
Введение
Пришла пора покупать СХД. Какую взять, кого слушать? Вендор А рассказывает про вендора B, а еще есть интегратор C, который рассказывает обратное и советует вендора D. В такой ситуации и у опытного архитектора по системам хранения голова пойдет кругом, особенно со всеми новыми вендорами и модными сегодня SDS и гиперконвергенцией.
Итак, как же во всем этом разобраться и не оказаться в дураках? Мы (AntonVirtual Антон Жбанков и korp Евгений Елизаров) попробуем об этом рассказать русским языком по белому.
Статья во многом перекликается, и фактически является расширением “Дизайна виртуализованного ЦОД” в плане выбора систем хранения данных и обзора технологий систем хранения. Мы кратко рассмотрим общую теорию, но рекомендуем ознакомиться и с указанной статьей.
Зачем
Часто можно наблюдать ситуацию как приходит новый человек на форум или в специализированный чатик, как например Storage Discussions и задает вопрос: “вот мне предлагают два варианта СХД — ABC SuperStorage S600 и XYZ HyperOcean 666v4, что посоветуете”?
И начинается мерянье у кого какие особенности реализации страшных и непонятных фишек, которые для неподготовленного человека и вовсе китайская грамота.
Так вот, ключевой и самый первый вопрос, который нужно себе задать задолго до сравнивания спецификаций в коммерческих предложениях — ЗАЧЕМ? Зачем нужна эта СХД?

Ответ будет неожиданным, и очень в стиле Тони Роббинса — чтобы хранить данные. Спасибо, капитан! И тем не менее, иногда мы так далеко углубляемся в сравнение деталей, что забываем зачем все это вообще делаем.
Так вот, задача системы хранения данных — это хранение и предоставление доступа к ДАННЫМ с заданной производительностью. С данных же мы и начнем.
Данные
Тип данных
Что за данные мы планируем хранить? Очень важный вопрос, который может вычеркнуть очень многие СХД даже из рассмотрения. Например, планируется хранение видеозаписей и фотографий. Сразу можно вычеркивать системы, рассчитанные под случайный доступ малым блоком, или системы с фирменными фишками в компрессии / дедупликации. Это могут быть просто превосходные системы, ничего плохого не хотим сказать. Но в данном случае их сильные стороны или станут напротив слабыми (видео и фото не компрессируются) или просто значительно увеличат стоимость системы.
И наоборот, если целевое использование нагруженная транзакционная СУБД, то превосходные потоковые системы под мультимедиа, способные выдавать гигабайты в секунду, будут плохим выбором.
Объем данных
Сколько данных мы планируем хранить? Количество всегда перерастает в качество, это не нужно забывать никогда, особенно в наше время экспоненциального роста объема данных. Системы петабайтного класса уже не редкость, но чем больше петабайт объема, тем более специфической становится система, тем менее будет доступно привычной функциональности систем со случайным доступом малого и среднего объема. Банально потому что одни только таблицы статистики доступа по блокам становятся больше доступного объема оперативной памяти на контроллерах. Не говоря уже о компрессии / тиринге. Предположим, мы хотим переключить алгоритм компрессии на более мощный и пережать 20 петабайт данных. Сколько это займет: полгода, год?
С другой стороны, зачем городить огород, если хранить и обрабатывать надо 500 ГБ данных? Всего 500. Бытовые SSD (с низким DWPD) подобного объема стоят всего ничего. Зачем для этого строить фабрику Fiber Channel и покупать внешнюю СХД высокого класса стоимостью в чугунный мост?
Какой процент от общего объема горячие данные? Насколько неравномерна нагрузка по объему данных? Именно тут может очень помочь технология многоуровневого хранения или Flash Cache, если объем горячих данных мизерный по сравнению с общим. Либо наоборот, при равномерной нагрузке по всему объему, часто встречающейся в потоковых системах (видеонаблюдение, некоторые системы аналитики) подобные технологии не дадут ничего, и лишь увеличат стоимость / сложность системы.
ИС
Обратная сторона данных — это информационная система, использующая эти данные. ИС обладает набором требований, которые наследуют данные. Подробнее об ИС см в “Дизайне виртуализованного ЦОД”.
Требования по отказоустойчивости / доступности
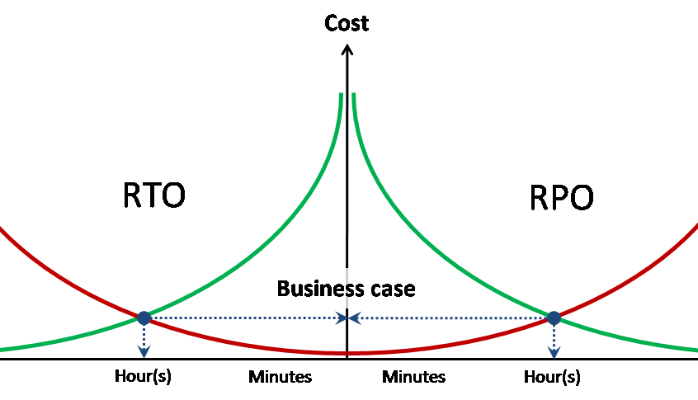
Требования по отказоустойчивости / доступности данных наследуются от использующей их ИС и выражаются в трех числах — RPO, RTO, доступность.
Доступность — доля за заданный промежуток времени, в течение которого данные доступны для работы с ними. Выражается обычно в количестве 9. Например, две девятки в год означает, что доступность равна 99%, или иначе допускается 95 часов недоступности в год. Три девятки — 9,5 часов в год.
RPO / RTO — это показатели не суммарные, а на каждый инцидент (аварию), в отличие от доступности.
RPO — объем потерянных при аварии данных (в часах). Например, если происходит резервное копирование раз сутки, то RPO = 24 часа. Т.е. При аварии и полной потере СХД могут быть потеряны данные объемом до 24 часов (с момента резервной копии). Исходя из заданного для ИС RPO, например, пишется регламент резервного копирования. Также, исходя из RPO, можно понять насколько нужна синхронная / асинхронная репликация данных.
RTO — время восстановления сервиса (доступа к данным) после аварии. Исходя из заданного значения RTO мы можем понять нужен ли метрокластер, или достаточно однонаправленной репликации. Нужна ли многоконтроллерная СХД hi end класса — тоже.
Требования по производительности
Несмотря на то, что это вполне очевидный вопрос, с ним то как раз и возникает большинство трудностей. В зависимости от того, есть у вас уже какая то инфраструктура или нет и будут строиться пути сбора необходимой статистики.
У вас уже есть СХД и вы ищите ей замену или хотите приобрести ещё одну для расширения. Здесь всё просто. Вы понимаете, какие сервисы у вас уже есть и какие вы планируете внедрять в ближайшей перспективе. Основываясь на текущих сервисах вы имеете возможность собрать статистику по производительности. Определиться с текущим количеством IOPS и нынешних задержках — каковы эти показатели и хватает ли их для ваших задач? Сделать это можно как на самой системе хранения данных, так и со стороны хостов, которые к ней подключены.
Причём смотреть нужно не просто текущую нагрузку, а за какой то период (лучше месяц). Посмотреть каковы максимальные пики в дневное время, какую нагрузку создаёт резервное копирование и т.д. Если ваша СХД или ПО к ней не даёт вам полный набор этих данных, можно воспользоваться бесплатным RRDtool, который умеет работать с большинством наиболее популярных СХД и коммутаторов и сможет предоставить вам подробную статистику по производительности. Также стоит смотреть нагрузку и на хостах, которые работают с данной СХД, по конкретным виртуальным машинам или что конкретно у вас работает на данном хосте.
