

Поводом для написания статьи стала непонятно как сложившаяся традиция, что при создании бэкапов хранилищем может выступать какой угодно хлам, и отчего-то ставшее нормой явление, когда единственной учитываемой характеристикой является цена оборудования. Причем желательно, чтобы за три выделенных копейки там были резиновые диски из самой тягучей резины. В самом лучшем случае могут ещё обратить внимание на заявленную производителем скорость работы, причём даже не задумываясь, что же за цифру показали и к чему она относится. Чем больше цифра, тем лучше, тут даже сомневаться не стоит.
Вот только проблема заключается в том, что некоторые режимы создания бэкапов предъявляют к хранилищам очень серьёзные требования по скорости чтения и/или записи, не забывая общую стабильность. А это значит, что если не учитывать их на этапе планирования, то можно в лучшем случае получить еле живую систему, а в худшем отправиться покупать новое оборудование за счёт своей премии.
Под катом я постараюсь объяснить, как заранее спрогнозировать поведение хранилища, исходя из вашего плана резервного копирования, а также на деле доказать, что выбирать хранилище для бэкапов по остаточному принципу – это порочная практика.
Быстрая и лёгкая матчасть
Как мы все прекрасно знаем, любое оборудование надо подбирать, исходя из предъявляемых к нему требований. Требования рождаются из того рода задач, которые будут решаться с помощью данного оборудования. В этом посте мы будем рассматривать конкретные сценарии работы решения Veeam Backup & Replication v8, но описанные ниже методики легко применяются и к работе вашего любимого софта.
В нашем случае нет необходимости использовать какое-то специализированное оборудование. Некоторые администраторы пытаются, например, использовать массивы с встроенным дедуплицированием данных — ибо «больше данных на дисках того же размера», — но быстро перестают делать это, столкнувшись с реальностью.
А для любого хранилища общего назначения достаточно учитывать всего два параметра — это объём и производительность. И если с первым всё понятно и не требуется дополнительных комментариев, то на втором обязательно надо заострить внимание. И масса статей про эту тему на Хабре — тому доказательство.
Многие ошибочно считают, что производительность накопителя — это некая характеристика, измеряемая в объёме переданных куда-то данных. Или, может быть, считанных данных, или (бывает даже такое!) времени случайного доступа. Все эти характеристики замечательны и прекрасны, но что в общем случае для вашей продакшн системы будет значить, если у нас большая скорость записи, маленькая скорость чтения и посредственное время доступа? А как это сравнить с вариантом, когда быстрое чтение, быстрая запись, но время доступа в два раза больше, а стоимость та же? Нужна комплексная характеристика, которая в одной, безотносительной цифре однозначно охарактеризует данное конкретное хранилище. И называется такая характеристика IOPS — количество операций ввода-вывода в секунду. Остаётся последний вопрос — как грамотно его измерять применительно к своим задачам.
И здесь нам открывается крайне важная истина — тестирование обязательно должно быть растянуто во времени. И чем дольше хранилище проведёт под нагрузочным тестом, тем более правильную картину мира вы получите. Классический пример, это NAS-накопители начального уровня, у которых показатель IOPS, полученный за 5 минут, будет отличаются на порядок или два от показателя, полученного после теста длинной в полчаса. А бэкап может длиться намного дольше, чем тридцать минут.
Небольшая ремарка про NAS и бэкапы
Абсолютно весь софт для резервного копирования поддерживает NAS в качестве репозитория, и многие выбирают эту опцию как самую простую. В этом нет ничего плохого, однако любой инженер техподдержки скажет вам, что нет ничего лучше, чем обычные диски зацепленные к обычному серверу. Причина проста — на сетевой шаре информацию можно хранить, но нельзя ей оперировать. Даже для самых банальных действий файл надо скачать, изменить и залить обратно. В случае больших файлов это может привести к сильной загрузке как сети, так и самого NAS, не говоря об общей скорости работы такой системы. Тогда как при использовании выделенного сервера на его стороне можно запустить микроскопический агент, который будет активно ворочать терабайтами бэкапов без всякого воздействия на внешнюю среду и без ограничений вызываемых средой передачи.
Другое следствие — невозможно быть на 100% уверенным в корректности записанной на NAS информации. У NAS постоянно есть промежуточная среда передачи данных, вносящая неопределённость.
И не забывайте, что NAS — это устройство файлового хранения, а диски — блочного. Это реверанс в сторону надёжности хранения.
Мораль — если есть возможно НЕ использовать NAS, надо смело ей пользоваться. Потом сами себе скажете спасибо.
Чем и как будем тестировать?
Не сказать, что стандарт, но одним из самых популярных методов тестирования — это долгий прогон с помощью прекрасного Iometr. Изначально разработанный Intel, это инструмент с массой возможностей, отличным интерфейсом и заслуженной славой. Позволяет тестировать как отдельные диски, так и целые кластеры, а гибкость настроек даёт возможность воссоздавать (имитировать) множество типов нагрузок.
Но для наших изысканий он не подходит совсем (от слова «полностью»), т.к. у всего этого великолепия есть набор важных нам минусов — например, последний релиз был аж в 2006 году, поэтому он не знает про такие вещи как SSD кэш, сервер-сайд кэш и прочие новомодные штуки, без которых не обходится ни одна современная железка, и не учитывать их было бы странно.
Другая проблема заключается в механизме эмуляции нагрузок, который несколько далек от настоящего продакшена. Механизм работы прост как три копейки — на диске создаётся файл-пустышка заданного размера, а дальше начинаются операции последовательного чтения/записи в заданных пропорциях. Это лишает возможности делать интересные фортели навроде “А давайте представим, что прямо сейчас в самом дальнем углу диска создался кусок данных, который наш кэш ещё не видел”. Такая ситуация называется “read miss” и для продакшн систем является серой обыденностью, а не фантастической редкостью. Также наличествует другая масса нюансов и тонкостей, которые вряд ли многим интересны, просто надо запомнить главное — Iometr отличный инструмент для быстрого тестирования, когда надо в пару кликов получить более-менее правдоподобную картинку мира, но долговременные тесты лучше поручить специализированному софту.
