
Схема:
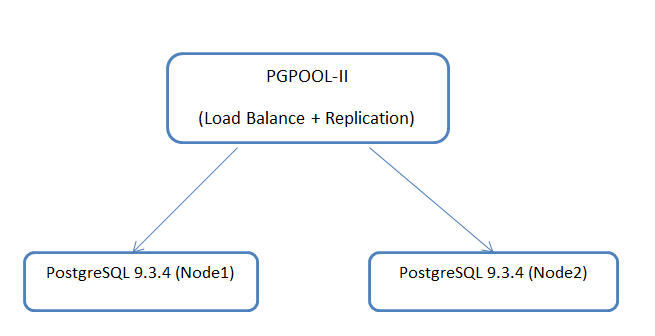
Как Вы понимаете, это будут два отдельно стоящих сервера, которыми будет управлять pgpool-II.
Конфигурация нод с PostgreSQL:
Оба сервера идентичны по своим аппаратным составляющим.
- 4vCPU;
- 16 Гб памяти;
- CentOS 6.5;
Диски:
- 50 Гб — система;
- 100 Гб — pg_xlog
- 500 Гб — каталог с данными
Пример,
Filesystem Size Used Avail Use% Mounted on /dev/sda3 48G 7.4G 38G 17% / tmpfs 7.8G 0 7.8G 0% /dev/shm /dev/sda1 194M 28M 157M 15% /boot /dev/sdb1 99G 4.9G 89G 6% /var/lib/pgsql/9.3/data/pg_xlog /dev/sdc1 493G 234G 234G 50% /var/lib/pgsql/9.3/my_data
Конфигурация нод с pgpool-II:
- 4vCPU;
- 8 Гб памяти;
- CentOS 6.5;
Диски:
- 50 Гб — система;
Про установку PostgreSQL в детали вдаваться не буду, так как она стандартная.
Настройка pgpool-II.
За основу настройки pgpool-II, взял инструкцию с официального сайта: www.pgpool.net/pgpool-web/contrib_docs/simple_sr_setting2_3.3/index.html
Хотел бы обратить внимание только самые важные моменты:
#------------------------------------------------------------------------------
# CONNECTIONS
#------------------------------------------------------------------------------
# - pgpool Connection Settings -
listen_addresses = '*'
port = 9999
socket_dir = '/tmp'
pcp_port = 9898
pcp_socket_dir = '/tmp'
# - Authentication -
enable_pool_hba = off
pool_passwd = ''
log_destination = 'syslog'
#------------------------------------------------------------------------------
# REPLICATION MODE (Говорим pgpool, что все полученные запросы надо транслировать на все ноды кластера)
#------------------------------------------------------------------------------
replication_mode = on
replicate_select = on
insert_lock = on
lobj_lock_table = ''
replication_stop_on_mismatch = off
failover_if_affected_tuples_mismatch = off
#------------------------------------------------------------------------------
# LOAD BALANCING MODE (Говорим pgpool, что все запросы SELECT отправлять на все узлы кластера)
#------------------------------------------------------------------------------
load_balance_mode = on
ignore_leading_white_space = on
white_function_list = ''
black_function_list = 'nextval,setval'
follow_master_command = '/etc/pgpool-II/failover.sh %d "%h" %p %D %m %M "%H" %P'
#------------------------------------------------------------------------------
# FAILOVER AND FAILBACK
#------------------------------------------------------------------------------
failover_command = '/etc/pgpool-II/failover.sh %d %P %H %R'
failback_command = ''
fail_over_on_backend_error = on
search_primary_node_timeout = 10
#------------------------------------------------------------------------------
# ONLINE RECOVERY (В данном случае, онлайн восстановление, в терминах pgpool, означает вернуть узел в кластер pgpool. Если одна из нод упадет и пролежит долгое время, то догонать эту ноду до актуальных данных придется в ручную)
#------------------------------------------------------------------------------
recovery_user = 'postgres'
recovery_password = ''
recovery_1st_stage_command = 'basebackup.sh'
recovery_2nd_stage_command = ''
recovery_timeout = 90
client_idle_limit_in_recovery = 0
#------------------------------------------------------------------------------
