
В статическом анализаторе NoVerify появилась киллер-фича: декларативный способ описания инспекций, который не требует программирования на Go и компиляции кода.
Чтобы вас заинтриговать, покажу описание простой, но полезной инспекции:
/** @warning duplicated sub-expressions inside boolean expression */
$x && $x;Эта инспекция находит все выражения логического &&, где левый и правый операнд идентичны.
NoVerify — статический анализатор для PHP, написанный на Go. Почитать о нём можно в статье «NoVerify: линтер для PHP от Команды ВКонтакте». А в этом обзоре я расскажу о новой функциональности и том, как мы к ней пришли.

Предпосылки
Когда даже для простой новой проверки нужно написать несколько десятков строк кода на Go, начинаешь задумываться: а можно ли как-то иначе?
На Go у нас написан вывод типов, весь пайплайн линтера, кеш метаданных и многие другие важные элементы, без которых работа NoVerify невозможна. Эти компоненты уникальны, а вот задачи типа «запретить вызов функции X с набором аргументов Y» — нет. Как раз для таких простых задач и добавлен механизм динамических правил.
Динамические правила позволяют отделить сложные внутренности от решения типовых задач. Файл с определениями можно хранить и версионировать отдельно — его могут редактировать люди, не имеющие отношения к разработке самого NoVerify. Каждое правило реализует инспекцию кода (которую мы иногда будем называть проверкой).
Да, если у нас есть язык описания этих правил, всегда можно написать семантически некорректный шаблон или не учесть какие-то ограничения типов — а это приводит к ложным срабатываниям. Тем не менее гонку данных или разыменование nil-указателя через язык правил не внести.
Язык описания шаблонов
Язык описания синтаксически совместим с PHP. Это упрощает его изучение, а также даёт возможность редактировать файлы с правилами, используя тот же PhpStorm.
В самом начале файла правил рекомендуется вставить директиву, успокаивающую любимую IDE:
<?php
/**
* Отключаем все инспекции для этого файла,
* так как у нас здесь не исполняемый PHP-код.
*
* @noinspection ALL
*/
// ...А ниже — уже сами правила.Моим первым экспериментом с синтаксисом и возможными фильтрами для шаблонов был phpgrep. Он может быть полезен и сам по себе, но внутри NoVerify он стал ещё интереснее, потому что теперь он имеет доступ к информации о типах.
Некоторые мои коллеги уже попробовали phpgrep в работе, и это было ещё одним доводом в пользу выбора именно такого синтаксиса.
Сам phpgrep является адаптацией gogrep для PHP (вам также может быть интересен cgrep). С помощью этой программы можно искать код через синтаксические шаблоны.
Альтернативой мог бы быть синтаксис structural search and replace (SSR) из PhpStorm. Преимущества очевидны — это уже существующий формат, но я узнал об этой фиче после того, как реализовал phpgrep. Можно, конечно, привести техническое объяснение: там несовместимый с PHP синтаксис и наш парсер это не осилит, — но эта убедительная «настоящая» причина обнаружилась после написания велосипеда.
Можно было требовать отображения шаблона с PHP-кодом почти один в один — или пойти другим путём: изобрести новый язык, например с синтаксисом S-выражений.
PHP-like Lisp-like
-----------------------------
$x = $y | (expr = $x $y)
fn($x, 1) | (expr call fn $x 1)
Мы могли бы выражать типы и ветвление прямо внутри шаблонов:
(or (expr == (type string (expr)) (expr))
(expr == (expr) (type string (expr))))В итоге я посчитал, что читабельность шаблонов всё же важна, а фильтры мы можем добавлять через атрибуты phpdoc.
clang-query — пример подобной идеи, но он использует более традиционный синтаксис.
Создаём и запускаем свою диагностику!
Давайте попробуем реализовать свою новую диагностику для анализатора.