Возьму на себя смелость порекомендовать утилиту FIO (Flexible I/O tester ) которая постоянно развивается и, кстати говоря, мультиплатформенна ( Вот тут есть готовые бинарники для Windows ). Утилита консольная, запускается с указанием конфиг файла в виде “fio config_file”. Всё по-взрослому.
Вместе с ней идёт прекраснейший HOWTO файл и несколько примеров готовых тестов. Поэтому я не буду детально расписывать все параметры (коих тьма, но они предусмотрительно разделены на основные и побочные), а просто разберём самые для нас важные.
Итак, каждый фал может состоять из нескольких секций. Секции [global] и уточняющих секций для разных вариантов тестов в рамках одного запуска.
Самое интересное для нас в секции [global]:
- size=100g
Указывает размер тестового файла. который будет создан на объекте тестирования. Основное правило — чем больше, тем лучше. Если в вашем распоряжении новое пустое хранилище, то наилучшее решение это выделить под тест всё хранилище целиком.
Но стоит учесть, что перед тем как непосредственно начать тест, fio будет создавать этот файл и на больших объёмах этот процесс может несколько затянуться.
В случае когда невозможно использовать весь объём хранилища, важно придерживаться правила, что размер файла должен хотя бы в два раза перекрывать размер всех доступных хранилищу кэшей. Иначе вы рискуете измерить исключительно их производительность. - bs=512k
Самый важный параметр, когда речь идёт о выжимании всех соков и поиске максимальных скоростей. Жизненно важно правильно указать размер блока данных когда речь идёт о тестировании конкретных сценариев. В нашем случае всё можно найти в документации. И важный нюанс — будем использовать половинные значения как средний ожидаемый выигрыш от использования встроенной в Backup&Replication дедупликации. Соответсвенно если не планируете дедуплицировать вовсе, то берёте целое значение.
Итак, возможные варианты:
- 512К, если установлен Local Target;
- 256K, если установлен Lan Target;
- 128K, если установлен Wan Target;
Для обладателей действительно больших инфраструктур, где ежедневный инкрементный бэкап доходит до терабайтов есть смысл использовать 2048К если установлен Local target 16 TB т.к. там размер блока равен 4096К - numjobs=1
Количество параллельно выполняемых задач. Просто начните с единицы и увеличивайте пока не увидите явной деградации. - runtime=3600
Продолжительность теста в секундах. 3600 секунд это час. Если хотите правильных результатов, то ставить меньше лишено смысла. Но когда надо просто прогнать несколько быстрых тестов, обязательно следите за наполняемостью кэша. Если тесты будут запускаться пока кэш не заполнен до отказа, полученные результаты могут быть намного выше действительных значений.
- ioengine=windowsaio
Если хранилище будет подключено в Windows серверу, оставляем так. Если к Linux, то заменить на libaio. Оба метода используют небуферизируемое IO, поэтому все кэши на пути до хранилища будут проигнорированы, что нам как раз и требуется. - iodepth=1
Количество процессов, одновременно работающих с файловой системой. В нашем случае всегда 1. - direct=1
Говорим fio не использовать файловый кэш системы для операций чтения и записи. Этим мы симулируем самый плохой случай когда системный кэш забит и не принимает данные.
Отдельно можно эмулировать использование кэша для операций записи. Для этого меняем direct=0 и добавляем опцию invalidate=1.
И надо отметить, что direct=0 нельзя использовать для Linux репозиториев с libaio механизмом. - overwrite=1
Рандомная перезапись блоков. Как зачастую и происходит в реальной жизни. Для тестирования хранилища под использование “тяжелых” вариантов бэкапов, таких как forward incremental, опция строго обязательна.
Создание файла с бэкапом детально
Прежде чем начать писать конфиги, давайте чуть подробнее разберёмся с нагрузками которые нам надо эмулировать.
Самый простой случай, это создание первой полной резервной копии (создание .vbk файла). Active Full в нашей терминологии. С точки зрения хранилища всё понятно — на каждый блок данных приходится одна операция записи.
Если в дальнейшем мы используем Forward incremental т.е. просто дописываем инкрементные файлы, то правило нагрузки сохраняется.
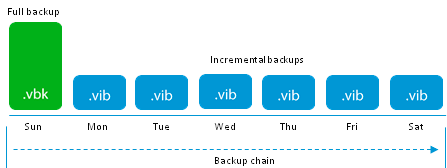
Таким образом, данный метод даёт наименьшую нагрузку на хранилище т.к. нет ничего проще последовательной записи. И подходит даже для многострадальных NAS начального уровня, если они готовы обеспечить стабильную работу, что к сожалению, далеко не всегда так.
Значит в конфигурации остаётся указать путь до объекта тестирования и то, что нам надо тестировать обычную запись:
filename= E\:\vbk #тестируем диск Е:
rw=write #только операции записи
Запустится простой тест последовательной записи, практически полностью идентичный реальному процессу. Почему практически? Причина кроется в процессе дедупликации, который перед тем как записать новый блок данных, сначала проверяет его наличие и в случае совпадения, блок пропускается на запись. Но поскольку сравнение происходит не с реальными блоками, а с их метаданными, размер которых пренебрежительно мал на фоне бэкапного файла, это погрешность носит род допустимых и игнорируется.
Здесь и далее, под спойлером, буду выкладывать полный конфиг теста.
[global]
size=100g
bs=512k
numjobs=2
runtime=3600
ioengine=windowsaio
iodepth=1
direct=1
overwrite=1
thread
unified_rw_reporting=1
norandommap=1
group_reporting
[forward]
filename=E\:\vbk
rw=write
Перейдём к более “взрослым” методам. Следующим будет Forward incremental с периодическими Synthetic fulls.
Режимы создания бэкапов уже многократно и подробно разбирались (можно освежить память здесь и здесь), поэтому скажу только про основное отличие: Synthetic full бэкап создаётся не путём прямого копирования данных с продакшн системы, на методом создания нового инкремента и “схлопывания” всей инкрементной цепочки в единый файл, который становится новым vbk. С точки зрения IO операций это значит, что каждый блок будет сначала прочитан из своего vbk или vib, а затем записан в новый vbk т.е. общее количество операций вырастает в два раза.
