

Все началось, казалось бы, с простого вопроса, который сначала ввел меня в ступор — "Зачем нужен make? Почему нельзя обойтись bash скриптами?". И я подумал — Действительно, зачем нужен make? (и самое важное) Какие проблемы он решает?
Тут я решил немного подумать — как бы мы собирали свои проекты, если бы у нас не было make. Допустим, мы имеем проект с исходниками. Из них нужно получить исполняемый файл (или библиотеку). На первый взгляд задача вроде простая, но пошли дальше. Пусть на начальном этапе проект состоит из одного файла.
Для его компиляции достаточно выполнить одну команду:
$ gcc main.c -o mainЭто было довольно просто. Но проходит некоторое время, проект развивается, в нем появляются некоторые модули и исходных файлов становится больше.

Для компиляции нужно выполнить условно вот такое количество команд:
$ gcc -c src0.c
$ gcc -c src1.c
$ gcc -c main.c
$ gcc -o main main.o src0.o src1.oСогласитесь, это довольно длительный и кропотливый процесс. Выполнять это вручную я бы не стал. Я бы подумал, что этот процесс можно автоматизировать, просто создав скрипт build.sh, который бы содержал эти команды. Окей, так намного проще:
$ ./build.shПогнали дальше! Проект растет, количество файлов с исходниками увеличивается и строк в них тоже становится больше. Мы начинаем замечать, что время компиляции заметно возросло. Тут мы видим существенную недоработку нашего скрипта — он выполняет компиляцию всех наших 50 файлов с исходниками, хотя мы модифицировали только один.
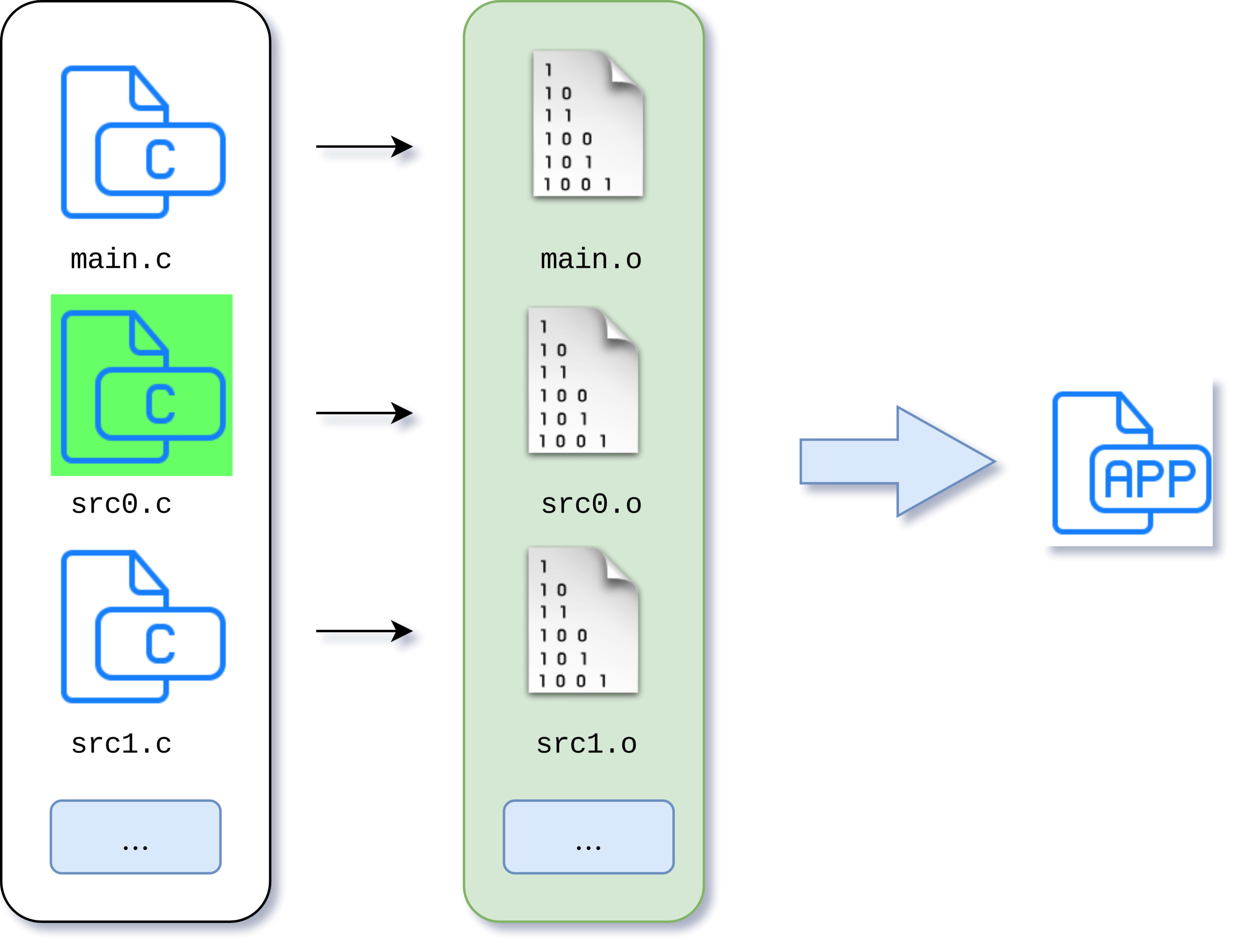
Так не пойдет! Время разработчика слишком ценный ресурс. Что же, мы можем попытаться доработать скрипт сборки таким образом, чтобы перед компиляцией производилась проверка времени модификации исходников и объектных файлов. И компилировать только те исходники, которые были изменены. И условно это может выглядеть как-то так:
#!/bin/bash
function modification_time
{
date -r "$1" '+%s'
}
function check_time
{
local name=$1
