

Поскольку на Хабре после лавины публикаций «N в 30 строк» в 2013-м г. почти не публикуются материалы по программированию, то скажу, что этот материал для домохозяек, желающих научиться программированию, тестировщиков и просто неравнодушных людей.
В современном мире микросервисов господствует API. Но сервисов с каждым днем все больше, а API предоставляют далеко не все. Между тем данные сервисов могут быть весьма важны для анализа, бизнеса,
Посмотрим, как можно распарсить один известный сайт объявлений о продаже/аредне недвижимости максимально эффективно (и быстро), научимся обходить качпу и парсить мобильные приложения.
Внимание. Данный материал не является призывом к действию, носит информационный характер с целью повышения квалификации и увеличения качества работы тестировщиков.
Теория
Парсинг — структурирование данных, если говорить коротко. Если рассматривать классическую схему работы любого сайта, то в любом случае у нас будет хранилище данных (база данных), которое будет иметь структурированный вид. Удобный для машин, но не удобный для человека. Но поскольку сайт должен обслуживать людей, а не машин, данные нужно перевести в удобный для человека вид, но уже не очень удобный для чтения машинами. Схематично это можно изобразить так:
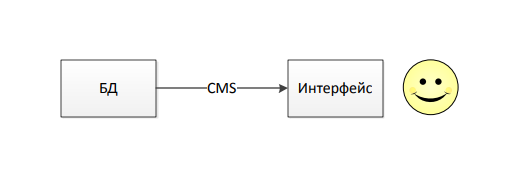
Всё это сферический конь в вакууме, и может быть не очень интересно, пока вдруг Вы не захотите прилично сэкономить, купив квартиру по методу линейной регрессии и Вам понадобятся данные не в няшном виде на сайте, а в конкретной SQL-таблице. А для этого нужно собрать данные.
Парсим на PHP
Итак, мы на коне. У нас есть: страницы сайта с HTML-версткой, в которую примешаны искомые данные. Чтобы вычленить наши данные, можно использовать разные методы, которые ограничиваются только вашей фантазией и функциями PHP для работы со строками, т.к. полученная HTML-страница — всего лишь строка (string):
- Связка mb_strpos и mb_substr будет работать быстрее всего, но съест у Вас большое количество нервов и и далеко не всегда подходит. Я использую этот метод, когда стоимость высокой скорости очень высока, а другие методы не дают нужного результата.
- Функция preg_match и регулярные выражения — мощный инструмент, я всегда начинаю с него. Но потребляемые ресурсы линейно зависят от сложности регулярного выражения. А если представить, что вы пробегаетесь по строке размером 2Мб, становится понятно, одно объявление вытягивается со страницы за 2-3 секунды. В качестве костыля к этому и предыдущему методу можно предварительно уменьшить искомую область. Например, удалить head и footer. С помощью, конечно, mb_strpos.
- А не проще просто оперировать с деревом HTML-документа, при помощи simplexml (или другого extension)? Да, конечно! Или просто пробежаться по HTML как по массиву:
$xml = simplexml_load_string($xmlstring); $json = json_encode($xml); $array = json_decode($json,TRUE);
Хм. Я уже умею кодить на jQuery, можно мне селектировать
phpQuery — для тех кто хочет кодить на jQuery в PHP. И когда при помощи phpQuery вы получите одну строчку в вашей таблице, соответствующую одному объявлению, Вас закружит эйфория, Вы поставите Ваш скрипт парсить весь сайт, а тем временем пойдете в ближайшую пятёрочку покупать шампанское и будете мечтать о маленькой яхточке. Так пройдет ночь.
Суровая реальность
Наутро, придя к монитору, Вы увидите, что в таблице у Вас всего 2 тыс. строк, а скрипт отвалился с ошибкой Allowed Memory Size of… Bytes Exhausted…
Да, phpQuery, хоть и удобная штука, но память утекает. А скорость — самая низкая. Тогда Вам придется отказаться от удобной библиотеки и перейти на preg_match ради стабильности и скорости.
Ещё одни грабли — динамические селекторы. Запустив скрипт на следующий день, Вы поймете, что все классы изменились.
