

Совсем недавно компания Check Point презентовала новую масштабируемую платформу Maestro. Мы уже публиковали целую статью о том, что это такое и как оно работает. Если коротко — позволяет почти линейно увеличивать производительность шлюза безопасности путем объединения нескольких устройств и балансировки нагрузки между ними. Удивительно, но до сих пор сохраняется миф, что эта scalable платформа подходит только для больших датацентров или для гигантских сетей. Это совершенно не так.
Check Point Maestro разрабатывался сразу для нескольких категорий пользователей (мы рассмотрим их чуть позже), среди который есть и средний бизнес. В этом небольшом цикле статей я постараюсь отразить технические и экономические преимущества Check Point Maestro для организаций среднего размера (от 500 пользователей) и почему этот вариант может быть лучше классического кластера.
Целевая аудитория Check Point Maestro
Прежде всего давайте рассмотрим пользовательские сегменты, для которых был разработан Check Point Maestro. Их всего 4:
1. Компании, которым не хватало возможностей шасси. Check Point Maestro это не первая масштабируемая платформа Check Point. Мы уже писали, что ранее были такие модели как 64000 и 44000. У них хоть и была БОЛЬШАЯ производительность, но все же были компании, которым этого было МАЛО. Maestro устраняет этот недостаток, т.к. позволяет собирать до 31-го устройства в один высокопроизводительный кластер. При этом собирать кластер вы можете из топовых устройств (23900, 26000), тем самым добиваясь колоссальной пропускной способности.

На самом деле, в области шлюзов безопасности, Check Point пока единственные, кто реализует подобную возможность.
2. Компании, которые хотят иметь возможность выбирать “железо”. Один из недостатков старых scalable платформ — необходимость использовать строго определенные “модули-лезвия” (Check Point SGM). Новая же платформа Check Point Maestro позволяет использовать огромное кол-во разных устройств. Вы можете выбирать как модели из среднего сегмента (5600, 5800, 5900, 6500, 6800), так и из High End сегмента (15000 серия, 23000 серия, 26000 серия). Более того, вы можете их комбинировать, в зависимости от задач.
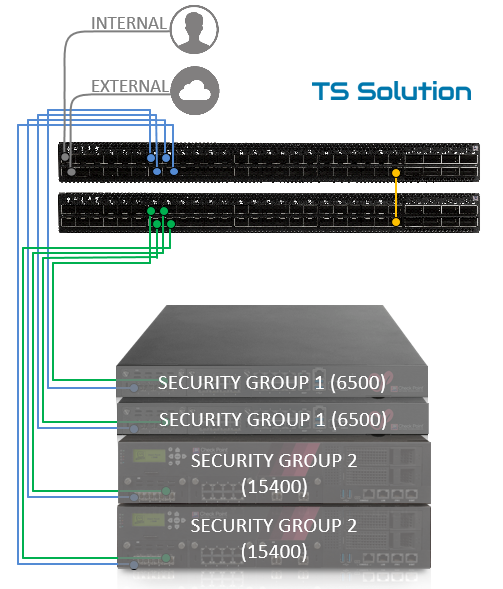
Это весьма удобно с точки зрения оптимального использования ресурсов. Вы можете докупать только нужную вам производительность, за счет выбора нужной модели.
3. Компании, для которых шасси это слишком много, но масштабируемость все равно нужна. Еще одним “недостатком” старых scalable платформ (64000, 44000) являлся высокий порог входа (с экономической точки зрения). Долгое время масштабируемые платформы были доступны только для крупного бизнеса с “хорошими” бюджетами на IT. С появлением Check Point Maestro все изменилось. Стоимость минимального бандла (оркестратор + два шлюза) сопоставима (а иногда и ниже) с классическим active/standby кластером. Т.е. порог входа существенно снизился. Компания при выборе решения может сразу заложить масштабируемую архитектуру, при этом не переплачивая за возможный последующий рост потребностей. Пользователей стало больше через год после внедрения Check Point Maestro? Просто добавляете один-два шлюза, без каких либо замен уже имеющихся. Не придется даже топологию менять. Просто подключаете новые шлюзы к оркестратору и применяете к ним настройки буквально в пару кликов.