Стоит отдельно отметить, что если задержки на томе и датасторе, который находится на данном томе отличаются довольно сильно — стоит обратить внимание на вашу SAN-сеть, высока вероятность, что с ней есть проблемы и прежде чем приобретать новую систему, стоит разобраться с этим вопросом, ведь очень высока вероятность увеличения производительности текущей системы.
Вы строите инфраструктуру с нуля, либо приобретаете систему под какой то новый сервис, о нагрузках которого вы не в курсе. Тут есть несколько вариантов: пообщаться с коллегами на профильных ресурсах, чтобы попытаться узнать и спрогнозировать нагрузку, обратиться к интегратору, у которого есть опыт внедрения подобных сервис и который сможет рассчитать нагрузку за вас. И третий вариант (обычно самый сложный, особенно если это касается самописных или редких приложений) попытаться выяснить требования к производительности у разработчиков системы.
И, внимание, самый правильный вариант с точки зрения практического применения — это пилот на текущем оборудовании, либо оборудовании предоставленном для теста вендором / интегратором.
Спецтребования
Спецтребования — все то, что не подпадает под требования о производительности, отказоустойчивости и функциональности по непосредственной обработке и предоставлению данных.
Одним из самых простых спецтребований к системе хранения данных можно назвать “отчуждаемые носители информации”. И сразу становится понятно, что данная система хранения данных должна включать в себя ленточную библиотеку или просто стример, на который сбрасывается резервная копия. После чего специально обученный человек подписывает ленту и гордо несет ее в специальный сейф.
Другой пример спецтребования — защищенное противоударное исполнение.
Где
Второй главной составляющей в выборе той или иной СХД является информация о том, ГДЕ будет стоять эта СХД. Начиная от географии или климатических условий, и заканчивая персоналом.
Заказчик
Для кого планируется данная СХД? Вопрос имеет под собой следующие основания:
Госзаказчик / коммерческий.
Коммерческий заказчик не имеет никаких ограничений, и не обязан даже тендеры проводить, кроме как по собственным внутренним регламентам.
Госзаказчик — дело иное. 44 ФЗ и прочие прелести с тендерами и ТЗ, которые могут быть оспорены.
Заказчик под санкциями
Ну тут вопрос очень простой — выбор ограничивается только доступными для данного заказчика предложениями.
Внутренние регламенты / разрешенные к закупке вендоры / модели
Вопрос тоже крайне прост, но о нем надо помнить.
Где физически
В данной части мы рассматриваем все вопросы с географией, каналами связи, и микроклиматом в помещении размещения.
Персонал
Кто будет работать с данной СХД? Это не менее важно, чем то, что СХД непосредственно умеет.
Насколько бы не была перспективна, крута и замечательна СХД от вендора А, смысла ставить ее наверное немного, если персонал умеет работать только с вендором B, и дальнейших закупок и постоянного сотрудничества с А не планируется.
И разумеется, обратная сторона вопроса — насколько доступен в данной географической локации подготовленный персонал непосредственно в компании и потенциально на рынке труда. Для регионов может иметь значительный смысл выбор СХД с простыми интерфейсами или возможностью удаленного централизованного управления. Иначе в какой то момент может стать мучительно больно. Интернет полон историй как пришедший новый сотрудник, вчерашний студент, наконфигурячил такого, что вся контора полегла.

Окружение
Ну и разумеется немаловажный вопрос — в каком окружении будет работать данная СХД.
- Что с электропитанием / охлаждением?
- Какое подключение
- Куда она будет смонтирована
- И тд.
Зачастую данные вопросы считаются сами собой разумеющимися и особо не рассматриваются, но иногда именно они могут перевернуть все с точностью до наоборот.
Что
Вендор
На сегодня (середина 2019) российский рынок СХД можно поделить на условные 5 категорий:
- Высший дивизион — заслуженные компании с широкой линейкой от самых простых дисковых полок до hi-end (HPE, DellEMC, Hitachi, NetApp, IBM / Lenovo)
- Второй дивизион — компании с ограниченной линейкой, нишевые игроки, серьезные вендоры SDS или поднимающиеся новички (Fujitsu, Datacore, Infinidat, Huawei, Pure и тд)
- Третий дивизион — нишевые решения в ранге low end, дешевый SDS, наколенные поделия на ceph и других открытых проектах (Infortrend, Starwind и тд)
- SOHO сегмент — малые и сверхмалые СХД уровня дом/малый офис (Synology, QNAP и тд)
- Импортозамещенные СХД — сюда входят как железо первого дивизиона с переклеенными лейблами, так и редкие представители второго (RAIDIX, дадим им авансом второй), но в основном это третий дивизион (Aerodisk, Baum, Depo и тд)
Деление достаточно условное, и совсем не означает, что третий или SOHO сегмент плохи и их нельзя использовать. В специфических проектах с четко определенным набором данных и профилем нагрузки они могут отработать очень хорошо, далеко превосходя первый дивизион по соотношению цена/качество. Важно сначала определиться с задачами, перспективами роста, требуемой функциональностью — и тогда Synology будет служить вам верой и правдой, а волосы станут мягкими и шелковистыми.
Один из немаловажных факторов при выборе вендора — текущая среда. Сколько и каких СХД у вас уже есть, с какими СХД умеют работать инженеры. Нужен ли вам еще один вендор, еще одна точка контакта, будете ли вы мигрировать постепенно всю нагрузку с вендора А на вендора B?
Не следует плодить сущности сверх необходимого.
iSCSI / FC / File
По вопросу протоколов доступа нет единого мнения среди инженеров, а споры напоминают более теологические дискуссии, чем инженерные. Но в целом можно отметить следующие пункты:
FCoE скорее мертв, чем жив.
FC vs iSCSI. Одно из ключевых преимуществ FC в 2019 перед IP СХД, выделенная фабрика под доступ к данным, нивелируется выделенной IP сетью. Глобальных преимуществ у FC перед IP сетями нет и на IP можно строить СХД любого уровня нагрузки, вплоть до систем для тяжелых СУБД для АБС крупного банка. С другой стороны, смерть FC пророчат уже не первый год, но этому постоянно что то мешает. На сегодня, например, некоторые игроки на рынке СХД активно развивают стандарт NVMEoF. Разделит ли он участь FCoE — покажет время.
Файловый доступ также не является чем то недостойным внимания. NFS / CIFS прекрасно показывают себя в продуктивных средах и при правильном проектировании имеют не больше нареканий, чем блочные протоколы.
Гибридные / All Flash Array
Классические СХД бывают 2 видов:
- AFA (All Flash Array) — системы, оптимизированные для использования SSD.
- Гибридные — позволяющие использовать как HDD, так и SSD или их сочетание.
Главное их отличие — поддерживаемых технологии эффективности хранения и максимальный уровень производительности (высокие показатели IOPS и низкие задержки). И те и другие системы (в большинстве своих моделей, не считая low-end сегмент) могут работать как блочные устройства, так и файловые. От уровня системы зависит и поддерживаемый функционал, и у младших моделей, он чаще всего урезан до минимального уровня. На это стоит обращать внимание, когда вы изучаете характеристики конкретной модели, а не просто возможности всей линейки в целом. Так же, конечно, от уровня систему зависят и её технические характеристики, такие как процессор, объём памяти, кэша, количество и типы портов и т.д. С точки зрения же По управления, AFA от гибридных (дисковых) систем отличаются лишь в вопросах реализации механизмов работы с SSD накопителями, и даже если вы используете SSD в гибридной системе, это совсем не значит, что вы сможете получить уровень производительности на уровне AFA системы. Так же в большинстве случаев inline механизмы эффективного хранения на гибридных системах отключены, а их включение ведёт к потере в производительности.
Специальные СХД
Помимо СХД общего назначения, ориентированных прежде всего на оперативную обработку данных, существуют специальные СХД с ключевыми принципами, в корне отличающимися от привычных (низкая задержка, много IOPS):
Медиа.