Для этого вам потребуется установленный NoVerify. Возьмите бинарный релиз, если у вас нет Go-тулчейна в системе (если есть, можете собрать всё из исходников).
| Если вы не установите NoVerify, можете продолжить читать дальше, но делайте вид, что воспроизводите перечисляемые шаги и восхищаетесь результатом! |
Постановка задачи
В PHP много любопытнейших функций, одна из них — parse_str. Её сигнатура:
// Разбирает строку encoded_string, которая должна иметь формат
// строки запроса URL, и присваивает значения переменным в
// текущем контексте (или в массиве, если задан параметр result).
parse_str ( string $encoded_string [, array &$result ] ) : voidВы поймёте, что здесь не так, если посмотрите на этот пример из документации:
$str = "first=value&arr[]=foo+bar&arr[]=baz";
parse_str($str);
echo $first; // value
echo $arr[0]; // foo bar
echo $arr[1]; // bazМ-м-м, параметры из строки оказались в текущей области видимости. Чтобы такого не допускать, мы будем в своей новой проверке требовать использовать второй параметр функции, $result, чтобы результат записывался в этот массив.
Создание своей диагностики
Создадим файл myrules.php:
<?php
/** @warning parse_str without second argument */
parse_str($_);Файл правил в общем виде представляет собой список выражений на верхнем уровне, каждое из которых интерпретируется как phpgrep-шаблон. К каждому такому шаблону ожидается особый phpdoc-комментарий. Обязательным является только один атрибут — категория ошибки с текстом предупреждения.
Всего сейчас есть четыре уровня: error, warning, info и maybe. Первые два — критические: линтер вернёт ненулевой код после выполнения, если хотя бы одно из критических правил сработает. После самого атрибута идёт текст предупреждения, который будет выдаваться линтером в случае срабатывания шаблона.
В шаблоне, который мы написали, используется $_ — это безымянная переменная шаблона. Мы могли бы назвать её, например, $x, но поскольку ничего с этой переменной мы не делаем, можем дать ей «пустое» название. Отличие переменных шаблона от переменных PHP в том, что первые совпадают с абсолютно любым выражением, а не только с «дословной» переменной. Это удобно: нам гораздо чаще нужно искать неизвестные выражения, а не конкретные переменные.
Запуск новой диагностики
Создадим небольшой тестовый файл для отладки, test.php:
<?php
function f($x) {
parse_str($x); // Здесь наш линтер должен ругаться
}Далее запустим NoVerify с нашими правилами на этом файле:
$ noverify -rules myrules.php test.phpНаше предупреждение будет выглядеть примерно так:
WARNING myrules.php:4: parse_str without second argument at test.php:4
parse_str($x);
^^^^^^^^^^^^^Названием проверки по умолчанию выступает имя rules-файла и строчка, которая определяет эту проверку. В нашем случае это myrules.php:4.
Можно задать своё имя, используя атрибут @name <name>.
/**
* @name parseStrResult
* @warning parse_str without second argument
*/
parse_str($_);WARNING parseStrResult: parse_str without second argument at test.php:4
parse_str($x);
^^^^^^^^^^^^^Именованные правила поддаются законам остальным диагностик:
- Можно отключить через
-exclude-checks - Уровень критичности можно переопределить через
-critical
Работа с типами
Предыдущий пример хорош для hello world — но часто нам нужно знать типы выражений, чтобы сократить количество срабатываний диагностики
Например, для функции in_array мы просим аргумент $strict=true тогда, когда первый аргумент ($needle) имеет строковой тип.
Для этого у нас есть фильтры результата.
Один из таких фильтров — @type <type> <var>. Он позволяет отбрасывать всё то, что не подходит под перечисляемые типы.
/**
* @warning 3rd arg of in_array must be true when comparing strings
* @type string $needle
*/
in_array($needle, $_);Здесь мы дали имя первому аргументу вызова in_array, чтобы привязать к нему фильтр типа. Предупреждение будет выдаваться только тогда, когда тип $needle равен string.