4. Компании, которые хотят оптимально использовать уже существующие устройства. Думаю многим знакома процедура Trade-In. Когда производительности существующих устройств уже недостаточно и для удовлетворения текущих потребностей нужно обновить “железо”. Довольно затратная процедура. Плюс, весьма часто бывает ситуация, когда у заказчика есть несколько кластеров Check Point под разные задачи. Например кластер под защиту периметра, кластер под удаленный доступ (RA VPN), кластер под VSX и т.д. Причем у одного кластера может не хватать ресурсов, а у другого их с избытком. Check Maestro является отличной возможностью оптимизировать использование этих ресурсов, динамически распределяя между ними нагрузку.

Т.е. вы получаете следующие преимущества:
- Нет необходимости “выкидывать” имеющееся железо. Вы можете докупить один-два шлюза, либо…
- Настроить динамическую балансировку нагрузки между другими существующими шлюзами, для более оптимального использования ресурсов. Если резко возрастает нагрузка на шлюз периметра, то оркестратор сможем задействовать “скучающие” ресурсы шлюзов удаленного доступа и наоборот. Это помогает сглаживать сезонные (или временнЫе) пики нагрузки.
Как вы наверно поняли, последние два сегмента относятся как раз к бизнесу среднего размера, которые теперь тоже могут себе позволить использование масштабируемых платформ безопасности. Однако, может возникнуть резонный вопрос: “Чем Check Point Maestro лучше обычного кластера?” Постараемся ответить на этот вопрос.
Классический кластер vs Check Point Maestro
Если говорить о классическом кластере Check Point то поддерживается два режима работы: High Availability (т.е. Active/Standby) и Load Sharing (т.е. Active/Active). Вкратце опишем их смысл работы, а также их плюсы и минусы.
High Availability (Active/Standby)
Как следует из названия, в этом режиме работы одна нода пропускает через себя весь трафик, а вторая в режиме ожидания и подхватывает трафик если активная нода начинает испытывать какие-либо проблемы.
Плюсы:
- Наиболее стабильный режим;
- Поддерживается проприетарный механизм SecureXL для ускорения обработки трафика;
- В случае выхода из строя активной ноды, вторая гарантированно сможет “переварить” весь трафик (потому что она точно такая же).
Минусы:
По сути только один минус — одна нода полностью простаивает. В свою очередь из-за этого мы вынуждены покупать более мощное “железо”, чтобы оно могло справляться с трафиком в одиночку.

Безусловно, HA режим более надежен, чем Load Sharing, но оптимизация ресурсов оставляет желать лучшего.
Load Sharing (Active/Active)
В данном режиме все ноды кластера обрабатывают трафик. Объединить в такой кластер можно до 8 устройств (больше 4-х не рекомендуется).
Плюсы:
- Можно распределить нагрузку между нодами, за счет чего требуются менее производительные устройства;
- Возможность плавного масштабирования (добавление в кластер до 8 нод).
Минусы:
- Как ни странно, но плюсы тут же вываливаются в минусы. Режим Load Sharing любят использовать даже когда в компании всего две ноды. Желая сэкономить, покупаются устройства, каждое из которых загружается на 40-50%. И вроде все хорошо. Но если падает одна нода, мы получаем ситуацию, когда вся нагрузка переходит на оставшуюся, которая просто не справляется. В итоге отказоустойчивость в такой схеме отсутствует как таковая.

