

Пару лет назад мы чувствовали себя в каком-то сюрреалистическом сне. Все вокруг шли в облако для тестирования (удобно же разворачивать-сворачивать тестовые среды), а мы пытались выяснить, какие инструменты «из коробки» нужно поставлять. Для этого мы вместе с заказчиками разбирались, как устроены процессы девопса. И оказалось, что только единичные компании в России как-то грамотно применяют автоматизацию.
Сразу поясню, что мы по большей части общались или с теми, кто занимается разработкой в компании до 150–200 человек, или с производствами, где с ИТ традиционно тяжело. У компаний крупнее обычно есть и процесс, и собственное облако, и к нам они приходят за резервным размещением.
Производство обычно хорошо отлажено. Есть цикл, план релизов, есть цель, код идёт к цели вместе с разработчиками.
Тестирование и QA тоже хорошо отлажены чаще всего.
А между ними — пропасть. И её пытается заполнить DevOps. Этот супермен должен взять релиз (а в идеале — собрать в Дженкинсе или чём-то подобном), создать машину, развернуть там всё, проверить работу, может, провести пару претестов и отдать уже в QA.
В чём проблема?
Когда продукт маленький типа веб-приложения, то проблемы никакой нет. Прямо разработчик или тестировщик берут базу из бэкапа, соединяют с последним релизом и бегут дальше.
А вот когда продукт чуть подрастает, наступает производственный коллапс.
Девопс получил релиз, а он взял и не собрался. Дальше он начинает искать крайнего и перебирать разработчиков. Релиз может собираться несколько часов и ночью, а разработчики обычно сидят в офисе днём.
Почти всё делается руками. То есть сидит опс и смотрит на прогресс-бар сборки. Потому что в любом месте что-то может пойти не так. Те, кто поэнергичнее, обвязывают всё это своими собственными скриптами, и иногда получается очень красиво и эффективно. Но куда чаще мы видим, что план поставки релиза выполняется по шагам, за каждый шаг отвечает отдельный человек, и ему проще двадцать раз повторить процедуру руками, потому что иначе получится, что он не работает.
При этом кто-то должен отвечать за процесс в целом, и это главный останавливающий фактор. Попытка найти такого человека часто заканчивается крахом. А именно он отвечает за автоматизацию, и именно ему она интересна. Отвечать за отдельные участки и потом переводить стрелки на кого-то в разработке, конечно, всегда проще.
Виртуализация добавляет ещё аспектов хаоса. Виртуальные среды — всегда бардак. Тот человек, который отвечает за группировку (сервер, стойку), он плохо ориентируется, кому что принадлежит, нужно это или нет. Логично, что системный администратор не должен особо волноваться, что там творится у разработчиков. А вот девопс должен, но его роль обычно не предполагает такого знания. А отключать лишнее он боится, потому что не понимает, понадобится оно ещё или нет.
Потом надо выставлять внутренние счета для взаиморасчётов отделов. Кто-то считает аптайм, кто-то считает использование процессора, потом делят поровну или в каких-то пропорциях затраты вроде электричества и работы администраторов.
Неожиданно, но готового продукта нет
Казалось бы, весь этот конвейер должен быть покрыт каким-то продуктом. Есть много хороших точечных решений. Тот же Ansible отлично разворачивает, но не умеет рулить виртуалками. А гипервизоры умеют. Есть все инструменты для девопс-скриптинга, можно подключать модули… Надо просто взять и собрать из этого цепочку софта, так?
Не так. Пришли банки и госкомпании с желанием тестировать в облаке. Каждый хороший безопасник имеет склонность к паранойе, зачастую вполне обоснованно. Для ИБ банка каждая новая инсталляция — это очень раздражающий фактор. Знаю один случай, когда опсы затащили в инфраструктуру Дженкинс, Терраформ, за ним развернули bash, а потом — СУБД, которое всё это держит. Получился хороший полуавтоматический конвейер, который можно было допилить до полностью автономного деплоя. Только для ИБ это была катастрофа.
Им хотелось всё в одном. И чтобы управлял виртуалкой (причём разных вендоров, включая Опенстек). У Заказчика на одном приложении может быть и Вмваре, и Хайпер-в, и ещё что-нибудь старое и страшное для поддержки FreeBSD или OS/2.
Нам нужен свой велосипед
В общем, мы написали свою платформу. Под капотом — Ansible, из коробки — интеграция с Jenkins. Можно писать свои скрипты для Ansible. Можно делать всё — от сбора подсетей до управления релизом.