[ ! -e "$name.o" ] && return $?
[ "$(modification_time "$name.c")" -gt "$(modification_time "$name.o")" ] && return $?
}
check_time src0 && gcc -c src0.c
check_time src1 && gcc -c src1.c
check_time main && gcc -c main.c
gcc -o main main.o src0.o src1.oИ теперь компилироваться будут только те исходники, которые были модифицированы.

Но что произойдет, когда проект превратится во что-нибудь подобное:
Рано или поздно наступит такой момент, когда в проекте будет очень сложно разобраться и сама по себе поддержка подобных скриптов станет трудоемким процессом. И не факт, что этот скрипт будет производить адекватную проверку всех зависимостей. К тому же, у нас может быть несколько проектов и у каждого будет свой скрипт для сборки.
Само собой мы видим, что напрашивается какое то общее решение этой проблемы. Инструмент, который бы предоставил механизм для проверки зависимостей. И вот тут мы потихоньку подобрались к изобретению make. И теперь, зная с какими проблемами мы столкнемся в процессе сборки проекта, в конце концов я бы сформулировал следующие требования к make:
- анализ временных меток зависимостей и целей
- выполнение минимального объема работы, необходимого для того, чтобы гарантировать актуальность производных файлов
- (ну и + параллельное выполнение команд)
Makefile
Для описания правил сборки проекта используются Makefile'ы. Создавая Makefile, мы декларативно описываем определенное состояние отношений между файлами. Декларативный характер определения состояния удобен тем, что мы говорим, что у нас есть некоторый список файлов и из них нужно получить новый файл, выполнив некоторый список команд. В случае использования какого-либо императивного языка (например, shell) нам приходилось бы выполнять большое количество различных проверок, получая на выходе сложный и запутанный код, тогда как make делает это за нас. Главное построить правильное дерево зависимостей.
< цель > : < зависимости ... >
< команда >
...
