

Вместо того, чтобы бушевать в комментариях, подумайте: а нужен ли вам REST вообще?
Что это — осознанный выбор или привычка?
Возможно, именно вашему проекту RPC-like API подойдет лучше?
Итак, что такое JSON-RPC 2.0?
Это простой stateless-протокол для создания API в стиле RPC (Remote Procedure Call).
Выглядит это обычно следующим образом.
У вас на сервере есть один единственный endpoint, который принимает запросы с телом вида:
{"jsonrpc": "2.0", "method": "post.like", "params": {"post": "12345"}, "id": 1}И отдает ответы вида:
{"jsonrpc": "2.0", "result": {"likes": 123}, "id": 1}Если возникает ошибка — ответ об ошибке:
{"jsonrpc": "2.0", "error": {"code": 666, "message": "Post not found"}, "id": "1"}И это всё!
Бонусом поддерживаются batch-операции:
Request:
[
{"jsonrpc":"2.0","method":"server.shutdown","params":{"server":"42"},"id":1},
{"jsonrpc":"2.0","method":"server.remove","params":{"server":"24"},"id":2}
]
Response:
[
{"jsonrpc":"2.0","result":{"status":"down"},"id":1}
{"jsonrpc":"2.0","error":{"code":1234,"message":"Server not found"},"id": 2}
]
В поле
id клиент API может отправлять что угодно, дабы после получения ответов от сервера сопоставить их с запросами.Также клиент может отправлять «нотификации» — запросы без поля «id», которые не требуют ответа от сервера:
{"jsonrpc":"2.0","method":"analytics:trackView","params":{"type": "post", "id":"123"}},
Библиотеки для клиента и сервера есть, наверное, под все популярные языки.
Если нет — не беда. Протокол настолько простой, что написать свою реализацию займет пару часов.
Работа с RPC-клиентом, который мне первым попался на npmjs.com, выглядит так:
client.request('add', [1, 1], function(err, response) {
if (err) throw err;
console.log(response.result); // 2
});
Профиты
Согласованность с бизнес-логикой проекта
Во-первых, можно не прятать сложные операции за скудным набором HTTP-глаголов и избыточными URI.
Есть предметные области, где операций в API должно быть больше чем сущностей.
Навскидку — проекты с непростыми бизнес-процессами, gamedev, мессенджеры и подобные realtime-штуки.
Да даже взять контентный проект вроде Хабра…
Нажатие кнопки "^" под постом — это не изменение ресурса, а вызов целой цепочки событий, вплоть до выдачи автору поста значков или инвайтов.
Так стоит ли маскировать
post.like(id) за PUT /posts/{id}/likes?Здесь также стоит упомянуть CQRS, с которым RPC-шный API будет смотреться лучше.
Во-вторых, кодов ответа в HTTP всегда меньше, чем типов ошибок бизнес-логики, которые вы бы хотели возвращать на клиент.
Кто-то всегда возвращает 200-ку, кто-то ломает голову, пытаясь сопоставить ошибки с HTTP-кодами.
В JSON-RPC весь диапазон integer — ваш.
JSON-RPC — стандарт, а не набор рекомендаций
Очень простой стандарт.
| Данные запроса могут быть: | |
|---|---|
| REST | RPC |
| В URI запроса | --- |
| В GET-параметрах | --- |
| В HTTP-заголовках | --- |
| В теле запроса | В теле запроса |
| Данные ответа могут быть: | |
|---|---|
| REST | RPC |
| В HTTP-коде ответа | --- |
| В HTTP-заголовках | --- |
| В теле ответа (формат не стандартизирован) | В теле ответа (формат стандартизирован) |
POST /server/{id}/status или PATCH /server/{id}?Это больше не имеет значения. Остается
POST /api.Нет никаких best practices с форумов, есть стандарт.
Нет разногласий в команде, есть стандарт.
Конечно же, качественно реализованный REST API можно полностью задокументировать. Однако…
Знаете, что и где нужно передать в запросе к Github API, чтобы получить объект reactions вместе с issue?
Accept: application/vnd.github.squirrel-girl-previewНезависимость от HTTP
В теории, принципы REST можно применять не только для API поверх HTTP.
На практике все по-другому.
JSON-RPC over HTTP безболезненно переносится на JSON-RPC over Websocket. Да хоть TCP.
Тело JSON-RPC запроса можно прямо в сыром виде бросить в очередь, чтобы обработать позже.
Больше нет проблем от размазывания бизнес-логики по транспортному уровню (HTTP).
| HTTP 404 | |
|---|---|
| REST | RPC |
| Ресурса с таким идентификатором нет | --- |
| Здесь API нет | Здесь API нет |
Производительность
JSON-RPC пригодится, если у вас есть:
— Batch-запросы
— Нотификации, которые можно обрабатывать асинхронно
— Вебсокеты
Не то, чтобы это все нельзя было сделать без JSON-RPC. Но с ним — чуть легче.
Подводные камни
HTTP-кеширование
Если вы собираетесь кешировать ответы вашего API на уровне HTTP — RPC может не подойти.
Обычно это бывает, если у вас публичное, преимущественно read-only API.
Что-то вроде получения прогноза погоды или курса валют.
Если ваше API более «динамичное» и предназначено для «внутреннего» использования — все ок.
access.log
Все запросы к JSON-RPC API в логах веб-сервера выглядят одинаково.
Решается логированием на уровне приложения.
Документирование
Для JSON-RPC нет инструмента уровня swagger.io.
Подойдет apidocjs.com, но он гораздо скромнее.
Впрочем, документировать такой простой API можно хоть в markdown-файле.
Stateless
«REST»? — об архитектуре, а не глаголах? HTTP — возразите вы. И будете правы.
В оригинальной диссертации Роя Филдинга не указано, какие именно глаголы, заголовки и коды HTTP нужно использовать.
Зато в ней есть волшебное слово, которое пригодится даже при проектировании RPC API. «Stateless».
Каждый запрос клиента к серверу должен содержать всю информацию, необходимую для выполнения этого запроса, без хранения какого-либо контекста на стороне сервера. Состояние сеанса целиком хранится на стороне клиента.Делая RPC API поверх веб-сокетов, может возникнуть соблазн заставить сервер приложения хранить чуть больше данных о сессии клиента, чем нужно.
Насколько stateless должен быть API, чтобы не причинять проблем? Для контраста вспомним по-настоящему statefull протокол? — ?FTP.
Клиент: [открывает TCP-соединение]
Сервер: 220 ProFTPD 1.3.1 Server (ProFTPD)
Клиент: USER anonymous
Сервер: 331 Anonymous login ok, send complete email address as your password
Клиент: PASS user@example.com
Сервер: 230 Anonymous access granted, restrictions apply
Клиент: CWD posts/latest
Сервер: 250 CWD command successful
Клиент: RETR rest_api.txt
Сервер: 150 Opening ASCII mode data connection for rest_api.txt (4321 bytes)
Сервер: 226 Transfer complete
Клиент: QUIT
Сервер: 221 Goodbye.
Состояние сеанса хранится на сервере. FTP-сервер помнит, что клиент уже прошел аутентификацию в начале сеанса, и помнит, в каком каталоге сейчас «находится» этот клиент.
Такой API сложно разрабатывать, дебажить и масштабировать. Не делайте так.
В итоге
Возьмите JSON-RPC 2.0, если решитесь сделать RPC API поверх HTTP или веб-сокетов.
Можете, конечно, придумать свой велосипед, но зачем?
Возьмите GraphQL, если он правда вам нужен.
Возьмите gRPC или что-то подобное для коммуникации между (микро)сервисами, если ваш ЯП это поддерживает.
Возьмите REST, если нужен именно он. Теперь вы, по крайней мере, выберете его осознанно.
Комментарии (237)

powerman
27.02.2019 03:39Стоит добавить, что JSON RPC 2.0 — это транспорто-независимый протокол. Т.е. как именно клиент передаст запрос серверу — никем не регулируется, можно хоть в файл
/tmp/request.jsonего записать, а ответ считать из созданного сервером файла/tmp/response.json. Можно передавать по TCP as is (хотя нередко используют в качестве разделителя запросов/ответов\nесли неудобно использовать потоковые парсеры JSON). Удобно передавать отдельными сообщениями WebSocket. Что касается самого распространённого случая — HTTP — то поскольку есть множество способов передать кусок JSON через HTTP то был дополнительно написан стандарт JSON-RPC 2.0 Transport: HTTP, и обычно все клиенты/сервера JSON RPC 2.0 использующие в качестве транспорта HTTP пишутся в соответствии с ним.
ZaEzzz
27.02.2019 07:35Yet another standart, или еще один способ отказаться от простых и понятных систем мониторинга.
Меня это постоянно удивляет. Если уж используется HTTP для транспорта, то почему он используется специально целенаправленно в обрезанном виде? Invalid Request с ответом 200.powerman
27.02.2019 08:31+2Потому что как транспорт — он свою задачу выполнил корректно, поэтому и 200. Попытка для ошибок подобрать какой-то другой код обречена на неудачу в любом случае, по причине того, что в RPC возможных кодов и типов ошибок намного больше, чем в HTTP, и они разные в каждом сервисе. Плюс есть batch-ответы, в которых возвращается массив обычных ответов, часть из которых может быть ошибками. Ну и вообще смешивать уровень транспорта и приложения без веской причины плохая идея. По сумме всех этих факторов получается, что если возвращать что-то помимо 200 то это создаст больше проблем, чем решит.
Что до мониторинга, то RPC-сервисы обычно реализуют более сложные операции (по сравнению с настоящим REST), и для их мониторинга 200/400/500 всё-равно не хватит, поэтому мониторинг таких сервисов обычно реализуется через их собственные метрики уровня приложения, собираемые prometheus.
ZaEzzz
27.02.2019 08:53Я не говорю, что надо для одних ошибок использовать HTTP коды, а для других писать в JSON.
Я говорю о том, что не нужно отказываться от HTTP кодов из-за мониторинга.
В мониторинге сразу будет видно, что пошел шквал 403 или 404, к примеру. Травить монитор на json так же надо, но я все равно честно не понимаю зачем отказываться еще от одного стэка мониторов и анализаторов. При чем отказываться целенаправленно.
rsvasilyev Автор
27.02.2019 09:13В одном ответе от RPC-сервера может быть несколько разных ошибок.
Например, "Access Denied" + "Method Not Found". А HTTP-код у нас только один.ZaEzzz
27.02.2019 10:07Да. Для пакетных операций надо хорошенько подумать. Согласен.
А если не на пакетную операцию возвращается несколько кодов, но я бы хорошо подумал над другими вопросами.
multiadmin
27.02.2019 11:22-2Может, просто зря «пакетирование» затащили на этот уровень протокола?
Сделали бы отдельный слой для пакетирования.
Nexen2
27.02.2019 21:16+1А еще в одном ответе на запрос «лайкнуть» может быть сразу несколько ошибок по сущностям, ведь мы можем обновить / создать несколько сущностей. А если не возвращать эти ошибки, а только отвечать «не удалось» в силу, например, секуьюрности, то на кой нам тогда вообще тут REST, как сущность-ориентированный подход? RPC в руки любого типа и вперед. можно и JSON-RPC. Я видел как люди через ПХП с сеть строили сервисы с бинарными протоколами, после этого любое решение кажется вменяемым)))