Данные системы предназначены под хранение и обработку медиа-файлов, отличающихся большим размером. Соотв. задержка становится практически неважной, а на первый план выходит способность отдавать и принимать данные широкой полосой в много параллельных потоков.
Дедуплицирующие СХД для резервных копий.
Поскольку резервные копии отличаются редкой в обычных условиях похожестью друга на друга (средняя резервная копия отличается от вчерашней на 1-2%), данный класс систем крайне эффективно упаковывает записанные на них данные в рамках достаточно небольшого количества физических носителей. Например, в отдельных случаях коэффициенты компрессии данных могут достигать 200 к 1.
Объектные СХД.
В этих СХД нет привычных томов с блочным доступом и файловых шар, а более всего они напоминают огромную базу данных. Доступ к объекту, хранящемуся в подобной системе, осуществляется по уникальному идентификатору, либо по метаданным (например все объекты формата JPEG, с датой создания между XX-XX-XXXX и YY-YY-YYYY).
Compliance системы.
Не так часто встречаются в России на сегодня, но упомянуть о них стоит. Назначение таких СХД — гарантированное хранение данных для соответствия политикам безопасности или требованиям регуляторов. В некоторых системах (например EMC Centera) была реализована функция запрета на удаление данных — как только ключ повернут и система перешла в данный режим, ни администратор, ни кто либо другой физически не могут удалить уже записанные данные.
Фирменные технологии
Flash cache
Flash Cache – общее название для всех фирменных технологий использования флэш-памяти в качестве кэша второго уровня. При использовании флэш кэша СХД как правило рассчитывается для обеспечения с магнитных дисков установившейся нагрузки, в то время как пиковую обслуживает кэш.
При этом необходимо понимать профиль нагрузки и степень локализации обращений к блокам томов хранения. Флэш кэш – технология для нагрузок с высокой локализацией запросов, и практически неприменима для равномерно нагруженных томов (как например для систем аналитики).
На рынке доступны две реализации флэш кэша:
- Read Only. В этом случае кэшируются только данные на чтение, а запись проходит сразу на диски. Некоторые производители, как например, NetApp, считают что запись на их СХД проходит и так оптимальным образом, и кэш никак не поможет.
- Read/Write. Кэшируется не только чтение, но и запись, что позволяет буферизовать поток и снизить влияние RAID Penalty, а как следствие повысить общую производительность для СХД с не таким оптимальным механизмом записи.
Tiering
Многоуровневое хранение (тиринг) — технология объединения в единый дисковый пул уровней с разной производительностью, как например SSD и HDD. В случае ярко выраженной неравномерности обращений к блокам данных система сможет автоматически отбалансировать блоки данных, переместив нагруженные на высокопроизводительный уровень, а холодные, наоборот, на более медленный.
Гибридные системы нижнего и среднего классов используют многоуровневое хранение с перемещением данных между уровнями по расписанию. При этом размер блока многоуровневого хранения у лучших моделей составляет 256 МБ. Данные особенности не позволяют считать технологию многоуровневого хранения технологией повышения производительности, как ошибочно считается многими. Многоуровневое хранение в системах нижнего и среднего классов – это технология оптимизации стоимости хранения для систем с выраженной неравномерностью нагрузки.
Snapshot
Сколько мы бы не говорили о надёжности СХД, существует множество возможностей потерять данные, не зависящие от аппаратных проблем. Это могут быть как вирусы, хакеры или любое другое, непреднамеренное удаление/порча данных. По этой причине, резервное копирование продуктивных данных является неотъемлемой частью работы инженера.
Снапшот — это снимок тома на какой то момент времени. При работе большинства систем, таких как виртуализация, БД и тд. нам необходимо снять такой снимок, из которого мы будем копировать данные в резервную копию, при этом наши ИС смогут спокойно продолжать работать с этим томом. Но стоит помнить — не все снапшоты одинаково полезны. У разных вендоров, разные подходы к созданию снапшотов, связанные с их архитектурой.
CoW (Copy-On-Write). При попытке записи блока данных его оригинальное содержимое копируется в специальную область, после чего запись проходит нормально. Таким образом предотвращается повреждение данных внутри снапшота. Естественно все эти «паразитные» манипуляции с данными вызывают дополнительную нагрузку на СХД и по этой причине вендоры с подобной реализацией не рекомендуют использовать более десятка снапшотов, а на высоконагруженных томах не использовать их вообще.
RoW (Redirect-on-Write). В данном случае, оригинальноый том натурально замораживается, а при попытке записи блока данных СХД пишет данные в специальную область в свободном пространстве, изменяя местоположение данного блока в таблице метаданных. Это позволяет уменьшить количество операций перезаписи, что в итоге нивелирует падение производительности и снимает ограничения на снапшоты и их количество.
Снапшоты бывают также двух типов по отношению к приложениям:
Application consitent. В момент создания снапшота СХД дергает агента в операционной системе потребителя, который принудительно сбрасывает дисковые кэши из памяти на диск и заставляет сделать это приложение. В этом случае при восстановлении из снапшота данные будут консистентны.
Crash consistent. В данном случае ничего подобного не происходит и снапшот создается как есть. В случае восстановления из такого снапшота картина идентична как если бы внезапно отключилось питание и возможна некоторая потеря данных, зависших в кэшах и так и не дошедших до диска. Такие снапшоты проще в реализации и не вызывают просадки производительности в приложениях, но менее надежны.
Зачем нужны снапшоты на системах хранения данных?
- Безагентное резервное копирование напрямую с СХД
- Создание тестовых сред на основе реальных данных
- В случае с файловыми СХД может использоваться для создания сред VDI через использование снапшотов СХД вместо гипервизора
- Обеспечение низких RPO путем создания снапшотов по расписанию с частотой значительно выше частоты резервного копирования
Cloning
Клонирование тома — работает по аналогичному принципу, что и снапшоты, но служит не просто для чтения данных, а для полноценной работы с ними. Мы имеем возможность получить точную копию нашего тома, со всем данными на нём, не делая физической копии, что позволит сэкономить место. Обычно клонирование томов используется или в Test&Dev или если вы хотите проверить работоспособность каких то обновлений на вашей ИС. Клонирование позволит сделать это максимально быстро и экономично с точки зрения дисковых ресурсов, т.к. записаны будут только изменённые блоки данных.
Репликация / журналирование
Репликация — механизм создания копии данных на другой физической СХД. Обычно существует фирменная технология у каждого вендора, работающая только внутри собственной линейки. Но также есть и сторонние решения, в том числе работающие на уровне гипервизора, как например VMware vSphere Replication.
Функциональность фирменных технологий и удобство их использования обычно сильно превосходят универсальные, но оказываются неприменимы, когда например необходимо делать реплику с NetApp на HP MSA.
Репликация делится на два подвида:
Синхронная. В случае синхронной репликации операция записи пересылается на вторую СХД немедленно и не подтверждается исполнение до тех пор, пока удаленная СХД не подтвердит. За счет этого растет задержка доступа, но зато мы имеем точную зеркальную копию данных. Т.е. RPO = 0 для случая потери основной СХД.
Асинхронная. Операции записи исполняются только на главной СХД и подтверждаются немедленно, параллельно накапливаясь в буфере для пакетной передачи на удаленную СХД. Подобный вид репликации актуален для менее ценных данных, либо для каналов низкой пропускной способности либо имеющих высокую задержку (характерно для расстояний свыше 100 км). Соответственно RPO = частоте пакетной отправки.
