
Алгоритмы RAID были представлены общественности в далеком 1987 году. По сей день они остаются наиболее востребованной технологией защиты и ускорения доступа к данным в сфере хранения информации. Но возраст IT технологии, перешагнувшей 30-ти летний рубеж, – это скорее не зрелость, а уже старость. Причиной является прогресс, неумолимо несущий в себе новые возможности. Во времена, когда фактически не было иных накопителей, кроме HDD, алгоритмы RAID позволяли наиболее эффективно использовать имеющиеся ресурсы хранения. Однако с появлением SSD ситуация коренным образом поменялась. Сейчас RAID при работе с твердотельными накопителями является уже «удавкой» на их производительности. Поэтому для раскрытия полного потенциала скоростных характеристик SSD просто необходим совершенно иной подход к работе с ними.

Помимо явных отличий HDD и SSD в принципах работы, у данных типов носителей есть и еще одна важная характеристика: любой жесткий диск может перезаписывать любые данные с гранулярностью в один блок (сейчас это чаще всего 4КБ). Для SSD же процесс перезаписи представляет собой куда более сложную процедуру:
- Измененные данные копируются в новое место. При этом гранулярность – тот же блок, но состоящий из нескольких страниц и имеющий размер 256КБ — 4МБ. Т.е. при изменении тех же 4КБ необходимо скопировать в том числе и все соседние страницы, образующие собой единый блок.
- «Старые» блоки пометить в качестве неиспользуемых, чтобы потом затереть сборщиком «мусора» (Garbage Collector).
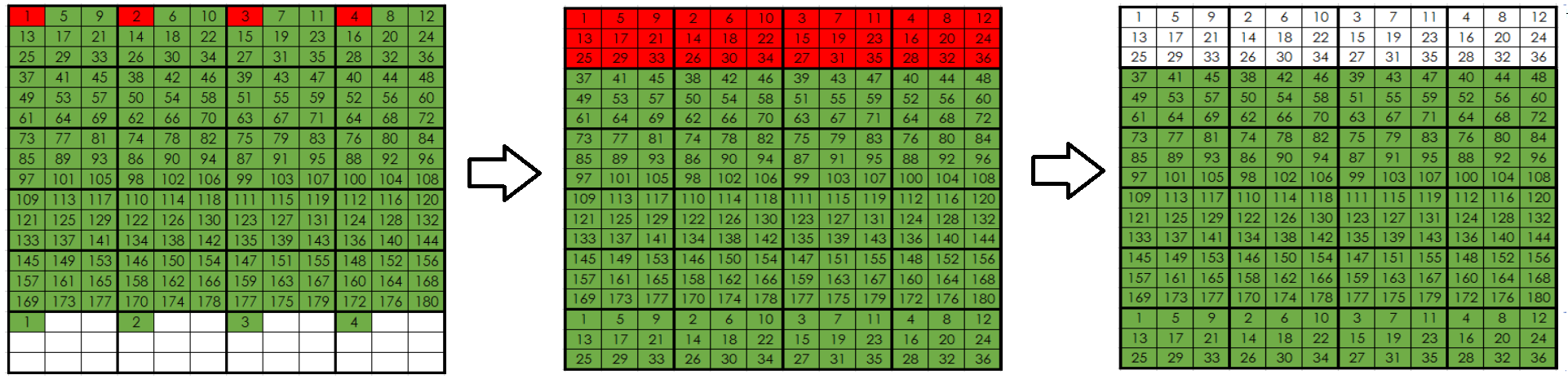
Последовательная запись/перезапись на SSD
В случае последовательной записи/перезаписи данная особенность функционирования SSD не играет большой роли с точки зрения его производительности, т.к. блоки расположены рядом, и сборщик «мусора» вполне справляется со своей работой в фоновом режиме. Но в реальной жизни, а уж тем более в Enterprise сегменте для SSD чаще всего используется случайный доступ к данным. И эти данные пишутся в произвольные места на накопителях.
Чем больше данных пишется на SSD, тем труднее работать сборщику «мусора», поскольку сильно растет фрагментация. В результате настает тот момент, когда процесс очистки накопителя перестает быть «фоновым»: производительность SSD значительно падает, т.к. заметную ее часть забирает Garbage Collector.
