
Результаты тестирования Oracle Coherence
Недавно мы участвовали в конкурсе по тестированию кластерных технологий In-Memory. Целью тестирования был выбор решения для разработки отказоустойчивых фронтальных компонент высоконагруженных систем. C нашей стороны был представлен Oracle Coherence.

Условия соревнования были весьма жесткими: например, предполагалось загрузить в кластер распределенного кэша около 1 млрд записей с последующей обработкой около 100 млн транзакций.
Требовалось проверить:
- Скорость обработки транзакций (как время обработки одной транзакции, так и общая пропускная способность).
- Эластичность кластера, т. е. зависимость производительности от количества узлов и копий данных.
- Устойчивость кластера к сбоям.
Условия тестирования распределенного кэш-кластера менялись от комфортных, когда ресурсов больше, чем требуется, до экстремальных. Репликацию данных на удаленный кластер и восстановление кластера после полной остановки проверять не требовалось.
Архитектура
Стенд для тестирования был построен в клиент-серверной архитектуре. Для обработки транзакций независимая компания разработала клиентское приложение, эмулирующее внешнюю среду. Каждый клиент-процесс соединялся с одним бизнес-узлом кластера, параметры транзакции передавались URL-запросом по протоколу HTTP-POST, TCP-соединение в ходе тестирования не закрывалось. Транзакции обрабатывались в двух режимах — построчном (чтение из файла по строке, сборка запроса, запрос и выполнение в кэш-кластере) и пакетном (с предварительной загрузкой пакета транзакций и их единовременным исполнением). Серверов нагрузки было два, и в максимальной конфигурации запускалось по 144 клиентских процесса на сервер, т. е. 288 активно работающих агентов.
Конфигурация
Теперь немного о структуре нашего Coherence кластера. Мы использовали новейшие версии решений Oracle — строили домен WebLogic 12c и на нем внедряли кэш-кластер Coherence 12c (и то, и другое — 12.1.3). Всего нам предоставили десять отдельно стоящих физических серверов с объемом оперативной памяти 256 ГБ и под управлением CentOS 7.0. В нашем распоряжении был сетевой коммутатор по два 10G Ethernet-порта на сервер, JDK: 7u75-linux-x64. Два сервера (2xE5-2640@2.5GHz) предназначались под нагрузку, остальные восемь (2xE5-2670 2.6GHz) — для кэш-кластера Coherence. Судейская комиссия снимала показания системной статистики (совокупную нагрузку на процессор без разбивки по ядрам, характеристики сетевых взаимодействий, использование памяти и т. п.). Весь процесс обработки транзакций отображался в журналах клиентов нагрузки, протоколирование процессов в кэш-кластере не отключалось, что, разумеется, слегка тормозило процессинг. Одним словом, условия тестирования напоминали события в «черную пятницу».
Бизнес-логика и решение
Теперь немного о структуре решения. У нас не было proxy-слоя (тестирование не касалось вопросов безопасности и контроля), Java-клиент отправлял запросы на один из серверов бизнес-слоя (рис. 1).
