

Проекту Lingualeo уже 10 лет. Более 23 миллионов человек из России, Турции, Испании и стран Латинской Америки учат с помощью нашего сервиса английский.
LinguaLeo создавали в конце нулевых – начале десятых годов и использовали передовые на тот момент технологии и методы. Но прошло время, и они сильно устарели. Так что мы решили, что систему пора обновить.
Мы попросили нашего лидера бэкэнд разработки, Олега Правдина, рассказать о том, как они с командой параллельно с поддержкой основного продукта собрали новую модульную структуру сервиса на базе PostgreSQL, перенесли бизнес-логику в базы данных и провели миграцию с миллионами пользователей.
Проблемы зрелого продукта
«Я пришёл в Lingualeo в августе 2018 руководить бэкэнд разработкой. Тогда бэком занималась команда из 8 разработчиков и 2 админов, которые обслуживали монолит на 1 миллион строк кода преимущественно на PHP. Чтобы внедрить даже небольшую новую фичу, уходило 2 месяца. А затраты на инфраструктуру на 10 000 активных пользователей превышали 1 000 $ в год.
Как это произошло? Дело в том, что за 10 лет в проекте сменилось несколько команд разработки. Приходили новые люди, как и я, они по-своему добавляли новые модули и фичи. Команды менялись, новички не всегда понимали, как работают старые части системы, в итоге код Lingualeo постепенно превратился в чёрный ящик: непрозрачная логика в бэкенде, перегруженный фронт, обилие костылей, большие пробелы в документации.
Всего у нас в штате было 20 разработчиков, но развивать продукт было невозможно: если что-то добавить, вылезали неожиданные проблемы. У команды уходило 2–3 недели, чтобы всё починить. Разработчики занимались поддержкой кода из 2013 года, и ресурсов на обновление функциональности не было.
С такими проблемами сталкивается большое количество компаний, которые развивают зрелые ИТ-продукты, написанные на технологиях десятилетней давности. Тренды меняются, но из-за старой архитектуры не все новинки можно использовать.
Продукт развивается и обрастает функциями, но их не успевают подробно документировать. Эти проблемы решают по-разному, но мы решили так: нужно выстроить новую систему с нуля и сохранить максимум продуктовой логики, чтобы пользовательский опыт в Lingualeo не поменялся.
Шаг 1. Собрали прототип новой архитектуры
Нам предстояло придумать, как обновить техническую составляющую сервиса и заново выстроить Lingualeo на современных технологиях. Я предложил руководству полностью сменить философию бэкенда: перенести бизнес-логику в базу данных, а саму базу данных MySQL заменить на PostgreSQL.
Я начал с прототипа на бумаге: нарисовал новую архитектуру, объяснил, как получится увеличить производительность и сколько ресурсов уйдёт на подготовку. Защищать проект было сложно, потому что под рукой не было однозначных историй успеха: никто не пишет о том, как провести миграцию сервиса с 20 миллионами пользователей без остановки бизнеса. Но в Lingualeo решили пойти на риск и одобрили план изменений.