...Не буду рассказывать про то, как писать Makefile'ы. В интернете очень много мануалов на эту тему и при желании можно обратиться к ним. И к тому же, мало кто пишет Makefile'ы вручную. А очень сложные Makefile'ы могут стать источником осложнений вместо того, чтобы упростить процесс сборки.
maisvendoo
А между прочим, упреждая попытки покритиковать автора за очевидность темы, не все, особенно начинающие разработчики, понимают последовательность сборки проекта, особенно если в дело идут shared library и прочие многоступенчатые зависимости… При том, что понимать, что происходит внутри всех этих Makefile, proj.pro, proj.sln и т.д. и т.п., очень и очень полезно, например при разборе сообщений об ошибках сборки. Так что думаю, то что вы написали — полезно
x67
Не такая уж очевидная тема, если ты не проф. разработчик на низкоуровневом языке.
Я, например, изучал с++ в институте. И это скорее можно было назвать изучением синтаксиса и алгоритмов. Причем писал программы, компилировал. Но пиратская студия, сами понимаете:) нажал зеленую кнопку и все готово.
А теперь хотя бы есть понимание, зачем я делаю мейк каждый раз, когда ставлю очередной питон или постгрес, например.
Но понимание, на самом деле, весьма поверхностное. Неужели все так просто — обновить объектные файлы и слинковать их воедино?
berez
Отслеживать зависимости можно, собирать промежуточные билиотеки, генерировать промежуточные файлы. Можно даже утилиты собирать промежуточные для генерирования всякого.
khim
Представьте, что один из этих файлов генерится утилитой, которая вроде как тоже из объектных файлов — но под другую архитектуру (потому как вы делаете проект под Android, а работаете всё не под Android'ом). У вас начнут появляться «параллельные» объектные файлы под две архитектуры. Или вам нужно собрать две версии библиотеки — «обычную» (для программы) и «инсталляционную». Вызвать bison, flex и бог знает что ещё.
Так и превращаются концептуально простые вещи вот в таких монстров где десятки файлов и тысячи строк кода…
fougasse
CMake с минимальным окружением на питоне отлично справляется с кроссом под 4 архитектуры.
Параллельные иерархии просто лежат в отдельных папках и подхватываются без проблем.
Аналогично с дебаг/релиз/инсталл/...
iig
CMake внезапно генерирует Makefile, который выполняется тем самым make ;)
fougasse
Внезапно, но это уже проблемы CMake, а не меня как пользователя системы сборки.
И проблем в генерируемом проекте особо не наблюдается.
slovak
Подскажите, а зачем нужен питон? Разве CMake сам с описанной задачей не справляется?
iig
Иногда проще написать костылик на питоне, чем сообразить, как объяснить cmake свое видение задачи.
aamonster
На самом деле всё ещё проще, если забыть об объектных файлах и т.п., и вначале понять принцип действия make.
А он прост до безумия. Пишем: цель A зависит от целей B, C, D, и для её сборки надо выполнить такие-то действия. Точка.
То же самое пишем для прочих целей.
Простейший декларативный язык. Просто записываем дерево целей и способы их сборки, всё.
ilammy
Make — это всего лишь Prolog для файловой системы :)
aamonster
Бинго!
khim
Прекрасно. А теперь у вас появляется скрипт, который порождает два файла (скажем .h файл и .cc файл). Что делать будете?
Любая система сборки «проста и невинна», пока все вокруг знают о её сущесствовании и весь код пишут сообразно нуждам этой системы сборки.
А вот если, вдруг, «парадигма меняется»… вот тут-то и появляются костыли.
А она меняется, потому что продукт развивается. Раньше все библиотеки клались в одно место — а теперь, вдруг, из решили разрести. Раньше у вас не было различий между билд-системой и хост-системой — а сегодня, вдруг, появились. И так далее.
aamonster
Два артефакта одним скриптом – вообще не проблема: "Multiple Targets in a Rule".
Но насчёт написания кода сообразно нуждам системы сборки – вы, imho, правы. Это даже не для того, чтобы системе сборки легко было :-), а для облегчения поддержки кодовой базы.
khim
То есть вы не решаете проблему. Вместо того, чтобы научить Make порождать из одного файла два — вы учите его порождать из одного файла первый файл и второй. Что не одно и то же: при параллельной сборке у вас начинуются гонки и билд то проходит, то нет. Необычайно увлекательно.
aamonster
С чего бы тут возникло состояние гонки? Да, make -j может порождать несколько процессов для параллельной сборки – но с чего вы взяли, что и makefile (точнее, построенный по нему DAG таргетов) он обрабатывает в несколько потоков?
