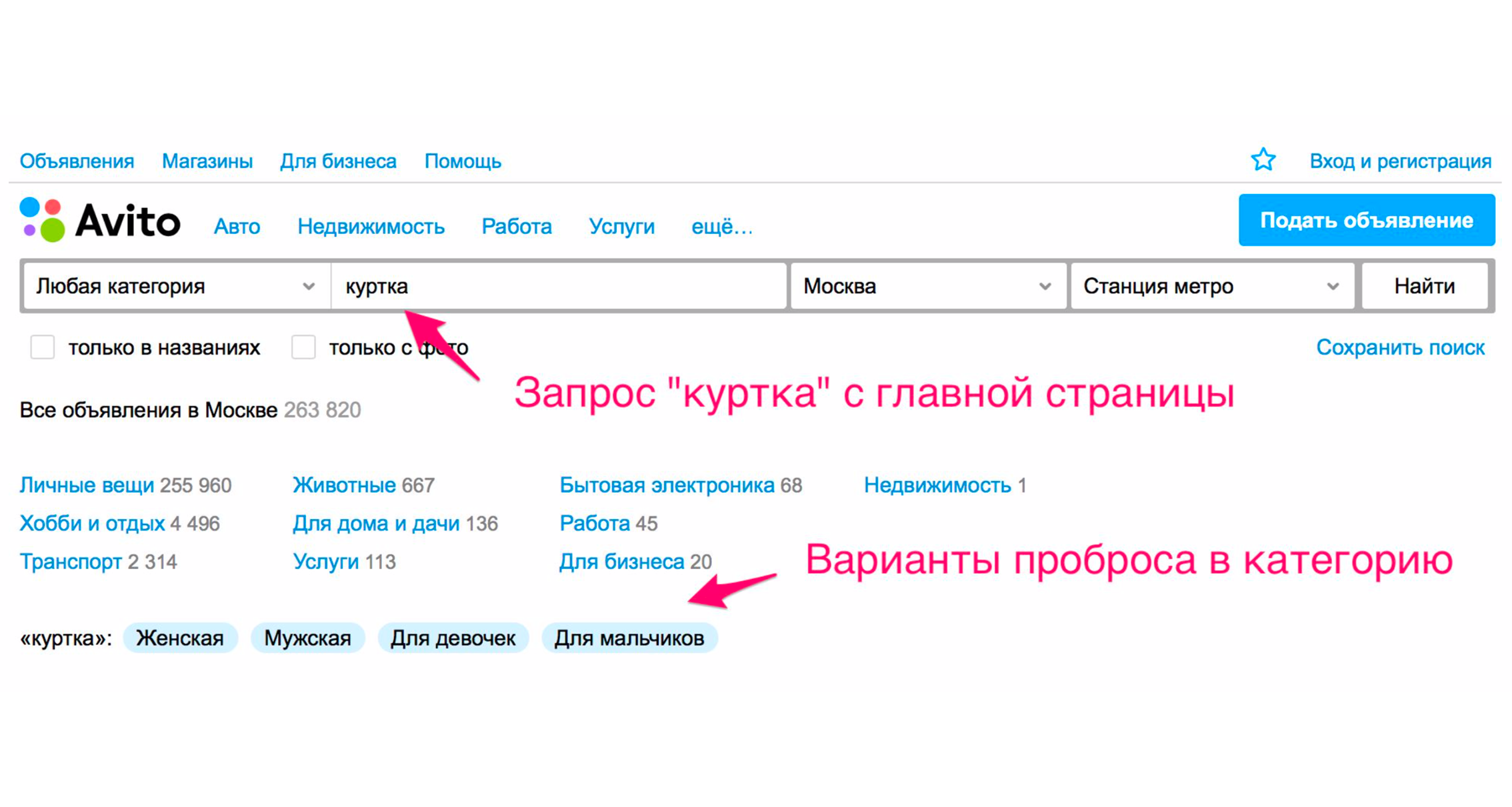
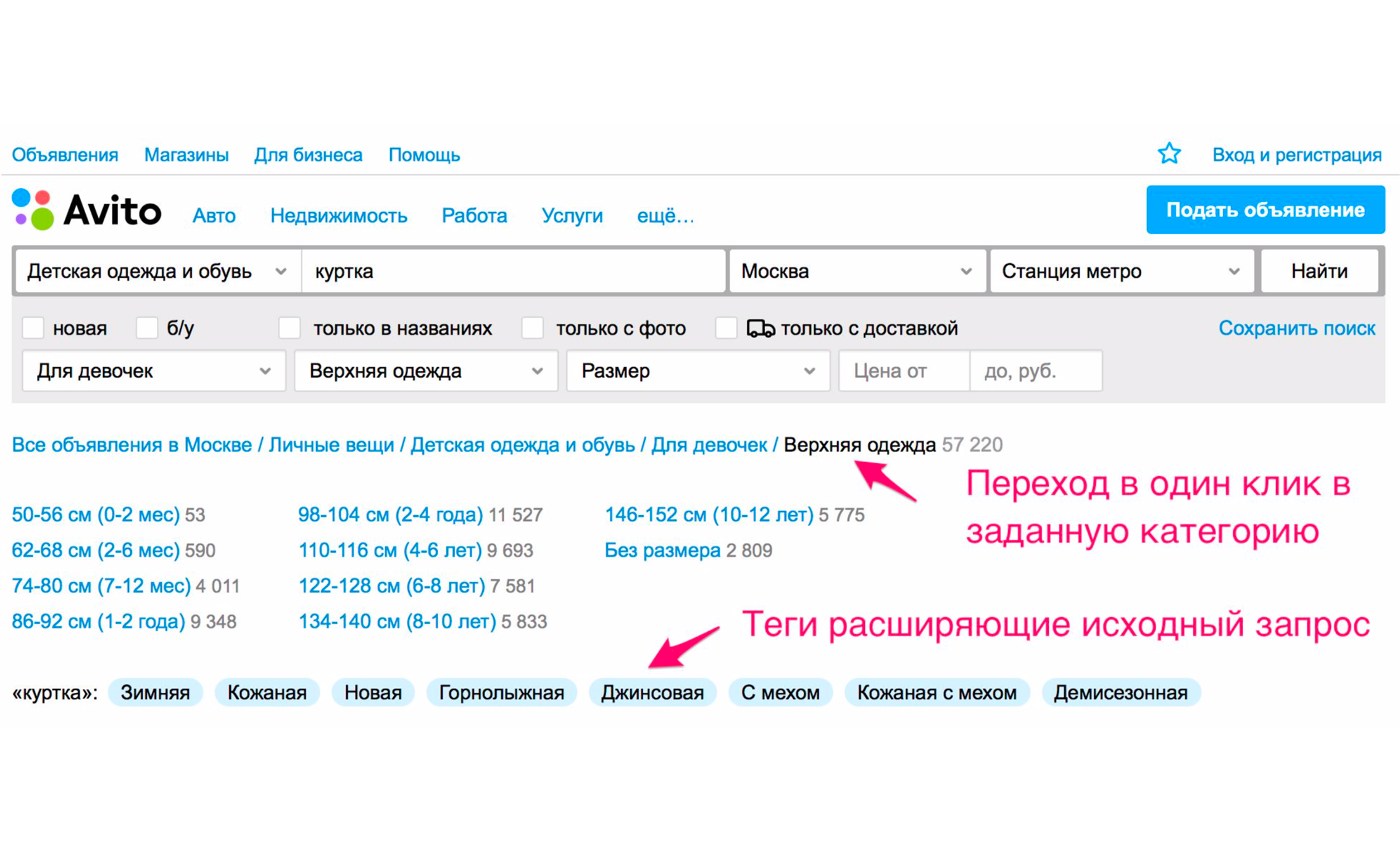
На скриншоте выше показаны подсказки: тип курток — женская, мужская, для девочек, для мальчиков. Если вы нажмёте «Для девочек», то сразу попадёте в категорию, где будут выбраны соответствующие фильтры. Также тут появится набор дополнительных расширяющих тегов: зимняя куртка, кожаная, новая и так далее. Если же спускаться по дереву категорий вручную до нужного товара, то надо совершать больше действий.
В чем разница между поиском и фильтрами
Когда я выступал с докладом на РИТ++, у слушателей был вопрос: в чем же разница между поиском по тексту и фильтрами? Всё достаточно просто. Найти нужное объявление можно и без текстового запроса, спустившись по дереву категорий. В этом случае поиск все равно будет находить товары и услуги, но не по заданному тексту, а по набору параметров, переданному из соответствующих фильтров выбранной категории.
Каждой категории соответствует собственный набор фильтров. Например, в категории «Автомобили» — одни фильтры, в категории «Личные вещи» — другие фильтры. То есть фильтры жестко привязаны к категории.
Размещение объявления за две минуты
Для продавцов появилось важное нововведение, которое они ощущают при подаче своего объявления. Если ваше объявление не содержит какой-то «запрещенки» или не является дубликатом — обычное хорошее объявление — вы его увидите в выдаче практически сразу. Реально эта задержка длится около двух минут, но в редких случаях может продлеваться до 30 минут. Раньше же объявление всегда появлялось на сайте только через полчаса.
Авито Помощник
«Авито Помощник» — это расширение для Chrome, которое отображает на сторонних сайтах цену аналогичного товара на Авито. В расширении вы можете сравнить цены во многих интернет-магазинах с ценами на Авито или просто искать нужные товары и услуги в нашем сервисе, не переходя напрямую на сайт или в приложение. Мы смогли реализовать «Помощник» в том числе благодаря новым инфраструктурным изменениям.

