
В Ситимобил мы используем базу данных MySQL в качестве основного хранилища постоянных данных. У нас есть несколько кластеров баз данных под различные сервисы и цели.
Постоянная доступность мастера является критическим показателем работоспособности всей системы и ее отдельных частей. Автоматическое восстановление кластера в случае отказа мастера сильно снижает время реагирования на инцидент и время простоя системы. В этой статье я рассмотрю схему обеспечения высокой доступности (HA) кластера MySQL на основе MySQL Orchestrator и виртуальных IP адресов (VIP).

Сначала кратко расскажу о том, что из себя представляет наша система хранения данных.
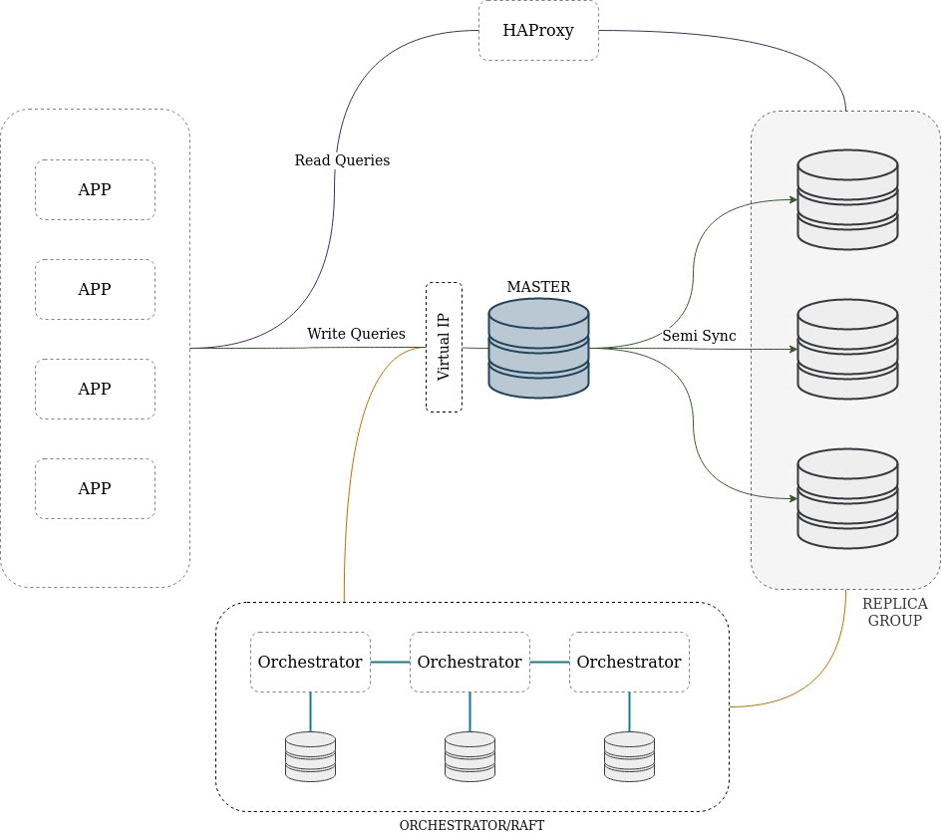
Мы используем классическую схему репликации с одним мастером, доступным на запись, и множеством реплик, которые используются только на чтение. Кластер может содержать промежуточный мастер — узел, который одновременно является и репликой, и мастером для других. Клиенты обращаются к репликам через HAProxy, что позволяет равномерно распределять нагрузку и легко масштабироваться. Использование HAProxy обусловлено историческими причинами, и сейчас мы в процессе миграции на ProxySQL.
Репликация выполняется в полусинхронном режиме на основе
Оркестратор периодически обновляет состояние топологии кластера, анализирует полученную информацию и в случае возникновения проблем может запустить процедуру автоматического восстановления. За саму процедуру отвечает разработчик, поскольку её можно реализовать разными способами: на основе VIP, DNS, с использованием служб обнаружения сервисов (service discovery) или самописных механизмов.
Одним из простых способов восстановления мастера в случае его отказа является использование плавающих VIP-адресов.
Что нужно знать об этом решении, прежде чем двигаться дальше:
Рассмотрим возможные проблемы с нашим мастером и представим, как должен отработать механизм автоматического восстановления.
Алгоритм аналогичен предыдущему случаю: обновление топологии и запуск процесса восстановления. Так как сервер доступен, мы успешно освобождаем VIP на старом мастере, переносим его на новый и отправляем несколько ARP-запросов. Возможный возврат старого мастера не должен повлиять на перестроенный кластер и работу приложения.