Зачастую вместе с репликацией существует механизм журналирования дисковых операций. В этом случае выделяется специальная область для журналирования и хранятся операции записи определенной глубины по времени, либо ограниченные объемом журнала. Для отдельных фирменных технологий, как например EMC RecoverPoint, существует интеграция с системным ПО, позволяющим привязать определенные закладки на конкретную запись в журнале. Благодаря этому возможно откатить состояние тома (либо создать клон) не просто на 23 апреля 11 часов 59 секунд 13 миллисекунд, а на момент, предшествовавший “DROP ALL TABLES; COMMIT”.
Metro cluster
Метро кластер — технология, позволяющая создать двунаправленную синхронную репликацию между двумя СХД таким образом, что со стороны эта пара выглядит как одна СХД. Применяется для создания кластеров с географически разнесенными плечами на метро- расстояниях (менее 100 км).
На примере использования в среде виртуализации метрокластер позволяет создать датастор с виртуальными машинами, доступный на запись сразу из двух датацентров. В этом случае создается кластер на уровне гипервизоров, состоящий из хостов в разных физических датацентрах, подключенный к данному датастору. Что позволяет сделать следующее:
- Полная автоматизация процесса восстановления после смерти одного из датацентров. Без каких либо дополнительных средств все ВМ, работавшие в умершем датацентре, будут автоматически перезапущены в оставшемся. RTO = таймаут кластера высокой доступности (15 секунд для VMware) + время загрузки операционной системы и старта сервисов.
- Disaster avoidance или, по-русски, избежание катастроф. Если запланированы работы по электропитанию в датацентре 1, то мы заранее, до начала работ, имеем возможность мигрировать всю важную нагрузку в датацентр 2 нон стоп.
Виртуализация
Виртуализация СХД — это технически использование томов с другой СХД в качестве дисков. СХД-виртуализатор может просто прокинуть чужой том до потребителя как свой, попутно зеркалировав его на еще одну СХД, или даже создать RAID из внешних томов.
Классические представители в классе виртуализации СХД — это EMC VPLEX и IBM SVC. Ну и разумеется СХД с функцией виртуализации — NetApp, Hitachi, IBM / Lenovo Storwize.
Зачем может понадобиться?
- Резервирование на уровне СХД. Создается зеркало между томами, причем одна половина может быть на HP 3Par, а другая на NetApp. А виртуализатор от EMC.
- Переезд данных с минимальным простоем между СХД разных производителей. Предположим, что данные надо мигрировать со старого 3Par, который пойдет под списание, на новый Dell. В этом случае потребители отключаются от 3Par, тома прокидываются под VPLEX и уже презентуются потребителям заново. Поскольку ни бита на томе не изменилось, работа продолжается. Фоном запускается процесс зеркалирования тома на новый Dell, а по завершению зеркало разбивается и 3Par отключается.
- Организация метрокластеров.
Компрессия / дедупликация
Компресиия и дедупликаия — это те технологии, которые позволяют вам экономить дисковое пространство на вашей СХД. Стоит сразу упомянуть, что далеко не все данные подлежат компрессии и/или дедупликации в принципе, при этом некоторые типы данных жмутся и дедуплицируются лучше, а какие то — наоборот.
Компрессия и дедупликация бывают 2 видов:
Inline — сжатие и дедупликация блоков данных происходит до записи этих данных на диск. Таким образом система только вычисляет хэш блока и сравнивает его по таблице с уже имеющимися. Во-первых это выполняется быстрее, чем просто запись на диск, во-вторых мы не расходуем лишнее дисковое пространство.
Post — когда эти операция проводят уже на записанных данных, которые находятся на дисках. Соответственно данные сначала записываются на диск, а только потом, вычисляется хэш и происходит удаление лишних блоков и высвобождение дисковых ресурсов.
Стоит сказать, что большинство вендоров используют оба вида, что позволяет оптимизировать эти процессы и тем самым повысить их эффективность. У большинства вендоров СХД, есть в наличии утилиты, которые позволяют проанализировать ваши наборы данных. Данные утилиты, работают по той же логике, что реализована и в СХД, по этому оценочный уровень эффективности будет совпадать. Также не стоит забывать, что у многих вендоров есть программы гарантии эффективности, которые обещают уровень не ниже заявленного для определённого (или всех) типов данных. И не стоит пренебрегать данной программой, ведь рассчитывая систему под свои задачи, с учётом коэффициента эффективности конкретной системы, вы можете сэкономить на объёме. Так же стоит учитывать, что эти программы рассчитаны на AFA системы, но благодаря закупке меньшего объёма SSD, нежели HDD в классических системах, это позволит снизить их стоимость, и если не сравняться со стоимостью дисковой системы, то довольно сильно к ней приблизиться.
Модель
И вот здесь мы приходим к правильно заданному вопросу.
“Вот мне предлагают два варианта СХД — ABC SuperStorage S600 и XYZ HyperOcean 666v4, что посоветуете”
Превращается в “Вот мне предлагают два варианта СХД — ABC SuperStorage S600 и XYZ HyperOcean 666v4, что посоветуете?
Целевая нагрузка смешанные виртуальные машины VMware с контуров продуктив / тест / разработка. Тест = продуктиву. 150 ТБ на каждый с пиковой производительностью 80 000 IOPS 8kb блоком 50% случайного доступа 80/20 чтение-запись. 300 ТБ на разработку, там 50 000 IOPS хватит, 80 случайный, 80 запись.
Продуктив предположительно в метрокластер RPO = 15 минут RTO = 1 час, разработку в асинхронную репликацию RPO = 3 часа, тест на одной площадке.
Будет 50ТБ СУБД, было бы неплохо для них журналирование.
У нас везде серверы Dell, СХД старые Hitachi, еле справляются, планируем рост 50% нагрузки по объему и производительности”
Как говорится, в правильно сформулированном вопросе содержится 80% ответа.
Дополнительная информация
С чем стоит ознакомиться дополнительно по мнению авторов
Книги
- Олифер и Олифер “Компьютерные сети”. Книга поможет систематизировать и возможно лучше понимать как работает среда передачи данных для IP / Ethernet систем хранения
- “EMC Information Storage and Management”. Прекрасная книга по основам СХД, почему, как и зачем.
Форумы и чаты
- Storage Discussions
- Nutanix / IT Russian Discussion Club
- VMware User Group Russia
- Russian Backup User Group
Общие рекомендации
Цены
Теперь что же касается цен — вообще на СХД цены если и попадаются, то обычно это List price, от которой каждый заказчик получает индивидуальную скидку. Размер скидки складывается из большого числа параметров, так что предсказать, какую конечную цену получит именно ваша компания, без запроса к дистрибьютору просто невозможно. Но при этом, в последнее время low-end модели стали появляться в обычных компьютерных магазинах, таких как, например nix.ru или xcom-shop.ru. В них можно сразу приобрести интересующую вас систему по фиксированный цене, как любые компьютерные комплектующие.
Но хочется отметить сразу, что прямое сравнение по TB/$ не является верным. Если подходить с этой точки зрения, то наиболее дешёвым решением будет простой JBOD + сервер, что не даст ни той гибкости, ни той надёжности, которые обеспечивает полноценная, двухконтроллерная СХД. Это совершенно не значит, что JBOD гадость гадостная и пакость пакостная, просто нужно опять-таки очень чётко понимать — как и для каких целей вы будете использовать это решение. Часто можно услышать, что в JBOD нечему ломаться, там же один бэкплейн. Однако и бэкплейны бывает выходят из строя. Все ломается рано или поздно.
Итого
Сравнивать системы между собой нужно не только по цене, или не только по производительности, а по совокупности всех показателей.
Покупайте HDD только если вы уверены, что вам нужны HDD. Для низких нагрузок и несжимаемых типов данных, в ином случае, стоит обратить на программы гарантии эффективности хранения на SSD, которые сейчас есть у большинства вендоров (и они действительно работают, даже в России), но тут всё зависит от приложений и данных, которые будут располагаться на данной СХД.
