

От переводчиков:
Постмортемы — одна из любимых и популярных тем в нашей среде. Но честный и оперативный отчёт такого крупного сервиса, как Cloudflare, — это всё же не самое частое явление. Поэтому нам показалось интересным перевести его для читателей нашего блога. Ну, а в конце — плюшечка для любителей матана.
Почти девять лет назад, когда Cloudflare была крошечной компанией, я был их клиентом, а не сотрудником. Где-то через месяц после их запуска я получил уведомление, что DNS-сервер, обслуживающий мой маленький сайт jgc.org, по всей видимости, прилег. Как оказалось, ребята выкатили обновление, затрагивающее работу Protocol Buffers, что и «сломало» обслуживающий меня DNS-сервер. Я написал письмо напрямую Мэттью Принсу с темой «Где мой DNS?», и он прислал длинный, полный технических деталей ответ (всю переписку вы можете прочитать здесь). Моя реакция была следующей:
От кого: Джон Грэм-Каминг
Дата: Четверг, 7 октября 2010 в 9:14
Тема: Re: Где мой dns?
Кому: Мэттью Принс
Отличный отчёт, спасибо. Будьте уверены, я обязательно позвоню вам, если возникнут проблемы. Возможно, было бы хорошей идеей написать об этом всем в блог, когда у вас появятся все технические детали. Думаю, люди хорошо оценили бы открытость и честность в подобной ситуации. Особенно если вы приложите снимки графиков с возросшим после запуска трафиком.
У меня есть довольно примитивная система мониторинга сайтов — я получаю смс, когда что-то идёт не так. И по моим данным, недоступность продолжалась с 13:03:07 до 14:04:12. Проверки осуществляются каждые 5 минут.
Вы наверняка сделаете выводы из этого инцидента. Но вы уверены, что вам не нужен кто-нибудь в Европе? :-)
На что он ответил:
От кого: Мэттью Принс
Дата: Четверг, 7 октября 2010 в 9:57
Тема: Re: Где мой dns?
Кому: Джон Грэм-Каминг
Спасибо. Мы отписались всем, кто к нам обратился. Сейчас я приеду в офис и напишу что-нибудь в блог или закреплю официальный пост вверху нашего форума. Я полностью согласен, что прозрачность — лучшая политика.
Итак, сегодня в качестве работника Cloudflare, которая стала гораздо больше, чем девять лет назад, я могу открыто и честно рассказать о свежей ошибке и ее влиянии на все последующие наши действия в этой области.
Что произошло 2 июля
Второго июля мы добавили новое правило фаервола, что вызвало перегрузку ядер CPU на серверах, маршрутизирующих HTTP/HTTPS-трафик в сети Cloudflare по всему миру. Мы постоянно обновляем наши правила для WAF с учетом новых уязвимостей и угроз. Например, в мае мы оперативно обновили правила файерволов для защиты сайтов от серьезной уязвимости в SharePoint. В целом, возможность быстрой раскатки обновлений безопасности на глобальном уровне является важнейшей фичей наших WAF.
Но к сожалению, в прошлый вторник наше обновление безопасности содержало в себе регулярное выражение, которое сделало чрезвычайно больно и без того загруженным процессорам серверов обработки HTTP/HTTPS-трафика. Это привело к резкому падению производительности proxy, CDN и файерволов компании. На графике ниже можно увидеть, как потребление ресурсов наших обработчиков трафика достигло отметки в 100%:
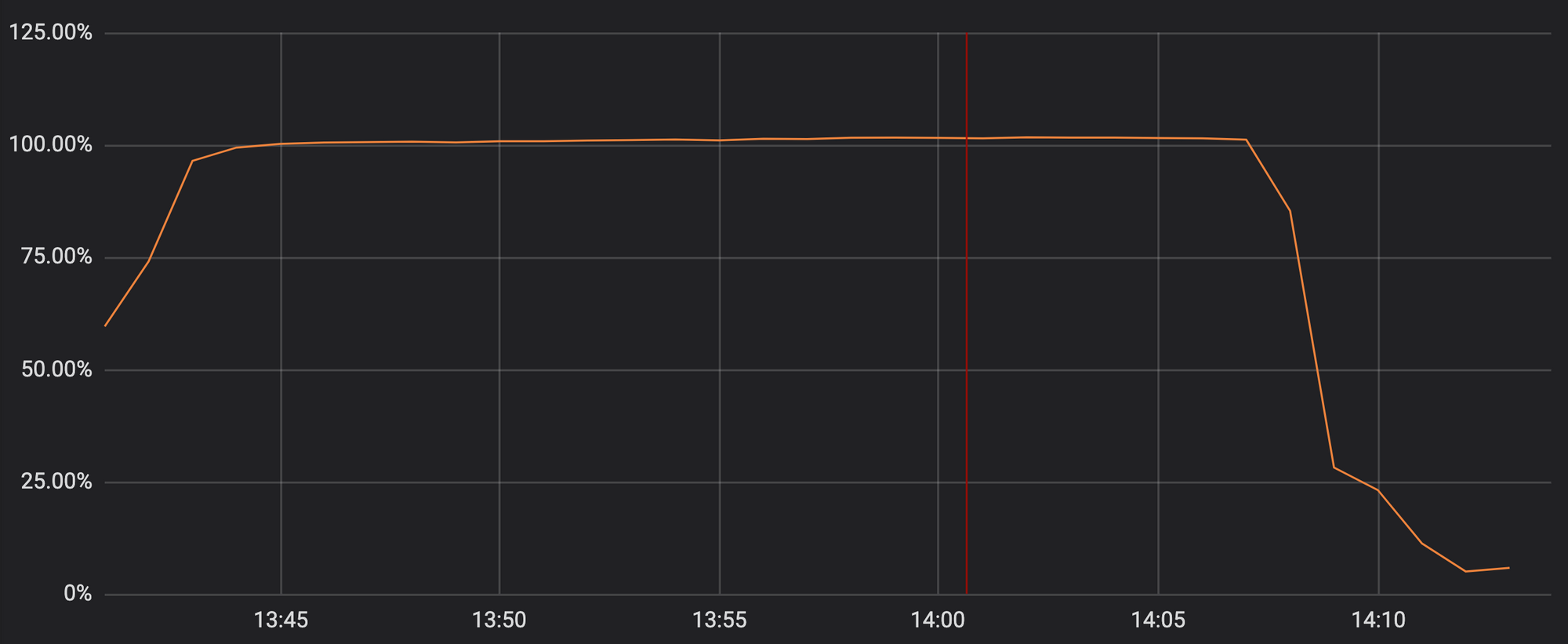
Нагрузка на процессоры в одном из наших PoPs во время инцидента.
В итоге, наши сайты-клиенты (и, соответственно, их клиенты) при попытке открыть любую страницу в домене Cloudflare в ответ получали ошибку 502. Страницы этих ошибок были сгенерированы первой линией веб-серверов Cloudflare, у которых еще оставались свободные мощности CPU, но вот на маршрутизацию трафика ресурсов уже не хватало.
Мы знаем, насколько подобная ситуация ужасна для наших клиентов. И нам стыдно за случившееся. Этот инцидент повлиял и на наши собственные процессы решения возникшей проблемы.
Уверен, наши клиенты получили солидную порцию стресса, страха и разочарования. Но что на самом деле обидно, так это то, что до этого мы отработали без глобальных сбоев целых шесть лет.