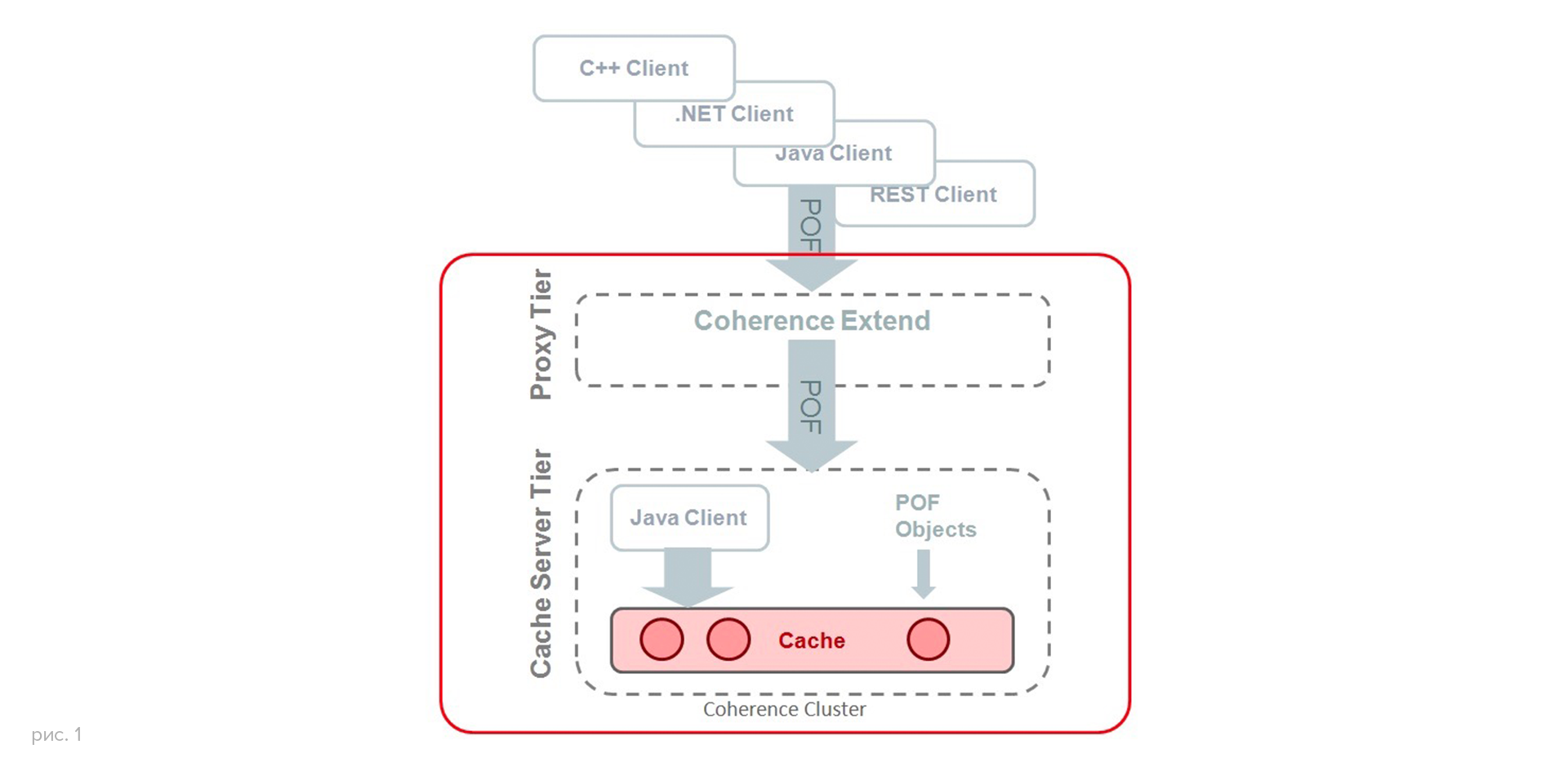
Всего было три кэша: Transfers, Credits и Accounts. Приводим фрагмент POF-файла:
<?xml version="1.0"?>
<cache-config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.oracle.com/coherence/coherence-cache-config"
xsi:schemaLocation="http://xmlns.oracle.com/coherence/coherence-cache-config coherence-cache-config.xsd">
<defaults>
<serializer system-property="tangosol.coherence.serializer">pof</serializer>
<socket-provider system-property="tangosol.coherence.socketprovider"/>
</defaults>
<caching-scheme-mapping>
<cache-mapping>
<cache-name>accounts</cache-name>
<scheme-name>normal-distributed</scheme-name>
</cache-mapping>
<cache-mapping>
<cache-name>transfers</cache-name>
<scheme-name>rwbm-distributed</scheme-name>
<init-params>
<init-param>
<param-name>cachestore.class</param-name>
<param-value>com.oracle.coherence.TransfersCacheStore</param-value>
</init-param>
</init-params>
<interceptors>
<interceptor>
<instance>
<class-name>com.oracle.coherence.DebitAccountInterceptor</class-name>
</instance>
</interceptor>
</interceptors>
</cache-mapping>
<cache-mapping>
<cache-name>credits</cache-name>
<scheme-name>normal-distributed</scheme-name>
<interceptors>
<interceptor>
<instance>
<class-name>com.oracle.coherence.CreditAccountInterceptor</class-name>
</instance>
</interceptor>
</interceptors>
</cache-mapping>
</caching-scheme-mapping>
<caching-schemes>
<distributed-scheme>
<scheme-name>normal-distributed</scheme-name>
<service-name>DistributedCache</service-name>
<thread-count>10</thread-count>
<partition-count>4093</partition-count>
<backup-count>1</backup-count>
<backing-map-scheme>
<local-scheme>
<scheme-ref>binary-backing-map</scheme-ref>
</local-scheme>
</backing-map-scheme>
<autostart>true</autostart>
</distributed-scheme>
…Кэш Accounts содержал объекты AccountData (включая, разумеется, баланс). Соответственно, остальные кэши отображали движение дебетов и кредитов. Transfers и Credits использовали объекты TransactionKey как ключи с их последующей трассировкой при проведении платежа. Для перевода средств между двумя счетами создавался экземпляр класса Transfers, и ключ TransactionKey (посредством метода transfer.makeKey()) использовался для поиска дебетового счета. По сути, нужно было лишь вставить объект Transfers в кэш Transfers — это событие вовлекало класс DebitAccountInterceptor, который атомарно выполнял дебетовую операцию. Одновременно в атомарную очередь кредитных операций добавлялся новый запрос. Последующая операция cache.put(transfer.makeKey(), transfer) тоже атомарно обновляла, сохраняла и возвращала значение баланса, а затем выполняла запрос из очереди кредитных операций, которые, в свою очередь, также обновляли значение баланса — в полном соответствии с классическими