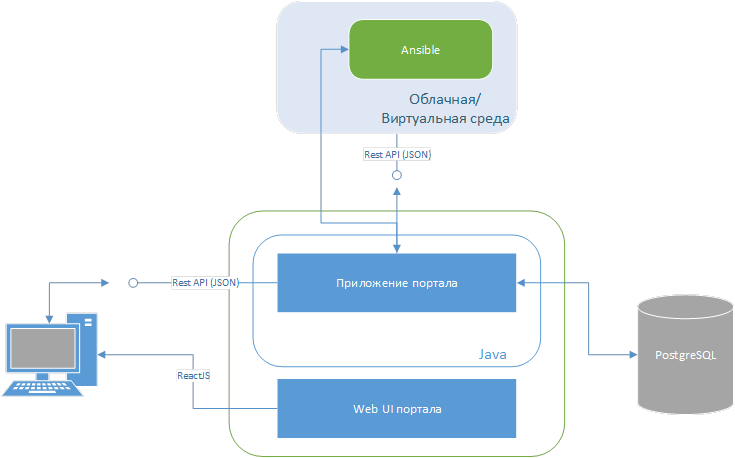
Портал живёт в парадигме тестовой среды. Это его основная сущность. Одна тестовая среда = одна подсеть. Плюс если совсем плохо — есть интеграция с RPA на случай, если API нету, и нужен робот проэмулировать действия пользователя и нажать на кнопки в интерфейсе. Есть биллинг, считаются аптайм и утилизации либо от заявки до заявки: пока заявку на уничтожение не написал, деньги будут капать.
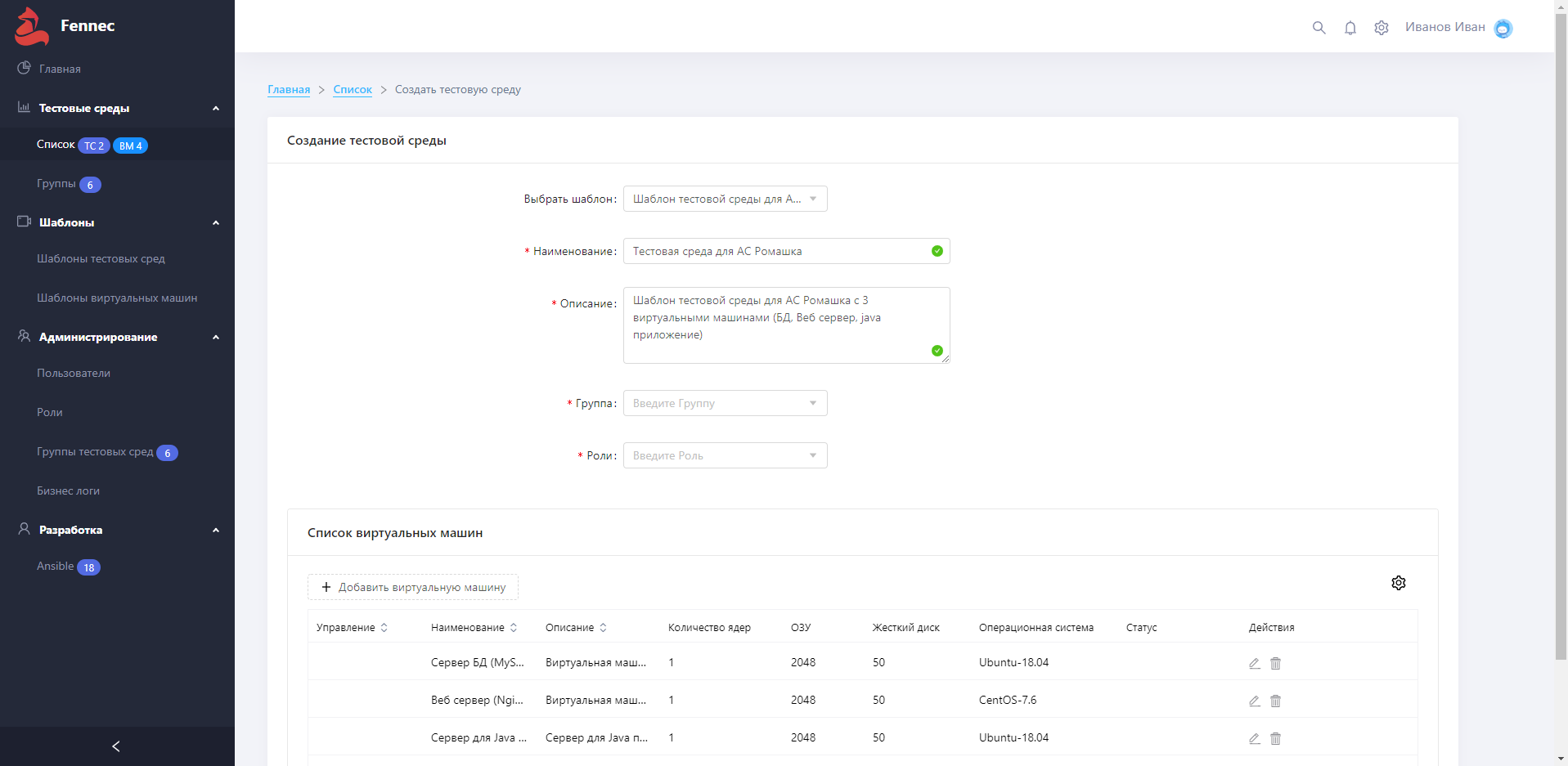
Вот так это выглядит. Создание среды по шаблону:
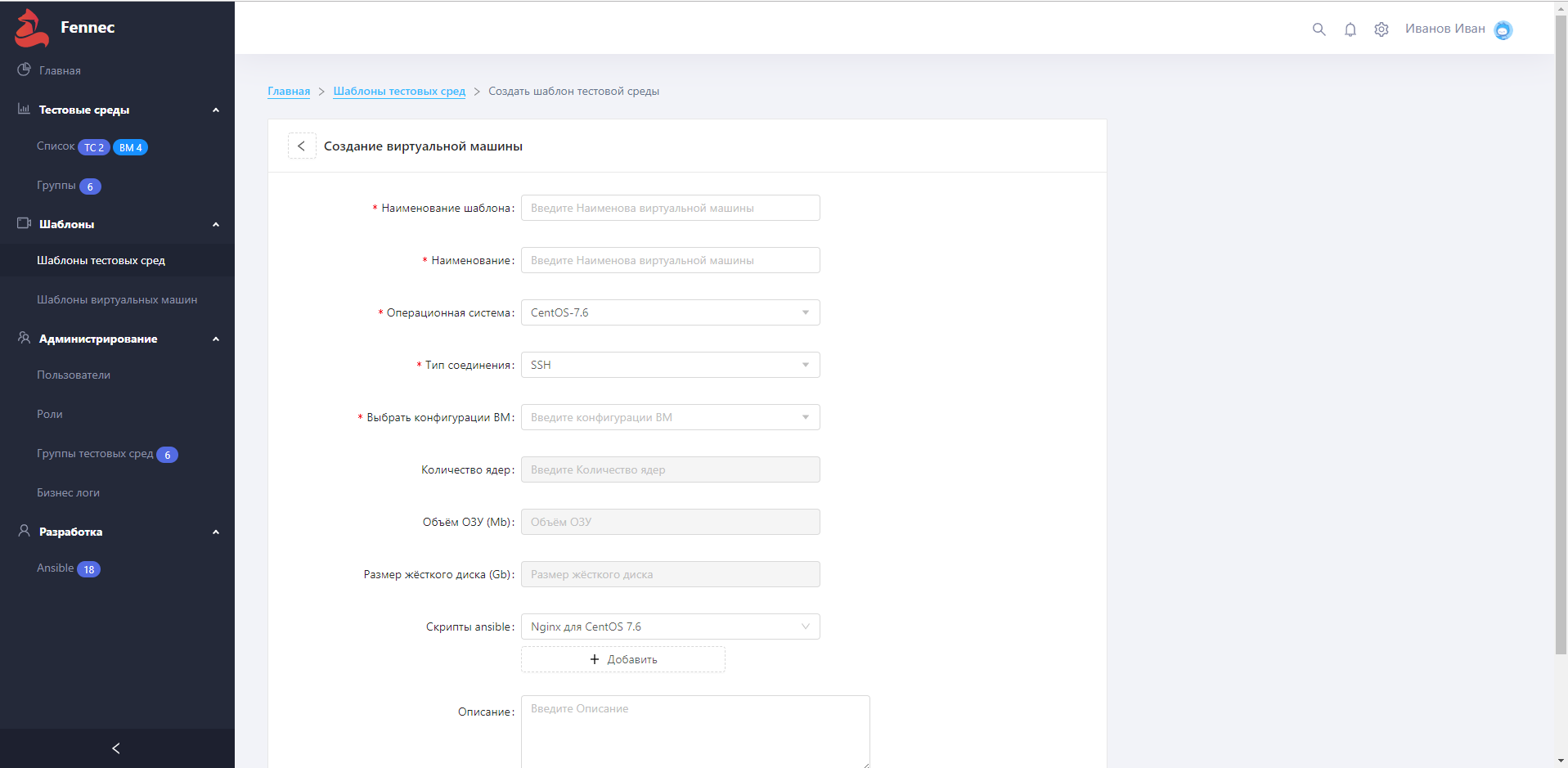
