

В свое время DevOps заметно изменил подход к разработке программного обеспечения. Последние пару лет благодаря практикам MLOps меняются принципы и подходы к работе дата-специалистов. Александр Волынский (Technical Product Manager ML Platform VK Cloud) и Сергей Артюхин (преподаватель программы «Симулятор ML» в Karpov Courses) рассказывают, почему MLOps — «новый черный» и как безболезненно реализовать этот подход в своем проекте.
MLOps и откуда он взялся
Статистически большая часть экспериментов Data-Science-команд — вплоть до 90 % — не доходит до продакшена. Часто проблемы возникают на уровне разработки ML-моделей. Не сохраняют различные версии моделей и доработки, не фиксируют параметры экспериментов, артефакты и поведение моделей в различных условиях. Поэтому постфактум довольно сложно объяснить особенность поведения модели при работе на определенном дата-сете.
Отсюда появляются непредсказуемости, которые блокируют выпуск ML-моделей в продакшен. Или того хуже: модель идет в прод, но ведет себя не так, как предполагалось, что может в принципе подорвать доверие команды к работе с ML.
Проблема процессов разработки — это не что-то новое и неизвестное. Практики DevOps, которыми активно пользуются соседи — разработчики ПО, снимают большинство сложностей. Однако очевидно, что разработка софта и работа с ML отличаются друг от друга. Поэтому появился MLOps — набор практик и инструментов, которые помогают стандартизировать и повысить эффективность процессов работы с машинным обучением. MLOps закрывает задачи трекинга, версионирования и мониторинга ML-моделей.
Для решения задач MLOps есть несколько инструментов. Мы остановимся на двух из них — JupyterHub и MLflow.
JupyterHub — это IDE для дата-специалистов, многопользовательская версия Jupyter Notebook. С ее помощью удобно работать в команде.
MLflow — один из наиболее популярных Open-Source-инструментов для решения MLOps-задач, который помогает организовать централизованный трекинг и хранение моделей, параметров экспериментов и артефактов и выполнять другие задачи. Он содержит четыре компонента: MLflow Tracking, MLflow Models, Model Registry и MLflow Projects.
- MLflow Tracking — это модуль для логирования метрик, параметров и артефактов модели. Его API для Python, REST, Java и R.
- MLflow Models — модуль, который решает задачи упаковки моделей в контейнеры и развертывания в различные окружения. С его помощью легко сделать модель доступной по REST API для решения задач Real-Time Serving или, например, использовать готовую модель в Apache Spark для Batch-задач.
- Model Registry — центральное хранилище ML-моделей, которое предоставляет API и UI для управления их жизненным циклом (Staging, Production, Archived). На его основе можно также организовать публикацию моделей.
- MLflow Projects — инструмент для упаковки кода для его переиспользования.
Важно понимать, что полное воркфлоу машинного обучения включает не только работу с моделями — нужно учитывать этапы подготовки и обработки данных. Облако позволяет развернуть Hadoop, использовать базы данных для организации DWH и Data Lake. То есть облако позволяет закрыть все этапы, от инжиниринга до развертывания.
Приступаем к практике с MLOps
Для практики будем использовать Cloud ML Platform. В этом сервисе инструменты JupyterHub и MLflow преднастроены и интегрированы между собой и с другими сервисами VK Cloud. Трекинг-сервер находится на отдельном хосте. Модели, изображения, код и прочие артефакты хранятся в S3 (отказоустойчивом геораспределенном хранилище). Managed PostgreSQL хранит метаданные: информацию о запусках, метрики, теги и прочее.
Вы можете зарегистрироваться на платформе VK Cloud и повторить эксперимент вместе с нами. Для всех новых пользователей есть приветственный бонус 3000 рублей.
Итак, для начала потребуется авторизоваться или создать аккаунт на платформе VK Cloud и перейти на вкладку Cloud Ml Platform.

Чтобы начать работать с MLflow, нужно создать JupyterHub, в котором мы и будем писать модели. В Cloud ML Platform это делается в несколько шагов:
- Задать имя инстанса.
- Выбрать тип виртуальной машины.
- Указать зону доступности.
- Выбрать тип и размер диска.
- Указать доменное имя.
- Задать пароль доступа.