правилами бухгалтерского учета. Все эти манипуляции были защищены от сбоев, так как использовали кэши и очереди с обратной записью (write-behind queue). В случае отказа кэш Credits сохранял данные, которые при необходимости могли быть использованы для отката транзакции. По завершении транзакции Transfers объект удалялся из кэшей. На этом цикл заканчивался. Повторюсь, мы строили не промышленное решение, а стенд для проверки производительности, эластичности и устойчивости кластера.
Данные как «соль» кластера...
Далее расскажу о данных и их размерах. Сколько «стоит» такой кластер — сколько нужно оперативной памяти, процессоров и т. д.
Теоретически объем кластера Coherence превышает объем данных, т. е. объем одного кэш-объекта, умноженный на количество кэш-объектов, как минимум в три раза — с учетом объема данных резервного копирования и метаданных самого кэш-кластера (классов, временных объектов, трансферно-сетевых буферов и т. п.). Цифры, полученные в результате нагрузочного тестирования, подтверждают этот расчет (табл. 1). Отсюда вывод: первичное планирование размера единицы объекта кэша имеет далекоидущие последствия и весьма по-разному отвечает на вопрос «сколько это стоит»…

Отдельный вопрос — как рассчитать JVM heap size и количество узлов кэш-кластера. Ответ: весьма по-разному. Рекомендации общеизвестны: нужно иметь два процессорных ядра на узел, стараться не раздувать размеры heapSize сверх 24 ГБ (хотя есть системы и с гораздо более большими размерами), учитывать накладные расходы JVM (overhead) и не забывать о резерве памяти для защиты от «эффекта домино» (когда при «падении» одного из физических серверов лавинообразно рушится весь кластер во время миграции и перераспределения данных кластера на оставшиеся «в живых» рабочие узлы), но в этом случае даже скорость сети косвенно влияет на размер…
В нашем случае количество физических серверов в кластере менялось от четырех до восьми. Четыре сервера (с оперативной памятью по 256 ГБ каждый!) оказались предельным минимумом для данного кэш-кластера Coherence. Oracle рекомендует строить подобные системы как минимум из пяти физических машин. Зато решение продемонстрировало прекрасную эластичность, кластер «растягивался» и вертикально, и горизонтально. Пропускная способность линейно росла, параметр heapSize менялся от 24 до 16 ГБ, ядер CPU было в достатке, и никаких лишних вопросов не возникло.
Разделяй и властвуй – мудрое правило
Сегодня управление кэш-кластером Coherence – это рутина. Нет больше драйва, романтики первопроходцев RC скриптования, восторженного почитания народа из техподдержки. С приходом контейнеров Coherence (Coherence Grid Archive или GAR), соответствующим парадигме Java EE и аналогичным моделям EJB, JMS, JCA, слой данных кластера Coherence развертывается как обычное приложение на WebLogic-сервере, а бизнес-слой — как приложение EAR (рис. 2).