Как я говорил ранее, перегрузку процессоров вызвало одно WAF-правило, которое содержало в себе некорректно написанное регулярное выражение. Именно оно стало причиной чрезмерного бэктрекинга. А вот и сам виновник наших проблем: (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))).
И хотя само регулярное выражение, поломавшее наши DNS, интересно многим людям, но полная история о том, как прошли 27 минут борьбы за работоспособность сервисов Cloudflare, намного сложнее, чем просто «мы выкатили обновление с кривой регуляркой». У нас было время на то, чтобы восстановить полную картину событий, которые в итоге привели нас к падению DNS и заставили реагировать на проблему в оперативном режиме. Если вы хотите узнать больше о бэктрекинге в регулярных выражениях и что делать в таких случаях, то вам стоит перейти в конец статьи. Вся нужная информация находится там.
Что случилось
Давайте начнем с восстановления последовательности произошедших событий. Все временные отметки далее по тексту указываются в формате UTC.
В 13:42 инженер из команды разработки файервола выкатил минорное обновление правил по обнаружению XSS-атак с помощью автоматизированных запросов. Эти действия привели к автоматическому создаю реквест-тикета в нашей Jira.
Спустя три минуты на главной PagerDuty появилось сообщение о проблемах в WAF. Это сработал синтетический тест, который проверяет функциональность WAF (всего у нас около сотни таких) из-за пределов инфраструктуры Cloudflare. Делается это, дабы убедиться, что все работает корректно. Вслед за первым алертом быстро посыпались предупреждения от внешних тестов на прочих элементах нашей инфраструктуры, глобальный трафик упал, стала вылетать 502 ошибка, и все это сопровождалось сообщениями о перегрузке CPU на наших PoPs по всему миру.


Некоторые из этих алертов прилетели и на мои смарт-часы, из-за чего я сорвался с совещания и устремился на свое рабочее место. Там же я узнал от нашего руководителя разработки, что мы потеряли около 80% трафика. Я побежал к нашим SRE, которые уже занялась исправлением возникшей ситуации. В самом начале кризиса у нас были предположения, что это какая-то беспрецедентная по масштабам атака, которую раньше мы никогда не видели.

SRE команда Cloudflare распределена по всему миру, что обеспечивает бесперебойную работу в режиме 24/7. Получаемые нами оповещения возникают каждый день и обычно носят весьма специфический и локальный характер. Все они отслеживаются внутренними системами мониторинга и ежедневно анализируются. Однако в этот раз общий паттерн возникновения страниц и ошибок указывал, что произошло что-то очень серьезное. Команда SRE немедленно объявила инцидент уровня P0 и эскалировала проблему выше — на руководителя отдела разработки и проектирования.
В это время лондонская команда инженеров находилась на нашем крупном внутреннем мероприятии и слушала технический доклад. Выступление спикера было прервано, после чего вся команда собралась в большом конференц-зале, а кто не поместился — подключились удаленно. Все указывало на то, что SRE столкнулись с проблемой, которую они не могут решить в одиночку без поддержки отдела разработки. Ситуация требовала, чтобы каждая причастная к возможному решению команда подключилась к параллельной работе.
К 14:00 мы выяснили, что проблемы возникали в WAF, так что вариант с крупномасштабной атакой был признан несостоятельным. В качестве подтверждения версии с WAF наша команда мониторинга производительности еще и извлекла логи CPU. Также мы все перепроверили с помощью strace. Кроме этого, в журналах ошибок было зафиксировано, что проблемы возникли именно в WAF, а не где-то еще. В 14:02 было предложено использовать «Global Kill» — встроенный механизм полного отключения какой-либо части Cloudflare по всему миру. И в этот момент вся команда дружно посмотрела на меня.
Но вообще, то, как мы пытались провести «Global kill» всего WAF — это совершенно другая история. Там проблема была в том, что мы используем внутренние разработки для авторизации и аутентификации наших сотрудников на нашей панели управления. И когда мы попытались провернуть этот сценарий оказалось, что некоторые члены нашей команды потеряли доступ к своим учетным записям из-за сработавшего механизма автоматического отключения, который настроен на мониторинг частоты использования панели управления. Пользовались они ею не слишком часто, и система их деактивировала.
Также мы оказались отрезаны от других наших сервисов, таких, как Jira или билд-система. Чтобы добраться до них, нам пришлось воспользоваться полузабытым обходным путем (который мы в итоге закрепим в качестве резервного варианта после решения проблемы). В итоге, к 14:07 один из наших сотрудников смог активировать «Global kill» и таки пристрелил проблемный WAF, а уже через две минуты, в 14:09, трафик по всему миру стабилизировался и нагрузка на процессоры вернулась к нормальным значениям. Все прочие механизмы защиты Cloudflare, само собой, продолжали работать.
После того, как мы убедились в том, что «интернет работает», мы перешли к починке самого WAF. Из-за общей деликатности ситуации мы стали перепроверять все возможные сценарии, в том числе и задавались вопросом «а на самом ли деле проблема была в WAF?» Точку поставил локальный тест, в ходе которого мы раскатали текущую версию WAF на один конкретный город (перебросив трафик наших клиентов на другие серверы) и увидели, что проблема повторилась.
К 14:52 мы достигли 100% уверенности в том, что нашли корень проблемы и исправили ее, после чего WAF был вновь активирован по всему миру.
Как работает Cloudflare
В Cloudflare есть команда инженеров, которая работает над нашим собственным продуктом WAF Managed Rules. Их задача состоит в постоянном улучшении показателей системы обнаружения, снижении количества ложных срабатываний и быстром реагировании на новые угрозы. За последние 60 дней команда обработала 476 тикетов на внесение изменений в правила WAF (то есть в среднем они делают это раз в 3 часа).
Наше проблемное изменение в правилах WAF изначально должно было быть развернуто в режиме симуляции, то есть трафик им обрабатывается, но без каких-либо последующих блокировок вне зависимости от полученного результата анализа. Мы используем этот режим для проверки эффективности вносимых изменений и измерения количества ложноположительных и ложноотрицательных срабатываний WAF. Но даже в режиме имитации правила все же выполняются (пусть и без дальнейших последствий для трафика). В нашем случае такое правило содержало в себе регулярное выражение, которое создавало чрезмерную нагрузку на CPU.

Как видно из реквеста выше, у нас всегда есть план развертывания, план отката и ссылка на Standard Operating Procedure (SOP) для этого типа операции. SOP для внесения изменений правил WAF позволяет производить операцию обновления глобально, то есть для всех серверов разом. Это очень отличается от того, как мы обычно работаем в Cloudflare: сначала SOP требует разместить программное обеспечение в нашей внутренней сети (PoP) для сотрудников, затем можно поставить обновление какому-то небольшому количеству клиентов, находящихся в изолированной от остального мира локации. И только после этого можно раскатать обновление в два этапа: по широкому кругу клиентов и, наконец, по всему миру.
Сам процесс выпуска новых версий программного обеспечения выглядит так: для работы внутри компании мы используем связку git и BitBucket. Разработчики пишут код, билдят его в TeamCity, а после сборки проводят ревью с последующим одобрением рабочей сборки. Как только одобрение получено, проходит сборка рабочей версии кода, которая подвергается повторному тестированию.
Если сборка и тесты пройдены успешно, в Change Request Jira генерирует запрос на изменение статуса, который должен быть одобрен менеджером или техлидом. После получения необходимого разрешения начинается процесс деплоя, который мы называем «animal PoPs»: DOG, PIG и Canaries.