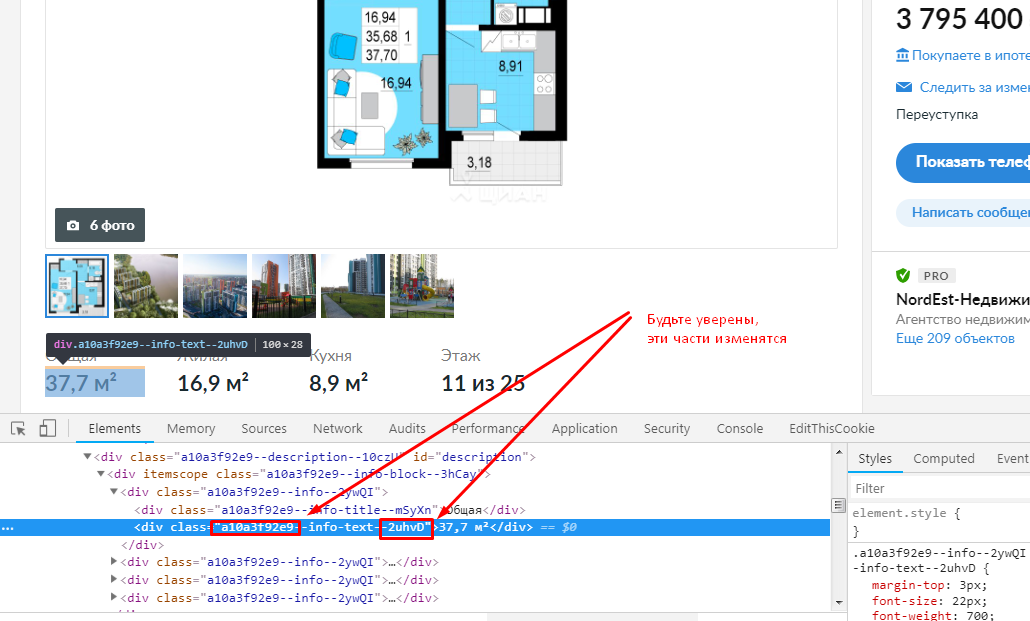
Решение: вообще не привязываться к классам. Ниже пример, как можно вычленить из циановского объявления
$paramsNames = '["Общая","Жилая","Кухня","Этаж","Год постройки","Материалы стен","Этажность","Подъездов","Квартир","Средняя цена за м<sup>2</sup>","Средний возраст домов","Средняя цена за м<sup>2</sup>","Население","Название","Налог на недвижимость"]';
if( preg_match_all( '#<div[^>]*>[^<]*<div[^>]*>[^<]*(' . implode( '|', $paramsNames ) . ')</div>[^<]*<div[^>]*>(.*?)</div>#ius', $html, $matches ) ){
/* ...... */
}
Как видите, структура верстки всегда одна и та же. Поэтому нет смысла вообще привязваться к классам, зацепимся к названиям параметров. И так, Вы опять ставите скрипт на ночь.
Капча
Наутро Вы увидите, что скрипт доработал до конца, но на сайт показывает 50 тыс. объявлений, а у Вас примерно те же 2 тыс.

Так выглядит капча ЦИАН
С капчей можно было бы посоревноваться при помощи ruCaptcha. Но только не в случае с reCaptcha. Бросьте эту идею, она провальна. Весь наш метод прямых HTTP-запросов из PHP уперся в тупик.
Есть выход
Выход заключается в том, что мы не будем делать GET-запросы прямо из PHP, а запустим браузер, и через PHP заставим его открывать нужные страницы и читать их содержимое. Когда вылетит капча, мы просто её пройдем, и будем парситься дальше. Рассмотрим технологии, которые нам понадобятся.
Selenium Webdriver — позволяет запускать браузер и управлять им по API (ссылка). Это инструмент тестировщиков, но мы ведь и тестируем, не правда ли? Обычно тестировщики используют Java. Но нам зачем эти танцы, если есть
php-webdriver — инструмент от Facebook (спасибо, Цукерберг!), предоставляющий SDK на PHP для Selenium webdriver.