# WATCHDOG
#------------------------------------------------------------------------------
# - Enabling -
use_watchdog = off
trusted_servers = 'IP-адрес-pgpool-хоста'
ping_path = '/bin'
wd_hostname = 'VRRIP IP. Единый вход при использовании watchdog'
wd_port = 9000
wd_authkey = ''
delegate_IP = 'VRRIP'
ifconfig_path = '/home/apache/sbin'
if_up_cmd = 'ifconfig eth0:0 inet $_IP_$ netmask 255.255.255.0'
if_down_cmd = 'ifconfig eth0:0 down'
arping_path = '/home/apache/sbin'
arping_cmd = 'arping -U $_IP_$ -w 1'
clear_memqcache_on_escalation = on
wd_escalation_command = ''
wd_lifecheck_method = 'heartbeat'
wd_interval = 10
wd_heartbeat_port = 9694
wd_heartbeat_keepalive = 2
wd_heartbeat_deadtime = 30
wd_life_point = 3
wd_lifecheck_query = 'SELECT 1'
wd_lifecheck_dbname = 'template1'
wd_lifecheck_user = 'nobody'
wd_lifecheck_password = ''
ssl_key = ''
ssl_cert = ''
ssl_ca_cert = ''
ssl_ca_cert_dir = ''
listen_backlog_multiplier = 2
log_line_prefix = ''
log_error_verbosity = 'DEFAULT'
client_min_messages = 'notice'
log_min_messages = 'warning'
database_redirect_preference_list = ''
app_name_redirect_preference_list = ''
allow_sql_comments = off
connect_timeout = 10000
check_unlogged_table = off
backend_hostname0 = 'Имя первой ноды'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/var/lib/pgsql/9.3/data'
backend_flag0= 'ALLOW_TO_FAILOVER'
backend_hostname1 = 'Имя второй ноды'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/var/lib/pgsql/9.3/data'
backend_flag1= 'ALLOW_TO_FAILOVER'
other_pgpool_hostname0 = ''
other_pgpool_port0 =
other_wd_port0 =
heartbeat_destination0 = ''
heartbeat_destination_port0 =
heartbeat_device0 = ''
После настройки конфигурационного файла, запускаем службу pgpool. Можно также настроить pgpooladmin для мониторинга состояния нод.
Я это делал по инструкции отсюда:
www.pgpool.net/docs/pgpoolAdmin/en/install.html
Также статус нод с PostgreSQL можно посмотреть, выполнив команду на pgpool:
pcp_node_info 10 "имя pgpool-ноды" 9898 postgres postgres 0
pcp_node_info 10 "имя pgpool-ноды" 9898 postgres postgres 1
Далее, проверяем работу нашей схемы — создаем пустую БД через pgpool. Сделать это можно двумя способами:
1) через pgadmin, подключившись к IP-адресу pgpool-II;
2) выполнив команду на ноде с pgpool: createdb -p 9999 bench_replication
Минусы:
- Синхронная репликация
- В случае выхода из строя одной из нод, над ее возвращением придется попотеть
- Достаточно мало, где используется такая архитектура
- Блокировка таблица
Плюсы:
- Логическая репликация, не уходит на уровень СУБД, снижая на нее нагрузку
- Балансировка нагрузки
- Кеширование запросов
- Объединение соединений
За основу взята инструкция по ссылке: www.pgpool.net/pgpool-web/contrib_docs/simple_sr_setting2_3.3/index.html
Комментарии (9)

Pilat
21.07.2015 20:25Ещё в минус — есть некоторые проблемы с выполнением функций, результат которых может быть разный на разных нодах. Например, now() будет выполнена на «мастере» (условно) — на одном из серверов, а вот на каком именно из нескольких? Функция, которая возвращает случайное значение, будет выполнена на обоих, или на каком-то одном (надо поместить её в белый список, не помню как называется). А если сомнительных функций тысячи?