DOG PoP — это личный PoP Cloudflare (по сути, такие стоят в городах по всему миру). Его отличие от внешней инфраструктуры в том, что используется этот PoP только сотрудниками компании. Этот PoP позволяет нам обнаруживать проблемы до того, как код попадет на боевые сервера с пользовательским трафиком. И чаще всего это работает.
Если тестирование на DOG PoP прошло успешно, код переносится на PIG — PoP Cloudflare, через который ходит трафик наших клиентов, пользующихся серверами бесплатно.
Если и на PIG все гладко, код перемещается на Canaries. Всего у нас три таких сервера по всему миру. Через них проходит как бесплатный, так и трафик от платящих за наши услуги клиентов. Там мы производим окончательную проверку обновления на наличие каких-либо ошибок.

WAF и угрозы
В последние несколько лет мы наблюдали резкий рост числа различных уязвимостей. Мы считаем, что произошло это по причине возросшей доступности инструментов для тестирования программного обеспечения, например, fuzzing ядра Linux (о котором мы писали ранее в блоге).

Для поиска уязвимостей часто используется принцип Proof of Concept (PoC), в рамках которого решения публикуются на Github, что позволяет командам разработки быстро оттестировать уязвимость и выстроить адекватную защиту. Исходя из этого, для Cloudflare крайне важно быстро реагировать на атаки для того, чтобы оперативно извещать клиентов, которые, в свою очередь, эти уязвимости устраняют.
Отличным примером того, как Cloudflare занимает активную позицию в защите ПО, стало развертывание наших средств защиты SharePoint в мае этого года (почитать можно здесь). Буквально сразу же после публикации нашего инструментария мы зафиксировали всплеск интереса к нему со стороны клиентов, поэтому наша команда до сих пор занимается этим направлением и создает новые правила для файерволов.
Правило, повлекшее после своего внедрения недавний сбой, было нацелено против XSS-атак. Их число также возросло в последние годы.

Стандартная процедура внедрения правил WAF гласит, что CI-тесты должны проводиться до момента глобальной раскатки обновления. То же произошло и 2 июня, собственно, для одного из новых правил. В 13:31 один из наших инженеров смержил пулл-реквест, и в итоге уже в одобренный и протестированный патч попал измененный код.

В 13:37 TeamCity провел свои тесты и дал зеленый свет на патч. Набор проводимых в билдере тестов проверял общую работоспособность основных функций и модулей WAF, а сам набор представляет собой большое число сравнительных модульных тестов для отдельных участков системы. После запуска модульных тестов отдельные WAF-правила проверяются путем генерации огромного числа HTTP-запросов к системе. Эти запросы нужны для тестирования блокировки спама со стороны WAF (то есть нужны, чтобы убедиться что система реагирует на атаки). Кроме того система должна пропускать «белые» HTTP-запросы, то есть тест помогает убедиться, что система не реагирует на ложные ситуации и не начинает резать все подряд просто так. Чего не сделал TeamCity? Он не протестировал WAF на чрезмерное потребление ресурсов CPU. Последующий анализ журналов показал, что на тестовых сборках WAF не было выявлено какого-либо увеличения времени выполнения тестов на новом правиле, которое в итоге на «боевой» версии приведет к исчерпанию вычислительных мощностей центральных процессоров.
После проведения тестов, в 13:42 TeamCity начал автоматическую раскатку обновления.

Quicksilver
Так как правила WAF нужны, чтобы противодействовать возникающим угрозам, они раскатываются с помощью нашего распределенного хранилища ключей (KV) Quicksilver. Этот инструмент может глобально применять изменения по всей инфраструктуре за считанные секунды. Quicksilver используется всеми нашими клиентами для внесения изменений в конфигурацию через нашу инфопанель и API. То есть именно Quicksilver лежит в основе нашей способности мгновенно реагировать на ситуацию и вносить изменения.
Мы не очень много рассказывали об этом инструменте. Раньше в качестве глобального распределенного хранилища мы пользовались Kyoto Tycoon, но в какой-то момент столкнулись с эксплуатационными проблемами и создали собственное KV-хранилище, которое сейчас реплицировано более чем по 180 городам. Короче, Quicksilver — это то, как мы вносим изменения в конфигурацию, обновляем правила WAF или раскатываем написанный с помощью Cloudflare Workers JS-код.
С момента нажатия кнопки на панели управления или вызова API-запроса на внесение изменения в конфигурацию и до момента его глобального вступления в силу требуется буквально несколько секунд. Клиенты полюбили такую скорость, а в связке с Workers они ожидают вообще почти мгновенного развертывания кода. В среднем, через Quicksilver ежесекундно применяется около 350 изменений.
Quicksilver — очень быстрый инструмент. С ним мы достигли среднего показателя глобального применения обновления в 2,29с. Обычно скорость — это прекрасно. Такая скорость означает, что при команде «очистить кэш» операция пройдет в глобальном масштабе почти мгновенно. Когда вы выгружаете код с Cloudflare Workers, он пушится с той же скоростью. Все это — часть обещанных быстрых обновлений от Cloudflare именно тогда, когда эти обновления нужны вам.
Но в нашей истории скорость означала, что новые правила раскатались глобально всего за пару секунд. Внимательный читатель мог заметить, что WAF написан на Lua. Cloudflare вообще широко применяет Lua в WAF, что обсуждалось тут. Для внутренних целей Lua WAF использует PCRE и обратное отслеживание совпадений, лишенное механизма защиты от runaway-выражений.

Все, что случилось до момента раскатки новых правил было выполнено «корректно»: был получен запрос на пуш, он был утвержден, CI/CD билдер собрал и протестировал код, запрос на внесение изменений был отправлен вместе с подробным отчетом SOP, и, наконец, правило было глобально развернуто.

Процесс развертывания WAF Cloudflare
Что пошло не так
Как уже говорилось ранее, мы добавляем десятки новых правил WAF еженедельно, плюс у нас есть множество систем для предотвращения любого негативного воздействия в ходе развертывания обновлений. Поэтому, когда что-то идет не так, причиной тому является маловероятное совпадение множества факторов. И если разобраться, какая именно последовательность событий привела к конечному сбою, то результат можно получить ошеломительный. Ниже перечислены события и уязвимости, которые в итоге привели нас к переходу службы маршрутизации HTTP/HTTPS-трафика в автономный режим:
- Инженер написал регулярное выражение, которое легко отследить.
- Защита, которая могла бы предотвратить чрезмерное потребление ресурсов CPU этим выражением, была ошибочно удалена из кода WAF в рамках рефакторинга, цель которого заключалась в снижении потребления системой ресурсов процессора.
- Используемый тип регулярных выражений не имел гарантированной сложности.
- В тестовой сборке не было возможности отследить чрезмерное потребление ресурсов процессора.
- SOP позволял вносить сразу глобальные изменения в правила WAF, если они не относились к критичным функциям и ситуациям.
- Стандартный план отката изменений требовал выполнения полной сборки WAF дважды, что занимает слишком много времени.
- Первое оповещение о глобальном падении трафика было получено слишком поздно.
- Мы не слишком быстро обновили страницу статуса.
- У нас возникли трудности с доступом к нашим собственным внутренним системам из-за произошедшего сбоя, а запасная процедура была известна не слишком хорошо.