Причем следует упомянуть, что введено понятие storage enabled/disabled, т. е. можно или нельзя хранить данные в Coherence сервере или кластере, по сути, изоляция данных посредством вышеупомянутого мудрого правила…
Структура нашего WebLogic домена отражена на рис. 3
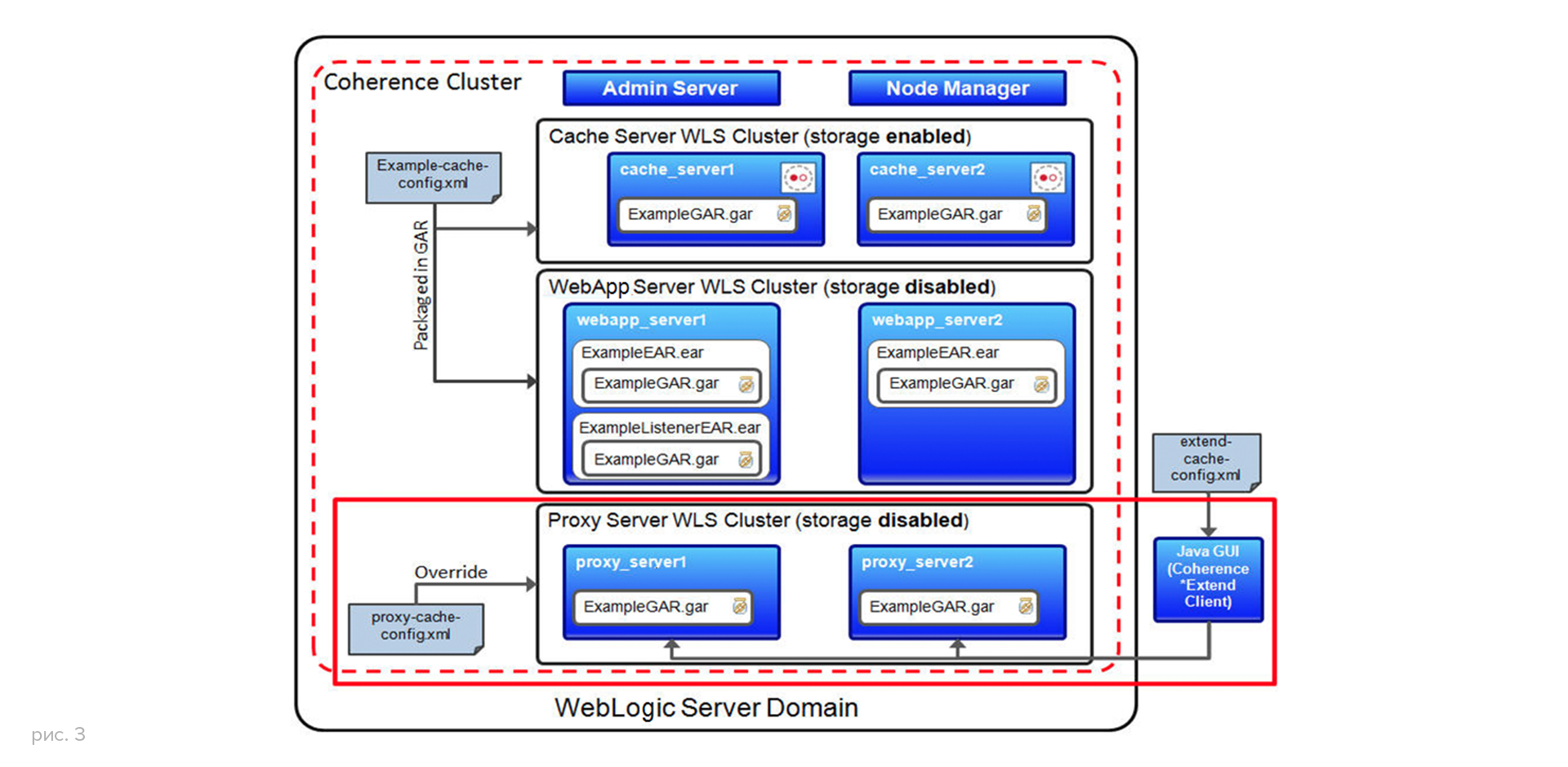
Поскольку наш кэш-кластер Coherence состоял всего из двух независимых слоев: слоя приложений (бизнес-слой) и слоя данных, – была возможность обеспечить управление доменом при помощи двух отдельных кластеров WebLogic. Каждый кластер, в свою очередь, представлял один из вышеуказанных слоев, при этом оба они входили в кластер Coherence (разделяй и властвуй). Кстати, новая единая модель управления серверами, существующая с версии 12.1.2, позволяет управлять десятками, а то и сотнями управляемых серверов Coherence (теперь так называются узлы кластера). Администратору WebLogic ничего не стоит поменять heap size для кэш-кластеров, состоящих из сотен серверов (в нашем случае — до 80), запустить или остановить кэш-кластер и т. п. Можете по-прежнему пользоваться скриптами WLST или JMX. Но наивысшую степень комфорта от работы вы получите с Enterprise Manager 12c.