funca
27.02.2019 22:44В переложении на REST может быть не сразу очевидно. Вот классная статья по теме How to GET a Cup of Coffee. Если нужны согласованные изменения, создавайте транзакци, например используя Two-phase commit protocol .
dimkrayan
27.02.2019 19:41справедливости ради, даже когда возвращается не-2хх — транспорт свою работу все равно выполнил корректно.
powerman
27.02.2019 19:48В случае JSON RPC 2.0 — нет. Случаи не 2xx — это случаи когда транспорт свою работу не выполнил — переданный клиентом кусок JSON не был доставлен RPC-сервису.
А в случае REST — большинство не 2xx действительно не ошибки транспорта (ошибками транспорта являются обычно 502/503/504).
dimkrayan
27.02.2019 19:53в таком случае вы считаете http транспортом между rpc-сервисами?
Мне кажется, вы наделили не свойственной ему ролью.powerman
27.02.2019 20:01+1Я не "считаю" его транспортом, я (и не только я) вполне осознанно использую очень богатый и функциональный протокол HTTP в качестве тупого транспорта, игнорируя практически все его возможности. :)
dimkrayan
27.02.2019 20:26вы не поняли. http — это транспорт гипертекста. Букв. Конкретно rpc-сервис — штука более специфичная. У него другие состояния, другие возможные ошибки. Если http — тупо транспорт — не-2хх — это не ошибки транспорта. А если это транспорт rpc-сервиса, а не просто букв — вот тут и появляется несвойственная ему роль.
powerman
27.02.2019 20:47В этом случае HTTP не используется как "транспорт RPC", он используется как "транспорт чёрного ящика в формате JSON, в режиме запрос-ответ".
bat
27.02.2019 09:58+1Yet another standart, или еще один способ отказаться от простых и понятных систем мониторинга.
Меня это постоянно удивляет. Если уж используется HTTP для транспорта, то почему он используется специально целенаправленно в обрезанном виде? Invalid Request с ответом 200.
потому что HTTP для jsonrpc yet another transportZaEzzz
27.02.2019 10:09Дак если HTTP и так используется, то почему бы его возможности так же не учесть?
VolCh
27.02.2019 10:34Простые и понятные системы мониторинга продолжат работать, мониторя, например, обращения не к ендпоинту, обращения с «левыми» content-type, падения апп-сервера и прочее, что относится к http.
yayashitoya
27.02.2019 11:39Если уж используется HTTP для транспорта, то почему он используется специально целенаправленно в обрезанном виде? Invalid Request с ответом 200
Если мы говорим о веб-браузерах, то некоторые коды ошибок они, заразы, обрабатывают самостоятельно, просто не допуская до них наше прикладное ПО.
Я бы не стал полагаться на разнообразие кодов ошибок HTTP, за небольшим исключением.
riky
27.02.2019 13:11если отвязаться от передачи информации через сам протокол (http error codes), то в дальнейшем будет легко перейти на вебсокеты.
mwizard
27.02.2019 03:42-1Лучше всего с CQRS работает GraphQL. Фактически, он под него и моделировался.

Stas911
27.02.2019 05:21На старой работе я пилил все сервисы на JSON-RPC, а потом пришел новый чувак, у которого его свежий PhD давил на мозг, и просто измучал меня тем, что я не делаю все по канонам REST и его пророков.
artX89
27.02.2019 11:38-1У меня такое ощущение, что этот чувак пришел к тебе из моей организации. Сколько я всего наслушался, возвращая код 200 с телом error.
dzsysop
27.02.2019 17:17А можно узнать почему вас заставляли возвращать 200? Какая была аргументация если есть довольно большой диапазон 4хх и 5хх и прочие? Чем аргументировали те кто продавливал такую имплементацию?

igordata
27.02.2019 17:27+1Ну например тем, что запрос отработал и штатно возвращает ответ. То, что в ответе ошибка — это уже дело программы, а не протокола. Эта же тема обсуждается выше в начале комментариев.
artX89
27.02.2019 17:46+9Аргументация в данном случае простая и ее уже писали выше: «Потому что как транспорт — он свою задачу выполнил корректно, поэтому и 200». Если мы пытаемся отправить запрос по адресу «site.com/api/v1», а такой адрес отсутствует, то тогда возвращаем 404, или нет доступа – 403, возможно сервер упал в момент обработки и не смог сформировать ответ – 500. Но если сервер получил запрос и, исходя из бизнес-логики, решил что он ошибочный (например: объект не найден), то в таком случае я считаю правильно ответить кодом 200, а вот уже в JSON-ответе в поле «error» указать код и описание ошибки.

Kwisatz
27.02.2019 18:27+4Согласен с вами.
На самом деле раздражает очень сильно меня REST уже. Я работал с довольно большим количеством различных API и меня от натягивния совы на глобус уже начинает подташнивать:
— Внезапно, появляющиеся ошибки в теле ответа, в некоторых местах (причем в документации ни слова)
— Натягивание HTTP кодов на совершенно не подходящие им случаи
— GET для получения информации (который очень меня веселит когда у ребят ограничение длинны URL)
— Путаница с PATCH/POST/PUT прям в пределах проекта.
— Возврат 500, когда на самом деле 400 (как приятно это отлаживать)
— Возврат 500/400, когда на самом деле 413 (как приятно экспериментально вычислять...)
— Мое любимое: возврат 4xx/5xx без дополнительной информации но при этом частично выполнить запрос.
Я может сильно не прав, но вроде как, всякие клевые штуки должны упрощать всем жизнь а не усложнять.asavin
27.02.2019 18:39Кажется, весомая часть ваших претензий не к REST как таковому, а к отсутствию стандарта. Тогда как для REST есть, например, JSON:API https://jsonapi.org/ У этой спецификации, безусловно, есть недостатки, но при использовании проблемы вроде "возврат 4xx/5xx без дополнительной информации но при этом частично выполнить запрос" уже актуальны не будут.
Kwisatz
27.02.2019 19:33+1Я не понимаю зачем нужно натягивать одно на другое?
Ну нужно вернуть ошибку ну пусть будет ERR_CONTENT_TOO_LARGE.
А когда прилетает некая 4xx и ты сидишь и думаешь, это я накосячил в запросе, сервак отлуп по размеру дает или приложение не справляется с таким пакетом? Очень здорово, особенно учитывая всякие прикольные сервисы, вот например концовка запроса одного из: "]]]]}"
Отдельную кстати боль доставляют любители выносить параметры в заголовки, особенно доставляет когда это указано где нить в общем разделе в духе «Если вам нужны только обновленные данные используйте if-modified-since».
windymindy
27.02.2019 22:23В чем принципиальная разница между JSON:API и JSON:RPC?
powerman
28.02.2019 00:23"JSON:RPC" не существует. Есть конкретный протокол "JSON-RPC 1.0" (устаревший и почти не использующийся) и конкретный протокол "JSON-RPC 2.0" (текущий, обычно говоря о "JSON RPC" имеют в виду именно его, но не обязательно — иногда речь о своей кустарной реализации RPC с использованием JSON для запросов/ответов).
"JSON:API" это тоже конкретный протокол. Не уверен насчёт его природы на 100% (я его смотрел поверхностно), но по-моему он намного ближе к REST/GraphQL, и полноценным RPC не является. Начинался он как REST-адаптер для фреймворка Ember.js, который потом решили попытаться отвязать от Ember.js и превратить в стандарт. На данный момент, по моему личному мнению, преимуществ перед JSON-RPC/REST/GraphQL у него нет, если только мы не пишем проект на Ember.js, а вот неприятные проблемы присутствуют (почитайте его форум).
Плюс к этому "JSON API" часто называют кустарные варианты API с передачей запросов/ответов в JSON — они могут быть по природе похожи на REST, могут быть похожи на RPC, могут быть вообще чем угодно.

trawl
28.02.2019 06:10На данный момент, по моему личному мнению, преимуществ перед JSON-RPC/REST/GraphQL у него нет
Преимущества JSON:API перед JSON-RPC те же самые, что и у REST перед JSON-RPC (как и недостатки)
Преимущества перед REST:
- стандартизация некоторых холиварных моментов (таких, как пагинация, HTTP-статусы ответов в большинстве случаев)
- возможность выборки только нужных полей сущности
- возможность получить только нужные связанные данные
Преимущества перед GraphQL:
- отсутствие повторяющихся данных (если мы выбираем N статей с их авторами, в GraphQL для каждой статьи продублируется автор, даже если он один, а JSON:API вернет только уникальных авторов)
mayorovp
27.02.2019 20:39Один и тот же код ошибки может означать совершенно разные вещи. При не очень аккуратной настройке веб-сервера можно получить почти любой код ошибки при любом запросе — а потому кодам ошибок тяжело доверять.
Так, 403 может означать как ошибку авторизации, так и ошибку в адресе. А ещё 403 может означать что сервис временно недоступен и надо повторить запрос позже.
Код 401 может означать как необходимость передать токен — так и ошибку в адресе или что сервис недоступен и нужно повторить запрос позже.
Код 404 может означать некорректный id, ошибку в адресе или недоступность сервиса.
Код 405 может означать как ошибку в алгоритме — так и ошибку в адресе или недоступность сервиса.
Код 418 может означать что угодно (кроме ошибки в адресе или недоступности сервиса).
Коды 502 или 504 могут означить что угодно, включая ошибку в адресе или недоступность сервиса.
Код 503 может означать временную недоступность сервиса… или ошибку в адресе.
robert_ayrapetyan
27.02.2019 06:06Есть один маленький ньюанс — с сессиями в куках (и вообще чем угодно в куках). Тут тоже можно вдоволь похоливарить. По-идее, канонично будет не использовать HTTP-заголовки. Но в этом случае нужно хранить состояние на клиенте и явно передавать с каждым запросом.
BerkutEagle
27.02.2019 06:47+1По моему, авторизация — задача не бизнеслогики, отвечающей на запрос. Авторизация должна быть между веб-сервером и сервером БЛ. HTTP-заголовки, сессии, токены никто не отменял. Это и в стандарте JSON-RPC 2.0 Transport: HTTP упомянуто.
robert_ayrapetyan
27.02.2019 08:24Простите, но ссылка на proposal\draft на домене simple-is-better никак не тянет на стандарт, оригинал если что тут: www.jsonrpc.org/specification, и там ни слова про заголовки и токены (что ожидаемо, ведь JSON-RPC не должен зависеть от сторонних протоколов и быть максимально переносим).
Про авторизацию в корне не согласен, она является частью именно бизнес-логики приложения, не очень понятно что вы имели ввиду говоря «должна быть между веб-сервером и сервером БЛ».powerman
27.02.2019 08:40Альтернативы ей нет, все кто активно используют JSON RPC 2.0 про неё знают, поэтому хоть у неё и нет официального статуса де-юре, но де-факто это стандарт.
Авторизацию/токены обычно передают отдельным первым параметром (в нём так же удобно передавать дополнительные данные для трассировки запросов, отладки, в общем — контекст запроса) во все RPC-методы, т.е. на уровне HTTP не используются ни заголовки ни куки. Но, да, если на уровне приложения авторизации нет, то можно прикрыть весь сервис на уровне стоящего перед ним nginx и проверять заголовок
Authorization:, спека это не запрещает.
mayorovp
27.02.2019 09:06В стандарте JSON-RPC ничего подобного и не должно быть упомянуто, поскольку это просто не тот уровень стека протоколов.
BerkutEagle
27.02.2019 09:23Про «стандарт» это я дал маху, согласен. С другой стороны стандарт — дело личное, можно за стандарт для себя/для компании принять то, что на заборе написано.
Про авторизацию: метод, обрабатывающий JSON-RPC запрос — это функция, которая принимает на вход то, что пришло в поле «params» и возвращает ответ — это бизнес-логика.
Позволить выполнить функцию или нет — задача системы авторизации. Она может быть реализована декоратором функции/класса или веб-прокси или ещё кучей других способов.
mayorovp
27.02.2019 09:11«Простой POST-запрос авторизованным юзером» нужно обязательно защищать анти-CSRF токеном, иначе это будет дырка в безопасности. А наличие такого токена, в свою очередь, сделает использование API не из браузера не таким простым как хотелось бы.
powerman
27.02.2019 17:03+1Защита от CSRF для JSON RPC 2.0 обычно не нужна — потому что куки не используются, авторизация реализована через передачу отдельного параметра с токеном, который стороннему сайту взять негде. В качестве вишенки API зачастую не публичный, открыт только для нашего сайта, а спека требует передать
Content-Type: application/json, который не является simple header и активирует CORS, что дополнительно расширяет возможности сервера по фильтрации левых запросов (напр. если для авторизации используется заголовокAuthorization:, но это редкость).mayorovp
27.02.2019 17:06-1Так я о том и говорю! Куки обычно не используются — именно по названным мною причинам.
powerman
27.02.2019 17:32+2Нет, куки не используются потому, что проверкой аутентификации и авторизации обычно в RPC занимается слой бизнес-логики (точнее, обёртка перед ним, но это не важно — она всё-равно находится внутри RPC-сервера). А это значит, что все необходимые для проверки данные (токен) они должны получить вместе с методом и параметрами RPC. Информация с транспортного уровня (HTTP) в этот момент обычно недоступна (если совсем-совсем честно, то обычно приходится изворачиваться, чтобы дать доступ к одному значению с транспортного уровня: IP клиента, для защиты от DoS). Более того, JSON RPC 2.0 не просто "формально" независим от транспорта, он и на практике часто передаётся по TCP или WebSocket, где никаких кук нет. В общем, куки не используются не ради защиты от CSRF, а потому, что они вообще никак в JSON RPC 2.0 не лепятся.
robert_ayrapetyan
27.02.2019 19:37«Информация с транспортного уровня (HTTP)» — это в какой модели он вдруг транспортный?
powerman
27.02.2019 19:44Для JSON RPC 2.0 — он вполне себе транспортный. Потому что всё, что от него требуется — доставить кусок JSON туда и обратно. Никакие особенности HTTP при этом не нужны и не используются (в отличие от того же REST), никакие метаданные к этому куску JSON не прилагаются, etc. — стандарт рекомендует использовать конкретные методы (
POST) и заголовки (Accept/Content-Type: application/json) исключительно ради интеоперабельности с существующими HTTP-сервисами вроде прокси, самому JSON RPC 2.0 всё это не нужно.