- SRE потеряли доступ к некоторым системам, потому что их учетные записи были отключены из-за срабатывания системы безопасности.
- Наши клиенты не могли получить доступ к личной панели управления Cloudflare или API, потому что они находятся за пределами сети компании.
Что изменилось с того вторника
Во-первых, мы полностью прекратили работу над релизом на WAF и сейчас делаем следующее:
- Повторно внедряем защиту от чрезмерного потребления ресурсов CPU, которую вырезали в ходе рефакторинга (готово).
- Проверяем все 3868 правил WAF вручную, в попытке найти и исправить любые подобные чрезмерные операции (проверка завершена).
- Устанавливаем пороговые значения производительности для всех правил в нашем наборе тестов (к 19 июля).
- Переключаемся на re2 или Rust regex engine, так как оба имеют ограничения по времени исполнения кода (к 31 июля).
- Изменяем SOP для развертывания правил — делаем его поэтапным, как и в случае любого другого программного обеспечения Cloudflare, сохраняя при этом возможность экстренно раскатать обновление в случае атаки.
- Внедряем возможность экстренного переноса Cloudflare Dashboard и API из-за пределов сети компании.
- Автоматизируем обновление страницы статуса Cloudflare
В долгосрочной перспективе планируется отойти от Lua в WAF, на котором я написал его несколько лет назад, и портировать систему на наш новый Firewall-движок. Это сделает WAF быстрее и добавит ему еще один уровень защиты.
Приложение: поиск с возвратом в регулярных выражениях
Чтобы полностью понять, как выражение (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*))) вызывало чрезмерное потребление процессорных ресурсов, нам нужно немного разобраться в том, как работает движок стандартных регулярных выражений. Критической частью является эта — .*(?:.*=.*). Выражение (?: с парной закрывающей скобкой ) является незахватывающей группой (т.е., выражения внутри скобок обрабатываются как единое целое).
В рамках обсуждаемой задачи мы эту группу можем спокойно игнорировать и развернуть выражение в виде .*.*=.*. После подобного разворачивания оно начинает выглядеть очевидно переусложнённым. Но, что ещё более важно, использование выражений «соответствие чему угодно, с последующим чем угодно» при работе с реальными производственными задачами (такими, как правила нашего WAF-фильтра) ведут к катастрофическому количеству операций обратного поиска.
И вот почему.
В регулярном выражении . означает соответствие одному символу, а .* значит жадное (максимально возможное количество символов) соответствие любому количеству символов, от нуля и более. Поэтому, .*.*=.* значит буквально следующее: ищем ноль или более символов, снова ищем ноль или более символов, потом ищем знак равенства =, а потом ещё раз ищем ноль или более символов.
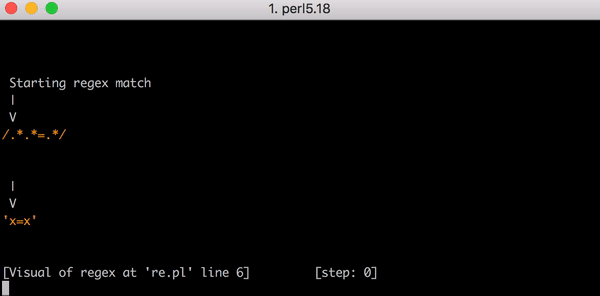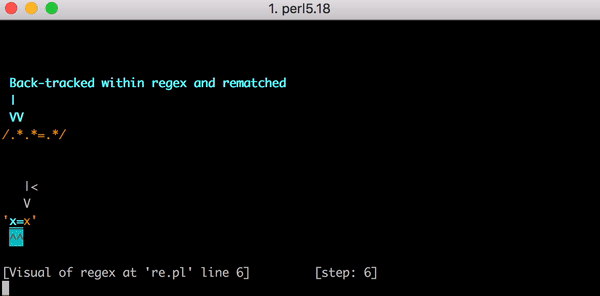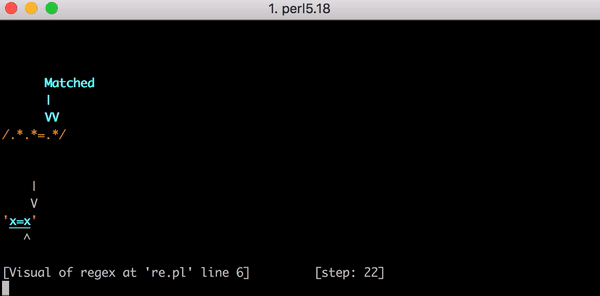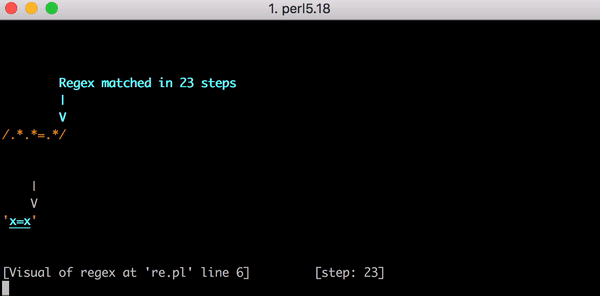
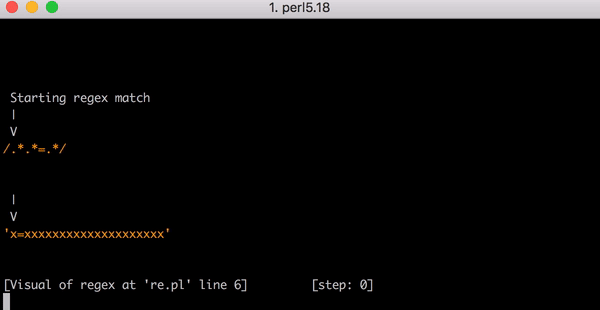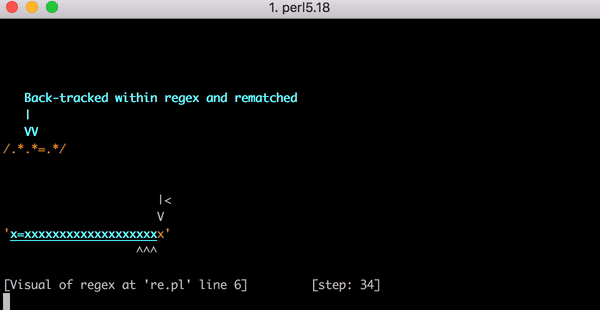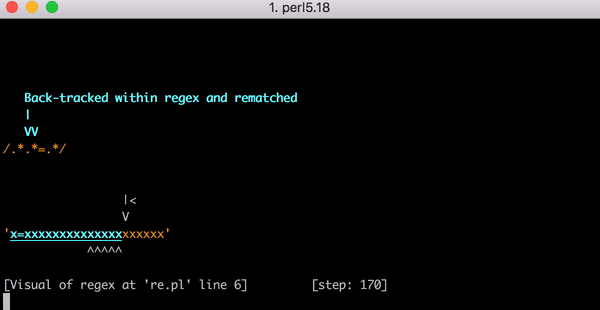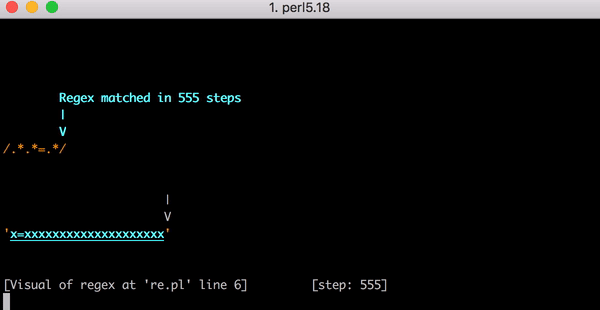
Предположим, у нас есть тестовая строка x=x. Она будет соответствовать указанному выше выражению. .*.* перед знаком равенства поймают первый x (один из .* будет соответствовать x, другой — нулю символов). Кусок же .*, стоящий после равно = будет ловить конечный x.