Отказ реплик или промежуточных мастеров не приводит к автоматическим действиям и требует ручного вмешательства.
Виртуальный сетевой интерфейс всегда добавляется временно, то есть после перезагрузки сервера VIP автоматически не назначается. Каждый экземпляр БД по умолчанию запускается в режиме только для чтения, оркестратор автоматически переключает новый мастер на запись и пробует установить
В процессе восстановления могут возникнуть проблемы, о которых стоит также уведомлять через UI оркестратора помимо стандартных средств мониторинга. Мы расширили REST API, добавив такую возможность (PR сейчас находится на рассмотрении).
Общая схема HA-решения представлена ниже.
Оркестратор достаточно умён и старается выбрать наиболее подходящую реплику в качестве нового мастера по следующим критериям:
Не каждая реплика является идеальным кандидатом на роль мастера. Например, реплика может использоваться для резервного копирования данных, либо сервер имеет более слабую конфигурацию «железа». Оркестратор поддерживает ручные правила, с помощью которых можно настроить свои предпочтения по выбору кандидата от наиболее предпочтительных до игнорируемых.
В случае инцидента важно минимизировать время простоя системы, поэтому рассмотрим параметры MySQL, влияющие на построение и обновление топологии кластера оркестратором:
Параметры оркестратора:
Каждый узел кластера опрашивается оркестратором один раз в
Тестирование HA-схемы мы начали с разработки локального тестового стенда и дальнейшего внедрения в тестовое и боевое окружения. Локальный стенд полностью автоматизирован на основе Docker и позволяет экспериментировать с конфигурацией оркестратора и сети, масштабировать кластер от 2-3 серверов до нескольких десятков и проводить учения в безопасной среде.
Во время учений мы выбираем один из методов эмуляции проблемы: мгновенно отстрелить мастер с помощью
Как вы знаете, система может вести себя по-разному в тестовом и production-окружениях из-за разной конфигурации «железа» и сети, различий в синтетической и реальной нагрузке и т.д. Поэтому периодически мы проводим учения в реальных условиях, проверяя, как ведет себя система при потере сетевой связности или деградации ее отдельных частей. В будущем хотим построить полностью идентичную инфраструктуру для обеих сред и автоматизировать ее тестирование.
Работоспособность главного узла системы хранения данных является одной из основных задач команды SRE и эксплуатации. Внедрение оркестратора и HA-решения на основе VIP позволило добиться следующих результатов:
Однако решение имеет свои ограничения и недостатки:
Чтобы избежать
Я рассказал о нашем подходе к созданию отказоустойчивого кластера MySQL. Он прост в реализации и обеспечивает приемлемый уровень надежности в текущих условиях. По мере развития всей системы в целом и инфраструктуры в частности этот подход, несомненно, будет эволюционировать.
Постоянная доступность мастера является критическим показателем работоспособности всей системы и ее отдельных частей. Автоматическое восстановление кластера в случае отказа мастера сильно снижает время реагирования на инцидент и время простоя системы. В этой статье я рассмотрю схему обеспечения высокой доступности (HA) кластера MySQL на основе MySQL Orchestrator и виртуальных IP адресов (VIP).
HA-решение на основе VIP
Сначала кратко расскажу о том, что из себя представляет наша система хранения данных.
Мы используем классическую схему репликации с одним мастером, доступным на запись, и множеством реплик, которые используются только на чтение. Кластер может содержать промежуточный мастер — узел, который одновременно является и репликой, и мастером для других. Клиенты обращаются к репликам через HAProxy, что позволяет равномерно распределять нагрузку и легко масштабироваться. Использование HAProxy обусловлено историческими причинами, и сейчас мы в процессе миграции на ProxySQL.
Репликация выполняется в полусинхронном режиме на основе
GTID. Это значит, что как минимум одна реплика должна записать транзакцию в журнал, прежде чем та будет признана успешной. Такой режим репликации обеспечивает оптимальный баланс между производительностью и сохранностью данных в случае выхода из строя главного узла. В основном все изменения передаются от мастера к репликам с помощью Row Based Replication (RBR), но часть узлов может иметь mixed binlog format.Оркестратор периодически обновляет состояние топологии кластера, анализирует полученную информацию и в случае возникновения проблем может запустить процедуру автоматического восстановления. За саму процедуру отвечает разработчик, поскольку её можно реализовать разными способами: на основе VIP, DNS, с использованием служб обнаружения сервисов (service discovery) или самописных механизмов.
