

Новые экспериментальные модели машинного обучения важно быстро разворачивать в продакшене, иначе данные устареют и появятся проблемы воспроизводимости экспериментов. Но не всегда это можно сделать быстро, так как часто процесс передачи модели от Data Scientist к Data Engineer плохо налажен. Эту проблему решает подход MLOps, но, чтобы его реализовать, нужны специальные инструменты, например Kubeflow.
При этом установка и настройка Kubeflow — довольно непростой процесс. Хотя существует официальная документация, она не описывает, как развернуть Kubeflow в продакшен-варианте, а не просто на тестовой локальной машине. Также в некоторых инструкциях встречаются проблемы, которые нужно обходить и искать их решения.
Я Александр Волынский, архитектор облачной платформы Mail.ru Cloud Solutions. В этой статье познакомлю вас с Kubeflow на базовом уровне и покажу, как его разворачивать. Мы не будем подробно знакомиться со всеми компонентами Kubeflow, потому что это выходит за рамки базового ознакомления.
В ходе этой статьи мы:
Создадим кластер Kubernetes на платформе Mail.ru Cloud Solutions.
Установим Istio.
Установим Kubeflow.
Запустим JupyterHub.
Обучим и опубликуем тестовую модель.
Но для начала немного расскажу про MLOps и Kubeflow.
Если вы предпочитаете видеоинструкцию, то можете посмотреть вебинар «MLOps без боли в облаке. Разворачиваем Kubeflow».
Пара слов о MLOps
MLOps (Machine Learning Operations) — это своего рода DevOps для машинного обучения, который помогает стандартизировать процесс разработки моделей машинного обучения и сокращает время их выкатки в продакшен.
MLOps помогает разбить барьер между Data Scientist и Data Engineer. Часто происходит так: Data Scientist экспериментирует, разрабатывает новую модель, отдает ее дата-инженеру и уходит снова ставить новые эксперименты и пробовать новые модели. А Data Engineer пытается развернуть эту модель в продакшене, но так как он не участвовал в ее разработке, у него может уйти на это несколько месяцев. Может пройти до полугода с момента начала разработки модели до ее развертывания в продакшене. Все это время модель не работает и не приносит пользы, данные устаревают, появляется проблема воспроизводимости экспериментов.
С MLOps новая модель быстро передается в производство и начинает приносить пользу бизнесу. Также MLOps решает задачи трекинга моделей, версионирования, мониторинга моделей в продакшене.
Kubeflow в связке с MLOps
Kubeflow — это Cloud-Native платформа с открытым исходным кодом, предназначенная для машинного обучения и Data Science. Kubeflow работает поверх Kubernetes, полностью с ним интегрирована и по максимуму использует возможности кластера вроде автомасштабируемости и гибкого контроля ресурсов.
Kubeflow включает в себя множество компонентов, решающих разные задачи Data Science и Machine Learning. Все эти компоненты Open Source, вы можете использовать их отдельно. То есть, работая с Kubeflow, можно получить опыт работы с этими компонентами и перенести его впоследствии на другие задачи.
Еще одно преимущество Kubeflow в том, что на ней можно быстро запускать JupyterHub и настраивать индивидуальное окружение для дата-сайентистов.
В традиционном подходе JupyterHub часто установлен на одном мощном сервере, в котором может быть 60–100 ядер и несколько сотен гигабайт оперативной памяти. Но со временем отдел Data Science растет, ресурсов на всех начинает не хватать. Кроме того, общее окружение приводит к конфликтам, когда кому-то из дата-сайентистов нужно обновить версии библиотек или установить новые, а другим это не нужно.
Используя Kubeflow внутри облачного Kubernetes, вы решаете эту проблему: любой Data Scientist может в несколько кликов быстро развернуть экспериментальную среду с нужным количеством ресурсов. А когда эксперимент окончен, ресурсы освобождаются и возвращаются в облако. Также Kubeflow позволяет развернуть полностью изолированные индивидуальные инстансы JupyterHub из отдельных Docker-образов. То есть каждый дата-сайентист может настроить окружение под свои потребности.
Другие возможности Kubeflow:
быстрая публикация моделей через компоненты TensorFlow Serving, Seldon Core — можно делать их доступными по REST-протоколу или gRPC;
удобный UI для управления экспериментами и мониторингом моделей — можно собрать свой Kubeflow из открытых компонентов, но управлять без UI им будет намного сложнее;
оркестрация сложных пайплайнов машинного обучения из множества шагов — платформа частично заменяет AirFlow;
встроенный компонент, который отвечает за подбор гиперпараметров;
возможности управления метаданными и Feature Store.