Наборы фильтров можно комбинировать оператором @or:
/**
* Каждой проверке можно дать комментарий-описание.
*
* @warning strings must be compared using '===' operator
* @type string $x
* @or
* @type string $y
*/
$x == $y;В примере выше шаблон будет совпадать только с теми выражениями ==, где любой из операндов имеет тип string. Можно считать, что без @or все фильтры комбинируются через @and, но явно это указывать не нужно.
Ограничиваем область действия диагностики
Для каждой проверки можно указать @scope <name>:
@scope all— значение по умолчанию, проверка работает везде;@scope root— запуск только на верхнем уровне;@scope local— запуск только внутри функций и методов.
Предположим, мы хотим докладывать о return вне тела функции. В PHP это иногда имеет смысл — например, когда файл подключается из функции… Но в рамках этой статьи мы такое осуждаем.
/**
* @warning don't use return outside of functions
* @scope root
*/
return $_;Посмотрим, как будет вести себя это правило:
<?php
function f() {
return "OK";
}
return "NOT OK"; // Gives a warning
class C {
public function m() {
return "ALSO OK";
}
}Аналогично можно сделать просьбу использовать *_once вместо require и include:
/**
* @maybe prefer require_once over require
* @scope root
*/
require $_;
/**
* @maybe prefer include_once over include
* @scope root
*/
include $_;Сейчас при сопоставлении шаблонов скобочки учитываются не вполне консистентно. Шаблон(($x))найдёт не «все выражения в двойных скобках», а просто любые выражения, игнорируя скобки. Тем не менее,$x+$y*$zи($x+$y)*$zведут себя так, как надо. Эта особенность исходит от трудностей работы с токенами(и), но есть шанс, что порядок будет наведён в одном из следующих релизов.
Группирование шаблонов
Когда появляется дублирование phpdoc-комментариев у шаблонов, на помощь приходит возможность комбинирования шаблонов.
Простой пример для демонстрации:
| Было | Стало (с группированием) |
|---|---|
/** @maybe don't use exit or die */ die($_); /** @maybe don't use exit or die */ exit($_); |
/** @maybe don't use exit or die */
{
die($_);
exit($_);
}
|
А теперь представьте себе, как было бы неприятно описывать правило в следующем примере без этой особенности!
/**
* @warning don't compare arrays with numeric types
* @type array $x
* @type int|float $y
* @or
* @type int|float $x
* @type array $y
*/
{
$x > $y;
$x < $y;
$x >= $y;
$x <= $y;
$x == $y;
}Формат записи, указанный в статье, — всего лишь один из предложенных вариантов. Если вы хотите поучаствовать в выборе, то у вас есть такая возможность: нужно ставить +1 тем предложениям, которые вам нравятся больше остальных. Подробнее — по ссылке.