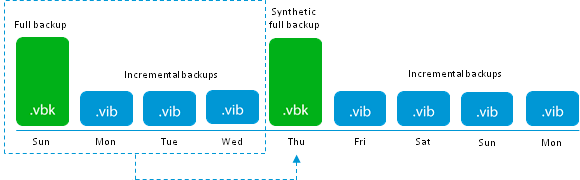
Придерживаясь идеи максимальной правдоподобности, наш тест, отныне, должен состоять из двух частей — первая это создание инкремента
[forward]
rw=write
filename=E\:\vib
И вторая часть, это создание synthetic full. Если вы планируете хранить бэкапы за неделю, то правильный конфиг будет выглядеть так:
[synthetic]
stonewall # ждать завершения теста из предыдущего раздела
new_group # вывести данные в отдельный отчёт
rw=randrw #произвольное чтение/запись
rwmixread=50 #соотношение r/w в процентах
file_service_type=roundrobin
filename=E\:\new_vbk
filename=E\:\old_vbk
filename=E\:\vib1
filename=E\:\vib2
filename=E\:\vib3
filename=E\:\vib4
filename=E\:\vib5
filename=E\:\vib6
filename=E\:\vib7_temporary
С параметром stonewall, надеюсь, всё понятно. Следующий за ним параметр new_group отвечает за вывод получаемых данных в отдельный отчет, иначе получаемые значения будут добавляться к данным от предыдущего теста.
Как говорилось абзацем выше, над каждым блоком будет произведено две I/O операции, поэтому параметром rwmixread задаём соотношение операций чтений/записи как 50%.
Как это происходит, заслуживает небольшого отступления, что позволит объяснить следующие девять строчек конфига.
В момент запуска процесса создания синтетического файла у нас имеется предыдущий vbk, шесть старых инкрементов, за каждый день недели, и один свежий за текущий день. Создаётся впечатление, что необходимый нам блок данных должен быть прочитан через всю цепочку этих файлов т.е. в самом худшем случае должны быть открыты все восемь файлов. Но так поступать совершенно негуманно, поэтому в оперативную память загружаются метаданные всех файлов и выбор местоположения нужного блока происходит там, а процессу остаётся только считать блок из нужного места.
Два важных момента, часто упускаемых администраторами — в последний момент создания синтетического vbk, на репозитории фактически находится два полных бэкапа, что может драмматически сказать на размере доступного места. Старый бэкап, и вся его инкрементная цепочка, будет удалён на самом последнем этапе, когда новый файл пройдёт все тесты на целостность.
Второй упускаемый момент, это время на создание синтетического файла. В общем случае оно равно удвоенному времени создания Active full.
Полный конфиг под спойлером
[global]
bs=512k
numjobs=2
ioengine=windowsaio
iodepth=1
direct=1
overwrite=1
thread
unified_rw_reporting=1
norandommap=1
group_reporting
[forward]
size=50g
rw=write
runtime=600
filename=E\:\vib
[synthetic]
stonewall
new_group
size=300g
rw=randrw
rwmixread=50
runtime=600
file_service_type=roundrobin
filename=E\:\new_vbk
filename=E\:\old_vbk
filename=E\:\vib1
filename=E\:\vib2
filename=E\:\vib3
filename=E\:\vib4
filename=E\:\vib5
filename=E\:\vib6
filename=E\:\vib7_temporary
Следующим на очереди будет обратный порядок построения файлов, используемый для Reversed incremental бэкапов. Возможно самый любимый обществом вид бэкапов, самый простой для понимания, но один из самых жутких с точки зрения нагрузок и дизайна всей системы.
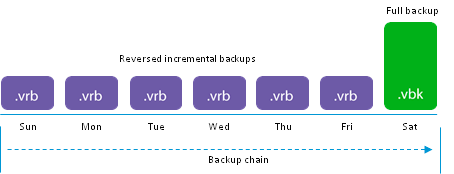
Начало как и везде одинаковое — создаётся полный бэкап в формате .vbk При следующих запусках, как и для forward incremental, создаются разностные файлы, но судьба их намного интересней. Вместо того, что бы быть записанными в виде отдельных .vib файлов, они инжектируются в существующий .vbk, вытесняя из него блоки данных, которые были изменены в бэкапируемой системе. Вытесненные блоки сохраняются в .vrb файл, а новый .vbk всё так же соответствует состоянию системы на момент создания последнего бэкапа.
Очевидные плюсы — минимальное использование места на хранилище, точное соответствие количества точек восстановление количеству файлов в хранилище, быстрое восстановление из последней точки.
Посмотрим как это реализуется на уровне хранения данных. Над каждым блоком данных производится три I/O операции:
- Считывание подлежащих замене данных из vbk файла
- Перезапись этого блока новыми данными
- Записать вытесненные данные в новый .vrb файл
Набор этих операций может быть запущен над любым хранимым блоком и невозможно предугадать кто будет следующий. Или проще говоря — на диске происходит шторм произвольных I/O операций и не каждой системе дано с честью пройти подобное испытание.
Но перейдём к практике! Интересующая нас часть конфига будет выглядеть так:
file_service_type=roundrobin
filename=E\:\vbk
filename=E\:\vrb
rw=randrw
rwmixread=33
Параметр rwmixread=33 следует интерпретировать так: 33% I/O операций будут операции чтения, 66% операции записи. Благодаря использованию round-robin алгоритма и возможности FIO работать с двумя файлами одновременно, получается отличная симуляция процесса который может поставить на колени не самое плохое оборудование.
И будьте внимательны когда дойдёт до анализа результатов — FIO покажет полное количество IOPS и красивую (надеюсь) цифру KB/s, но не стоит обольщаться пока не разделите на три. Поделили — получили реальную скорость работы, не поделили — получили скорость записи нового файла на пустое хранилище.
И конечно, готовый к запуску конфиг.