evnp
27.02.2019 06:15В примерах к apidocjs только REST однако
BerkutEagle
27.02.2019 06:56А вот это да. Инструментов для описания и документирования API на базе JSON-RPC похоже нет. Он слишком стар для всего этого. Когда начался подъём популярности JS, REST захватил умы большинства, и инструменты пишут для него. Сейчас ещё GraphQL добавился. А JSON-RPC несправедливо забыт.
Возможно и не нужно дополнительных инструментов. Ендпойнт один (какой-нибудь example.com/api/), запросы всегда POST (если следовать стандарту). Нужно лишь описать параметры методов и возвращаемый ими результат. С этим справятся jsdoc, pydoc и прочие подобные.powerman
27.02.2019 08:44Но вообще инструмента типа swagger действительно не хватает, автоматическая генерация/обновление доки со встроенной проверкой запросов, кода для клиентов и серверов, а так же тестовых заглушек из единого описания протокола нам бы очень пригодилась.
BerkutEagle
27.02.2019 09:39Периодически мониторю интернет в поисках такого инструмента, но всё тщетно :)
Не то что уровня swagger, вообще ничего нет! Видимо нет запроса от аудитории, все ушли в REST.bevalorous
28.02.2019 08:05Если вы пишете на Javascript, гляньте вот этот пакет: www.npmjs.com/package/jrgen

vmm86
27.02.2019 19:47Сейчас как раз требуется такое описание для автоматического импорта методов JSON API в сервис тестирования.
Сходу в голову не приходит ничего, кроме как создать "фэйковое" описание Swagger/Open API, где URL и статус-коды ответов всех методов будут одинаковыми.-)
vsb
27.02.2019 19:48Посмотрите на gRPC. Это свежая итерация RPC-протокола от Google. Мне она не очень нравится, но, похоже, у неё есть шансы «выстрелить».
powerman
27.02.2019 20:04А чем конкретно не нравится?

yokotoka
27.02.2019 20:54Извините, что встреваю. У меня есть к нему претензия. Я читал код grpc-либы под python и моя жизнь никогда не будет прежней (к слову о «гениях», работающих в Google). И сам protobuf — не самый приятный IDL из существующих. Однако, по моему опыту это лучший инструмент для кроссплатформенного RPC поверх http2, который распространен чуть более, чем везде. Двухсторонние стримы, мультиплексирование (куча виртуальных коннектов в рамках одного tcp-соединения), сжатие, поддержка практически всех ходовых платформ… Плюс вменяемая документация в виде protobuf-описаний. В общем, хоть он и горький, но лекарство после «кто-в-лес-кто-по-дрова-REST-это-не-спецификация-а-общий-набор-рекомендаций» и неэффективного json-rpc, для которого кроме спецификаций полей простейшего request-reply протокола вообще ничего толком нет.
powerman
27.02.2019 21:06Претензия к реализации не самая валидная. Да, чистый код это очень важно, но если нет выбора, то если реализация качественно протестирована, работает без проблем, то что у неё внутри — становится не критично, коль уж лично Вам лезть в этот код не придётся.
sergeyfast
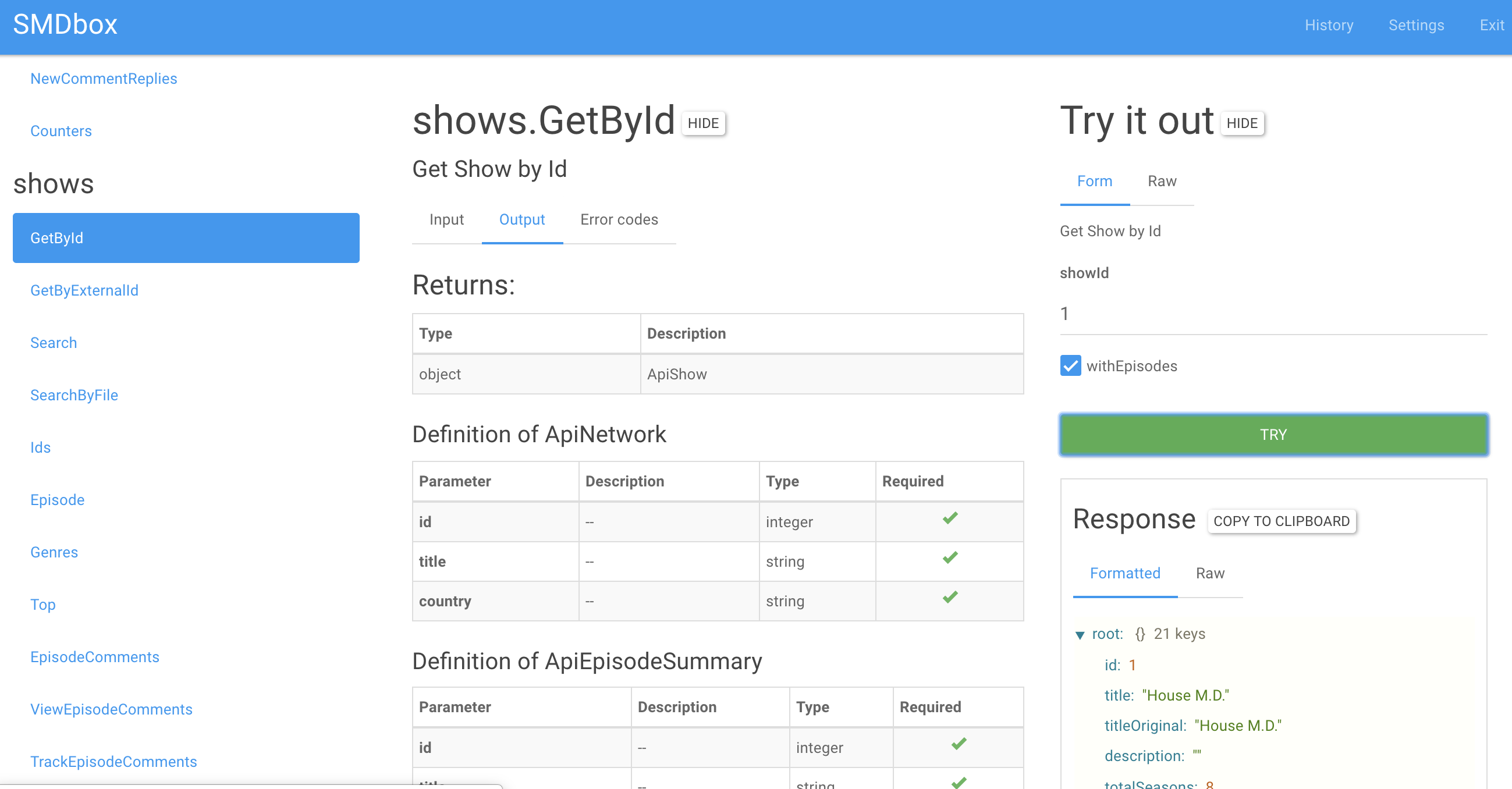
27.02.2019 22:44+1Инструменты есть, но мало о них кто знает. В 2012 писал про SMD схему habr.com/ru/post/150803 (ctrl+f smd), Недавно нам удалось сделать github.com/semrush/smdbox, хорошо работает как с PHP реализацией github.com/sergeyfast/eazy-jsonrpc/tree/shuler_response, так и с Go github.com/semrush/zenrpc. Т.е. есть автодокументация и playground.
Так же есть еще генерация сваггера (все в репозитории выше), пример api.myshows.me/shared/doc, пример endpoint'a api.myshows.me/v2/rpc/?smd
Удалось сделать даже документацию ошибок, которые есть в JSON-RPC. Ну и генерация самого клиента тоже есть. Вот так это все примерно выглядит (smdbox)
vmm86
28.02.2019 16:10Интересное решение.
Передо мной сейчас стоит задача описать сервисы JSON PRC API в одном файле и импортировать их из него в сервис тестирования. Нюанс в том, что для импорта поддерживаются только форматы Swagger/OpenAPI или WSDL/WADL. OpenAPI можно было бы использовать как обходной вариант, но URL и HTTP-методы для всех сервисов в этом случае будут одинаковыми.
Минус SMD в этом смысле — что это, во-первых, малоизвестная штука, во-вторых, скорее, видимо, всё ещё proposal, чем утверждённая спецификация?
PerlPower
27.02.2019 06:22+1Вы не понимаете сути специальной олимпиады идущей вокруг того как правильно писать REST, где правильность написания REST никого из участников не волнует.
xitt
27.02.2019 17:45+1Я тоже не понимаю, можете коротко развернуть?
PerlPower
27.02.2019 20:27+1Просто запомните что любое упоминание о том как следует писать REST будет встречно контраргументом как это делать не надо. Причин почему так происходит несколько — и неприменимость REST для ряда случаев, и попытка дотошно описать простые вещи в самом стандарте, и достаточно широкий простор для трактовки что считать чем при проектировании REST.
bat
27.02.2019 08:03-1Во-вторых, кодов ответа в HTTP всегда меньше, чем типов ошибок бизнес-логики, которые вы бы хотели возвращать на клиент.
Кто-то всегда возвращает 200-ку, кто-то ломает голову, пытаясь сопоставить ошибки с HTTP-кодами.
В JSON-RPC весь диапазон integer — ваш.
наверное, опять холиварная тема, но в некоторых случаях предпочел оставить поле error для ошибок протокола, описанных в спецификации, а ошибки бизнес логики передавать внутри result. Некоторые случаи — это api для межсервисного взаимодействия, где сервис одновременно может поддерживать jsonrpc, grpc, очереди сообщений и не только… хочется минимизировать влияние протокола на форматы сообщейни.
fukkit
27.02.2019 08:06-5Да и нужен ли Вам JSON?
Былой человекочитаемости уж не сыщешь. Эти анонимные объекты кого угодно загонят на перекур!
Открывается одна единственная, плохо различимая сквозь диоптрии, махонькая фигурная скобочка без роду и племени, без всякого названия. Начинай читать миллион полей содержимого — авось по смыслу догадаешься, чего туда светлый ум понапихал!
То ли дело XML-RPC! Все чётко, по делу, имя не понятное — глянь схему. Строгость, стройность, либы для всех языков, автовалидация, XPath, — все дела!
Да и стандартище! Не в пример доморощенным костылям.
Бросайте эти ваши ресты с джэйсонами, назад к истокам!
fukkit
27.02.2019 09:47О — отбитый (рус., слэнг., жарг.) — состояние чувства юмора среднего хаброминусатора.