Важно заметить, что некоторые из компонентов Kubeflow еще находятся в бета-версии. Но уже сейчас можно начать пользоваться Kubeflow, потому что это одна из немногих Production-Ready платформ, решающая задачи MLOps и машинного обучения. Для начала Kubeflow можно использовать как гибкий вариант JupyterHub, а потом постепенно знакомиться с остальными возможностями.
Итак, приступаем к установке Kubeflow.
Инструкция по установке и настройке Kubeflow
Шаг 1: создаем кластер Kubernetes
Сначала нам необходимо развернуть кластер Kubernetes. Мы будем делать это на нашей облачной платформе Mail.ru Cloud Solutions.
Перед созданием кластера нужно настроить сеть, сгенерировать и загрузить SSH-ключ для подключения к виртуальной машине. Вы можете самостоятельно настрои сеть по инструкции.
Сначала заходим в панель MCS и создаем кластер Kubernetes. Кластер можно создать в разных конфигурациях, выбираем «Другое», указываем версию Kubernetes 1.16.4. Это не самая актуальная версия, которая есть на платформе, но, по словам разработчиков Kubeflow, она лучше всего протестирована. Также выбираем два предустановленных сервиса: мониторинг на базе Prometheus/Grafana и Ingress Controller.
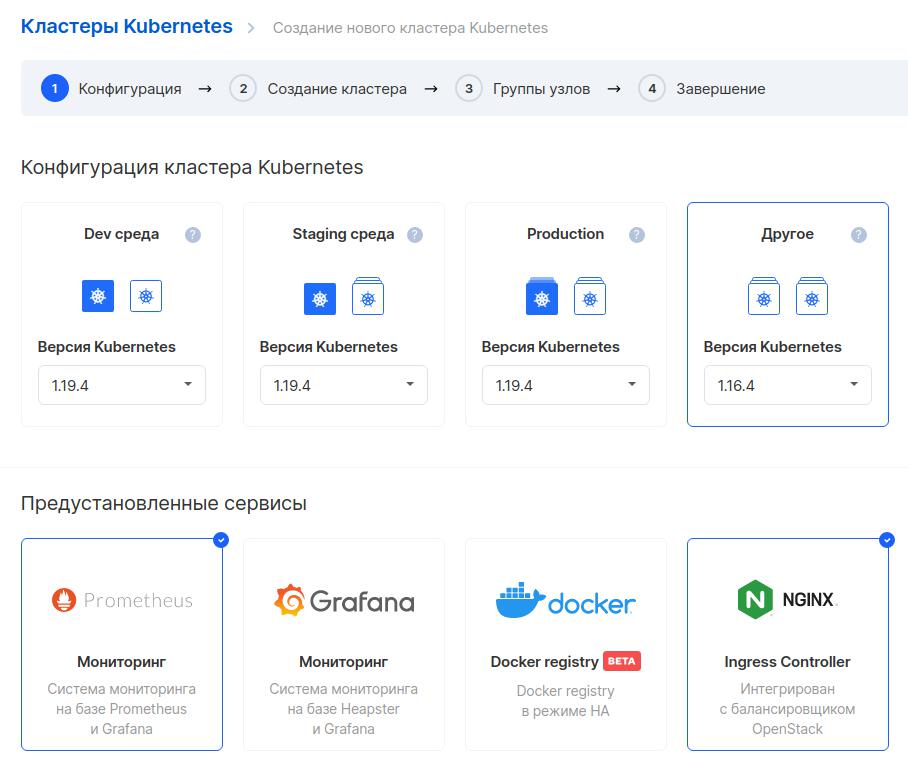
На следующем шаге выбираем конфигурацию кластера. Тип виртуальной машины «Standard 4-8», размер диска 200 Гб. Выбираем заранее настроенную сеть и отмечаем «Назначить внешний IP» — это нужно, чтобы потом подключиться к этой машине. Затем выбираем SSH-ключ для подключения, который сгенерирован и загружен заранее.
