
Хотя нейронные сети стали использоваться для синтеза речи не так давно (например), они уже успели обогнать классические подходы и с каждым годам испытывают на себе всё новые и новый задачи.
Например, пару месяцев назад появилась реализация синтеза речи с голосовым клонированием Real-Time-Voice-Cloning. Давайте попробуем разобраться из чего она состоит и реализуем свою многоязычную (русско-английскую) фонемную модель.
Строение
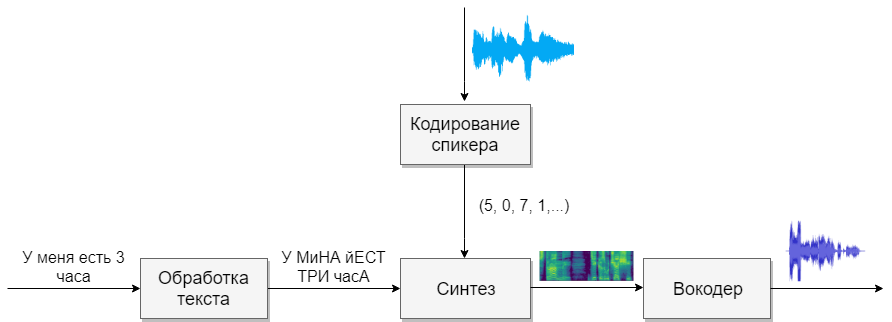
Наша модель будет состоять из четырёх нейронных сетей. Первая будет преобразовывать текст в фонемы (g2p), вторая — преобразовывать речь, которую мы хотим клонировать, в вектор признаков (чисел). Третья — будет на основе выходов первых двух синтезировать Mel спектрограммы. И, наконец, четвертая будет из спектрограмм получать звук.
Наборы данных
Для этой модели нужно много речи. Ниже базы, которые в этом помогут.
| Имя | Язык | Ссылка | Комментарии | Моя ссылка | Комментарии |
|---|---|---|---|---|---|
| Словарь фонем | En, Ru | En,Ru | link | Совместил русский и английский фонемный словарь | |
| LibriSpeech | En | link | 300 голосов, 360ч чистой речи | ||
| VoxCeleb | En | link | 7000 голосов, много часов плохого звука | ||
| M-AILABS | Ru | link | 3 голоса, 46ч чистой речи | ||
| open_tts, open_stt | Ru | open_tts, open_stt | много голосов, много часов плохого звука | link | Почистил 4 часа речи одного спикера. Поправил аннотацию, разбил на отрезки до 7 секунд |
| Voxforge+audiobook | Ru | link | много голосов, 25ч разного качества | link | Выбрал хорошие файлы. Разбил на отрезки. Добавил аудиокниг из интернета. Получилось 200 спикеров по паре минут на каждого |
| RUSLAN | Ru | link | Один голос, 40ч чистой речи | link | Перекодировал в 16кГц |
| Mozilla | Ru | link | 50 голосов, 30ч нормального качества | link | Перекодировал в 16кГц, Раскидал разных пользователей по папкам |
| Russian Single | Ru | link | Один голос, 9ч чистой речи | link |
Обработка текста
Первой задачей будет обработка текста. Представим текст в том виде, в котором он будет в дальнейшем озвучен. Числа представим прописью, а сокращения раскроем. Подробнее можно почитать в статье посвященной синтезу. Это тяжелая задача, поэтому предположим, что к нам поступает уже обработанный текст (в базах выше он обработан).
Следующим вопросом, которым следуют задаться, это использовать ли графемную, или фонемную запись. Для одноголосного и одноязычного голоса подойдет и буквенная модель. Если хотите работать с многоголосой многоязычной моделью, то советую использовать транскрипцию (Гугл тоже).