- Прибавьте к этому кучу ограничений Load Sharing-а (sk101539). А самое главное ограничение — не поддерживается SecureXL, механизм, который существенно ускоряет обработку трафика;
- Что касается масштабирования путем добавления новых нод в кластер, то к сожалению Load Sharing здесь далеко не идеален. Если в кластер добавляется больше 4-х устройств, то производительность начинает драматически падать.
Учитывая первые два минуса, для реализации отказоустойчивости при использовании двух нод, мы вынуждены также приобретать более производительное железо, чтобы оно могло “переварить” трафик в критической ситуации. По итогу, никакой экономической выгоды мы не имеем, но получаем большое кол-во ограничений. Более того, стоит отметить, что начиная с версии R80.20 режим Load Sharing не поддерживается. Это ограничивает пользователей в необходимых обновлениях. Будет ли поддерживаться Load Sharing в более новых релизах пока неизвестно.
Check Point Maestro как альтернатива
С точки зрения кластера, Check Point Maestro взял главные плюсы High Availability и Load Sharing режимов:
- Шлюзы подключенные к оркестратору могут использовать SecureXL, что обеспечивает максимальную скорость обработки трафика. Отсутствуют и другие ограничения свойственные Load Sharing;
- Трафик распределяется между шлюзами в одной Security Group (логический шлюз состоящий из нескольких физических). Благодаря этому можно заложить менее производительные устройства, ведь у нас больше нет простаивающих шлюзов, как в режиме High Availability. При этом наращивать мощность можно практически линейно, без таких серьезных потерь как в Load Sharing режиме (подробнее чуть позже).
Все это здорово, но давайте рассмотрим два конкретных примера.
Пример №1
Пусть компания Х собирается установить на периметре сети кластер шлюзов. Они уже ознакомились со всеми ограничениями Load Sharing (которые для них неприемлемы) и рассматривают исключительно High Availability режим. После сайзинга выясняется, что им подходит шлюз 6800, который не должен быть загружен более чем на 50% (чтобы был хоть какой-то запас по производительности). Поскольку это будет кластер, то нужно покупать и второе устройство, которое будет в режиме standby просто “коптить” воздух. Весьма дорогая «коптилка» выходит.
Но есть альтернатива. Взять бандл из оркестратора и трех шлюзов 6500. В этом случае трафик будет распределяться между всеми тремя устройствами. Если вы посмотрите характеристики двух моделей, то увидите, что три шлюза 6500 мощнее, чем один 6800.

Таким образом компания Х при выборе Check Point Maestro получает следующие преимущества:
- Компания сразу закладывает масштабируемую платформу. Последующее увеличение производительности будет сводиться к простому добавлению еще одной “железки” 6500. Что может быть проще?
- Решение по прежнему является отказоустойчивым, т.к. при выходе из строя одной ноды, оставшиеся две смогут справиться с нагрузкой.
- Не менее важное и удивительное преимущество — это дешевле! К сожалению я не могу выкладывать цены в открытый доступ, но если интересно, можете обратиться к нам за расчетами
Пример №2
Пусть компания Y уже имеет HA кластер из моделей 6500. Активная нода загружена на 85%, что при пиковых нагрузках приводит к потерям в продуктивном трафике. Логическим решением проблемы видится обновление железа. Следующая модель — 6800. Т.е. компании нужно будет сдать шлюзы по программе Trade-In и приобрести два новых (более дорогих) устройства.
Но есть и альтернативный вариант. Приобрести оркестратор и еще одну точно такую же ноду (6500). Собрать кластер из трех устройств и “размазать” эти 85% нагрузки уже по трем шлюзам. В итоге вы получите огромный запас по производительности (три устройства в среднем будут загружены всего на 30%). Даже если одна нода из трех “умрет”, то оставшиеся две все равно справятся с трафиком со средней загрузкой в 45%. При этом для пиковых нагрузок кластер из трех активных шлюзов 6500 будет мощнее, чем один шлюз 6800, который находится в HA кластере (т.е. active/standby). Кроме того, если через год-два у компании Y опять возрастут потребности, то все что им нужно будет сделать — добавить еще одну/две ноды 6500. Думаю экономическая выгода здесь очевидна.
Заключение
Да, Check Point Maestro это не решение для SMB. Но даже средний бизнес может уже задуматься об этой платформе и хотя бы попробовать рассчитать экономическую эффективность. Вы будете удивлены, когда обнаружите, что масштабируемые платформы могут оказаться выгоднее классического кластера. При этом существуют преимущества не только экономические, но и технические. Однако о них мы поговорим уже в следующей статье, где кроме технических «фишек» я постараюсь показать несколько типовых кейсов (топология, сценарии).
Вы также можете подписаться на наши паблики (Telegram, Facebook, VK, TS Solution Blog), где можно следить за появлением новых материалов по Check Point и другим security продуктам.