Реальное расположение данных на SSD при повседневном использовании
Для иллюстрации эффекта влияния работы сборщика «мусора» в зависимости от режима записи на накопитель можно провести простейшие тесты: последовательная и случайная запись блоками 4КБ на 100ГБ накопитель. (Источник – компания Micron)

Производительность при последовательной записи
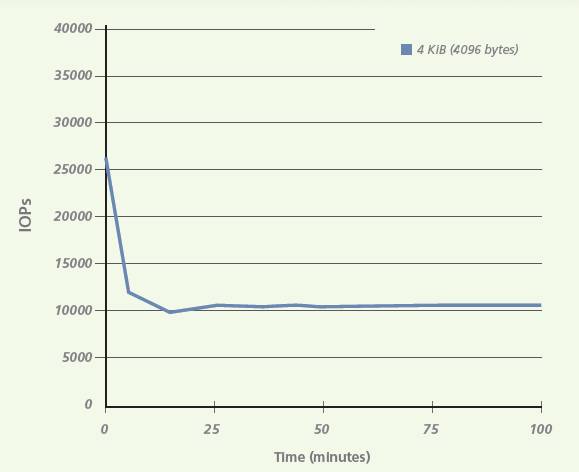
Производительность при случайной записи
Как видно из тестов, падение производительности может достигать более двух раз. И это всего лишь одиночный накопитель. В случае использования SSD в составе RAID группы количество операций перезаписи сильно возрастает, благодаря работе с parity.
Вообще, благодаря этим особенностям работы SSD, для них существует такой параметр, как коэффициент записи (write amplification). Это – соотношение объема данных, записанных на накопитель, к объему данных, которые на самом деле отправил хост. И для наиболее популярного RAID5 этот коэффициент равен ~3.5.
В итоге системы с классическим RAID в своей основе утилизируют SSD только ~10% от их реальной скорости и слабо масштабируются по производительности при увеличении количества накопителей более десятка.
Также отметим, что избыточные операции записи не только снижают производительность SSD, но и уменьшают его далеко не бесконечный ресурс, сокращая тем самым срок службы накопителя.
Технология FlexiRemap®, являющаяся ядром всех продуктов AccelStor, как раз и разработана в качестве альтернативы классическим алгоритмам RAID при работе с SSD. Инновационность технологии отмечена как различными патентами и наградами (в том числе на Flash Memory Summit 2016), так и результатами независимых тестов (например, SPC1).
Суть FlexiRemap® состоит в преобразовании всех поступающих запросов на запись, и главным образом типа random, в набор блоков, максимально похожего на режим последовательной записи с точки зрения накопителя. В результате запись на SSD происходит в максимально комфортном для них режиме, а итоговая производительность превышает любые системы с классическим RAID.
Все SSD в системах AccelStor делятся на две симметричные группы FlexiRemap®. Размер группы зависит от модели и составляет 5-11 накопителей. Для отказоустойчивости внутри группы применяется parity подобно RAID5. Обе группы используются совместно, образуя общее пространство хранения. Поэтому итоговая отказоустойчивость будет аналогична массиву RAID50, состоящего из двух групп: система способна выдержать отказ до двух SSD, но не более одного в каждой группе FlexiRemap®.
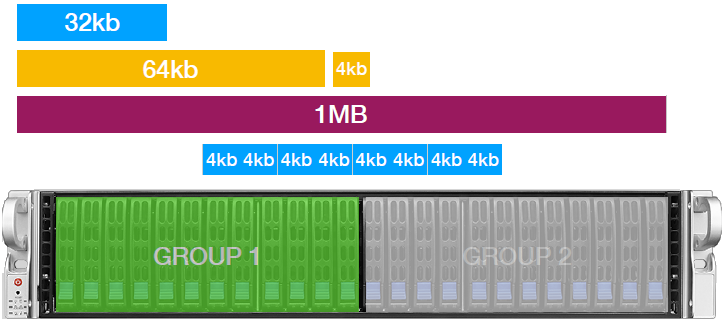
Все поступающие запросы на запись дробятся на блоки размером 4КБ, которые в режиме round robin записываются на обе группы FlexiRemap®. При этом система постоянно ведет учет востребованности записанных блоков, стараясь при их изменении записывать подобные блоки максимально близко друг к другу. Получается виртуальный аналог тиринга, если выражаться в терминах СХД. В этом случае значительно облегчается работа сборщика «мусора»: ведь неиспользуемые блоки постоянно будут находиться рядом.