Вот как мы откроем главную страницу ЦИАН и нажмем на кнопку «Найти»
# используем хром как рабочую лошадку
$capabilities = DesiredCapabilities::chrome();
$capabilities->setCapability(ChromeOptions::CAPABILITY, $options);
$driver = RemoteWebDriver::create('192.168.1...:4444/wd/hub', $capabilities, 5000);
$driver->manage()->timeouts()->implicitlyWait(10);
# открываем сессию и сразу открываем страницу
$remote = $driver->get('https://cian.ru/');
# ищем по CSS-селектору. Да, это почти что jQuery
$remote->findElement(WebdriverBy::cssSelector('.c-filters-field-button___1EBB-'))->click();
В примере я просто вставил динамический CSS-селектор. Но так делать нельзя, нужно сначала узнать класс у кнопки «Найти», предварительно получив все содержимое в HTML, потом программно подставить. Получить содержимое страницы из Selenium можно так:
$content = $remote->findElement(WebdriverBy::cssSelector('body'))->getAttribute('innerHTML');И вот, Вы один раз ввели капчу, наслаждаетесь потоком приятных строк, наполняющих Вашу таблицу, параллельно тестируя ЦИАН. Вам нравится процесс, хотя он идет и не очень быстро, но главное — идет! И Вы уходите спать.
Грабли
А наутро приходите, и обнаруживаете, что парсинг закончился, а в таблице стало чуть больше объявлений. Всего 3 тыс. Скрипт не может вызвать Selenium (не достучаться). Что происходит?!
А вот что.
Открывая страницу через $driver->get, Вы заполняете location history у браузера. Открывая следующую в текущей сессии, предыдущая из памяти не стирается. И браузер просто пухнет в оперативной памяти, пока не произойдет коллапс. Выход — прерывать сессию через $driver->close. Но тогда можно опять нарваться на капчу…
А что если...
И так до бесконечности. Скорость очень низкая, Selenium чересчур, постоянные срывы парсинга… Нужно искать что-то другое. Да, у сервиса
Прослушивать трафик, чтобы протестировать мобильное приложение, можно, но
Так выглядит интерфейс приложения одного из
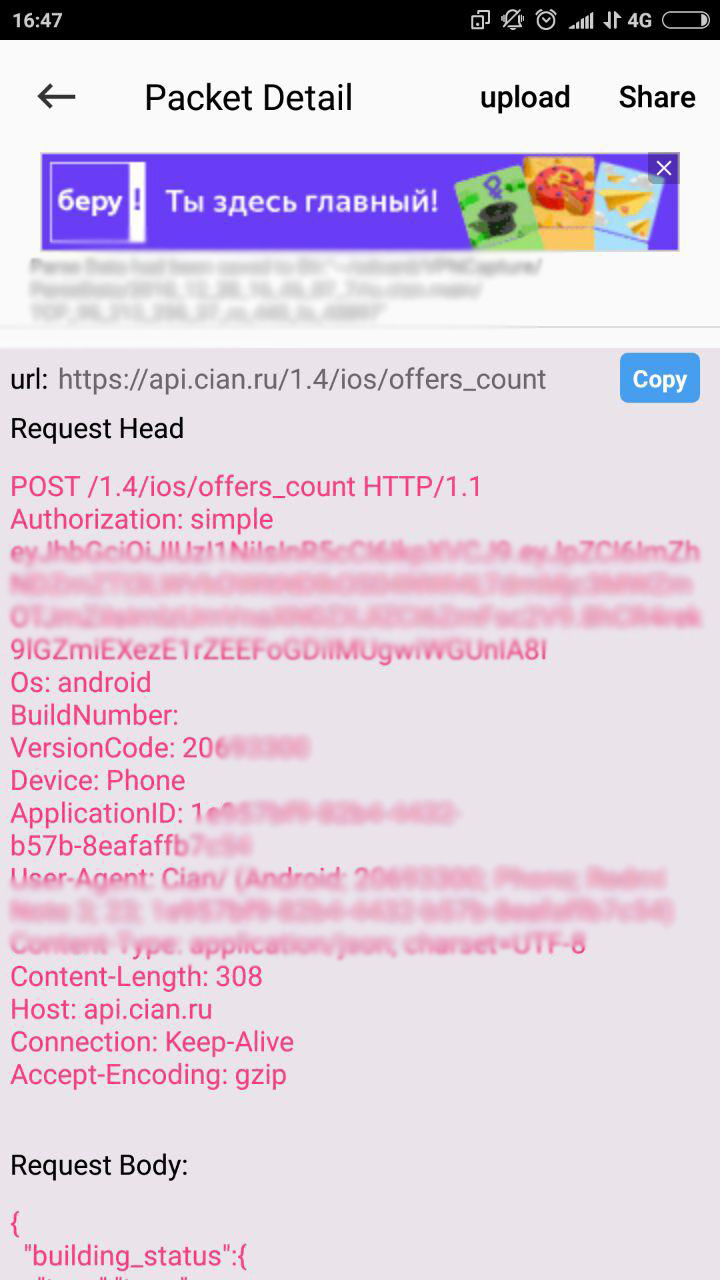
Так выглядит запрос на получение общего количества объявлений. Да-да, это на Android.
