

Это миф, достаточно распространённый в сфере серверного железа. На практике же гиперконвергентные решения (когда всё в одном) нужны много для чего. Исторически сложилось, что первые архитектуры были разработаны Amazon и Google под свои сервисы. Тогда идея была в том, чтобы сделать вычислительную ферму из одинаковых узлов, у каждого из которых есть собственные диски. Всё это объединялось неким системообразующим софтом (гипервизором) и разбивалось уже на виртуальные машины. Главная задача — минимум усилий на обслуживание одного узла и минимум проблем при масштабировании: просто докупили ещё тысячу-другую таких же серверов и подключили рядом. На практике это единичные случаи, и гораздо чаще речь про меньшее число узлов и немного другую архитектуру.
Но плюс остаётся тем же — невероятная простота масштабирования и управления. Минус — разные задачи по-разному потребляют ресурсы, и где-то локальных дисков будет много, где-то мало оперативки и так далее, то есть при разном типе задач будет падать утилизация ресурсов.
Получалось, что вы платите на 10–15% больше за удобство настройки. Это и вызвало миф из заголовка. Мы долго искали, где же будет применяться технология оптимально, и нашли. Дело в том, что у Циски не было своих СХД, но они хотели полный серверный рынок. И они сделали Cisco Hyperflex — решение с локальными хранилищами на нодах.
А из этого внезапно получилось очень хорошее решение для резервных дата-центров (Disaster Recovery). Почему и как — сейчас расскажу. И покажу тесты кластера.
Где нужно
Гиперконвергенция — это:
- Перенос дисков в вычислительные узлы.
- Полноценная интеграция подсистемы хранения данных с подсистемой виртуализации.
- Перенос/интеграция с сетевой подсистемой.
Такая связка позволяет реализовывать многие фичи СХД на уровне виртуализации и всё из одного окна управления.
В нашей компании очень востребованы проекты по проектированию резервных ЦОДов, и часто выбирается именно гиперконвергентное решение из-за кучи опций по репликации (вплоть до метрокластера) из коробки.
В случае резервных ЦОДов обычно речь идёт про удалённый объект на площадке на другом краю города или вообще в другом городе. Он позволяет восстановить критичные системы в случае частичного или полного отказа основного ЦОДа. Туда постоянно реплицируются данные с прода, и эта репликация может быть на уровне приложения или же на уровне блочного устройства (СХД).
Поэтому сейчас я расскажу про устройство системы и тесты, а потом — про пару сценариев реального применения с данными по экономии.
Тесты
Наш экземпляр состоит из четырёх серверов, в каждом из которых — 10 SSD-дисков на 960 ГБ. Есть выделенный диск для кэширования операций записи и хранения сервисной виртуальной машины. Само решение — четвёртая версия. Первая откровенно сырая (судя по отзывам), вторая сыровата, третья уже достаточно стабильная, а эту можно назвать релизом после окончания бета-тестирования на широкой публике. За время тестирования проблем я не увидел, всё работает как часы.
Изначально платформа могла работать только с гипервизором VMware ESXi и поддерживала небольшое количество нод. Также процесс развёртывания далеко не всегда заканчивался успешно, приходилось перезапускать некоторые шаги, были проблемы с обновлением со старых версий, данные в GUI отображались не всегда корректно (хотя я и сейчас не в восторге от отображения графиков производительности), иногда возникали проблемы на стыке с виртуализацией.
Сейчас все детские болячки исправлены, HyperFlex умеет и ESXi, и Hyper-V, плюс к этому возможно:
- Создание растянутого кластера.
- Создание кластера для офисов без использования Fabric Interconnect, от двух до четырёх нод (покупаем только серверы).
- Возможность работы с внешними СХД.
- Поддержка контейнеров и Kubernetes.
- Создание зон доступности.
- Интеграция с VMware SRM, если встроенный функционал не устраивает.