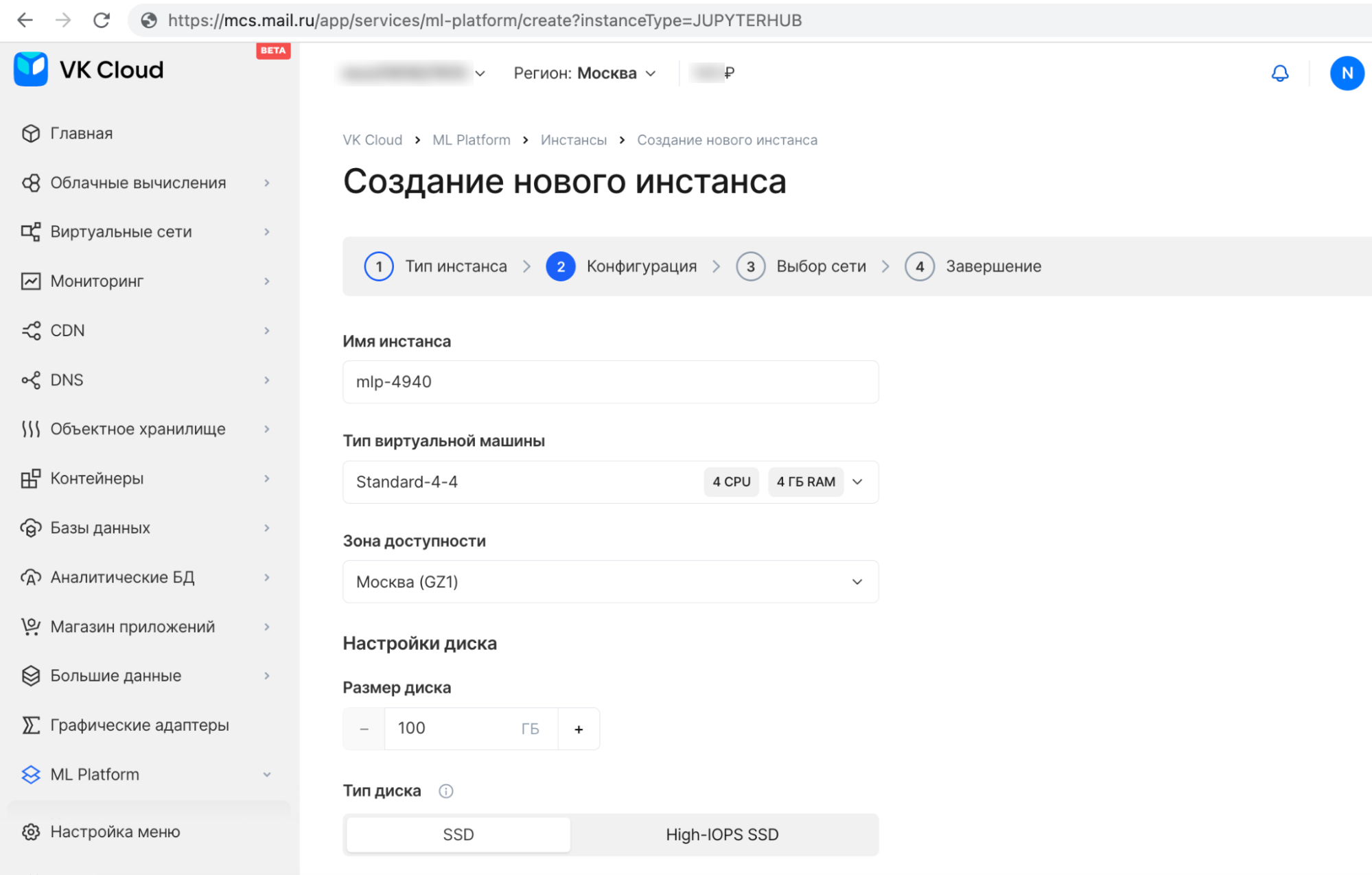
В демоверсии MLflow данные хранятся на виртуальной машине. Этот вариант подходит для тестовых, ознакомительных или обучающих задач. В этом случае данные хранятся на виртуальной машине. Если вы планируете сразу внедрять процесс в продакшен, то рекомендуем перейти в режим MLflow Prod, тогда все данные будут храниться в S3 и Managed PostgreSQL.
MLflow Tracking
MLflow Tracking — это компонент для логирования параметров, версий кода, метрик и выходных файлов при запуске кода машинного обучения. Внутри него есть две важные концепции:
- Run — единичный запуск кода. На каждый запуск будет создана новая директория, сохранены метрики, параметры и артефакты.
- Experiment — именованная группа run.
Чтобы запустить run, мы используем команду mlflow.start_run(). Затем прописываем фичи и таргет. Через эту функцию мы логируем дата-сет, модель и другие параметры.
mlflow.log_param('features', FEATURES)
mlflow.log_param('categorial features', CATEGORIAL_FEATURES)
mlflow.log_param('target', TARGET)После этого создаем модель и логируем ее класс.
model = CatBoostClassifier(iterations=10,
eval_metric='F1',
random_seed=17,
silent=False)
mlflow.log_param('model_type', model.__class__)
Команда ниже будет полезна для логирования тегов. Через нее можно добавить дополнительную информацию об экспериментах, которую потом можно удалять и менять. В целом функция обеспечивает удобный поиск по тегам.
mlflow.set_tags(tags = {
"auto_tracking": "false",
"framework": "Catboost"
})
После этого создаем и логируем сетку параметров для перебора:
grid = {'learning_rate': [0.03, 0.1, 0.05],
'depth': [2, 4, 6],
'l2_leaf_reg': [1, 3, 5, 7, 9, 20]}
mlflow.log_param('param_grid', grid)
И наконец, запускаем обучение:
grid_search_result = model.grid_search(grid, train_pool, plot=True)
Следующая команда — логирование лучших параметров.
