
Периодически, с целью переезда в ЦРС собеседуюсь в разных крупных компаниях, в основном Питера и Москвы на должность DevOps. Обратил внимание, что во многих компаниях (во многих хороших компаниях, например в яндексе) задают два сходных вопроса:
Как часто бывает, я был уверен, что эту тему знаю хорошо, но как только начал объяснять — обозначились провалы в знаниях. Чтобы систематизировать свои знания, заполнить пробелы и больше не позориться, пишу эту статью, может еще кому пригодится.
Начну «снизу», т.е. с жесткого диска (флешки, SSD и прочие современные штуки отбросим, для примера рассмотрим любой 20 или 80 гиговый старый диск, т.к. там размер блока 512 байт).
Жесткий диск не умеет адресовать свое пространство побайтно, условно оно разбито на блоки. Нумерация блоков начинается с 0. (называется это LBA, подробности тут: ru.wikipedia.org/wiki/LBA)
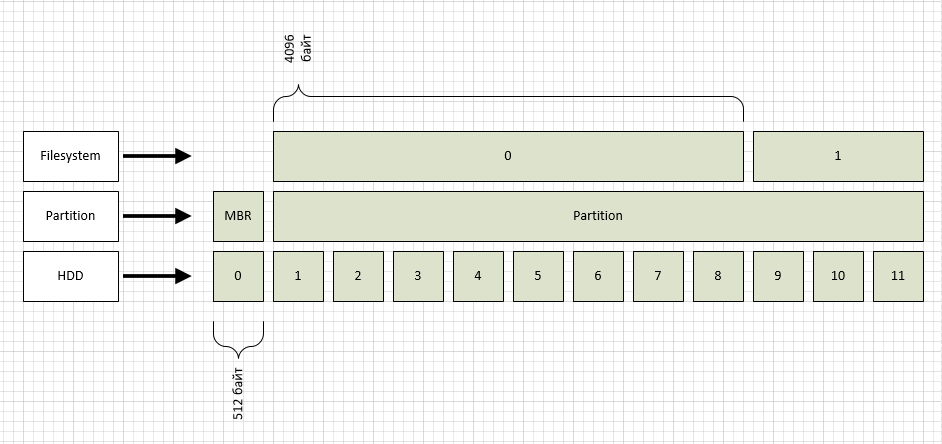
Как видно из рисунка, блоки LBA я обозначил как уровень HDD. К слову, посмотреть, какой размер блока у вашего диска можно так:
Уровнем выше размечен раздел, один на весь диск (опять же для простоты). Чаще всего используют разметку разделов двух типов: msdos и gpt. Соответственно msdos — старый формат, поддерживающий диски до 2Tb, gpt — новый формат, способный адресовать до 1 зеттабайта 512 байтных блоков. В нашем случае имеем раздел типа msdos, как видно из рисунка, раздел при этом начинается с блока №1, нулевой же используется для MBR.
В первом разделе я создал файловую систему ext2, по умолчанию размер блока у нее 4096 байт, что также отражено на рисунке. Посмотреть размер блока файловой системы можно так:
Нужный нам параметр — «Block size».
Теперь самое интересное, как прочитать файл /home/serp/testfile? Файл состоит из одного или нескольких блоков файловой системы, в которых хранятся его данные. Зная имя файла, как его найти? Какие блоки читать?
Вот тут нам и пригождаются inode. В файловой системе ext2fs есть «таблица», в которой содержится информация по всем inode. Количество inode в случае с ext2fs задается при создании файловой системы. Нужные цифры смотрим в параметре «Inode count» вывода tune2fs, т.е. имеем 65536 штук. В inode содержится нужная нам информация: список блоков файловой системы для искомого файла. Как найти номер inode для указанного файла?