Архитектура несильно отличается от решений основных конкурентов, велосипед создавать не стали. Работает это всё на платформе виртуализации VMware или Hyper-V. Аппаратно размещается на серверах собственной разработки Cisco UCS. Есть те, кто ненавидит платформу за относительную сложность первоначальной настройки, множество кнопочек, нетривиальную систему шаблонов и зависимостей, но есть и те, кто познал дзен, проникся идеей и больше не хочет работать с другими серверами.
Мы рассмотрим именно решение для VMware, т. к. решение изначально создавалось под него и имеет больший функционал, Hyper-V допилили по ходу дела, чтобы не отставать от конкурентов и соответствовать ожиданиям рынка.
Имеется кластер из серверов, набитых дисками. Есть диски под хранение данных (SSD или HDD — на ваш вкус и потребности), есть один SSD-диск для кэширования. При записи данных на датастор происходит сохранение данных на кэширующем слое (выделенный SSD-диск и RAM сервисной ВМ). Параллельно блок данных отправляется на ноды в кластере (количество нод зависит от фактора репликации кластера). После подтверждения от всех нод об успешной записи подтверждение записи отправляется в гипервизор и далее — в ВМ. Записанные данные в фоновом режиме дедуплицируются, сжимаются и записываются на диски хранения. При этом на диски хранения всегда пишется большой блок и последовательно, что снижает нагрузку на диски хранения.
Дедупликация и компрессия включены постоянно, и отключить их нельзя. Чтение данных происходит напрямую с дисков хранения или из кэша RAM. Если используется гибридная конфигурация, то чтение также кэшируется на SSD-диске.
Данные не привязываются к текущему расположению виртуальной машины и распределяются между нодами равномерно. Такой подход позволяет одинаково нагрузить все диски и сетевые интерфейсы. Напрашивается очевидный минус: мы не можем максимально уменьшить задержку чтения, т. к. нет гарантии наличия данных локально. Но я считаю, что это незначительная жертва по сравнению с полученными плюсами. Тем более задержки в сети достигли таких значений, что практически не влияют на общий результат.
За всю логику работы дисковой подсистемы отвечает специальная сервисная ВМ Cisco HyperFlex Data Platform controller, которая создаётся на каждой ноде хранения. В нашей конфигурации сервисной ВМ был выделено восемь vCPU и 72 ГБ RAM, что не так уж и мало. Напомню, что сам хост имеет в наличии 28 физических ядер и 512 ГБ RAM.
Сервисная ВМ имеет доступ к физическим дискам напрямую с помощью проброса SAS-контроллера в ВМ. Общение с гипервизором происходит через специальный модуль IOVisor, который перехватывает операции ввода-вывода, и с помощью агента, позволяющего передавать команды в API гипервизора. Агент отвечает за работу с HyperFlex-снепшотами и клонами.
В гипервизор дисковые ресурсы монтируются как NFS- или SMB-шара (зависит от типа гипервизора, угадайте, какой где). А под капотом это распределённая файловая система, которая позволяет добавить фичи взрослых полноценных СХД: тонкое выделение томов, сжатие и дедупликация, снепшоты по технологии Redirect-on-Write, синхронная/асинхронная репликация.
Сервисная ВМ предоставляет доступ к WEB-интерфейсу управления подсистемы HyperFlex. Есть интеграция с vCenter, и большая часть повседневных задач может быть выполнена из него, но датасторы, например, удобнее нарезать из отдельной вебки, если вы уже перешли на быстрый HTML5-интерфейс, или же использовать полноценный Flash-клиент с полной интеграцией. В сервисной вебке можно посмотреть производительность и подробный статус системы.
Существует и другой вид нод в кластере — вычислительные ноды. Это могут быть рэковые или блейд-серверы без встроенных дисков. На этих серверах можно запускать ВМ, данные которых хранятся на серверах с дисками. С точки зрения доступа к данным разницы между типами нод нет, ведь архитектура предполагает абстрагирование от физического расположения данных. Максимальное соотношение вычислительных нод и нод хранения — 2:1.
Использование вычислительных нод увеличивает гибкость при масштабировании ресурсов кластера: нам не обязательно докупать ноды с дисками, если у нас потребность только в CPU/RAM. К тому же мы можем добавить блейд-корзину и получить экономию на размещении серверов в стойке.