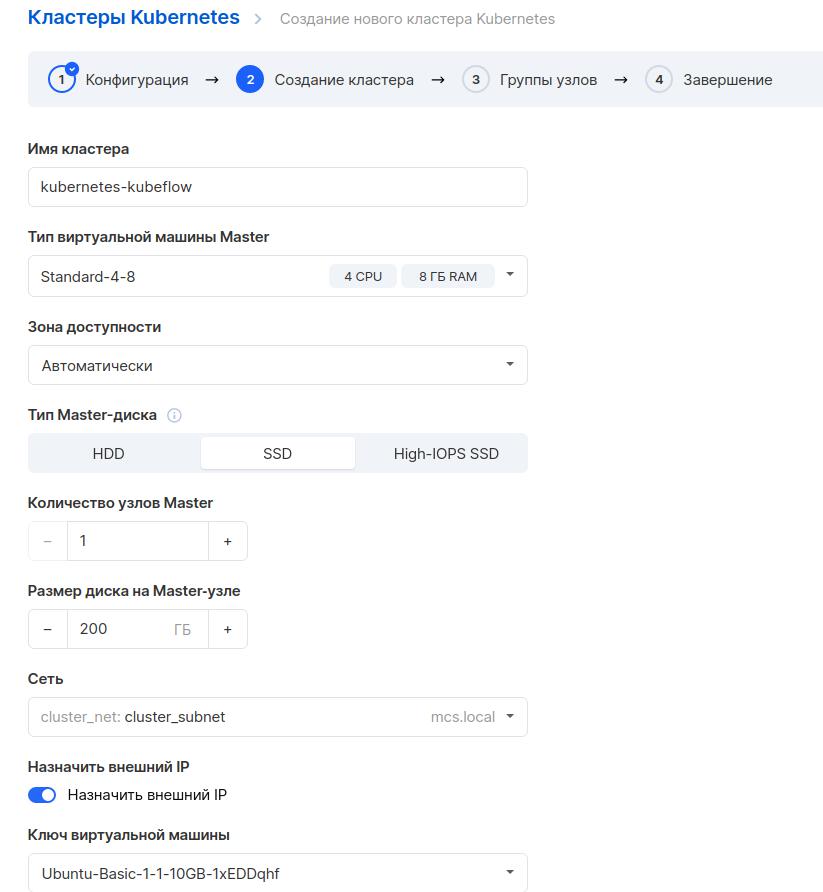
На следующей вкладке нужно указать минимальные системные требования для рабочей ноды Kubeflow. В минимальных системных требованиях указано 4 ядра, 50 Гб диска и 12 Гб оперативной памяти. Создаем ноду с запасом: 8 ядер, 200 Гб диска и 16 Гб оперативной памяти.
Важный момент: включаем автомасштабирование и указываем максимум 10 узлов. Это нужно на случай, если в процессе работы потребуется больше ресурсов, тогда кластер сам создаст дополнительные ноды.
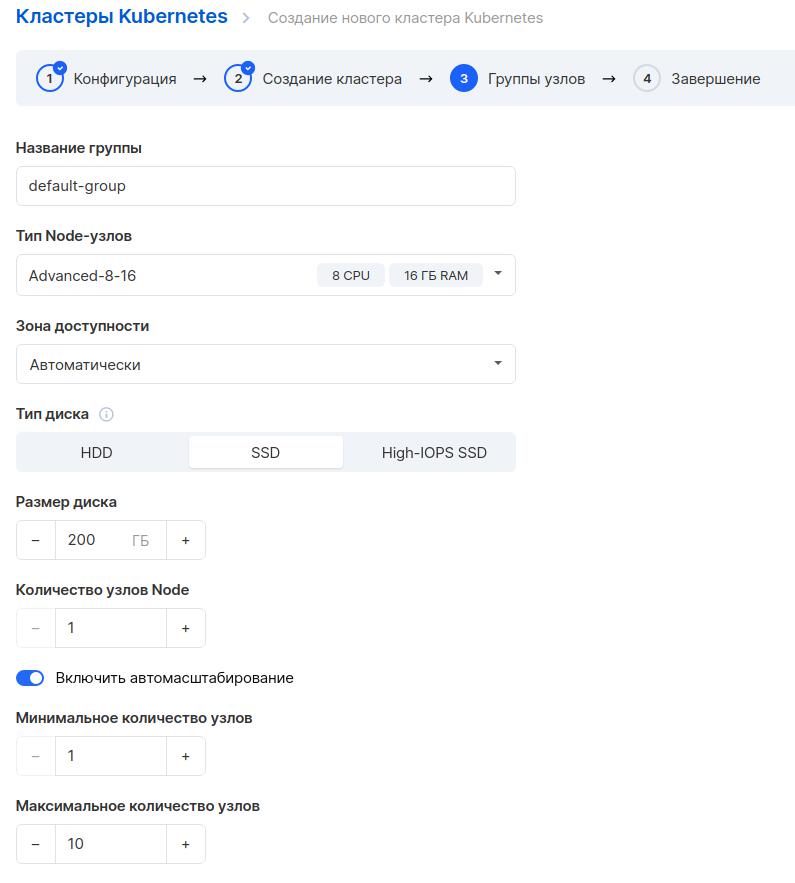
Если возникнут сложности, вот полная инструкция по созданию кластера Kubernetes.