mikechips
27.02.2019 22:29+4Не говорю за всех, но мне лично кажется, что лаконичнее так:
{'objects': ['object1', 'object2']}
Чем так:
<objects> <object1></object1> <object2></object2> </objects>
При наличии таланта можно как XML сделать нечитаемым, так и JSON гениально простым (особенно с pretty-print). Но в большинстве случаев мы не смотрим на JSON, а сразу же его парсим и смотрим уже в том виде, в котором предлагает нам язык.


multiadmin
27.02.2019 08:33-1{«jsonrpc»: «2.0», «method»: «post.like», «params»: {«post»: «12345»}, «id»: 1}
Вот тут сразу виден недостаток стандарта (или следствие наличия «бонуса» в виде batch-операций):
метод закодирован в теле сообщения!
С точки зрения простоты протоколирования, мониторинга, возможности перекрытия реализации метода, балансировки и т.п. это неудобно.
Все таки название метода в пути, может, и не идеальное, но вполне удачное решение.
А здесь «бонус» вильнул собакой.powerman
27.02.2019 08:47+1Нет, это следствие не batch, а того, что протокол транспорто-независимый, поэтому никаких "путей" (равно как и HTTP в принципе) в нём просто нет.
multiadmin
27.02.2019 09:54{«jsonrpc»:«2.0»,«error»:{«code»:1234,«message»:«Server not found»},«id»: 2}
И еще. Почему код — это число, а не строка? Как так?VolCh
27.02.2019 10:40А почему нет? Боитесь, что чисел для всех ситуаций не хватит? :)
multiadmin
27.02.2019 11:20А почему нет? Боитесь, что чисел для всех ситуаций не хватит? :)
Ну хорошо, тогда дополнительный вопрос.
Если «код» сделали числом, то почему «метод» тоже не сделали числом?
Боятся, что что чисел для идентификации методов не хватит? :)VolCh
27.02.2019 11:31А как связаны код и метод? Зачем делать методом числом или зачем делать код строкой?
multiadmin
27.02.2019 13:47+1А как связаны код и метод?
И код, и метод — это перечисляемые типы.
Представляя значение кода/метода в виде числа мы получаем последствия:
1) разрабатывая API командой (разными людьми) гораздо вероятнее получить коллизию по их значениям;
2) нужно что-то особое придумывать, что бы исправить существующие коллизии и что делать, что бы таких коллизий не было в дальнейшем;
3) представляя значение перечисляемого типа в виде числа мы автоматически попадаем на антипаттерн магическое число.VolCh
27.02.2019 14:32Как по мне, то вероятности коллизий одинаковы, что в строке, что в числах. Вернее нет оснований считать, что с числами она заметно больше будет. В коде всё равно будут использоваться enum типы или, хотя бы, константы для каждого кода. И с кодами гораздо проще выделять классы ошибок. Собственно как в HTTP.
multiadmin
27.02.2019 14:38коде всё равно будут использоваться enum типы или, хотя бы, константы для каждого кода
Эти константы все равно будут иметь какие-то значения. Какая разница, оборачиваются они в красивые идентификаторы или нет в языке программирования?
И с кодами гораздо проще выделять классы ошибок.
Точно не проще. Потому что каждое число и так имеет строковое представление.
А что бы изолировать набор значений, достаточно придумать уникальный префикс. С числами такой фокус не проходит.Doomsday_nxt
27.02.2019 14:43С числами такой фокус не проходит.
Чевойта? Простой пример HTTP-коды:
1хх — инфо, 2хх — всё ОК, 3хх — перенаправление, 4хх — ошибка клиента, 5хх — ошибка сервераmultiadmin
27.02.2019 14:45Реальный мир шире, чем HTTP-протокол.
Ради чего ограничивать себя сотней типов (значений)?
Как это решит проблему коллизий?
Это что-то из разряда «640 кб хватит всем»?

Cykooz
27.02.2019 10:45Что бы «предполагаемый противник» не догадался о значении ошибки, особенно если в message писать одно и то-же для всех ошибок :)
BerkutEagle
27.02.2019 13:33+11234 — это 1234 на любом языке, а message можно отдавать на языке пользователя.
Ещё числовой код удобно бить на диапазоны по критичности, например, или области ответственности.multiadmin
27.02.2019 13:54а message можно отдавать на языке пользователя
А как API узнает язык пользователя?
И какого пользователя? Оператора или программиста?
И зачем, вообще, служебные сообщения переводить?
putnik
27.02.2019 14:14+1А как API узнает язык пользователя?
Из заголовка Accept-Language, например.
И зачем, вообще, служебные сообщения переводить?
Если у вас мультиязычное мобильное приложение, то вполне допустимый вариант переводить их на стороне API.multiadmin
27.02.2019 14:22Из заголовка Accept-Language, например.
Во первых, у нас же протокол «изолирован» от HTTP, какие заголовки?
Во вторых, ради чего эти усложнения, делать вам больше нечего?
Если у вас мультиязычное мобильное приложение, то вполне допустимый вариант переводить их на стороне API.
Мой идеал: API занимается обработкой данных (доступом к данным), мобильное приложение — представлением этих данных, в т.ч. локализацией. Каждый в чужую зону ответственности не лезет.
Вы определенно описали случай, далекий от моего идеала.keydet
27.02.2019 19:37Банально, данные в трёх экземплярах не будешь хранить локально. Локализация вполне себе может быть "на лету".
multiadmin
27.02.2019 20:31Может быть все, что угодно, только помните про принцип разделения ответственности, если не хотите, что бы ваша система превратилась в лапшу.
keydet
28.02.2019 16:12На практике наиболее оптимальна комбинация server-side/client-side localization&internationalizationдля разной степени динамичности элементов, пропускной способности канала и профиля взаимодействия с фронтендом (частота опрашивания, количество перед. данных, кол-во открываемых соединений, вид транспорта и т.д.)
Статику вполне допустимо локализовывать client-side и отдавать в API только string ID, а вот часто обновляемый контент удобней локализовывать server-side. Также для многих языков есть свои разные устоявшиеся практики/рекомендации на эту тему.
Oxoron
27.02.2019 12:29Нет, это следствие не batch, а того, что протокол транспорто-независимый, поэтому никаких «путей» (равно как и HTTP в принципе) в нём просто нет.
Вопрос от человека незнакомого с протоколом: не повторяют ли разработчики структуру HTTP путей? То есть, в REST у нас имеется post/like, post/bookmark, post/share/vk, etc. Не будет ли в json rpc построена аналогичная структура: «method»:«post.like», «method»:«post.bookmark», «method»:«post.share.vk»?bat
27.02.2019 12:45+1Будет что-то типа Api.LikePost, Api.BookmarkPost, Api.SharePost.
В jsonrpc нет путей, есть нотация Service.Method. На одном эндпоинте может быть несколько сервисов.
x67
27.02.2019 14:05Но самое забавное, что даже в этом примере, который должен показать типо независимость и самостоятельность json-rpc, автор по сути придумал yet another post request.
Имхо не надо придумывать миллион велосипедов в себе. Универсального все равно не будет! И не надо добиваться бюрократической точности в соблюдении стандартов без необходимости. В 95% случаев совет — юзать рестоподобную архитектуру, хорошо документируйте ее и никогда ни у кого не возникнет проблем с пониманием вашего велосипеда.
GameDeV + Realtime = http rest???? Не смешите мои тапочки. И джейсон-рпц сам по себе тут проблем не решает. Имхо тут важнее используемый транспортный протокол, чем структура данных, которую вы передаете. А передаете вы джейсон, xml или двоичные данные — вопрос уже десятый.
trawl
27.02.2019 08:41+1Вспоминая о JSON-RPC и документировании API, не забывайте о SMD.
Например{ "transport": "POST", "envelope": "JSON-RPC-2.0", "contentType": "application/json", "SMDVersion": "2.0", "services": { "post.list": { "transport": "POST", "envelope": "JSON-RPC-2.0", "parameters": [ { "name": "author", "type": "string" }, { "name": "token", "type": "string", "optional": true } ], "returns": { "type": "array", "items": { "type": "object", "properties": { "title": { "type": "string" }, "content": { "type": "string" }, "author": { "type": "string" }, "status": { "type": "string", "enum": [ "draft", "published" ] } }, "required": [ "title", "content", "status", "author" ] } }, "post.create": { "transport": "POST", "envelope": "JSON-RPC-2.0", "returns": { "type": "object", "properties": { "title": { "type": "string" }, "content": { "type": "string" }, "author": { "type": "string" }, "status": { "type": "string", "enum": [ "draft", "published" ] } }, "required": [ "title", "content", "status", "author" ] }, "parameters": [ { "name": "title", "type": "string" }, { "name": "content", "type": "string" }, { "name": "status", "type": "string" }, { "name": "token", "type": "string" } ] } } } }
ris58h
27.02.2019 10:59+1Выглядит неплохо, но для описания использовать JSON - не лучший выбор, т.к. комментариев нет, а они, будьте уверены, понадобятся. Надеюсь, что смогут предложить YAML или что-то подобное.
trawl
27.02.2019 11:37Ничто не мешает добавить в сервис поле
descriptionmichael_vostrikov
27.02.2019 21:01+1Как здесь будет выглядеть с description?
{ // url for special service // "serviceUrl": "http://example.com/api", // change back when standard url will work "serviceUrl": "http://subdomain.example.com/api" }FrozenWalrus
28.02.2019 00:04Можно было бы использовать JSON5, который допускает использование комментариев, если SMD его поддерживал.
trawl
28.02.2019 06:21Не очень понял вопрос.
здесь— это какое место?
{ "serviceUrl": "http://subdomain.example.com/api", "description": "change back when standard url will work" }
Вот так не получится?
michael_vostrikov
28.02.2019 07:28Все закомментированное с сохранением информации. Для отладки тоже часто бывает нужно, например временно переключить БД по умолчанию на свою локальную.
trawl
28.02.2019 07:42{"description":"url for special service\n\"serviceUrl\": \"http:\/\/example.com\/api\"\nchange back when standard url will work"}
Но это будет приемлемо, если использовать какой-нибудь UI для SMD. В чистом виде читать это — такое себе, да...
А что касается БД — то каким образом тут SMD играет роль?
SMD — это описание, а БД — это уже реализация...michael_vostrikov
28.02.2019 09:43Ну так параметры подключения к БД хранятся в конфиге. Надо переключить, закомментировал одну строчку, раскомментировал другую.
sergeyfast
27.02.2019 22:45Про UI написал тут habr.com/ru/post/441854/#comment_19815744
Возможно пригодится