Стоит отметить, что системы AccelStor в отличие от продукции конкурентов не используют функционал кэширования входящих запросов в оперативной памяти контроллера. Все поступающие блоки данных немедленно записываются на SSD. Хост получает подтверждение об успешной записи только после физического размещения данных на накопителях. В RAM хранятся лишь таблицы размещения блоков на SSD для ускорения доступа и определения, куда записать очередной блок данных. Разумеется, для надежности копии этих таблиц расположены и на самих носителях. В результате системам AccelStor не требуется никакая защита кэша в виде батареи/конденсатора (впрочем, возможность установить связь с ИБП имеется – для «мягкого» выключения в случае проблем с электропитанием).
Благодаря подобному подходу к организации записи, сборщик «мусора» действительно способен работать в фоновом режиме, не оказывая существенного влияния на скорость накопителей, что в итоге позволяет в рамках системы утилизировать до 90% производительности SSD. Именно в этом заключается высокие показатели IOPS в системах AccelStor на фоне All Flash, имеющих в основе RAID алгоритмы.
Также важной особенностью технологии FlexiRemap® является значительное сокращение избыточных операций записи на SSD. Так коэффициент записи (write amplification) для систем AccelStor составляет всего 1.3, что в переводе на общепринятый язык означает увеличение срока службы накопителей по сравнению с RAID5 более чем в 2.5 раза!

Благодаря постоянному контролю со стороны системы за политикой размещения данных на SSD, все накопители изнашиваются одинаково. Такой подход позволяет спрогнозировать их срок службы и заранее подать сигнал администратору об исчерпании ресурса записи.
Понятно, что SSD могут выйти из строя. В таком случае система немедленно начнет ребилд на один из дисков hot spare. При этом группа FlexiRemap®, находящаяся в состоянии degraded, переходит в режим «только для чтения», а все запросы на запись направляются на вторую группу. Такой механизм защиты предусмотрен для ускорения операции ребилда и снижения вероятности выхода из строя еще одного накопителя в рамках той же группы. Ведь не секрет, что во время ребилда все накопители в составе группы испытывают повышенную нагрузку из-за интерференций операций чтения, записи и восстановления на hot spare. Тем самым повышается вероятность отказа еще одного диска. И чем больше операций записи, тем дольше будет производиться ребилд.
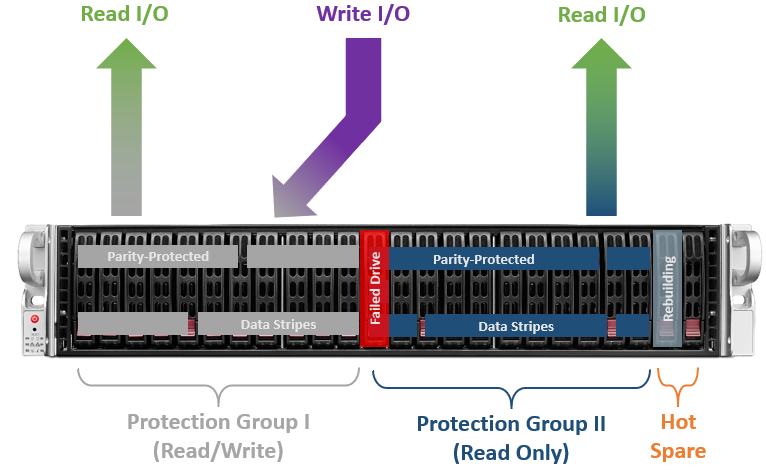
После завершения процесса восстановления и возврат группы FlexiRemap® в нормальное состояние возникнет небольшой перекос в ресурсе записи между двумя группами. Поэтому для его выравнивания последующие операции записи будут чаще приходиться на восстановленную группу (разумеется, с таким расчетом, чтобы итоговая производительность системы не сильно страдала).
Увеличить производительность All Flash систем, основанных на алгоритмах RAID, выше некоторых значений (~280K IOPS@4K random write) не получается даже при использовании сложных систем кэширования. Технология FlexiRemap®, благодаря абсолютно иному подходу к организации пространства хранения, не только с легкостью преодолевает этот барьер, но и попутно увеличивает в несколько раз срок службы SSD. Так что системы AccelStor имеют серьезные преимущества среди All Flash массивов по многим фронтам (IOPS/$, GB/$, TCO, ROI), делая их идеальными кандидатами на ключевые позиции в датацентрах заказчиков для решения ресурсоемких задач.
Комментарии (19)

nApoBo3
27.03.2019 10:54А всего-то надо забросить raid5 на свалку истории и забыть как страшный сон.