После того как кластер создался, нужно подключиться к мастер-ноде и внести некоторые изменения. Это нужно, так как Kubeflow требует для работы одну фичу, которая пока не активна, но скоро мы ее включим по стандарту. Для этого сначала нужно назначить белый внешний IP-адрес. Поэтому в панели MCS заходим в раздел «Облачные вычисления» — «Виртуальные машины». Напротив мастер-ноды в выпадающем меню выбираем «Управлять IP-адресами».
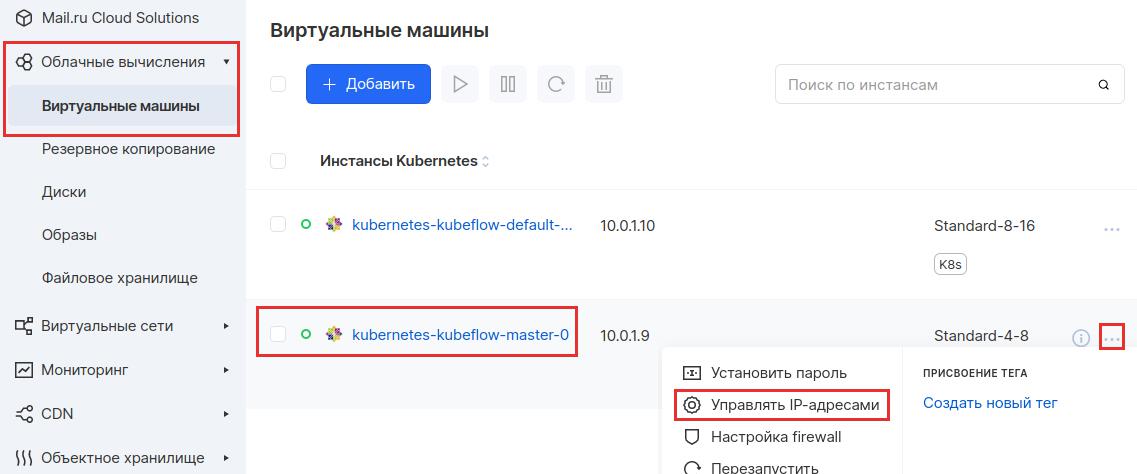
В появившемся окне в столбце «Внешний» назначаем внешний IP-адрес и копируем его, как только он создается.
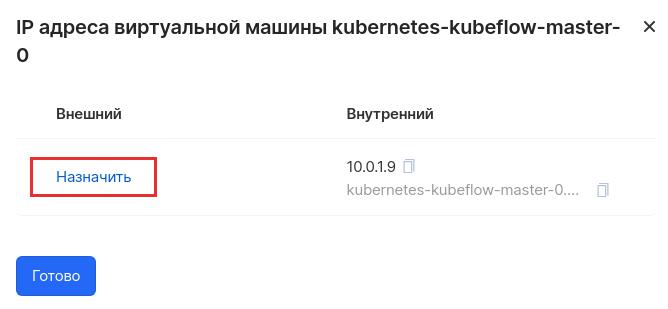
Теперь подключаемся по SSH к мастер-ноде Kubernetes, подставляя свои параметры:
ssh -i your_key.pem centos@ip_of_masterОткрываем файл /etc/kubernetes/apiserver для редактирования:
sudo vim /etc/kubernetes/apiserverВ строку KUBE_API_ARGS добавляем параметры. Это нужно для того, чтобы заработали Kubeflow и Istio:
--service-account-issuer=kubernetes.default.svc
--service-account-signing-key-file=/etc/kubernetes/certs/ca.key
--service-account-api-audiences=api,istio-caТеперь можно отвязать внешний IP-адрес от мастер-ноды.
Затем нужно перезагрузить Kubernetes-кластер после внесения изменений. Для этого в разделе «Кластеры Kubernetes» сначала останавливаем кластер, а потом запускаем заново.