[global]
size=100g
bs=512k
numjobs=2
runtime=3600
ioengine=windowsaio
iodepth=1
direct=1
overwrite=1
thread
unified_rw_reporting=1
norandommap=1
group_reporting
[reversed]
file_service_type=roundrobin
filename=E\:\vbk
filename=E\:\vrb
rw=randrw
rwmixread=33
Переходим к смешанным режимам создания бэкапов. Их представляет Forever Forward Incremental алгоритм.
Он нов и свеж, и лучше рассказать немного деталей. Данный режим призван бороться с главной проблемой простых инкрементных бэкапов — хранение избыточного количества точек восстановления.
До достижения количества точек восстановления, указанных в настройках задания, алгоритм работает как forward incremental т.е. создаётся полных архив и каждый день к нему дописываются инкременты.
Фокус начинается в день достижения указанного количества точек. Первым делом создаётся очередной инкремент:
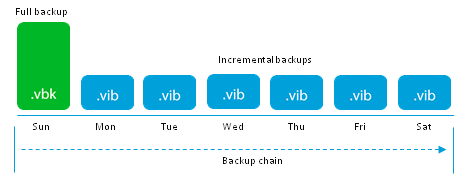
Следующим шагом, первоначальный .vbk начинает своё “путешествие” наверх, и поглощаетт ближайший инкрементный .vib. замещая свои устаревшие блоки, блоками ближайшего инкрементного файла. После успешной инжекции, .vib файл удаляется, а .vbk становится на один день моложе.
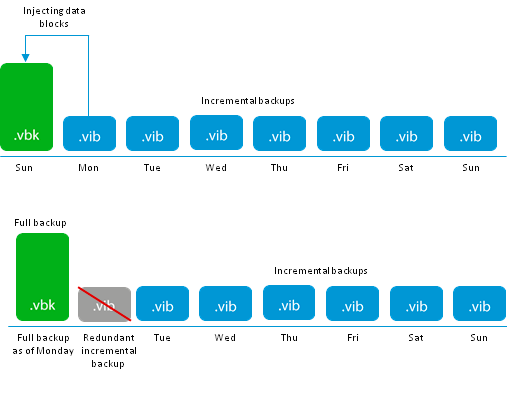
Такой алгоритм позволяет всего хранить точное количество файлов в инкрементной цепочке, а также имеет ряд других плюсов:
— В сравнении с классическим forward incremental нет необходимости в периодическом создании полного бэкапа, что очень положительно влияет на здоровье продакшн систем
— Как и reverse incremental использует минимум необходимого места
— Потребление I/O операций остаётся на прежнем уровне: всего две операции для инжекции данных, что позволяет не растягивать время необходимое для бэкапа.
— Сравнивая с forward incremental, с периодическими synthetic full, где так же задействованы только два I/O, можно заметить интересное соотношение. По сути, вместо разового запуска тяжёлой и длинной трансформации большого файла, происходит ежедневных прогон мини копии этой операции, что в сумме дает тот же результат, но меньшей кровью.
Перейдём к тестам! Создадим файл инкрементов:
[forward]
size=50g
rw=write
filename=E\:\vib
Теперь симулируем трансформацию:
[transform]
stonewall
new_group
size=100g
rw=randrw
rwmixread=50
runtime=600
file_service_type=roundrobin
filename=E\:\vbk
filename=E\:\old_vib
Как видите никакой магии, поэтому сразу готовый конфиг:
[global]
bs=512k
numjobs=2
ioengine=windowsaio
iodepth=1
direct=1
overwrite=1
thread
unified_rw_reporting=1
norandommap=1
group_reporting
[forward]
size=50g
rw=write
runtime=600
filename=E\:\vib
[transform]
stonewall
new_group
size=100g
rw=randrw
rwmixread=50
runtime=600
file_service_type=roundrobin
filename=E\:\vbk
filename=E\:\old_vib
Интерпретируем результаты
Итак, тест завершен и перед нами набор цифр. Давайте его разбирать.
В качестве препарируемого сегодня будет Netapp FAS2020, не сочтите за рекламу, с 12 дисками на борту, одним контроллером и всё это в режиме RAID-DP, что по сути обычный RAID6. Подключено это хозяйство к Windows машине по iSCSI, все тесты запускаются на той же машине.
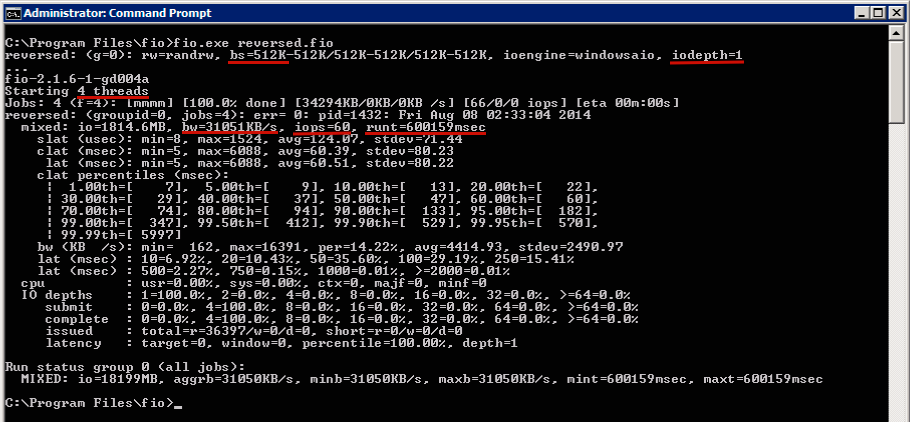
Как видно на скриншоте, был проведён тест с блоками размером 512K, в четыре потока одним процессом (iodepth=1). Время работы установлено 10 минут, эмулировали прогон reverse increment и в итоге мы имеем 60 iops со средней пропускной способностью в 31051 KB/s. Не забываем разделить на три, перевести KB/s в MB/s и получаем эффективную скорость создания бэкапа 10,35 MB/s. Или 37,26 GB данных за час.
В табличке ниже приведены данные по усреднёным значениям — каждый тест был запущен три раза. Для чистоты эксперимента, запуски показывающие отклонение больше чем на 10% были проигнорированы, а тест перезапущен.
Данные представлены, как в виде эффективной скорости, так и в чистом виде.