И на то, чтобы это соответствие полностью посчиталось, требуется 23 шага. Первый .* в выражении .*.*=.* действует жадно и соответствует всей строке x=x. Алгоритм переходит дальше, к следующему .*. Но больше в строке не осталось символов, так что он ловит соответствие нулю символов (это логично). После алгоритм переходит к знаку равенства =. И поскольку тестовая строка уже закончилась (первый .* покрыл x=x полностью), то проверка соответствия проваливается.
В этот момент движок регулярных выражений возвращается в исходную точку. Он возвращается к первому .* и пытается покрыть им строку x= (вместо x=x) и затем переходит ко второму .*. Тот .* покрывает второй x и символы для поиска соответствий снова заканчиваются. Поэтому, когда алгоритм пытается найти соответствие знаку равенства =, проверка выражения .*.*=.* снова проваливается. Движок откатывается ещё раз.
На сей раз он снова пытается покрыть первым .* строку x=, но второй .* на сей раз не пытается соответствовать x, теперь он соответствует нулю символов. Следующим шагом снова ищем =, снова проваливаемся, снова откатываемся.
Теперь же первый .* соответствует только первому x. Но второй .* действует жадно и соответствует остатку строки =x. И вы понимаете, к чему это приводит. При попытке в очередной раз найти = снова ничего не выходит, откатываемся ещё раз.
Первый .* всё ещё соответствует первому x. Второй же .* теперь соответствует одному лишь знаку равенства =. Но, да, вы снова угадали, когда мы начинаем искать конкретно знак равенства, мы снова оказываемся там же, где и в прошлые разы. Откатываемся. И помните, это всего лишь строка из трёх символов.
Наконец, когда первый .* соответствует только первому x, а второй .* соответствует нулю символов, движку удаётся найти соответствие знаку равенства = из выражения знаку равенства = в строке. Он переходит к последнему .* и сопоставляет его с конечным x.
23 шага, чтобы найти соответствие строке x=x. А вот короткое видео, наглядно показывающее с помощью перлового модуля Regexp::Debugger, как происходит вычислительный процесс.
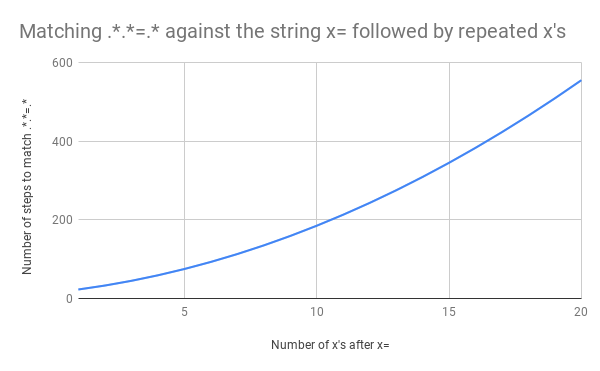
Это серьёзная работа. Но что произойдёт, если строка изменится и у нас вместо x=x будет, например, x=xx? Поиск соответствия в такой строке займёт 33 шага. А для строки x=xxx — 45 шагов. Рост нелинейный. Вот график, показывающий рост количества шагов, необходимых для поиска соответствия строкам от x=x до x=xxxxxxxxxxxxxxxxxxxx (20 иксов после знака равенства). Для строки с 20-ю иксами алгоритму требуется 555 шагов на поиск соответствия! (Ещё хуже, если x= убрать: для того, чтобы понять, что строка из одних иксов (20 шт.) не соответствует регулярке, алгоритму понадобится 4067 шагов).
Вот видео с процессом поиска соответствия строке x=xxxxxxxxxxxxxxxxxxxx:
Это плохо, потому что с ростом размера входных данных супер-линейно растёт и время поиска их соответствия. Но ситуацию можно сделать ещё кошмарнее, если использовать слегка изменённое выражение. Представим, что оно выглядело бы вот так: .*.*=.*; (т.е. с точкой с запятой в конце). Оно легко могло бы использоваться для поиска соответствий в строках вида foo=bar;.
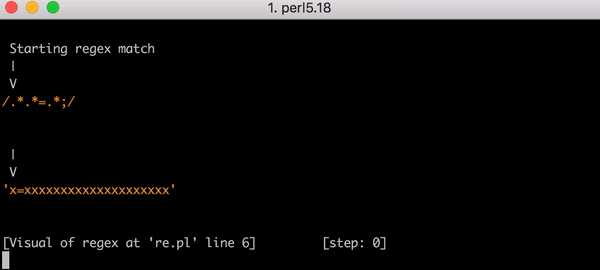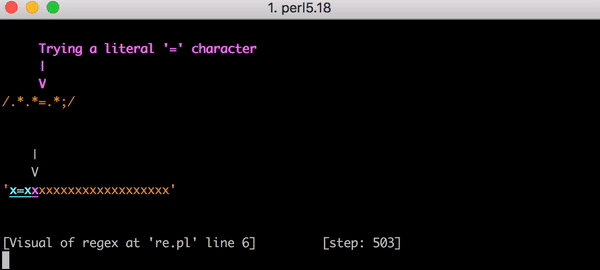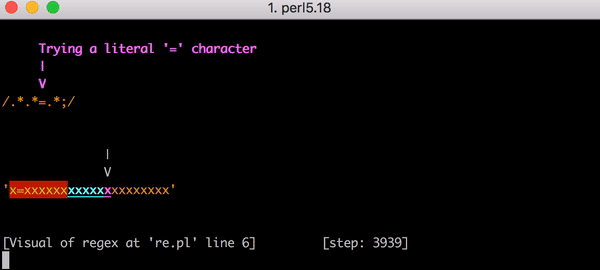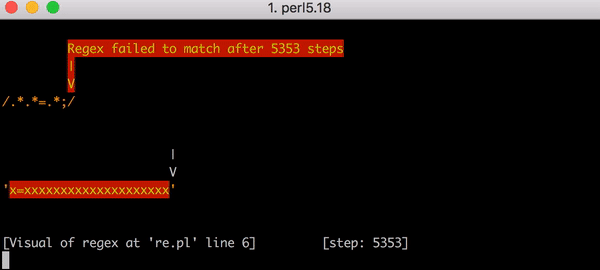
В этом виде количество необходимых шагов становится просто катастрофическим. Для поиска соответствия строке x=x требуется 90 шагов вместо 23. И количество этих шагов растёт очень быстро. Поиск соответствия в строке x=xxxxxxxxxxxxxxxxxxxx требует 5353 шага. Вот соответствующий график. Внимательно посмотрите на значения по оси ординат в сравнении с предыдущим графиком.