Когда кластер Kubernetes остановлен, вы платите только за место на дисках, что удобно при проведении экспериментов в облаке.
Далее нужно подготовить виртуальную машину, в которой мы будем выполнять все дальнейшие действия. Сначала создайте виртуальную машину с ОС Ubuntu 18.04 и подключитесь к ней по SSH. Затем установите kubectl и импортируйте конфигурационный файл, чтобы подключиться к созданному кластеру Kubernetes. Также вы можете развернуть все это на своей машине.
Шаг 2: устанавливаем istioctl и Istio
Kubeflow и Istio можно установить одним пакетом сразу, но мы будем устанавливать их отдельно. Потому что на момент написания этой инструкции Istio, который идет в комплекте с Kubeflow, не заработал.
Скачиваем пакет с Istio. Рекомендуем именно версию 1.3.1, потому что на момент написания инструкции именно она рекомендована для работы с Kubeflow:
curl -L https://istio.io/downloadIstio | ISTIO_VERSION=1.3.1 TARGET_ARCH=x86_64 sh -Добавляем путь к переменной PATH:
export PATH="$PATH:/home/ubuntu/istio/istio-1.3.1/bin"Проверяем установку:
istioctl verify-installЕсли вы видите такое сообщение, значит, все готово для установки Istio:
-----------------------
Install Pre-Check passed! The cluster is ready for Istio installation.Устанавливаем Istio Custom Resource Definitions:
cd ~/istio/istio-1.3.1
for i in install/kubernetes/helm/istio-init/files/crd*yaml; do kubectl apply -f $i; done
kubectl apply -f install/kubernetes/istio-demo.yamlНужно проверить, все ли поды запустились:
kubectl get pods -n istio-systemНужно дождаться, пока все поды будут в статусе Running или Completed:
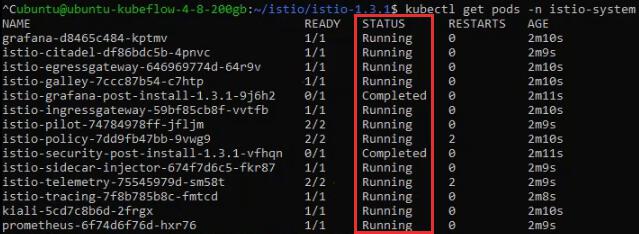
Шаг 3: устанавливаем Kubeflow
Сначала нужно скачать и распаковать kfctl — утилиту для работы с Kubeflow.
Затем задаем переменные:
export PATH=$PATH:"~/"
export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.1-branch/kfdef/kfctl_istio_dex.v1.1.0.yaml"
export KF_NAME=kubeflow-mcs
export BASE_DIR=~/
export KF_DIR=${BASE_DIR}/${KF_NAME}Далее создаем директорию и конфигурационный файл в ней:
mkdir -p ${KF_DIR}
cd ${KF_DIR}
kfctl build -V -f ${CONFIG_URI}
export CONFIG_FILE=${KF_DIR}/kfctl_istio_dex.v1.1.0.yamlНужно отредактировать конфигурационный файл и удалить из него все, что связано с Istio. Иначе в процессе установки Kubeflow Istio снова попробует установиться и из-за этого все сломается:
nano $CONFIG_FILEНужно удалить эти блоки:
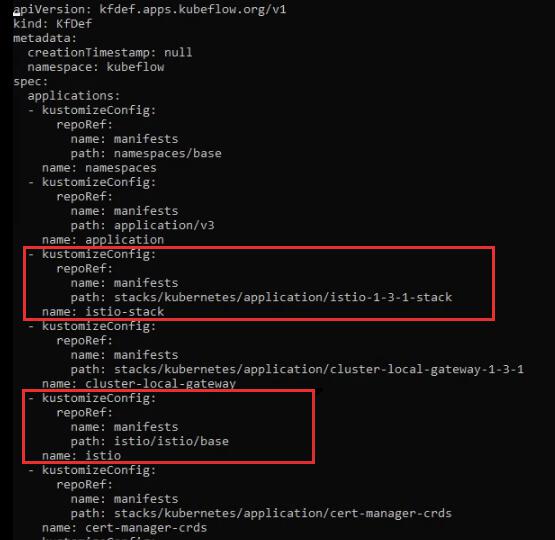