Схема архитектуры до миграции
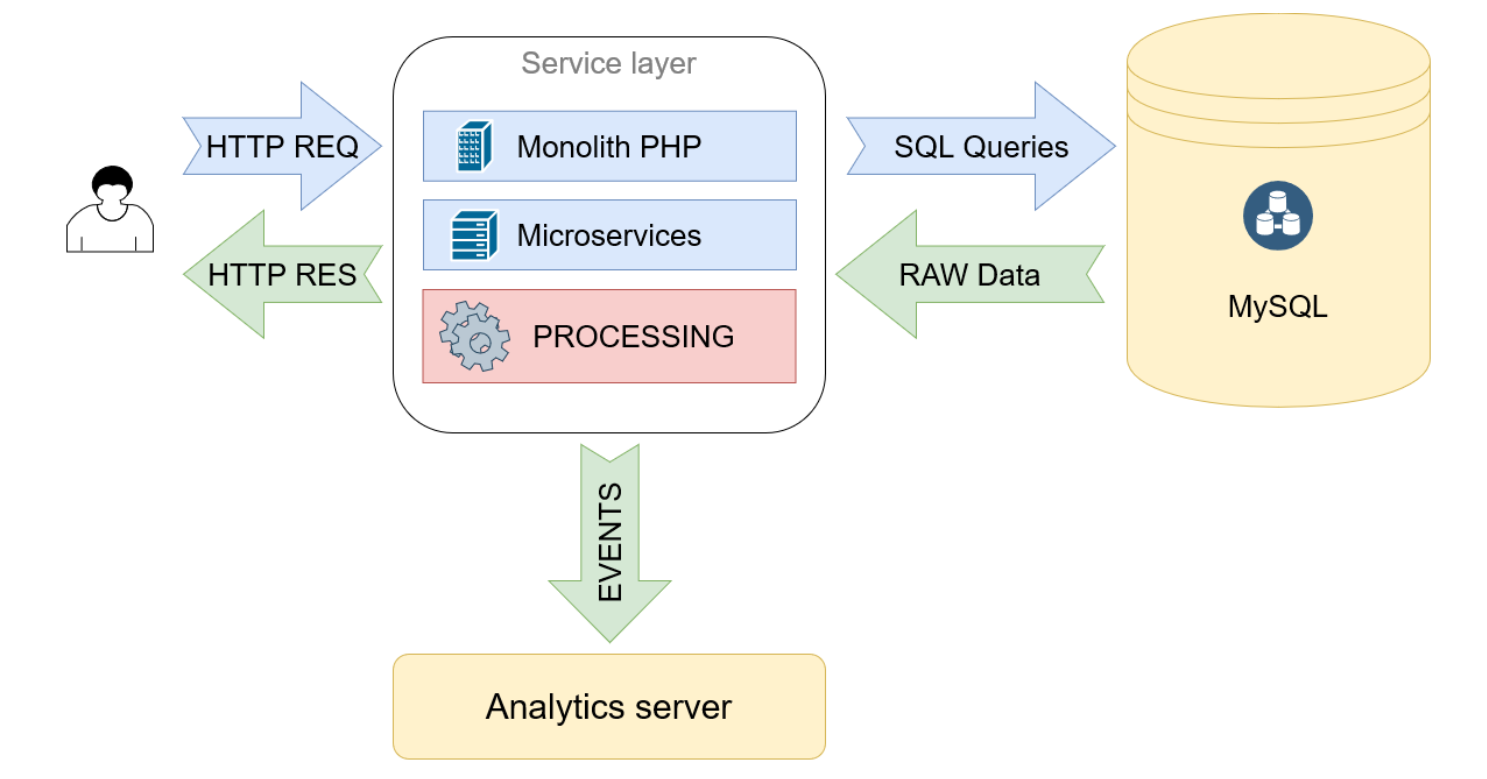
Запросы с фронта приходят в монолит на PHP, он обрабатывает их, многократно обращается к БД в MySQL и получает оттуда сырые данные. Затем обрабатывает их и формирует ответы в JSON
Схема новой архитектуры

Меняем SQL на PostgreSQL, переносим туда расчёты и создание JSON. Убираем монолит и ставим вместо него прокси-сервис, который направляет запросы в нужную базу данных, а затем отдаёт готовый JSON на фронт
Шаг 2. Обновили команду
Когда мы поделились планами с разработчиками, стало понятно, что команда не готова к изменениям. Большинство людей покинули компанию: остались только те, кто пришёл совсем недавно. Чтобы провести миграцию, мы решили заново собрать команду разработки.Искали амбициозных и готовых к переменам, профессиональных и ответственных. Старались обращать внимание не только на качество кода, но и на софт скиллз. Мы заново выстраивали архитектуру сервиса, поэтому нужны были люди, которые не испугаются сложных проектов и будут готовы решать задачи, с которыми раньше не сталкивались.
Некоторых людей нашли случайно, как, например, и меня: я познакомился с CEO Lingualeo Владимиром Сиротинским в самолёте. Будущего лидера фронтэнда Владимир встретил на консультации другого стартапа. Но большинство новых разработчиков мы набрали с рынка. Чтобы закрыть 8 вакансий, мы изучили 1118 откликов и провели 124 собеседования:
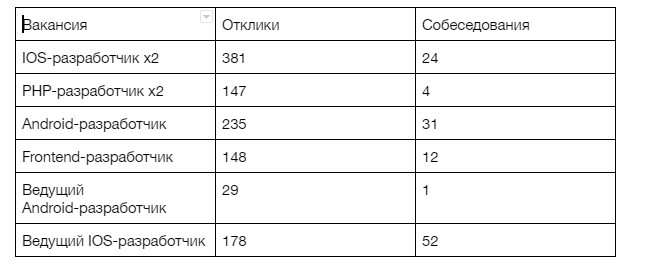
Воронка кандидатов на вакансии новых разработчиков в Lingualeo.
Шаг 3. Упростили оргструктуру
У нас три направления разработки: веб, бэкэнд и мобильные приложения, также есть отдел тестировщиков. Найти кого-то, кто понимает во всех отраслях сразу, в короткий срок очень сложно. Поэтому мы решили отказаться от технического директора и сделать оргструктуру новой команды максимально плоской. В компании остался только один уровень менеджмента — по одному лидеру в каждом направлении.
Мы проводим регулярные встречи и общаемся напрямую, поэтому разработка стала более прогнозируемой, сроки сократились. Технический директор может принять нерациональное решение, например, неправильно распределить ответственность между командами. В системе, где лиды общаются без дополнительного слоя менеджеров, вероятность нерациональных решений снижается: любую проблему мы всегда можем обсудить в личной беседе.
Например, если я понимаю, что какую-то функцию в новой структуре будет логичнее реализовать в базе данных, а не на фронте, я пишу в чат и обсуждаю идею с лидером фронтэнда. Не нужно договариваться о встрече с техническим директором или готовить презентацию, чтобы подкрепить свою идею.
