
Стандарт ASCII был принят в 1963, и сейчас вряд ли кто-нибудь использует кодировку, первые 128 символов которой отличались бы от ASCII. Тем не менее, до конца прошлого века активно использовалась EBCDIC — стандартная кодировка для мейнфреймов IBM и их советских клонов ЕС ЭВМ. EBCDIC остаётся основной кодировкой в z/OS — стандартной ОС для современных мейнфреймов IBM Z.
То, что сразу бросается в глаза при взгляде на EBCDIC — то, что буквы идут не подряд: между I и J и между R и S остались неиспользованные позиции (на ЕС ЭВМ по этим промежуткам распределили символы кириллицы). Кому могло придти в голову кодировать буквы с неравными пропусками между соседними буквами?
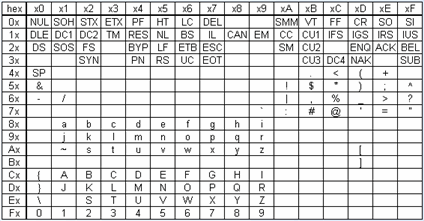
Само название EBCDIC ("Extended BCDIC") намекает на то, что эта кодировка — в отличие от ASCII — создавалась не на пустом месте, а на основе шестибитной кодировки BCDIC, которая использовалась начиная с IBM 704 (1954):

Непосредственной обратной совместимости нет: удобной чертой BCDIC, утраченной при переходе к EBCDIC, было то, что цифрам 0-9 соответствуют коды 0-9. Тем не менее, разрывы в семь кодов между I и J и в восемь кодов между R и S в BCDIC уже были. Откуда же они взялись?
История (E)BCDIC начинается одновременно с историей IBM — задолго до электронных компьютеров. IBM образовалась в результате слияния четырёх компаний, из которых самой технологически продвинутой была "Tabulating Machine Company", основанная в 1896 Германом Холлеритом — изобретателем табулятора. Первые табуляторы просто подсчитывали число перфокарт, пробитых в определённом месте; но в 1905 Холлерит начал производство десятичных табуляторов. Каждая карта для десятичного табулятора состояла из полей произвольной длины, и чи?сла, записанные в этих полях в привычной десятичной форме, суммировались по всей колоде. Разбивка карты на поля задавалась соединением проводов на коммутационной панели табулятора. Например, на этой перфокарте Холлерита, хранящейся в Библиотеке Конгресса, очевидным образом выбито число 23456789012345678, неизвестно как разделённое на поля:
Самые внимательные могли заметить, что на карте Холлерита 12 рядов для отверстий, хотя для цифр достаточно десяти; а в BCDIC для каждого значения старших двух битов используются только 12 кодов из 16 возможных.
Конечно же, это не случайное совпадение. Изначально Холлерит предназначал дополнительные ряды для "специальных отметок", которые не суммировались, а просто подсчитывались — как в самых первых табуляторах. (Сегодня мы бы назвали их "битовыми полями".) Кроме того, среди "специальных отметок" можно было задать group indicators: если при табуляции требовались не только окончательные суммы, но и промежуточные, то табулятор останавливался, когда обнаруживал изменение любого из group indicators, и оператор должен был переписать промежуточные суммы с цифровых табло на бумагу, обнулить табло, и возобновить табуляцию. Например, при подсчёте бухгалтерских балансов группа карт могла соответствовать одной дате или одному контрагенту.
К 1920, когда Холлерит уже ушёл на пенсию, вошли в употребление "печатающие табуляторы", которые подключались к телетайпу и могли сами печатать промежуточные суммы, не требуя вмешательства оператора. Сложность теперь заключалась в том, чтобы определить, к чему относится каждое из напечатанных чисел. В 1931 IBM решила при помощи "специальных отметок" обозначать буквы: отметка в 12-том ряду обозначала букву от A до I, в 11-том — от J до R, в нулевом — от S до Z. Новый "алфавитный табулятор" мог печатать название каждой группы карт вместе с промежуточными суммами; при этом непробитый столбец превращался в пробел между символами. Заметьте, что S обозначается комбинацией отверстий 0+2, а комбинация 0+1 изначально не использовалась из опасения, что два отверстия рядом в одном столбце могут вызвать механические проблемы в считывателе.

Теперь на таблицу BCDIC можно посмотреть немного под другим углом:

За исключением того, что 0 и пробел переставлены местами, старшие два бита определяют "специальную отметку", которую с 1931 пробивали в перфокарте для соответствующего символа; а младшие четыре бита определяют цифру, пробиваемую в основной части карты. Поддержка символов & - / добавилась в табуляторы IBM в 1930-х, и кодировка этих символов в BCDIC соответствует пробиваемым для них комбинациям отверстий. Когда понадобилась поддержка ещё большего числа символов, то в качестве дополнительной "специальной отметки" стали пробивать ряд 8 — таким образом, в одном столбце могло быть до трёх отверстий. Такой формат перфокарт сохранился практически неизменным до конца века. В СССР оставили IBM-овские кодировки латиницы и пунктуации, а для букв кириллицы пробивали сразу по нескольку "специальных отметок" в рядах 12, 11, 0 — не ограничиваясь тремя отверстиями в одном столбце.
Когда создавался компьютер IBM 704, то над кодировкой символов для него долго не думали: взяли кодировку, уже используемую тогда в перфокартах, и лишь 0 "поставили на место". В 1964, при переходе от BCDIC к EBCDIC, младшие четыре бита каждого символа оставили без изменений, хотя немного перетасовали старшие биты. Таким образом формат перфокарт, выбранный Холлеритом в начале прошлого века, оказал влияние на архитектуру всех компьютеров IBM, до IBM Z включительно.