Дополнительно, все тесты были проведены на блоках разного размера, что бы подобрать лучшие параметры для конкретной железки.
| 512K | 256K | 128K | |
| Forward / 1 thread | 76 iops / 39068 KB/s 140,64 GB в час |
142 iops / 36476 KB/s 131,31 GB в час |
232 iops / 29864 KB/s 107,51 GB в час |
| Forward / 2 threads | 127 iops / 65603 KB/s 236,17 GB в час |
239 iops / 64840 KB/s 233,42 GB в час |
409 iops / 52493 KB/s 188,97 GB в час |
| Forward / 4 threads | 161 iops / 82824 KB/s 298,16 GB в час |
312 iops / 80189 KB/s 288,68 GB в час |
624 iops / 79977 KB/s 287,91 GB в час |
| Synthetic / 1 thread | 32 iops / 17108 KB/s 61,59 GB в час 30,79 реальный объём в час |
42 iops / 11061 KB/s 39,82 GB в час 19,91 реальный объём в час |
66 iops / 8590 KB/s 30,92 GB в час 15,46 реальный объём в час |
| Synthetic / 2 threads | 48 iops / 25198 KB/s 90,71 GB в час 45,35 реальный объём в час |
71 iops / 18472 KB/s 66,50 GB в час 33,25 реальный объём в час |
112 iops / 14439 KB/s 51,98 GB в час 25,99 реальный объём в час |
| Synthetic / 4 threads | 58 iops / 30360 KB/s 109,29 GB в час 54,64 реальный объём в час |
99 iops / 25424 KB/s 91,52 GB в час 45,76 реальный объём в час |
174 iops / 22385 KB/s 80,58 GB в час 40,29 реальный объём в час |
| Reversed / 1 thread | 36 iops / 19160 KB/s 68,97 GB в час 22,99 реальный объём в час |
50 iops / 12910 KB/s 46,47 GB в час 15,49 реальный объём в час |
68 iops / 8777 KB/s 31,59 GB в час 10,53 реальный объём в час |
| Reversed / 2 threads | 52 iops / 27329 KB/s 98,38 GB в час 32,79 реальный объём в час |
76 iops / 19687 KB/s 70,87 GB в час 23,62 реальный объём в час |
109 iops / 14085 KB/s 50,70 GB в час 16,90 реальный объём в час |
| Reversed / 4 threads | 66 iops / 34183 KB/s 123,06 GB в час 41,02 реальный объём в час |
100 iops / 25699 KB/s 92,51 GB в час 30,84 реальный объём в час |
172 iops / 22006 KB/s 79,22 GB в час 26,41 реальный объём в час |
| Forward incremental forever / 1 thread |
31 iops / 16160 KB/s 58,17 GB в час 29,09 реальный объём в час |
41 iops / 10806 KB/s 38,90 GB в час 19,45 реальный объём в час |
54 iops / 7081 KB/s 25,49 GB в час 12,74 реальный объём в час |
| Forward incremental forever / 2 threads |
48 iops / 25057 KB/s 90,21 GB в час 45,10 реальный объём в час |
66 iops / 17075 KB/s 61,47 GB в час 30,73 реальный объём в час |
95 iops / 12304 KB/s 44,29 GB в час 22,15 реальный объём в час |
| Forward incremental forever / 4 threads |
57 iops / 29893 KB/s 107,61 GB в час 53,80 реальный объём в час |
88 iops / 22770 KB/s 81,97 GB в час 40,98 реальный объём в час |
150 iops / 19323 KB/s 69,56 GB в час 34,78 реальный объём в час |
Немного про оптимизацию
Всегда когда хочется выжать максимум из оборудования, очень важно не перегнуть палку и не наоптимизировать лишнего.
Как пример, мы посмотрим динамику изменения показателей при изменении количества I/O потоков. Проверять будем на forward incremental задании, с блоками данных в 1 MB.
- 1 thread 76 iops / 39,07 MB/s 140,64 GB в час
- 2 threads 127 iops / 65,60MB/s 236,17 GB в час
- 4 threads 161 iops / 82,82 MB/s 298,16 GB в час
- 6 threads 174 iops / 89,44 MB/s 321,98 GB в час
- 8 threads 180 iops / 92,49 MB/s 332,99 GB в час
- 10 threads 186 iops / 95,24 MB/s 342,89 GB в час
- 15 threads 191 iops / 98,19 MB/s 353,48 GB в час
- 20 threads 186 iops / 95,23 MB/s 342,84 GB в час.
Хорошо видно, что пропускная способность растёт вплоть до 15 одновременных потоков. Но начиная, уже с 6 прирост производительности настолько незначителен, что встаёт вопрос о целесообразности дальнейшего увеличения нагрузки на CPU в попытке выжать лишний мегабайт скорости.
При использовании 20 потоков, начинает наблюдаться деградация производительности т.к. входящих данных становится слишком много и I/O операции помещаются в очередь, начинают теряться, возникают запросы на повторную передачу и прочий ужас.
Эта метрика позволяет нам понять оптимальное количество одновременно запущенных заданий для наилучшего использования мощностей хранилища. Некоторые администраторы, имея много несколько бэкапных заданий, предпочитают не заморачиваться, а просто ставить одновременный запуск на красивое время. Например час ночи. В итоге большую часть дня сервер спит, а потом несколько часов пашет как проклятый. Он, конечно, железный, но если нагрузку хоть чуть-чуть разнести по времени, пик загрузки сгладится и хранилище прослужит вам несколько дольше.
Далее. В начале статьи упоминался параметр direct=1, благодаря которому тестовые потоки игнорируются кэшем ОС и идут напрямую в хранилище. Конечно, в реальности такая ситуация бывает не часто, но её надо учитывать. В нашем примере, вот каким будет изменение:
- direct=1 65,60 MB/s
- direct=0 98,31 MB/s
- direct=0+invalidate 96,51 MB/s
Параметр invalidate отвечает за принудительную очистку кеша и сильно на результат не влияет, но как мы видим само наличие кэша даёт отличный прирост. Особенно если считать в процентах. Хотя кого это удивляет?