flancer
27.02.2019 09:01Как-то меня смущает во всей этой холиварне слово "stateless". На большинстве сайтов, с которыми лично я сталкиваюсь, требуется аутентификация/авторизация, а это уже, как минимум, два состояния: анонимный и аутентифицированный.
Cykooz
27.02.2019 09:22+2Потому что вы не правильно понимаете это слово. Под «состоянием» имеется ввиду состояние некой «сессии» между клиентом и сервером. Например такой «сессией» может быть подключение через TCP. Как только оно разрывается, то «сессия» завершается, состояние теряется. При следующем подключении надо это состояние опять восстанавливать: выполнять аутентификацию, давать команды для перехода в нужную директорию (как в FTP) и др.
Если же у вас «stateless» — то каждый запрос от клиента передаёт всю необходимую информацию не полагаясь на то, что сервер «помнит» клиента. В общем случае запросы клиента могут с помощью балансировщика направляться на разные сервера, какая тогда вообще может быть речь про «сессию» и «состояние сессии»?flancer
27.02.2019 10:30В общем случае запросы клиента могут с помощью балансировщика направляться на разные сервера
Вот и вопрос, как же тогда разные сервера определяют, анонимный клиент дал запрос или он уже аутентифицирован ранее и имеет права на доступ к restricted-данным?
Cykooz
27.02.2019 10:42Ну если у разных серверов есть доступ к общей базе с этими «restricted-данными», то скорее всего в этой же (или соседней) базе есть данные необходимые для авторизации клиента. Например есть таблица с мапингом токенов на юзеов. Клиент в этом случае передаёт в каждом запросе свой авторизационный токен, который получил от сервера в процессе аутентификации.
Ну или всё ещё проще — клиент в каждом запросе передаёт свой логин-пароль, как это сделано в HTTP Basic авторизации.flancer
27.02.2019 11:53Филдинг описал концепцию построения распределённого приложения, при которой каждый запрос (REST-запрос) клиента к серверу содержит в себе исчерпывающую информацию о желаемом ответе сервера (желаемом представительном состоянии), и сервер не обязан сохранять информацию о состоянии клиента («клиентской сессии»).
Это из вики. Получается, что таблица с авторизационными токенами на сервере — это не REST. Если подходить строго, то REST возможен только при HTTP Basic аутентификации. Только тогда сам запрос содержит в себе достаточно информации, чтобы сформировать ответ. При этом на каждый запрос нужно будет проводить аутентификацию и авторизацию.
bat
27.02.2019 12:47+2flancer
27.02.2019 13:12О! Вот это то самое! Спасибо :)
niksamokhvalov
27.02.2019 16:52+2Но помните, что исключив обращение к БД, вы потеряете возможность мгновенного бана пользователя.
Rsa97
27.02.2019 16:55-1А зачем смешивать аутентификацию (JWT) и авторизацию? Всё равно проверять, есть ли у данного пользователя права на запрошенное действие.
TonyLorencio
27.02.2019 17:04+1Всё равно проверять, есть ли у данного пользователя права на запрошенное действие.
Можно и не проверять права, а записывать их прямо в токен при выдаче. Если срок жизни токена небольшой (например, минута, цифра с потолка) — мгновенно забанить пользователя, конечно, не выйдет, но после протухания его токен превратится в тыкву, а новый ему уже никто не даст.
Rsa97
27.02.2019 17:09Можно в простых случаях, например, когда достаточно прав «guest, user, admin».
В более сложных, когда у пользователя есть права только на определённые действия только для определённых групп объектов токен слишком большой получится.
niksamokhvalov
27.02.2019 17:19Ни в коем разе! Аутентификация != авторизация.
Но я читал и даже слушал выступления людей, вкладывающих в пейлоад информацию о правах доступа (гранты, роли и т. п.) Из чего делаю вывод, что это распространённая практика. Однако, я не призываю так делать, и я намеренно оставил за скобками обсуждение качества такого подхода.TonyLorencio
27.02.2019 17:42Разве в качестве аутентификации в JWT выступает не тот факт, что подпись токена верна?
Тогда в качестве авторизации можно использовать содержимое токена без дополнительных обращений к сервису авторизации для проверки того, какие права имеет пользователь такой-то.
При этом подходе фактически задачи авторизации фактически будут переложены на сервис, занимающийся выдачей токена, что хорошо ложится в микросервисную модель.
niksamokhvalov
27.02.2019 17:48+2Ну да. Мы вернулись к тому, с чего начали: так можно жить, но мы лишаемся возможности моментального изменения данных пользователя / бана / разлогина. Каким-то проектам эта схема подходит, каким-то — нет.
VolCh
27.02.2019 13:27+1Таблица (или полноценный сервис) с токенами вполне может быть за REST ендпоинтом, главное сервер не должен делать предположений откуда получен токен клиентом, не должен предполагать что для получения токена был сделан конкретный запрос перед текущим и какая-то информация о нём сохранилась.
Cykooz
27.02.2019 15:33+1Уже ответили, но я дополню.
Как я написал в первом ответе, наиболее типичным вариантом «сессией с состоянием» как правило является нечто вроде привязки состояния к TCP-соедниению между клиентом и сервером, а не то что у вас в базе данных на сервере или в клиенте хранится. Храните в базе что хотите и как хотите, передавайте информацию от клиента к серверу тоже как хотите (через куки, через тело запроса, через другие заголовки) — главное передавайте в каждом запросе если они ему нужны.
Если рассуждать как вы описали выше, то вообще любое хранение сервером данных — это нарушение REST, т.к. это хранение «состояния». Но это не так, т.к. это совершенно другое «состояние». Это состояние сервера. У клиента тоже есть какое-то своё состояние и он посредством запросов к серверу пытается «синхронизировать» своё состояние с тем, что есть на сервере. При этом ни сервер, ни клиент не должны полагаться на то, что за сколь угодно малое время между двумя запросами, состояние одного из них не изменилось. Архитектура должна проектироваться так, как будто между двумя запросами и даже одновременно с ними, происходят другие процессы меняющие «локальное» состояние участников процесса. Отсюда и происходит требование, что бы в запросе передавалась вся необходимая для его выполнения информация. И не важно в каком она виде, как называется и каким образом обрабатывается сервером. Главное что серверу будет достаточно этой информации.
Попробую привести «кухонный пример» почему stateless важен для построения масштабируемой архитектуры.
Представьте кинотеатр, кассы, билетёр на входе в зал. Вы купили билет, показали билетёру и вошли в зал. Потом решили вернуться в машину за забытыми очками. Если, когда вы возвращались, билетёр ОБЯЗАН запомнил вас в лицо и пустить без проверки билета — это не масштабируемая система. Такого билетёра нельзя подменить другим, потому что он вас не знает и не сможет впустить. Вам придётся снова проходить процедуру покупки билета, если вы его потеряли, и показывать его билетёру.
Если же билетёр ОБЯЗАН пропускать только по билету — то любой билетёр сможет пропустить вас с билетом, даже если видит вас впервые. Вот это масштабируемая схема — можно поставить хоть 10 билетёров и вы можете к любому подойти со своим билетом, а не только к тому, кто вас первым проверил.
VolCh
27.02.2019 10:42Как вариант, аутентифицированный добавляет к запросу токен, а сервер проверяет валидный токен или нет. Вот только проверяет он не «аутентифицирован ранее», а именно валидный токен или нет.
flancer
27.02.2019 11:57Что значит в данном контексте "валидный токен"? Может ли у одного и того же пользователя (с одним и тем же внутренним идентификатором на сервере) быть два разных валидных токена? Что делать, если пользователь "засветил" свой токен перед злоумышленником и теперь хочет поменять его?
VolCh
27.02.2019 13:04Валидный значит сервер не видит причин не доверять информации в токене. Может или не может быть несколько токенов, принудительная инвалидация и т. п. — как требования будут, так и реализуете.
Jesting
27.02.2019 17:33+1Токен формируется в процессе логина как результат успешной аутентификации. Токен нигде хранить не нужно — его достаточно подписать и отдать пользователю. При последующих запросах проверяем валидность переданного нам токена. Если токен попадёт в руки злоумышленника то проблема решается так же как и в случае с паролем — смена пароля ведёт к генерации нового ключа для токенов. Все прежде выпущенные токены становятся не валидными.
mayorovp
27.02.2019 09:27+1Практически, это холиварное слово означает что никаких проблем часть запросов делать анонимно, часть — от имени некоторого пользователя, а часть — от имени другого пользователя, и всё это одновременно. Или последовательно, но через общее HTTP-соединение. Ну, если аутентификация сделана не куками и сессиями, как тут предлагали выше, а как полагается — токенами.
flancer
27.02.2019 10:35Но токен же должен храниться и на клиенте, и на сервере, чтобы можно было обеспечить аутентификацию/авторизацию? И по мне, так нет никакой принципиальной разницы с точки зрения stateless, как передавать токен с клиента на сервер — в заголовке
Cookieили в заголовкеAuthorization.VolCh
27.02.2019 10:45Не должен. Токен может быть самодостаточным, содержать, например, userId непосредственно.
nanshakov
27.02.2019 11:55+1Но как его тогда защитить от подделки?
Antigluk
27.02.2019 12:22электронной подписью, например
но возникает вопрос — как тогда экспайрить такие токены?VolCh
27.02.2019 13:06Кроме срока действия может быть обращение к сервису авторизации на предмет не отозван ли он.
TonyLorencio
27.02.2019 15:52Если токен подписан, то достаточно проверить лишь саму подпись. В этом случае при проверке на то, не отозван ли он, теряется весь смысл подписанных токенов и система приобретает состояние.
ИМХО более удачное решение в этом смысле — короткие по времени действия токены.
VolCh
27.02.2019 17:48-1Состояние состоянию рознь. А ради кейсов, которые происходят раз в полгода, всех клиентов заставлять постоянно рефрешить токен как-то не тру.
Jesting
27.02.2019 17:36У каждого юзера свой криптоключ для подписи токена. Если один из токенов скомпрометирован — меняем ключ и все токены автоматом становятся невалидные. Пользователю нужно заново логинитьcя дабы получить валидный токен.
mayorovp
27.02.2019 20:44Ничем не лучше варианта с хранимым списком токенов — точно так же серверу нужна актуальная база с некоторой информацией.
Jesting
27.02.2019 21:23Только непонятно зачем этот список хранить. Совсем непонятно. Этож не сессии.
mayorovp
28.02.2019 08:39А как вы собрались узнавать актуальный ключ пользователя чтобы проверить токен?
Jesting
28.02.2019 09:44Так у пользователя всего один ключ актуальный.
mayorovp
28.02.2019 12:59Так пользователей много.
Jesting
28.02.2019 14:07Ну тут два пути:
1. Можно всех пользователей по очереди перебирать с их ключами и к какому подойдёт того и пускать в систему.
2. Можно из payload'а извлекать уникальный айди, по нему находить пользователя, получать его ключ и проверять валидность токена. Так все и делают, кстати.mayorovp
28.02.2019 15:56-1Ну так вам в любом случае нужна актуальная база с ключами пользователей. Чем она принципиально отличается от актуальной базы токенов?
В обоих случаях проверка токена сводится к одному запросу к БД.Jesting
28.02.2019 16:03Ключ один. А токенов может быть много — для веба, для андроид и иос приложений. У каждого токена может быть своя область видимости а так же время действия. Зачем всё это хранить непонятно. Ключ нужно хранить в любом случае.
BerkutEagle
28.02.2019 20:31-1В JWT-токен можно положить id пользователя, его имя, список ролей, например. И не надо будет при каждом запросе лезть в базу за этими данными. Хранить только список отозванных токенов (скидывать туда при разлогине или рефреше). Можно держать в памяти (в редисе, например) и проверять хоть nginx'ом на входе. При потере списка невалидных токенов (при ребуте, например) инвалидировать вообще все токены выданные раньше даты ребута, пользователи просто снова залогинятся. Чтобы редис не сожрал всю память, вычищать токены, протухшие по сроку. Вроде схема простая и много где описана.
mayorovp
28.02.2019 21:41А в чем принципиальная разница: лезть в базу чтобы проверить что токен там есть, лезть в базу чтобы проверить что токена там нет — или лезть в базе за ключом пользователя?
BerkutEagle
28.02.2019 22:24Слазить в SQL в несколько таблиц, чтоб вытащить инфу о пользователе куда дороже, чем проверить наличие строки в редисе.
mayorovp
01.03.2019 09:38+1Ни один из перечисленных мною сценариев не требует лезть в несколько таблиц…