G2P
Для русского языка существует реализация под названием russian_g2p. Она построена на правилах русского языка и хорошо справляется с задачей, но имеет минусы. Не для всех слов расставляет ударения, а также не подходит для многоязычной модели. Поэтому возьмём созданный ей словарь, добавим словарь для английского языка и скормим нейронной сети (например этим 1, 2)
Прежде чем обучать сеть, стоит подумать, какие звуки из разных языков звучат похоже, и можно им выделить один символ, а для каких нельзя. Чем больше будет звуков, тем сложнее модели учиться, а если их будет слишком мало, то у модели появиться акцент. Не забудьте ударным гласным выделять отдельные символы. Для английского языка вторичное ударение играет малую роль, и я бы его не выделял.
Кодирование спикеров
Сеть схожа с задачей идентификации пользователя по голосу. На выходе у разных пользователей получаются разные вектора с числами. Предлагаю использовать реализацию самого CorentinJ, которая основана на статье. Модель представляет собой трехслойный LSTM с 768 узлами, за которыми следует полносвязный слой из 256 нейронов, дающие вектор из 256 чисел.
Опыт показал, что сеть, обученная на английской речи, хорошо справляется и с русской. Это сильно упрощает жизнь, так как для обучения требуется очень много данных. Рекомендую взять уже обученную модель и дообучить на английской речи из VoxCeleb и LibriSpeech, а также всей русской речи, что найдёте. Для кодера не нужна текстовая аннотация фрагментов речи.
Тренировка
- Запустите
python encoder_preprocess.py <datasets_root>для обработки данных - Запустите "visdom" в отдельном терминале.
- Запустите
python encoder_train.py my_run <datasets_root>для тренировки кодировщика
Синтез
Перейдём к синтезу. Известные мне модели не получают звук напрямую из текста, так как, это сложно (слишком много данных). Сначала из текста получается звук в спектральной форме, а уже потом четвертая сеть будет переводить в привычный голос. Поэтому сначала поймём, как спектральное вид связанна с голосом. Проще разобраться в обратной задаче, как из звука получить спектрограмму.
Звук разбивается на отрезки длинной 25 мс с шагом 10 мс (по умолчанию в большинстве моделей). Далее с помощью преобразования Фурье для каждого кусочка вычисляется спектр (гармонические колебания, сумма которых даёт исходный сигнал) и представляется в виде графика, где вертикальная полоса — это спектр одного отрезка (по частоте), а по горизонтальной — последовательность отрезков (по времени). Этот график называется спектрограммой. Если же частоту закодировать нелинейно (нижние частоты качественнее, чем верхние), то изменится масштаб по вертикали (нужно для уменьшения данных) то такой график называют Mel спектрограммой. Так устроен человеческий слух, что небольшое отклонение на нижних частотах мы слышим лучше, чем на верхних, поэтому качество звука не пострадает
Существует несколько хороших реализаций синтеза спектрограмм, такие как Tacotron 2 и Deepvoice 3. У каждой из этих моделей есть свои реализации, например 1, 2, 3, 4. Будем использовать(как и CorentinJ) модель Tacotron от Rayhane-mamah.
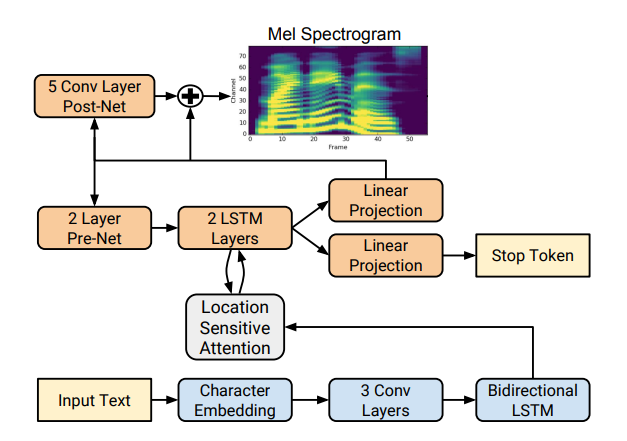
Tacotron основан на сети seq2seq с механизмом внимания. Ознакомитесь с подробностями в статье.
Тренировка
Не забудьте отредактировать utils/symbols.py, если будете синтезировать не только английскую речь, hparams.pу, а так же preprocess.py.