Как итог у нас есть гиперконвергентная платформа со следующими фичами:
- До 64 нод в кластере (до 32 нод хранения).
- Минимальное количество нод в кластере — три (две — для Edge-кластера).
- Механизм избыточности данных: зеркалирование с фактором репликации 2 и 3.
- Metro-кластер.
- Асинхронная репликация ВМ на другой HyperFlex-кластер.
- Оркестрация переключения ВМ в удалённый ЦОД.
- Нативные снепшоты по технологии Redirect-on-Write.
- До 1 ПБ полезного пространства при факторе репликации 3 и без учета дедупликации. Фактор репликации 2 не учитываем, т. к. это не вариант для серьёзного прода.
Ещё один огромный плюс — простота управления и развёртывания. Все сложности настройки серверов UCS берёт на себя специализированная ВМ, подготовленная инженерами Cisco.
Конфигурация тестового стенда:
- 2 x Cisco UCS Fabric Interconnect 6248UP в качестве управляющего кластера и сетевых компонентов (48 портов, работающих в режиме Ethernet 10G/FC 16G).
- Четыре сервера Cisco UCS HXAF240 M4.
Характеристики серверов:
| CPU |
2 x Intel ® Xeon ® E5-2690 v4 |
| RAM |
16 x 32GB DDR4-2400-MHz RDIMM/PC4-19200/dual rank/x4/1.2v |
| Network |
UCSC-MLOM-CSC-02 (VIC 1227). 2 порта 10G Ethernet |
| Storage HBA |
Cisco 12G Modular SAS Pass through Controller |
| Storage Disks |
1 x SSD Intel S3520 120 GB, 1 x SSD Samsung MZ-IES800D, 10 x SSD Samsung PM863a 960 GB |
- HXAF240c M5.
- Один или два CPU начиная от Intel Silver 4110 до Intel Platinum I8260Y. Доступно второе поколение.
- 24 слота памяти, планки от 16 GB RDIMM 2600 до 128 GB LRDIMM 2933.
- От 6 до 23 дисков для данных, один кэширующий диск, один системный и один бутовый диск.
Capacity Drives
- HX-SD960G61X-EV 960GB 2.5 Inch Enterprise Value 6G SATA SSD (1X endurance) SAS 960 GB.
- HX-SD38T61X-EV 3.8TB 2.5 inch Enterprise Value 6G SATA SSD (1X endurance) SAS 3.8 TB.
- Caching Drives
- HX-NVMEXPB-I375 375GB 2.5 inch Intel Optane Drive, Extreme Perf & Endurance.
- HX-NVMEHW-H1600* 1.6TB 2.5 inch Ent. Perf. NVMe SSD (3X endurance) NVMe 1.6 TB.
- HX-SD400G12TX-EP 400GB 2.5 inch Ent. Perf. 12G SAS SSD (10X endurance) SAS 400 GB.
- HX-SD800GBENK9** 800GB 2.5 inch Ent. Perf. 12G SAS SED SSD (10X endurance) SAS 800 GB.
- HX-SD16T123X-EP 1.6TB 2.5 inch Enterprise performance 12G SAS SSD (3X endurance).
System / Log Drives
- HX-SD240GM1X-EV 240GB 2.5 inch Enterprise Value 6G SATA SSD (Requires upgrade).
Boot Drives
- HX-M2-240GB 240GB SATA M.2 SSD SATA 240 GB.
Подключение к сети по 40G, 25G или 10G портам Ethernet.
В качестве FI могут быть HX-FI-6332 (40G), HX-FI-6332-16UP (40G), HX-FI-6454 (40G/100G).
Сам тест
Для тестирования дисковой подсистемы я использовал HCIBench 2.2.1. Это бесплатная утилита, позволяющая автоматизировать создание нагрузки из нескольких виртуальных машин. Сама нагрузка генерируется обычным fio.
