

Привет, Хабр. Меня зовут Саша, в прошлый раз я рассказывал сообществу про поиск организаций в Яндексе. В этот раз мы вновь поговорим про поиск, но уже совершенно другого рода. Сегодня расскажем про «Поиск по архивам». Этот проект вырос из моего личного интереса к истокам семьи, но в итоге (хочется верить!) поможет тысячам других таких же пользователей чуть больше узнать о своих корнях.
Генеалогическое исследование — очень трудоёмкий процесс. Информация о родственниках разбросана по разным архивам, запросы на получение данных могут обрабатываться долго, а доступ даже в открытые архивы ограничен. Несмотря на то что оцифровка архивных документов ведётся уже более десяти лет, по ним не так-то просто искать — придётся отсматривать вручную множество сканов в надежде найти фамилию предка.
Чтобы упростить этот процесс, мы научились превращать в текст сканы архивных документов. Основная сложность этой задачки заключалась в том, что текст в архивах написан от руки. Машинописный текст всё-таки создан по предсказуемым правилам: автор использует набор уже известных шрифтов. А рукописный текст уникальный, потому что каждый человек пишет по-своему. Кроме того, архивные документы написаны не просто от руки, но и на дореволюционном русском языке, который существенно отличается от современного.
Решению этой задачи мы и посвятим историю. А поможет мне с ней Таня @miryable из команды, которая уже много лет развивает в Яндексе технологию оптического распознавания символов (OCR).
С чего всё началось
Около двух лет я занимался поиском информации об истории своей семьи. За это время я не только смог найти данные о предках вплоть до второй половины XVII века, но и успел разочароваться в самом процессе «раскопок». Найти подходящий архив уже проблема. Для этого нужно или иметь профильное образование по архивному делу, или пообщаться с историками, которые подскажут направление.
Получить документы из архива тоже не всегда просто. Если у архива нет электронного доступа, то нужно записаться, приехать, получить какую-то небольшую порцию книг и отсмотреть их прямо на месте. У некоторых архивов есть электронный доступ, но их вычислительные ресурсы и ширина канала связи часто ограничены, что сказывается на скорости загрузки таких сканов.
Неудивительно, что в какой-то момент родилась мысль упростить это дело с помощью наших технологий. Пришёл в команду, которая отвечает за OCR в Яндексе. Коллеги поддержали идею. Ну а дальше мы собрали на коленке прототип, показали его руководителям, получили благословение и отправились делать.
Подключаем архивы
Мы договорились с несколькими архивами, что возьмём их материалы для обучения нейросетей. Нас интересовали документы, которые связаны с историей семьи, другими словами — те, в которых могла содержаться генеалогическая информация:
Метрические книги — документы для актовых записей о рождении, браке или смерти в период с начала XVIII века по 1918 год.
Ревизские сказки — результаты проведения подушных переписей населения Российской империи в начале XVIII — 2-й половине XIX веков.
Исповедные ведомости — ежегодный отчёт по каждому приходу православной церкви в Российской Империи в XVIII — начале XX веков.
Сейчас мы работаем с документами из архива города Москвы, архивами Оренбургской и Новгородской областей. Надеемся, что к ним скоро присоединятся архивы из других регионов.
Разметка страниц
Модель для распознавания печатного текста можно обучить на синтетических данных, сгенерировав миллионы изображений. Однако для рукописного текста такой сценарий не работает: он более вариативен, искусственно промоделировать его невозможно.
Исторические тексты очень сложно читать, поэтому мы пригласили экспертов по работе с архивными документами. Они помогли расшифровывать тексты и разметить сканы. Для обучения модели нам нужно было выделить многоугольником каждую строку, ввести её текстовую расшифровку, а также сгруппировать все строки в смысловые блоки. Блоки нужны, в том числе и для того, чтобы текст из разных колонок не перемешивался, а получался связным.
На этом этапе было важно определить единое понятие «смыслового блока», потому что количество краевых случаев было просто безграничным. Порой на одной картинке получалось до 300 смысловых блоков, и ведь это даже не строки, которых ещё больше! А для каждой картинки из обучения нужно было разметить абсолютно все строки и блоки, чтобы не путать нейросеть неразмеченными текстами.

Во время работы было место интересным открытиям и наблюдениям. Особенно наши расшифровщики и расшифровщицы обращали внимание на имена. Иногда можно было встретить что-то необычное: например, однажды они нашли Фиону, а до этого — Елпидофора.
В итоге мы получили первую обучающую выборку для нейросети из 2000 рукописных документов.
Работы над моделью автоматической расшифровки
Дальше началось самое интересное. Нам необходимо было сделать систему, способную автоматически расшифровывать старые документы.
Для рукописного текста из-за разнообразия почерков необходимо более глубокое знание о языковой модели. Если для печатных тестов возможно базовое распознавание с минимальными знаниями о языковой модели, то в случае рукописного текста зачастую сложно даже примерно понять, какое слово написано. Особенно без знания языка конкретного времени.
Ещё один вызов, с которым нам предстоит работать: одно и то же написание у разных писарей может означать разные буквы. Из-за этого нам необходимо учитывать глобальный контекст всего документа для распознавания каждого отдельного слова. Иногда, чтобы разобрать то или иное слово, нужно посмотреть, как у конкретного писаря выглядит определённая буква в других словах.
В Яндексе уже была своя технология распознавания текста, и первым делом мы, конечно же, решили начать с того, чтобы адаптировать ее под новую задачу. Тут можно выделить три крупных этапа: детекция строк, расшифровка отдельной строки и группировка полученных строк в смысловые блоки. Расскажем о них подробнее.
Детекция строк
Первый этап в распознавании документа — это детекция местоположения каждой отдельной строки. В отличие от классических задач Object Detection, где нужно найти на фотографии котика, собачку или припаркованные автомобили, строки текста бывают очень вариативными по соотношению сторон: может быть длинная строка на два разворота книги, а может быть одиночная цифра как номер страницы. Они также могут быть одновременно как горизонтальными, так и вертикальными на одной странице: например, в названии колонки.
, строки шириной в две страницы и одиночные цифры сверху")
Из-за таких особенностей сильно ограничиваются возможности классических подходов к детекции. Как правило, они предсказывают уточнение позиций предопределённого набора «якорных прямоугольников». Но из-за такой вариативной структуры старого документа их было бы необычайно много.
Альтернативный подход — решать задачу сегментации. То есть предсказывать для каждого пикселя на изображении, относится ли он к тексту или нет, а потом брать компонент, состоящий из текста, и считать его строкой. Но такой вариант не подойдёт по двум причинам:
для рукописных архивных данных из-за различных завитушек отдельные строки очень часто пересекаются;
недостаточно просто предсказать, является ли кусок текстом или нет, необходимо ещё объединить его в строку, а делать какую-то ручную постобработку всегда хуже, чем обучаемую.