Архитектура
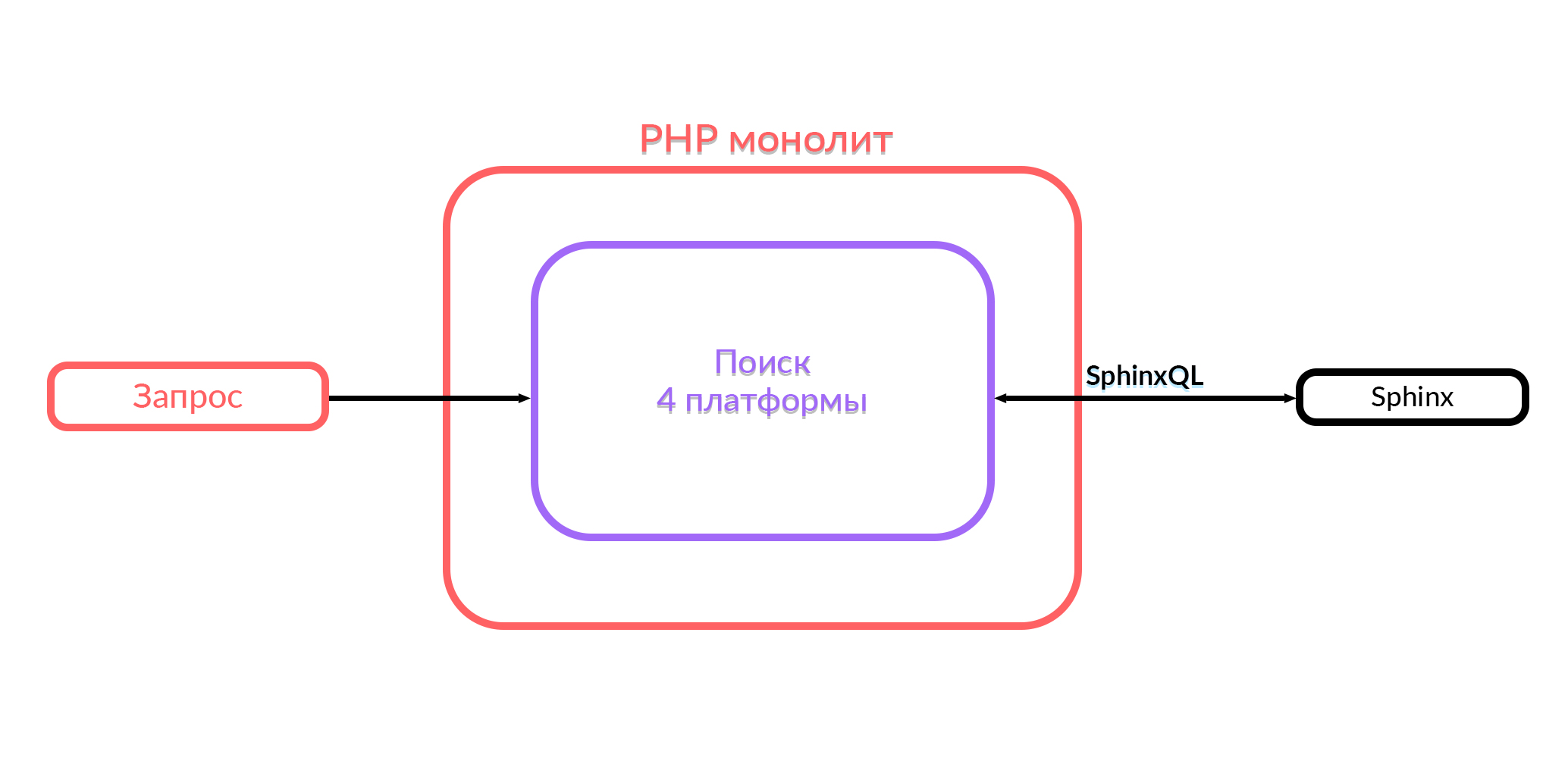
Пилим монолит
В Авито есть монолит на PHP. Год назад весь поисковый функционал, который работает в Авито, был в этом монолите. Поиск в монолите работал с четырьмя платформами: Android, iOS, мобильная версия в браузере и десктоп. Чтобы отдать выдачу, внутри этого кода формировались соответствующие SQL-запросы в Sphinx, шла обработка, и выдача отправлялась в формате JSON или HTML. Тогда пользователи видели то, что они искали.
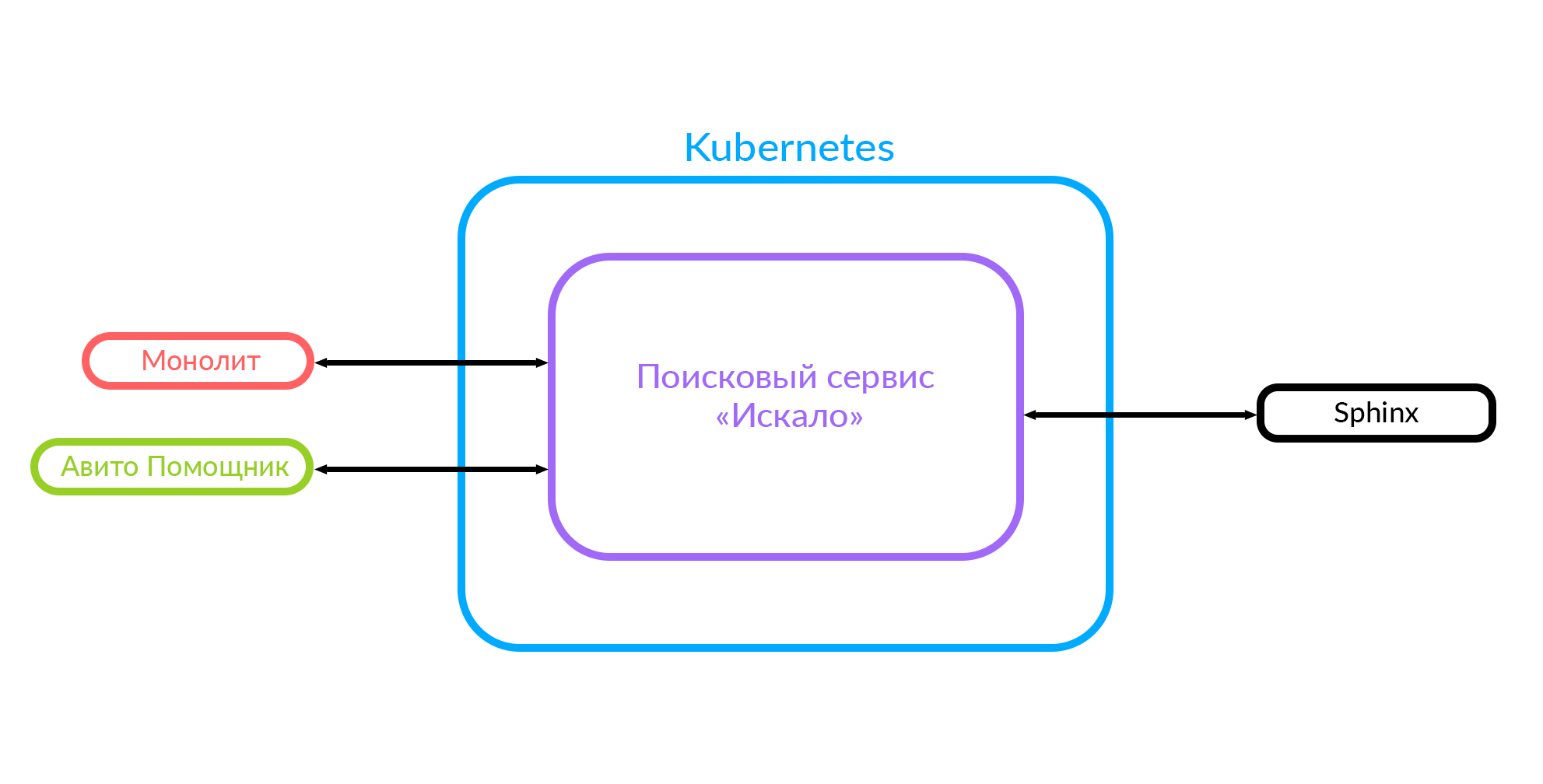
Что у нас сейчас
Если реализовывать новые фичи, то очень сложно интегрироваться с этим монолитом. Поэтому мы приняли решение разработать поисковый сервис, который между собой назвали «Искало». Теперь монолит ходит в этот поисковый сервис, а сервис ходит в Sphinx.

Причины создания поискового сервиса
При разработке сервисов всегда нужно понимать, зачем вы это делаете. Первый очевидный плюс — вынос низкоуровневой логики. В нашем случае это скрытие кухни по обработке SphinxQL-запросов. Кроме того, мы можем проще предоставлять поисковый функционал сторонним системам.
Асинхронное выполнение запросов. Это преимущество достаточно очевидно и в зависимости от реализации можно достигнуть тех или иных успехов. Наш сервис реализован на Golang, и существовал функционал, который можно было распараллелить — три запроса в Sphinx, из-за чего получились хорошие результаты.
Быстрый деплой. Мы выделили отдельный функционал с меньшим объёмом кода, лишних тестов (в монолите много тестов, не только на поисковый функционал), и он проще выкатывается. Самое главное, что за счёт удачного подхода в реализации этого сервиса мы смогли запиливать интересные штуки и реализовывать продвинутые алгоритмы ранжирования — делать достаточно сложную обработку, которую не могли бы сделать в монолите. Это предоставляет нам очень хороший фундамент для проведения экспериментов с качеством поиска.