Graphite
27.02.2019 09:51+3Помимо всех плюсов навскидку вижу два минуса по сравнению с REST.
- Клиентское кеширование. Можно сколько угодно говорить, что кешировать RPC нельзя (как настаивает указанный выше JSON-RPC 2.0 Transport: HTTP), но в реальности кешировать нужно. И тогда мы либо поддерживаем два разных API — одно JSON-RPC, одно REST или что угодно с кешированием, либо начинаем реализовывать кеширование руками. Изобретаем ETag / Last-Modified, решаем что является идентификатором ресурса, делаем кучу ошибок и не можем пользоваться браузерными кешем.
Даже в вашем примере Хабра можно кешировать информацию о старых постах, профили пользователя, посты для мобильной версии (куда не включены комментарии), в общем все что редко изменяется. Это позволит сэкономить очень много ресурсов. - Микросервисная архитектура и балансировка нагрузки. На балансировщике намного дешевле проверить префикс URI, чем распарсить JSON и вытащить оттуда метод. Нехорошие клиенты могут отправлять валидные запросы с очень длинным телом, а метод в нем ставить в конце.
Да даже разделить read-only и read-write становится трудно. Я уже не говорю о том, что при необходимости некоторые параметры можно тоже включить в балансировку нагрузки и в случае REST это все тот же префикс. Да, смешиваем транспортный уровень и уровень приложения, но бывают ситуации когда это оправдано.
Упомянутый выше мониторинг это проявление той же проблемы под названием "JSON парсить дорого". В приложении это уже не так дорого по сравнению с остальной логикой, но на других уровнях — очень и очень дорого.
artX89
27.02.2019 12:06В своих проектах я решаю минусы JSON-RPC очень простым способом, для запросов, передающихся через HTTP, просто выношу поле method в URL, строка запроса при этом выглядит как «/api/posts.add», где «posts.add» значение method, а параметры передаю уже в теле через params. Но я не использую batch-операции т.к. в зависимости от метода, балансировщиком выбирается сервер обработки и мешанина методов в одном пакете в этом случае только мешает. Также не использую в теле «jsonrpc:2.0» из-за того что полученный протокол не является чистым JSON-RPC. В остальном же стараюсь придерживаться стандарта.
multiadmin
27.02.2019 14:05Наверное, так в основном и делают, а спецификация JSON-RPC не прижилась в жизни:
переусложнена, там, где не надо (из-за batch-операций возникают далеко идущие последствия), сложнее в балансировке и мониторинге относительно REST и полу-REST решений.
robert_ayrapetyan
27.02.2019 18:07-3Какой ужас. Тут статья про то, какой JSON-RPC 2.0 стандарт, не позволяющий вольностей набрала уже 150 плюсов, а вы jsonrpc:2.0 выкидываете и метод в путь. Ай-ай-ай…
artX89
27.02.2019 18:17+2Так поэтому я и написал, что полученный протокол не является чистым JSON-RPC и по этой причине в теле не используется «jsonrpc:2.0». Инструмент надо выбирать из задачи, а не наоборот. В моем случае отсутствует необходимость обращения сторонних серверов к моим API, нет необходимости 100% соответствовать стандарту. Зато этот подход позволяет мне разрабатывать более удобный интерфейс клиент-серверного взаимодействия.
powerman
27.02.2019 19:11С одной стороны Вы правы. И многие из нас, включая меня, когда-то делали нечто подобное. Но, с годами опыта, обычно приходит понимание, что любое отступление от существующего стандарта/протокола должно требовать значительно больше плюсов, чем "мне так удобнее" или "мы получим одну классную фичу" — потому что неудобств такие отступления от стандартов, со временем, создают больше, чем изначально ожидалось. В качестве конкретного примера таких "неудобств":
- внезапно бизнес требует обеспечить совместимость со стандартным протоколом, т.к. этого требуют новые партнёры, или это нужно чтобы сделать API публичным, или ещё по куче непредсказуемых заранее причин
- нужно вручную реализовывать библиотеки для своего протокола, причём нередко со временем оказывается, что нужна не одна для языка используемого сейчас на бэкенде, а ещё одна на бэкенд для другого языка плюс ещё пара для мобильных клиентов плюс ещё одна для веба
- у стандартных протоколов есть недостатки… как и у любых других, но — недостатки стандартных протоколов уже хорошо известны, документированы, и есть рекомендации по их преодолению… а вот со своим протоколом все шишки придётся набивать самостоятельно, и узнавать о его недостатках в самый неподходящий момент — когда нужно срочно сделать фичу, а протокол начинает в этом мешать, а не помогать
- следствие предыдущего пункта — свой протокол периодически приходится изменять/расширять не продумав как следует последствия, что создаёт ещё больше проблем в будущем
Поэтому перед принятием решения пилить свой протокол крайне желательно, чтобы существующие действительно не подходили для данного проекта, и чтобы свой давал немало ценных преимуществ, чтобы компенсировать вышеупомянутые проблемы.
artX89
27.02.2019 19:42Абсолютно согласен с приведёнными выше пунктами, только они не совсем подходят для конкретно данного случая и протокола, так как:
- изменения в протоколе минимальны, реализовать публичную точку входа на строгом JSON-RPC будет не очень сложно, и на порядок проще чем в случае с REST
- сам по себе протокол очень простой и отсутствие специальных библиотек не большая проблема
- простата протокола позволяет особо не переживать о скрытых ошибках, да и отклонения от стандарта минимальны
- следствие предыдущего пункта — свой протокол периодически не приходится изменять/расширять не продумав как следует последствия
В данном случае небольшое отклонение от стандарта дает немало ценных преимуществ, компенсирующих вышеупомянутые проблемы.
rsvasilyev Автор
27.02.2019 12:53В некоторой степени вторую проблему можно решить, вынося балансировку на сторону клиента.
Можно сделать API, отдающий конфигурацию вида:
{ "post.get": "https://posts.example.com/rpc", "post.like": "https://likes.example.com/rpc", "comment.like": "https://likes.example.com/rpc", "default": "https://example.com/rpc" }
При таком подходе в любой момент времени любой метод можно вынести в отдельный микросервис.

Grox
27.02.2019 17:54+11. Доверять нельзя, как сказали выше.
2. В результате получается тот же URI навыворот.
powerman
27.02.2019 17:24+1Кешировать RPC запросы это плохая идея. Нужно кеширование — используйте REST, вместо или вместе с RPC.
Что до балансировки нагрузки на уровне HTTP, то это вообще не проблема — просто делаем для каждого публичного микросервиса свой url/endpoint, вроде https://api.example.com/rpc/microserviceA, и дальше nginx по url раскидает запросы по разным сервисам. Даже если в будущем этот микросервис будет заменён несколькими другими (что бывает достаточно редко), то мы просто на его месте поставим микросервис-прокси, который будет реализовывать старое API и преобразовывать его в новое — это в любом случае необходимо для сохранения совместимости API.
- Клиентское кеширование. Можно сколько угодно говорить, что кешировать RPC нельзя (как настаивает указанный выше JSON-RPC 2.0 Transport: HTTP), но в реальности кешировать нужно. И тогда мы либо поддерживаем два разных API — одно JSON-RPC, одно REST или что угодно с кешированием, либо начинаем реализовывать кеширование руками. Изобретаем ETag / Last-Modified, решаем что является идентификатором ресурса, делаем кучу ошибок и не можем пользоваться браузерными кешем.
pilyugin
27.02.2019 10:23Что делать с наборами удобных браузерных Developer Tools? url с параметрам в виде списка (не надо заходить смотреть тело), фильтры
ExplosiveZ
27.02.2019 12:26А уже есть «XML over JSON»? Чтобы были все фичи XML и написано было по-json'овски?
(уверен, что выглядеть будет в миллион раз хуже, чем просто xml)rsvasilyev Автор
27.02.2019 12:30Не поверите) https://en.wikipedia.org/wiki/XML-RPC
ExplosiveZ
28.02.2019 00:21Вы не поняли. В XML есть типизация, из коробки, в JSON такого нет. Тут еще и сделали аналог XML-RPC. Я уверен, что уже и для типизации что-то придумали, что-то настолько страшное, что лучше пользоваться XML и не придумывать очередной xxx-RPC.
BerkutEagle
28.02.2019 06:24Я уверен, что уже и для типизации что-то придумали
Ну а как же! JSON Schema :)
Хотя это калька с XML Schema и не совсем типизация, но и типы и структуру валидировать может.

