
Вчера здесь вышла статья о быстром парсинге double, я зашёл во блог к её автору, и нашёл там ещё один интересный трюк. При сравнении чисел с плавающей точкой особое внимание приходится уделять NaN (восемь лет назад я писал про них подробнее); но если сравниваемые числа заведомо не NaN, то сравнить их можно быстрее, чем это делает процессор!
Положительные double сравнивать очень просто: нормализация гарантирует нам, что из чисел с разной экспонентой больше то, чья экспонента больше, а из чисел с равной экспонентой больше то, чья мантисса больше. Стандарт IEEE 754 заботливо поместил экспоненту в старшие биты, так что положительные double можно сравнивать просто как int64_t.
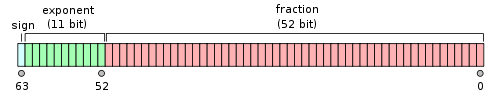
С отрицательными числами немного сложнее: они хранятся в прямом коде, тогда как int64_t — в дополнительном. Это значит, что для использования целочисленного сравнения младшие 63 бита double необходимо инвертировать (при этом получится -0. < +0., что не соответствует стандарту, но на практике не представляет проблемы). Явная проверка старшего бита и условный переход уничтожили бы всю выгоду от перехода к целочисленному сравнению; но есть способ проще!
Во блоге у Daniel Lemire несколько другой код (той же вычислительной сложности), но мой вариант сохраняет то полезное свойство, что
Положительные double сравнивать очень просто: нормализация гарантирует нам, что из чисел с разной экспонентой больше то, чья экспонента больше, а из чисел с равной экспонентой больше то, чья мантисса больше. Стандарт IEEE 754 заботливо поместил экспоненту в старшие биты, так что положительные double можно сравнивать просто как int64_t.

С отрицательными числами немного сложнее: они хранятся в прямом коде, тогда как int64_t — в дополнительном. Это значит, что для использования целочисленного сравнения младшие 63 бита double необходимо инвертировать (при этом получится -0. < +0., что не соответствует стандарту, но на практике не представляет проблемы). Явная проверка старшего бита и условный переход уничтожили бы всю выгоду от перехода к целочисленному сравнению; но есть способ проще!
inline int64_t to_int64(double x) {
int64_t a = *(int64_t*)&x;
uint64_t mask = (uint64_t)(a >> 63) >> 1;
return a ^ mask;
}
inline bool is_smaller(double x1, double x2) {
return to_int64(x1) < to_int64(x2);
}a>>63 заполняет все 64 бита копиями знакового бита, и затем >>1 обнуляет старший бит.Во блоге у Daniel Lemire несколько другой код (той же вычислительной сложности), но мой вариант сохраняет то полезное свойство, что
to_int64(0.) == 0


mayorovp
Приведенный код содержит UB. Вот так делать правильнее:
ZimM
Почему тут UB?..
tyomitch Автор
stackoverflow.com/questions/63422076/why-is-type-punning-considered-ub
nickolaym
Правильный ответ "по кочану! в стандарте так сказано!".
На самом же деле, есть паттерны UB, которые эксплуатируются в благих целях, и на которые компилятор смотрит благосклонно.
Например, чисто сишный приём преобразования типов через union.
Почему нельзя reinterpret_cast'ить типы?
1) Потому что выравнивание. Некоторые процессоры болезненно чувствительны к попытке прочитать невыравненные double и даже int.
Здесь неприменимо, так как у приёмника int64 выравнивание уж точно не сильнее, чем у источника double.
2) Потому что алиасинг. Прочитали, поменяли, а компилятор думает, что это одно и то же, или наоборот, что это не одно и то же, и оптимизирует внезапным способом.
Здесь неприменимо, так как читаем ровно единожды, и из значения, а не из внешней ссылки.
3) Потому что компилятор — психопат с мачете. Как увидит явное UB, так вместо того, чтобы писать вонинг, вставит код форматирования диска.
Покажите мне такие компиляторы.
4) Потому что психопат с мачете — ревьювер.
Ну, тут уж медицина бессильна.
Sdima1357
Склонен согласиться. На фоне данного трюка использующего особенности формата хранения fp64 в памяти, данный UB совсем безобиден.
В частности одна из причин UB — неоднозначность формата хранения, вспомним 8087 с его 80-битными флоатами, даже если в коде они определены как FP64…
Примерно как соблюдение правил движения, когда убегаешь от полиции после ограбления
khim
memcpy) будет отлично работать.Я принёс в банк чек с подписями и печатями и мне выдали денег! Я ограбил банк! Срочно убегать от полиции!
P.S. Чисто для тех, кто в танке: в стандарте существует такая вещь, как is_iec559 — именно для того, чтобы всё описанное в статетье не было “ограблением банка”.
0serg
8087 может работать с 80-битными флоатами в памяти и это даже будет is_iec559 тип. Но правда 754 вроде требует сейчас от компилятора гарантировать что double это именно 64-битный тип и ни один компилятор без явной просьбы использовать long double подобный код не генерировал
khim
static_assert(sizeof(double) == sizeof(std::uit64_t));.Это тоже правда, но это даже не главное. Главное, что вы можете всё это проверить во время компиляции… а вот UB — это таки UB.
khim
Например, чисто сишный приём преобразования типов через union.