Впрочем, я не призываю использовать make. А вот понять – очень полезно.
khim
Ну потому что я, в отличие от вас, знаю как работает make. И умею читать. Да, редкое сегодня качество, признаю.
Вот вам пример, может заставит задуматься:
Не объясните с какого перепугу тут генератор Жопыпопы (sleep 1 для чистоты эксперимента) вызвался дважды? Причём впараллель? И чем это может закончится если он будет действительно что-нибудь генерировать?
Да, вокруг этой задачи есть несколько костылей разных сортов и размеров. Но самоё весёлое даже не в них. Факт остаётся фактом: удивительным убразом Make умеет в несколько файлов из одного правила одновременно… более того — там есть такие шняги по умолчанию… вот только это описано вот не в разделе «Multiple Targets in a Rule» и вот нифига не очевидно, в чём проблема, пока не начнёшь разбираться с «flake build»ом, который «уже всех задолбал».
P.S. Вот те рассуждения про GNAT — на самом деле были подсказкой. Но вы, похоже, ниасилили…
aamonster
Спасибо!
edo1h
Вы про Handling Tools that Produce Many Outputs?
Да уж, не сталкивался, действительно жопа-попа.
khim
Самое весёлое, что самый разумный вариант там упомянут вскользь, в самом-самом конце, мимоходом так. Даже без примера.
А вот вариант, который напрашивается, который «очевиден», который «легко гуглится»… не работает. Вернее работает через раз и периодически будет вам красить боты в красный цвет «непонятно почему»…
edo1h
pattern rule? ну да, в реальной жизни оно покрывает, наверное 99% всех случаев, но вот именно с жопа-попа как-то не особо применимо ИМХО )
khim
Ну натянуть-то можно. Главная беда — как раз даже не в том, что поправить сложно — там, как вы обнаружили, даже и отдельная глава есть в мануале с подробным описанием.
Самая большая беда — с осознанием: если вы про эту конкретную «жопу» не в курсе — то догадываться почему у вас боты падают можно буквально месяцами.
И вот в этом — вся беда Make: он так-то инструмент несложный, но чтобы им пользоваться нужно очень глубоко в него «въехать», фактически весь мануал в себя «впитать»… карго-культ чреват очень неприятными последствиями… даже не знаю как к этому относиться.
Для инструментов «старой школы» (Bash там или TeX) — это весьма характерно. Главное задаёшь вопрос почему ни черта не работает — а в ответ получаешь ссылку на «замечание к примечанию»… всё ж просто — бери и работай… только прочитай вначале всё от корки до корки.
edo1h
Обратная сторона: "инструменты старой школы" подразумевают ознакомление с документацией перед применением. Подразумевается, что человек будет понимать (хотя бы в общих чертах) что происходит.
"Новая школа", зачастую, — это просто набор скриншотов "некст/некст/готово". И даже на хабре (и даже в статьях про unix/linux) это в полный рост, куча статей вроде "сегодня мы настроим XXX. запишем YYY в этот файл, запустим ZZZ — готово". Такой недоделанный плейбук ансибла.
У вас есть хорошие примеры "новой школы"?
yarick123
У меня такое видение проблемы. Если скрипт генерирует несколько целей, и важно этот факт отслеживать в ходе сборки, то можно поступить так. (Я поступал).
Выделяем «главный порождаемый файл», скажем, .h, либо порождаем искусственный touch-файл в начале скрипта, скажем, .hcc42 (естественно, при ошибке трём). Собственно правило, которое и дёргает этот скрипт и есть единственное правило для главного порождаемого файла. Все остальные генерируемые файлы (.cc в вашем случае) называем «второстепенными». Для них ставим зависимость от главного порождаемого файла. В команде генерации [каждого] второстепенного файла вываливаемся с ошибкой, если он [второстепенный файл] старше главного. Больше ничего для второстепенных файлов не делаем.
khim
Собственно все ваши пляски с бубнами описаны в документации.