Наш кластер состоит из четырёх нод, фактор репликации 3, все диски Flash.
Для тестирования я создал четыре датастора и восемь виртуальных машин. Для тестов записи предполагается вариант, когда кэширующий диск не переполняется.
Результаты тестов следующие:
| 100 % Read 100 % Random |
0 % Read 100%Random |
|||||||||
| Блок/глубина очереди |
128 |
256 |
512 |
1024 |
2048 |
128 |
256 |
512 |
1024 |
2048 |
| 4K |
0,59 ms 213804 IOPS |
0,84 ms 303540 IOPS |
1,36ms 374348 IOPS |
2.47 ms 414116 IOPS |
4,86ms 420180 IOPS |
2,22 ms 57408 IOPS |
3,09 ms 82744 IOPS |
5,02 ms 101824 IPOS |
8,75 ms 116912 IOPS |
17,2 ms 118592 IOPS |
| 8K |
0,67 ms 188416 IOPS |
0,93 ms 273280 IOPS |
1,7 ms 299932 IOPS |
2,72 ms 376,484 IOPS |
5,47 ms 373,176 IOPS |
3,1 ms 41148 IOPS |
4,7 ms 54396 IOPS |
7,09 ms 72192 IOPS |
12,77 ms 80132 IOPS |
|
| 16K |
0,77 ms 164116 IOPS |
1,12 ms 228328 IOPS |
1,9 ms 268140 IOPS |
3,96 ms 258480 IOPS |
3,8 ms 33640 IOPS |
6,97 ms 36696 IOPS |
11,35 ms 45060 IOPS |
|||
| 32K |
1,07 ms 119292 IOPS |
1,79 ms 142888 IOPS |
3,56 ms 143760 IOPS |
7,17 ms 17810 IOPS |
11,96 ms 21396 IOPS |
|||||
| 64K |
1,84 ms 69440 IOPS |
3,6 ms 71008 IOPS |
7,26 ms 70404 IOPS |
11,37 ms 11248 IOPS |
||||||
Полужирным отмечены значения, после которых роста производительности нет, иногда даже видна деградация. Связано с тем, что упираемся в производительность сети/контроллеров/дисков.
- Последовательное чтение 4432 МБ/с.
- Последовательная запись 804 МБ/с.
- При отказе одного контроллера (отказ виртуальной машины или хоста) просадка по производительности — в два раза.
- При отказе диска хранения — просадка на 1/3. Ребилд диска занимает 5% ресурсов каждого контроллера.
На маленьком блоке мы упираемся в производительность контроллера (виртуальная машина), её CPU загружен на 100%, при повышении блока упираемся в пропускную способность портов. 10 Гбит/с недостаточно для раскрытия потенциала AllFlash-системы. К сожалению, проверить работу на 40 Гбит/с не позволяют параметры предоставленного демостенда.
По моему впечатлению от тестов и изучения архитектуры, за счёт алгоритма, размещающего данные между всеми хостами, мы получаем масштабируемую предсказуемую производительность, но это же и является ограничением при чтении, т. к. с локальных дисков можно было бы выжимать и больше, тут может спасти более производительная сеть, например, доступны FI на 40 Гбит/с.
Также один диск на кэширование и дедупликацию может являться ограничением, фактически в данном стенде мы можем писать на четыре SSD-диска. Было бы отлично иметь возможность увеличивать количество кэширующих дисков и увидеть разницу.
Реальное использование
Для организации резервного ЦОДа можно использовать два подхода (размещение бэкапа на удалённой площадке не рассматриваем):
- Active-Passive. Все приложения размещаются в основном ЦОДе. Репликация синхронная или асинхронная. В случае падения основного ЦОДа нам нужно активировать резервный. Делать это можно вручную/скриптами/приложениями оркестрации. Здесь мы получим RPO, соизмеримый с частотой репликации, и RTO зависит от реакции и умений администратора и качества проработки/отладки плана переключения.