Только это не «сишный приём». Стандарт это запрещает. gcc поддерживает, хотя и с оговорками, разработчики clang говорят что-то вроде “простейшие случаи такого рода мы отлавливаем и поддерживаем, но никаких попыток гарантировать его работоспособность во всех случаях мы не делаем”.Прекрасно применимо. Вы читаете через указатель, а это значит, что содержимое
aиxникак между собой не связаны.Что самое смешное — что для этого даже не нужны какие-то козни с компилятором. Например математические сопроцессоры (8087, Weitek и другие) работают параллельно основному процессору, но независимо от него. Соотвественно простейшая конструкция:
без специальных усилий со стороны компилятора работать не будет: вызов
sinзапусит вычисление синуса (занимающее под сотню тактов) на сопроцессоре, после чего основной процессор прочитает то, что там было в памяти — и начнёт радостно использовать в вычислениях.Приводили много раз.
Конкретно с этой функцией вроде компиляторы ничего плохого не делают ещё. Но имеют право. Вот реальный пример (что самое смешное:
dtoaкак раз использует трюки, подобные описанному в статье… только код там чуток посложнее).tyomitch Автор
Сишный — разрешает. stackoverflow.com/questions/25664848/unions-and-type-punning
Имеют, но в обозримом будущем не будут — именно потому, что такой код используется сплошь и рядом. Обратите внимание, что в случае с
dtoaэту (правомочную!) оптимизацию сочли багом в clang и в конечном счёте убрали.khim
-fno-strict-aliasingи избавиться от UB.Согласен. Я с C стараюсь не связываться, так что некоторые ньюансы не знаю.
Но забавно что как в силу специфики реализации железа как раз в C с этим подходом и возникают проблемы на старом железе (современные процессоры от концепции сопроцессоров давно отказались: либо плавучка встроена в основной процессор, либо её нет вообще и она эмулируется).
DustCn
Ну memcpy то целиком на 8 байт вызывать не стоит, наверное… Мы же об эффективности говорим?
mayorovp
А никакого "вызова целиком" там и не происходит, всё memcpy упрощается до двух инструкций mov: https://godbolt.org/z/x83Mez
tyomitch Автор
Если добавить -O1, то не будет и них.
DustCn
Спасибо, покопался. -O3 дает возможность всем компиляторам убить memcpy() кроме… msvc. Может там еще чего надо, я хз, не умею в него.
godbolt.org/z/GGnxr1
tyomitch Автор
У MSVC нужный ключ называется /O2
mayorovp
А у него нет опции O3, только O1 и O2...
destman
И даже больше скажу я ловил креши из-за этого UB. На старых arm процессорах которые не умеют читать по не выровненному адресу…
Так что да memcpy оно более безопасно. В релизе (-O3) оно все равно упрощается до нескольких инструкций (если это безопасно)
tyomitch Автор
Каст double к int64_t не может вызвать проблем с выравниванием.
destman
Пример: читаем данные из файла. Сделали mmap. Адрес не выровнен и тип указателя из которого читаем вполне может быть int64_t…
tyomitch Автор
Если бы адрес не был выровнен, то по этому адресу и double не мог бы лежать.
destman
Что вам запрещает записать double в бинарный файл со смещением 123?
tyomitch Автор
Ну вы ещё скажите, что
void foo(double *bar) {...}не может разыменовывать*bar, а может толькоmemcpyего в локальную переменную, потому что мало ли, вдругbarпрочитан из файла.destman
В какой части кода ошибка: в функции foo(double *bar) или в функции что ее вызывает?
И да в некоторых случаях foo(double *bar) может ожидать что адрес не выравненный.
Пример:
template<class Type, class Ptr>
Type readUnaligned(Ptr *ptr) {
Type rv;
memcpy(&rv, ptr, sizeof(Type));
return run
}
tyomitch Автор
Об этом и речь: если после каста double к int64_t возникли проблемы с выравниванием, значит они и без каста бы были при обращении к исходному double. Значит, эти проблемы вызваны вовсе не кастом double к int64_t.
destman
Об этом и было мое сообщение. В таких случаях безопаснее использовать memcpy а не каст. Оно решает проблему выравнивания.
destman
Стандарт явно не описывает размеры float, double, long double. Есть только определение что точность long double выше double и точность double выше float.
И в совсем общем случае каст в int любого размера (как и memcpy) даст неопределенное поведение.
Поэтому «Каст double к int64_t не может вызвать проблем с выравниванием» справедливо только в частном случае когда размер double равен 8 байт.
mobi
В стандарте есть
std::numeric_limits<double>::is_iec559(и static_assert) для тех, кто хочет убедиться, что тип данныхdoubleсоответствует IEEE 754.0serg
del
khim
Вы не путаете
reinterpret_castи bit_cast?Если “играться с указателями” как в статье, то как раз
reinterpret_castотлично скомпилируется (и натворит делов).Ипользовать нужно только
bit_cast. Если у вас не C++20 компилятор, то можете своровать определение с cppreference (только вstdего не суйте, а то конфликт будет после обновления компилятора).0serg
Я вообще имел в виду reinterpret_cast с использованием ссылочных типов
Но да, оно по факту работает так же как с указателями, я ошибся )
DurRandir
С no-strict-aliasing прокатит.