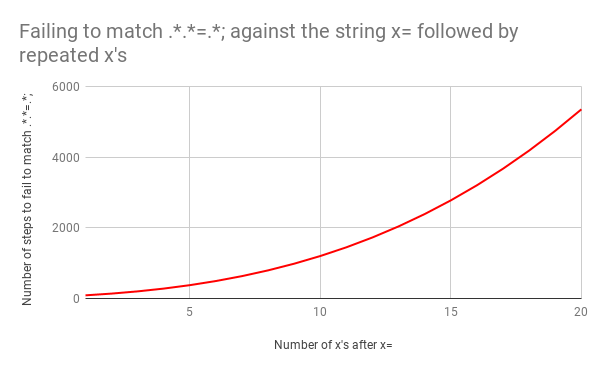
Для полноты картины вот все 5353 шага, ведущие к провалу в поиске соответствия выражению .*.*=.*; в строке х=xxxxxxxxxxxxxxxxxxxx:
Использование ленивых квантификаторов вместо жадных помогает держать в узде количество откатов, возникающих в подобных ситуациях. Если изменить оригинальное выражение на .*?.*?=.*?, то на поиск соответствия в строке x=x уйдёт 11 шагов (вместо 23). Столько же для строки x=xxxxxxxxxxxxxxxxxxxx. Так происходит потому что знак вопроса ? после .* указывает движку искать наименьшее возможное количество подходящих символов.
Но ленивые квантификаторы — не полное решение проблемы большого количества операций обратного поиска. Смена ужасного примера с .*.*=.*; на .*?.*?=.*?; не меняет время выполнения вообще. Для x=x это всё ещё 555 шагов, для x=xxxxxxxxxxxxxxxxxxxx — 5353 шага.
Единственным реальным решением, кроме полного переписывания выражения в более конкретном виде, является отход от движка регулярных выражений с механизмами обратного поиска. Чем мы будем заниматься в течение следующих нескольких недель.
Решение данной проблемы известно с 1968 года, когда Кен Томпсон написал статью «Методы программирования: алгоритм поиска регулярных выражений». В статье описывается механизм конвертации регулярных выражений в недетерминированный конечный автомат, с последующим проходом через цепочку состояний, используя алгоритм, выполняющийся линейно, в зависимости от размера вводимых данных.

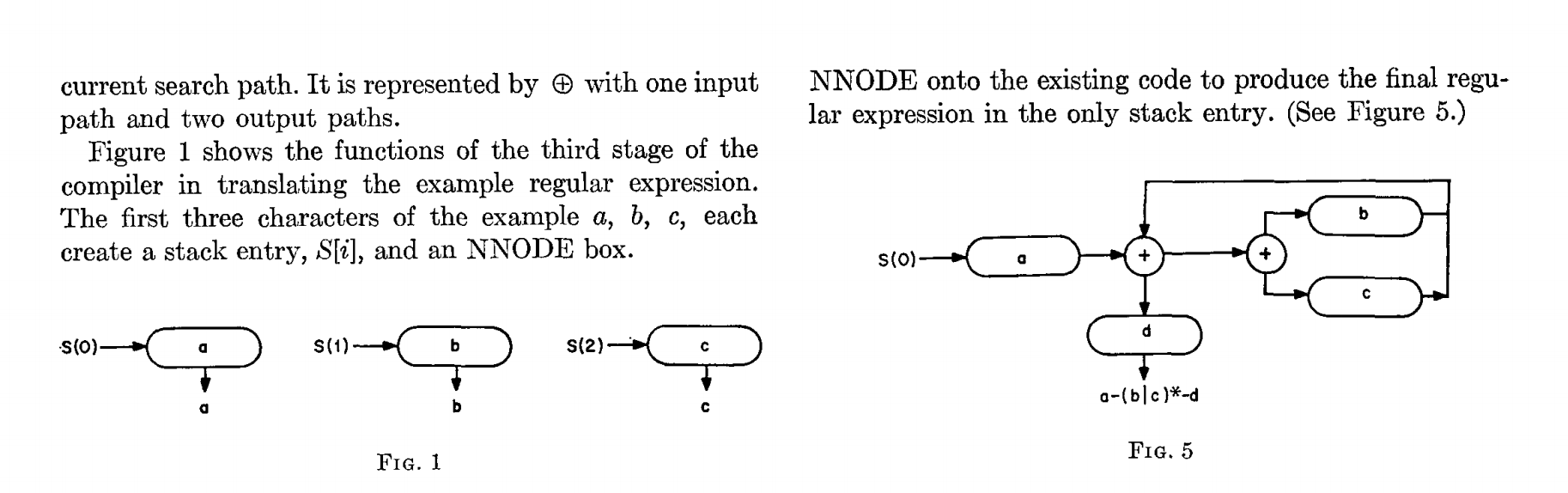
Вот как будет выглядеть выражение .*.*=.* представленное по аналогии с диаграммами из статьи Томпсона.
На рис. 0 указано пять состояний, начинающихся с 0, а также три цикла, начинающиеся с состояний 1, 2 и 3. Эти три цикла соответствуют трём .* в регулярном выражении. Три блока с точками внутри соответствуют отдельному символу. Блок со знаком равенства соответствует литералу =. Состояние 4 — конечное состояние, по его достижении регулярное выражение считается успешно совпавшим.
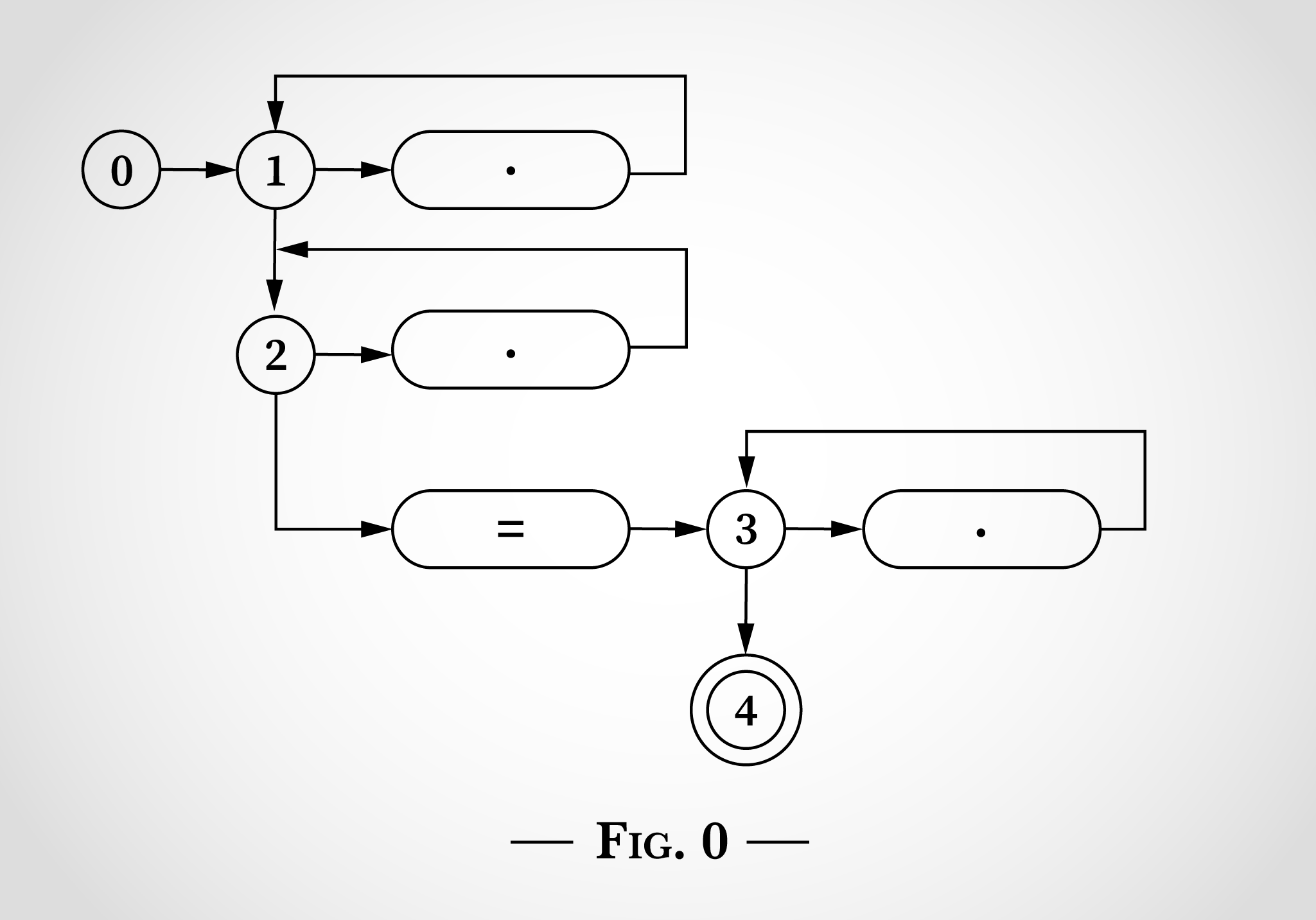
Чтобы понять, как подобный график состояний можно использовать для сопоставления регулярного выражения .*.*=.*, мы снова возьмём строку x=x. Программа начинается в состоянии 0, как показано на рис. 1.
