
Признаюсь, но я не знаю Python. Просто потому, что не использую. Тем не менее, взявшись за его освоение, а также в попытках расшифровать загадочную аббревиатуру GIL, вышел на статью с описанием «необъяснимых магических явлений» параллельного варианта CPU-зависимой функции на Python. Возникло желание перепроверить данный тест и сравнить с эквивалентной реализацией в форме модели конечного автомата (Finite-state machine или сокращенно FSM) в среде Визуального Компонентного Программирования (автоматного) — ВКП(а).
Очевидно любая программа в определенной мере CPU-зависима. С другой стороны, если это только не ассемблер, то тестированием на том или ином языке высокого уровня мы в большей степени исследуем программную прослойку, скрываемую им. Поэтому, рассматривая Python, правильнее было бы говорить о CPU-зависимости его интерпретатора. Можно даже утверждать, что программа на Python будет иметь скорость, зависимую от версии интерпретатора, и обладать характерной для него «мистикой».
В то же время есть ситуации, когда зависимости от CPU может почти не быть (в этом мы убедимся). Речь идет о языках, вычислительная модель которых отлична от типовой архитектуры процессоров. Вычислительная модель Python, ей соответствует, а автоматная модель вычислений, о которой далее пойдет речь, имеет другую архитектуру и это будет определять специфику ее тестирования. Какая будет скорость и будет ли иметь место мистика выяснится в процессе тестирования «автоматного кода».
Код на Python, заимствованный из статьи, в последовательном и параллельном вариантах представлен соответственно на листингах 1 и 2. В нашем случае он дополнен строками, фиксирующими время работы, а последовательный тест заключен в «обертку», позволяющую задавать число повторений (следствие моего знакомства с декораторами в Python).
Рис.1 и рис.2 демонстрируют результаты тестирования, которые получены для двух последовательных прогонов теста (Python 3.8.3 64-bit) для процессора Intel® Core(TM) i5-2400S CPU @2.5 GHz, ОЗУ 6.0 ГБ. Результаты следующие:
В статье о GIL (далее — исходной статье) это было соответственно 24.6 сек и 45.5 сек. Обращает на себя внимание время параллельного теста. В сравнении с результатами исходной статьи это демонстрирует, что дело продвинулось, хотя бы с точки зрения реализации интерпретатором параллелизма (хотя это лишь только предположение).
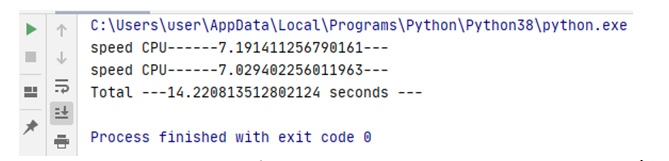
Рис.1. Время работы последовательного теста на языке Python
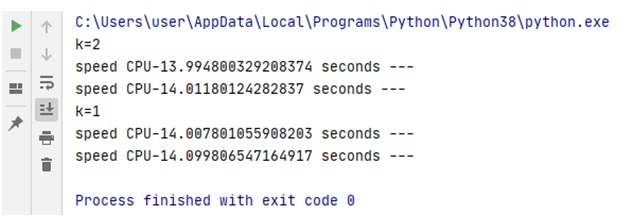
Рис.2. Время работы параллельного теста на языке Python
Обратим внимание, что параллельный вариант почти в два раза медленнее аналогичного последовательного. При этом, если мы создадим три потока, то и результат замедлится пропорционально (см. рис. 3). Из этого можно заключить, что увеличение числа потоков ведет к кратному увеличению времени работы. Если не лезть под капот, то на текущем уровне понимания Python это может выглядеть, как мистика.
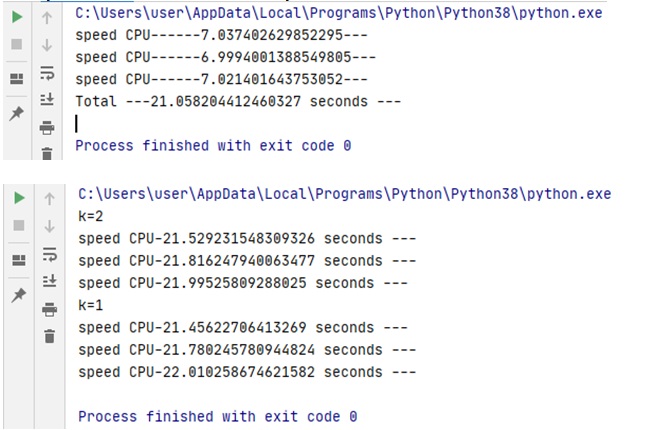
Рис.3. Тест CPU на трех потоках на языке Python
Прежде чем перейти к созданию автоматного кода и тестированию в среде ВКП(а), рассмотрим реализацию автоматов вне ее. Эквивалентная алгоритму исходной статьи модель в форме графа автомата показана на рис. 4. Из разнообразия возможных вариантов (см., к примеру, статью) рассмотрим наиболее типовой и известный — в формате, так называемой, SWITCH-технологии (подробнее о ней см. на сайте ИТМО).
Далее мы будем сравнивать программу на Python с реализацией на С++. Соответствующий графу код на С++ с кодом его запуска (см. функцию main) приведен на листинге 3.