В своём решении мы опирались на статью Character Region Awareness for Text Detection. Для каждого пикселя изображения мы предсказываем, является ли он текстом. Причём эти предсказания не бинарные, а Gaussian heatmap относительно центра символа: чем ближе к центру, тем выше должно быть предсказываемое значение, чтобы рядом стоящие строки не смешивались. Также мы предсказываем карту связей между символами в строке, что позволяет уйти от ручного постпроцессинга при склейке.
Для начала мы просто попробовали нашу версию детекции, обученную на печатных данных. К нашему удивлению, она вполне себе заработала и на рукописных. Пусть и с рядом недочётов: находилось много шума, разрывались строки. Но детекция училась на данных, в котором рукописного текста не было в принципе. То, что она заработала, говорит о том, что наша технология уже применима к очень широкому кругу задач.
Далее мы обучили модель на тех данных, которые мы получили из расшифровки рукописных документов. Детекция стала чище и точнее.


После этого нужно было решить ещё одну проблему. Как я говорил, у архивных документов сложная структура: они могут быть записаны в виде таблиц или колонок, а ещё фрагменты разных текстов могут плотно стоять друг к другу. Поэтому очень часто детекция распознавала как одну строку то, что было написано в разных блоках.

Эту задачу мы решили на уровне модели группировки в абзацы — подробнее расскажу после раздела о расшифровке строк. На том этапе мы смирились с этой трудностью непосредственно для модели детекции строк и занялись решением другой проблемы — просветами текста на обороте страницы.
На сканах часто был виден текст, который просвечивался с другой стороны: из-за подсветки сканера или пропечатавшихся чернил. А наш детектор оказался очень кропотливым и считал, что это текст, который он тоже должен находить. Само собой, такое распознавание было ложным, а из-за того, что оно подмешивалось к реальному распознаванию, в итоге мы получали не всегда связанный текст. Особенно остро эта проблема была видна на машинописных архивах, но и нередко встречалась на рукописных.

Мы отправили примеры с просветами на дополнительную разметку непосредственно этой детекции. После обучения на новых данных модель стала показывать более чистый результат. Однако просвеченный текст всё ещё появляется в результатах — это то, что нам предстоит доработать.
Расшифровка строк
Следующий, и, пожалуй, самый сложный шаг — обучить модель расшифровывать то, что содержит вырезанная детектором строка. То есть распознать последовательность символов из последовательности пикселей строки, вырезанной в той области, которую нашёл детектор.
На этом этапе наши стандартные модели расшифровки не подошли. Во-первых, обученные на машинописных текстах модели почти никак не работают на рукописных данных. Во-вторых, имеют место и особенности языка тех времён.
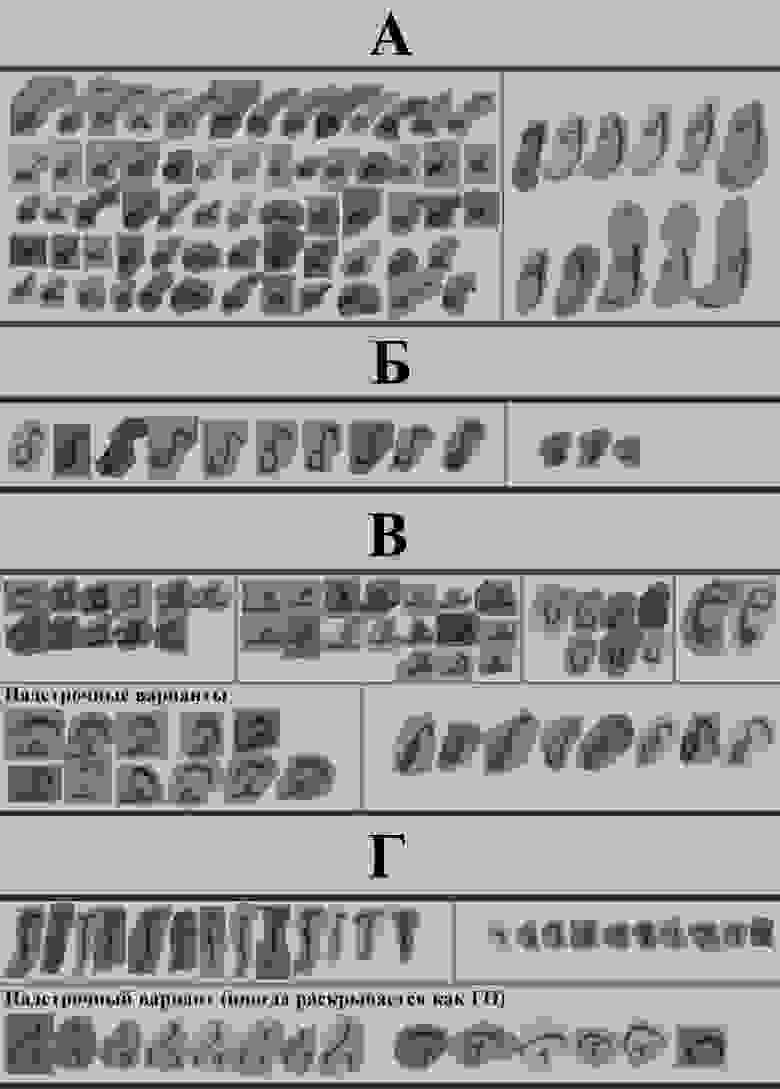
В архивах часто встречаются документы, которые были составлены на церковнославянском языке. В нём были символы, которые сейчас мы не используем: например, буквы ѣ (ять), ѳ (фита), ѵ (ижица), юс большой и малый (Ѫ, Ѧ). Чтобы пользователь мог найти информацию в документах, нужно научить модель распознавать эти и другие буквы. И чем больше мы найдём разных вариантов написания этих символов, тем проще будет нашей нейросети.