Как интегрированы динамические правила
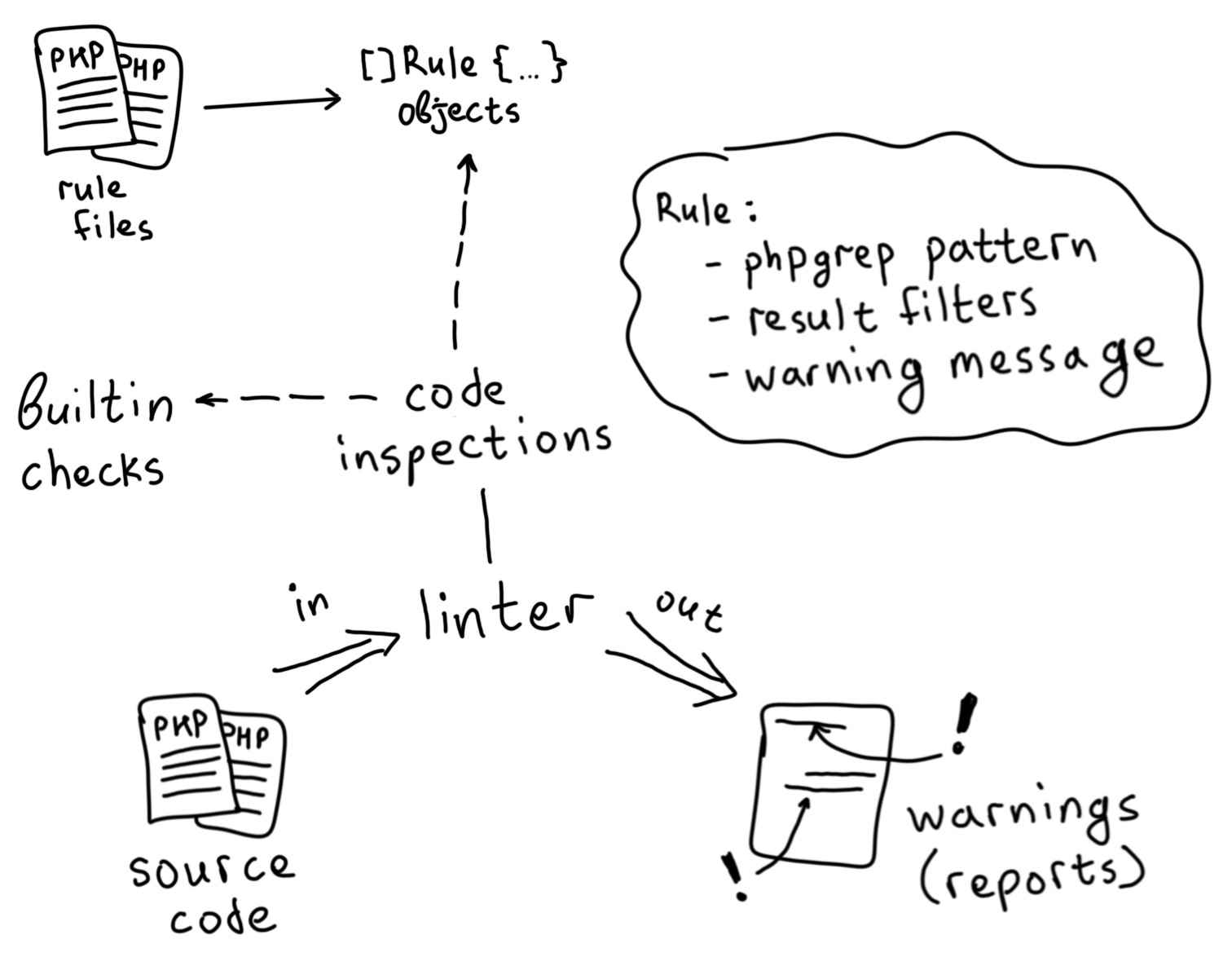
В момент запуска NoVerify пытается найти файл с правилами, который указан в аргументе rules.
Далее этот файл разбирается как обычный PHP-скрипт, и из полученного AST собирается набор объектов-правил с привязанными к ним phpgrep-шаблонами.
Затем анализатор начинает работу по обычной схеме — разница только в том, что для некоторых проверяемых участков кода он запускает набор привязанных правил. Если правило срабатывает, выводится предупреждение.
Срабатыванием считается успешное сопоставление phpgrep-шаблона и прохождение хотя бы одного из наборов фильтров (они разделены @or).
На данном этапе механизм правил не вносит значительного замедления в работу линтера, даже если динамических правил достаточно много.
Алгоритм матчинга
При наивном подходе для каждого AST-узла нам нужно применять все динамические правила. Это очень неэффективная реализация, потому что большая часть работы будет проделана впустую: многие шаблоны имеют определённый префикс, по которому мы можем кластеризовать правила.