Соответствие имени и номера inode содержится в директории, а директория в ext2fs — это файл особого типа, т.е. тоже имеет свой номер inode. Чтоб разорвать этот порочный круг, для корневой директории назначили «фиксированный» номер inode «2». Смотрим содержимое inode за номером 2:
Как видно, нужная нам директория содержится в блоке с номером 579. В ней мы найдем номер нода для папки home, и так далее по цепочке, пока в директории serp не увидим номер нода для запрошенного файла. Если вдруг кому то захочется проверить, верный ли номер, и есть ли там нужная инфа, это не сложно. Делаем:
В выводе можно прочитать имена файлов в директории.
Вот я и подошел к главному вопросу: «по каким причинам может возникнуть ошибка записи»?
Естественно так случится, если не останется свободных блоков файловой системы. Что можно в этом случае сделать? Кроме очевидного «удалить что-нибудь ненужное», следует помнить, что в файловых системах ext2,3 и 4 есть такая штука, как «Reserved block count». Если посмотреть в листинге выше, то у нас таких блоков «13094». Это блоки доступные для записи только пользователю root. но если нужно оперативно решить вопрос, как временное решение можно сделать их доступными для всех, в результате чего появится немного свободного места:
Т.е. по умолчанию, у вас не доступно для записи 5% дискового пространства, и учитывая объемы современных дисков, это могут быть сотни гигабайт.
Что еще может быть? Еще возможна ситуация, когда свободные блоки у есть, а ноды кончились. Такое обычно случается, если у вас в файловой системе куча файлов размером меньше размера блока файловой системы. Учитывая, что на 1 файл или директорию тратится 1 inode, а всего их имеем (для данной файловой системы) 65536 — ситуация более чем реальная. Наглядно это можно увидеть из вывода команды df:
Как хорошо заметно на разделе /var/www, количество свободных блоков файловой системы, и количество свободных нодов сильно различается.
На случай если кончились inode, заклинаний не подскажу, т.к. их нет (если не прав, дайте знать). Так что для разделов в которых плодятся мелкие файлы следует грамотно выбирать файловую систему. Так например в btrfs inode не могут закончиться, т.к. динамически создаются новые при необходимости.
- что такое inode;
- по каким причинам можно получить ошибку записи на диск (или например: почему может закончиться место на диске, суть одна).
Как часто бывает, я был уверен, что эту тему знаю хорошо, но как только начал объяснять — обозначились провалы в знаниях. Чтобы систематизировать свои знания, заполнить пробелы и больше не позориться, пишу эту статью, может еще кому пригодится.
Начну «снизу», т.е. с жесткого диска (флешки, SSD и прочие современные штуки отбросим, для примера рассмотрим любой 20 или 80 гиговый старый диск, т.к. там размер блока 512 байт).
Жесткий диск не умеет адресовать свое пространство побайтно, условно оно разбито на блоки. Нумерация блоков начинается с 0. (называется это LBA, подробности тут: ru.wikipedia.org/wiki/LBA)
Как видно из рисунка, блоки LBA я обозначил как уровень HDD. К слову, посмотреть, какой размер блока у вашего диска можно так:
root@ubuntu:/home/serp# blockdev --getpbsz /dev/sdb
512Уровнем выше размечен раздел, один на весь диск (опять же для простоты). Чаще всего используют разметку разделов двух типов: msdos и gpt. Соответственно msdos — старый формат, поддерживающий диски до 2Tb, gpt — новый формат, способный адресовать до 1 зеттабайта 512 байтных блоков. В нашем случае имеем раздел типа msdos, как видно из рисунка, раздел при этом начинается с блока №1, нулевой же используется для MBR.