Применяем конфигурационный файл:
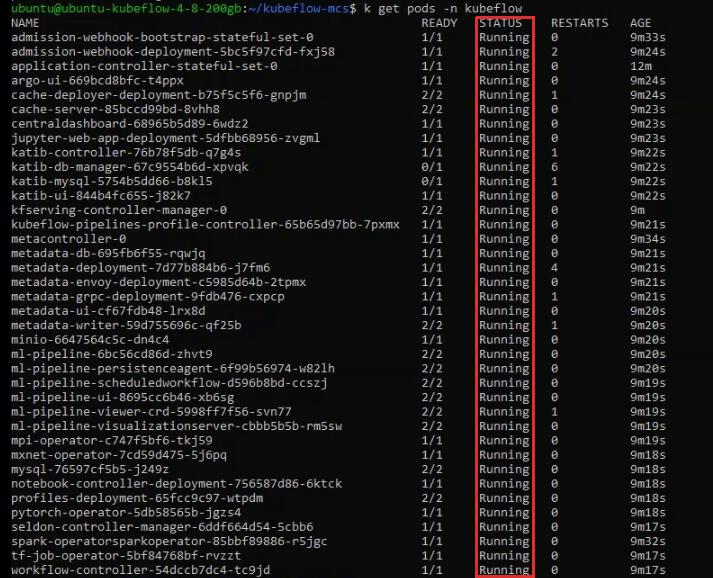
kfctl apply -V -f ${CONFIG_FILE}Нужно подождать, пока создадутся все поды. Статус подов можно проверить командами:
kubectl get pods -n kubeflow и
kubectl get pods -n intio-systemНужно дождаться, пока все поды будут в статусе Running или Completed:
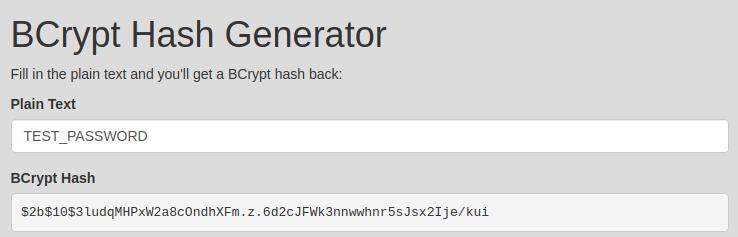
Рекомендуется сразу сменить в Kubeflow пароль по умолчанию. Для этого создадим конфигурационный файл для авторизации:
kubectl get configmap dex -n auth -o jsonpath='{.data.config\.yaml}' > dex-config.yamlДальше нужно получить хеш пароля, для этого зайдем на сайт https://passwordhashing.com/BCrypt, вводим пароль и копируем полученный хеш, чтобы потом прописать его в YAML-файл.
Далее открываем конфигурационный файл для редактирования:
nano dex-config.yamlВписываем полученный хеш:
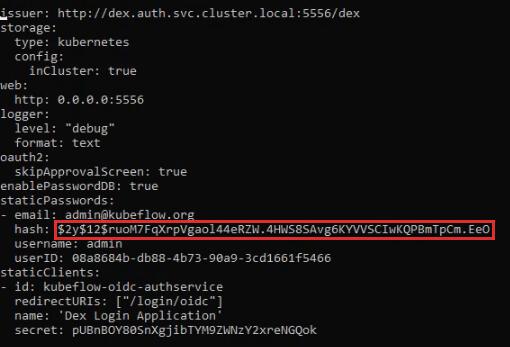
Применяем этот конфигурационный файл:
kubectl create configmap dex --from-file=config.yaml=dex-config.yaml -n auth --dry-run -oyaml | kubectl apply -f -Перезапускаем Dex, который отвечает за процесс аутентификации:
kubectl rollout restart deployment dex -n authЗатем, чтобы Kubeflow был доступен по HTTPS, необходимо в Kubernetes внести изменения в конфигурацию Kubeflow Gateway:
cat <<EOF | kubectl apply -f -
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"networking.istio.io/v1alpha3","kind":"Gateway","metadata":{"annotations":{},"name":"kubeflow-gateway","namespace":"kubeflow"},"spec":{"selector":{"istio":"ingressgateway"},"servers":[{"hosts":["*"],"port":{"name":"h$ creationTimestamp: "2020-11-11T07:34:04Z"
generation: 1
name: kubeflow-gateway
namespace: kubeflow
spec:
selector:
istio: ingressgateway
servers:
- hosts:
- '*'
port:
name: http
number: 80
protocol: HTTP
tls:
httpsRedirect: true
- hosts:
- '*'
port:
name: https
number: 443
protocol: HTTPS
tls:
mode: SIMPLE
privateKey: /etc/istio/ingressgateway-certs/tls.key
serverCertificate: /etc/istio/ingressgateway-certs/tls.crt
EOFПримечание. В следующих шагах генерируем самоподписанный сертификат, и Chrome будет выдавать предупреждение, когда будем заходить в Kubeflow. При этом может быть проблема, что Kubeflow будет недоступен по внешнему IP-адресу. Чтобы это исправить, можно сменить тип istio-ingressgateway на NodePort и обратно на LoadBalancer:
kubectl patch service -n istio-system istio-ingressgateway -p '{"spec": {"type": "NodePort"}}'Ждем около минуты, затем:
kubectl patch service -n istio-system istio-ingressgateway -p '{"spec": {"type": "LoadBalancer"}}'
Дальше необходимо узнать новый внешний IP-адрес:
kubectl get svc -n istio-systemКопируем адрес:

Необходимо сгенерировать сертификат для этого IP-адреса. Ниже в коде на место INSERT_IP_RECEIVED_ON_PREV_STEP нужно вставить IP-адрес из предыдущего шага:
export INGRESS_IP=INSERT_IP_RECEIVED_ON_PREV_STEP
cat <<EOF | kubectl apply -f -
apiVersion: cert-manager.io/v1alpha2
kind: Certificate
metadata:
name: istio-ingressgateway-certs
namespace: istio-system
spec:
commonName: istio-ingressgateway.istio-system.svc
# Use ipAddresses if your LoadBalancer issues an IP
ipAddresses:
- ${INGRESS_IP}
isCA: true
issuerRef:
kind: ClusterIssuer
name: kubeflow-self-signing-issuer
secretName: istio-ingressgateway-certs
EOFШаг 4: запускаем JupyterHub
В браузере переходим по внешнему IP в панель управления Kubeflow. Для входа используем логин и пароль, которые сгенерировали в предыдущем разделе «Установка Kubeflow».
При первом входе необходимо создать Namespace. По умолчанию предлагается имя admin, для примера создадим admin-kubeflow. Новым пользователям также надо будет сгенерировать под себя Namespace.
Далее нам понадобятся credentials от Docker Hub. Сначала переводим их в base64:
echo -n USER:PASSWORD | base64Создаем конфигурационный файл, для того чтобы JupyterHub мог работать с docker-registry:
nano config.jsonВставляем код. Вместо generated_base64_string нужно вставить ваш хеш от Docker Hub:
{
"auths": {
"https://index.docker.io/v1/": {
"auth": "generated_base64_string"
}
}
}Далее создаем config-map, который будет содержать credentials для доступа к нашему Docker Registry. Необходимо указать название вашего Namespace вместо ${NAMESPACE}, в данном примере это admin-kubeflow:
kubectl create --namespace ${NAMESPACE} configmap docker-config --from-file=config.jsonПроверяем, что файл создался:
k get configmap -n admin-kubeflowТут видно, что нужный docker-config был создан 24 секунды назад, значит, все хорошо:

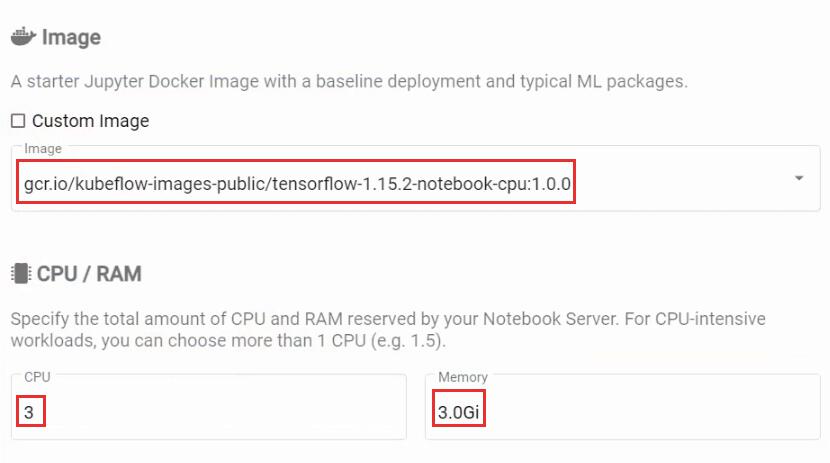
Теперь нужно запустить инстанс JupyterHub. Возвращаемся в панель управления Kubeflow, переходим в раздел Notebook Servers и создаем новый инстанс. Выбираем Image версии 1.15. Вы можете использовать любой другой кастомный Image, но тогда придется устанавливать нужные версии библиотек. Для теста задаем 3 CPU и 3 Гб оперативной памяти, но вы можете задать объем ресурсов гибко под свои задачи.