Для синтеза нужно много чистого, хорошо размеченного звука разных спикеров. Здесь чужой язык не поможет.
- Запустите
python synthesizer_preprocess_audio.py <datasets_root>для создания обработанного звука и спектрограмм - Запустите
python synthesizer_preprocess_embeds.py <datasets_root>для кодирования звука (получения признаков голоса) - Запустите
python synthesizer_train.py my_run <datasets_root>для тренировки синтезатора
Вокодер
Теперь осталось только преобразовать спектрограммы в звук. Для этого служит последняя сеть — вокодер. Возникает вопрос, если спектрограммы получаются из звука с помощью преобразования Фурье, нельзя ли с помощью обратного преобразования получить снова звук? Ответ и да, и нет. Гармонические колебания, из которых состоит исходный сигнал, содержат как амплитуду, так и фазу, а наши спектрограммы содержат информацию только об амплитуде (ради сокращения параметров и работаем со спекрограммами), поэтому если мы сделаем обратное преобразование Фурье, то получим плохой звук.
Для решения этой проблемы придумали быстрый алгоритм Гриффина-Лима. Он делает обратное преобразование Фурье спектрограммы, получая "плохой" звук. Далее делает прямое преобразования этого звука и получают спектр, в котором уже содержится немножко информации о фазе, причём амплитуда в процессе не меняется. Далее берётся еще раз обратное преобразование и получается уже более чистый звук. К сожалению, качество сгенерированной таким алгоритмом речи оставляет желать лучшего.
На его смену пришли нейронные вокодеры, такие как WaveNet, WaveRNN, WaveGlow и другие. CorentinJ использовал модель WaveRNN за авторством fatchord

Для предобработки данных используется два подхода. Либо получить спектрограммы из звука (с помощью преобразования Фурье), или из текста (с помощью модели синтеза). Google рекомендует второй подход.
Тренировка
- Запустите
python vocoder_preprocess.py <datasets_root>для синтеза спектрограмм - Запустите
python vocoder_train.py <datasets_root>для вокодера
Итого
Мы получили модель многоязычного синтеза речи, умеющей клонировать голос.
Запустите toolbox: python demo_toolbox.py -d <datasets_root>
Примеры можно послушать тут
Советы и выводы
- Нужно много данных (>1000 голосов, >1000 часов)
- Скорость работы сравнима с реальным временем только при синтезе минимум 4 предложений
- Для кодера используйте предобученную модель для английского языка, немножко дообучив. Она справляется хорошо
- Синтезатор, обученный на "чистых" данных, работает лучше, но хуже клонирует, чем тот, кто обучался на большем объёме, но грязных данных
- Модель хорошо работает только на данных, на которых училась
Можете синтезировать свой голос онлайн с помощью colab, или посмотреть мою реализацию на github и скачать мои веса.
Комментарии (5)

DarkTwin
03.09.2019 06:58Подскажите на какое решение смотреть если нужно голос в текст?
Если конкретнее то надо вычленять, по словарю, слова паразиты и мат.
Yandex.Kit и гугл не надо предлагать.Vlomme Автор
03.09.2019 09:01Я бы смотрел в сторону DeepSpeech 2, wav2letter++.
И может помочь iPavlov.
Но, возможно, есть что-то и лучше.
akreal
03.09.2019 19:08Можете попробовать ESPnet. Я недавно добавил модель для русского:
github.com/espnet/espnet/blob/master/egs/ru_open_stt/asr1/RESULTS.md
KonstantinSpb
Ждем когда появятся приложения преобразующие голос в текст, а потом текст в голос робота или какого-то другого человека, и привет товарищу майору и его системе распознавания голоса и поиска по голосовому отпечатку :)
Vlomme Автор
Если сносного качества можно достичь на слабой видеокарте и небольшом датасете, то боюсь представить возможности тех, у кого есть время и деньги. Причем если учить сеть только на русской речи, качество получается существенно выше.
Особенно забавляют новости про индетификацию пользователей в банках по голосу