Для того, чтобы распарсить весь тестируемый сайт (сервис), нужен всего-лишь один метод API. Вот он: api.cian.ru/offers/v1/search-offers-for-mobile-apps
И в завершение прикреплю функцию (код), при помощи которой Вы сможете уже через час получить весь массив данных. Никаких (!!!) ограничений на запросы к мобильному API нет.
$request = [
'query' => [
'engine_version' => [
'type' => 'term',
'value' => '2'
],
'limit' => [
'type' => 'term',
'value' => 50
],
'object_type' => [
'type' => 'terms',
'value' => [0]
],
'page' => [
'type' => 'term',
'value' => $page
],
'_type' => 'flatsale'
]
];
$body = json_encode( $request );
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://api.cian.ru/offers/v1/search-offers-for-mobile-apps/?new_schema=1&multioffer_version=3" );
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1 );
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt($ch, CURLOPT_POST, 1 );
curl_setopt($ch, CURLOPT_HEADER, 0 );
curl_setopt($ch,CURLOPT_ENCODING , "gzip");
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Authorization: simple ....',
'Os: android',
'BuildNumber: ',
'VersionCode: 20630300',
'Device: Phone',
'ApplicationID: ....',
'User-Agent: Cian/ (Android; ....; Phone; ....)',
'Content-Type: application/json; charset=UTF-8',
'Content-Length: ' . mb_strlen($body),
// 'Host: api.cian.ru',
'Connection: Keep-Alive',
'Accept-Encoding: gzip',
]);
curl_setopt($ch, CURLOPT_POSTFIELDS, $body );
$result=json_decode( curl_exec ($ch), true );
Вместо точек нужно подставить свои данные авторизации. После этого в $result['data']['offers'] будет абсолютно вся информация по каждому объявлению в списке.
Если у Вас есть критические замечания по данному материалу, просьба написать в ЛС. Так же я всегда открыт к предложениям.
Используемые инструменты:
phpQuery
Selenium Webdriver
php-webdriver
Oracle VirtualBox
Комментарии (22)

php_freelancer
28.12.2018 21:45+1Зачем писать парсер на PHP? Я разрабатываю на PHP, но парсеры пишу для самых сложных сайтов, даже с Client Side Rendering на PhantomJS -> CasperJS, что в 10000 раз компактнее, удобнее, стабильнее.
LazyTalent
28.12.2018 23:49+2Если не секрет, то почему именно PhantomJS? Он же
мёртвне поддерживается уже больше, чем пол года.

rudinandrey
29.12.2018 08:50Есть еще Simple HTML Dom для PHP библиотека для парсинга, мне она больше нравится чем phpQuery.
Rukis
30.12.2018 19:28+1А я посоветую github.com/Imangazaliev/DiDOM есть сравнение с другими в том числе с Simple HTML Dom: github.com/Imangazaliev/DiDOM/wiki/Comparison-with-other-parsers-(1.0)
spy45242
29.12.2018 10:53Занимательно! И способ с парсингом сайта с динамическими селекторами в статье мне понравился, тоже об этом думал, но никак не доходили руки попробовать. Но! Это что касаемо классов. Вы используете регулярку типа '#<div[^>]*>[^<]*<div[^>]*>[^<]*('. Как насчет динамического контента, к примеру когда на сайте части контента разделены тегом , а через минуту уже тегом
с динамическим классом? То есть меняються не только классы, но и теги и их вложенность.
qravits Автор
29.12.2018 11:01Такое, скорее всего, не встретится. Чтобы защитить сайт от парсинга, достаточно передавать «пустую» верстку, данные подставлять через javascript, который, конечно, обфусцировать, хотя, всякое может быть. Если энтропию и в DOM добавили, то уже не зацепишься.
spy45242
29.12.2018 12:54Ну даже, если данные подставлять через js, тому же PhantomJS как бы всё равно, через что данные подставляются. Не знаю, может быть мне так «везет», но я встречал ресурсы, где к примеру в теге «div» лежит часть контента, а после перезагрузки страницы эта часть лежит уже в теге «р» и у регулярки, которая работала с «div» на этом, как говориться, полномочия уже всё…
iit
29.12.2018 13:50А почему не DomCrawler?