- Active-Active. В этом случае присутствует только синхронная репликация, доступность ЦОДов определяется кворумом/арбитром, размещённом строго на третьей площадке. RPO = 0, а RTO может достигать 0 (если приложение позволяет) или равно времени на отработку отказа ноды в кластере виртуализации. На уровне виртуализации создаётся растянутый (Metro) кластер, требующий Active-Active СХД.
Обычно мы видим у клиентов уже реализованную архитектуру с классической СХД в основном ЦОДе, поэтому проектируем ещё один для репликации. Как я и упоминал, Cisco HyperFlex предлагает асинхронную репликацию и создание растянутого кластера виртуализации. При этом нам не нужна выделенная СХД уровня Midrange и выше с недешёвыми функциями репликации и Active-Active доступа к данным на двух СХД.
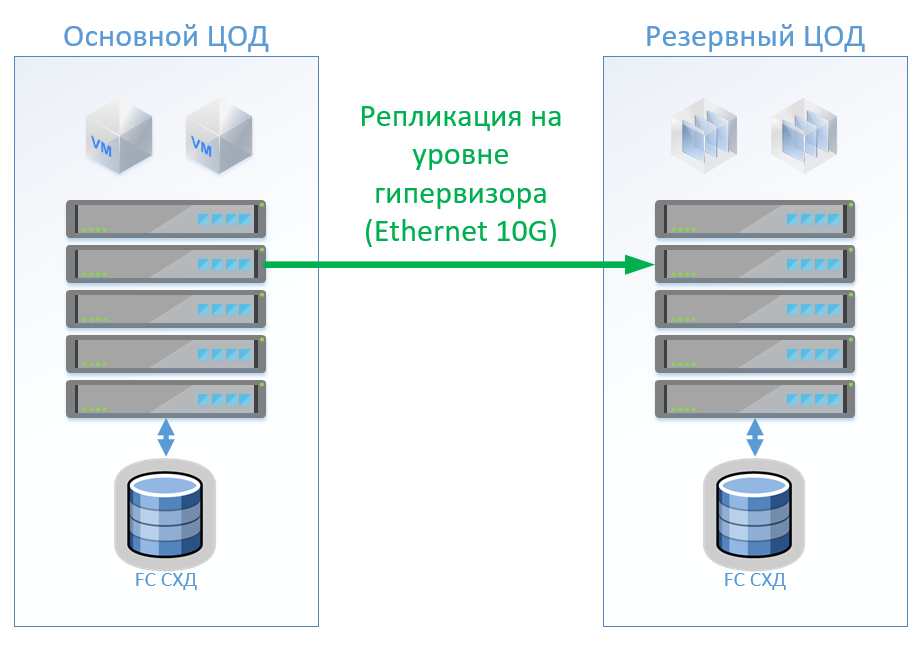
Сценарий 1: У нас есть основной и резервный ЦОДы, платформа виртуализации на VMware vSphere. Все продуктивные системы располагаются в основном ЦОД, а репликация виртуальных машин выполняется на уровне гипервизора, это позволит не держать ВМ включёнными в резервном ЦОД. Базы данных и специальные приложения реплицируем встроенными средствами и держим ВМ включёнными. При отказе основного ЦОД мы запускаем системы в резервном ЦОД. Считаем, что у нас порядка 100 виртуальных машин. Пока действует основной ЦОД, в резервном ЦОД можно запускать тестовые среды и прочие системы, которые можно отключить в случае переключения основного ЦОД. Также возможен вариант, когда у нас используется двухсторонняя репликация. С точки зрения оборудования ничего не поменяется.
В случае классической архитектуры поставим в каждый ЦОД гибридную СХД с доступом по FibreChannel, тирингом, дедупликацией и компрессией (но не онлайн), 8 серверов на каждую площадку, по 2 коммутатора FibreChannel и Ethernet 10G. Для репликации и управления переключением в классической архитектуре можем использовать средства VMware (Replication + SRM) или же сторонние средства, которые будут немного дешевле и иногда удобнее.
На рисунке представлена схема.