Это похоже на идею параллельного матчинга, только вместо честного построения NFA мы выполняем «параллелизацию» только первого шага вычислений.
Рассмотрим это на примере с тремя правилами:
/** @warning duplicated then/else parts of ternary */
$_ ? $x : $x;
/** @warning don't call explode with delim="" */
explode("", ${"*"});
/** @maybe suspicious empty body of the if statement */
if ($_);Если у нас N элементов и M правил, при наивном подходе имеем N*M операций для выполнения. В теории эту сложность можно свести к линейной и получить O(N) — если объединить все шаблоны в один и выполнять матчинг так, как это делает, например, пакет regexp из Go.
Однако на практике я пока остановился на частичной реализации такого подхода. Он позволит правила из файла выше разделить на три категории, а тем элементам AST, которым не соответствует никакое правило, присвоить четвёртую, пустую категорию. Благодаря этому на каждый элемент выполняется не более одного правила.
Если у нас появятся тысячи правил и мы будем ощущать значительное замедление, алгоритм будет доработан. А пока простота решения и полученное ускорение меня устраивают.
Муки выбора, или Немного о форме записи @type
| Задача: выбрать для фильтров хороший синтаксис в рамках phpdoc-аннотаций. |
Текущий синтаксис дублирует @var и @param, но нам могут понадобиться новые операторы, например, "тип не равен". Пофантазируем, как это могло бы выглядеть.
У нас как минимум два важных приоритета:
- Читабельный и лаконичный синтаксис аннотаций.
- Максимально возможная поддержка от IDE без дополнительных усилий.
Для PhpStorm есть плагин php-annotations, который добавляет автодополнение, переход к классам-аннотациям и прочие полезности для работы с phpdoc-комментариями.
Приоритет (2) на практике означает, что вы принимаете решения, которые не противоречат ожиданиям IDE и плагинов. Например, можно сделать аннотации в таком формате, который сможет распознавать плагин php-annotations:
/**
* Type is a filter that checks that $value
* satisfies the given type constraints.
*
* @Annotation
*/
class Filter {
/** Variable name that is being filtered */
public $value;
/** Check that value type is equal to $type */
public $type;
/** Check that value text is equal to $text */
public $text;
}Тогда применение фильтра для типов выглядело бы как-то так:
@Type($needle, eq=string)
@Type($x, not_eq=Foo)Пользователи могли бы переходить к определению Filter, подсказывался бы список возможных параметров (type/text/etc).
Альтернативные способы записи, некоторые из которых были предложены коллегами:
@type string $needle
@type !Foo $x
@type $needle == string
@type $x != Foo
@type(==) string $needle
@type(!=) Foo $x
@type($needle) == string
@type($x) != Foo
@filter type($needle) == string
@filter type($x) != FooПотом мы немного отвлеклись и забыли, что это всё внутри phpdoc, — и появилось такое:
(eq string (typeof $needle))
(neq Foo (typeof $x))Хотя вариант с постфиксной записью в шутку тоже прозвучал. Язык для описания ограничений типов и значений можно было бы назвать sixth:
@eval string $needle typeof =
@eval Foo $x typeof <>Поиски самого лучшего варианта всё ещё не закончены...
Сравнение расширяемости с Phan
Как одно из преимуществ Phan в статье "Статический анализ PHP-кода на примере PHPStan, Phan и Psalm" указывается расширяемость.
Вот то, что было реализовано в плагине-примере:
Мы захотели оценить, насколько наш код готов к PHP 7.3 (в частности, узнать, нет ли в нём case-insensitive-констант). Мы практически были уверены в том, что таких констант нет, но за 12 лет могло произойти всякое — следовало проверить. И мы написали плагин для Phan, который бы ругался, если бы в define() использовался третий параметр.