hermes-jr
27.02.2019 12:36+1Впрочем, документировать такой простой API можно хоть в markdown-файле.
Извините, но это лукавство какое-то. Если у нас есть 200 сущностей, над которыми можно осуществлять 5 операций, то, условно, фронтендщику надо дать документацию на 1к возможных вариантов (эндпоинт + что в него слать и что вернётся в ответ на get/put/post + параметры). Если функционал остаётся тот же, но вы используете jsonrpc, то только переносите часть информации одействии из урла+метода в тело, но эта тысяча возможных вариантов взаимодействия никуда не денется и документировать надо ровно столько же.rsvasilyev Автор
27.02.2019 12:36+2Если у нас есть 200 сущностей, над которыми можно осуществлять 5 операций
В этом случае подойдет именно REST
AlexTheLost
27.02.2019 13:59По мне выгоды от JSON-RPC, в общем случае, нет.
URI это просто параметр в теле HTTP запроса, вы его из заголовка 'GET URI', перенесли в body в чем профит?)
А разделить обработку входных данные на основании пути достаточно удобно и стандартно:
/path1/val1
… обработчик 1…
/path2/val2
… обработчик 2 ..
Вам же прижется писать тот же routing только своими руками.
И не везде это применимо. Если у вас "сайт" с которым нужно взаимодействовать через браузер, очевидно будет выбор решения через url.VolCh
27.02.2019 14:15> вы его из заголовка 'GET URI', перенесли в body в чем профит?)
Забыли про HTTP-метод. В JSON-RPC вы не ограничены менее чем десятком методов со стандартной семантикой.
> Если у вас «сайт» с которым нужно взаимодействовать через браузер, очевидно будет выбор решения через url.
Только для загрузки «загрузчика» типа public/index.html, а реальные данные могут грузиться любым доступным способом.
Pydeg
27.02.2019 14:30Что-то не вижу преимуществ у JSON-RPC, в сравнении с GraphQL, а проблемы все те же. При этом у GraphQL есть ряд преимуществ: вложенные запросы, типизация, версионирование, возможность подписки на обновления данных (стандартизированная), разделение запросов и мутаций на уровне схемы, документация на уровне схемы, ну и куча тулинга на любой вкус и язык, хотя и на JSON-RPC его не мало, но банальной интеграции с девтулзами, чтобы нормально видеть запросы, я так и не нашел.
В общем, не понимаю зачем выбирать JSON-RPC вместо GraphQL сегодняVolCh
27.02.2019 14:40Разделение запросов и мутаций для вас, видимо, плюс, а для кого-то минус. Главное преимущество RPC (любого) — это вызов процедур.
Pydeg
27.02.2019 14:49Не представляю в каком случае может быть минусом возможность сразу определить идемпотентность запроса. В RPC получение и модификацию данных также разделяют, только с помощью префиксов (fetch/get и т.д.), документации и других нестандартизированных договоренностей, которые меняются от реализации к реализации.
powerman
27.02.2019 17:43Я немного экспериментировал с добавлением в имена RPC-методов префиксов Safe и Idemp, чтобы на клиенте было проще реализовать единообразную обработку некоторых типов ошибок. Клиент писал не я, но, по-моему, принципиальной разницы это не дало. Прикол идемпотентных REST-запросов не столько в том, что их можно повторить, сколько в том, что их повторят автоматически без нашего участия (браузер) — а в случае RPC прикол в том, что без нашего участия почти ничего не делается, больше контроль над происходящим но и больше ручной работы, в т.ч. обработки сетевых ошибок. А раз код обработки этих ошибок всё-равно надо писать, ручная автоматизация повтора части запросов в случае достаточно редких сетевых ошибок оказывается не настолько полезной, чтобы на это сильно заморачиваться.

igrishaev
27.02.2019 14:34+1Согласен. REST бесит тем, что данные размазаны по всему запросу. Параметры пути, query args, JSON-тело, заголовки… а в случае с RPC все в одном месте. Стандарта нет, всегда срач. Никогда не знаешь, какой метод выбрать — PUT, PATCH, etc.
Еще удобно, что тело RPC-запроса легко отдать в очередь типа Кафки и процессить воркерами.
Pydeg
27.02.2019 14:56+1Никогда не знаешь, какой метод выбрать — PUT, PATCH
PUT — замена ресурса или создание в случае отсутствия (RFC 7231)
PATCH — изменение ресурса в случае наличия (RFC 5789)igrishaev
27.02.2019 14:59Спасибо, я в курсе. Я имел в виду сложные случаи, когда апишка изменяет сразу несколько сущностей разных типов.
Pydeg
27.02.2019 15:09-1Разве REST предполагает такой сценарий использования? Batching же никак не стандартизирован, насколько мне известно. Есть только вот такой draft http-way батчинга, с ним никаких проблем не должно возникнуть
igrishaev
27.02.2019 15:22+1При чем тут батчинг? У вас может быть такая бизнес-операция, которая меняет несколько разных сущностей.
Кстати, вы напомнили про еще одну беду REST. Что якобы сущности изменяются отдельно друг от друга, а это не так.
Pydeg
27.02.2019 15:43У вас может быть такая бизнес-операция, которая меняет несколько разных сущностей
В REST такая операция дожна быть отдельным ресурсом, поскольку за один запрос вы можете производить какое-либо действие только над одним ресурсом/коллекцией ресурсовmichael_vostrikov
27.02.2019 21:02Ага, вместо "POST someComplexAction" с одним ответом делаем "GET/POST/UPDATE/DELETE someComplexActionRequest" с разными. В чем профит?

rpiontik
27.02.2019 15:47+3Мдя… я не понял почему статья противопоставляет REST и RPC. Т.е. на безе REST не может быть RPC? Скажу как есть — может. И часто реализуется, как внутренние типизированные интерфейсы. Например на базе REST есть шлюз /prc/ который реализует собственно rpc путем нескольких REST методов.
Суть самого определения RPC это удаленный вызов процедур. Как не банально это звучит. Он не заменяет REST который — архитектурный стиль взаимодействия компонентов распределённого приложения в сети. Нужно ли говорить, что вызов REST не подразумевает вызов конкретной процедуры?
RPC вводит жесткие ограничения, которые удобны по ряду причин в бизнес-приложениях. Но он убивает взаимодействие с транспортным слоем, т.к. является транспорто-независимым. Это его сильная и слабая сторона одновременно.
RPC можно прекрасно поднять на WEBScoket канале. И очень эффективно реализовать его потенциал для online коммуникации с сервером. REST тут в принципе не может быть. Это нонсенс.
RPC очень полезная штука, но я бы сказал в совокупности с манифестами. Это позволяет держать консистентным канал связи клиента и сервера, а также, решает проблему документирования и развития интерфейса. Для бизнес-приложений с множественными интеграциями server-server по прямым каналам связи очень полезная штука.
На REST следует останавливаться тогда, когда вы делаете именно — взаимодействие компонентов распределённого приложения в сети. Т.к. REST предполагает влияние вашей бизнес-логики на транспортный слой. И это должен быть осмысленный выбор в его пользу.
cross_join
27.02.2019 15:48Возьмите тогда уж SOAP, там будет вообще всё: от WSDL до отсутствия нужды реализовывать протокол на клиенте. А там, глядишь, и CORBA захочется.
igordata
27.02.2019 15:50REST тем хорош, что как раз никакой схемы нет — там поменял, сям поменял, бац-бац и в продакшн.
bat
27.02.2019 16:49xml слишком многословен и затратен при кодировании/декодировании
kzhyg
27.02.2019 22:47Ваш софт работает настолько быстро, что парсер становится узким местом?
bat
28.02.2019 06:51а вы про какой софт?
для клиентского это не критично, а для серверного вполне может быть узким местом.
Например, для API Gateway это критично. Это критично для сервиса, который оперирует данными в памяти.kzhyg
28.02.2019 12:16В этом случае вам, пожалуй, стоит отказаться от RPC и прочей автоматики, и, возможно, перейти на
REST«классический» HTTP API, а не экономить на спичках.bat
28.02.2019 13:241. разговор шел json vs xml без относительно протокола, по которому они передаются
2. как будто HTTP парсить не надоkzhyg
28.02.2019 17:111. Нет. Поскольку никто не определил условия эксперимента, разговор ведётся в контексте статьи, а она про веб. А если да, то предмет спора мне неинтересен.
2. Как будто при передаче данных через JSON/XML нижележащий HTTP парсить не надо.