В случае использования Cisco HyperFlex получается следующая архитектура:
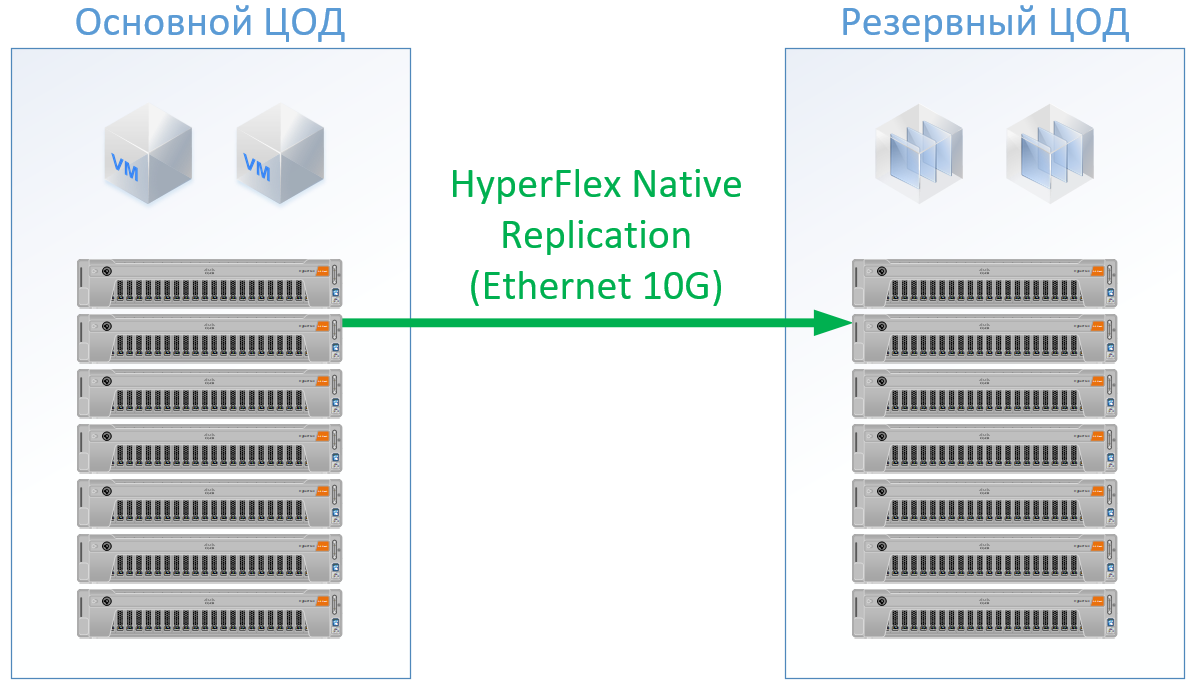
Для HyperFlex я использовал сервера с большими ресурсами CPU/RAM, т.к. часть ресурсов пойдёт на ВМ контроллера HyperFlex, по CPU и памяти я даже немного перезаложился в конфигурации HyperFlex, чтобы не подыгрывать в сторону Cisco и гарантировать ресурсы для остальных ВМ. Зато мы можем отказаться от FibreChannel коммутаторов, и нам не потребуются Ethernet-порты под каждый сервер, локальный траффик коммутируется внутри FI.
В итоге получилась следующая конфигурация для каждого ЦОД:
| Серверы |
8 x 1U Server (384 GB RAM, 2 x Intel Gold 6132, FC HBA) |
8 x HX240C-M5L (512 GB RAM, 2 x Intel Gold 6150, 3,2 GB SSD, 10 x 6 TB NL-SAS) |
| СХД |
Гибридная СХД с FC Front-End (20TB SSD, 130 TB NL-SAS) |
- |
| LAN |
2 x Ethernet switch 10G 12 ports |
- |
| SAN |
2 x FC switch 32/16Gb 24 ports |
2 x Cisco UCS FI 6332 |
| Лицензии |
VMware Ent Plus Репликация и/или оркестрация переключения ВМ |
VMware Ent Plus |
Для Hyperflex не закладывал лицензии ПО репликации, т. к. у нас это доступно из коробки.