К тому же мы заметили, что часто в документах некоторые слова, например, «месяц» или «сын», сокращали и писали через титло — небольшую волнистую или зигзагообразную линию. Было важно, чтобы модель могла распознавать этот символ, а не считать его за пыль или случайную черту.
Ещё одна интересная особенность — выносные буквы. Они встречаются в документах XV — 1-й половины XVIII века. Это ещё один вариант сокращения слов, когда над строкой появлялась согласная. Этот момент тоже нужно учитывать при обучении модели.

Решать задачу sequence-to-sequence распознавания можно несколькими способами:
Для каждого фрейма (в конкретной позиции по горизонтали) предсказывать, какой символ в нём изображён, например, с помощью свёрточной нейронной сети, и далее использовать CTC-loss. В этом случае для изображения, где написано «Марья», нейросеть предскажет, «МММ__аа_ррр___ььь_яя». Склеив одинаковые предсказания в соседних фреймах мы получим правильное предсказание.
Использовать подходы, в которых нейросеть сама предсказывает последовательность символов, не привязываясь к их геометрической позиции (такие как, например, RNN или TRANSFORMER-based).
Из-за описанных выше особенностей, таких как титло и выносные буквы, первый подход не работал, потому что в одной позиции по горизонтали может быть сразу несколько символов. Это подтвердилось и нашими экспериментами, поэтому в результате мы использовали второй подход, а именно — RNN based decoder with attention.
Для распознавания выносных букв мы также подавали на вход распознаванию не чёткую область детекции, а немного расширенный вариант. За счёт этого сеть получала информацию о контексте.
Далее мы провели ряд экспериментов и поняли, что качество получаемой модели сильно зависит от объёма данных, на которых она учится. Есть два варианта, как решить проблему нехватки данных: предобучить модель на синтетических данных или применить различные способы аугментации.
Аугментация, или генерирование новых данных на основе имеющихся, позволяет довольно просто и дешево решить часть проблем с обучающей выборкой подручными способами. Мы попробовали по-разному вырезать одни и те же строки, чтобы они немного отличались: например, исходя из того, как их нашел детектор или как наши коллеги разметили страницу.
Также мы пробовали зашумление картинок: размытость, расфокус, засветы, замену фона. Другими словами, мы пробовали хоть как-то разнообразить реальные тексты. В итоге мы получили датасет из 4 млн строк.
Расскажу ещё об одном интересном моменте. В одном из экспериментов мы обучили модель на очень небольшом количестве реальных данных. Записи в метрических книгах специфичны и однотипны, поэтому нейросеть научилась находить текст там, где его нет. Например, в каком-то шуме, или в узоре, который наш детектор строк ошибочно определил как строку текста, она могла прочитать какое-то слово или даже осмысленную строку.

Это говорит о том, что в задаче распознавания рукописного текста большой вес имеет выучиваемая языковая модель.
И тут уже никак не поможет аугментация картиночных данных, которую мы использовали. В этом случае сам текст никак не меняется — меняется только картинка, и модель не учит из этого ничего нового в части языковой модели.
Чтобы исправить ситуацию, нам пришлось досыпать в обучение модели различных текстов, чтобы улучшить языковую часть. Для этого мы использовали синтетически сгенерированные изображения с текстами того времени — в основном художественную литературу, например, «Анну Каренину». С их помощью модель узнала, что тексты — это не только метрические книги, и таким образом получила представление о том, как был устроен язык тех времён.
Группировка в абзацы
Итак, мы нашли строки и распознали их — теперь нужно объединить полученное в семантически связанные фрагменты. Это объединение поможет нам получить связную по смыслу область текста, в которой мы сможем правильно обрабатывать переносы слов между строками и корректно искать информацию по тексту документа.
Для этого мы сделали отдельную модель, которая детектирует смысловые блоки на изображении. Но как мы помним, структура текста в архивных документах очень сложная и здесь недостаточно просто выделить прямоугольник — он может содержать сразу несколько смысловых блоков. Например, информация о семье и код, который относится к чему-то ещё. При этом, как и для детекции строк, рядом стоящие абзацы могут пересекаться.
Эту задачу мы решали как Instance Segmentation, когда необходимо для каждого блока предсказать не только прямоугольник, задающий область абзаца, но также маску внутри этого прямоугольника, которая более точно описывает конкретный абзац.

Здесь одна из проблем была в том, что у входного изображения большой размер — до 10 000 пикселей по одной стороне. Обучить модель на таком разрешении было бы очень сложно, потому что обучение требовало бы огромных ресурсов GPU.
Мы уже начали думать о вариантах разбиения картинки на части, но мы рисковали потерять общий контекст целого изображения. Мы составили план серии экспериментов, чтобы заставить это всё работать. И буквально ради шутки мы подумали: а что если очень сильно ресайзить картинку до стандартного размера и попробовать запустить как есть. Оказалось, что всё заработало на очень хорошем уровне.
На данный момент мы расшифровали и открыли для поиска около 2,5 млн страниц из архивных документов. Для этого коллеги даже применили «осовременивание» текстов, чтобы, например, по запросу «Петров» можно было найти документы с «Петровъ». Конечно, у нас ещё много нерешённых задачек и работы. Но то, что мы видим сейчас, по мнению людей, работающих с архивными документами, это уже большой шаг вперёд. На расшифровку одной страницы архивного рукописного текста специалист тратит около получаса, а нашей нейросети требуется всего несколько секунд.
Хочется верить, что так мы сделаем важные генеалогические сведения доступней и поможем тем, кто зашёл в тупик в поисках информации о своих предках.
Комментарии (75)

GDragon
25.01.2023 10:46+10Спасибо вам, нужное дело делаете.
Поиск в не оцифрованных архивах это время и деньго-затратный ад и израиль.