Как бонус, у нас есть возможность перейти со Sphinx на Elastic, потому что низкоуровневая логика теперь скрыта.
На этой схеме уже отображен случай, когда есть монолит, сервис «Искало» и сторонний сервис «Авито Помощник».
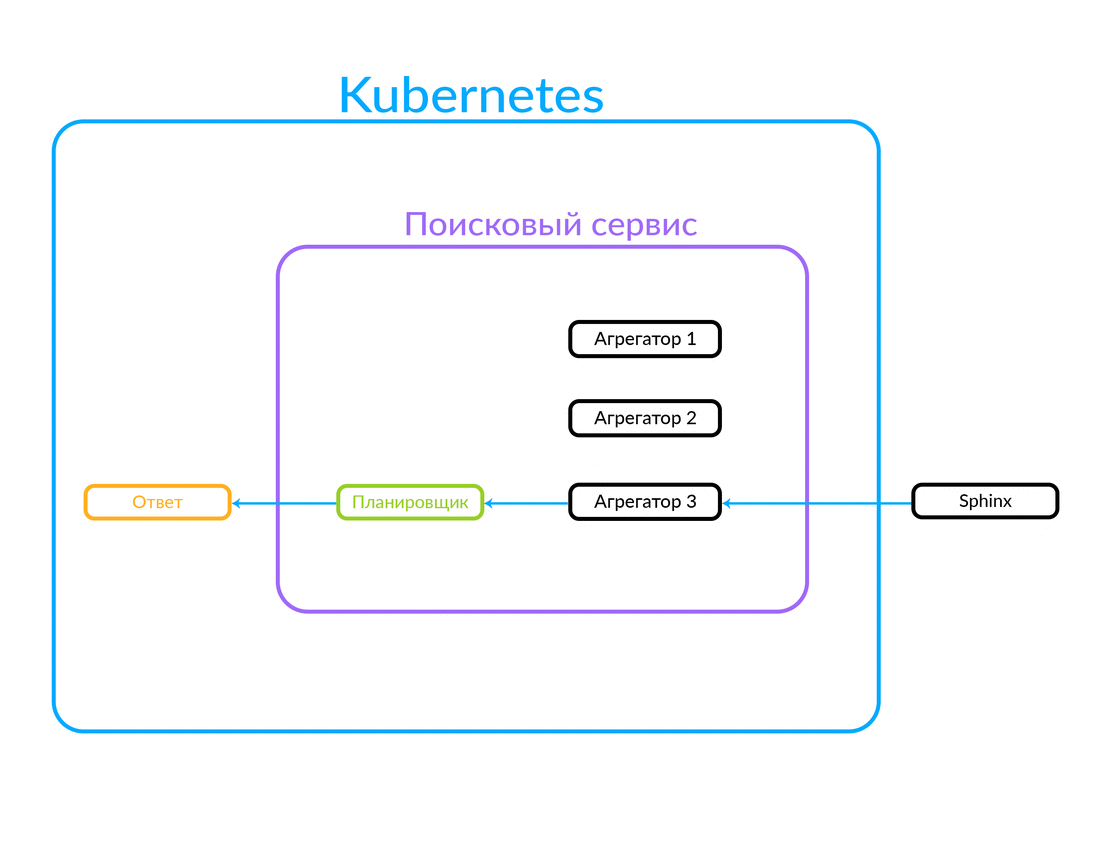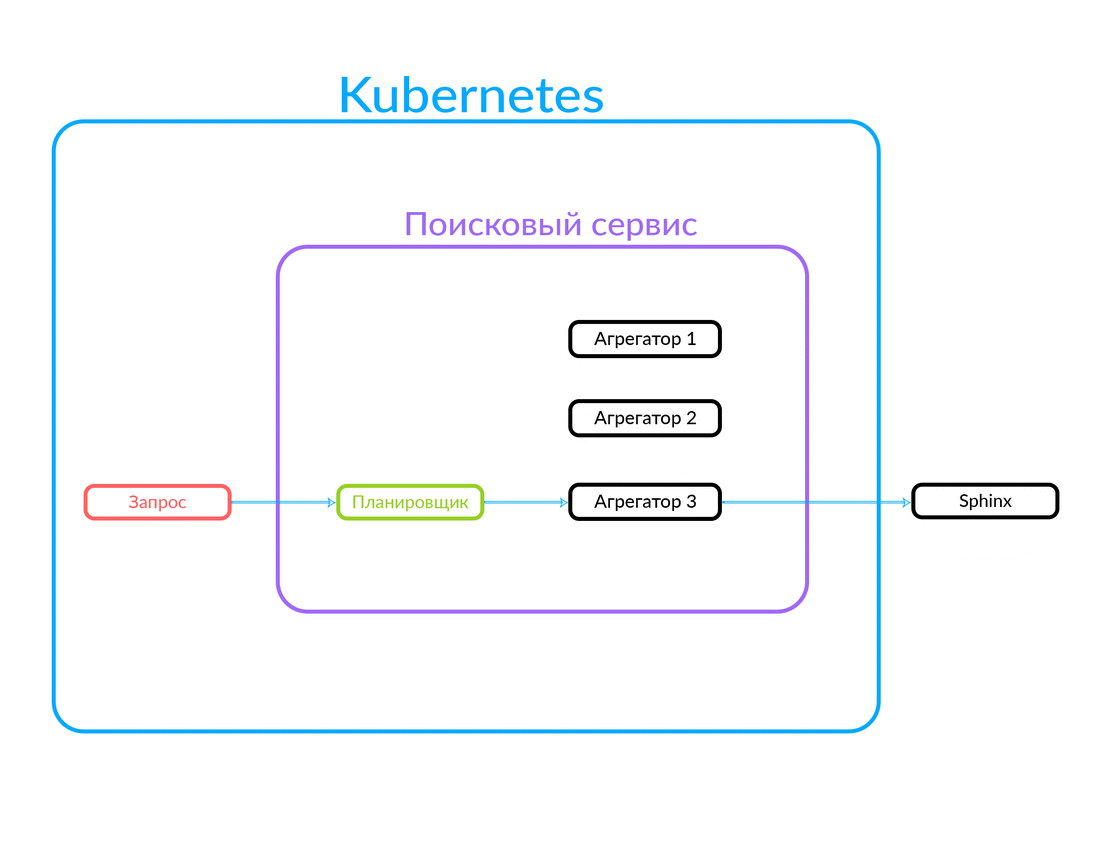
Как работает поисковый сервис
В нем есть набор агрегаторов. Каждый агрегатор выполняет некую бизнес-логику, связанную с обработкой выдачи. Он может формировать эту выдачу определенным образом.
Запрос поступает на планировщик. Планировщик по критерию запроса с точки зрения его параметров (или если в самом запросе указан нужный агрегатор) выбирает агрегатор. Агрегатор идет в Sphinx. Получив от Sphinx ответ, он формирует выдачу и отдаёт ответ клиенту.