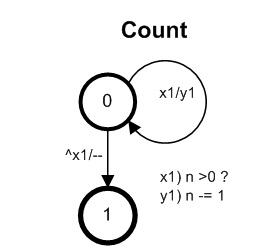
Рис.4. Автоматная модель CPU-зависимой функции
Время работы теста на упомянутой аппаратной базе находится в пределах 250 мсек. Это более чем в 55 раз быстрее по сравнению с кодом Python. Сравнение проведено с параллельным вариантом тестирования для двух потоков (см. рис.2).
Но скорость можно повысить еще больше, если функцию вычислять, не выходя за пределы действия/метода y1 (см. листинг 4). В результате скорость теста уменьшилась до менее чем 1 мсек (точнее сказать сложно, т.к. тест выдает значение равное нулю). Если взять за основу даже это значение, то скорость получаем более чем в 14000 (!) раз выше, чем на Python. Становится понятным, почему С++ отдают предпочтение при проектировании тех же систем реального времени.
Наша дальнейшая цель — сравнение Python со средой ВКП(а). Автоматный тест, как и выше, должен соответствовать модели на рис. 4. Его код демонстрирует листинг 5.
Время исполнения теста в пределах 5.35 сек при количестве циклов 100000. Т.е. он, написанный на быстром С++, работает более чем в 2600 раз (!?) медленнее параллельного теста на Python. Такой результат не может не огорчать :( Но отметим, что длительность дискретного такта при этом равно 0.0535 мсек. Например, стандартный цикл ПЛК типа ОВЕН-100 равен 1 мсек, а поэтому с точки зрения систем управления реального времени результат вполне достойный. Хотя, еще раз, на первый взгляд результат не в пользу АП, т.к. и код объемный, да и скорость вызывает определенную тревогу (например, для чисто вычислительных задач).
Использование С++ в качестве языка проектирования ВКП(а) позволяет достаточно просто решить возникшую проблему скорости. Листинг 6 демонстрирует код автомата, использующего стандартные системные потоки на базе класса QThread библиотеки Qt. В результате время упало до 70-80 мсек даже при увеличении циклов до 100000000. Таким образом, тест, использующий поток, работает уже в 200 раз быстрее, чем на Python.
Заметим, что полученный результат представляет замедленную версию теста, синхронизированную со средой ВКП(а). Если закомментировать строку (листинг 6):
то время «рухнет» до 1 мсек и менее. В результате скорость по отношению к Python уже будет выше более чем в 14000 раз.
Замечание 1. Флаг bIfExecuteStep управляется средой ВКП(а). Устанавливается ею в начале текущего дискретного такта. Введен для синхронизации с дискретным временем автоматного пространства процесса.
С целью увеличения скорости мы создали комбинацию автомата и потока, где последний реализует нужную функциональность, а автомат — его обертка. Получился достаточно специфический объект, но и мы решали прежде всего задачу увеличения скорости работы, которую в результате и решили.
Рассмотрим еще один тест, обратив внимание на время работы потоков. Поскольку они абсолютно одинаковы, то, запущенные одновременно, они должны одновременно и завершить работу. Если для Python это справедливо лишь в пределах определенной погрешности (см. рис. 5), то для процессов в ВКП(а) время полностью совпадает (см. рис. 6). Заметим, что дополнительно созданный объект-секундомер, определяющий время работы теста извне его, показывает фактически такое же время, как и время, отмеряемое самим тестом/тестами (см. листинг 4).
Замечание 2. «Секундомер» — автоматный процесс, начинающий отсчет, когда контролируемый процесс попадает в состояние «s1» и фиксирующий время, когда тот переходит в состоянии «st» (см. таблицу переходов автомата на листинге 4).
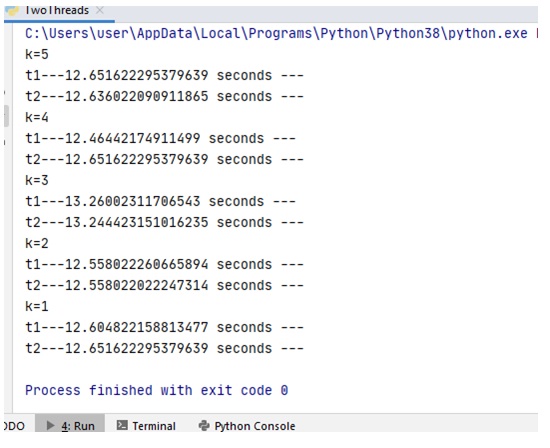
Рис.5. Время работы тестов в Python
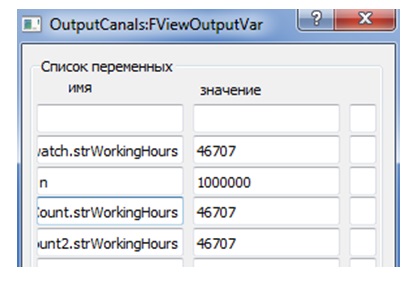
Рис.6. Время работы тестов в среде ВКП(а)
Автоматы в сравнении с другими моделями имеют дискретное время. Величина дискретного такта может быть фиксированной для синхронных автоматов или плавающей — для асинхронных (классификация по Глушкову В.М.). Следующим тестом будет проверка среды ВКП(а) на синхронность — способность поддерживать постоянное значение такта дискретного времени. Напомним, что режим синхронной работы автоматов особенно востребован при проектировании систем автоматического управления (см. подробнее [1]). Одновременно подобный режим служит примером реализации фактической независимости вычислительной модели от скорости CPU.