YMA
25.01.2023 11:26+6Спасибо! Ждем остальные регионы. У меня отец просматривал вручную архивы по северным регионам, построил родословную до 1600-х годов, но на другие регионы пока не решился. А с вашим сервисом будет легче...

Didimus
25.01.2023 18:44Является ли родословная персональными данными?

PereslavlFoto
25.01.2023 19:41Судя по тому, что сведения на могильном памятнике являются ПД, значит, и родословная тоже является.
YMA
25.01.2023 20:01+1В том составе, как в сказках и ведомостях, думаю, не являются. Они не позволяют однозначно идентифицировать субъекта ПД. Надо запрос писать, однако..

develmax
25.01.2023 11:47Потыкал тексты, есть успехи, но яндекс пока не научился распознавать тексты, результат близкий к обычной OCR. Вот возможность увеличить в высоком разрешении - слава сканеру, это очень полезно, можно легко рассмотреть, что там реально написано. Поэтому данную систему можно пока рассматривать как вспомогательную для специалистов - много чего распознает, но связывать слова, предложения и править ошибки пока должен человек.

anazarta Автор
26.01.2023 12:17Мы уже работаем над улучшение качества распознавания. Как можно заменить, текст в старых документах структурировали, часто писали иначе, чем сейчас в плане орфографии (переноса строк). Это все создает дополнительные сложности. Я думаю в обозримом будущем качество моделей, которые применяются в сервисе будет расти.

okolobaxa
25.01.2023 12:22+1А есть какой-то стандарт или стандартный формат для разметки изображения как на первой картинке? Например у меня есть фотография со списком ФИО, как мне лучше разметить на ней отдельные фамилии чтобы это был какой-то файл с мета-данными к имеющейся фотографии.
anazarta Автор
26.01.2023 12:18Мы для себя определили свой формат хранения расшифровок, потому что многое зависит от решаемой задачи. Если нужно уметь распознавать символы в строке - один формат, если надо уметь понимать структуру документа - формат конечно будет отличаться.
okolobaxa
25.01.2023 12:29+11Ваш поиск нашёл больше данных по моим предкам, чем поиск Генотека. Зачёт! Надеюсь скоро добавятся и другие архивы (Тула, Курск, Воронеж, Самара)
anazarta Автор
26.01.2023 12:19+2Мы работаем над увеличением числа архивов. Надеюсь в ближайшее время сможем обрадовать всех хорошими новостями.

Vjay
25.01.2023 15:10+4Есть малейший шанс на платный API? Лежат 250К снимков метрик по селам на границе Полтавской и Черниговской губерний, откуда мои предки. Но, официально получить такие сканы на нашем веку думаю уже не будет возможности.

Akr0n
25.01.2023 17:17Лежат у Вас или вы про госархив Украины? Тоже интересуют данные из тех мест для генеалогических изысканий.
Vjay
25.01.2023 17:41У меня, одолжил у мормонов, т.е. то же самое что доступно на FS.

BMXer_V
26.01.2023 23:48+1А можно ссылку, пожалуйста? Или хотя бы по каким ключевым словам гуглить?
UPD: похоже, я сам нашёл. Имелось в виду вот это? https://www.familysearch.org/ru/ В любом случае, спасибо за наводку!
okolobaxa
25.01.2023 17:45Присоединяюсь. Любой нормальный исследователь после пары лет поисков обрастает парой десятков гигов официально купленных в архивах или вымененных у других исследователей документов. Многое из этого никогда не появится в публичном доступе и хочется хотя бы для себя распознать.
YMA
25.01.2023 18:01+4Это бы на торренты выкладывать для сохранности... Лежит же там либрусек 2-терабайтный, я бы с удовольствием сидировал еще и по сканам исторических документов.
PereslavlFoto
25.01.2023 19:42+1Но что же мешает помещать это в публичном доступе?
okolobaxa
26.01.2023 10:07Жадность и индивидуальные договоренности. Я например не спешу выкладывать в общий доступ документ, на получение которого я потратил несколько лет и 25к рублей. Если мне кто-то напишет в личку, я конечно поменяюсь на что-нибудь ещё чего у меня нет или предложу совместно скинуться на оцифровку чего-то полезного обеим сторонам. Индивидуальные договоренности - кто-то скинул мне документ с обязательством не публиковать его публично например потому что он получен по знакомству или через "крота" или так же куплен за большие деньги.