А правила-шаблоны, как раз, умеют всё, что нужно «из коробки» — там этих проблем вообще нет.В GNU make как раз этого не нужно. Это нужно для BSD make или для make на каком-нибудь HP-UX'е… вы реально часто свою программу на HP-UX'е собираете? Вам можно только посочувствовать…
yarick123
Да нет, это было некоторое количество лет назад, внезапно… только под windows :) Так что некоторые детали подзабыл.
yarick123
.
Griboks
Теперь напрашивается следующий вопрос: автоматизация конфигурирования make-файла.
fougasse
Уже придумали CMake.
ilammy
А до него Autotools, а после него Meson и Ninja.
berez
Ninja вообще не для людей. Это скорее обрезанный по самые уши make, у которого по умолчанию сборка идет в несколько потоков.
khim
Там главная фишка не в том, что сборка в несколько потоков (Make тоже так умеет). Там дело в том, что если вы вы засунете в Make конфиг-файл на гиг, то только на то, чтобы его разобрать — Make потратит не одну минуту. А ninja — за пару секунд разберётся.
И не надо думать, что я, это, чуток переборщил с размерами: Android, к примеру, имеет примерно 150 мегабайт .mk-файлов, которые превращаются в .ninja объёмом в полтора гигабайта (этим Kati занимается). И вот это преобразование занимает больше минуты, а ninja потом свой файл читает секунды две (если он в кеше, конечно).
fougasse
Ну, никто же не заставлял делать make на 150 мегабайт.
У меня есть подозрения, что минута или пару секунд на чтение погоды никакой не делают, глобально.
pdima
Обычно делают, если меняется один файл и пересобирается тест, с Makefile 1 минута на make, + 3 с на сборку, с nunja — 1 секунда на ninja + 3 с на сборку.
fougasse
Один make файл или исходник?
Если исходник — очень странно там тогда написаны скрипты.
Я, конечно, на чуть более меньшем масштабе работаю с make файлами(которые генерирует CMake, а не самописный), но и при миллионах строк плюсового кода оверхед от make при изменении в файлах — минимален.
Так что, не всё, что гугл делает является best practice и с андроидом, похоже, как раз это и доказывает.
khim
Если у вас в проекте сто тысяч файлов и могут быть созданы миллионы промежуточных объектов (потенциально — это не значит, что каждый билд будет их создавать… какие-то могут и ненужными оказаться), то вам приходится либо из make запускать make (практика, признанная порочной ешё в прошлом веке), либо make придётся вот всё это загрузить и «понять» — и делать это придётся при каждом запуске.
С андроидом уже всё хорошо: от чистого Make там давно отказались, сейчас .mk файлы преобразуются в ninja формат и если ни один из них не менялся — этап преобразования из .mk файлов в .ninja пропускается.
Так что минута и больше парсинга случается только тогда, когда сами .mk файлы приходится менять.
Размер-таки имеет значение. Можете скачать ранные исходники DOS и убедиться — там даже и без Make обошлись. И без командных файлов. В поздних версиях DOS… там уже командные файлы…
А для проектов масштаба Android или Windows… уже и Make неудобным становится… кстати CMake «отваливается» раньше — потому что он довольно-таки неэффективные Makefile генерит (хотя он может уже генерить напрямую ninja и, наверное, на сегодня это лучший вариант… но когда Android начинали делать ninja ещё не было).
vilgeforce
Открываешь Makefile, а там почти тот же bash-скрипт, но сложнее и непонятнее…
OnYourLips
make — крайне негибкий инструмент с торчащими изо всех щелей граблями и отвратительной читаемостью. Обычный скрипт решает типичные задачи сборки лучше, поиск измененных зависимостей добавляется совсем просто.