Для классической архитектуры я взял вендора, который зарекомендовал себя как качественный и недорогой производитель. Для обоих вариантов применил стандартную для конкретного решения скиду, на выходе получил реальные цены.
Решение на Cisco HyperFlex получилось на 13% дешевле.
Сценарий 2: создание двух активных ЦОДов. В этом сценарии мы проектируем растянутый кластер на VMware.
Классическая архитектура состоит из серверов виртуализации, SAN (протокол FC) и двух СХД, которые умеют читать и писать на том, растянутый между ними. На каждой СХД закладываем полезную ёмкость для лока.
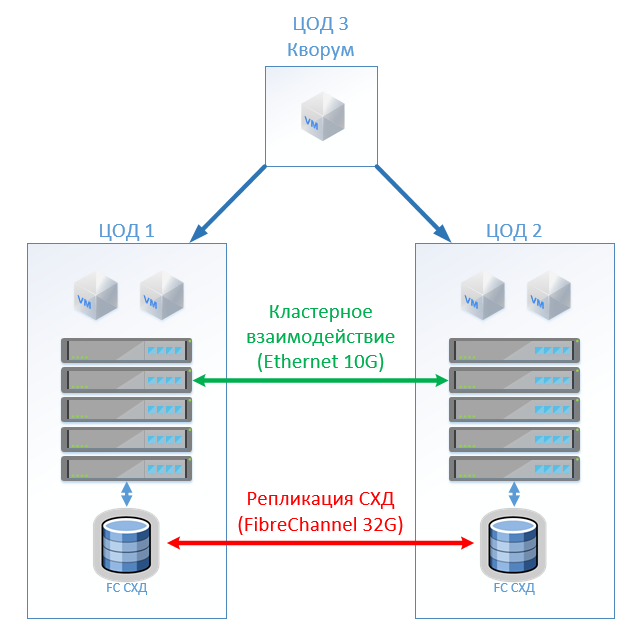
У HyperFlex просто создаём Stretch Cluster с одинаковым количеством нод на обеих площадках. В этом случае используется фактор репликации 2+2.
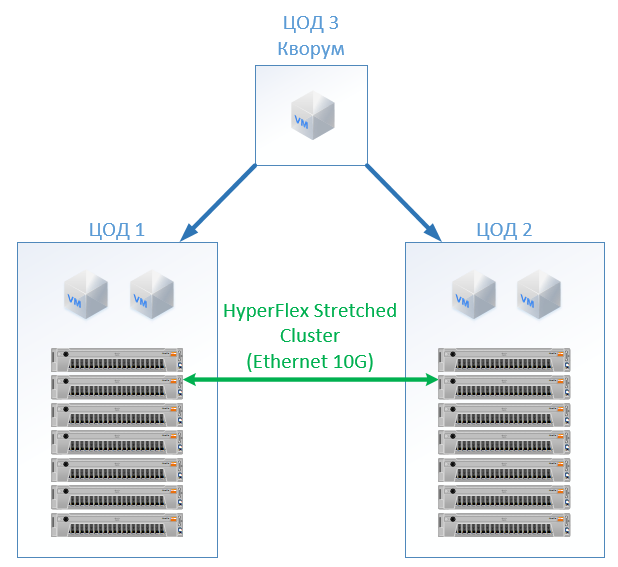
Получилась следующая конфигурация:
| Классическая архитектура |
HyperFlex |
|
| Серверы |
16 x 1U Server (384 GB RAM, 2 x Intel Gold 6132, FC HBA, 2 x 10G NIC) |
16 x HX240C-M5L (512 ГБ RAM, 2 x Intel Gold 6132, 1,6 TB NVMe, 12 x 3,8 TB SSD, VIC 1387) |
| СХД |
2 x AllFlash СХД (150 TB SSD) |
- |
| LAN |
4 x Ethernet switch 10G 24 ports |
- |
| SAN |
4 x FC switch 32/16Gb 24 ports |
4 x Cisco UCS FI 6332 |
| Лицензии |
VMware Ent Plus |
VMware Ent Plus |
Во всех подсчётах я не учитывал сетевую инфраструктуру, затраты на ЦОД и т. д.: они будут одинаковыми для классической архитектуры и для решения на HyperFlex.