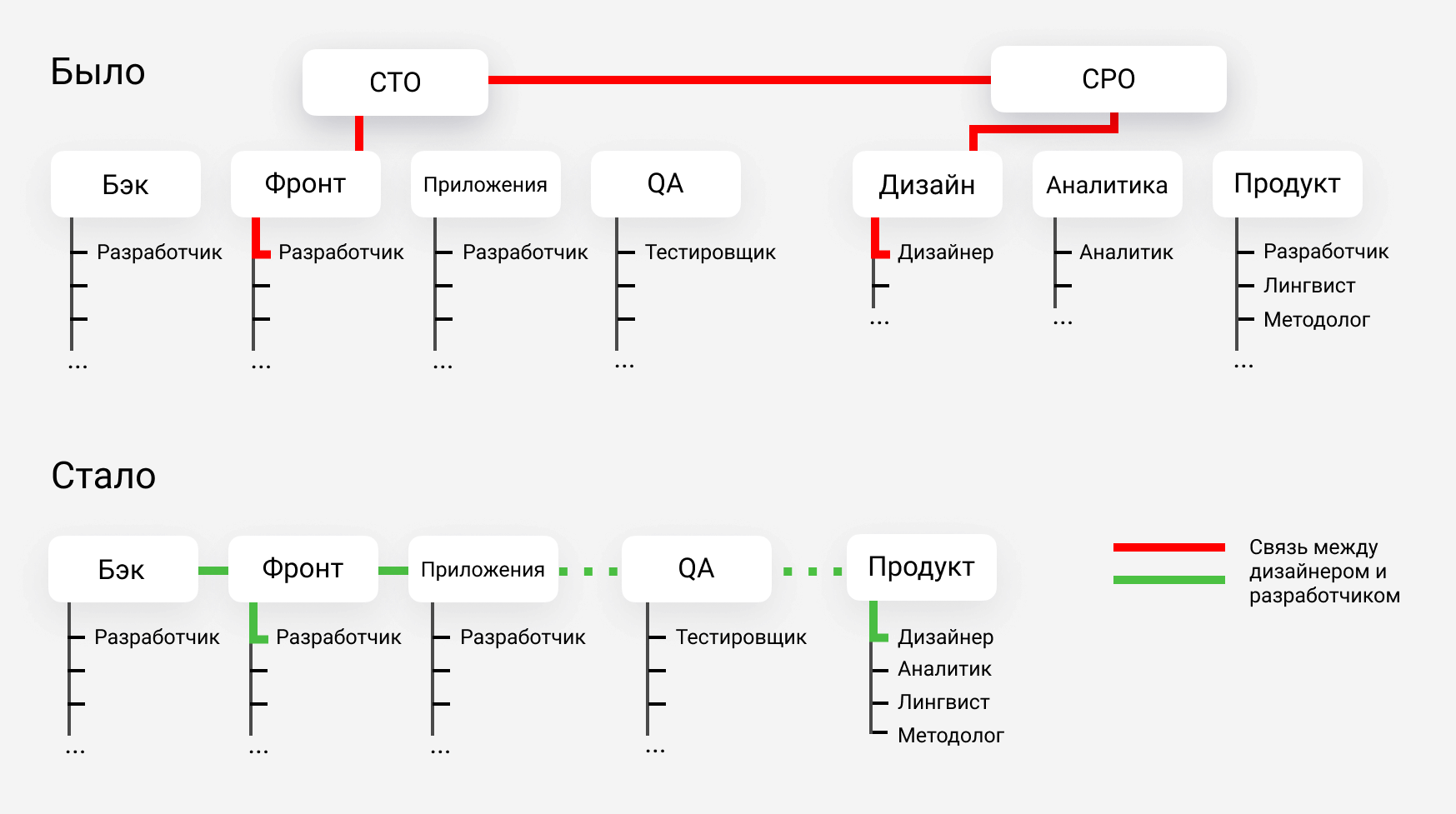
Оргструктура до и после изменений: отказались от технического директора в разработке и упростили структуру в продуктовом отделе. Сейчас продуктовому дизайнеру не нужно общаться с двумя уровнями менеджеров, чтобы передать идею на фронт
Шаг 4. Перенесли бизнес-логику в базы данных
Раньше бизнес-логика Lingualeo была на фронте и в приложениях. Функции продукта решались системами, которые не предназначены для обработки данных, например, в коде на JavaScript или PHP. Поэтому мы перенесли бизнес-логику Lingualeo в базы данных на PostgreSQL.
Джунгли
Один из 4 главных разделов сервиса Lingualeo — Джунгли. Это набор материалов на иностранном языке — текстов, аудио и видео, — в которых к любому слову можно узнать перевод. То есть, пользователи изучают реальный контент на английском, а если что-то непонятно, могут кликнуть на слово в тексте или в субтитрах к видео и посмотреть перевод.