Время работы теста при дискретном такте (в теории автоматического управления (ТАУ) именуемом интервалом квантования) длительностью 1 мсек и числе циклов 100000 должно быть 100 сек. Полученные при тестировании результаты демонстрирует рис. 7.
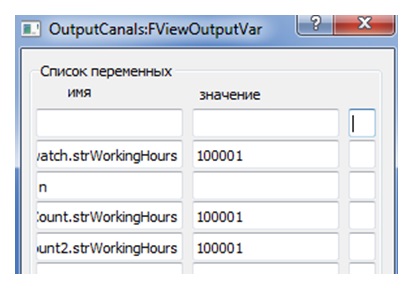
Рис.7. Тестирование в синхронном режиме (1 мсек)
Основное тестирование мы фактически закончили и теперь можно обсудить объем кода, т.к., глядя на листинг 3, критики не преминут указать на это. Но они в очередной раз забудут о том, о чем не раз уже говорилось. Код включает оболочку, организующую взаимодействие со средой ВКП(а). Какой вид примет автомат, если ее исключить, поясняет листинг 7, представляющий чистый код автоматной функции.
Получилось, не правда ли, заметно проще, хотя время работы осталось прежним. Но, как мы уже выяснили, время функции, заключенной в поток, составляет буквально единицы микросекунд. Подобное действие уже было рассмотрено (см. листинг 4). С ним время теста будет исчисляться, как и ранее, микросекундами (см. рис. 8).
Таким образом, многие проблемы автоматных программ можно разрешить, если представлять, как можно управлять их эффективностью. Возможности С++ в этом смысле фактически ни чем не ограничены.
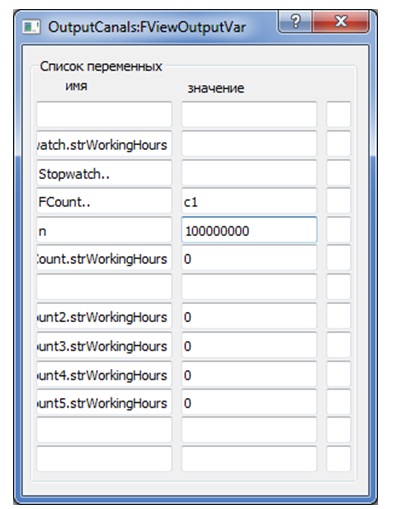
Рис.8. Результаты тестирование действия y1 (листинг 6).
Осталось рассмотреть «автоматную обертку» для функции в листинге 7. Ее демонстрирует листинг 8. Код объемный, но, еще раз, типовой, выполняющий стандартные для среды функции.
Итак, можно подвести итоги. В общем случае автоматы в ВКП(а) работают медленнее почти в 2600 раз в сравнении с процессами на Python. Такова фактически оценка «автоматного интерпретатора» среды ВКП(а). С одной стороны, в этом сокрыты колоссальные резервы роста, а, с другой, с точки зрения реактивности среды даже такой скорости вполне достаточно. Но, напомним, использование потоков позволяет справиться и с этой проблемой уже сейчас и, наоборот, на этой базе быть быстрее Phython более чем в 200 раз. В дополнение к потокам существует даже более простое и теоретически более верное «автоматное решение» — вызов проблемной функции в рамках одного или нескольких действий (аналог «разделения операции или процесса на чанки» см. статью). В любом случае с С++ ситуация в АП с точки зрения производительности программ не выглядит безвыходной, а в определенной ситуации (проектирование, например, систем реального времени) даже выигрышная.
И в заключение немного о том, что выходит за пределы простого тестирования. Меня зацепила статья. Я согласен с тем, что «хватит уже бояться субъективно красивых решений в коде». С одной существенной поправкой — я за объективность. Код автоматной программы может казаться громоздким (что достаточно поправимо), не очень красивым (это весьма субъективно) и даже не устраивать по скорости (здесь, как мы убедились, в АП есть решение и не одно), но постижение его сути открывает скрытую от стороннего взгляда красоту. Причем красоту объективную.
Что здесь выступает критерием объективности? Теория. В нашем случае — теория автоматов. Ее реализация, как бы она не выглядела, по определению не может быть некрасивой ;) И наоборот, если реализация не соответствует ей, то как бы выигрышно она не выглядела, она не имеет, как правило, перспективы с точки зрения теории. А потому в каком бы запале ни пропагандируй SWITCH-технологию, как ни расхваливай UniMod, но если они не соответствуют требованиям теории автоматов, искажая ее красоту, то мы поневоле и объективно сталкиваемся с ситуацией, что «автомат многим не друг». И одними «камланиями» и «танцами с бубном» такую ситуацию не исправишь. Но, если следовать теории, этого и не понадобится.
Пуская критические стрелы в сторону автоматов, я, как тот «вшивый о бане», не мог не вспомнить о корутинах ;) Хотелось бы их тоже протестировать, а заодно и оценить их красоту, т.к. неужели красота «конструкций», подобных представленным на рис. 9 (см. также), которые реализуют, если не ошибаюсь, два параллельных (?) оператора a = a-b и b = a+b, могут вызывать хоть минимальные приступы восхищения?