Не гонитесь за дешевизной. Порой под эти скрывается множество неприятных моментов, один из которых Евгений Елизаров описывал в своих статьях про Infortrend. И что, в конечном итоге, эта дешевизна может выйти вам же боком. Не стоит забыть — «скупой платит дважды».
Комментарии (97)

GilevVyacheslav
27.06.2019 19:52хитро спрятана проблема NVMe
сейчас один такой диск иногда может больше, чем дорогущая полка из-за устаревших интерфейсов (точнее их пропускной способности)
KorP
27.06.2019 20:56+1хитро спрятана проблема NVMe
А в чё собственно проблема NVMe? В том, что не все вендоры к нему уже готовы?
NetApp сейчас, пожалуй, лидер в этом направлении, так в «Full NVMe» массиве AFF A320 полки подключаются через 100GbE через RoCE, к примеру.

AntonVirtual Автор
27.06.2019 21:49+1Я скажу более, даже SATA SSD зачастую может больше, чем выдает полка. Ввиду расстояния до данных.
Но проблема одиночного диска в его:
1. Надежности. Умрет диск — пропадут данные
2. Монопольном доступе. С диском может работать только система, в которую он физически включен.

DZITs
27.06.2019 22:32Ключевое слово — «иногда». Не все проблемы можно решить, воткнув NVMe диск в сервер.


navion
27.06.2019 20:52Зачем сложный и некрасивый RRDtool, когда есть прекрасный DPACK?
catsfamily
27.06.2019 21:17Ну он уже давно LiveOptics, но картинки рисует красивые и информативные :)

ximik13
28.06.2019 08:34А можно подробнее, что прекрасного в DPACK? Кроме красивых картинок, которые можно с умным видом показывать начальству или заказчику? По мне так утилита от уважаемого вендора, которая не умеет анализировать уже собранные performance логи с его же вендорских СХД выглядит мягко говоря странным поделием. Если проблемы с производительностью у меня были «вчера», то чем мне поможет DPACK «сегодня»? :). Это не говоря уже про СХД сторонних вендоров.

Smasher
28.06.2019 11:39DPACK не для анализа проблем, котрые были вчера. Это инструмент, который позволяет понять текущее состояние, а дальше уже решать, что с этим делать. Чаще всего его используют для сбора статистики для последующего сайзинга нового решения.
ximik13
28.06.2019 11:52Таки уважаемый вендор совсем не под этим соусом подает его партнерам и заказчикам :), скорее как серебряную пулю. Т.е. по факту DPACK в лучшем случае подходит для того, что бы сильно на глазок прикинуть текущую нагрузку заказчика со стороны серверов (и только некоторых СХД уважаемого вендора) и не более того :). При этом вендор отказался от Mitrend, который выглядел куда как интереснее и умеет намного больше и лучше чем DPACK (в то время даже не знавший, что в природе существует еще что то кроме серверов) :).
Smasher
28.06.2019 12:25Ну тогда это вопрос к вендору. Я DPACK как раз воспринимаю как инструмнет для "прикидывания на глазок".
ximik13
28.06.2019 13:33Собственно к тому почему DPACK вдруг "на глазок". Мне не очень понятен например смысл тратить 3 дня или неделю на снятие данных о производительности систем заказчика в реальном времени в случаях, когда на СХД уже присутствует готовая статистика на 90 дней назад. Но DPACK с ней работать почему-то не научили. Проблема тут только в том, что статистика эта для простых смертных доступна только при прямом подключении в интерфейс управления СХД, а для пресейлинга это как раз не назвать удобным.
navion
28.06.2019 12:06Он простой, наглядный и его формат понимают сайзеры других вендоров.
А для анализа производительности есть бесплатные утилиты от производителей СХД, тот же OCUM или Cloud Insights.
Dr_Wut
27.06.2019 21:55-1Странная статья. Половина макетинговый булшит — половина оооочень общие слова.
Где хоть слово про типы нагрузки? (OLTP/dwh)
Где рассказ про iops/latency/bandwidthи их зависимость?
Мне кажется те, кто в теме знают что делать и без таких статей. Те, кто не в курсе после этой статьи будут еще более не в курсе.
Лучше пойти к 2-3 вендорам и поговорить с их пресейлами и сравнить показания — пользы будет больше
Am0ralist
27.06.2019 22:29С вендорами вообще странно разговаривать. Есть вопрос с заменой интерфейса полки HP MSA.
Вендор шлёт сразу к дилерам, те хорошо если ответят пару вопросов и всё. Цифр получить не получается.
Ну да, да, заменить можно, но так как вы не хотите брать новую полку, то отвечать мы вам не будем.
Алё, ребятки, если нам цирфы не даёте, с чем мы пойдем к начальству бюджет выбивать?
Примерно тоже самое с драйвом к старой ленточной библиотеки IBM. В результате сами в МСК, а купили через ребят из глубинки. С гарантией, что если не заведется — мы им вернём. Завёлся.
Короче, если вы не собираетесь закупаться на пару лямовой — общаться с этими товарищами вообще толку нет.
KorP
27.06.2019 22:40+1Лучше пойти к 2-3 вендорам и поговорить с их пресейлами и сравнить показания
Собрались американец, русский и француз, и говорят по-китайски…
Сколько раз было — закидываешь вендору спеку — столько то iops, под такие то задачи, такой объём… один на флеше считает, второй на гибриде — какой пользы тут будет лучше?AntonVirtual Автор
27.06.2019 22:52+1Ну мне один очень опытный пресейл по СХД в крупном вендоре не смог посчитать на бумаге с калькулятором набивку СХД по дискам под заданные IOPS потому что не знал что такое RAID Penalty.
А ты говоришь флэш, гибрид…Dr_Wut
27.06.2019 23:29А вы в курсе что в некоторых схд их нет? Ну просто в силу архитектуры =) ну или настолько малы что ими можно пренебречь

vkostr
28.06.2019 10:06Тут скорее проблема не в том что они есть или нет, а в том что технический специалист должен это в принципе знать (как минимум в рамках конкурентного анализа) и учитывать как этот (если есть), так и другие факторы (garbage collection, например) при расчетах
IsyanovDV
28.06.2019 02:20+1Полтора года назад покупали СХД, All-flash, выбирали из трех брендов (не буду перечислять чтобы не было рекламы/антирекламы) «высшего» дивизиона.
Спеки урегулировались не один месяц, и было большой проблемой даже привести их к более-менее одинаковым показателям… Например, у одного вендора дополнительные диски можно втыкать по одному а у другого только пару, или у одного емкость дисков / полки больше чем у другого и там надо докупать еще одну полку (цена растет) и т.д.
В итоге вопрос выбора вендора — это не простой процесс.AntonVirtual Автор
28.06.2019 11:09Я нигде не говорил, что это простой процесс. Но до выбора конкретной модели конкретного вендора надо сформулировать — а что же собственно мы хотим от этой системы хранения.
Smasher
28.06.2019 11:41+1Потому что надо выбирать не по одинаковому количеств удисков, а по требуемым показателям производительности, наджености и функциональности. Каждый вендор может выполнить это требования, используя разные технологии и разное количество дисков.
IsyanovDV
28.06.2019 13:23Ну про прописные истины тут не надо, естественно во главу угла ставились показатели производительности, надежность, поддержка и прочее.
Но чтобы просто сравнить спеки, привести их к более-менее одинаковым характеристикам — надо попотеть… а потом оказывается что один вендор конкретно дороже из-за таких вот особенностей.
AntonVirtual Автор
27.06.2019 23:05>Где хоть слово про типы нагрузки? (OLTP/dwh)
>Где рассказ про iops/latency/bandwidthи их зависимость?