Текст в Джунглях
Видео в Джунглях
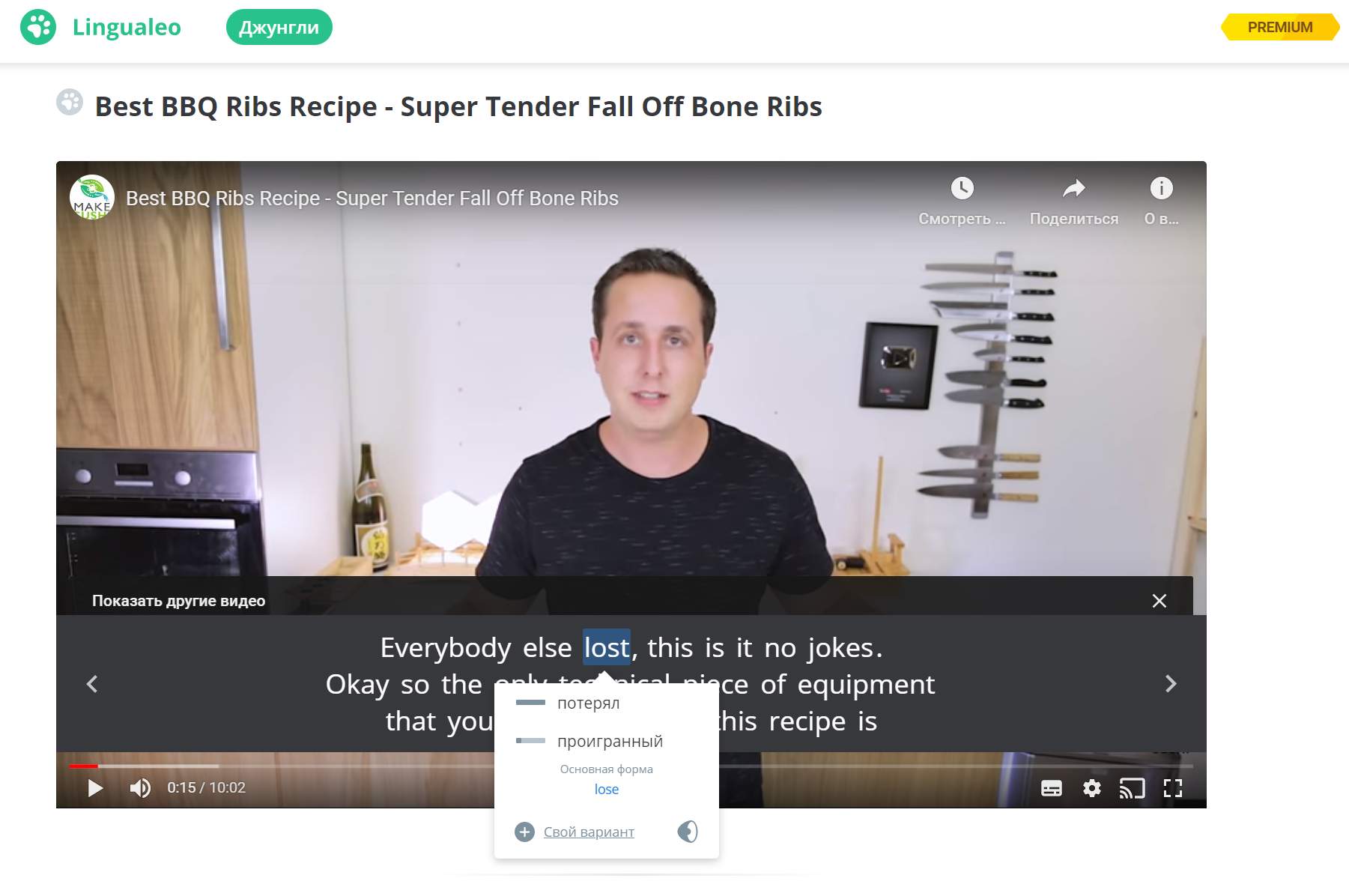
Чтобы заработала функция перевода слов по клику, текст надо разделить на слова, выражения и словосочетания. Затем — обратиться к словарю и вывести пользователю перевод в новом окошке поверх текста. Разбить текст для перевода довольно трудно: есть устойчивые выражения и фразовые глаголы, которые нет смысла делить на два слова. Например, take off и take — разные по значению единицы контента, хотя включают в себя одно и то же слово.
Вся логика этой функции вместе с исключениями и сложными правилами деления текста раньше была написана на JavaScript на фронте. Функция была очень громоздкой, перевод мог занимать много времени.
Мы реализовали эту функцию в базе данных. Бэк передаёт на фронт готовый JSON, в котором текст уже разбит на слова и выражения. Каждому слову и выражению в базе присвоен ID, по которому легко найти перевод. Также в JSON учитывается, какие слова есть в словаре у пользователя, а каких — пока нет. На фронте остаётся просто отобразить информацию и подсветить слова с определёнными признаками.