В данном случае запрос был снаружи, не из облака, в котором работает наш поисковый сервис. Но возможен и другой вариант: какой-то другой наш сервис, внутри облака, например, «Авито Помощник», обращается в поисковый сервис. Этот запрос идёт уже в другой агрегатор — там другая бизнес-логика. Вот как это работает:
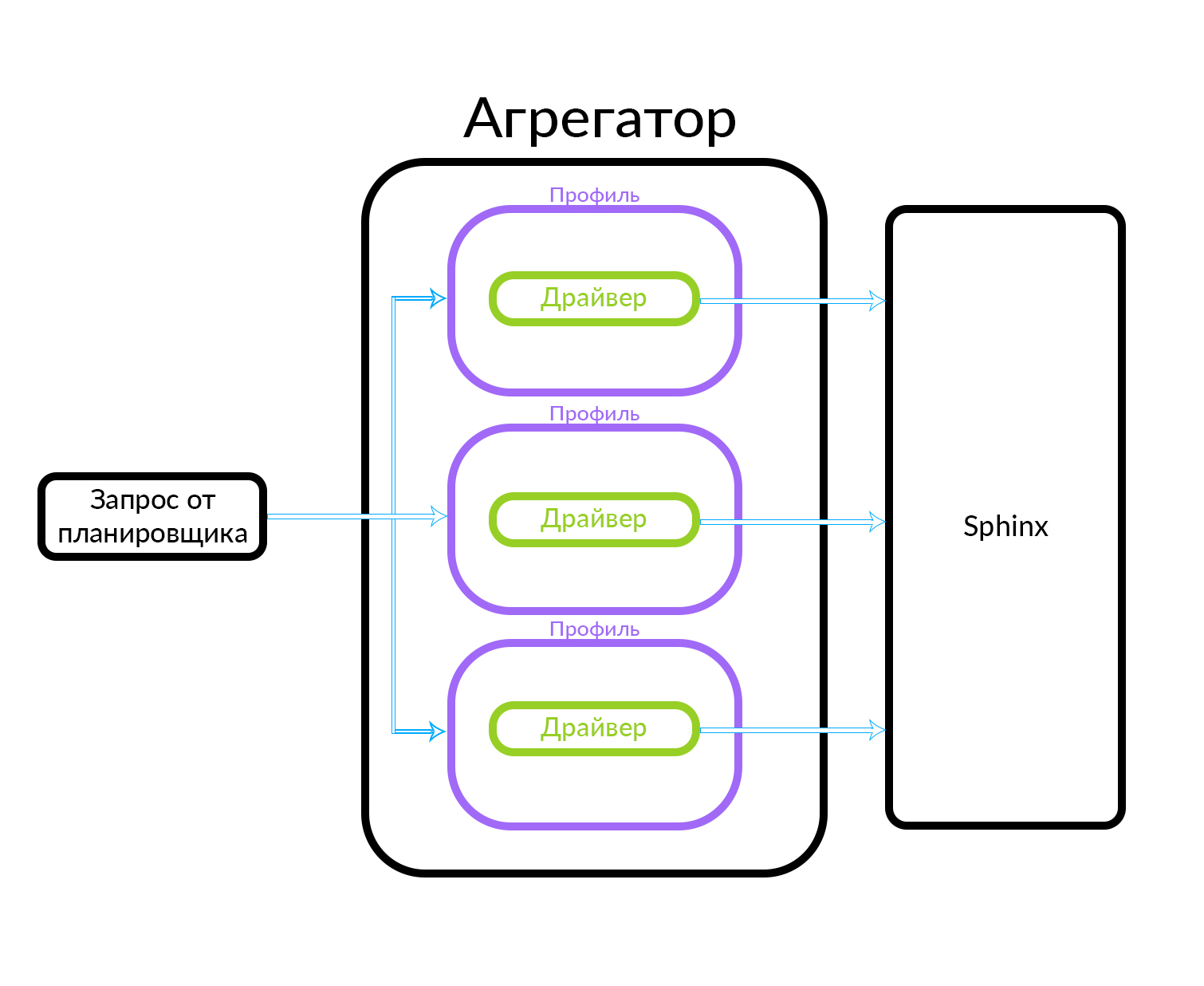
Как работает асинхронное выполнение запросов на агрегаторе
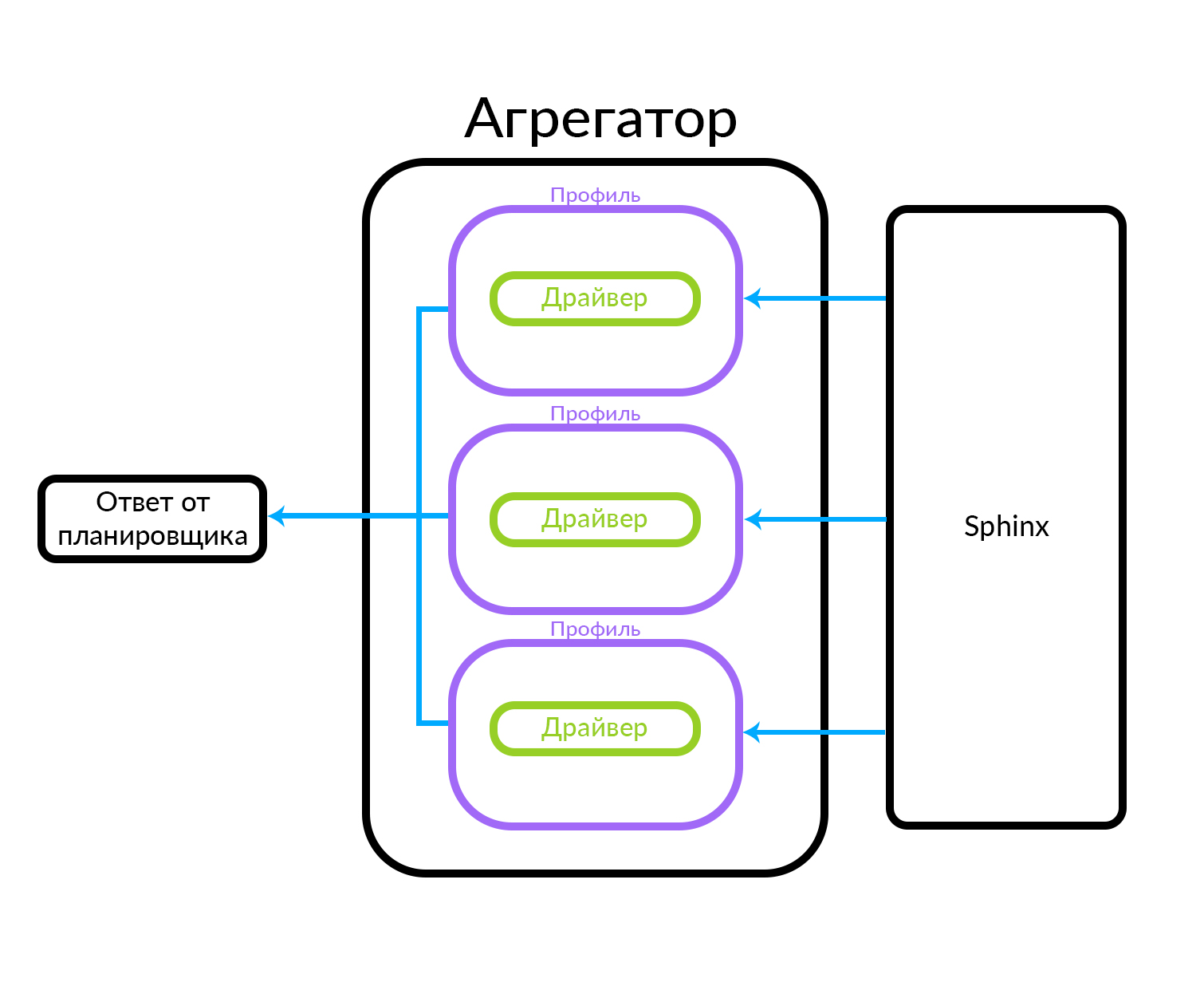
Агрегатор состоит из нескольких профилей. Профиль — это, грубо говоря, сущность, в которой можно получить объявление какого-либо типа или каким-то определенным способом. Например, это можно объяснить через аналогию: на Авито есть «Премиум», «VIP» и обычные объявления. Агрегатор получает запрос от планировщика, при этом для известного в агрегаторе набора профилей выполняются параллельные запросы. Профиль имеет внутри себя драйвер, который физически обращается на нижележащий уровень, в данном случае в Sphinx, но это может быть любой другой источник данных
Агрегатор может просто отдать планировщику результаты запросов к профилям, а может произвести и более сложные действия, например, смешать эти результаты по тому или иному алгоритму.
Хранение поискового индекса
В связи с тем, что в архитектуре мы используем Kubernetes, на РИТ++ мне задали вопрос про хранение поискового индекса — хранится ли он в Kubernetes? Нет, у нас Sphinx живёт на физических машинах. В Kubernetes у нас разворачивается поисковый сервис, который обрабатывает логику поиска. В облаке также лежит семпл поискового индекса для среды разработки, на котором запускаются тесты, но боевой индекс туда класть нежелательно, потому что сервисы, которые работают в Kubernetes, это, прежде всего, stateless-сервисы.
