
Когда люди вводят в поиске Яндекса название автомастерской, клиники или магазина, то хотят найти о них информацию. Например, график работы или номер телефона. От точности и актуальности этих данных зависит, решит человек свою проблему быстро или потеряет время и нервы.
Меня зовут Александр, и я представляю команду Геопоиска и Яндекс.Справочника, данными которого пользуются более 46 млн человек в месяц. Сегодня я коротко расскажу о том, как нам удалось сократить время обновления данных в поиске Яндекса с нескольких дней до нескольких часов, порой — до минут. А ещё вы узнаете, кто такой Рикардо Милос и какие проблемы он нам доставил.
Справочник — это база данных об организациях. Любая компания или человек может добавить туда сведения: указать адрес, часы работы, телефон и всё остальное — а Яндекс донесёт это до пользователей. Данные Справочника применяются в Поиске, Алисе, Картах, Такси, Навигаторе и даже в нашем определителе номеров, о котором мы уже рассказывали на Хабре.
И всё бы хорошо, но данные устаревают: организации закрываются, переезжают, меняют номера и всё такое. Мы и сами умеем отслеживать изменения и вносить правки, но сегодня поговорим о тех правках, которые присылают нам пользователи или компании. Для этого у нас есть формы и другие механизмы обратной связи. Так мы получаем несколько тысяч правок в сутки. Но мы не можем просто взять и опубликовать их.
В правках встречаются ошибки — из-за невнимательности или злого умысла. Последних особенно много. Одни искажают данные конкурентов и «закрывают» организацию. Другие, обычные вандалы, добавляют мат и прочие несуразности в названия и описания компаний.

Значит, если публиковать правки как есть, пользователи будут страдать. Поэтому мы всё проверяем. Операторы колл-центров звонят в организации и уточняют изменения. Толокеры доходят до компаний и сверяют данные «вживую». Но такие методы недостаточно быстрые, а поток правок большой. Поэтому мы придумали ещё и робота.
Мы используем автоматический классификатор правок — Автомодератор. Это машина, в основе которой лежит наша технология CatBoost. Она обучена на примерах хороших и плохих правок. К счастью, таких данных у нас с запасом хватает.
Когда поступает правка, Автомодератор учитывает несколько десятков факторов (например, историю предыдущих правок пользователя) и решает, одобрить правку, отклонить её или отправить на перепроверку человеку. Автомодератор может свериться с базой Справочника и убедиться, что в нём не пытаются создать дубликат, или заглянуть на сайт организации в поисках новых сведений, или даже позвонить в организацию, представиться Снежаной и уточнить изменения.
Один пример. В 2018 году в картографических сервисах и справочниках началась волна «переименований» школ, памятников и прочих организаций: на картах им присваивали имя Рикардо Милоса (на TJ есть статья об этом флешмобе). Так против своей воли мы познакомились с популярным в то время мемом о бразильском стриптизёре (не то чтобы мы этого хотели, но кто нас спрашивал). И именно комбинация Автомодератора и других механизмов проверки помогла нам отстоять истинные наименования.
Итак, автоматический классификатор позволил сократить время обновления данных. Но на этом мы не остановились. Даже с учётом помощи Автомодератора правки могли доходить до пользователей сервисов несколько дней. Это долго. Чтобы сократить это время, пришлось решить две технологические задачки.
Раньше Автомодератор выглядел как батч-процесс, он запускался по расписанию и требовал больших ресурсов для локальных вычислений (работа с таблицами на десятки миллионов записей). Мы это изменили.
Теперь это сервис, в который в реалтайме поступает правка и информация об её отправителе. Затем Автомодератор вычисляет факторы и выносит вердикт. Раньше вердикты на заявки мы могли ждать часы. Теперь — минуты.
Но это не значит, что изменения дойдут до пользователя за минуты. И здесь нас ждала вторая задачка.
Изменение попадает в базу Справочника, но для «прорастания» в сервис нужно время. Например, Поиск должен обновить поисковый индекс, чтобы учесть изменения из Справочника. Чтобы обойти это, разработали контур хранения состояний объектов. Проще говоря, теперь заменить номер телефона в объектном ответе Поиска можно и без перестроения поискового индекса. Теперь Поиск при построении выдачи знает, какие объекты устарели, и может подтянуть более свежую информацию. Конечно, ещё остаются ситуации, когда изменение данных влияет на ранжирование организации, но тут без перестроения индекса уже никак.
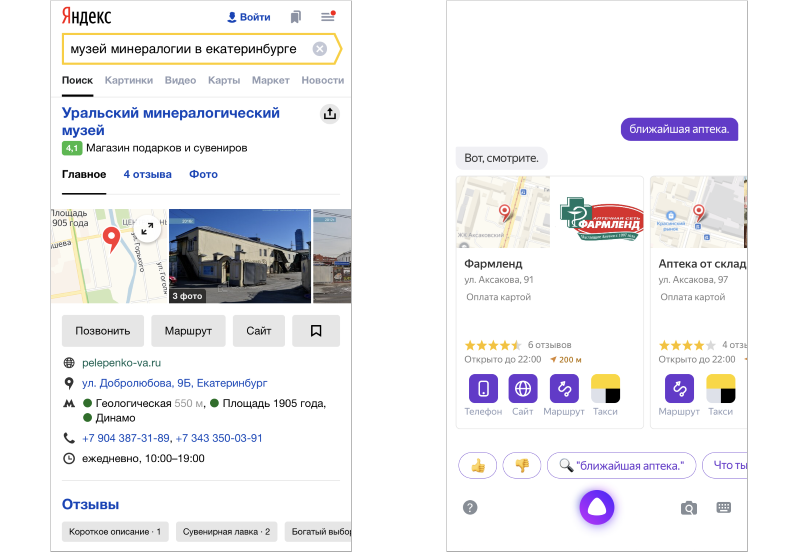
Итак, после доработок и внедрений нам удалось сократить среднее время обновления данных об организациях в сервисах Яндекса с нескольких дней до часов, а иногда — до минут. Хочется верить, что вы это заметили.
Сегодня я уместил достаточно длинную историю работы в короткий обзорный пост. Расскажите, о каких сторонах или решениях вы бы хотели прочитать более детально в будущем. Будем рады отзывам и обращениям, продолжим работать над Справочником и рассказывать о его новостях читателям Хабра.



Sabbaot
Хочется иметь каталог организаций (а не поиск) и уже с ним делать выборки. Есть ощущение, что неправильный поиск может не выдать все организации. При поиске (яндекс) специфичного изделия часто нельзя найти производителя, а только перекупщиков. Нужная плита лежала на заводе, а продавали ее через организации по всей России с наценкой в 20-25%.
Я бы хотел видеть список организаций, допустим, по классификации ОКВЭД/ОКПД2, а еще лучше — сразу по нескольким, хоть по PACS.
Пример:
Ну кто в здравом уме будет смотреть все эти 5 млн. Первым делом найдется какой-нибудь список этих заводов, в котором часть контактов будут не актуальны. Другое дело когда есть конечный список заводов, которые льют определенную марку сплава. На практике приходится обзванивать, делать официальные запросы.