Также при создании инстанса создается Persistent Storage, который позволяет сохранить данные, даже когда Kubeflow будет перезапущен, им также можно управлять и задавать объем.
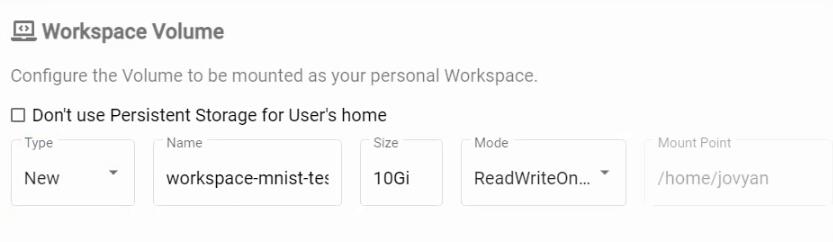
Остальные параметры оставляем по умолчанию.
После того как Jupyter Notebook запустится, подключаемся к нему.

Запускаем терминал.
В терминале клонируем репозиторий, в котором находятся примеры pipeline. В данном примере использую свой репозиторий, а не официальный, потому что на момент написания этой инструкции официальные примеры устарели и не работают:
git clone https://github.com/stockblog/kubeflow_examples.git git_kubeflow_examplesШаг 5: обучаем и публикуем тестовую модель
На этом шаге мы обучим в Kubernetes и опубликуем модель, запустим эксперименты и посмотрим на результаты. Работа будет проходить в двух Jupyter-блокнотах, которые находятся в склонированном репозитории: mnist_mcs_k8s.ipynb и Simple Notebook Pipeline.ipynb. Мы по очереди откроем эти блокноты и будем последовательно запускать ячейки.
Этот процесс лучше посмотреть на коротком видео:
Если использовать подход MLOps и специальные инструменты, например Kubeflow, можно значительно ускорить процесс выкатки экспериментальных моделей в продакшен, а это значит, что они будут быстрее решать бизнес-задачи.
Также 23 марта в 18:00 я проведу вебинар «MLflow в облаке. Простой и быстрый способ вывести ML-модели в продакшен». На вебинаре мы пройдем все этапы установки и настройки MLflow в максимально близком к production варианте, а также покажем, как реализовать использование облачных сервисов в качестве различных backend-сервисов MLflow. Регистрация здесь.
Что еще почитать по теме:
Akkarine
Отличная статья, спасибо! Как раз изучал тему разворачивания JupyterHub на простаивающих мощностях. Не знал о Kubeflow. Подскажите пожалуйста лучшее решение для такого кейса:
Есть два сервера. Свободные ресурсы примерно равны. Могу выделить на первом 24 ядра / 16 Гб оперативки, а на втором 10 ядер / 32 Гб. Можно перегнать некоторую нагрузку по оперативке с первого на второй.
В идеале хотелось бы объединить этот ресурс созданием вычислительного кластера.
Возможно ли получить один мощный инстанс Jupyter Notebook и утилизировать объединённый ресурс для проверки ML теорий (устал по 3 часа ждать в google colaboratory :)?
Или, как вы пишете, лучше по максимуму освободить ресурс одной из машин и на ней поднять чистый JupyterHub? И имеет ли при этом смысл установка Kubeflow?
В компании я пока один начинающий дата-сатанист, но не исключено появление интереса у других моих коллег.
Практического опыта с kubernetes нет, поэтому рассматривал вариант ещё использовать OpenShift (чтобы за меня команды куберу слал).
volinski Автор
Kubeflow, скорее всего, не поможет вам в решении задачи. По умолчанию Kubeflow не распараллелит за вас data science эксперименты. Нужно смотреть какой фреймворк используете. Умеет ли он работать в кластерном режиме. Предлагаю вам для начала посмотреть в сторону Spark. Его кстати тоже можно запускать в кубере.
www.youtube.com/watch?v=fYGc4elKW-g
Akkarine
Да, похоже что я фундаментально ошибался и без дополнительных инструментов не обойтись. Спасибо!