Словари
С разделом Словарей сделали так же: вся работа теперь происходит в базе данных. У нас есть пользователи, у которых в словаре больше 100 000 слов и выражений. В словаре нужно обеспечить удобный поиск, разбить слова на группы, дать пользователю широкий набор фильтров.
Раньше логика словарей была на стороне фронта или в прослойке на PHP, а сейчас в системе появился полноценный API между фронтом и бэкендом. Можно отправить один запрос с большим количеством параметров в базу данных, и оттуда придёт готовый JSON:

Фильтры словаря: поиск по словам, выбор слов по видам тренировки, выбор между словами и фразами, фильтр по изученным и новым словам
Курсы
Перенос бизнес-логики в базу данных многократно уменьшил количество кода и ускорил работу сервиса. Например, изменился бэкенд-код страницы Курсов после миграции. Её видят зарегистрированные пользователи, а курсы туда отбираются системой по десятку критериев. Раньше такая страница формировалась 600 мсек и отправляла 12 запросов в базу данных, сейчас — всего один:

Шаг 5. Учли обратную связь пользователей после релиза
На разработку ушло примерно полгода: мы занялись обновлениями в конце 2018, а релиз состоялся в мае 2019 года. Большинство пользователей ощутили, что сервис стал работать гораздо быстрее. Раньше в Lingualeo могли без потери скорости заниматься не более 2 000 человек одновременно, а сейчас система выдерживает пики больше 100 000 пользователей.
Часть людей заметили и негативные последствия. Мигрируя с чёрным ящиком, сложно обеспечить сохранность ста процентов данных, поэтому у кого-то потерялись слова из словаря, у кого-то — некорректно отображался прогресс в курсах.
Постепенно мы с командой пофиксили все проблемы. Главный результат перемен в том, что теперь мы работаем не с чёрным ящиком, а с простой и прозрачной системой, поэтому отрабатывать обратную связь было гораздо легче.
Lingualeo стал быстрее для пользователей и удобнее для разработчиков
В апреле 2020 во время самоизоляции нагрузка на Lingualeo была в пять раз больше по сравнению с аналогичным периодом год назад. Это не вызвало проблем: скорость работы сервиса не просела, пользователи ничего не заметили. Я уверен: если бы мы не обновили систему, сервис бы просто не выдержал.
Продукт стал не только быстрее для пользователей, но и гораздо проще для работы: теперь команде легче вводить и тестировать новые функции. Мы привели документацию в порядок, а код стал примерно в 40 раз меньше, так что новые разработчики легко разберутся в том, как устроен сервис.
Продукт стал обходиться дешевле, поэтому для него нужно арендовать меньше вычислительных мощностей. Затраты на активного пользователя в Lingualeo сократились более чем в 50 раз, хотя после обновлений число активных юзеров уже удвоилось.
Наконец, продукт стал безопаснее. Раньше, когда вся бизнес-логика была в прослойке на PHP, оттуда из разных функций шли запросы в базу данных. Открытая для SQL-запросов база данных — это проблема: можно сделать SQL-инъекцию и заставить её выполнить опасный код, например, удаление данных. Сейчас снаружи не приходит ни одного SQL-запроса, потому что мы перенесли всю логику внутрь».
Мы хотим и дальше регулярно писать в блог о том, как устроена разработка в обновлённом Lingualeo. Пишите в комментариях, о чём стоит рассказать в первую очередь: у нас поменялась и команда, и структура управления, и технологии. Будем рады ответить на все вопросы.

























































Melanchall
Несколько не ясно. Т.е. уже работающим разработчикам озвучили новую задачу и все они сразу покинули компанию? Если не все, то оставшихся уволили/перевели в другие команды? Просто интересно, если пришлось менять команду, какова участь тех, кто по вашему мнению, не должен был в ней остаться? Или я чего-то не понял.
LinguaLeo Автор
Бывшие разработчики сами решили свою участь, покинув проект. К сожалению, не все готовы выходить из зоны комфорта и штурмовать новые вершины. Со своей стороны мы честно сказали, что будет очень трудно, но интересно)
miksir
А может проблема в вершинах? Может они увидели там огромный такой овраг? Может они решили, что все же не очень интересно — возвращаться во времена программирования на оракле.
LinguaLeo Автор
Каждый вершитель своей судьбы. Вопрос не в инструментах, а в результате. Если разработчики могут обеспечить результат — действуйте. Если нет — то зачем обсуждать инструменты?
kdmitrii
Я что то тоже не понял. Куча давно работающих сотрудников (т.е самых важных) взяла и ВНЕЗПНО уволилась. Это с чего это они так решили? Может их мнение по поводу этого проекта не учли? Я ни разу не видел чтобы разработчики увольнялись после оглашения новых проектов, только после оглашения нового бреда. Тут 100% муть какая-то.