Вероятно ждут вашего пера. Цель данной статьи не включала данную тематику.Dr_Wut
27.06.2019 23:27Простите пожалуйста, а как вы предлагаете выбирать схд без этой информации? По цвету лампочек на передней панели? Если уж взялись писать статью о том как выбрать схд, так опишите основы хотя бы.
AntonVirtual Автор
27.06.2019 23:36Смотрите какая у вас прекрасная возможность причинить ИТ сообществу добро и нанести непоправимую пользу.
Напишите замечательную статью как выбирать СХД правильно. Со всеми подробностями, включая общую теорию проведения пилотного тестирования, генерации нагрузки, правильной трактовки результатов. Судя по вашим комментариям, вы являетесь в этом несомненным специалистом. Почту за честь учиться общей теории СХД по вашим статьям.Dr_Wut
27.06.2019 23:42Не возьмусь, ибо никогда не закончу. Это очень обширная тема, с кучей нюансов и подводных камней. Но вы решили что сможете — теперь получаете обратную связь. Я ж не виноват что вы в своей статье упустили огромные очевидные куски.
xopen
28.06.2019 00:58+2С точки зрения читателя, у меня есть прекрасная статья от Антона и эээ ничего от доктора. Кто из вас мне больше полезен?
Нет ничего плохого, чтобы спросить у автора о пропусках. Отличный ответ, что это за рамками данного материала. А вот дальнейшее нытье что все плохо, но сам не дам… Это не достойно профессионала.Dr_Wut
28.06.2019 12:37В статье нет половины важных вещей, которые действительно нужны для подбора СХД. В итоге человек сделавший выбор на основании этих данных сделает заранее неверный выбор из-за отсутствия важной информации по теме. И вы считаете что это действительно полезная статья?
Простой пример — у вас нагрузка OLTP, и вы решаете по статье сделать все на базе iscsi (там же написано что это тоже самое что и fc). При этом для экономии вы скорее всего пустите данные по тем же свичам, что и общий трафик (хорошо если в разных vlan-ах). И тут кто-то решил себе на вечер скачать фильм, или просто воткнули в сеть кривой принтер — и вот уже ваша OLTP база офигевает от задержек в пару секунд на запись/чтение, вас натягивают как сову на глобус у начальства.
Статья под таким названием скорее вредная, чем полезная. Жаль что вы этого не понимаетеAntonVirtual Автор
28.06.2019 13:05Я правильно понимаю, что в данном случае вы описываете свой печальный опыт?
О том как вы пустили все по одним свитчам в одном VLAN и как у вас в офисе народ качает на вечер фильмы и в итоге лежит ваша 1С, а потом вас натягивают как сову на глобус?Dr_Wut
28.06.2019 13:33Нет, это я описываю опыт людей, которые руководствовались как раз такого рода статьями. А мне нужно было привести это в божеский вид (и привел).
AntonVirtual Автор
28.06.2019 13:39Что то мне подсказывает, что человек, делающий такое, никакими статьями и учебниками не руководствуется.
Но вернемся к вопросу — вы вольны написать правильную статью. Займет у вас не сильно больше времени, чем написание вот всех этих обличительных комментариев.
И есть еще одно подозрение — что после статьи такого уровня у вас сменится работа и вырастет зарплатаDr_Wut
28.06.2019 13:59И есть еще одно подозрение — что после статьи такого уровня у вас сменится работа и вырастет зарплата
=) посмеялся
Но вернемся к вопросу — вы вольны написать правильную статью. Займет у вас не сильно больше времени, чем написание вот всех этих обличительных комментариев.
печально что вы не слышите что вам говорят — это большая целая статей, в которые должны входить основы хотя бы:
Теория (3-5 статей статьи):
- физическая теория (диски/рейды/iops/latency и тому подобное)
- теория про нагрузки и какие они бывают
- блочный/файловый доступы
- построения san-сетей
"Практика" (еще не понятно сколько статей):
- что такое классические san-сети и как с этим жить
- что такое sds и как с этим жить
- сравнение когда что более уместно
- высокая доступность
- высокие нагрузки
И это то, о чем я сходу подумал. А есть еще тысячи моментов которые всплывут во время написания.
По сути все эти выборы сводятся к шутке с баша — "какой лучше дистрибутив Linux выбрать? Тот, который стоит у твоего знакомого админа"
Займет у вас не сильно больше времени, чем написание вот всех этих обличительных комментариев.
Каждая статья это примерно 3-5 дней плотной работы (актуализировать знания, подобрать пруфы, само написание). В итоге это реально месяцы работы и на выходе по сути просто книжка. И вы реально считаете что я трачу столько на комментарии?
AntonVirtual Автор
28.06.2019 15:00Пробовали читать EMC Information Storage & Management, упомянутый в статье?
Scif_yar
29.06.2019 21:59Теория (3-5 статей статьи):
физическая теория (диски/рейды/iops/latency и тому подобное)
теория про нагрузки и какие они бывают
блочный/файловый доступы
построения san-сетей
Это уже все давным давно написано в виде толстых книжек и статей на хабре.
например habr.com/ru/post/346352
Dr_Wut
29.06.2019 23:16Воооот! Вот эта статья действительно может называться "как выбрать себе схд" =)
romxx
30.06.2019 10:31«эта статья» поможет «как», а статья выше отвечает, в итоге, на гораздо более важный вопрос — «зачем».
Или, иначе, справочник врача поможет врачу, но бесполезен для дилетанта, только сильнее его запутает.
KorP
28.06.2019 13:29При этом для экономии вы скорее всего пустите данные по тем же свичам, что и общий трафик
Давайте будем честными — это не проблема выбора СХД, а полное отсутствие компетенции у человека, который этим занимается. Тут ни одна статья не поможет.Dr_Wut
28.06.2019 13:43Ну смотрите — статья называется «Как выбрать СХД, не выстрелив себе в ногу». Там есть много действительно полезной информации для людей которые впервые столкнулись с этой проблемой, но совершенно нет базовых вещей. Мне вот всегда казалось что идти надо от задачи, а это тут как-то не очевидно описано.
Теорию струн бесполезно рассказывать людям у которых нет соответствующей базы для понимания.KorP
28.06.2019 13:50Так в том то и дело, что в статье «Как выбрать СХД" описывается — как выбрать СХД, а не построить всю инфраструктуру или SAN. Естественно в рамках одной статьи — физически невозможно рассказать всё. Тут уже надо не статью, а книгу тогда писать, от и до. В конце-концов, никто не же мешает кому то, считая, что какая то часть темы не рассказана должным образом — написать статью самому. Опять-таки для нас, камменты это то же повод посмотреть — что хотят люди, получить фидбек и возможно потом написать ещё.
Alexsandr_SE
28.06.2019 22:32Завалить свич скачкой фильма? У вас свичи 10 мегабитные? ЧП могут быть, но такое подключение имеет иногда и плюсы.
bbk
28.06.2019 02:44Именно из-за таких вот комментариев я и перестал писать свои статьи на хабре.
А вот попробуйте сами что-то написать. Прийдут такие же как вы и спасибо не скажут.Dr_Wut
28.06.2019 14:12Вы не поверите — у меня есть статьи. За одну нахватал столько минусов что пришлось даже убрать. И в комментариях так же огребал за косяки в статье — просто слушал, и дельные вещи сразу правил.
ximik13
28.06.2019 08:24Антон, вполне занимательная статья для общего развития. Спасибо! Мне казалось ты ушел в воинствующего HCI вендора (возможно ошибался), где все приходящие немедленно становяться адептами нового учения :). Рад что с тобой такого не произошло и здравый взгляд на вещи ни куда не делся.
romxx
28.06.2019 10:43Во первых «вендор» вообще не воинствующий. То что в нем работает и пишет по русски ровно один такой человек не значит, что «вендор воинствующий». Это индивидуальный стиль одного человека. Сейчас в России работает у вендора _семь_ человек, и никто из них не «воинствующий».