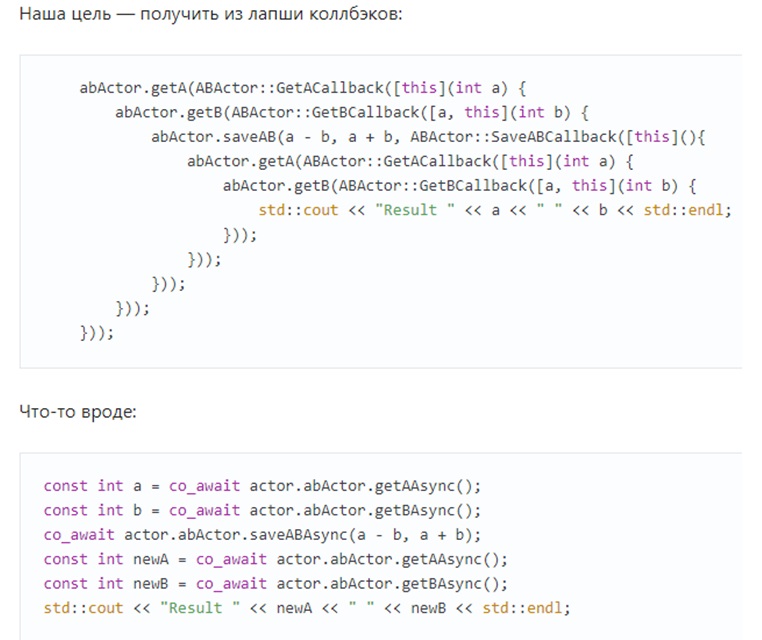
Рис.9. Пример корутин
Может быть этот код даже эффективен, а для кого-то несомненно красив, но речь-то о другом. Я здесь не о маниакальном желании описать параллелизм шаблонами последовательного мышления. Хотя это, если уж прямо, напрягает, т.к. мышление нужно менять. Я совсем о другом. Есть ли независимая от языка программирования теория корутин, которая позволяла бы просто и наглядно преодолеть «загогулины» языка (см. еще раз рис. 9) и дать однозначный ответ на заданный вопрос? В отношении корутин я такой теории не знаю, хотя уже, если честно, обыскался ;) Для конечных автоматов — это теория автоматов, в которой автомат — всегда автомат в любом виде (граф, таблица, матрица и т.п.) вне связи с языком/языками программирования.
Дернув за, казалось бы, простейшую «тестовую ниточку», мы затронули клубок… параллельных проблем. Может быть, правда, лишь немножко его распушили. А начали-то, если кто еще не забыл, с элементарной CPU-зависимой функции.
Кто же мог подумать, во что это выльется… :)
Литература
1. Мирошник И.В. Теория автоматического управления. Линейные системы. — СПб.: Питер, 2005. — 336 с.
Очевидно любая программа в определенной мере CPU-зависима. С другой стороны, если это только не ассемблер, то тестированием на том или ином языке высокого уровня мы в большей степени исследуем программную прослойку, скрываемую им. Поэтому, рассматривая Python, правильнее было бы говорить о CPU-зависимости его интерпретатора. Можно даже утверждать, что программа на Python будет иметь скорость, зависимую от версии интерпретатора, и обладать характерной для него «мистикой».
В то же время есть ситуации, когда зависимости от CPU может почти не быть (в этом мы убедимся). Речь идет о языках, вычислительная модель которых отлична от типовой архитектуры процессоров. Вычислительная модель Python, ей соответствует, а автоматная модель вычислений, о которой далее пойдет речь, имеет другую архитектуру и это будет определять специфику ее тестирования. Какая будет скорость и будет ли иметь место мистика выяснится в процессе тестирования «автоматного кода».
Код на Python, заимствованный из статьи, в последовательном и параллельном вариантах представлен соответственно на листингах 1 и 2. В нашем случае он дополнен строками, фиксирующими время работы, а последовательный тест заключен в «обертку», позволяющую задавать число повторений (следствие моего знакомства с декораторами в Python).
Листинг 1. Последовательный тест CPU на Python
import time
def count(n):
st_time = time.time()
while n > 0:
n -= 1
t = time.time() - st_time
print("speed CPU------%s---" % t)
return t
def TestTime(fn, n):
def wrapper(*args):
tsum=0
st = time.time()
i=1
while (i<=n):
t = fn(*args)
tsum +=t
i +=1
return tsum
return wrapper
test1 = TestTime(count, 2)
tt = test1(100000000)
print("Total ---%s seconds ---" % tt)
Листинг 2. Параллельный тест CPU
import time
from threading import Thread
def count(n):
start_time = time.time()
while n > 0:
n -= 1
print("speed CPU-%s seconds ---" % (time.time() - start_time))
k = 2
while k > 0:
print("k=%d " % k)
t1 = Thread(target=count,args=(100000000,)); t1.start()
t2 = Thread(target=count,args=(100000000,)); t2.start()
t1.join();
t2.join();
k -= 1
Рис.1 и рис.2 демонстрируют результаты тестирования, которые получены для двух последовательных прогонов теста (Python 3.8.3 64-bit) для процессора Intel® Core(TM) i5-2400S CPU @2.5 GHz, ОЗУ 6.0 ГБ. Результаты следующие:
- последовательный тест — 14.221 сек
- параллельный тест — 13.995 сек
В статье о GIL (далее — исходной статье) это было соответственно 24.6 сек и 45.5 сек. Обращает на себя внимание время параллельного теста. В сравнении с результатами исходной статьи это демонстрирует, что дело продвинулось, хотя бы с точки зрения реализации интерпретатором параллелизма (хотя это лишь только предположение).