UPDATE: Я почитал коменты и понял. Какой-то дядя пришел и сказал группе разработчиков на PHP/Go/чё_там_ещё_использовалось, что они с завтра начинают "программировать" на SQL. После чего этот дядь был послан в известное место. Ну а те кто устроился недавно уволятся в ближайшее время, не волнуйтесь. Им просто надо новую работу найти.
LinguaLeo Автор
Некоторые уже два года ищут))
golovchanskiy
Конечно, с таким бэкграундом кто их возьмёт))
anonymous
В подавляющем большинстве случаев SQL сильно лучше для обработки данных, чем Python. Так что я прекрасно могу понять желание перенести все эти расчеты в БД. А если разработчик выучил Python и теперь пытается использовать его везде, где только можно и нельзя, то это, ИМХО, контрпродуктивный подход. Никак не пойму, почему все так боятся SQL.
LinguaLeo Автор
Полностью согласен, тем более что возможности обработки разных типов данных (включая json) за последние 3-5 лет в БД сильно улучшились
VolCh
"Боятся" не SQL, а отсутствия удобных инструментов разработки хранимок, триггеров и т. п. Со схемой-то полно проблем, но её хоть редактировать можно, а уж с ними...
LinguaLeo Автор
Хранимки прекрасно разрабатываются в pdAdmin. Они небольшие (200 — 400 строк), их даже для крупного проекта не требуется более 200. Триггеры, при правильной архитектуре проекта, вообще не требуются (у нас нет ни одного триггера).
Если сразу с компактной (10- 15 таблиц) и гибкой (можно вводить сотни новых сущностей без изменения таблиц) структуры данных, то и сами хранимки получаются очень простыми и удобными.
Подписывайтесь — скоро новые статьи на эту тему будут
VolCh
Этот This 'pdadmin' command line utility is a part of IBM Tivoli Access Manager?
Со сдержанным энтузиазмом жду статей: может действительно что-то сильно изменилось и теперь с хранимками хотя бы только на PgSql можно нормально работать, в частности:
Когда в последний раз занимался исследованием вопроса (года 4 назад) то ничего сравнимого с современной IDE c исходниками под git/hg не нашёл. Основную проблему, почему за 40+ лет существования SQL ничего подобного не было создано, для себя обозначил как "Не смотря на заявленную декларативность языка, по факту он императивный. Мы пишем множество команд на изменение состояния схемы и подобных вещей, а не редактируем это состояние и даём одну команду на приведение текущего состояния к ожидаемому. Инструментов, позволяющих из двух описаний состояния сделать набор команд на приведение одного к другому ("сгенерировать патч"), не то чтобы совсем нет, но они очень ограничены и примитивны."
rinace
Еще добавлю.
Похоже, современное поколение разработчиков привыкло к использованию инструментов и библиотек.
Когда я сказал, что написал на PostgreSQL функции для реализации поиска в графе это вызвало детское удивление — как сам?
А что такого? Задачка то элементарная, 3-й курс института.
LinguaLeo Автор
Полностью поддерживаю. Процесс разработки становится настолько простым, что нет необходимости в инструментах, без которых разработка кода на PHP/… невозможна.
Папки с текстовыми файлами и текстового редактора с подсветкой SQL вполне достаточно даже для разработки крупного проекта.
jMas
За "простоту" приходится всегда платить. Всегда. Вопрос, в том: видите вы то, чем вы платите или нет.
Ощущение, что вы нашили серебренную пулю и обманули всех — оно ведь всегда ошибочное, оно сохраняется лишь до момента когда вы наткнетесь на понимание чем вы за это платите.
Не даром есть поговорка: "простота хуже воровства".
LinguaLeo Автор
Есть еще поговорка: «все гениальное просто»
jMas
То что выглядит "просто" — может быть временным решением, которое эффективно решает ситуационную задачу, но завтра может оказаться "сильно упрощенным" для более сложной задачи. Возможно вы не четко очертили круг задач которые решаете при помощи хранимок в БД, что заставляет людей думать о том что при помощи хранимок вы решаете совсем все. Что с моей точки зрения, вводит в справедливое заблуждение. Опять же, с моей точки зрения, это не правильный пиар для такого подхода (лучше когда четко определили какие задачи решаются при помощи хранимок в БД и какие не стоит решать, и какие особенности при работе с хранимками в БД и как лечить).
LinguaLeo Автор
И в статье, и в комментах я подчеркиваю, что в хранимках решается задача обработки данных! Это не единственная часть сложной системы, но очень важная.
Каких-либо сложностей в обработке данных внутри хранимок я пока не встретил. Если у Вас есть иной опыт — приведите примеры.
jMas
Обработка данных — это сильно расплывчатое понятие. Программирование, в принципе, занимается обработкой данных. Что вы имеете ввиду под этим?