Одним из простых способов восстановления мастера в случае его отказа является использование плавающих VIP-адресов.
Что нужно знать об этом решении, прежде чем двигаться дальше:
- VIP — это IP-адрес, который не привязан к конкретному физическому сетевому интерфейсу. При выходе узла из строя или при плановых работах мы можем переключить VIP на другой ресурс с минимальным временем простоя.
- Освобождение и выдача виртуального IP-адреса — дешевые и быстрые операции.
- Для работы с VIP требуется доступ к серверу по SSH, либо использование специальных утилит, например,
keepalived.
Рассмотрим возможные проблемы с нашим мастером и представим, как должен отработать механизм автоматического восстановления.
Пропала сетевая связность до мастера, либо возникла проблема на уровне «железа», и сервер недоступен
- Оркестратор обновляет топологию кластера, каждая реплика сообщает о недоступности мастера. Оркестратор запускает процесс выбора реплики, подходящей на роль нового мастера, и начинает восстановление.
- Пытаемся снять VIP со старого мастера — безуспешно.
- Реплика переключается на роль мастера. Топология перестраивается.
- Добавляем новый сетевой интерфейс с VIP. Поскольку снять VIP не удалось, в фоновом режиме запускаем периодическую отправку запроса gratuitous ARP. Этот вид запроса/ответа позволяет обновить на подключенных коммутаторах таблицу соответствия IP- и MAC-адресов, тем самым уведомляя о переезде нашего VIP. Это минимизирует вероятность
split brainпри возврате старого мастера.
- Все новые соединения сразу же перенаправляются на новый мастер. Старые соединения завершаются неудачно, выполняются повторные обращения к БД на уровне приложения.
Сервер работает в нормальном режиме, произошел отказ на уровне СУБД
Алгоритм аналогичен предыдущему случаю: обновление топологии и запуск процесса восстановления. Так как сервер доступен, мы успешно освобождаем VIP на старом мастере, переносим его на новый и отправляем несколько ARP-запросов. Возможный возврат старого мастера не должен повлиять на перестроенный кластер и работу приложения.
Другие проблемы
Отказ реплик или промежуточных мастеров не приводит к автоматическим действиям и требует ручного вмешательства.
Виртуальный сетевой интерфейс всегда добавляется временно, то есть после перезагрузки сервера VIP автоматически не назначается. Каждый экземпляр БД по умолчанию запускается в режиме только для чтения, оркестратор автоматически переключает новый мастер на запись и пробует установить
read only на старом мастере. Эти действия направлены на уменьшение вероятности split brain.В процессе восстановления могут возникнуть проблемы, о которых стоит также уведомлять через UI оркестратора помимо стандартных средств мониторинга. Мы расширили REST API, добавив такую возможность (PR сейчас находится на рассмотрении).
Общая схема HA-решения представлена ниже.
Выбор нового мастера
Оркестратор достаточно умён и старается выбрать наиболее подходящую реплику в качестве нового мастера по следующим критериям:
- отставание реплики от мастера;
- версия MySQL мастера и реплики;
- тип репликации (RBR, SBR или mixed);
- расположение в одном или разных дата-центрах;
- наличие
errant GTID— транзакции, которые были выполнены на реплике и отсутствуют на мастере;
- также учитываются пользовательские правила выбора.
Не каждая реплика является идеальным кандидатом на роль мастера. Например, реплика может использоваться для резервного копирования данных, либо сервер имеет более слабую конфигурацию «железа». Оркестратор поддерживает ручные правила, с помощью которых можно настроить свои предпочтения по выбору кандидата от наиболее предпочтительных до игнорируемых.
Время реагирования и восстановления
В случае инцидента важно минимизировать время простоя системы, поэтому рассмотрим параметры MySQL, влияющие на построение и обновление топологии кластера оркестратором:
slave_net_timeout— количество секунд, в течение которых реплика ожидает поступления новых данных или heartbeat-сигнала от мастера, прежде чем соединение признается потерянным и выполняется переподключение. Чем меньше значение, тем быстрее реплика сможет определить, что связь с мастером нарушена. Мы устанавливаем это значение равным 5 секундам.
MASTER_CONNECT_RETRY— количество секунд между попытками переподключения. В случае сетевых проблем низкое значение этого параметра позволит быстро переподключиться и предотвратить запуск процесса восстановления кластера. Рекомендуемое значение — 1 секунда.