В первом разделе я создал файловую систему ext2, по умолчанию размер блока у нее 4096 байт, что также отражено на рисунке. Посмотреть размер блока файловой системы можно так:
root@ubuntu:/home/serp# tune2fs -l /dev/sdb1
tune2fs 1.42.9 (4-Feb-2014)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: a600bf40-f660-41f6-a3e6-96c303995479
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: ext_attr resize_inode dir_index filetype sparse_super large_file
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 65536
Block count: 261888
Reserved block count: 13094
Free blocks: 257445
Free inodes: 65525
First block: 0
Block size: 4096
Fragment size: 4096
Reserved GDT blocks: 63
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
Filesystem created: Fri Aug 2 15:02:13 2019
Last mount time: n/a
Last write time: Fri Aug 2 15:02:14 2019
Mount count: 0
Maximum mount count: -1
Last checked: Fri Aug 2 15:02:13 2019
Check interval: 0 (<none>)
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Default directory hash: half_md4
Directory Hash Seed: c0155456-ad7d-421f-afd1-c898746ccd76Нужный нам параметр — «Block size».
Теперь самое интересное, как прочитать файл /home/serp/testfile? Файл состоит из одного или нескольких блоков файловой системы, в которых хранятся его данные. Зная имя файла, как его найти? Какие блоки читать?
Вот тут нам и пригождаются inode. В файловой системе ext2fs есть «таблица», в которой содержится информация по всем inode. Количество inode в случае с ext2fs задается при создании файловой системы. Нужные цифры смотрим в параметре «Inode count» вывода tune2fs, т.е. имеем 65536 штук. В inode содержится нужная нам информация: список блоков файловой системы для искомого файла. Как найти номер inode для указанного файла?
Соответствие имени и номера inode содержится в директории, а директория в ext2fs — это файл особого типа, т.е. тоже имеет свой номер inode. Чтоб разорвать этот порочный круг, для корневой директории назначили «фиксированный» номер inode «2». Смотрим содержимое inode за номером 2:
root@ubuntu:/# debugfs /dev/sdb1
debugfs 1.42.9 (4-Feb-2014)
debugfs: stat <2>
Inode: 2 Type: directory Mode: 0755 Flags: 0x0
Generation: 0 Version: 0x00000000:00000002
User: 0 Group: 0 Size: 4096
File ACL: 0 Directory ACL: 0
Links: 3 Blockcount: 8
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x5d43cb51:16b61bcc -- Fri Aug 2 16:34:09 2019
atime: 0x5d43c247:b704301c -- Fri Aug 2 15:55:35 2019
mtime: 0x5d43cb51:16b61bcc -- Fri Aug 2 16:34:09 2019
crtime: 0x5d43b5c6:00000000 -- Fri Aug 2 15:02:14 2019
Size of extra inode fields: 28
BLOCKS:
(0):579
TOTAL: 1Как видно, нужная нам директория содержится в блоке с номером 579. В ней мы найдем номер нода для папки home, и так далее по цепочке, пока в директории serp не увидим номер нода для запрошенного файла. Если вдруг кому то захочется проверить, верный ли номер, и есть ли там нужная инфа, это не сложно. Делаем:
root@ubuntu:/# dd if=/dev/sdb1 of=/home/serp/dd_image bs=4096 count=1 skip=579
1+0 records in
1+0 records out
4096 bytes (4,1 kB) copied, 0,000184088 s, 22,3 MB/s
root@ubuntu:/# hexdump -c /home/serp/dd_imageВ выводе можно прочитать имена файлов в директории.
Вот я и подошел к главному вопросу: «по каким причинам может возникнуть ошибка записи»?
Естественно так случится, если не останется свободных блоков файловой системы. Что можно в этом случае сделать? Кроме очевидного «удалить что-нибудь ненужное», следует помнить, что в файловых системах ext2,3 и 4 есть такая штука, как «Reserved block count». Если посмотреть в листинге выше, то у нас таких блоков «13094». Это блоки доступные для записи только пользователю root. но если нужно оперативно решить вопрос, как временное решение можно сделать их доступными для всех, в результате чего появится немного свободного места:
root@ubuntu:/mnt# tune2fs -m 0 /dev/sdb1
tune2fs 1.42.9 (4-Feb-2014)
Setting reserved blocks percentage to 0% (0 blocks)Т.е. по умолчанию, у вас не доступно для записи 5% дискового пространства, и учитывая объемы современных дисков, это могут быть сотни гигабайт.