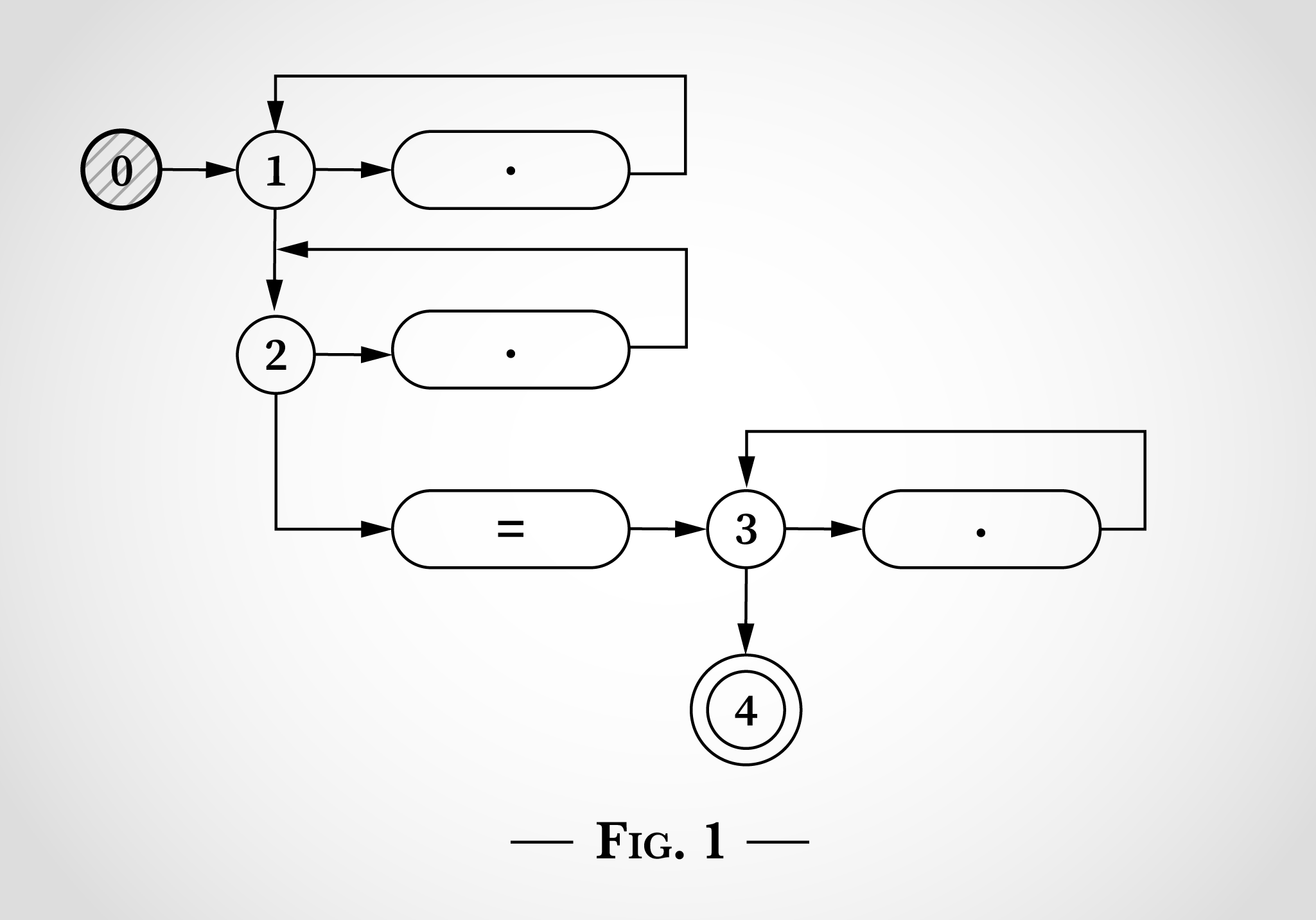
Ключом к работе этого алгоритма является то, что конечный автомат находится в нескольких состояниях одновременно. Недетерминированный конечный автомат (НКА) сделает все возможные переходы одновременно.
И прежде чем он начинает читать входные данные, он сразу переходит к состояниям 1 и 2, как показано на рис. 2.