Во вторых, статья принципиально задумывалась про классические СХД, здесь намеренно ни одно HCI решение не упомянуто.
Effi3
28.06.2019 11:05+1«удаляющее кодирование», тут, видимо, речь про другой устойчивый термин «помехоустойчивое кодирование» (erasure coding)?
AntonVirtual Автор
28.06.2019 11:13Да, верно. В процессе просто автоматом всплыл откуда то неверный перевод. И как уже было отмечено, по нему ничего не было написано, поскольку фактически в классических внешних СХД оно реализовано в виде RAID, и является основой работы.
Непосредственно как фишка erasure coding именно под таким названием применяется только в гиперконвергентных системах, поэтому я просто убрал его из заголовка. Поскольку гиперконвергенцию в рамках данной статьи мы не рассматриваем от слова совсем.ximik13
28.06.2019 12:15В классических erasure coding не используется, но применяется он и не только в гиперконвергентных системах. Есть еще горизонтально масштабируемые системы хранения, которые не являются гиперконвергентными и появились за долго до них. Isilon, HydraStor, Elastic Cloud Storage и возможно еще какие-то похожие по принципам защиты данных решения.
Effi3
28.06.2019 12:36Добавлю к списку еще несколько вариантов реализации объектных СХД: Scality, Cleversafe. Да, у систем своя ниша, принцип работы: данные воспринимаются как объекты, каждая порция со своим хэш адресом, по которому происходит поиск уже записанной информации. Из интересного — Erasure Coding в объектных СХД эта одна из реализаций подхода к избыточности имени Reed-Solomon'а, тот же подход к устройству избыточности и принципу разбиения всего поступающего набора данных, с некими изменениями, применяется в технологии RAID 6. Теория разработана еще в 1960г. :)
AntonVirtual Автор
28.06.2019 13:02Открываем https://en.wikipedia.org/wiki/Erasure_code
Optimal erasure codes
Parity: used in RAID storage systems.
ximik13
28.06.2019 13:23Это к чему сейчас? :)
К тому что WiKi редактируется всеми и ни кем?
Или к тому что parity это частный случай для Erasure Code, но используемый только в RAID (а значит и классических СХД)? :)AntonVirtual Автор
28.06.2019 15:02Есть утверждение «в классических erasure coding не используется».
Это утверждение неверно, потому что используется в виде parity в RAID.
Effi3
28.06.2019 11:10+1Можно еще к выводу: тестируйте свои реальные данные на СХД перед покупкой. Некоторые маркетинговые «фичи» работают только в узком диапазоне данных и смотрите «наперед»: то, что важно сегодня (объем, скорость, функционал) слабо коррелируется с тем набором данных, который будет на ваших СХД через 2-3 года.

amarao
28.06.2019 13:09Как-то вы очень цеф обидели.
alexnovik
28.06.2019 15:53Чем? Все кто с ним плотно работал всё это знают )
amarao
28.06.2019 16:51В посте ceph упоминается только в фразе про "наколенные изделия".
alexnovik
28.06.2019 17:13Ну они такими и являются. Коммерческих решений на Ceph либо нет, либо поставляются с отказом от ответственности.
Если зрелые системы SDS на базе устоявшихся платформ периодически оформляются в виде коммерческих продуктов как например:
ZFS
— Nexenta
— Open-E
— Raidix
— etc.
Lustre
— DDN
— Supermicro
— Hitachi
— HPE
— etc.
Scality
— HPE
— DELL
WEKA.IO
— HPE
— DELL
— Supermicro
То Ceph на сколько я знаю никто не продает как продукт с поддержкой. Потому что на коленке и сырой.amarao
28.06.2019 18:31Э… Вы когда-нибудь слышали о компании Red Hat? И что они шипят RH Storage с цефом внутри? А уж сколько они за саппорт берут...
Алсо, я хочу с интересом послушать про вендора, который готов взять полную ответственность за баги и их последствия.
romxx
28.06.2019 18:54После покупки RedHat IBMом, последний прекратил поддержку ряда продуктов, в частности коммерческого ceph, он сейчас передан комьюнити, новых продаж с поддержкой не будет.
navion
28.06.2019 19:50Red Hat Ceph Storage не просто продаётся (Сбербанк недавно купил подписок на пару миллионов баксов), но и заменит Gluster в OpenShift 4.2.
AntonVirtual Автор
28.06.2019 22:15+2Проще ответить чего Сбербанк не купил. Наличие чего либо в Сбербанке и РЖД не является подтверждением стабильности или качества.
navion
28.06.2019 22:50Мой комментарий не про качество, а что Ceph ещё продают и покупают. Впрочем, неизвестно сколько это будет продолжаться.

DmitriyTitov
Я в последнее время не занимаюсь корпоративной информационной инфраструктурой и СХД в частности, но вот складывается ощущение, что вся эта сакральность СХД как невероятно отказоустойчивой, сложной и высокоэффективной штуковины осталась в прошлом.
Большинству контор, даже крупных, нахрен не сдался весь этот набор возможностей СХД EMC на пять листов (также как и большинству гос. покупателей коммутаторов и маршрутизаторов Cisco не нужно 98% их возможностей). При этом весь этот маркетинг о покупке крутого устройства, которое решит проблемы на десять лет вперёд (т.е. проблемы, которых ещё нет) уже тоже приелся.
На мой взгляд, программные решения уже вполне зрелые и надёжные, и перейти от простого iSCSI СХД на встроенном функционале Windows или Linux на одном сервере к Windows Storage Spaces на куче серверов и JBOD или чему-то ещё более сложному вообще не проблема. И такой переход будет решать реальные проблемы. Ну и дешевле будет, само собой.
Что авторы статьи думают на этот счёт?
KorP
Про Windows Storage Spaces не скажу, я его в продакшене в принципе не видел, но наверняка — какие то задачи он способен решать. В целом, если не брать самосборные серверы, то SDS не выходит дешевле классической хранилки, т.к. стоимость ПО довольно высока. По тому и бума SDS до сих пор нет (не беря в расчёт opensource, тут другая ситуация). Но опять же — всё зависит от задач. Если ваш SLA вам позволяет использовать SDS, если ваши задачи требуют высокой параллелизации, если вам не нужна функциональность СХД, почему нет?
r2r2
Посчитано и внедрено — SDS Open-E JovianDSS + Supermicro выходит значительно дешевле классических хранилок. И ни в чем не уступает.
KorP
Ну отлично, что данное решение отвечает вашим требованиям и вышло экономически эффективным для ваших нужд.
Alexsandr_SE
Софтовые решения дают и разноуровневое хранение и SSD кеширование и дедупликацию.
KorP
А аппаратные не дают? :)
Alexsandr_SE
Аппаратные дают тоже, но софт дешевле и проще в плане поднятия в случае проблем с железом (кроме проблем с накопителями). Для небольших и думаю многих средних контор это предпочтительнее решение. Софт постепенно вытесняет железные решения.
KorP
Статистикой поделитесь?
Alexsandr_SE
А она хоть у кого-то есть? Как учесть кучу серверов которые используют как хранилище дисковое, как учесть кучу самосбора с вполне себе приемлемыми характеристиками?
Ну а софт, так уж получается в жизни, что специализированные решения со временем переделываются на более дешевые чипы + софт.
KorP
Ну подождите, вы же пишите
так на чём основано ваше мнение? чем его можно подкрепить?
AntonVirtual Автор
>Большинству контор, даже крупных, нахрен не сдался весь этот набор возможностей
Большинство контор даже не подозревает о реальных требованиях к инфраструктуре и СХД. И я значительно чаще вижу обратную ситуацию, коогда из-за непонимания реальных цифр по RPO и RTO, стоимости простоя в час, контора использует решения и архитектуры на порядок худшие, чем реально требуются.