Что еще может быть? Еще возможна ситуация, когда свободные блоки у есть, а ноды кончились. Такое обычно случается, если у вас в файловой системе куча файлов размером меньше размера блока файловой системы. Учитывая, что на 1 файл или директорию тратится 1 inode, а всего их имеем (для данной файловой системы) 65536 — ситуация более чем реальная. Наглядно это можно увидеть из вывода команды df:
serp@ubuntu:~$ df -hi
Filesystem Inodes IUsed IFree IUse% Mounted on
udev 493K 480 492K 1% /dev
tmpfs 493K 425 493K 1% /run
/dev/xvda1 512K 240K 273K 47% /
none 493K 2 493K 1% /sys/fs/cgroup
none 493K 2 493K 1% /run/lock
none 493K 1 493K 1% /run/shm
none 493K 2 493K 1% /run/user
/dev/xvdc1 320K 4,1K 316K 2% /var
/dev/xvdb1 64K 195 64K 1% /home
/dev/xvdh1 4,0M 3,1M 940K 78% /var/www
serp@ubuntu:~$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 2,0G 4,0K 2,0G 1% /dev
tmpfs 395M 620K 394M 1% /run
/dev/xvda1 7,8G 2,9G 4,6G 39% /
none 4,0K 0 4,0K 0% /sys/fs/cgroup
none 5,0M 0 5,0M 0% /run/lock
none 2,0G 0 2,0G 0% /run/shm
none 100M 0 100M 0% /run/user
/dev/xvdc1 4,8G 2,6G 2,0G 57% /var
/dev/xvdb1 990M 4,0M 919M 1% /home
/dev/xvdh1 63G 35G 25G 59% /var/wwwКак хорошо заметно на разделе /var/www, количество свободных блоков файловой системы, и количество свободных нодов сильно различается.
На случай если кончились inode, заклинаний не подскажу, т.к. их нет (если не прав, дайте знать). Так что для разделов в которых плодятся мелкие файлы следует грамотно выбирать файловую систему. Так например в btrfs inode не могут закончиться, т.к. динамически создаются новые при необходимости.
Комментарии (37)

Lando
08.08.2019 14:19Можно добавить что раздел у вас на картинке начинается с сектора 1 что очень плохо. Потому что современные диски имеют физический размер серктора в 4K. А чтение по LBA не кратным физическому блоку даст пенальти по производительности. Соответственно если границы блоков файловой системы не попадут на границы физических секторов диска будет просадка производительности. Узнать размер физического сектора на диске можно с помощю «hdparm -I /dev/sda». Ну или создать раздел по смещению в 1MB от начала диска что б наверняка.
lega
08.08.2019 15:32Как видно, нужная нам директория содержится в блоке с номером 579. В ней мы найдем номер нода для папки home,
А почему сделано через ноды?, когда можно было бы хранить ссылку на нужный блок, т.е. вся инфа о содержимом папки была бы в блоке этой папки, и подобной проблемы бы не возникло.
serp2002 Автор
09.08.2019 01:44+1Как минимум, тогда невозможно было бы реализовать хардлинки. Думаю есть и другие причины.
sub31
Все чаще диски в разметке GPT. Стоит изучить тему.
Из ситуации с закончившимися inode ситуация почти безвыходная, но можно попробовать финты с уменьшением размера файловой системы и созданием нового диска с новой файловой системой. Благо дерево очень гибкое. Как временное решение — файл с временной файловой системой и устройство /dev/loop{n}.
alekciy
Ещё лучше заиспользовать XFS.
edo1h
периодически ловлю подвисания на большом (8x10Tb) разделе xfs при активном обращении + проверка массива md.
bugzilla.kernel.org/show_bug.cgi?id=201331
не так давно поймал потерю данных после такого фриза + ребут, было очень больно.
alekciy
Альтернативы? ZFS?