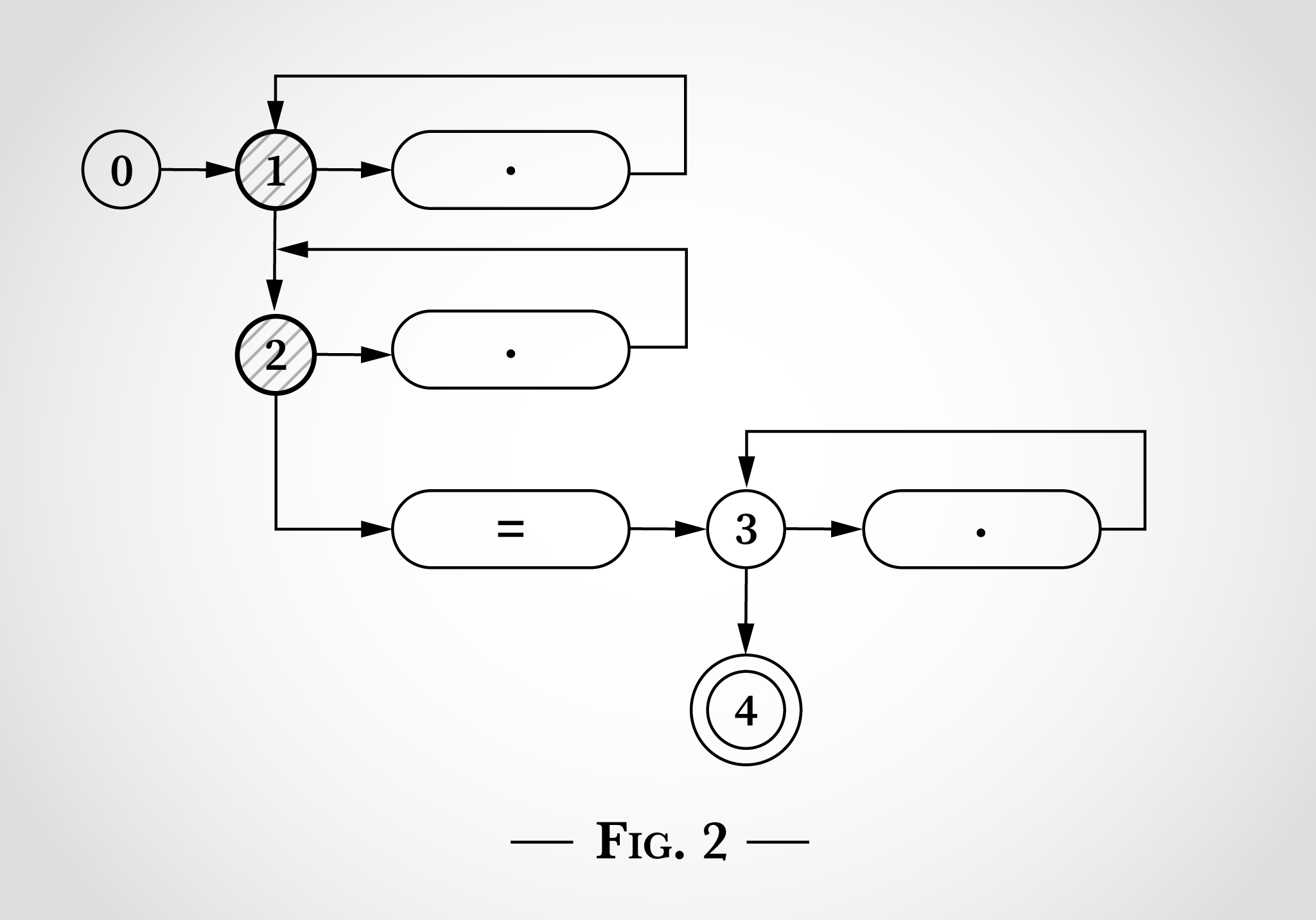
И как можно увидеть на рис. 2, вот что происходит при попытке оценки первого x в x=x — он может быть сопоставлен с верхней точкой с переходом от состояния 1 обратно к состоянию 1. Или же он может быть сопоставлен с нижней точкой с переходом от состояния 2 к состоянию 2.
Поэтому после сопоставления первого x в x=x состояния система всё ещё находится в состояниях 1 и 2. Перейти к состояниям 3 или 4 невозможно без литерала =.
Далее алгоритм учитывает = в x=x. Как и в ситуации с x ранее, он может быть сопоставлен как с первыми двумя циклами переходов состояния 1 и состояния 2, так и с литералом = и алгоритм перехода из состояния 2 к состоянию 3 (и сразу к 4). Это показано на рис. 3.
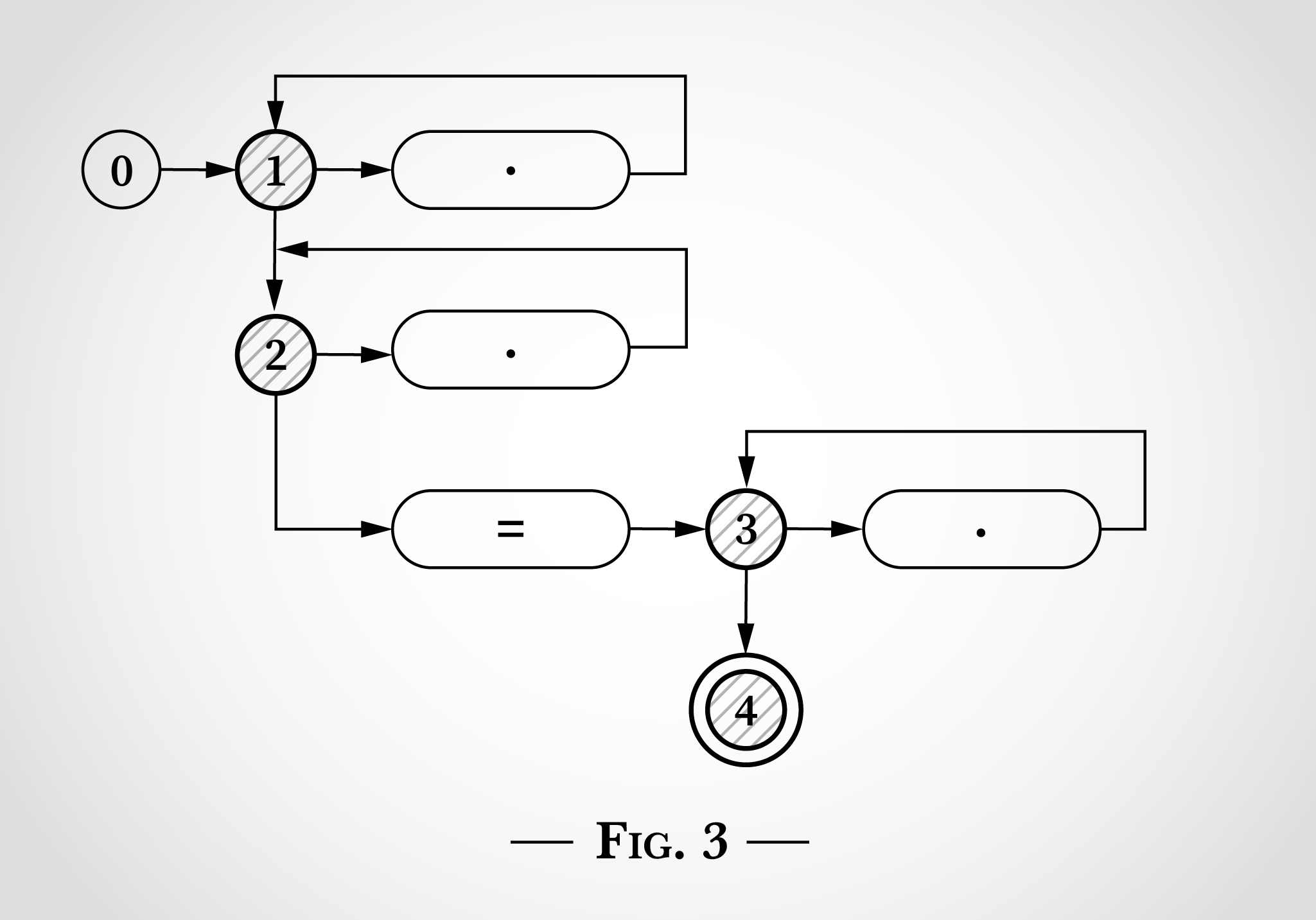
После чего алгоритм достигает последнего x в x=x.
На этом этапе каждый символ строки x=x уже сопоставлен и, потому как состояние 4 достигнуто, строка считается соответствующей регулярному выражению. Каждый символ был обработан единожды, поэтому алгоритм работает линейно, в зависимости от размера вводных данных. И нет необходимости в обратном поиске.
Ну, и наверное, довольно очевидно, что как только было достигнуто состояние 4 (после совпадения x=), регулярное выражение уже было подходящим и алгоритм мог завершаться без оценки последнего x.