LinguaLeo Автор
Вот так:
Получение данных из таблиц, преобразование и сохранение данных в таблицах по определенным критериям
Формирование ответа с данными по определенным спецификациям
Критерий, где делать обработку, на мой взгляд следующий: если действие можно сделать с помощью одной/нескольких SQL-команд, то делать в хранимке. Если SQL бесполезен, то в микросервисах на других языках. Здесь главное понимать, какие есть возможности у SQL — не все об этом знают(
jMas
Другое дело!
Kwisatz
на каком языке хранимки, что у вас скрывается под понятием «подготовка Json»?
С последним кстати вообще удобней всего на v8 работать внутри пг
PsyHaSTe
Реализовать поиск на графе — это одно. Реализовать его максимально эффективно — совсем другое.
Кто угодно умеет писать "шифротексты" ксором на ключ или более прошаренные могут вспомнить асимметринчное шифрование. Но почему-то пользуются библиотеками для этого.
rinace
Реализация графа это так этюд, чисто как иллюстрация, все равно рекурсивный CTE запрос эффективнее.
LinguaLeo Автор
Аналогично реализовал в хранимке токенизацию текстов с иероглифами (когда идет сплошной список иероглифов, без проблемов, и их надо правильно разбить на слова и выражения, словарь прилагается в таблице).
Хранимка с рекурсивным CTE, 50 строк, примерно час ушел на разработку. Скорость обработки в 20 раз быстрее, чем скрипт на питоне. И по размеру кода в 10 раз меньше
PsyHaSTe
Если у вас парсер в 20 раз быстрее в БД мне страшно представить сколько времени работал скрипт на питоне.
Было бы прикольно показать на конкретном примере, вот текст, на питоне разбираем с таким вот слоаврем за Х мс, а на постгре за Y.
LinguaLeo Автор
Да, готовим статью с такими примерами. Я сам был поражен, когда увидел скорость работы в БД
xapienz
Ок, пойду напишу пережиматель жпегов на SQL, там всё просто, стандарт открыт, библиотеки не нужны :)
PsyHaSTe
"Обработка данных" это что? Например, определить что у пользователя в списке покупок есть 3 товара одной категории, и если у пользователя в настройках задано "оповещать о скидках" то отправить смс — это всё в храникмке должно быть?
anonymous
Речь не только про хранимки. Например нам нужно получить некоторое аналитическое представление каких-то данных в БД. Часто вижу, что это начинает лопатиться на бэке. С аргументацией "логики в БД быть не должно". Ну начнем с того, что даже фильтр по какому-то полю относится к логике. WHERE тоже на бэке будете делать? При тщательном рассмотрении можно понять, что БД — это и есть отражение предметной области с которой вы работаете. А если это не так, то Вас ждут проблемы. Где та грань, что нельзя делать в БД? Прям реально любопытно. Сможете рассказать?
PsyHaSTe
Всё что не относится к SELECT/WHERE/GROUP BY/ORDER BY в бд быть не должно. В частности обработка ошибок, любые "если то-то то сделай то-то", контракт для конечного пользователя, и так далее.
Даже то что делается аналитическими функциями часто имеет смысл делать на беке, просто потому что так проще. Если нет конкретных бенчей которые показывают что система тормозит от таких запросов, тогда конечно.
anonymous
А почему имеет смысл делать это на бэке? Я про аналитические функции. Давайте возьмем простейшее. Нужно посчитать SUM() по разным срезам и, возможно, фильтрам. Допустим где-то по месяцам разбить, а где-то по годам. Причем само отношение, которое мы будем группировать, получается путем джойна 5 таблиц. Итак, что вы будете делать в БД, а что на бэке? Мой вариант — создать вьшку, которая джойнит эти 5 таблиц, а потом обращаться к ней с разными WHERE и GROUP BY, применяя SUM(), как агрегирующую функцию. Это будет в 5 раз короче, чем то же делать на бэке. Это будет быстрее. Это будет дешевле по памяти. Это будет удобнее поддерживать. В частности это удобнее читать. А какой Ваш вариант?
PsyHaSTe
Тут нет никакой сложной логике, и это можно считать на БД.
Хотя даже этот вариант в современном софте будет лежать в коде. Вьюшка будет сделана к модели БД в коде, после чего запросы улетят в БД и вернутся с ответом. Логика останется на беке, правда исполняться будет на базе. Типичный ОРМ в общем.
LinguaLeo Автор
Все очень просто:
1. Фронт дергает ручку «Список покупок»
2. Прокси-сервис получает запрос и дергает соответствующую хранимку в базе (в этой точке возможен гибкий роутинг к слэйвам, например)
3. Хранимка формирует ответ в виде json. В ответе есть атрибут с инструкцией для прокси-сервиса: «вызови микросервис sms_sending, вот ему json с параметрами»
4. Прокси-сервис выполняет инструкцию
5. Прокси-сервис отправляет готовый ответ на фронт (п. 4 и 5 могут параллельно выполняться, если независимые)
Что нужно:
1. Разработать хранимку на 50-100 строк
2. Время разработки и отладки: 1 — 2 часа
3. Скорость отклика: 1 — 2 мсек (если структура данных правильная)
Зачем здесь нужны прослойки на PHP/…?
rinace
Повторюсь — проще найти десяток джуниоров для бека, чем одного мидла для БД.