alexxz
Занятная IT археология. Схожая история повлияла на порядок кириллических символов в КОИ-8. Символы располагаются в соответствии с фонетической схожестью с латинскими символами в первой половине таблицы. Таким образом, если текст попадет в 7битное окружение, то он останется в некоторой степени читаемым. Пример из википедии: слова «Русский Текст» превратятся в «rUSSKIJ tEKST». Только остается загадкой для меня почему регистр инвертировали…
vadimr
Регистр инвертировали, потому что, отбросив старший бит в КОИ-8, получаем КОИ-7, состоящую из больших английских и больших русских букв (наиболее широко распространённую кодировку русского языка с конца 70-х до конца 80-х).
Слова «Русский Текст» в КОИ-8 превратятся после отбрасывания старшего бита в «РUSSKIJ ТEKST» в КОИ-7, а слова «РУССКИЙ ТЕКСТ» в КОИ-8 – в «РУССКИЙ ТЕКСТ» в КОИ-7. А 7-битная кодировка ASCII с большими и маленькими латинскими буквами не применялась на оборудовании, использовавшемся в СССР, поэтому «rUSSKIJ tEKST» неактуален.
ikle
Вообще-то, в КОИ-7 три таблицы символов: Н0, Н1 и Н2:
В советское время производились микросхемы масочного ПЗУ знакогенератора для каждой из трёх таблиц. Системы попроще-подешевле использовали только Н2, системы подороже Н0 + Н1 с переключением страниц. Одни умели это делать автоматически (хранение бита в экранном буфере, плюс SI/SO для переключения при кодировании), в других нужно было тумблер вручную переключать (либо всё латиницей, либо всё кириллицей — любительский Радио-86РК, как пример).
P.S. Для меня загадка, почему КОИ-7, совместимая с ISO 646, не стала стандартом вместо несовместимой КОИ-8 с сопутствующими проблемами из-за графических символов в наборе C1.
Portnov
Запомнилась история из школы, видимо как раз связанная с этими несколькими таблицами. Изучали паскаль на каких-то БК. У товарища что-то глюкануло, и на экране после набора программы получилось «програм гуси; жар и: интегер; бегин...». Насколько я помню, оно компилировалось и работало — глюканул только знакогенератор, видимо.
:)
vadimr
А КОИ-8 де-факто никогда не была стандартом. Сначала почти повсюду использовалась КОИ-7, а потом распространились PC с альтернативной кодировкой ГОСТ, на основе которой впоследствии была внедрена CP866.
ikle
КОИ-8 была de facto стандартом на UNIX и клонах. Зафиксировано как RFC 1489:
Другими словами, был ещё мир за пределами PC и и на PC за пределами PC/MS-DOS, MS Windows и даже OS/2.
vadimr
Unix тогда был распространён меньше, чем сейчас, и даже там КОИ8 использовалась не во всех реализациях.
tyomitch Автор
Не только Unix, но и клоны RT-11 работали с КОИ-8.
vadimr
КОИ-7, как правило.
ikle
Зато в Linux двадцать лет назад почти все использовали либо koi8-r, либо koi8-u.
Преимуществ против КОИ-7 практически нет никаких:
Зато минус ощущали все из-за огромного количества ПО, ожидавшего в C1 управляющих кодов согласно ISO 646.
NetBUG
Ох уж эти стандарты доUTFовских времён…
tyomitch Автор
Вы таки не поверите!
en.wikipedia.org/wiki/UTF-EBCDIC
tyomitch Автор
Википедия пишет: «Была широко распространена как основная русская кодировка в Unix-совместимых ОС и в электронной почте»
vadimr
Про электронную почту вопрос крайне спорный, так как основной русскоязычный трафик в то время шёл через фидо, в кодировке 866.
borisxm
Как поддерживавший почтовые UUCP/SMTP сервера с первой половины 90-х, могу сказать, что koi8-r была стандартом. Если кодировка не была указана явно, то подразумевалась koi8-r. Зарубежные писатели почтовых программ были далеки от наших реалий и отправляли письма либо в 1251, либо в 866-й без указания кодировок, что и приводило ко всяческой бНОПНе.
vadimr
В системе UUCP/SMTP (условно говоря, в релкоме) koi8-r, действительно, была стандартом.
Но я к тому, что электронная почта в то время не исчерпывалась UUCP.
vadimr
Помню компилятор Паскаля на ДВК, который букву щ воспринимал, как конец комментария, так как она имела одинаковый код с правой фигурной скобкой.
Komrus
А если погрузиться ещё глубже в эту ветвь археологиии, то можно обнаружить, что КОИ-7 — появился на свет под влиянием телеграфного 5-битного кода МТК-2 (в котором было 3 регистра — для латинских букв; для русских букв; для цифр)
И в МТК-2 — совпадали коды латинские и русские буквы (каждая — на своем регистре). Если не переключить регистр — текст оставался читабельным, как сейчас говорится TRANSLITERACIEY :)
А эта идеология пришла в МТК-2 из русской версии азбуки Морзе, принятой в 1856 году :)