Так выглядит код плагина (форматирование оптимизировано по ширине):
<?php
use Phan\AST\ContextNode;
use Phan\CodeBase;
use Phan\Language\Context;
use Phan\Language\Element\Func;
use Phan\PluginV2;
use Phan\PluginV2\AnalyzeFunctionCallCapability;
use ast\Node;
class DefineThirdParamTrue
extends PluginV2
implements AnalyzeFunctionCallCapability {
public function getAnalyzeFunctionCallClosures(CodeBase $code_base) {
$def = function(CodeBase $cb, Context $ctx, Func $fn, $args) {
if (count($args) < 3) {
return;
}
$this->emitIssue(
$cb, $ctx,
'PhanDefineCaseInsensitiv',
'define with 3 arguments', []
);
};
return ['define' => $def];
}
}
return new DefineThirdParamTrue();А вот как это можно было бы сделать в NoVerify:
<?php
/** @warning define with 3 arguments */
define($_, $_, $_);Примерно такого результата мы и хотели добиться — чтобы тривиальные вещи можно было делать максимально просто.
Заключение
- Попробуйте NoVerify в своём проекте.
- Если у вас будут идеи для доработок или отчёты о багах, расскажите нам об этом.
- Если вы хотите поучаствовать в разработке, welcome!
Ссылки, полезные материалы
Здесь собраны важные ссылки, часть из которых могла уже упоминаться в статье, но для наглядности и удобства я их собрал в одном месте.
- Статья про NoVerify на Хабре
- Статья про phpgrep на Хабре
- Видео доклада о phpgrep с IT Nights
- gogrep — поиск Go кода по синтаксическим шаблонам
- Близкая к синтаксическим шаблонам концепция AST selectors из ESLint
Если вам нужны ещё примеры правил, которые можно реализовать, можете подглядеть в тестах NoVerify.
Комментарии (5)


quasilyte Автор
09.11.2019 14:14+1Есть чатик https://t.me/noverify_linter, где обсуждаем статический анализ и сам NoVerify.
В идеале это должно стать community чатом проекта, где голоса пользователей и контрибьюторов могут быть услышаны более оперативно и в менее формальной обстановке, чем GitHub issues.
Присоединяйтесь, если интересен статический анализ PHP (другие линтеры там тоже обсуждаем и сравниваем). :)
tsukanov-as
Спасибо за статью.
Немного недопонял, а что мешает эти шаблоны сразу превращать в код на Go?
Грубо говоря вместо динамики «NFA» сразу получить нативный «DFA»?
Например, для шаблона
$_ ? $x : $x;кажется известно заранее какой конкретный узел AST «слушать».Динамика просто удобнее или есть технические препятствия?
quasilyte Автор
Ничего не мешает, кроме того, что это придётся реализовывать и поддерживать в дополнение к динамической подгрузке, так динамические проверки удобны для тех, кто работает с PHP и не хочет/не может собирать Go. А ещё это полезно в окружениях, где есть линтер, но нет Go тулчейна.
Нужно учитывать, что это линтер для PHP, а Go здесь — деталь реализации. Поэтому требовать от людей наличия Go тулчейна для использования этой фичи может быть слишком. :)
Компиляция шаблонов — это оптимизация, а пока у нас нет проблем с производительностью. Даже если умножить на 10 количество текущих шаблонов, работает очень быстро, при этом нет гарантии, что у нас когда либо действительно будет x20 шаблонов.
В текущей реализации тоже не сложно запускать шаблон только для тернарных операторов. По-моему сейчас он в группе условных выражений, но не сложно довести отображение к 1-to-1, но опять же, рановато оптимизировать, как по мне.
Я бы сказал, динамика даже мне удобна для отладки, когда экспериментируешь. Компиляция шаблонов была бы интересной дополнительной фичей, но вытеснить динамические правила она, думаю, не должна. Для совсем-совсем критичных к производительности проверок всегда можно написать обычное расширение линтера на Go, без использования "правил".
tsukanov-as
Понятно. Спасибо за развернутый ответ!