Нагрузка на поисковый сервис
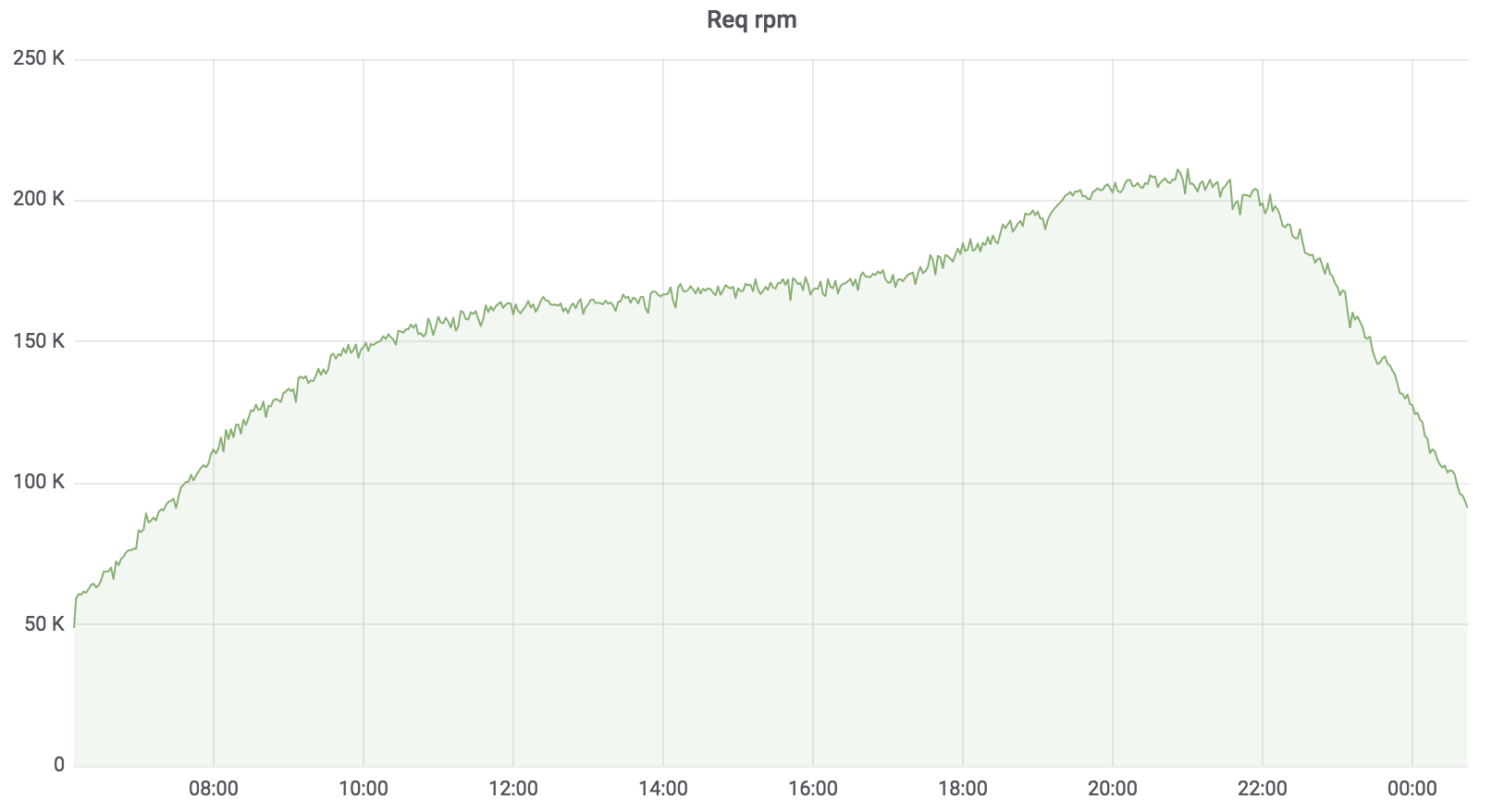
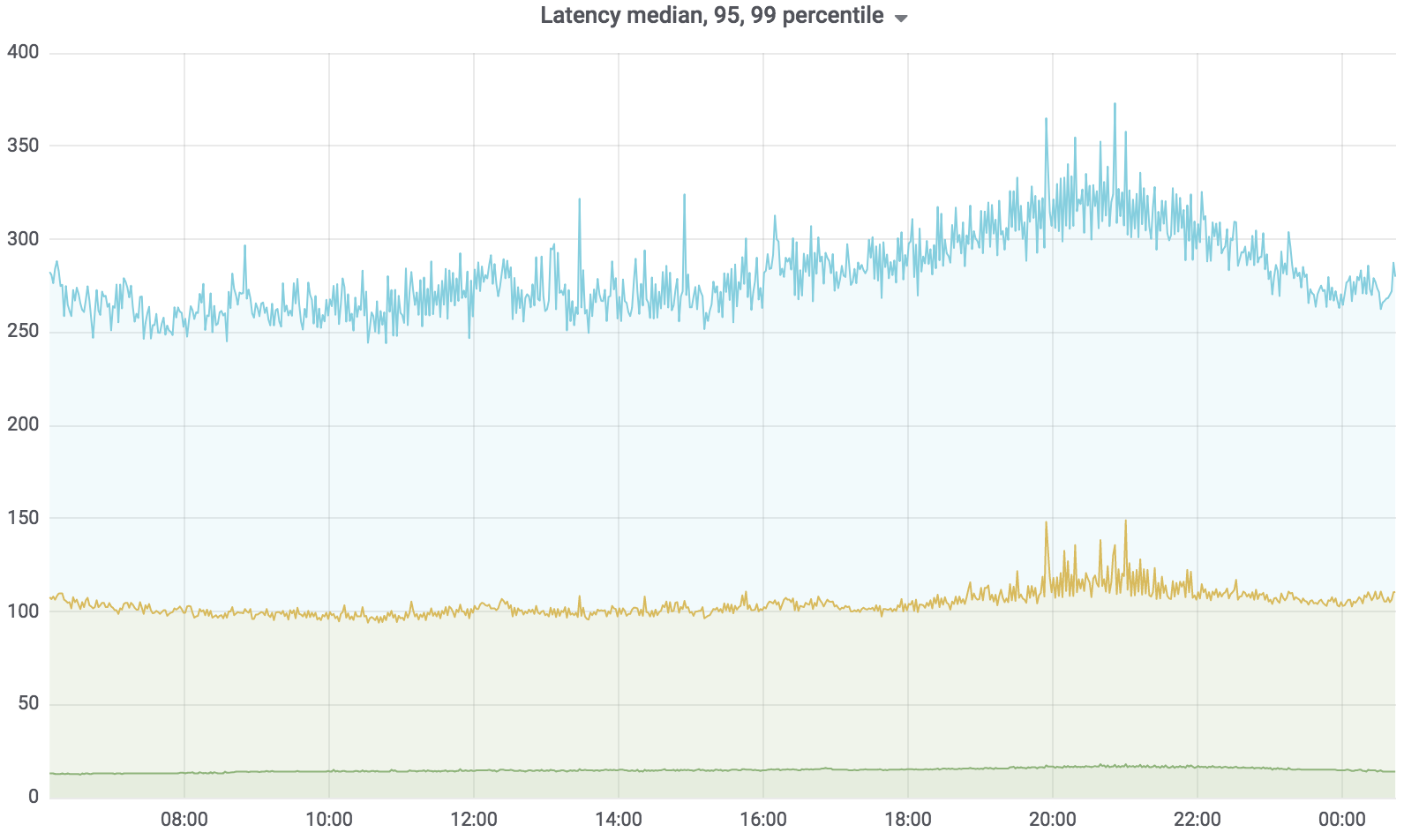
Сейчас этот сервис в бою, он обслуживает 100% нагрузки за небольшим исключением. Нагрузка, которую он держит — это примерно 200 krpm. Задержка: медиана — до 17 мс, 95 процентиль — до 120 мс, 99 процентиль — до 320 мс.
Итого по поисковому сервису
Поисковый сервис написан на Golang, разворачивается в Kubernetes, агрегатор асинхронно работает с несколькими профилями. Профиль работает с заданным драйвером, драйвер обращается к заданному источнику данных, например, Sphinx. Количество запросов, которые обслуживает наш сервис, до 200 krpm в данный момент. Задержка: медиана — до 17 мс, 95 процентиль — до 120 мс, 99 процентиль — до 320 мс.
Внедрение сервиса в рабочую систему