Рис.1. Время работы последовательного теста на языке Python
Рис.2. Время работы параллельного теста на языке Python
Обратим внимание, что параллельный вариант почти в два раза медленнее аналогичного последовательного. При этом, если мы создадим три потока, то и результат замедлится пропорционально (см. рис. 3). Из этого можно заключить, что увеличение числа потоков ведет к кратному увеличению времени работы. Если не лезть под капот, то на текущем уровне понимания Python это может выглядеть, как мистика.
Рис.3. Тест CPU на трех потоках на языке Python
Прежде чем перейти к созданию автоматного кода и тестированию в среде ВКП(а), рассмотрим реализацию автоматов вне ее. Эквивалентная алгоритму исходной статьи модель в форме графа автомата показана на рис. 4. Из разнообразия возможных вариантов (см., к примеру, статью) рассмотрим наиболее типовой и известный — в формате, так называемой, SWITCH-технологии (подробнее о ней см. на сайте ИТМО).
Далее мы будем сравнивать программу на Python с реализацией на С++. Соответствующий графу код на С++ с кодом его запуска (см. функцию main) приведен на листинге 3.
Рис.4. Автоматная модель CPU-зависимой функции
Листинг 3. Реализация теста на С++
class FsmCount
{
public:
FsmCount(int n) { nCount = n; nState = 0; };
void ExecOneStep();
int nState;
protected:
int nCount;
int x1();
void y1();
};
#include "FsmCount.h"
int FsmCount::x1() { return nCount > 0; }
void FsmCount::y1() { nCount--; }
void FsmCount::ExecOneStep()
{
switch (nState) {
case 0:
if (x1())
y1();
else nState = 1;
break;
}
}
#include <QCoreApplication>
#include <QTime>
#include "FsmCount.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
QTime time;
FsmCount *pFsmCount{nullptr};
pFsmCount = new FsmCount(100000000);
time.start();
while (!pFsmCount->nState)
pFsmCount->ExecOneStep();
double dTime = QString::number(time.elapsed()).toDouble();
printf("%f", dTime);
if (pFsmCount) delete pFsmCount;
return a.exec();
}
Время работы теста на упомянутой аппаратной базе находится в пределах 250 мсек. Это более чем в 55 раз быстрее по сравнению с кодом Python. Сравнение проведено с параллельным вариантом тестирования для двух потоков (см. рис.2).
Но скорость можно повысить еще больше, если функцию вычислять, не выходя за пределы действия/метода y1 (см. листинг 4). В результате скорость теста уменьшилась до менее чем 1 мсек (точнее сказать сложно, т.к. тест выдает значение равное нулю). Если взять за основу даже это значение, то скорость получаем более чем в 14000 (!) раз выше, чем на Python. Становится понятным, почему С++ отдают предпочтение при проектировании тех же систем реального времени.
Листинг 4. Вариант быстрого метода для класса FsmCount
void FsmCount::y1() {
while (nCount>0)
nCount--;
}
Наша дальнейшая цель — сравнение Python со средой ВКП(а). Автоматный тест, как и выше, должен соответствовать модели на рис. 4. Его код демонстрирует листинг 5.
Листинг 5. Автоматная программа теста CPU
#include "lfsaappl.h"
#include <QTime>
class FCount :
public LFsaAppl
{
public:
LFsaAppl* Create(CVarFSA *pCVF) { Q_UNUSED(pCVF)return new FCount(nameFsa); }
bool FCreationOfLinksForVariables();
FCount(string strNam);
CVar *pVarCount;
CVar *pVarExtVarCount{nullptr};
CVar *pVarStrNameExtVarCount;
CVar *pVarWorkingHours;
protected:
int x1(); int x12();
void y1(); void y2(); void y3(); void y12();
QTime time;
};
#include "stdafx.h"
#include "FCount.h"
static LArc TBL_Count[] = {
LArc("st", "st","^x12","y12"),
LArc("st", "s1","x12", "y2"),
LArc("s1", "s1","x1", "y1"),
LArc("s1", "st","^x1", "y3"),
LArc()
};
FCount::FCount(string strNam):
LFsaAppl(TBL_Count, strNam)
{ }
bool FCount::FCreationOfLinksForVariables() {
pVarCount = CreateLocVar("n", CLocVar::vtInteger, "local counter");
pVarStrNameExtVarCount = CreateLocVar("strNameExtVarCount", CLocVar::vtString, "external counter name");;
string str = pVarStrNameExtVarCount->strGetDataSrc();
if (str != "") { pVarExtVarCount = pTAppCore->GetAddressVar(pVarStrNameExtVarCount->strGetDataSrc().c_str(), this); }
pVarWorkingHours = CreateLocVar("strWorkingHours", CLocVar::vtString, "working hours");
return true;
}
int FCount::x1() { return pVarCount->GetDataSrc() > 0; }
int FCount::x12() { return pVarExtVarCount != nullptr; }
void FCount::y1() {
int n = int(pVarCount->GetDataSrc());
pVarCount->SetDataSrc(this, --n);
}
void FCount::y2() {
time.start();
pVarCount->SetDataSrc(this, pVarExtVarCount->GetDataSrc());
}
void FCount::y3() {
pVarWorkingHours->SetDataSrc(nullptr, QString::number(time.elapsed()).toStdString(), nullptr);
}
void FCount::y12() { FInit(); }
Время исполнения теста в пределах 5.35 сек при количестве циклов 100000. Т.е. он, написанный на быстром С++, работает более чем в 2600 раз (!?) медленнее параллельного теста на Python. Такой результат не может не огорчать :( Но отметим, что длительность дискретного такта при этом равно 0.0535 мсек. Например, стандартный цикл ПЛК типа ОВЕН-100 равен 1 мсек, а поэтому с точки зрения систем управления реального времени результат вполне достойный. Хотя, еще раз, на первый взгляд результат не в пользу АП, т.к. и код объемный, да и скорость вызывает определенную тревогу (например, для чисто вычислительных задач).