Вместо make я рекомендую начать использовать таск-раннер, например rake, а в случае активной работы с параметрами и вовсе на самостоятельные скрипты.
iig
"Обычный скрипт решает типичные задачи сборки лучше"
Типичные задачи как раз проще делать готовыми инструментами, make вполне годен. Да и альтернативных систем сборки чуть больше чем 100500, есть на любой вкус. Хотел бы я глянуть на тот скрипт, который лучше ;)
khim
Всё зависит от масштабов, на самом деле. Когда у вас 10 файлов в проекте, то любая система сборки отлично справляется и Make — не исключение… А вот когда из становится 100, 1000, 10000, 100000… вот тут-то и появляются проблемы.
iig
На таких масштабах, где make не справляется, я бы посмотрел на тот обычный скрипт ;)
fougasse
А поддержки make файлы в сложных проектах не требуют?
По собственному опыту — надо переходить сразу на что-то еще более высокоуровневое.
Неплохо подходит CMake с небольшой обвязкой на питоне.
Он прекрасно генерирует и make, и те же студийные проекты(если такая необходимость есть).
А копаться и саппортить сборку на самописных make-файлах в сложных проектах — лучше оставить храбрым.
MooNDeaR
Я два года работал над большой кодовой базой полностью построенной на голых makefile. Никому не посоветую :)
yarick123
Make-файлы make-файлам рознь. Какими напишешь — такими и будут. Долгое время — больше пяти лет — жили с системой сборки развесистого c++ проекта, построенной на базе gnu make. Всё было понятно, лаконично, быстро.
Потом перешёл на другую работу, поэтому, как эта система сборки развивалась дальше — не знаю.
MooNDeaR
Ну, оно работало. В целом были шаблонные человекочитаемые файлы, с десяток изящных костылей, упрощающих внедрение нового кода. В целом, все было неплохо, но make в мире сборочных систем — это почти ассемблер в мире программирования: оч круто если знаешь, но лучше выучи CMake)
edo1h
linux kernel и buildroot/openwrt сделаны же на make, недостаточно сложные проекты?
fougasse
Есть и на autoconf проекты, и на шелл скриптах, никто не спорит.
Но, по опыту, квалификация для написания качественного make нужна гораздо выше, чем того же CMake.
staticmain
Мы первое время для с-проектов сидели на .pro, затем достаточно ощутимый период времени на самописных bash скриптах с основной фичей — автогенерацией library header по исходному коду, которое всегда пересобирало весь код, сейчас перелезли на самописное решение на c, которое автоматически детектит какие файлы поменялись, раскручивает весь стек зависимостей и пересобирает только те библиотеки и проекты, которые реально надо пересобирать. Параллельно говорит bamboo, какие артефакты надо будет забрать
iig
То есть вы сделали ещё одну программу, которая умеет make и make install :)
NeoCode
Я бы предпочел чтобы были не make и не bash-скрипты, а декларативный файл проекта, формат которого является частью стандарта языка программирования. Причем формат должен быть по возможности простым, прозрачным и человекочитаемым.
Почему? Потому что проект нужен не только для сборки, но и например для загрузки в среду разработки. Хорошо когда все эти функции совмещены в одном файле и не нужны никакие промежуточные генерации. Не говоря уже о такой странной вещи, как «конфигурирование» (cmake и прочие), которое само по себе является грандиозным костылем у языка с полным отсутствием модульности. Модульность — это ведь не только замена древних инклудов, но и интеграция модулей-библиотек в среду/окружение разработки.
make слишком низкоуровневый, слишком явно заточенный под сборку, и в нем слишком много от скриптов. А в идеале это должен быть просто список файлов исходников (возможно с какими-то атрибутами) и информация о проекте в целом. Формат vcxproj например немного ближе к идеалу, но он очень перегружен и в нем слишком много костылей и Microsoft-специфичных вещей.
fougasse
gradle?
lorc
Как насчёт задач где часть файлов генерируется на лету? Я ковырялся в системах сборки Linux kernel, xen, op-tee. Везде часть кода генерируется на основе каких-то данных. Везде нужно два-три прохода линковщика чтобы сгенерировать список symbols, который будет доступен из самого кода. Иногда нужно вызывать bison или flex, иногда — самописный скрипт, который сгенерирует код.