Штормы, бури, ураганы...
Traffic/Unicast/Multicast storm или «широковещательный шторм» — событие прогнозируемое и ожидаемое в веселые дни новогодних распродаж, акций и прочих «ликвидаций», не сулящих ничего хорошего ИТ-people продуктивного звена. Так называется сетевое перераспределение данных и метаданных при падении узла или целого сервера в составе Coherence-кластера… Ибо тогда мы и познаем всю прозорливость архитекторов проекта, надежность самого решения и их способность ликвидировать последствия ИТ-стихии! Поэтому наше соревнование предполагало и такой сценарий.
По сценарию, приблизительно равному половине исполнения теста, одна из «серверных» машин выключалась командой «shutdown -h now», и… грянул 10-ти GigE балльный шторм! Вся система, особенно кластер, напряглась до 100%-ной загрузки процессоров, транзакции замерли, роутеры «накалились» — но кэш-кластер выжил!
Последующая проверка целостности данных подтвердила устойчивость Coherence к сбоям такого рода. В следующей версии Coherence 12.2.1 будет возможно восстанавливать состояние данных даже при полном «кластерокрушении» в «идеальный траффик-шторм»…
Цифры говорят
Ниже я представляю вашему вниманию сводную таблицу тестов.
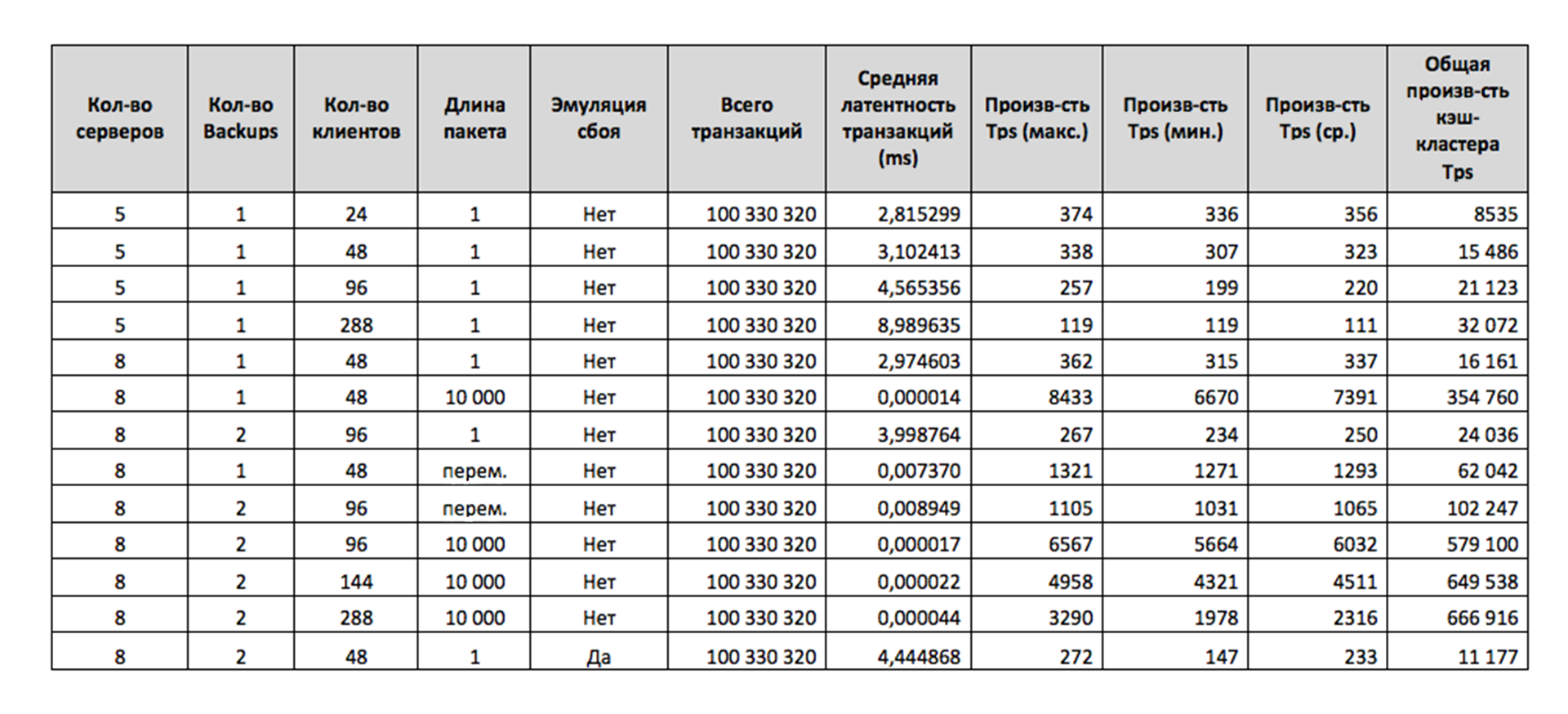
Там, где количество серверов равно 5-ти, означает, что 4 сервера работали под кэш-кластер (GAR приложение) и на 5-ти запускали бизнес-приложение (EAR). Общее количество узлов кэш-кластера при 5-серверной архитектуре — 40 узлов слоя данных (heapSize 24 ГБ), 10 узлов бизнес-слоя (heapSize 1 ГБ). При 8-серверной архитектуре — 64 узла слоя данных (heapSize 16 ГБ), 16 узлов бизнес-слоя (heapSize 1 ГБ). Переменная длина пакета означает, что длина пакета не фиксировалась и определялась как значение аргумента в запросе клиента на обработку. Тест с эмуляцией сбоя — это то самое испытание на устойчивость кластера к «широковещательному шторму». Средняя латентность транзакций исчисляется как среднее время теста, деленное на среднее число транзакций.