Добавление виртуальной машины:
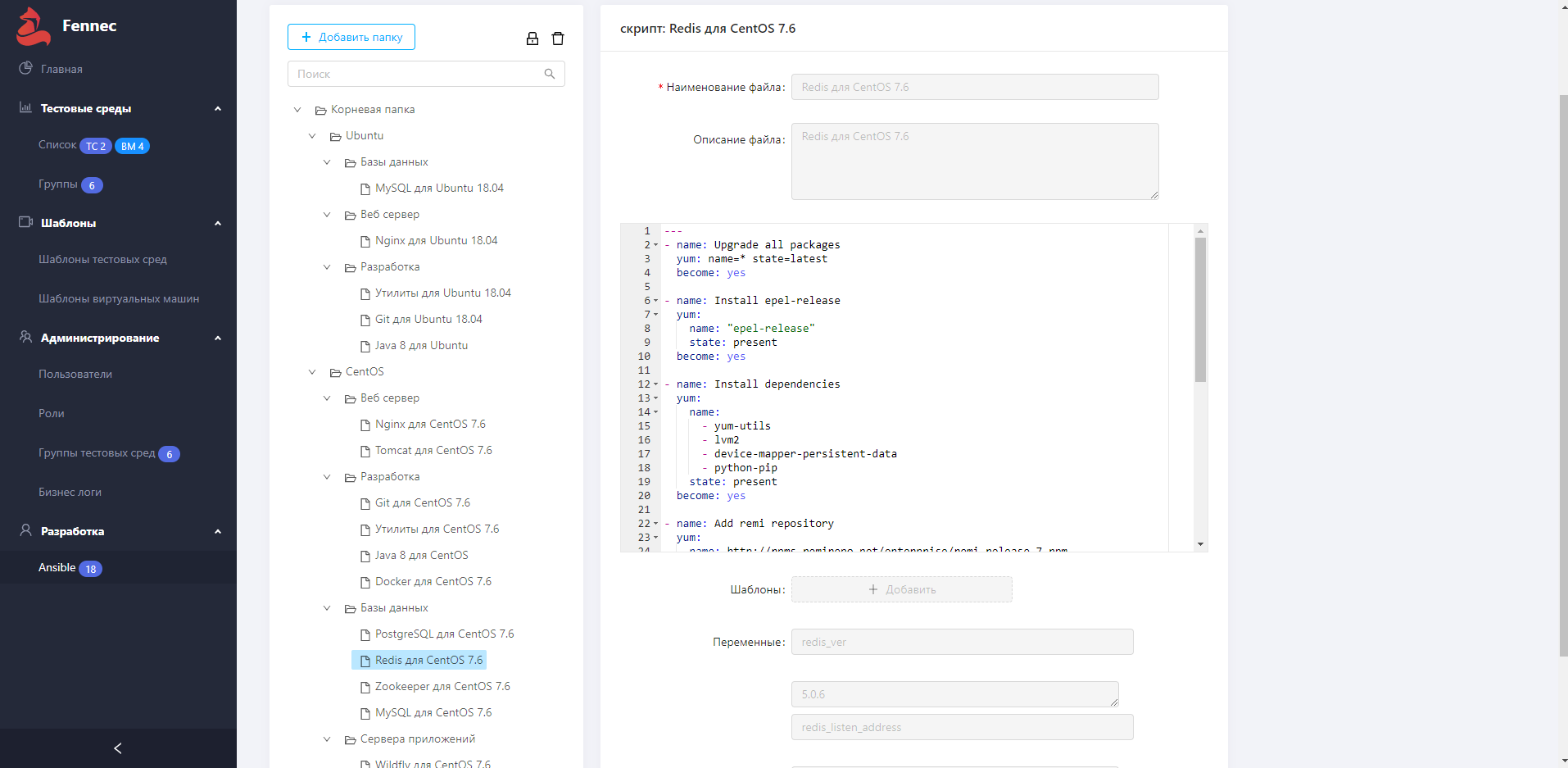
Скриптинг:
Как оказалось чуть позже, жалобы «Я не хочу бегать по 50 системам» слышны со всех сторон. Мы попали в важную боль. Любой крупный заказчик с тестированием хотел что-то подобное, но почему-то не решал либо решал организационно людьми-скриптами. Проблемы самые разные начиная от безымянных виртуалок (удалили, а потом кто-то вспомнил, что она был нужна) и заканчивая тем, что никто не хочет отвечать за скрипты накатки. Сценарии наката пишутся с трудом, регламенты тоже страдают. Где-то в цикле должна быть обезличка данных, и это выглядит как «Когда-то в начале года мы сделали обезличенную БД», а софт поменялся шесть раз, данные обновились.
В общем, если у вас вдруг болит что-то похожее, то просто приходите смотреть. Демо-доступ можно получить в облаке Техносерв Cloud.

kkostin
Зачем вам наши персональные данные для демо-доступа?
TS_Development Автор
Чтобы было куда потом отправить форму для обратной связи. Если вы не хотите указывать ничего — оставьте случайное имя и случайную почту, мы всё равно пропустим.