MASTER_RETRY_COUNT— максимальное количество попыток переподключения.
MASTER_HEARTBEAT_PERIOD— интервал в секундах, после которого мастер отправляет heartbeat-сигнал. По умолчанию равен половине значенияslave_net_timeout.
Параметры оркестратора:
DelayMasterPromotionIfSQLThreadNotUpToDate— если равенtrue, то роль мастера не будет применена на реплике-кандидате до тех пор, пока SQL-поток реплики не выполнит все непримененные транзакции из Relay Log. Мы используем эту опцию, чтобы не терять транзакции в условиях отставания всех реплик-кандидатов.
InstancePollSeconds— частота построения и обновления топологии.
RecoveryPollSeconds— частота анализа топологии. В случае обнаружения проблемы запускается восстановление топологии. Это константа, равная 1 секунде.
Каждый узел кластера опрашивается оркестратором один раз в
InstancePollSeconds секунд. При обнаружении проблемы состояние кластера принудительно обновляется, а затем принимается окончательное решение о выполнении восстановления. Экспериментируя с различными параметрами БД и оркестратора, нам удалось снизить длительность реагирования и восстановления до 30 секунд.Тестовый стенд
Тестирование HA-схемы мы начали с разработки локального тестового стенда и дальнейшего внедрения в тестовое и боевое окружения. Локальный стенд полностью автоматизирован на основе Docker и позволяет экспериментировать с конфигурацией оркестратора и сети, масштабировать кластер от 2-3 серверов до нескольких десятков и проводить учения в безопасной среде.
Во время учений мы выбираем один из методов эмуляции проблемы: мгновенно отстрелить мастер с помощью
kill -9, мягко завершить процесс и остановить сервер (docker-compose stop), имитировать проблемы с сетью с помощью iptables -j REJECT или iptables -j DROP. Мы ожидаем такие результаты:- оркестратор обнаружит проблемы с мастером и обновит топологию не более чем за 10 секунд;
- автоматически запустится процедура восстановления: изменится сетевая конфигурация, роль мастера перейдёт к реплике, топология перестроится;
- новый мастер станет доступен для записи, живые реплики не будут потеряны в процессе перестроения;
- данные начнут записываться в новый мастер и реплицироваться;
- общее время восстановления составит не более 30 секунд.
Как вы знаете, система может вести себя по-разному в тестовом и production-окружениях из-за разной конфигурации «железа» и сети, различий в синтетической и реальной нагрузке и т.д. Поэтому периодически мы проводим учения в реальных условиях, проверяя, как ведет себя система при потере сетевой связности или деградации ее отдельных частей. В будущем хотим построить полностью идентичную инфраструктуру для обеих сред и автоматизировать ее тестирование.
Выводы
Работоспособность главного узла системы хранения данных является одной из основных задач команды SRE и эксплуатации. Внедрение оркестратора и HA-решения на основе VIP позволило добиться следующих результатов:
- надежное обнаружение проблем с топологией кластера БД;
- автоматическое и быстрое реагирование на инциденты, связанные с мастером, что снижает время простоя системы.
Однако решение имеет свои ограничения и недостатки:
- масштабирование HA-схемы на несколько ЦОДов потребует наличия единой L2-сети между ними;
- прежде чем назначить VIP на новом мастере, нам нужно освободить его на старом. Процесс является последовательным, что увеличивает время восстановления;
- освобождение VIP требует SSH-доступа к серверу, либо любого другого способа вызова удаленных процедур. Поскольку сервер или БД испытывает проблемы, вызвавшие процесс восстановления, мы не можем быть уверены, что снятие VIP завершится удачно. А это может привести к появлению двух серверов с одинаковым виртуальным IP-адресом и проблеме
split brain.
Чтобы избежать
split brain, можно использовать метод STONITH («Shoot The Other Node In The Head»), который полностью изолирует или отключает проблемный узел. Существуют и другие способы реализации высокой доступности кластера: комбинация VIP и DNS, обнаружение служб и прокси-сервисы, синхронная репликация и прочие способы, которые имеют свои недостатки и преимущества.Я рассказал о нашем подходе к созданию отказоустойчивого кластера MySQL. Он прост в реализации и обеспечивает приемлемый уровень надежности в текущих условиях. По мере развития всей системы в целом и инфраструктуры в частности этот подход, несомненно, будет эволюционировать.
gtbear
А можно добавить информацию почему не выбрали galera?
BHYCHIK
Тут существует несколько причин.