Хотел бы поделиться важной, на мой взгляд, информацией о скорости загрузки и выгрузки данных в кластер:
- Распределенная загрузка данных: 991 879 015 счетов в кластер (собственно разогрев кластера) — в среднем 317 сек., или около 3 128 956 счетов в секунду.
- Распределенная выгрузка данных: 991 879 015 счетов из кластера — 112 сек., или 8 856 063 счетов в секунду.
Цифры говорят
Предвидя разочарование читателя по поводу «а где же сравнение с конкурентами?», отвечу. Во-первых, данные конкурентов, к нашему большому сожалению, не предоставлялись. Во-вторых, условия, в которых тестировались IMDG, лично мне не показались идеальными (экстремальные сроки на проведение тестов, медленные каналы FTP при массивных логах, разные диалекты OS и т. п.).
Общие замечания ко всем тестам:
- Слабая загрузка системы, т. е. 96 клиентских сессий (заявленная как крейсерская) для такой системы не нагрузка. Нам не удалось загрузить процессоры кэш-кластера Coherence более чем на четверть, даже когда мы разогнались до скорости около 660 тыс. транзакций в секунду.
- Обработка в пакетном режиме (batch > 1) выдает результаты в десятки/сотни раз выше, чем одиночная обработка, понятно, что основное время тратится на вызов сервиса.
- По нашим оценкам реальную производительность Coherence системы на предоставленном оборудовании можно было поднять до миллиона транзакций в сек, если увеличить количество клиентов и размер пакета обработки.
Главное из данного события – состоялось настоящее соревнование систем на основе IMDG, а не маркетинговых заявлений, в котором решение Oracle Coherence с блеском подтвердило свою репутацию одного из лучших в мире.
Комментарии (6)

ibKpoxa
27.08.2015 15:05+2>> Однако по итогам тестирования Oracle Coherence – в тройке лидеров, о чем я вам с удовольствием и сообщаю.
Это значит, что тестирование было для как минимум у трех программных продуктов, какие были неназванные 2 конкурента?

VladislavLysov
28.08.2015 16:24Интересует сравнение с Gigaspaces. И был ли представлен GridGain? Имею опыт построения огромного кластера с высокой нагрузкой на Gigaspaces. Хотел посмотреть, в данном примере что было лучше / хуже, по каким критериям и почему.
Optik
Где ж вы транзакции замеряли, что они до 17нс опускаются?
romychs
Ну какие могут быть сомнения, неужели Вы думаете, что за время, за которое одно ядро процессора на 2,6GHz успевает выполнить до 44 инструкций, нельзя успеть Обработать запрос на AS Weblogic, передать его по сети на кластер Coherence найти данные и вернуть все обратно? ;)
Coherence, конечно, крутая штука, особенно, если нужна интеграция с другими продуктами оракла.
Но если смотреть на цены, Couchbase, например, с поддержкой выйдет на порядок дешевле (есть еще и community edition).
gurinderu
Насколько я помню, Couchbase совершенно для других вещей.
Хотелось бы сравнения к примеру с Apache Ignite.
warlog
Optik Avg Processing Time (s) / Avg # Trx *1000/10000