Проблема двойного функционала достаточно очевидна, нам приходится поддерживать две кодобазы, которые должны выполнять одну и ту же задачу. Нам нужен fallback. Мы назвали его «Соломка» — вспомнили про «подстелить соломку». Кроме того, нам нужно управление трафиком, желательно чтобы оно было быстрым, через дашборд.
Как работает «Соломка»
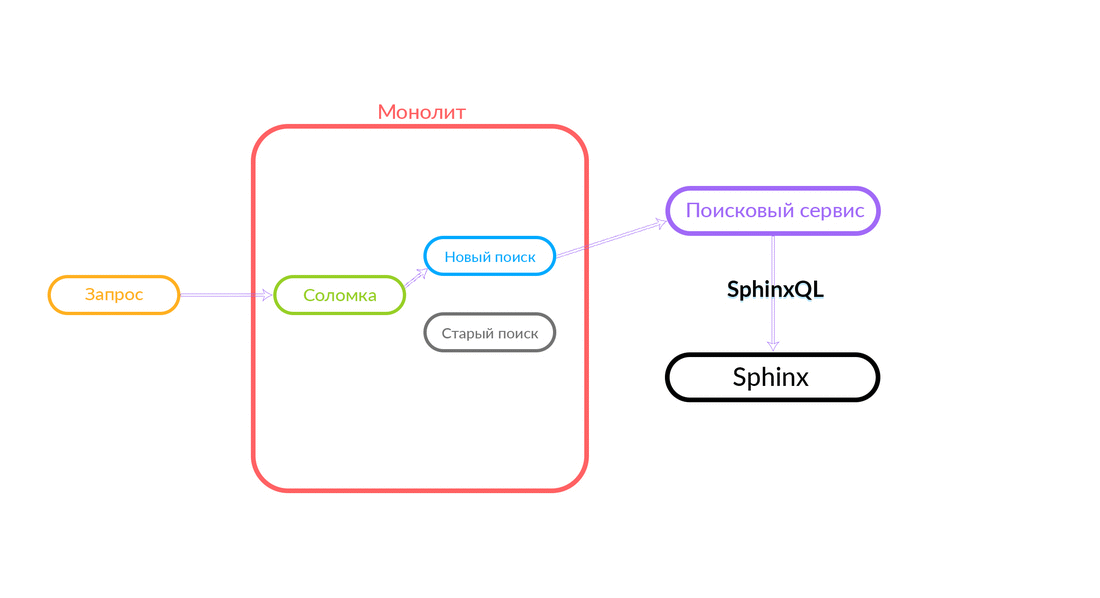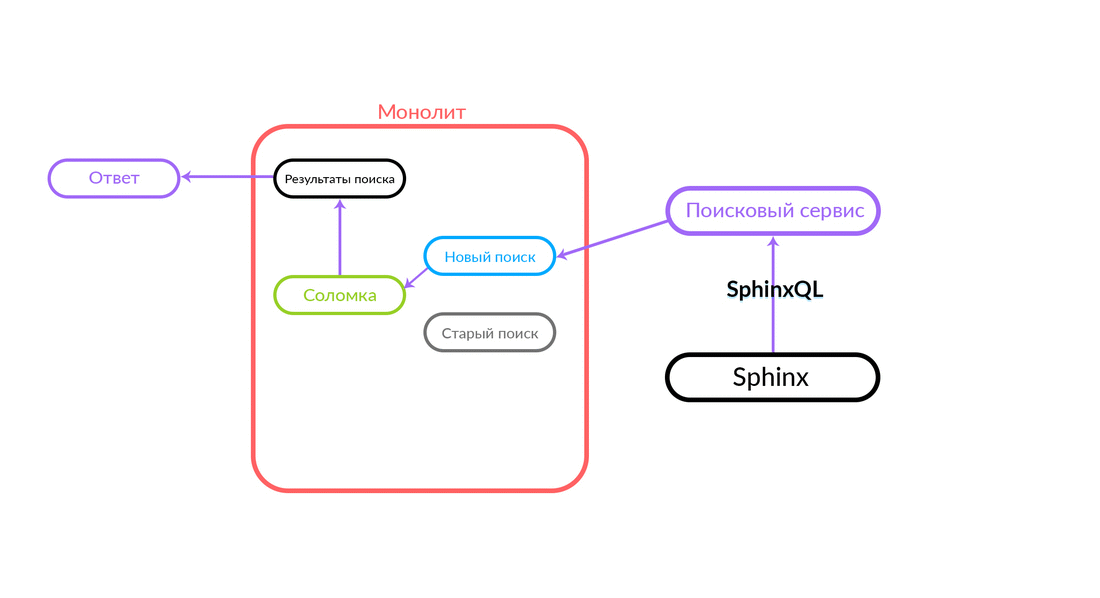
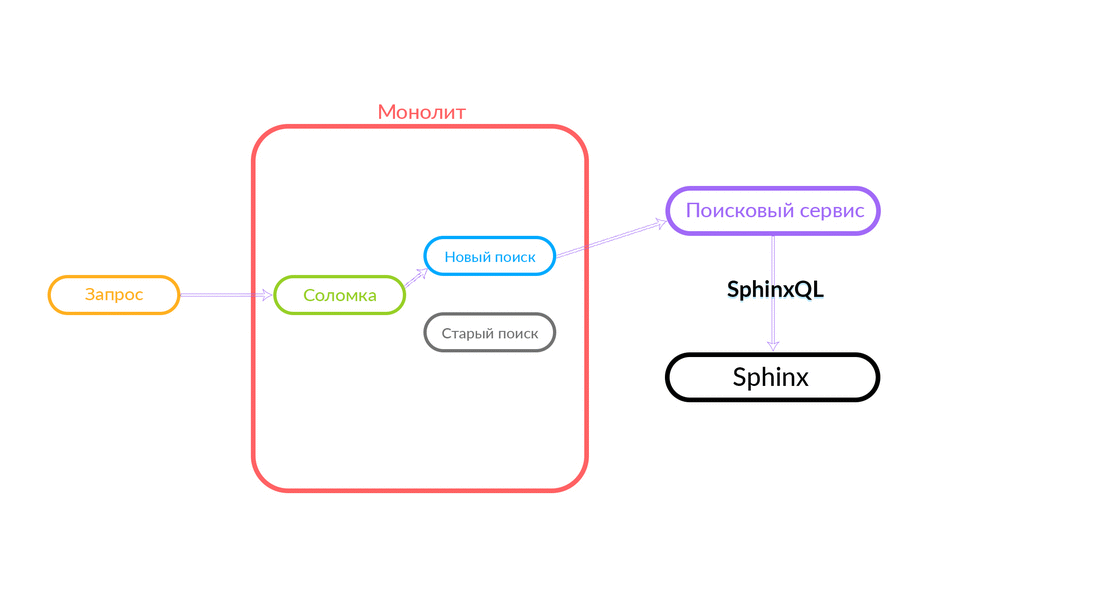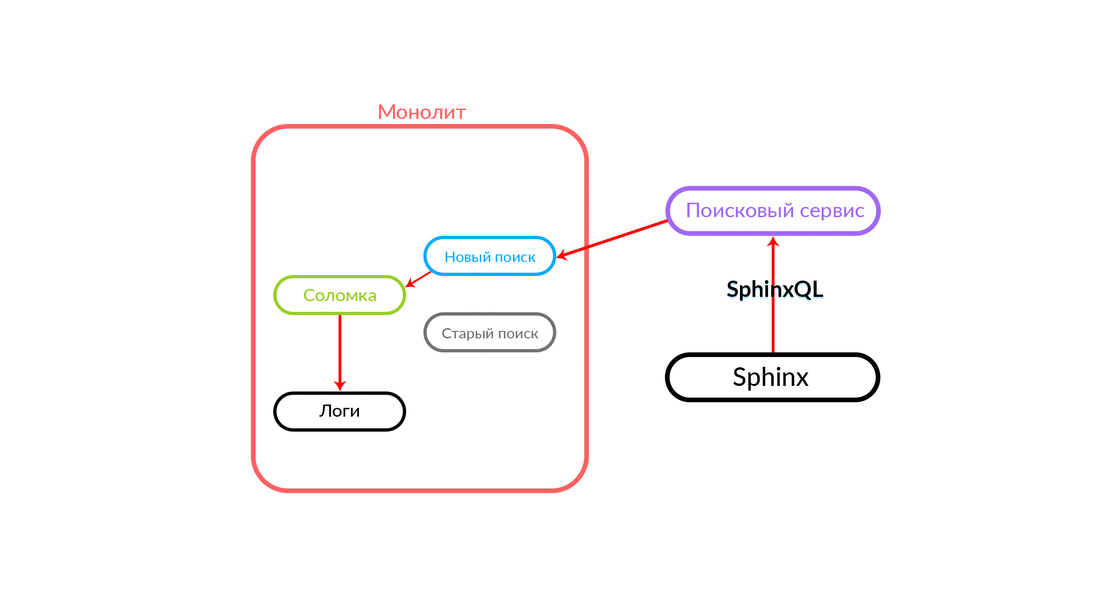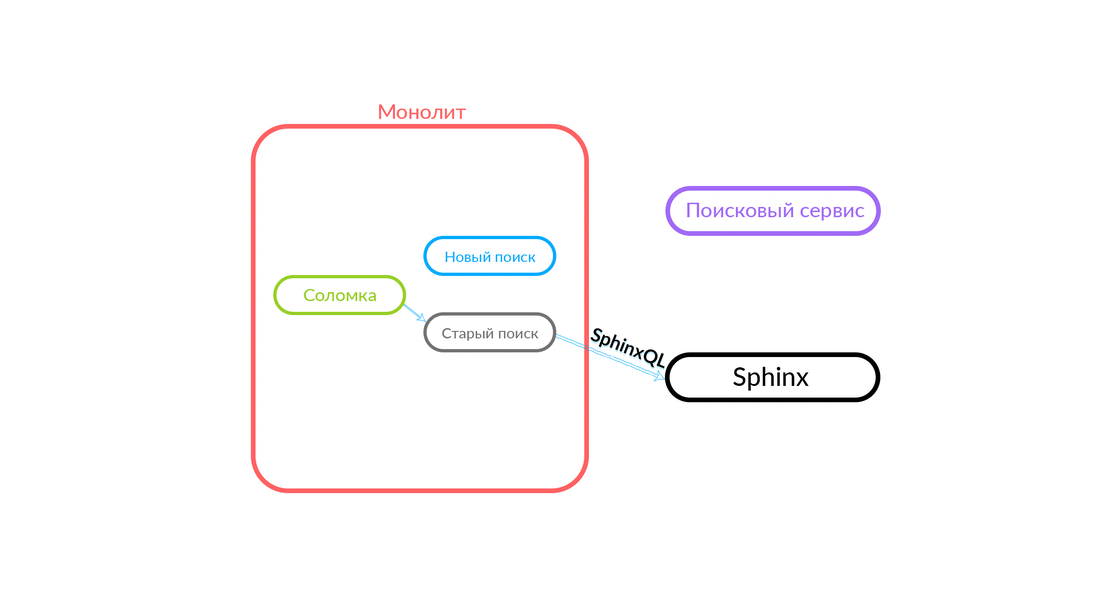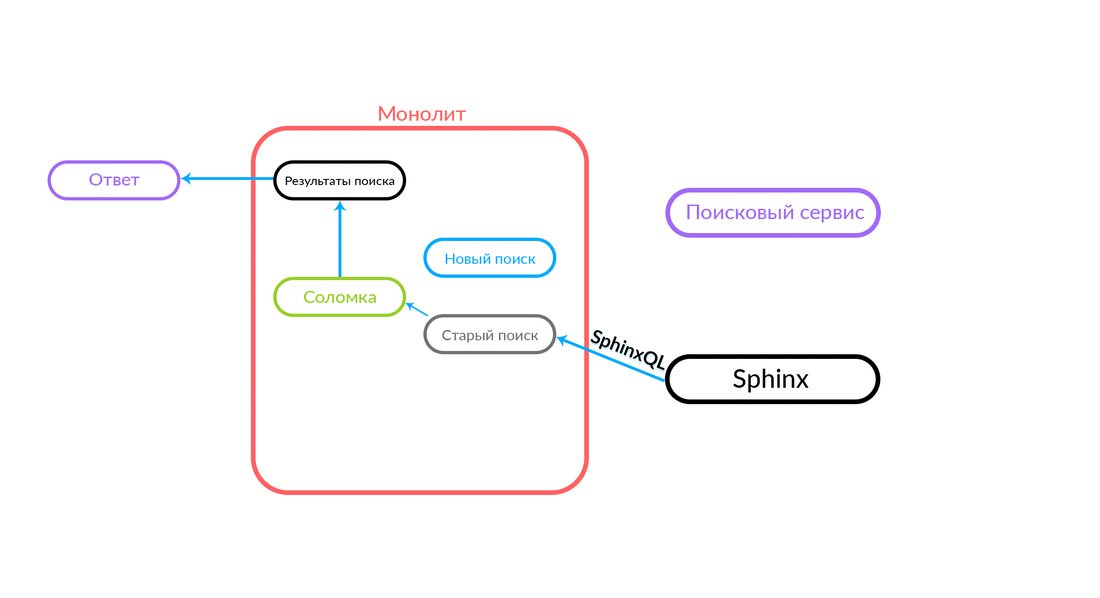
Поисковый запрос приходит в «Соломку», которая работает внутри монолита и может сделать дальнейший вызов либо в новый поиск, либо в старый. Она делает вызов в новый поиск, тот его отрабатывает, и в случае успеха мы просто получаем выдачу из нового поиска.