vikarti
26.01.2023 05:28+3Купленных?
А вот такой вопрос — вот допустим такие материалы уплывут яндексу и появятся в общей базе?
Или появятся на рутрекере а яндекс их оттуда возмет.
Какие юридические последствия?
Допустим все тексты — до 1918.
Какие действующие сейчас права на содержание этих документов могут быть и у кого?
И неужели договорится никак нельзя?YMA
26.01.2023 08:57+2Права на документы уже в публичном достоянии, но вот права на их сканы - нет. Люди проделали большую работу, сканируя старые документы и имеют право на доход от предоставления доступа к сканам.
На торренты я предлагал разместить те документы, которые находятся под риском полной утраты. Документы в РФ и Украине, в частности - прилетит что-нибудь куда-нибудь и опаньки, данные, пережившие несколько столетий - будут потеряны. :(
PereslavlFoto
26.01.2023 18:29+1Сканирование не создаёт новых авторских прав. Здесь вы что-то преувеличили.
YMA
26.01.2023 19:50Фотография - создает, исполнение музыкального произведения - создает, а сканирование нет? ;)
PereslavlFoto
26.01.2023 20:05+1Если вы сфотографируете картину точно так, как она была нарисована, получится фотокопия. Авторское участие в ней нулевое, авторских прав не возникнет. То же самое будет и с фотокопией чертежа.
Исполнение музыкального произведения не создаёт копию нотного текста. Этот пример не подходит к нашему обсуждению.
Обратите внимание, что в альбомах с картинами всегда использованы фотокопии картин и указаны художники, однако нигде не указаны фотографы, делавшие эти фотокопии для издательства.YMA
27.01.2023 11:36Использование материалов сайта - Третьяковская галерея (tretyakovgallery.ru)
Использование фотографий – с указанием автора снимка, если он указан на сайте.
PereslavlFoto
27.01.2023 13:44Вы правы, когда речь идёт про фотографии.
Вы ошибаетесь, когда речь идёт про фотокопии картин. Именно поэтому в цитате и сказано, что автор снимка не всегда наличествует.YMA
27.01.2023 14:08Не соглашусь, полистал сейчас статьи на эту тему в Консультанте - в итоге авторы сходятся к тому, что только фотографии, полученные автоматическим путем без участия человека - можно считать свободными от авторских прав. И то с оговорками - снимки животных с фотоловушек тому примером.
Остальное, даже если просто снята картина - человек пришел, выбрал оптимальную точку, поставил свет, штатив, нажал на кнопку - уже имеется творчество.
Фотография как объект авторских прав (фрагмент статьи)
Статья: Использование фотографий, взятых из Интернета: правовые риски, практика, рекомендации (Гайдук В.П.) ("ИС. Авторское право и смежные права", 2022, N 6)
Фотография является объектом авторских прав (ч. 1 ст. 1259 ГК РФ). Для возникновения авторских прав на фотографию необходимо, чтобы фотография отвечала определенным критериям. Назовем их позитивные и негативные критерии. К числу позитивных критериев отнесем: наличие творческого результата и объективную форму. Негативные критерии: отсутствие в фотографии признаков, предусмотренных частями 5 и 6 ст. 1259 ГК РФ.
Фотография должна быть выражена в объективной форме (цифровая, пленочная, негатив, бумажная и т.п.), то есть таким образом, чтобы другие люди могли ее воспринимать как существующую реальность (ч. 1 ст. 1259 ГК РФ).
Фотография должна быть результатом творческого труда (статьи 1228, 1257, 1258 ГК РФ). Несмотря на то что воплощение творчества является ключевым критерием в определении того, является ли объект объектом авторских прав, Гражданский кодекс РФ не дает определения тому, что является творчеством и творческим трудом.
Не раскрывается определение творчества и творческого труда и в Постановлении Пленума Верховного Суда РФ от 23 апреля 2019 г. N 10 "О применении части четвертой Гражданского кодекса Российской Федерации" (далее - Постановление). Постановление прописывает презумпцию творческого труда в объекте авторских прав: "Пока не доказано иное, результаты интеллектуальной деятельности предполагаются созданными творческим трудом" (пункт 80 Постановления). При этом "само по себе отсутствие новизны, уникальности и (или) оригинальности результата интеллектуальной деятельности не может свидетельствовать о том, что такой результат создан не творческим трудом и, следовательно, не является объектом авторского права". Исключение критериев новизны, оригинальности и уникальности как признаков творческого результата и отсутствие легального определения творчества усложняют задачу определения объекта авторских прав в правоприменительной практике.
Для отнесения фотографии к охраняемым объектам важно понимать, что "творческий характер создания произведения не зависит от того, создано произведение автором собственноручно или с использованием технических средств. Вместе с тем результаты, созданные с помощью технических средств в отсутствие творческого характера деятельности человека (например, фото- и видеосъемка работающей в автоматическом режиме камерой видеонаблюдения, применяемой для фиксации административных правонарушений), объектами авторского права не являются" (пункт 80 Постановления).
Таким образом, применительно к фотографии можно сделать вывод, что практически любая фотография может быть признана объектом авторских прав, если только она не была сделана в автоматическом режиме фотосъемки. При этом качество фотографии, ее художественная, эстетическая, смысловая ценность значения не имеют, поскольку "объектами авторских прав являются произведения науки, литературы и искусства независимо от достоинств и назначения произведения, а также от способа его выражения" (ч. 1 ст. 1259 ГК РФ).
Из этого следует, что подавляющее большинство фотографий, которые представлены в Интернете, являются объектами авторских прав. Поэтому правомерное использование фотографий возможно только при соблюдении авторских прав. Они предполагают законную монополию правообладателя на использование фотографии. Третьи лица могут использовать фотографии только с письменного (или приравненного к письменному) разрешения. При этом важно понимать следующие правовые принципы. Первый: "Отсутствие запрета не считается согласием (разрешением)" (ч. 1 ст. 1229 ГК РФ). Применительно к фотографии это означает, что если на фотографии либо на сайте, аккаунте, где размещена фотография, нет запретов на ее копирование, скачивание, скринирование, распечатывание и совершение иных манипуляций с фотографией, то это не свидетельствует, что такие манипуляции с фотографией можно совершать.
Второй принцип: отсутствие имени автора (фотографа) и/или авторского знака / знака копирайта на фотографии или на ресурсе Интернета, где размещена фотография, не свидетельствует о том, что у фотографии нет правообладателя и ее можно свободно использовать, поскольку автор вправе опубликовывать, распространять свои произведения как с указанием имени, псевдонима, так и анонимно (ч. 1 ст. 1265 ГК РФ).
Поэтому использование фотографии, взятой из ресурсов Интернета, возможно с письменного согласия правообладателя. Исключением из этого правила являются случаи свободного использования объектов авторских прав, предусмотренные законом (статьи 1273 - 1279 ГК РФ), а также случаи, когда пользовательское соглашение сайта позволяет использовать фотографии без непосредственного согласия автора. Это так называемые стоки - сайты, где размещаются фотографии на условиях открытых лицензий При этом при использовании фотографий на этих сайтах необходимо внимательно смотреть возможности использования фотографий, в том числе для коммерческих целей. Также свободно можно использовать фотографии, перешедшие в общественное достояние, то есть срок действия исключительного права на которые истек (ст. 1282 ГК РФ).Кто является правообладателем,
автором и собственником фотографии?Вопрос очень важный, поскольку именно от этого зависит, кто может подавать претензию лицу, использовавшему фотографию. От этого также зависит выбор средств защиты.
Итак, автором фотографии является гражданин, творческим трудом которого она создана согласно статье 1257 ГК РФ.
Кто может быть автором фотографии? Таковым может быть фотограф - как профессиональный, так и любитель, обычный гражданин. Представим себе следующую ситуацию. Человек (фотолюбитель) создал композицию для снимка, придумал сюжет, выбрал место, подобрал освещение, аппаратуру, сделал себе грим, но сам себя снять не может, приглашает для этого знакомого, который по команде фотолюбителя нажимает на кнопочку фотоаппарата (или телефона; технический инструмент не важен). Кто будет автором фотографии?
Согласно статье 1228 ГК РФ "не признаются авторами результата интеллектуальной деятельности граждане, не внесшие личного творческого вклада в создание такого результата, в том числе оказавшие его автору только техническое, консультационное, организационное или материальное содействие или помощь...". Поэтому автором такого снимка будет тот, кто создал все условия для создания фотографии. А второй человек будет техническим исполнителем.
Правообладатель фотографии - это лицо, которому принадлежит исключительное (имущественное) право на фотографию (статьи 1229, 1270 ГК РФ). При этом "исключительное право на результат интеллектуальной деятельности, созданный творческим трудом, первоначально возникает у его автора. Это право может быть передано автором другому лицу по договору, а также может перейти к другим лицам по иным основаниям, установленным законом". Таким образом, первоначально исключительное право возникает у того, кто создал фотографию, а затем оно может быть передано другим лицам. Так, при проведении фотосессии по заказу автором и правообладателем прав на фотоснимки будет фотограф. Исключительное право на фотографии может перейти к заказчику фотосессии только в том случае, если это отражено в договоре с фотографом. Тогда правообладателем фотографий будет заказчик фотосессии (ст. 1288 ГК РФ, п. 1 ст. 1291 ГК РФ).
Если же проведение фотосессии является служебной обязанностью фотографа и это отражено в трудовом договоре с фотографом, то правообладателем таких фотографий будет работодатель фотографа (ч. 2 ст. 1295 ГК РФ, п. 104 Постановления), поскольку согласно статье 1295 ГК РФ под служебным произведением подразумевается произведение науки, литературы или искусства, созданное в пределах установленных для работника (автора) трудовых обязанностей. В этом случае исключительное право на фотографии заказчику может передать работодатель фотографа (ст. 1296, абз. 2 п. 1 ст. 1291 ГК РФ).
Какие права на фотографии возникают у заказчика фотографий? Ответ: авторские права у заказчика фотографий не возникают, а возникает право собственности на материальный носитель фотографий и право на изображение, являющееся личным неимущественным правом лица, изображенного на фотографии (ст. 152.1 ГК РФ).
И еще есть очень важный принцип авторского права, который я обозначила следующим образом: "Рукописи не горят". Это означает, что передача материального носителя результата интеллектуальной деятельности не влечет передачу интеллектуальных прав на этот результат интеллектуальной деятельности (ст. 1227 ГК РФ). Он имеет важное практическое значение. Если фотограф осуществил фотосессию по договору оказания услуг или договору авторского заказа и передал фотографии заказчику, не обозначив в договоре передачу исключительного права на фотографии, то весь комплекс авторских прав остался у фотографа. Это означает, что в случае попадания фотографии на различные ресурсы Интернета требования о защите авторских прав может заявить только правообладатель фотографии, то есть фотограф в приведенном примере.
Так, суд частично удовлетворил требование (снизив размер компенсации) фотографа о взыскании денежной компенсации за нарушение исключительного права, компенсации морального вреда за нарушение личных неимущественных авторских прав с ответчиков, которые использовали фотографии в рекламных целях. При этом из судебных актов следует, что ранее фотограф передал фотографии заказчику на основании договора на проведение фотосессии, в котором отсутствовала передача исключительного права на фотографии [1]. Еще один пример из практики, который отражает данный подход: в споре между администратором сайта и владельцем сайта, в котором администратор сайта размещал созданные им фотографии для своего клиента (ответчик по делу - владелец сайта) и в дальнейшем размещал их на сайте, выиграл администратор сайта, поскольку в договоре не были прописаны обязанности администратора сайта по созданию фотографий для клиента и, соответственно, не была осуществлена передача прав на фотографии клиенту администратором сайта [2].
Этот подход судебной практики отражает смысл норм интеллектуального права о том, что права на интеллектуальную собственность возникают у автора (ст. 1228 ГК РФ), только автор (правообладатель) вправе разрешать использовать авторские результаты (ст. 1229 ГК РФ), передача материального носителя не влечет передачу интеллектуальных прав на интеллектуальную собственность (ст. 1227 ГК РФ).
Гражданин, изображенный на фотографии, не обладающий авторскими правами на фотографию, может заявить только требование об удалении фотографии и компенсации морального вреда (ст. 151, ст. 152.1 ГК РФ).
У автора и правообладателя фотографий правовой инструментарий защиты гораздо больше, чем у изображенного на фотографии гражданина, о чем мы поговорим далее.
Собственником фотографий, зафиксированных на материальном носителе, будет то лицо, которому принадлежит право собственности на материальные носители фотографий. Это может быть заказчик фотосессии при получении фотографий на материальном носителе, лицо, которому отчуждено право собственности на фотографии по разным сделкам (продажа, дарение, мена и т.д.). В отношении собственников фотографий следует отметить еще одну важную норму. "При отчуждении оригинала произведения его собственником, обладающим исключительным правом на произведение, но не являющимся автором произведения, исключительное право на произведение переходит к приобретателю оригинала произведения, если договором не предусмотрено иное" (п. 1 ст. 1291 ГК РФ). Это означает, например, что если фотостудия (юрлицо или индивидуальный предприниматель) привлекает фотографа на основании трудового договора, то заказчику при передаче фотографий передается исключительное право на фотографии одновременно с фотографиями.
Подведем некоторый итог выше сказанному. Первое. Фотографии являются объектами авторских прав по умолчанию, если только они не созданы в режиме автоматической фотосъемки. Второе. Размещение фотографии без указания имени автора и/или правообладателя в Интернете не означает, что эти фотографии можно свободно использовать. Так, Определением СК по гражданским делам Верховного Суда РФ от 28.01.2020 N 5-КГ19-228 Суд отменил Апелляционное определение, которым отказано в удовлетворении требований о запрете использования фотографического произведения, взыскании компенсации за нарушение исключительного права на произведение, и направил дело на новое апелляционное рассмотрение, поскольку "сам по себе факт того, что спорная фотография в настоящее время размещена на различных информационных порталах в сети Интернет в отсутствие сведений об авторстве, не свидетельствует о том, что изображение находится в свободном доступе с возможностью копирования без согласия автора и без выплаты вознаграждения" [3].PereslavlFoto
27.01.2023 14:13Вы упираете на то, что фотограф --> творческий вклад.
При фотокопировании картины никакого творческого вклада быть не должно. Творческий труд уже совершил художник, и теперь фотограф должен не добавлять никакого творческого труда. Иначе получится не фотокопия картины, а производная работа двух авторов (художника и фотографа).
YMA
27.01.2023 14:15Вот это - творческий продукт или фотокопия? Я назову это произведение "Картина в музее" ;)
Объект авторских прав