NeoCode
Я думал об этом. Все достаточно просто решается.
Во-первых, в файле проекта просто может быть указано что файл генерируемый — соответствующим атрибутом и даже можно указать номер прохода и прочую метаинформацию.
Во-вторых, в файле проекта не обязательно указывать конкретные файлы. Можно придумать указание папки с файлами — и тогда все файлы в указанной папке будут включаться в проект.
Вариантов много. Главное — чтобы был древовидный структурированный декларативный формат, а не скрипт. Скрипты — это частный случай кодогенерации и в особых случаях должны указываться отдельно. Наверное и в IDE такие файлы должны отображаться особым образом.
lorc
Так Makefile — это и не скрипт. Он декларативным образом описывает как собрать заданную цель.
Что до генерируемых файлов — то они обычно генерируются на основе других файлов. То есть их нужно перегенерировать при изменении исходного файла — появляется потребность в описании зависимостей. Т.е. опять приходим к make — декларативно описываем зависимости, получаем результат.
khim
Чтобы достичь счастья и получить полностью декларативное описание нужно её тоже на что-то заменить… скажем на Blueprint… но тогда у вас от Make не останется ничего!
lorc
Ну полнота по Тьюрингу вылазит в любой более-менее мощной системе. Если уж CSS является Тьюринг-полным…
А вместе с полнотой по Тьюрингу мы получаем и проблему остановки. Так что да, единственный способ узнать что же делает Makefile — исполнить его.
GNU Make стал таким огромным и сложным потому что на него возложили не свойственные ему задачи по конфигурации собираемого приложения. Сборка какой-нибудь несложной прошивки легко описывается самым примитивным Makefile. Его легко читать и легко писать. Но потом нам захочется иметь несколько сборок — с дебагом и без, под этот камень и под тот, с таким набором фич и с другим. Вместо того, чтобы использовать какой-нибудь внешний инструмент, мы начинаем лепить это в Makefile… Ну и дальше вы знаете.
В этом плане ninja конечно лучше. Она достаточно антигуманна, чтобы писать .ninja файлы руками. Это приводит к совершенно правильному желанию генерировать эти файлы на основе какой-то более высокоуровневой спецификации.
slovak
А если в проекте используется более одного языка программирования? Под Ваши требования подходит CMake, но он тоже тот еще монстр.
Andronas
Ant? Но он заточен для java хотя и для других языков наверно может
gotch
Честно говоря, ожидал гораздо более длинную статью, которая заканчивается такими словами:
hakain Автор
А зачем тратить как свое, так и чужое время? Главное поднять вопрос и попытаться кратко и наглядно ответить.
gotch
Если вы имели в виду вот этот комментарий
https://habr.com/ru/post/477656/comments/?mobile=no#comment_20975760
то трудно не согласиться.
Cerberuser
Всё зависит от цели статьи, на самом деле. Можно писать с целью кратко и наглядно ответить, а можно — с целью детально разобраться и дать разобраться другим. Скажу честно, будь у меня в запасе несколько свободных дней, я бы, пожалуй, сказал "hold my beer" и накатал ответ с этим самым "огромным, но красивым скриптом" — именно по принципу "сделай сам, чтобы понять".
klvov
TL;DR; make нужен затем, что в нем реализован алгоритм топологической сортировки, что позволяет ему принимать на вход зависимости между файлами исходников, и выдавать на выход порядок, в котором их надо компилировать.
alan008
Рискую словить минусов, но все-таки в 2019 году все эти make, скрипты и пр выглядит так же архаично, как и редактор типа vim. Считаю, что вести разработку, сборку и отладку проектов гораздо удобнее в нормальных IDE, включающих в себя отладчик, редактор кода с инструментами рефакторинга, систему сборки, профилировщик и кучу других полезных инструментов, а главное всё это с нормальным графическим пользовательским интерфейсом, т. е. когда сделано для людей, а не для роботов. Примерами могут служить PyCharm, Android Studio, Visual Studio, IDEA, Eclipse, Embarcadero RAD Studio.