Бывают ситуации, когда какой-нибудь запрос к поисковому сервису сфейлился: например, и пока не реализован какой-то функционал внутри поискового сервиса. Тогда мы обязательно залогируем такой запрос — «Соломка» выполнит его в старом поиске. Старый поиск из монолита обратится в Sphinx, и ответ уйдет клиенту. Клиент ничего не почувствует.
Достаточно надёжная схема, и всегда интересно посмотреть, что случается на практике. Отдел архитектуры Авито постоянно совершенствует наше облако, тюнит, делает более надежным и производительным. На каком-то этапе были проблемы, что при обслуживании одной из нод, с достаточно большой интенсивностью из монолита шли ошибки (100 ошибок в секунду).

При этом у нас резко поднялась задержка на сервисе — на картинке ниже видно пики.
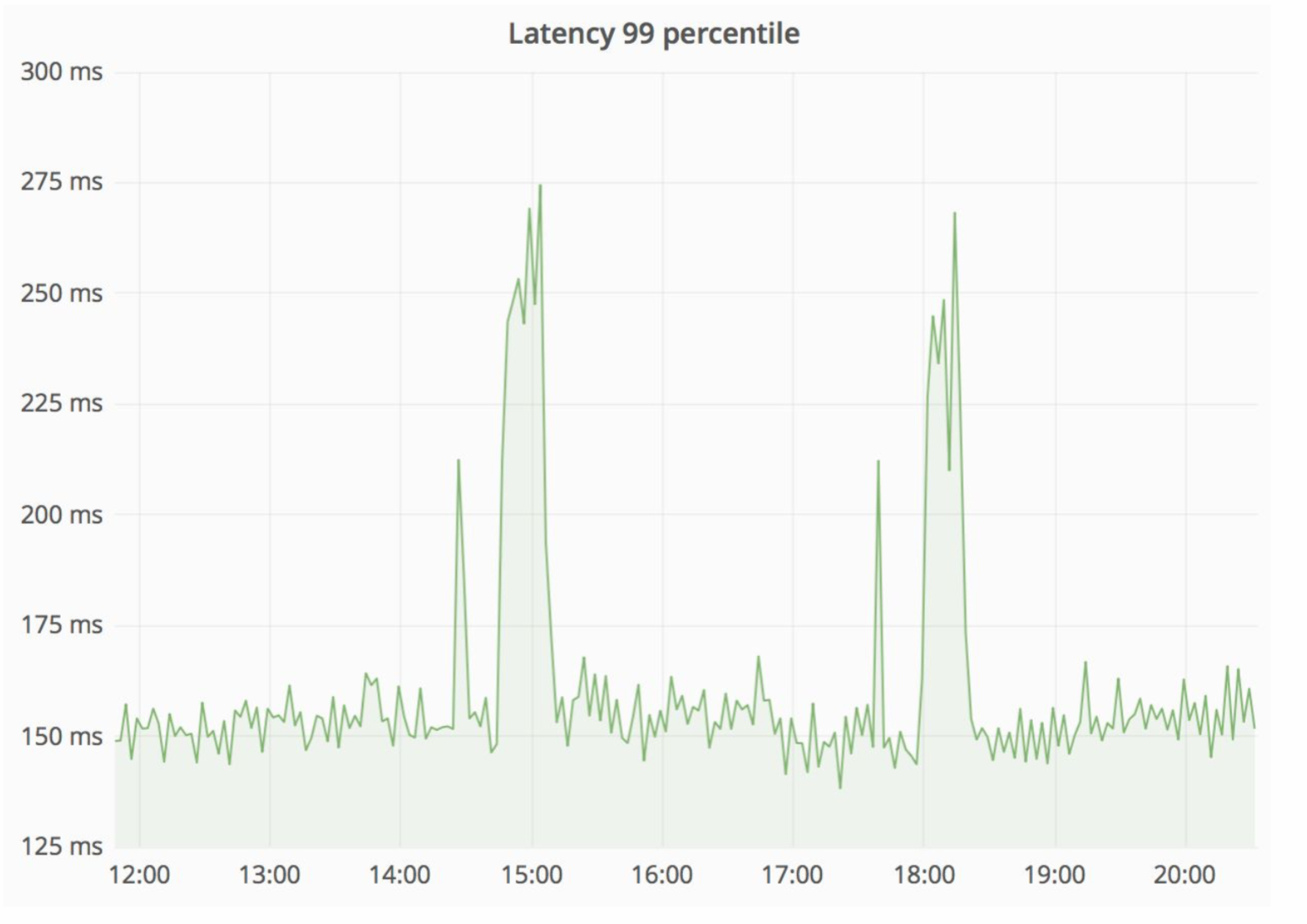
«Соломка» замечательно отрабатывала эту ситуацию, и итоговые HTTP ошибки были на прежнем уровне — единица ошибок на весь Авито. Наши посетители ничего не заметили.
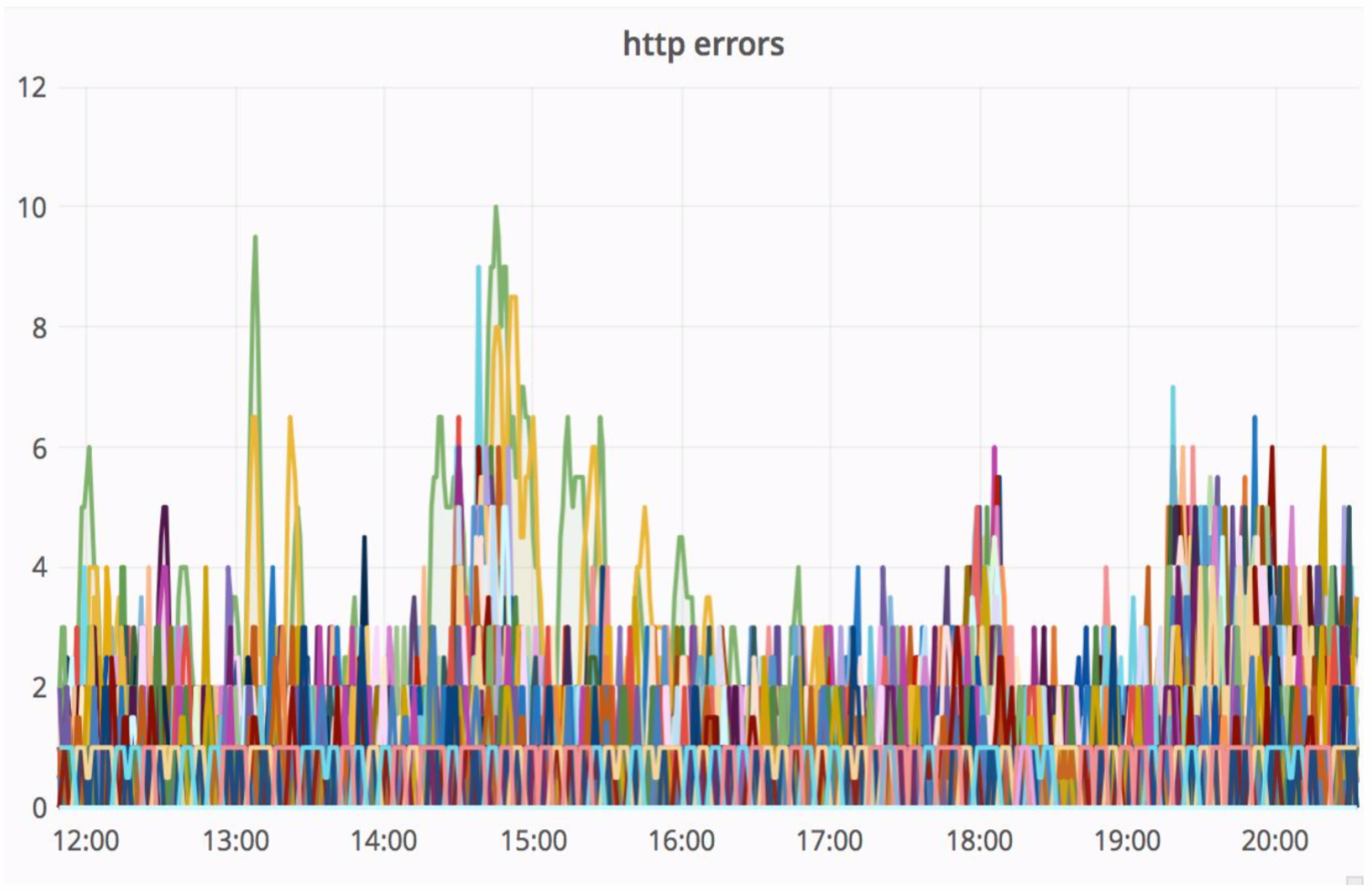
Автоматизация экспериментов
Мы хотим, чтобы поиск развивался быстро, и выкатывать в него новые фичи было проще. Для этого нужна соответствующая инфраструктура. У нас настроена автоматизация А/В тестов. С помощью дашборда мы можем заводить новые эксперименты, конфигурировать их, исходя из добавленных нововведений, и, соответственно, запускать эксперименты без выкаток монолита.