До сего момента этого фото в Интернете не было, если что.
PereslavlFoto
27.01.2023 14:23Вы правы, это не фотокопия. Здесь картина очень серьёзно искажена, а к ней добавлено много того, что не является картиной.
okolobaxa
26.01.2023 10:34Эта тема ещё сложнее чем закон об авторских правах.
Документы в архиве лежат, каждый может прийти и их глазами посмотреть, сделать выписки. В некоторых архивах есть электронные читальные залы и можно делать тоже самое удаленно. Где-то бесплатно, где-то за деньги.
Но когда речь заходит о копиях - архив хочет денег. Можно скопировать собственным фотоаппаратом за 57р кадр, а можно воспользоваться услугами архива за 114р. Не все документы можно фотографировать самому, потому что архив решил что они "особо ценные" (все метрические книги например) и фотографировать их можно только силами архива. В одном документе может быть 1000 листов. Например список всех налогоплательщиков одного очень крупного села за 1858 год как раз 1200 листов. Посчитайте сколько стоит получить дело целиком.
Яндексу они не уплывут, Яндекс просто не станет к себе добавлять документы неизвестного происхождения. Я представляю какую огромную работу провели в Яндексе чтобы договориться с тремя доступными архивами о передаче сканов Яндексу.
Никаких прецедентов не было. Только в прошлом году был забавный инцидент, когда одна коммерческая генеалогическая компания скраулила с сайта архива все названия дел для своего поискового сервиса. Не сами дела, только их названия. Последовал поросячий визг руководства архива, угрозы убрать вс заголовки дел из публичного доступа (это значительно усложнит жизнь исследователям), пойти в суд и т.д.. В итоге полюбовно разошлись, материалы этого архива из поисковика убрали. Яндексу такие скандалы не нужны, поэтому он будет добавлять только то, что было подкреплено договорами с архивами.
Didimus
26.01.2023 10:50+3По-хорошему за скрытие архивов должна быть уголовная ответственность такая же, как и за уничтожение информации.
okolobaxa
26.01.2023 11:10+1А в чем скрытие? Приходите в читальный зал и изучайте документ глазами, делайте выписки. К сожалению закон об архивном деле не обязывает архивы предоставлять у документам удаленный доступ. А недавние изменения в законе полностью легализовали побор платы даже за фотографирование собственными средствами (раньше это было бесплатно).