igorp1024
Минусить — дурное дело, а вот контрагументировать — пожалуйста! Возражу насчёт вести сборку. Дело в том, что пока проект живёт в пределах ноутбука, можно собирать и с помощью IDE. А когда над ним трудятся несколько человек (а ещё и если команда распределённая), то без CI-сервера уже не обойтись. И никакого IDE там нет и быть не может. Дальше. Если сборка идёт скриптом, то обеспечивается воспроизводимость результата сборки. Т.е., если сборщик (make) собрал и получил нужный результат, то как локальную IDE ни настраивай, результат сборки не испортишь и у каждого (и на сервере) он будет одинаковым.
RoadTrain
Ну в случае VS за сборку отвечает отдельный инструмент — MSBuild, соответственно на сборочные агенты ставится Build Tools, а не полноценная IDE. Хотя никто не запрещает ставить и студию. На счёт других сред разработки не в курсе.
igorp1024
Наверное всё так и есть, не спорю. Но автор коммента просто сделал акцент на GUI и удобстве для пользователя, хотя упомянутая задача в промышленных масштабах решается исключительно с помощью автоматизированных средств.
iig
Как только ваш проект станет немного сложнее чем helloworld, ему понадобится система сборки.
littorio
Ну начина-а-ается. А то, что чуть ли не все перечисленные имеют vim-режим вас не смущает? Или последняя волна LanguageServer'ов, которые как раз и рассчитаны, во многом, на работу с вимом и другими продвинутыми редакторами?
firk
bash-скриптами и правда лучше не обходиться, bash это интерактивный шелл для линукса (в других *nix — обычно не баш), а скрипты на нём писать это либо только для своего личного использования, либо плохой тон. Особенно если скрипт с расширением .sh как у вас, а внутри #!/bin/bash
А вот это очень плохо и портит первоначальную идею make — утилиты которая по человекопонятным описаниям сделает всё что нужно, то что скриптом было бы сложно и нечитабельно. Если уж генерировать Makefile то можно сразу шелл-скрипт генерировать — и то и то уже нечитабельно. Все эти autotools/cmake и им подобное — гадость.
x67
При установке — скорее всего незачем, там могла быть и обычная простыня из вызовов gcc одного за другим — ведь исходники никто после компиляции менять и перекомпилировать не собирается а скорее всего вообще удалят. А вот для модели "обновить исходники через VCS — перекомпилировать то что изменилось — поставить", так сказать инкрементальные апдейты версий (которую почти никто не использует) было бы полезно. Ну и разработчикам конечно крайне полезно после мелкой правки не ждать полчаса пересборку всего.
technic93
Статья опоздала лет на десять минимум. Во первых сейчас с каждым мейнстрим языком идёт своя система сборки. Во вторых мейк довольно стремная штука с макро подобным синтаксисом странными правилами про перенос строк и табуляции. Т.е если надо что то программировать, т.е. нужна какая то логика при конфигурации приложения то лучше взять другой язык, и использовать все плюсы нормального кода. Единственно что мейк делает хорошо это относительно быстро парсит дерево зависимостей и вычесляет порядок сборки, но ninja говорят делает это быстрее. Хотя для любителей скобочек там завезли guile как сторонний язык.
Arris
Использовать make только для сборки бинарников — это, ну… типичный подход сишного программиста, который ничего не видел за пределами gcc [ирония]
На одном из проектов у нас makefile используется как для примитивного
make build,make test,make install, так и для нестандартных:make sync_db,make prepare_environmentАх да, это веб-проект.
А еще я встречал развесистый мейк-файл для управления докером:
make build— стартует сборку докер-контейнера, внутрь которого заворачивается сайт, который где-то тут же.make start— стартует докер-контейнер, собранный ранееmake stop,make clean,make destroyи так далее.Очень удобно, как по мне, главное помнить несколько неочевидных вещей (в частности — каждая строчка в сценарии — отдельная команда в отдельном процессе шелла)
da411d
Теперь понял зачем это всё. Очень интересно. Спасибо!