AccelStor Автор
27.03.2019 10:59У RAID1 хоть и ниже penalty тоже хватает недостатков в плане разброса блоков с данными по накопителю.

IgorPie
27.03.2019 18:21не получится. У каждого SSD свои мозги и сквозной оптимизации все равно не выйдет. Производители просто не покажут что там под капотом.
nApoBo3
27.03.2019 21:59Ну так и у предложенного решения ее не будет.
AccelStor Автор
28.03.2019 09:12Разумеется, внутрь SSD не удастся «влезть». Но перегруппировать входящие данные так, чтобы накопитель думал, будто бы на него в последовательном режиме пишут, возможно. Что, собственно, и реализовано.
nApoBo3
28.03.2019 11:53ИМХО это еще хуже. Пытаться перемудрить контроллер накопителя учитывая, что у него внутри совершенно не тривиальные алгоритмы, да и организация памяти может иметь множество вариантов.
Плюс на все это наложить ограничения рэйдов высокого уровня которые очень критичны к отказам при ребилде. Идя прямо скажем не очень.
Хочется управлять накопителями, нужно с производителем работать над прошивкой, другие варианты чреваты.AccelStor Автор
28.03.2019 12:14Основная идея — не перехитрить контроллер накопителя, а подстроиться под его режим работы, ведя учет за расположением данных на нем.
nApoBo3
28.03.2019 14:01Для этого вы должны уметь предсказывать его поведение. А для этого вы должны иметь доступ к алгоритмам которые в него заложены.
AccelStor Автор
28.03.2019 14:39Так доступ к глубинным алгоритмам и не требуется. При последовательной работе записи/перезаписи поведение одинаково для всех современных накопителей. Если есть разница, например, в триггерах, по которым работает «сборщик мусора», то в глобальном смысле это не так уж и важно, т.к. на общую производительность данное обстоятельство слабо влияет.
AlexTOPMAN
27.03.2019 11:10А что мешает просто собирать поступающие друг за другом на запись случайные запросы и записывать их только блоком по мере его наполнения, помечая неактивным только старый адрес перезаписанных данных (а сами данные пусть там пока остаются)? А по мере прохождения критической массы либо изменений в конкретном блоке, либо сокращения свободного места на накопителе/группе накопителей, либо снижении интенсивности запросов на запись ниже предельной (освобождение очереди и переход в idle) заняться чтением и перезаписью блоков с наибольшим числом устаревших адресов. При таком подходе явно же сократится общее число необходимых операций перезаписи, а высвобождающееся таким образом время доступности накопителя, как раз позволит спокойнее и чаще заниматься менеджментом «старых адресов». Цена вопроса — всего лишь некоторый (оперативный, но обязательный) запас свободного места на накопителе.
AccelStor Автор
27.03.2019 11:30Не берусь в полной мере оценивать эффективность вашего метода. Вполне возможно, что это будет работать. Тем более, что в некотором приближении напоминает подход Nettap. Но в наших продуктах применен описанный в статье механизм.
angel_zar
27.03.2019 14:01А так ли важен сборщик «мусора» в Энтерпрайз сегменте?
Все проблемы SSD выходят из того, что есть новая технология, но в целях совместимости ее используют как HDD, а чтоб продлить срок службы и тому подобное, прозрачно для пользователя, в контролеры вшивают непонятный функционал, который потом вываливается в тормоза.
От сильно умных контроллеров в SSD надо избавляться и переносить логику на файловую систему, нужны новые ФС, вроде как NTFSfromSSD, ext3/4fromSDD или просто новая SSDFS, и контроллеры RAID должны научится вести себя по другому с SSD.
п.с. это моя точка зрения, может я и не прав.
Oz_Alex
28.03.2019 04:45Ребят, у вас там всё хорошо?
Как так получилось, что у компании, продвигающей передовую технологию, сайт работает по http, а https://accelstor.ru говорит «It works» и сертификат там некорректный?
Это ведь даже не nginx, это apache.

IgorPie
Как восстанавливать данные, если все диски целы, а, например, в контроллер попал метеорит?
Где хранятся данные о расположении блоков?
AccelStor Автор
На дисках конечно. В случае замены контроллера данные будут полностью доступны.
IgorPie
Не окажется область хранения данных о блоках точкой ненадежности? Или она тоже перемещается для равномерного износа?
AccelStor Автор
Не так уж и страшно, что данные на SSD пишутся в одно и то же место, т.к. в случае износа этого пространства блоки ремапятся из резервного объема накопителя.