diogen4212
26.01.2023 12:29+1Видимо, без чёткого закона вида «предоставлять доступ любому гражданину РФ по первому требованию с правом копирования и распространения» и нормального финансирования ничего не изменится. Большие библиотеки и архивы никогда не были дружелюбны к пользователям (помню, как сперва искал книги в бумажном каталоге, потом заполнял требование в трёх экземплярах на каждую книгу и делал копии в читальном зале за оверпрайс ). Всем нужно выживать и зарабатывать, а книги пусть дальше на полках лежат, чем меньше их трогают, тем лучше(
Akr0n
26.01.2023 11:08+2А архиву-то что от этого? Ощутимое падение доходов? Разве там директору капает ЗП с этих доходов? Так-то налогоплательщики это все содержат.
okolobaxa
26.01.2023 11:17+1У архива есть два источника финансирования - бюджет и "внебюджетные источники". Под вторым как раз понимается исполнение не социальных запросов (НЕ подтверждение стажа, наград, права собственности и т.п.), а например генеалогических запросов, платный удаленный доступ к электронному читальному залу, копирование документов. Это всё составляет приличную часть доходов архива, из которых сотрудникам к копеечным зарплатам выплачиваются премии. Ну и часть своих внебюджетных доходов архив передаёт в общак региона. В этом смысле региональный архив мало чем отличается от МУП "Банно-прачечное хозяйство", директор так же ходит на летучки к губернатору и получает план по доходам. Печально, но так это сейчас работает.
anazarta Автор
26.01.2023 12:21Перед тем, как думать в сторону платного API мы хотим научиться еще лучше распознавать документы. Это первоочередная задача для нас.




arjunarus
25.01.2023 19:03+2А есть ли (или планируется) аналогичный проект для распознавания старых медицинских карт?
anazarta Автор
26.01.2023 12:29Мы будем смотреть как наша модель работает на разных документах с разными текстами и уже от этого принимать решение. Конечно, хочется попробовать всё :) Очень уж интересная область!

SergLit
26.01.2023 16:13Не представляю, как там можно будет расшифровать медицинский подчерк.