isden
> ZFS
Да, вполне. Отлично работает уже больше полугода в продакшене. 2x4Tb, зеркалирование средствами самого ZFS (миграция живого сервака md+ext4 -> zfs без физического доступа и вменяемой консоли была очень интересным развлечением). Уже подумываю о переезде этого сервера на FreeBSD :)
al_ace
Причин, конечно может быть много, но в тему статьи подходит такая: подвисание происходит из-за перестроения какого-нибудь дерева:
— каталог с большим числом файлов в XFS — это дерево
— свободное место отслеживается с помощью 2х деревьев: одно упорядоченно по смещению, а второе по размеру свободных (или занятых, не помню точно) областей.
Berkof
Ловили подвисания на очень активно используемом массиве в пару терабайт на XFS, лечилось дефрагментацией и настройкой предвыделения места (мы открывали кучу файлов и дописывали в них рандомно — получали больше миллиона сегментов в одном файле и зависания XFS при попытке работы с таким большим деревом фрагментов в ядре)
gotch
Да, нельзя ли ответить на собеседовании «Если у вас XFS или NTFS, значит просто кончилось место»?
dbax
Отвечать обычно нужно то что хотят услышать.
В данном случае хотят услышать про иноды…
gotch
Да тут я сам уже напутал резерв блоков для root с inode, так что правильно всё на собеседовании спрашивают.
Впервые столкнулся с нехваткой inode когда ставил Linux на 4Gb SSD. Удивился, что их число зависит от размера раздела.
rionnagel
При этом стоит учитывать, что xfs разделы нельзя уменьшить.
eaa
Мы на файловом хранилище решали очень просто: много мелких файлов клали в zip-архив. Кроме inodes выиграли «случайно» еще несколько сотен гигов места (при упаковке «без сжатия»).
Да, поскольку файлы раздавал nginx, то пришлось к нему прикрутить модуль распаковки zip на лету.
edo1h
можно про модуль подробнее?
eaa
Спонтанно родилась статья на хабре, описал все там
habr.com/ru/company/srg/blog/462967
Sheti
zip по своей структуре тоже довольно сложно устроен. Интересно, есть ли варианты менее ресурсоёмкие при условии, что сжатие не нужно?
felix0id
tar же?
Sheti
боюсь tar тут тоже далеко не самый лучший вариант. Поиск нужного файла в нём это тупо перебор блоков, причем последовательный. Да и структура tar файла подразумевает работу блоками по 512 байт. И если у нас файлы меньше, то будет куча хвостов.
VioletGiraffe
tarball?
a1ien_n3t
7zip есть store only режим
4144
если вы всегда пересоздаете zip архивы и не делаете append, то там ничего сложного нет.
линейный список имен файлов + различные атрибуты
serp2002 Автор
zip? В Linux? А как с правами доступа и атрибутами файлов? Они же в zip не сохраняются. И почему не loop device?
Daemon_Hell
Для большинства случаев будет достаточно что права можно назначить на весь архив.
А какая фс натянута на луп девайс?
Rullix
Внутри zip структура файлов хранится в этом zip? Там свой маленький inode?
eaa
структура хранится, в этом его плюс по сравнению с tar
Rullix
tar хранит свою структуру архива снаружи, во внешней файловой системе? Неожиданно.
eaa
tar не хранит каталог файлов в каком-то отдельном выделенном месте, у него вообще нет этой структуры, в tar есть информация об одном файле, потом сам файл, потом опять информация, потом файл, т.е. эта информация размазана по всему архивному файлу, и ее нельзя получить разово. В этом и есть проблема.
Rullix
Понятно. Поэтому zip может легко использоваться как виртуальная папка. А tar просто простейший архив, составленный из файлов как поезд из вагонов.
al_ace
В конце zip файла есть что-то вроде «содержания» архива — список структур с именем, размером и датами для каждого сжатого файла.
serp2002 Автор
У нас все сервера виртуализированные, поэтому проще создать новый диск с новой файловой системой и перенести данные.