Использование С++ в качестве языка проектирования ВКП(а) позволяет достаточно просто решить возникшую проблему скорости. Листинг 6 демонстрирует код автомата, использующего стандартные системные потоки на базе класса QThread библиотеки Qt. В результате время упало до 70-80 мсек даже при увеличении циклов до 100000000. Таким образом, тест, использующий поток, работает уже в 200 раз быстрее, чем на Python.
Заметим, что полученный результат представляет замедленную версию теста, синхронизированную со средой ВКП(а). Если закомментировать строку (листинг 6):
while (bIfExecuteStep) { bIfExecuteStep = false; }, то время «рухнет» до 1 мсек и менее. В результате скорость по отношению к Python уже будет выше более чем в 14000 раз.
Замечание 1. Флаг bIfExecuteStep управляется средой ВКП(а). Устанавливается ею в начале текущего дискретного такта. Введен для синхронизации с дискретным временем автоматного пространства процесса.
С целью увеличения скорости мы создали комбинацию автомата и потока, где последний реализует нужную функциональность, а автомат — его обертка. Получился достаточно специфический объект, но и мы решали прежде всего задачу увеличения скорости работы, которую в результате и решили.
Листинг 6. Тест CPU на базе потока
#include "lfsaappl.h"
#include <QThread>
#include <QTime>
class QCount;
class ThCount : public QThread
{
Q_OBJECT
public:
ThCount(QCount *p, QObject *parent);
protected:
bool bIfRun{false};
bool bIfStop{false};
bool bIfExecuteStep{false};
QCount *pQCount;
void run();
friend class QCount;
};
class QCount :
public LFsaAppl
{
public:
void ExecuteThreadStep();
void WaitForThreadToFinish();
LFsaAppl* Create(CVarFSA *pCVF) { Q_UNUSED(pCVF)return new QCount(nameFsa); }
bool FCreationOfLinksForVariables();
QCount(string strNam);
virtual ~QCount(void);
ThCount *pThCount{nullptr};
CVar *pVarCount;
CVar *pVarExtVarCount;
CVar *pVarStrNameExtVarCount;
CVar *pVarWorkingHours;
protected:
int x1(); int x12();
void y1(); void y2(); void y12();
QTime time;
friend class ThCount;
};
#include "stdafx.h"
#include "QCount.h"
#include <QTimer>
static LArc TBL_Count[] = {
LArc("st", "st","^x12","y12"), //
LArc("st", "s2","x12", "y1"), //
LArc("s2", "s3","^x1", "y2"), //
LArc("s3", "s2","^x1", "--"), //
LArc()
};
QCount::QCount(string strNam):
LFsaAppl(TBL_Count, strNam, nullptr, nullptr)
{ }
QCount::~QCount(void) { }
bool QCount::FCreationOfLinksForVariables() {
pVarCount = CreateLocVar("n", CLocVar::vtInteger, "local counter");
pVarExtVarCount = nullptr;
pVarStrNameExtVarCount = CreateLocVar("strNameExtVarCount", CLocVar::vtString, "external counter name");;
string str = pVarStrNameExtVarCount->strGetDataSrc();
if (str != "") { pVarExtVarCount = pTAppCore->GetAddressVar(pVarStrNameExtVarCount->strGetDataSrc().c_str(), this); }
pVarWorkingHours = CreateLocVar("strWorkingHours", CLocVar::vtString, "working hours");
return true;
}
void QCount::ExecuteThreadStep() { if (pThCount) pThCount->bIfExecuteStep = true; }
void QCount::WaitForThreadToFinish() {
if (pThCount) {
// завершить поток
pThCount->bIfRun = false;
pThCount->quit();
pThCount->wait(500);
pThCount->terminate();
}
delete pThCount;
}
int QCount::x1() { return pVarCount->GetDataSrc() > 0; }
int QCount::x12() { return pVarExtVarCount != nullptr; }
// создаем поток
void QCount::y1() {
pThCount = new ThCount(this, pTAppCore->pMainFrame);
}
void QCount::y2() { pVarCount->SetDataSrc(this, pVarExtVarCount->GetDataSrc()); }
void QCount::y12() { FInit(); }
// поток поток поток поток поток поток поток поток поток поток поток поток поток
ThCount::ThCount(QCount *p, QObject *parent) :
QThread(parent)
{
pQCount = p;
bIfRun = true; // установить признак запуска/завершения потока
start(QThread::IdlePriority); // запустить поток
}
// цикл исполнения потока
void ThCount::run()
{
bIfStop = false; // сбросить признак останова потока
pQCount->pVarWorkingHours->SetDataSrc(nullptr, "", nullptr);
pQCount->pVarCount->SetDataSrc(pQCount, pQCount->pVarExtVarCount->GetDataSrc());
pQCount->pVarCount->UpdateVariable();
while(bIfRun) {
if (pQCount->pVarCount->GetDataSrc() > 0) {
bIfExecuteStep = false;
int n = pQCount->pVarCount->GetDataSrc();
if (n>0) {
pQCount->time.start();
}
pQCount->time.start();
while (n>0) {
n--;
while (bIfExecuteStep) { bIfExecuteStep = false; }
}
string str = QString::number(pQCount->time.elapsed()).toStdString();
pQCount->pVarWorkingHours->SetDataSrc(nullptr, QString::number(pQCount->time.elapsed()).toStdString(), nullptr);
pQCount->pVarCount->SetDataSrc(pQCount, 0.0);
while (n<=0) {
n = int(pQCount->pVarCount->GetDataSrc());
}
}
}
bIfStop = true; // установить признак останова потока
}
Рассмотрим еще один тест, обратив внимание на время работы потоков. Поскольку они абсолютно одинаковы, то, запущенные одновременно, они должны одновременно и завершить работу. Если для Python это справедливо лишь в пределах определенной погрешности (см. рис. 5), то для процессов в ВКП(а) время полностью совпадает (см. рис. 6). Заметим, что дополнительно созданный объект-секундомер, определяющий время работы теста извне его, показывает фактически такое же время, как и время, отмеряемое самим тестом/тестами (см. листинг 4).