Lapk
27.01.2023 19:43по количеству закорючек, актуальному словарю с различными наименованиями лекарств и болезней, контекст по диагнозу и прочим закорючкам в том же документе. Скорее всего, больше никак. Конечно исключая вариант "спросить врача и самому записать", это не распознавание.

bolk
25.01.2023 19:35Нужное дело делаете, жаль пока до идеала далеко — по моим фамилиям много ложноположительных срабатываний, да и интерфейс пилить и пилить ещё. Но это большой шаг вперёд, спасибо вам за это!


bak
25.01.2023 21:25+1По итогу какую точность получили (cerr, werr)? Языковую модель поверх результатов seq2seq нейронки применяете?

nehrung
25.01.2023 21:36+7Чем плодить ограниченно полезные новые опции, лучше бы вернули одну старую, чрезвычайно полезную — кнопку (или чекбокс) «Искать в найденном». Хорошо помню, как с помощью этой опции мне в несколько итераций удавалось свести развесистую поисковую выдачу из нескольких тысяч (или сотен тысяч) строк к единственному, максимально релевантному результату.
Didimus
26.01.2023 10:51+2"Искать в найденом и рекламе"
nehrung
26.01.2023 21:17А вам она зачем? Я вот приучил свои глаза не замечать рекламу.
PereslavlFoto
27.01.2023 13:50Дело в том, что если не вводить рекламу — поисковый бизнес становится невыгодным.
nehrung
27.01.2023 20:04+1Да, к владельцам этого бизнеса придётся отнестись с пониманием — им тоже надо на что-то жить. С другой стороны, лично я ненавижу пропаганду в любом виде, в т.ч. и в виде рекламы. Похвастаюсь — не могу припомнить случая, когда я хоть что-то (даже мелкую мелочь) купил с подачи рекламы.
Так что, ПМСМ, пусть бизнесмены воюют на более широком фронте — например, с адблокерами, а конкретный узкий и некритичный для бизнеса сегмент «Искать в найденном» пусть оставят в покое. Особенно с учётом того, что этого сегмента пока нет ни в одном поисковике.

inscriptor
26.01.2023 01:09Уважаемый @anazarta, а есть ли у вас табличка со скорописями 15–19 веков в более высоком (хайрезном) качестве? Если есть, приложите, пожалуйста.
anazarta Автор
26.01.2023 12:31В более высоком качестве я не встречал на просторах интернета. Можно воспользоваться поиском по Картинкам (https://yandex.ru/images) и туда просто скопировать картинку со скорописью и посмотреть похожие. Находятся очень полезные картинки с примерами.
dim-ev
26.01.2023 21:06Есть вот такие варианты. Взято отсюда: https://rodnaya-vyatka.ru/blog/11990/129773

caban
26.01.2023 06:18+1Открывает крутой просто для исследователей, например известный спортивный журналист разрешил один из споров https://t.me/stg_50/1029. Очень крутая и интересная вещь, ждём больше архивов и развития.
yo-jik
26.01.2023 09:16+1Во-первых, огромное спасибо за это замеченный проект!!! Сегодня день, когда мечты сбываются!
А во-вторых, хотелось бы уточнить, есть или подразумевается ли в будущем возможность вручную корректировать результат распознавания? Сегодня много раз встречалась ситуация, когда ты точно знаешь, что написано в документе, а программа распознает это иначе/ не корректно. Хотелось бы иметь возможность вносить корректировки для облегчения своих повторных или чужих поисков.
Ещё заинтересовал вопрос, может ли помочь распознаванию текста дополнительная информация, к примеру список с названиями губерний, уездов и т.д?!

AigizK
26.01.2023 09:28+2@anazarta как с вами можно связаться, чтоб добавить https://basharchive.ru/census/reviz/ ?

rscout13
26.01.2023 13:05Уважаемый Александр Валерьевич, как с Вами связаться?
Хочу отправить смежную генеалогическую идею в один абзац, эти технологии в Яндексе уже разработаны и используются в сервисах.
San66
26.01.2023 22:25Как здорово! Я как раз недавно пытался врукопашную отследить судьбу бабушкиной семьи по сканам, выложенным в свободный доступ (https://cgamos.ru/metric-books/203/203-780/ ). Сломался на пятой метрической книге и подумал, что было бы полезно всё оцифрованное распознать и тут такой подарок судьбы ( и связанных с ней специалистов)!
Распознавание конечно хромает на обе лапы, но это уже прогресс в любительской генеалогии. Полезно было бы подгрузить список имен, а то всякие Екаторины. Опять таки, священники и дьяконы на одном листе почти всегда одинаковые с одинаковым почерком, но распознаются по разному.
Не против, если я кину ссылку на соответствующем форуме? Они могут ломануться и положить вам сервер :-)

DivoTech
26.01.2023 23:01+1Было бы полезно, если можно было бы распознавать свои документы. А так, вероятность, что в базе в ближайшее время появится нужный документ крайне мала

khan-alex
27.01.2023 11:19+1Отличный проект, отличная реализация, СПАСИБО! Сам долгое время занимался генеалогическими исследованиями, что называется посиживал в архивах и представляю какой это огромный труд: найти фонд, опись, единицу в единице архива найти нужное село-приход и потом уже подобраться к нужному родственнику (научившись что-то разбирать по старославянски) и испытать неописуемое чувство удовлетворения от процесса - НАШЁЛ!
А у Вас как всё прекрасно и здорово: ввёл Фамилию, уточнил имя и сразу нашёл прадеда, который был поручителем в одной из венчающихся семей, просто феноменальный результат. В бытность изучения истории семьи о таком даже не мечтал.
Конечно, сейчас Вас завалят предложениями по оцифровке, уже много архивов имеют документы в цифровом виде и можно посетить архив online за умеренную плату (в том числе и наш Ярославский), но всё это конечно не идёт ни в какое сравнение с Вашим текстовым поиском.
Ещё раз спасибо от всех исследователей и посетителей архивов!!!
P.S. А у работников архивов с которыми Вы сотрудничали никакого противодействия не возникало? Ведь если "ВСЁ" оцифровать и выложить в открытый доступ, то у них (работников архива) небольшой коммерческий ручеёк от услуг архива прервётся.
YMA
27.01.2023 11:41+2Думаю, стоит подумать о заключении договоров с архивами. Я лично согласен заплатить за доступ к качественно отсортированному и распознанному массиву данных.
Отец при поиске предков оплачивал услуги доступа к архивам - но там были только сырые сканы, слабо каталогизированные (населенный пункт и год).
Aquahawk
А где потыкать можно?
UP: нашёл https://ya.ru/archive/