Как по мне — одна из самых шустрых и надежных библиотек а если еще использовать css-selector то парсинг становится даже приятным.
riky
30.12.2018 19:08+1использую и DomCrawler и phpQuery. второй есть сборка в одном файле — удобно когда надо спарсить чтото совсем маленькое по-быстрому, проинклюдил и поехал. композер конечно тоже не сложно, но на практике так быстрее.
к тому же обе библиотеки обертки над DomDocument и разрешают прямой доступ к DomElement. да и главное там css селекторы которые плюс минус одинаковые.
Если делаю более менее серьезный проект — то использую DomCrawler.
RuCaptcha
30.12.2018 19:27+1Добрый день.
Зарегистрировались дабы указать на неточность при упоминании нашего сервиса.
С капчей можно было бы посоревноваться при помощи ruCaptcha. Но только не в случае с reCaptcha. Бросьте эту идею, она провальна. Весь наш метод прямых HTTP-запросов из PHP уперся в тупик.
Это не так.
Мы успешно работаем по методу передачи токена от решённой ReCaptcha. Вам ну нужно эмулировать браузер, Вы продолжаете общаться с любым сайтом посредством HTTP-запросов.
Всё дело в том, как работает ReCaptcha:
у пользователя она появляется во фрейме, загружаясь с google.com. После решения рекапчи, пользователь получает текстовую строку (g-recaptcha-responce), эту текстовую строку браузер пользователя отправляет вместе с остальными данными формы сайту, на котором и установлена капча. Сайт обращается к google.com с проверкой валидности g-recaptcha-responce от пользователя. Google.com поддтверждает (или нет), что токен валидный.
Фишка в том, что RuCaptcha умеет вызывать в софте работника рекапчу со всеми нужными параметрами, а потом отдаёт Вам, как клиенту, g-recaptcha-responce, который Вы в свою очередь используете при обращении к сайту. Таким образом обходится ReCaptcha (V2 и V3 тоже).
На нашем сайте вы можете ознакомиться с более подробным объяснением (ссылку давать не буду, а то модератор порежет комментарий от свежего пользователя)qravits Автор
30.12.2018 19:36+1Спасибо, что зарегистрировались здесь! Да, я видел, что у вас анонсирован обход reCaptcha v.3.
Конечно, не стоит надеяться, что кто-то будет палить инсайд, но вкратце, было бы интересно узнать какой путь вы прошли, выстраивая архитектуру и обучая нейронную сеть.
guyasyou
30.12.2018 19:28+1Скажу по секрету — в циане есть JS, в которой все нужные данные, и даже больше, аккуратно упакованы в JSON. И это не единственный сайт, который защищается от парсинга в HTML и при этом выкладывает все в json.
Rastishka
30.12.2018 19:36+1Да, phpQuery, хоть и удобная штука, но память утекает.
Неправда. Если очищать — ничего не утекает.
Проверено на сотнях тысяч страниц.
Вы документацию читали?
a-tk
30.12.2018 21:07Картинка в начале статьи вполне соответствует впечатлениям от беглого её просмотра
SDKiller
А это материал по программированию, которого хабр ждал с 2013 года?
KorP
Там же дальше сказано
Правда не понятно, что это за домохозяйки такие со знанием PHP и зачем им вообще циан парсить :)
OnYourLips
А кому еще кроме домохозяек придется парсить таким способом?
Лично я бы, если бы передо мной стояла такая задача, использовал очереди, а в случаях требования высокой производительности — очереди и асинхронный ввод-вывод. Но этого в статье просто нет, а организация флоу парсинга на мой взгляд более сложная тема, чем выбор способа разбора.