Замечание 2. «Секундомер» — автоматный процесс, начинающий отсчет, когда контролируемый процесс попадает в состояние «s1» и фиксирующий время, когда тот переходит в состоянии «st» (см. таблицу переходов автомата на листинге 4).
Рис.5. Время работы тестов в Python
Рис.6. Время работы тестов в среде ВКП(а)
Автоматы в сравнении с другими моделями имеют дискретное время. Величина дискретного такта может быть фиксированной для синхронных автоматов или плавающей — для асинхронных (классификация по Глушкову В.М.). Следующим тестом будет проверка среды ВКП(а) на синхронность — способность поддерживать постоянное значение такта дискретного времени. Напомним, что режим синхронной работы автоматов особенно востребован при проектировании систем автоматического управления (см. подробнее [1]). Одновременно подобный режим служит примером реализации фактической независимости вычислительной модели от скорости CPU.
Время работы теста при дискретном такте (в теории автоматического управления (ТАУ) именуемом интервалом квантования) длительностью 1 мсек и числе циклов 100000 должно быть 100 сек. Полученные при тестировании результаты демонстрирует рис. 7.
Рис.7. Тестирование в синхронном режиме (1 мсек)
Основное тестирование мы фактически закончили и теперь можно обсудить объем кода, т.к., глядя на листинг 3, критики не преминут указать на это. Но они в очередной раз забудут о том, о чем не раз уже говорилось. Код включает оболочку, организующую взаимодействие со средой ВКП(а). Какой вид примет автомат, если ее исключить, поясняет листинг 7, представляющий чистый код автоматной функции.
Листинг 7. Чистый код автомата
#include "lfsaappl.h"
extern LArc TBL_CountMini[];
class FCountMini :
public LFsaAppl
{
public:
FCountMini(string strNam): LFsaAppl(TBL_CountMini, strNam) {};
int nCount;
protected:
int x1();
void y1();
};
#include "stdafx.h"
#include "fcountmini.h"
LArc TBL_CountMini[] = {
LArc("с1", "с1","x1", "y1"),
LArc("с1", "00","^x1", "--"),
LArc()
};
int FCountMini::x1() { return nCount > 0; }
void FCountMini::y1() { --nCount; }
Получилось, не правда ли, заметно проще, хотя время работы осталось прежним. Но, как мы уже выяснили, время функции, заключенной в поток, составляет буквально единицы микросекунд. Подобное действие уже было рассмотрено (см. листинг 4). С ним время теста будет исчисляться, как и ранее, микросекундами (см. рис. 8).
Таким образом, многие проблемы автоматных программ можно разрешить, если представлять, как можно управлять их эффективностью. Возможности С++ в этом смысле фактически ни чем не ограничены.
Рис.8. Результаты тестирование действия y1 (листинг 6).
Осталось рассмотреть «автоматную обертку» для функции в листинге 7. Ее демонстрирует листинг 8. Код объемный, но, еще раз, типовой, выполняющий стандартные для среды функции.