Clevik
28.02.2019 13:10В моем текущем проекте софт при некоторых условиях должен делать полную синхронизацию. Это значит что надо вытащить через API все данные по клинике и распарсить их. Затраты времени на парсинг большого объема данных в соотношении ко времени передачи — 2 к 1.
При обычной работе объем данных на один запрос мал и соотношение обратное 1 к 2 (парсится быстрее чем передается). А вот полная синхронизация может занимать несколько минут — суммарно на сотню запросов может уйти 1-2 минуты на передачу + 2-4 минуты на парсинг.
Выход конечно найден, но факт есть факт. Когда надо вытянуть всю информацию по нескольким сотням клиентов за раз — текстовый формат передачи не очень подходит.kzhyg
28.02.2019 17:24Импортирую большие объёмы данных (сотни мегабайт) на Android, картина противоположная. Парсинг XML и маппинг на объекты занимает 20% времени, запись в БД и сопутствующие расходы — 80. Я понимаю, что SQLite и ORMLite — не лучший выбор с точки зрения производительности, но факт есть факт)
Алсо, примерно все СУБД возвращают результаты запроса в промежуточном текстовом формате,что печально.
igordata
27.02.2019 15:49+4REST API должно вроде как реализовывать HATEOAS, и не может быть заменено в этой части на RPC-протоколы.
HATEOAS в теории позволяет машинам читать REST API и безо всяких там документаций. В реальности REST API, поддерживающих HATEOAS, почти нет от слова совсем — их считанные единицы. А всё то, что мы называем REST API просто случайный набор эндпоинтов, которые мы именуем, как душе угодно, и описываем это всё в лучшем случае только в документации.
Если это учитывать, то становится понятно, что нет никакой разницы, где именно мы напишем ключевые слова — в урле или в json-пакете.
На мой взгляд, получить HTTP 200 с ошибкой внутри — правильно, т.к. HTTP в данном случае выступает как транспортный протокол. Но это уже дело вкуса, т.к. ложки-то не существует.yayashitoya
27.02.2019 16:02REST API должно вроде как реализовывать HATEOAS, и не может быть заменено в этой части на RPC-протоколы.
Почему?
Ведь тут дело всего лишь в ответе.
Любой способ можно использовать, он все так же может возвращать в ответе дополнительную информацию «что делать еще».igordata
27.02.2019 17:34Но это будет уже не REST, а просто «какое-то API на HTTP», вот в чем соль. В концепции REST обязательно возвращать все возможные действия и ссылки на ресурсы в каждом ответе :D И в этом как раз вся суть REST, и без этого это действительно «просто API over HTTP», что мы и наблюдаем в действительности. Без этой приписки к ответу требуется писать доку (полюбому же писать) и тогда у такого API нет объективных преимуществ перед RPC — только концептуальные и субъективные (вкусовщина).
А так как один хрен доку писать и это какое-то безумие в каждый ответ вкладывать полный список возможных действий и урлов — то это никто и не делает. В итоге мы имеем что имеем — зоопарк реализаций, подходов и даже философий.
И это хорошо. Лучше делать как удобно конкретному проекту, чем корчиться в угоду некой философии.
lega
27.02.2019 16:22Несколько вопросов:
1. Eсть ли какие-то консольные утилиты для «jsonrpc over tcp» на подобии curl?
2. Есть ли «keep-alive» режим? Понятно, что от стандарта это не зависит, но реализуют ли это авторы библиотек?
3. Как передавать бинарные данные? Конвертация в base64 ведет к распуханию и падению производительности, какие есть «бест-практис» в этом плане?mayorovp
27.02.2019 16:48Eсть ли какие-то консольные утилиты для «jsonrpc over tcp» на подобии curl?
А чем nc (netcat) не устраивает?
powerman
27.02.2019 17:59+1- Ответили выше —
echo '{"jsonrpc":"2.0",…}' | nc host port. Либо за 15 минут пишется своя тулза, если нужен более удобный UI. - KeepAlive для самого RPC не требуется, он stateless. Но если это нужно на уровне приложения (напр. это чат и нужно знать что юзер ещё онлайн) то делается отдельный RPC-метод "ping", который клиент должен периодически вызывать. Если это нужно на уровне транспорта, обычно в случае TCP, то на сокете включается штатный keep-alive средствами OS (слой бизнес-логики/RPC об этом не знает).
- В JSON нет поддержки бинарных данных, поэтому либо base64 (обычно для однозначности в доке API нужно ещё указать какой именно вариант base64 и нужно ли выравнивание), либо, для передачи больших объёмов данных (вроде видео), используется HTTP или REST, а на уровне RPC бегают только соответствующие url-ки.
lega
27.02.2019 19:072. Речь не про stateless, а про скорость, с keep-alive может работать на порядок быстрее т.к. не нужно создавать коннект на каждый запрос.
3. Как вариант, для «over http» можно бинарь вкладывать вторым в multipart, тогда и json и бинарные данные полетят в одном запросе.powerman
27.02.2019 19:15+1Какие коннекты, протокол-то транспорто-независимый и про коннекты ничего не знает. Вы можете открыть одно TCP-соединение, после чего отправлять по нему RPC-запросы и ответы на них хоть год. Более того, обе стороны могут одновременно быть и клиентом и сервером, и отправлять запросы друг-другу всё по тому же одному соединению. Всё, что для этого необходимо (мультиплексирование запросов в одном соединении) в протоколе уже есть — это поле
"id".
multipart это плохой вариант, потому что на уровне RPC-сервиса доступа к транспортному уровню нет, так что добраться до второй части multipart не получится.
lega
27.02.2019 19:34Какие коннекты, протокол-то транспорто-независимый и про коннекты ничего не знает.
Я про это указал в вопросе.
Вы можете открыть одно TCP-соединение, после чего отправлять по нему RPC-запросы и ответы на них хоть год
Если библиотеки не поддерживают потоковую обработку json, т.е. если пришел не весь кусок json или несколько json слипились в один пакет и т.п., тогда это нельзя сделать с текущими либами и нужно писать свой велосипед.
multipart это плохой вариант, потому что на уровне RPC-сервиса доступа к транспортному уровню нет
Вы же говорите, что «протокол-то транспорто-независимый»powerman
27.02.2019 19:57Если библиотеки не поддерживают потоковую обработку json
Какие именно библиотеки? Библиотеки для JSON RPC 2.0 — да, не поддерживают (точнее, если их написали корректно — транспорто-независимо — то не поддерживают). Библиотеки для транспорта — ну так транспорт для JSON RPC 2.0 не стандартизирован (не считая HTTP), так что каждый сам придумывает себе транспорт и пишет под него библиотеку, если есть что писать.
В случае TCP обычно делают одно из двух: либо сериализуют JSON "в одну строку", чтобы внутри гарантированно не было переводов строк, и при передаче добавляют перевод строки после каждого запроса/ответа (а "библиотека для транспорта" читает построчно и "библиотеке для JSON RPC 2.0" отдаёт отдельные строки-запросы/ответы), либо сериализуют как попало и используют потоковый парсер JSON в "библиотеке для транспорта".
Что Вам неясно насчёт multipart я не понял.
bat
27.02.2019 19:362. я так понимаю вопрос про jsonrpc over http
со стороны сервра: сервис обычно спрятан за каким-нибудь nginx, который умеет HTTP 1.1, если напрямую, например, в локалке, зависит от ЯП или фреймворка, но обычно проблем с этим нет
со стороны клиента: строится так же на базе уже готового http клиента, который умеет HTTP 1.1
- Ответили выше —
Kroid
27.02.2019 19:08+1Насчет кеширования и прочего middleware.
Как вариант, в случае использования http протокола, можно просто использовать часть url вместо ключа method в json'e запроса. К примеру `http://site.com/rpc/:method_name`. А в приложении первым делом парсить этот юрл, превращать запрос в стандартный json-rpc формат и передавать дальше в бизнес логику.
Плюс будет в том, что nginx, метрики и прочие штуки, которые стоят между клиентом и непосредственно приложением бизнес логики, смогут продолжать заниматься своими делами безо всяких переделок под rpc.
Ну а минус в том, что велосипед.
rgs350
27.02.2019 19:31Еще один стандарт. Я не против стандартов, но вы в очередной раз пытаетесь загнать в жесткие рамки крайне простую вещь, которая даже не будучи стандартизованной вряд ли вызовет проблемы в конкретном проекте.
trawl
28.02.2019 06:29Эта спецификация предложена ещё в 2009 году.
rgs350
28.02.2019 08:49Эта спецификация предложена ещё в 2009 году.
А можно еще какой-нибудь ГОСТ 70-х готов откопать. Уверен, что если поискать, то можно что-нибудь найти. Сей стандарт можно уместить в две строки:
— Запрос делай так…
— Ответ делай так…
И сразу возникает несколько вопросов:
— А вдруг мы хотим передавать метод в URL.
— Нам не нужно два свойства для ошибки, а достаточно одного.
(еще очень много вопросов)
На эти случаи будем другие стандарты писать?trawl
28.02.2019 08:57А можно еще какой-нибудь ГОСТ 70-х готов откопать.
Можно. Если стандарт хорош под ваши задачи, почему бы и не придержаться его?
И сразу возникает несколько вопросов:
— А вдруг мы хотим передавать метод в URL.
— Нам не нужно два свойства для ошибки, а достаточно одного.
(еще очень много вопросов)
На эти случаи будем другие стандарты писать?Либо искать другие, потому что данный в этих условиях не подходит, либо писать другой, да.
lega
27.02.2019 19:47Ещё такой вопрос, допустим вы запустили json-rpc сервис на нескольких серверах и сбалансировали через nginx (или через что-нибудь другое), и нужно вызвать одну процедуру но на всех запущенных серверах (типа pubsub с ответом).
Как бы вы это решили? Дополнительно внедрять MQ-сервис (rabbitmq/...) для этой процедуры или как?
(И ещё вариант если нет прямого доступа к серверам, только через балансер).powerman
27.02.2019 20:04Пишем сервис-прокси, который скроет от клиента эти подробности — клиент пришлёт один RPC в этот прокси (любой из его инстансов, если их тоже несколько на разных серверах), а уже проксик подключится ко всем запущенным серверам и выполнит для клиента нужную операцию на каждом из них.
sergey_prokofiev
27.02.2019 21:55Все каменты не асилил, возможно повторяюсь или просто работаю капитаном очевидность.
1.
Если взять аббревиатуру REST и расшифровать ее, то получим Representational State Transfer — «передача состояния представления» — тоесть есть некоторые ресурсы(чего в определении нет, но про это написано много) и протокол направлен на то, чтобы просто и эффективно передавать состояние этих ресурсов между клиентом и сервером. То есть надо всего лишь передавать состояние ресурсов и команды на их изменение. Это можно сравнить с CRUD операциями в СУБД. К слову, это помогает автоматизировать типичные операции в например админках.
2.
С другой стороны, если расшифровать RPC, то получим Remote Procedure Call, тоесть вызов некоторой «подпрограммы» на удаленном сервере, которая делает какую то сложную магию. Это можно сравнить с бизнес операциями над СУБД, состоящих из нескольких(десятков) CRUD над разными таблицами и еще много чего. И да, батчи тут очень даже к месту.
3.
Поэтому, с моей точки зрения не надо натягивать сову на глобус и искать серебрянную пулю. Я думаю что тезис «все в вебе есть ресурс и его состояния» рано или поздно приведет к проблемам, равно как и тезис «давайте делать по RPC на выборку каждой сущности по ID» в проектах больше HelloWorld.funca
27.02.2019 22:08Representational State Transfer — «передача состояния представления» — тоесть есть некоторые ресурсы(чего в определении нет, но про это написано много)
определение ресурса есть в https://tools.ietf.org/html/rfc3986sergey_prokofiev
27.02.2019 22:16Да, прям оттуда:
This specification does not limit the scope of what might be a resource; rather, the term «resource» is used in a general sense for whatever might be identified by a URI.
Сферические кони в вакууме — ни больше ни меньше, что в принципе логично для столь обобщенной спецификации.
funca
27.02.2019 22:32+1История с REST API чем то похожа на другие классные штуки, как например чисто функциональное программирование или нормализация данных. Архитектура, построенная на простых принципах, но непростая в понимании и имплементации. Это порождает перманентное желание срезать углы при разработке. Желание понятное, главное правильно оценивать pros & cons.
bevalorous
28.02.2019 08:18Как в JSON-RPC реализовать валидацию форм — удобную и без велосипедов? В REST можно прислать общий код «Форма не верна» (422, например), а в теле ответа — массив/объект с информацией обо всех полях, заполненных ошибочно, после чего клиент легко и просто отображает ошибки на соответствующих полях.
Какая best practise для этого в JSON-RPC? Присылать по одной ошибке для каждого неверно заполненного поля, пока все они не окажутся заполненными правильно? Или изобрести свой формат поля data для подобного случая? Есть ли примеры готовой реализации?Rsa97
28.02.2019 08:22+2А чем не устраивает запись того же «массива/объекта с информацией обо всех полях, заполненных ошибочно» в поле data?
bevalorous
28.02.2019 09:08Вполне устраивает. Просто для REST у меня была готовая реализация от фреймворка, где в случае ошибок валидации формы сериализатор выставлял в ответе нужный HTTP-код (422) и формировал нужную структуру массива ошибок полей формы. А в случае JSON-RPC пришлось писать подобный сериализатор самому.
trawl
28.02.2019 09:06В REST можно прислать общий код «Форма не верна» (422, например), а в теле ответа — массив/объект с информацией обо всех полях, заполненных ошибочно, после чего клиент легко и просто отображает ошибки на соответствующих полях.
например так:
{ "jsonrpc": "2.0", "error": { "code": -32602, "message": "Invalid params", "data": [ { "field": "login", "message": "Логин уже занят" }, { "field": "name", "message": "Имя может состоять только из буквенных символов" } ] }, "id": "1" }bevalorous
28.02.2019 09:09Да, ровно так и сделано: InvalidParams (-32602) для индикации ошибок во входных данных (поля формы в данном случае).
bevalorous
28.02.2019 09:17Еще один подводный камень, с которым вы, скорее всего, столкнетесь при работе с JSON RPC на стороне клиента — довольно скудный набор клиентских библиотек. Если же вы используете JSON-RPC over HTTP и хотите применять стандартную клиентскую библиотеку для сетевых запросов, вы столкнетесь с необходимостью переопределить то, что считается ошибкой и что — успешным запросом: в HTTP-клиенте эти ситуации различаются обычно по HTTP-коду (2хх и 3хх — все ОК, 4хх и 5хх — ошибка), а в JSON-RPC код будет почти всегда равен 200, а для различения error/success придется проанализировать тело ответа: если в наличии поле result — то запрос завершился успехом, если поле error — ошибкой.
lega
28.02.2019 13:09код будет почти всегда равен 200
Для ошибок можно отправлять 400, завист от реализации
VolCh
28.02.2019 13:42Некоторые клиентские библиотеки считают любой HTTP ответ успешным, их нужно дополнительно конфигурировать или вообще оборачивать, чтобы некоторые HTTP-коды бросали исключение, реджектили промис и т. п. Собственно, если это HTTP-библиотека, то это правильный подход.
mspain
28.02.2019 09:49-1Уф, я думал я один такой. :) REST вообще ни разу не использовал. Для сложных сервисов SOAP намного лучше, для остальных «колхоз» из servlet+JSON/XML.


wtpltd
Сломано копий и разбито щитов в баталиях славных! Поднимем же кубки за тех героев отважных, осмелившихся бросить вызов богам по протоколу HTTP!
Понапридумано и понаобсуждено и понахоливарено столько вокруг старичка, что каждый для себя сам может выбрать удобный подход для своего вполне конкретного проекта.
А ложки нет.