А с возвращением ноды особых проблем как раз и нет, мне кажется. pg_basebackup и всё.
ToSHiC
21.07.2015 23:24А почему вы считаете, что применить запрос, модифицирующий данные, на 2 машины дешевле с точки зрения нагрузки, чем накатить изменения из WAL? Ведь в WAL уже готовый результат по сути, а исходный запрос надо распарсить, применить, записать собственно результат в WAL и только потом закоммитить в файл с данными. Слейв, соответственно, не делает бОльшую часть работы, только применяет изменения из WAL.
Отдельный вопрос в вашей схеме — консистентность реплик при конкурентных запросах на изменение данных. Кто гарантирует, что транзакции на двух машинах будут применены в одинаковом порядке?
olku
22.07.2015 00:57Было дело пару лет назад… не пуля.
Да, не дешевле, время отклика растет из-за синхронизации.
Консистентность есть, ибо синхронность проверяется. Но динамические значения типа рандов — беда. И чуть что — кластер деградировал в 1 ноду.
Интересно для чтения — селекты распределяются по нодам равномерно, а точка входа для приложения одна.
thunderspb
22.07.2015 13:01Точка входа одна — значит если она ляжет, то все? Эх, лучше всего, кмк, это реализовано в кассандре, любая нода может быть точкой входа…
olku
22.07.2015 13:06Картинка как бы намекает… В статье не рассматривась установка двух PGpool перекрестно, равно как и Кассандра.
pbobrovnikov Автор
22.07.2015 14:26Всё верно — изначально архитектура предполагала наличие второго Pgpool, они работали перекрестно и это было настроено, судя по разделу «WatchDog», где виртуальный IP-бегает между двумя Pgpool. Затем при тестировании Online Recovery, я убрал второй Pgpool из-за предостережения, которое нашел в мануале: «Note that there is a restriction about online recovery. If pgpool-II itself is installed on multiple hosts, online recovery does not work correctly, because pgpool-II has to stop all clients during the 2nd stage of online recovery. If there are several pgpool hosts, only one will have received the online recovery command and will block connections.»
pbobrovnikov Автор
22.07.2015 10:28Изначально была задача разобраться в решениях по отказоустойчивости в PostgreSQL. Сначала настроил Stream + Pgpool — чаще всего такая архитектура встречается в Интернете. Здесь тебе и select-ы на все ноды, но запись в одно место. Но потом захотелось попробовать писать сразу везде (некий мультимастер). И как оказалось, это мало кто использует, видимо как раз потому, что доверяют больше внутренним механизмам, это видимо и есть mainstream. Просто когда у тебя много транзакций в базе, генерация wal просто сумасшедшая, но это получается дешевле чем проигрывать в потере SQL-запросов (цитата от О.Бартунова) Захотелось раскурить pgpool — настроить его можно, поддерживать можно, но вот если одна из нод останавливается (при этом система продолжит, конечно, работать)по любой причине начинаются танцы с бубном.
Какие у Вас архитектуры по отказоустойчиовсти? pgBouncer + Stream?
Askon
28.07.2015 20:42Зачем делать реплику pgpool'ом при наличии 9.3+? Год назад описывал про настройку подобной связки для AWS. Связка рабочая, синхронную репликацию не использую.
guai
Недавно подыскивал путный способ обеспечивать failover. pgpool тоже поковырял в числе прочего. Толком не получилось сделать бесшовный вывод из строя одной из нод, и потом возвращение ее в строй. Хотя, может я чего не так делал…
В итоге запилил для явы своё решение для 2х нод: github.com/guai/HikariCP. В бою оно еще толком не побывало, но, может, пригодится кому.