Выводы
Главная идея статьи — больше тестов хороших и правильных! Не стесняйтесь тестировать всё до чего дотянутся руки, но делайте это правильно и не спеша.
Если на массиве, который использовался в тестах для этой статьи, запустить обычный тест последовательной записи, то мы увидим восхитительные 12717 IOPS для 8К блоков, или 199,57 MB/S для 1 MB блоков. Насколько это далеко от реальной ситуации, прекрасно проиллюстрировано в таблице, но кому лень мотать выше — разница два порядка.
Ну и всегда держите в голове простой набор правил:
- Даже самые простые, на ваш взгляд, функции в софте могут состоять из множества простых действий и быть очень сложными для оборудования, поэтому прежде чем обвинить софт, посмотрите, что происходит на харде. В нашем случае примером такого стресса являются reverse incremental бэкапы.
- Чем больше размер блока — тем лучше результат
- Дедупликация это замечательная технология, но не увлекайтесь высокими значениями
- Несколько одновременно запущенных заданий дадут результат лучший, чем одно большое. Мультизадачность наше всё.
Комментарии (35)

nutanix
20.07.2015 16:53> Небольшая ремарка про NAS и бэкапы
… показывает, что вы крайне плохо и мало знаете эту тему. Что, вообще говоря, странно читать в корпоративном блоге Veeam.
Даже не знаю, с чего начать.
> однако любой инженер техподдержки скажет вам, что нет ничего лучше, чем обычные диски зацепленные к обычному серверу.
Нет, только не понимающие тему.
> Причина проста — на сетевой шаре информацию можно хранить, но нельзя ей оперировать.
Какое это отношение иимеет к БЭКАПУ?
> Даже для самых банальных действий файл надо скачать, изменить и залить обратно.
Файлы в бэкапе не должны изменяться. Вообще. Никогда. На то они и БЭКАП.
> В случае больших файлов это может привести к сильной загрузке как сети, так и самого NAS, не говоря об общей скорости работы такой системы.
Ерунда какая. У автора время остановилось во времена стомегабитной или гигабитной сети? Какие Enterprise-class NAS автор вообще видел в жизни?
>Другое следствие — невозможно быть на 100% уверенным в корректности записанной на NAS информации. У NAS постоянно есть промежуточная среда передачи данных, вносящая неопределённость.
Да ну? Серьезно? Невозможно? ;)
> И не забывайте, что NAS — это устройство файлового хранения, а диски — блочного. Это реверанс в сторону надёжности хранения.
Ерунда снова какая-то. В огороде бузина, а в Киеве — дядка. А поверх «блочного хранилища диска» что у вас лежит-то? RAW space? Бгг. 8)
В завершение снова повторю. Был удивлен, увидев ЭТО на корпблоге. Все же до сих пор считал, что до корпблога допускают все же подготовленных сотрудников, а не вот это вот.
ЗЫ. Пр IOmeter тоже нагнано мрачно. Какая-то фигня вообще. Автор, вы бы хоть посмотрели дату изменения свежего релиза IOmeter в его репозитории, прежде чем писать про 2006 год, про остальное не прошу даже, только это.
Loxmatiymamont Автор
20.07.2015 17:06-4> … показывает, что вы крайне плохо и мало знаете эту тему.
Значит пишу глупости и не надо их читать.
> Нет, только не понимающие тему
А аргументировать?
> Какое это отношение имеет к БЭКАПУ?
Бэкап не информация и хранить её нигде не надо. Вот ещё глупости!
> Файлы в бэкапе не должны изменяться. Вообще. Никогда. На то они и БЭКАП.
Эм, а сам бекап это, простите, что?
> Какие Enterprise-class NAS автор вообще видел
В Enterprise-class автор видит только SAN, а на остальное смотрит с недоумением
> Ерунда снова какая-то.
А вы в нутаниксе точно работаете? Прямо за деньги?
Вас тема насов ну совсем как то задела. Неконструктивный диалог получается…
htol
20.07.2015 17:51Тут дело не в NAS. А в совете использовать для бэкап локальные диски. Очень вредный и дорогой в итоге совет.
ka3ax
10.08.2015 11:58как я уже отметил ниже, мы выбираем бюджетный способ хранения второй (offsite) копии бeкапов. один из рассматриваемых вариантов — windows 2012 сервер на четыре диска (типа hp microserver).
Если не использовать для бекапа локальные диски, то что вы посоветуете?
nutanix
21.07.2015 00:05> Значит пишу глупости и не надо их читать.
А по моему глупости не надо писать. Тогда и читать их не придется.
> В Enterprise-class автор видит только SAN, а на остальное смотрит с недоумением
Как я и предполагал, в общем.
> А вы в нутаниксе точно работаете? Прямо за деньги?
Нет, за проездной ;)

sysmetic
21.07.2015 01:49+2>> Даже для самых банальных действий файл надо скачать, изменить и залить обратно.
>Файлы в бэкапе не должны изменяться. Вообще. Никогда. На то они и БЭКАП.
Автор, очевидно, имел в виду ситуацию, что, начиная с прошлогодней версии 8, Veeam Backup & Replication использует по умолчанию метод Forward Incremental Forever, который как раз файл полного бэкапа постоянно обновляет (после каждого инкремента), «инжектируя» в него данные самого старого инкремента («самый старый» определяется согласно установленной retention policy). Аналогично метод Synthetic Full Copy, который существует уже давно, также постоянно обновляет файл синтетической полной копии.

navion
23.07.2015 19:07+1Время работы установлено 10 минут, эмулировали прогон reverse increment и в итоге мы имеем 60 iops со средней пропускной способностью в 31051 KB/s. Не забываем разделить на три, перевести KB/s в MB/s и получаем эффективную скорость создания бэкапа 10,35 MB/s.
Если не ошибаюсь, в обзоре этого метода мне сказали что очистка запускается уже после копирования очередного инкремента. В этом случае окно бекапа не увеличивается, а лишь откладывается завершение задачи и I/O можно принебречь — пусть хоть весь день лопатит данные, главное чтобы успел до следующего окна.sysmetic
23.07.2015 19:34Абсолютно верное наблюдение! — просто фокус статьи был именно на операциях I/O на хранилище данных. Если бы анализ затрагивал еще и операции I/O на исходной (резервируемой) машине, то мы бы действительно увидели, что она освободилась от нагрузки, связанной с операциями бэкапа гораздо раньше, чем хранилище.