Листинг 8. Обертка для автоматной функции на листинге 5
#include "lfsaappl.h"
#include <QTime>
class FCountMini;
class FCount :
public LFsaAppl
{
public:
LFsaAppl* Create(CVarFSA *pCVF) { Q_UNUSED(pCVF)return new FCount(nameFsa); }
bool FCreationOfLinksForVariables();
FCount(string strNam);
virtual ~FCount(void);
CVar *pVarCount;
CVar *pVarExtVarCount{nullptr};
CVar *pVarStrNameExtVarCount;
CVar *pVarWorkingHours;
protected:
int x1(); int x12();
void void y3(); void y4(); void y12();
QTime time;
FCountMini *pCountMini{nullptr};
};
#include "stdafx.h"
#include "FCount.h"
#include "fcountmini.h"
static LArc TBL_Count[] = {
LArc("st", "s1","--","y4"),
LArc("s1", "st","--","y3"),
LArc()
};
FCount::FCount(string strNam):
LFsaAppl(TBL_Count, strNam)
{ }
FCount::~FCount(void)
{
if (pCountMini) delete pCountMini;
}
bool FCount::FCreationOfLinksForVariables() {
pVarCount = CreateLocVar("n", CLocVar::vtInteger, "local counter");
pVarStrNameExtVarCount = CreateLocVar("strNameExtVarCount", CLocVar::vtString, "external counter name");;
string str = pVarStrNameExtVarCount->strGetDataSrc();
if (str != "") { pVarExtVarCount = pTAppCore->GetAddressVar(pVarStrNameExtVarCount->strGetDataSrc().c_str(), this); }
pVarWorkingHours = CreateLocVar("strWorkingHours", CLocVar::vtString, "working hours");
return true;
}
int FCount::x1() { return pVarCount->GetDataSrc() > 0; }
int FCount::x12() { return pVarExtVarCount != nullptr; }
void FCount::y3() {
pVarWorkingHours->SetDataSrc(nullptr, QString::number(time.elapsed()).toStdString(), nullptr);
}
void FCount::y4() {
time.start();
if (pCountMini) delete pCountMini;
pCountMini = new FCountMini("CountMini");
pCountMini->nCount = pVarExtVarCount->GetDataSrc();
pCountMini->FCall(this);
}
void FCount::y12() { FInit(); }
Итак, можно подвести итоги. В общем случае автоматы в ВКП(а) работают медленнее почти в 2600 раз в сравнении с процессами на Python. Такова фактически оценка «автоматного интерпретатора» среды ВКП(а). С одной стороны, в этом сокрыты колоссальные резервы роста, а, с другой, с точки зрения реактивности среды даже такой скорости вполне достаточно. Но, напомним, использование потоков позволяет справиться и с этой проблемой уже сейчас и, наоборот, на этой базе быть быстрее Phython более чем в 200 раз. В дополнение к потокам существует даже более простое и теоретически более верное «автоматное решение» — вызов проблемной функции в рамках одного или нескольких действий (аналог «разделения операции или процесса на чанки» см. статью). В любом случае с С++ ситуация в АП с точки зрения производительности программ не выглядит безвыходной, а в определенной ситуации (проектирование, например, систем реального времени) даже выигрышная.
И в заключение немного о том, что выходит за пределы простого тестирования. Меня зацепила статья. Я согласен с тем, что «хватит уже бояться субъективно красивых решений в коде». С одной существенной поправкой — я за объективность. Код автоматной программы может казаться громоздким (что достаточно поправимо), не очень красивым (это весьма субъективно) и даже не устраивать по скорости (здесь, как мы убедились, в АП есть решение и не одно), но постижение его сути открывает скрытую от стороннего взгляда красоту. Причем красоту объективную.
Что здесь выступает критерием объективности? Теория. В нашем случае — теория автоматов. Ее реализация, как бы она не выглядела, по определению не может быть некрасивой ;) И наоборот, если реализация не соответствует ей, то как бы выигрышно она не выглядела, она не имеет, как правило, перспективы с точки зрения теории. А потому в каком бы запале ни пропагандируй SWITCH-технологию, как ни расхваливай UniMod, но если они не соответствуют требованиям теории автоматов, искажая ее красоту, то мы поневоле и объективно сталкиваемся с ситуацией, что «автомат многим не друг». И одними «камланиями» и «танцами с бубном» такую ситуацию не исправишь. Но, если следовать теории, этого и не понадобится.
Пуская критические стрелы в сторону автоматов, я, как тот «вшивый о бане», не мог не вспомнить о корутинах ;) Хотелось бы их тоже протестировать, а заодно и оценить их красоту, т.к. неужели красота «конструкций», подобных представленным на рис. 9 (см. также), которые реализуют, если не ошибаюсь, два параллельных (?) оператора a = a-b и b = a+b, могут вызывать хоть минимальные приступы восхищения?
Рис.9. Пример корутин
Может быть этот код даже эффективен, а для кого-то несомненно красив, но речь-то о другом. Я здесь не о маниакальном желании описать параллелизм шаблонами последовательного мышления. Хотя это, если уж прямо, напрягает, т.к. мышление нужно менять. Я совсем о другом. Есть ли независимая от языка программирования теория корутин, которая позволяла бы просто и наглядно преодолеть «загогулины» языка (см. еще раз рис. 9) и дать однозначный ответ на заданный вопрос? В отношении корутин я такой теории не знаю, хотя уже, если честно, обыскался ;) Для конечных автоматов — это теория автоматов, в которой автомат — всегда автомат в любом виде (граф, таблица, матрица и т.п.) вне связи с языком/языками программирования.
Дернув за, казалось бы, простейшую «тестовую ниточку», мы затронули клубок… параллельных проблем. Может быть, правда, лишь немножко его распушили. А начали-то, если кто еще не забыл, с элементарной CPU-зависимой функции.
Кто же мог подумать, во что это выльется… :)
Литература
1. Мирошник И.В. Теория автоматического управления. Линейные системы. — СПб.: Питер, 2005. — 336 с.
shred_dev_sda
=_= мое лицо когда питонский threading называют паралелизмом.
lws0954 Автор
Чем же он Вас так достал? И чем он отличается от любого другого threading?
loltrol
Ну хотя бы тем, что даже в офф-доке написано, что в любой момент времени python код может выполнятся только в одном потоке. Threading в python использовать в cpu задачах с таким ограничением так себе идея :)
lws0954 Автор
Не очень важно, что под капотом. Много важнее — как ездит «машина» и насколько она соответствует описанию. Если не устраивает просто скорость, то иногда проще заменить двигатель, чем машину целиком на тот же самолет. Вот примерно такая идея :)
fougasse
GIL