1) Кадровая — людей, которые умеют траблшутить галеру на рынке достаточно мало.
2) Галера работает на основе синхронной репликации. То есть в случае замедления работы на одном из серверов, это будет сказываться на всем кластере. Да и в штатном режиме такой режим работы медленнее. При этом наше ПО адекватно реагирует на вменяемое отставание реплик.
Когда мы начнем задумываться об отказоустойчивости по ДЦ, то мы обязательно вернемся к этому вопросу. Пока думаем, что наши проблемы решаются без получения дополнительной головной боли.
gtbear
Да, синхронность галеры может доставить проблем там где нужна скорость. Но вроде как у вас сервис как раз таки требующий надежности хранения данных. Кроме того по идее можно иметь группу нод галеры + слейвы, то есть тормоза будут только на запись. Ну и получается что если сейчас возникнет проблема с ДЦ то сервис склеивает лапки, так?
BHYCHIK
На самом деле надежность хранения не сверхкритична. Поездки на такси более-менее стейтлесс штука. Нам куда важнее при непредсказуемом росте нагрузки осуществлять поездки.
Вероятность роста таких нагрузок все же много больше вероятности отказа ДЦ. Мы впервую очередь закрываем наиболее вероятные риски с наибольшей опасностью для аптайма.
На случай ухода ДЦ у нас есть свои механизмы восстановления работоспособности (пока с небольшим даунтаймом), но об этом в следующих сериях ;-)
BHYCHIK
Ну и да — с точки зрения надежности уход мастер-базы у нас не приводит к потере транзакций. Полусинхронная репликация же.
parshinpn Автор
Важно иметь баланс между производительностью и надежностью.
По галере: для внедрения нужен как минимум опыт в команде по её использованию и сопровождению в продакшене под нагрузкой. Галера накладывает ряд ограничений на схему, допустимые операции, локи + обычно всплывают подводные камни во время использования такого рода систем. Поэтому решение выбираем, исходя из текущих реалий (об этом можно прочитать у Ивана в статье) и тем как быстро и на приемлемом уровне можем устранить SPOF.
naim
А почему не решения на Consul KV для переключения типа как тут к примеру https://blog.pythian.com/mysql-high-availability-with-proxysql-consul-and-orchestrator/ ?
parshinpn Автор
Есть в планах как дальнейшее улучшение схемы, но сначала собираемся интегрировать ProxySQL.
naim
А сейчас без проксиsql какие проблемы или неудобства возникают?
И сколько у вас мастеров если не секрет?
BHYCHIK
Сейчас 5. Без proxysql сложно наращивать кластер web-серверов из-за линейного роста числа коннектов к базам.
naim
А переназначение мастеров будете и в планах делать скриптами вызываемые оркестратором?
parshinpn Автор
Возможно, какая-то логика в скриптах останется. Но основная часть переедет на Consul и его шаблоны.
naim
А сейчас у вас в конечных приложениях как стоит куда подключаться? К одному ипу?
BHYCHIK
Когда нужно цепляться к мастеру — VIP конкретного мастера. Когда нужно цепляться к слейву — локальный haproxy, который уже балансит по слейвам. Хотя вобще-то лучше к локальному proxysql, задача на это есть в бэклоге, но пока не приоритет.
naim
А на уровне приложения они по DNS имени коннектиться и если да то время переключения как контролируете?
BHYCHIK
По IP
JuriM
с proxysql был негативный опыт, когда вдруг прокси перевел ноду из read-only в read-write и поломанная репликация в итоге
parshinpn Автор
А удалось выяснить причину такого поведения?
JuriM
Нет, так как из прода это сразу убрали, а на форуме proxysql по данной проблеме ничего особо не посоветовали. Кстати вспомнил что на предыдущей работе стоял haproxy для мускула и тоже пришлось отказаться — haproxy вносил ощутимые тормоза.
naim
А какая там была версия и когда по времени это было?
JuriM
Было в прошлом году, версия proxysql 2.0.2
Были созданы две группы, только-чтение для слейва и чтение-запись для мастера и несколько правил для роутинга запросов. Все работало примерно месяц, пока не случился факап.
UPD. Зашел к ним на гитхаб и сразу вижу такое github.com/sysown/proxysql/issues/2592
naim
У вас какие то логи или что то осталось?
JuriM
Увы, ничего не осталось.
naim
И какое другое решение сейчас используете?
JuriM
Был pacemaker, но тоже убрали. Ничего не используем сейчас, тупо мастер слейв :)