alexkuzko
31.07.2015 17:19Но без анализа возможностей исходной машины можно сделать неверные выводы! Как раз у нас похожие вопросы есть с ESXi хостами. И то, как делает бекапы Veeam, не позволяет (?) сделать их быстрее 30 Мб/сек! Возможности целевого хранилища не при чем.
Loxmatiymamont Автор
31.07.2015 17:53Вы можете описать вашу ситуацию более подробно? Можно в личку.
За редким исключением скорость создания бекапа зависит от трёх вещей: скорость чтения с хранилища хоста, скорость записи в репозиторий бекапов и линия связи между компонентами т.е. виртуалка на этот процесс может влиять только косвенно, например, сильно загружая продакшн сторейдж.
Эта статья именно про сторейдж бекапов и как его не сделать узким местом всей системы.
Veeam старательно выжимает максимум из доступных ресурсов и даже иногда слишком хорошо, поэтому мы включили функцию искусственного снижения производительности. Писал про это здесь.
ka3ax
06.08.2015 00:15вопрос к экспертам veeam backup: выбираем бюджетный способ хранения второй (offsite) копии бeкапов. имеем десяток виртуалок и планируем использовать veeam backup, позже возможен рост числа виртуалок. один из рассматриваемых вариантов — windows 2012 сервер на четыре диска (типа hp microserver). также планируем дедуплицировать бeкапы при помощи Windows 2012. будет ли верным решением использовать raid10? или просто оставить четыре отдельных диска? как найти баланс между скорострельностью, надежностью и эффективным использованием дисковой ёмкости? :) вроде вторая копия, надежность менее важна, дисковая ёмкость важнее…

ximik13
06.08.2015 08:17Дедуплицировать бэкапы уже дедуплицированые в Veeam не лучшая идея. Примерно как пытаться ужать в архив сотню jpg и потом удивляться почему место не только не сэкономилось, а архив стал занимать еще больше чем файлы до этого. А в остальном вполне себе вариант. Вот только если рэйд, то лучше софтовый, что бы в случае чего не искать второй такой же микросервер или аналогичный Raid контроллер. Ну и тут все может еще упереться в пропускную способность канала между площадками.
P.s. Я не эксперт по Veeam, но по работе сталкивался с ним. Мое мнение — это только мое мнение и все :).Loxmatiymamont Автор
06.08.2015 09:22Да, включать дополнительную дедупликацию на уровне системы не лучшая затея. Даже крайне не рекомендованная.
Будет неплохая скорость записи, но всем операциям чтения будет предшествовать регидрация данных и общая производительность будет на крайне низком уровне. А выигрыш по месту будет копеечным.
И я лично плохо отношусь к raid10 из 4-х дисков т.к. надежность этой конструкции больше кажется, чем есть на самом деле.
Просто диски тоже можно оставить, создать на каждом свой репозиторий и бекапить разные машины. Тут вопрос исключительно в том, насколько критично потерять информацию на офсайте.ka3ax
06.08.2015 11:52спасибо за советы. я рассчитывал задействовать дедупликацию Windows 2012 после прочтения вот этой статьи:
www.veeam.com/blog/how-to-get-unbelievable-deduplication-results-with-windows-server-2012-and-veeam-backup-replication.html
вроде бы deduplication friendly compression и дедупликация Windows 2012 server показывают сказочные результаты :) статья устарела?Loxmatiymamont Автор
06.08.2015 12:09Классический сферический маркетинг в вакууме. Теоретически показывает на право, практически на лево, а в вас может показать вперёд )
В любом случае лучший выход — прогнать несколько раз тестовое задание и всё станет понятно.
Если переносить на офсайт будете через backup copy job, то не забудьте изменить настройки первичного бекапа иначе смысл пропадает.
Sergey-S-Kovalev
07.08.2015 08:13Раз пошла пьянка про дедупликацию томов средствами Windows Server 2012 R2 на которых хранятся архивы сделанные Veeam B&R 8, я пожалуй, выскажу свой практический опыт:
Вот прямо сейчас — от 9 до 35 процентов.
от 9% на томах куда бэкапится Exchange+AD DC.
~35% на томах куда бэкапятся разносортные виртулаки с sql, файлопомойками, терминальниками и etc.
Статистика с отдельного сервера для горячих бэкапов. Тома в массе своей на основе RAID5 из 1 или 2TB обычных sata винтов. Ночью бэкапит, днем дедуплицирует. По быстродействию претензий нет, если прокурить и оптимизировать WeeklyScrubbing у дедупликацииLoxmatiymamont Автор
07.08.2015 08:30Чем больше в задании схожих виртуалок, а ещё лучше если они созданы из одного шаблона, тем лучше будет рейт дедупликации. В таких средах дедуп рейт под 400% нормальное явление.
ka3ax
07.08.2015 10:19спасибо, интересно. у вас даже RAID5 справляется с нагрузкой. я думал в сторону RAID10 именно из-за скорострельности.
ximik13
07.08.2015 12:52«Скорострельность» в первую очередь зависит от количества шпинделей, а тип Raid только вносит свои коррективы. Если утрировать, то Raid5 из 9 дисков будет быстрее, чем Raid10 из 4-рех.
ka3ax
07.08.2015 13:41мы планируем hp microserver на четыре диска (см мой коммент выше).
ximik13
07.08.2015 13:50Я видел то, что выше. И конкретно про ваш случай с hp microserver я бы собирал два софтовых Raid1 средствами самой OS. И использовал их как два отдельных репозитория для Veeam. Что бы исключить зависимость от испарвности/неисправности встроенного Raid-контроллера, который все равно «ненастоящий», а такой же полусофтовый (использующий ресурсы CPU). В этом случае, при необходимости, винты можно перекинуть в любой другой сервер/компьютер и более-менее спокойно забрать с них данные.