По стоимости HyperFlex получился на 5% дороже. Здесь стоит отметить, что по ресурсам CPU/RAM у меня для Cisco получился перекос, т. к. в конфигурации заполнял каналы контроллеров памяти равномерно. Стоимость чуть выше, но не на порядок, что явно указывает, что гиперконвергенция не обязательно «игрушка для богатых», а может конкурировать со стандартным подходом к построению ЦОДа. Также это может быть интересно тем, у кого уже есть сервера Cisco UCS и соответствующая инфраструктура под них.
Из плюсов получим отсутствие затрат на администрирование SAN и СХД, онлайн-компрессию и дедупликацию, единую точку входа для поддержки (виртуализация, сервера, они же — СХД), экономия места (но не во всех сценариях), упрощение эксплуатации.
Что касается поддержки, то тут вы получаете её от одного вендора — Cisco. Если судить по опыту работы с серверами Cisco UCS, то она мне нравится, на HyperFlex открывать так и не пришлось, всё и так работало. Инженеры отвечают оперативно и могут решать не только типовые проблемы, но и сложные пограничные случаи. Порой я обращаюсь к ним с вопросами: «А можно ли сделать так, прикрутить это?» или «Я тут что-то наконфигурировал, и оно не хочет работать. Помогите!» — они там терпеливо найдут нужный гайд и укажут на правильные действия, отвечать: «Мы решаем только аппаратные проблемы» они не станут.
Ссылки
- Спеки
- Виртуальный дата-центр
- Дата-центр в ящике стола
- Моя почта — StGeneralov@croc.ru
Комментарии (6)

Schalker
15.10.2019 20:42+1Хорошая статья, правильная. Гиперконвергенция это интересно. Для больших ЦОДов. Для « обычного» предприятия, до 1000 пользователей — все же слишком сложно.
2 года назад я чуть было не перешёл. Пронесло. Нормального VMware кластера с выделенной блочной СХД — пока хватает. Проще выносить ресурсы в коммерческий Cloud.
Дешевле, и самое главное Админу проще
Как всегда, разные интересы интеграторов и локальных админов
StGeneralov Автор
16.10.2019 14:39Необходимость использования гиперконвергенции действительно зависит от сценария, но сейчас она становится доступнее и при не больших сценариях. Если говорить о сложности решения, то в следующей статье покажем, что развернуть SDS не сложнее, чем настроить внешнюю СХД. Лично я сам привык к использованию выделенной СХД, но администратору виртуализации, не знающему SAN, удобнее развернуть очередной «Appliance» в составе виртуализации и получить полноценное хранилище
vesper-bot
16.10.2019 15:20Ну не знаю, чего сложного — затратно, разве что. Берем Nutanix CE, 4 одинаковых сервера, 10Gb сеть, соединяем, хоп готовая HCI (под запросы обычного предприятия может вполне подойти). Бэкапать, правда, придется по-другому.
shapa
Пара «нюансов»
1) Вы с cisco согласовали вообще публикацию? Параметры производительности по результатам тестов — очень плохие (особенно учитывая что это All Flash), и такое выкладывать на публику — гхм.
2) EULA читали? Большинство вендоров (включая VMware) вообще-то запрещают результаты любых тестов выкладывать публично. Особенно — если они откровенно плохие (как в этом случае).
teemour
а вы с автором согласовывали эту самоцензуру вообще?
shapa
Если вы не понимаете разницу между лицензионным соглашением вендора и «самоцензурой» — успехов вам.
Фактически, работник «Крок» выставил решение Cisco (партнером которой они и являются) в очень плохом свете, и теперь на эту статью можно ссылаться и показывать — что конкуренты всенепременно и будут делать.
Конкурирующие HCI решения (даже VSAN) покажут в разы более высокие параметры производительности на аналогичном оборудовании.