Любые разговоры же «им все это не надо» вообще лишены смысла пока не сформулирована стоимость данных и влияние простоев и потери данных на основной бизнес.
DmitriyTitov
Вот эти-то сложновысчитываемые характеристики меня и смущают (RPO, RTO и пр.)
Давайте рассмотрим конкретный пример. Когда-то я участвовал в модернизации (читай создании) ЦОД для одной из крупнейших и авторитетнейших госструктур. Вы, конечно, знаете, но для тех кто не в курсе, скажу, что именно государство в России является основным покупателем СХД. Некоторые крупнейшие вендоры первые годы жили только! за счёт госзаказов от какого-нибудь РЖД. Тоже факт из первых рук, если что.
Так вот, большая госструктура. Каков у неё стоимость простоя в час? Да кто же знает? Это же не коммерческая компания. Но не это главное, суть в следующем.
Поставили мы им СХД за сумму порядка миллиона долларов, подключили к корзинкам с серверами по 10GB FCoE (или iSCSI — не помню). На серверах VMware vSphere. Всё работает, всё хорошо.
Проходит время и диски начинают сыпаться, они же там обычные, что бы и кто не говорил про «доработку прошивок», «дополнительное тестирование» и пр. И в какой-то момент вендор говорит: «Ребята, вы под санкциями, менять диски не можем!». А купить при наличии гарантии не так просто.
Так чего же делала эта СХД за бешеные деньги — то же что и 99% СХД — обслуживала кластер виртуализации. Всё, что её отличало от самосбора в этом смысле — два независимых контроллера. Хотя и самосбор может иметь сколько угодно путей просто добавив сетевые интерфейсы.
Так что я не к тому, что СХД надо срочно заменить на SuperMicro + CentOS + tgtd. Я про то, что представление о корпоративном ИТ всё же меняется и зачастую такая замена уже уместна. Также как и использование публичных облаков, что в первые годы их продвижения казалось скорее экзотикой.
AntonVirtual Автор
Давайте разберем потезисно.
RPO / RTO — это не сложновысчитываемые характеристики, а всего лишь целевые показатели доступности сервисов, которые ДОЛЖНЫ присутствовать в техническом задании на проектирование.
Проектирование любой инфраструктуры без данных показателей — это шаманство, а не инженерная работа.
На практике получается совсем нелегко добыть от бизнес-подразделений показатели руб/час по простою и потере данных, из которых мы конечно получаем экономическое обоснование той или иной технологии в архитектуре инфраструктуры, или непосредственно сами RPO / RTO. Но это говорит лишь о слабости и незрелости менеджмента в целом. Никакой связи с безграмотностью проектировщика или его отношением к проектированию.
«Всего лишь обслуживала кластер виртуализации». Обслуживание кластера виртуализации — это предоставление пространства хранения данных с заданными / удовлетворяющими показателями производительности и надежности. При этом можно использовать весь набор технологий — репликацию (с управлением через средства гипервизоров, в данном случае SRM), снапшоты, QoS для выделенных под нагруженные сервисы отдельных томов, журналирование и так далее.
То, что хранилка за миллион долларов была тупой дисковой полкой с двумя контроллерами — это фейл, извините, вашего проектирования. Или попросту освоение бюджета.
DmitriyTitov
ОК, я вас понял. В вашей деятельности, судя по всему, возможно посчитать текущие и примерные будущие потребности, сравнить предложения на рынке и выбрать оптимальный вариант. При этом обосновав выбор с экономической точки зрения и увязав его с ИТ-стратегией, которая основана на бизнес-стратегии.
Мне же не так повезло. Мне приходилось прикидывать «на глаз» что есть сейчас и что будет. Выбирать из одного вендора (потому что другие не подходят). Экономические обоснования всегда должны быть в рамках бюджета. Да и вообще — заказчик как правило был из госсектора (хотя и не всегда), где понятие стоимости простоя в рублях вызовет тяжёлое недоумение (представьте, к примеру, Ген. прокуратуру). Ну и ТЗ и прочее писалось со стороны — пообщаться с бизнес-пользователями, поинтересоваться планами развития ИТ и будущими потребностями было просто не у кого или нельзя.
Вот мне почему-то кажется, что мой случай несколько чаще встречается на практике чем ваш. А может и нет, может просто так сложилось.
Norno
Сервера редко работают в вакууме и сами на себя, обеспечивают неких информационных систем обеспечивающих выполнение процессов. Ну а дальше определяем критичность процесса, его влияние на выполняемые организацией функции, от этого и стоит исходить.
В самом простом варианте, можно посчитать на сколько увеличится трудоемкость выполняемых процессов и определить стоимость простоя как суммарное увеличение трудоемкости (и стоимости соответственно). Не правильно и очень грубо, но вполне возможно.
Dr_Wut
SDS имеет свою нишу и далеко не везде применим
AntonVirtual Автор
Открою секрет. Абсолютное большинство современных классических СХД — это стандартные x86 серверы без какого либо специального аппаратного обеспечения. Вся логика реализована в софте, т.е. фактически это SDS.
Одним из мамонтов пока остается HPE 3Par, в котором используются ASICи.
Dr_Wut
И? Как это относиться в тому что я сказал? Или для вас это одно и тоже?
NoOne
Это отонсится так, что уже почти везде и есть в принципе SDS. И да, это и есть SDS, просто разные формы.
Dr_Wut
Вы реально считаете что какой-нибудь Dell compilent/IBM storwize то же самое что vsan/nutanix (в части sds)? Реально?
DmitriyTitov
Мне со стороны кажется, что да, примерно так оно и есть.
Вам, как я понимаю, так не кажется. Можете указать основные различия, которые на ваш взгляд именно делают разницу?
bbk
Мелким компаниям из 15 сотрудников, может и нужно, но здесь вопрос не в том что хотелось бы, а в том что у таких компаний денег на это нет. По этому такие комапнии выкручиваются самосбором а-ля Windows File Server или Linux NFS. И такой подход приемлем и скорее всего даже бизес-обоснован для таких компаний.
Но не нужно пытаться натянуть мартышку на глобус, для больших компаний этот же подход просто не катит.
А вот огромные клауд-провайдеры а-ля AWS/Azure/Google/Alibaba/IBM могут себе позволить это держать на самосборе. Но даже они не могут покрыть все портебности бизнеса в системах хранения, собственно по этому вендоры появляются как услуга в этих гигантах со своими железяками и софтом. Потому что десятки лет опыта, интеграцию и экосистему, не пропьёшь.
AntonVirtual Автор
>а в том что у таких компаний денег на это нет.
Нет денег на что? на ЭТО?
ИТ на сегодня — это часть средств производства. В рамках ИТ оборудования есть система хранения данных. Стоимость покупки средств производства (CapEx) и обслуживания средств производства (OpEx) учитываются при продаже продуктов / услуг.
Далее мы рассматриваем влияние доступности / качества средств производства на само производство. Если встанет станок, то как это повлияет на деятельность компании? Если будет утерян годовой отчет, или полностью будет утеряна 1С: Склад, то как это повиляет на деятельность компании?
«Денег нет» — это неверная фраза, верная будет звучать так: «ты, как ответственный за ИТ системы, не предоставил мне, ответственного за финансы, ИТ-риски и влияние их на основную деятельность компании, а я не заложил это в бюджет». Об этом я тоже не раз писал.
www.beerpanda.ru/?p=176
И да, если влияние ИТ систем и в частности СХД на компанию низкое и компания может спокойно простоять дня три без СХД, то выбор SOHO системы или самосбор вполне обоснованный и правильный. Но сначала надо посчитать.