P.s. Но опять же в данном случае мое мнение не претендует на истинность :).ka3ax
07.08.2015 17:20RAID1 значительно медленнее (и в теории и в наших тестах), выигрыша в доступном дисковом пространстве нет… точно не наш вариант. в случае неисправности встроенного Raid-контроллера перекинем диски в соседний сервер hp, старшие модели подхватывают RAID массивы microserver'a без проблем.
ximik13
07.08.2015 12:57Не совсем понял, что значат 9% и 35%. Это объем исходных данных после дедупликаци?
Если да то какой дедупликации?
Используется Veeam. Задания настроены с использованием встроенной дедупликации. После этого на полученных дедуплицированных архивах применяется постпроцесная Windows дедупликация и объем архивов уменьшается до 9%-35% от исходного объема архивов? Или уменьшается еще на 9%-35% от исходного объема архивов?
Можно подробнее рассказать? :)Sergey-S-Kovalev
07.08.2015 13:26Подробности
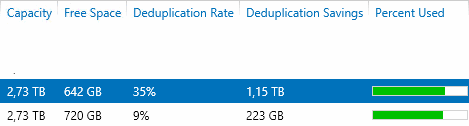
Я думаю оснастка Windows Server привычна и понятна.ximik13
07.08.2015 13:30Да это немного проясняет картину. Но вы так и не ответили. Встроенная дедупликация Veeam в заданиях бэкапа при этом используется или нет?
Loxmatiymamont Автор
07.08.2015 13:46Мы рекомендуем в Veeam выставлять dedup friendly при использовании дедупликации на уровне хранилища.
Sergey-S-Kovalev
07.08.2015 13:56Нажал «Опубликовать» раньше чем выразил мысль полноценно :/ а время на редактирование ограничено
Veeam берет виртуалку, жмет её и кладёт в файловое хранилище. После этого сверху Windows Server дедуплицирует.
Поскольку в логах выполнения задачи у Veeam стоит почти везде deduplication x1.0, то я полагаю, что Veeam не дедуплицирует, а просто жмет. BackupProxy руки развернуть еще не дошли, хотя инженеры Veeam предлагали помочь с развертыванием. У нас Veeam закрывает не весь цикл резервного копирования в виду его фришной версии, а нишевую часть с тяжелыми виртуальными машинами, которые VDP не бэкапит в приемлемые сроки. Поэтому я не могу сейчас сказать точно на предмет «не дедупликации в самом Veeam» из-за отсутствия BackupProxy или из-за того что редакция Free.Loxmatiymamont Автор
07.08.2015 14:11Прокси автоматом ставится на той же машине, что и консоль вима т.к. это обязательная часть.
Если в репорте deduplication x1.0, значит в рамках бекапного файла достойно дедуплицировать не получилось и применилось только дефолтовое сжатие.
Если есть возможность, попробуйте восстановить из бекапа тяжелый файл на пару гигабайт. Интересно с какой скоростью пойдёт рестор.Sergey-S-Kovalev
10.08.2015 11:09+1Если честно, не вижу проблем с скоростью, но в конфигурации:
Виртуалка-файлсервер с включенной дедупликацией (Deduplication Rate = 38%) на разделе с файлопомойкой, заархивированная (Optimal, Compression x1.1) Veeam B&R8 и аккуратно положенная на локальный массив RAID5 на бэкап сервере, после чего раздел с архивом продедуплицирован еще раз поверх — на выходе выдает скорость восстановления 1GB файла архива почты PST на другой массив RAID1 этого же бэкап сервера со скоростью ~70 мегабайт в секунду (если просто копировать файлы с RAID5 на RAID1, то там ~160мб/сек). Добраться до файла по менюшкам труда тоже не составило, зависаний нет.
Восстанавливать в виртуалку не побывал, но не думаю, что результат будет сильно отличаться, потому что при бэкапе бутылочным горлышком выступает источник примерно на 60-80 мегабайт в секунду.
ximik13
07.08.2015 14:22Я Free версию Veeam не использовал. Потому хочется докопаться до истины.
В недрах настроек Job-а в резделе Storage=>Advanced=>вкладка Storage стоит чекбокс «Enable inline data deduplication (recomended)»? Поле «Compression level» настроено?
Если посмотреть отчет (Report) по завершенному Job, то что то подобное есть?

Просто хочется для себя понять. Действительно ли встроенная дедупликация Windows может приносить дополнительную выгоду в дополнение к средствам Veeam? Или все таки нет? :)
В общем если у вас и Veeam дедуплицирует и выполняет компрессию данных. А затем Windows еще добавляет компактности хранимым данным от себя, то это крайне интересные факт :).Sergey-S-Kovalev
10.08.2015 11:19Вот это истины там нет :)
В отчете:
Total size 700,0 GB / Backup size 600,7 GB
Data read 648,3 GB / Dedupe 1,1x
Transferred 600,5 / GB Compression 1,1x
Видно, что там где внутри виртуалки дедупликация идет, последующие сжатия уже не так эффективны, что вполне закономерно.
ka3ax
07.08.2015 17:35У меня к вам ещё вопрос, про полный интерфейс в VB&R FREE. Все ли функции полного интерфейса сохраняются навсегда? (free forewer) Или часть функционала пропадает через N дней?
Будет неприятно, настроил кучу всего… например, репозитории а они через 30 испытательных дней превратятся в тыкву?Sergey-S-Kovalev
10.08.2015 11:22Вот тут не готов ответить, поскольку в последней боевой инсталляции не было триального периода. А предыдущие были на тестовых виртуальных машинах, которые после окончания триала удалялись. Поэтому пропадут ли настроенные репозитории — не ведаю.
ximik13
Спасибо за статью, она очень познавательна. Но про Iometr вы зря так. Ровно все то же самое, что вы описали для FIO можно реализовать и на нем. B он тоже кроссплатформенный если что :), в том числе из исходников можно собрать под нужную OS. Тут вопрос в том, кто и с чем лучше разобрался :). Ну и в 2006 году вышла не последняя версия Iometr, т.к. после компании Intel его развитием занимались другие люди. Последние версии доступны тут www.iometer.org.