В исходном состоянии, когда не запущено ни одного эксперимента, все посетители видят привычный поисковый функционал.
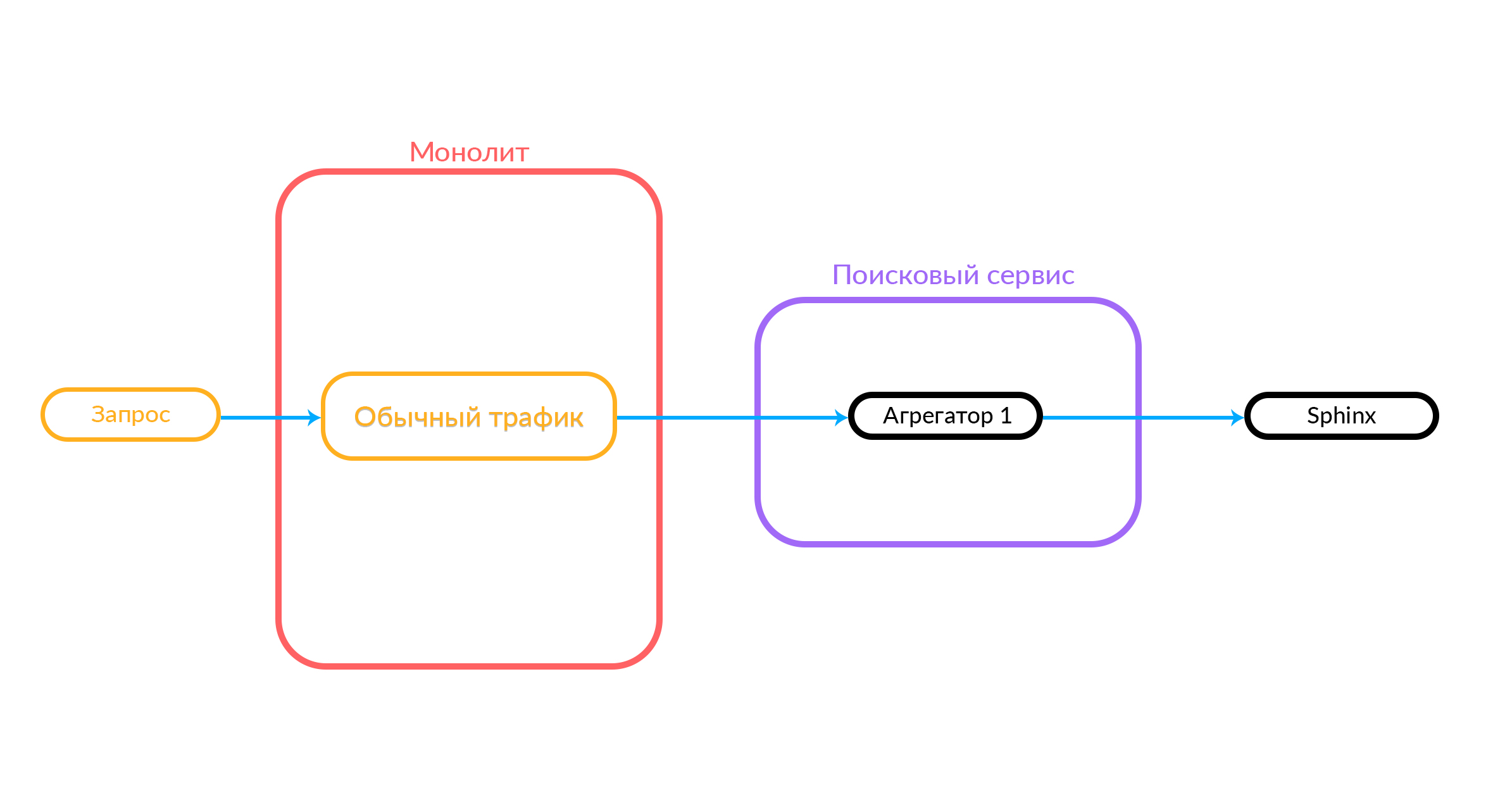
В типичном эксперименте пользователи делятся на группы. Контрольная группа — с привычным функционалом для наших посетителей. Есть несколько тестовых групп — с нововведениями. Когда нам нужно создать новый эксперимент, в поисковом сервисе мы реализуем новый поисковый функционал (добавляем новые агрегаторы) и через дашборд настраиваем эксперимент с необходимыми группами, связывая их с новыми агрегаторами.
При анализе экспериментов мы сравниваем поведение посетителей в контрольной группе с тестовыми и на основе этого делаем выводы об успешности эксперимента.

Предположим, мы разработали новую формулу ранжирования. Что нам нужно сделать, чтобы провести эксперимент с ней?
- В поисковом сервисе выкатить соответствующий агрегатор (пусть это будет «Агрегатор 2»).
- Через дашборд создать эксперимент и связать одну из групп в этом эксперименте с этим агрегатором.
- Теперь если в поиск приходит запрос, попадающий в тестовую группу, он уходит в поисковый сервис на «Агрегатор 2».
Мы можем продолжать создавать новые эксперименты и связывать их тестовые группы с новыми агрегаторами.
Итого по инфраструктуре поиска
Есть кластер серверов Sphinx 3. Он держит 13 krps SphinxQL запросов, и на нем более 45 миллионов активных объявлений.
Sphinx 3.0 стабилен и радует своей производительностью. Кстати, бинарники в открытом доступе. Кроме того, благодаря Авито в Sphinx 3 запиливаются новые фичи, например, операция скалярного произведения векторов, а найденные баги фиксятся.
Мы применяем сервисную архитектуру. У нас есть поисковый сервис «Искало» и сервис «Авито Помощник». Часть функционала пока осталась в монолите, но мы продолжаем работы по его распилу.
Выводы
За последний год получена продвинутая система разработки поискового функционала. Мы получили возможность проведения быстрых и гибких экспериментов. И теперь поиск для пользователей стал удобнее, быстрее и лучше помогает решать их задачи.
Что дальше
Дальше мы будем продолжать выносить из монолита то, что осталось: рендеринг, фильтры. Будем работать над повышением качества поиска, продолжать радовать наших посетителей. Надеюсь, вас тоже.
Если у вас есть вопросы про работу нашего поиска, хотели бы узнать больше технических подробностей, пишите в комментариях. С удовольствием отвечу. Кстати, недавно Андрей Дроздов выступал на Highload++ 2018 с докладом про многокритериальную оптимизацию поисковой выдачи, вот его презентация.
Комментарии (13)

denisgrim
27.11.2018 21:28А что у вас сейчас с синтаксисом для поискового запроса? Помню, когда мне это было нужно, в вашей справке ничего не было на этот счет. Пришлось искать неофициальную инфу на левых сайтах. А еще, вы урезали опции поиска в приложении. Стало дико неудобно уточнять результаты поиска. Вопрос: зачем?
vkrukov Автор
28.11.2018 00:23Увы, у нас нет публично специфицированного синтаксиса поискового запроса. Уточните, пожалуйста, вторую часть вашего вопроса. Это сайт или мобильное приложение и какие элементы интерфейса?
Danikey
28.11.2018 18:42Небольшой вопрос: неужели сразу не было понятно, что людям нужны релевантные запросы с сортировкой по дате? Это же ну прям-прям очевидно: я пришел на сайт перепродажи товаров, я с 70-90% вероятности хочу видеть последние предложения по продаже, а не по обслуживанию или услугам, причём самые свежие.
vkrukov Автор
29.11.2018 11:59На раннем этапе мы считали, что обычной фильтрации по ключевым словам и дерева категорий вполне хватает. После того, как мы выросли, стало ясно: то, о чем вы говорите, и добавление релевантности — это не так просто. Но мы справились с этой задачей.
martovskiy
29.11.2018 15:41Баланс между релевантные запросы, сортировка по времени и платными объявлениями (не секрет, мы зарабатываем на платных услугах продвижения) — очень сложен. Мы работаем над этой задачей и есть успехи.
10-30% — это слишком большое количество пользователей. Для уточнения есть категории, а для желающих сортировка по времени.
WooHoo
29.11.2018 11:39Здравствуйте, спасибо за интересную статью. Как вы опреляете что lamborghini это автомобиль а не фирменная игрушка или какой-нибудь ноутбук lambo-edition?
vkrukov Автор
29.11.2018 11:59У нас есть аналитика, на основании которой мы автоматически формируем переход. Туда входят далеко не все случаи жизни, и мы стараемся не допускать неоднозначности. Если такое случится, то пользователю придется сменить категорию и искать в ней, а мы постараемся продетектить это и убрать неоднозначность.
WooHoo
29.11.2018 12:47Я догадываюсь что эта аналитика основана на CTR из результатов поиска. Если это так, то как вы избегаете self feedback loop когда релевантные результаты остаются быть релевантными только потому что предлагаются пользователям первыми?
martovskiy
29.11.2018 16:45Для ранжирования используется не только CTR но и другие источники данных.
Итоговая формула зависит от множества компонентов несколько из которых влияют на разнообразие выдачи. Например влияет свежесть объявления
msdos9
Может не по теме, но спрошу.
У меня иногда из избранного пропадают позиции. Но стоит выбрать там же (в избранном) категорию, тут же невидимки появляются. Ситуация возникает довольно редко, но всё же неприятно.
avitocare
У нас есть неполадка с пропадающими из избранных объявлениями, уже работаем над решением :)