Я другой причины для переноса бизнес-логики на бек пока не вижу.
И эта причина подтверждена на практике.
PsyHaSTe
А ваш "прокси сервис" на чем написан?
LinguaLeo Автор
Go
PsyHaSTe
Ну вот если бы ваш "прокси сервис" отвечал за логику а бд за данные то было бы ближе к распространенным подходам.
LinguaLeo Автор
Простой перенос обработки данных в базу упростил и удешевил систему в 10+ раз. Об этом опыте мы и рассказываем
mad_nazgul
ИМХО с аналитиками это вопрос денег.
Есть деньги на сервера и OLAP-решения, то удобнее работать в них.
Нет. Используем «модные технологии», например Hadoop+Spark.
philipto
У меня был один пример OLAP-решения, которое работало на два порядка медленнее, чем явно написанные в скрипте запросы к БД. Разумеется, это было не только дорого (платить за ресурсы), но и бесполезно (ответ на простой запрос занимал часы вместо секунд). Всё-таки хочется не только разрабатывать с комфортом, но и пользоваться без боли тем, что разработано.
mad_nazgul
Вообще странно. Т.к. обычно в OLAP-кубы выгружают данные, таким образом, чтобы быстро получить срез, по той или иной аналитике.
При этом — да, загрузка данных может быть и долгой.
Но обычно это не критично.
LinguaLeo Автор
Все очень просто:
1. С фронта идет через прокси-сервис запрос к базе: «дай список покупок»
2. Хранимка выбирает необходимые данные и возвращает в json на фронт (также через прокси)
3. Если нужно сделать дополнительные действия (отправить SMS), то в ответе в отдельном атрибуте идет инструкция прокси-сервису «вызывай микросервис sms_sending, вот ему json с данными)
4. Проксик все эти инструкции обрабатывает
Итог:
1. Фронт дернул один! запрос к бэку
2. Хранимка сделала один! запрос к базе
3. Все дополнительные действия сделаны в фоне
Размер такой хранимки — 50-100 строк (это если запрос достаточно сложный)
Время разработки и отладки — не более 1 часа
Скорость ответа — 1-2 мсек.
RekGRpth
получается, всё-таки, не вся логика в базе, а есть и на go?
LinguaLeo Автор
В базе данных логика обработки данных.
Естественно, любая более-менее сложная система включает в себя не только обработку данных — например, взаимодействие с другими системами. Эту логику нет смысла тащить в базу данных — не для этого они созданы.
LinguaLeo Автор
2
LinguaLeo Автор
3
kdmitrii
У меня вот такой вопрос. Пусть в БД лежат, не знаю, данные метеорологических датчиков. Нужно вернуть прогноз погоды на следующий день. Непосредственно модель будет запущена в БД или бекенд сначала дернет данные из БД, обработает у себя и вернёт запросившему?
Ivan22
для метео моделей обычно использую специализированные БД, например spark
LeKovr
Не стоит ли в этой формулировке заменить «Python» на «любой нехранимый в БД язык»? Это же глобальное деление — операции с данными, в основном, стоит положить в БД, а остальные — нет. К примеру, рассылку почты лучше делать не хранимым языком, не так ли?
LinguaLeo Автор
Совершенно верно — об этом статья и написана. Обработка данных должна производиться базой данных, с помощью SQL. Зачем для этого городить прослойки? А взаимодействие с внешним миром — через микросервисы на любом удобном языке.
При рассылке почты основная проблема не в том, как отправить письмо, а в том, кому и что отправить. Вопросы, кому и что отправить, решаются на стороне базы (это и есть данные), а сам процесс отправки нужного текста на нужный адрес — это уже микросервис
VolCh
Да откуда у вас "должно"? Вы не у себя в команде на код ревью :)
gudvinr
Тем более, что тот же Python можно для хранимок использовать.
Нужно ли — это другой вопрос.
enchantner
> В подавляющем большинстве случаев SQL сильно лучше для обработки данных, чем Python
Ну как бы сказать… Нет. Вообще ни разу. Просто он привычнее людям, которым надо декларативно описать выборку, а не программировать. И у этого есть как плюсы, так и минусы.
> Так что я прекрасно могу понять желание перенести все эти расчеты в БД.
Только вот PostgreSQL — не аналитическая база. Это обычный OLTP, изначально не заточенный так под аналитическую нагрузку, как, скажем, Vertica. И в аналитических базах часто есть коннекторы и расширения, позволяющие делать аналитику куда удобнее. Но тут уж своя мотивация и своя модель данных.
vitalijs
Какой хороший работодатель...
Sm1le291
Я даже знаю что это за овраг! Это перенос всей логики в БД. Это адский трэш на мой взгляд