mlflow.log_param('best_params', grid_search_result['params'])
Теперь посмотрим на логирование метрик. В данном случае мы просто считаем различные метрики на тестовом дата-сете и логируем как единичное значение. Тут есть важный момент: логирование происходит как ключ — значение и залогировать, например, Time Series через единичную команду нельзя. Но, допустим, вы обучаете нейросеть и нужно залогировать метрику каждой из эпох, тогда можно использовать цикл и параметр step=0. Таким образом, в MLflow вы получите график метрики.
y_test_pred_proba = model.predict_proba(X_test)[:, 1]
y_test_pred = model.predict(X_test)
roc_auc = roc_auc_score(y_test, y_test_pred_proba)
precision = precision_score(y_test, y_test_pred)
recall = recall_score(y_test, y_test_pred)
f1 = f1_score(y_test, y_test_pred)
mlflow.log_metric('roc_auc', roc_auc)
mlflow.log_metric('precision', precision)
mlflow.log_metric('recall', recall)
mlflow.log_metric('f1', f1)
print(f'ROC AUC: {roc_auc}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1: {f1}')
После метрик логируем саму модель вместе с ее весами, окружением и так далее. Перед этим мы создаем схему входных данных и таргета.
input_schema = Schema([
ColSpec("double", "age"),
ColSpec("string", "sex"),
ColSpec("string", "car_class"),
ColSpec("double", "driving_experience"),
ColSpec("double", "speeding_penalties"),
ColSpec("double", "parking_penalties"),
ColSpec("double", "total_car_accident")
])
output_schema = Schema([ColSpec("long", "has_car_accident")])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
mlflow.catboost.log_model(model,
artifact_path="driver_accident_demo",
registered_model_name="driver_accident_demo",
signature=signature)
Jupyter notebook с рассмотренными примерами доступен на GitHub.
Фичи MLflow
Логирование любых файлов. Логирование xml-файлов. Если вы будете использовать библиотеку Plotly для построения графиков или метрик, то их можно сделать интерактивными. Команды ниже создают изображения и записывают их в HTML — картинки тоже будут интерактивными.
roc_auc_fig.write_html("./metrics/roc_auc.html")
fpr_fig.write_html("./metrics/fpr_curve.html")
Логирование папок. Это удобно для разбиения и хранения информации по категориям.
mlflow.log_artifact("./metrics")
В созданной папке driver_accidet_demo хранится вся информация об эксперименте. В частности, в ML Models находятся созданные конфиги в удобной форме. Она будет полезна для коллег, которые захотят воспроизвести эксперимент в будущем.
Получение списка всех run. Через функцию get_experiment_by_name и название эксперимента получаем его ID и выводим список всех run.
exp = mlflow.get_experiment_by_name("driver_accident_demo")
run_info = mlflow.list_run_infos(exp.experiment_id)[0]
print("Run ID: ", run_info.run_id)
with mlflow.start_run(run_id=run_info.run_id) as run:
mlflow.log_metric("f1", 0.0)
Создание subrun. Эксперимент c id = 0 формируется автоматически по умолчанию. Внутри него будут создаваться проекты второго уровня с помощью конструкции with. Она автоматически закрывает эксперимент после выполнения кода конструкции, точно так же, как открывается файл в Python. Двухуровневый run удобен, чтобы делить большие проекты на несколько частей и в каждой из них логировать отдельные метрики.
with mlflow.start_run(experiment_id=0, run_name="top_lever_run") as run:
with mlflow.start_run(experiment_id=0, run_name="subrun1", nested=True) as subrun1:
mlflow.log_param("p1","red")
mlflow.log_metric("m1", 5.1)
with mlflow.start_run(experiment_id=0, run_name="subsubrun1", nested=True) as subsubrun1:
mlflow.log_param("p3","green")
mlflow.log_metric("m3", 5.24)
with mlflow.start_run(experiment_id=0, run_name="subsubrun2", nested=True) as subsubrun2:
mlflow.log_param("p4","blue")
mlflow.log_metric("m5", 3.25)
with mlflow.start_run(experiment_id=0, run_name="subrun2", nested=True) as subrun2:
mlflow.log_param("p2","magenta")
mlflow.log_metric("m2", -.25)
Не всегда вы будете запускать эксперименты из Jupyter-ноутбуков. Часто это будут делать какие-то ETL-инструменты, шедулеры, кроны. Поэтому нужно научиться оборачивать Jupyter-ноутбуки в Python-скрипты. На GitHub находится код, повторяющий Jupyter-ноутбук и обернутый в одну функцию. С помощью библиотеки fire удобно использовать командную строку, в которой мы запускаем код с MLflow с помощью команды:
!python run_job.py --random-state 777
В интерфейсе видим, что добавилась вторая версия driver_accident_demo. Это логично, так как перед этим был только один запуск.
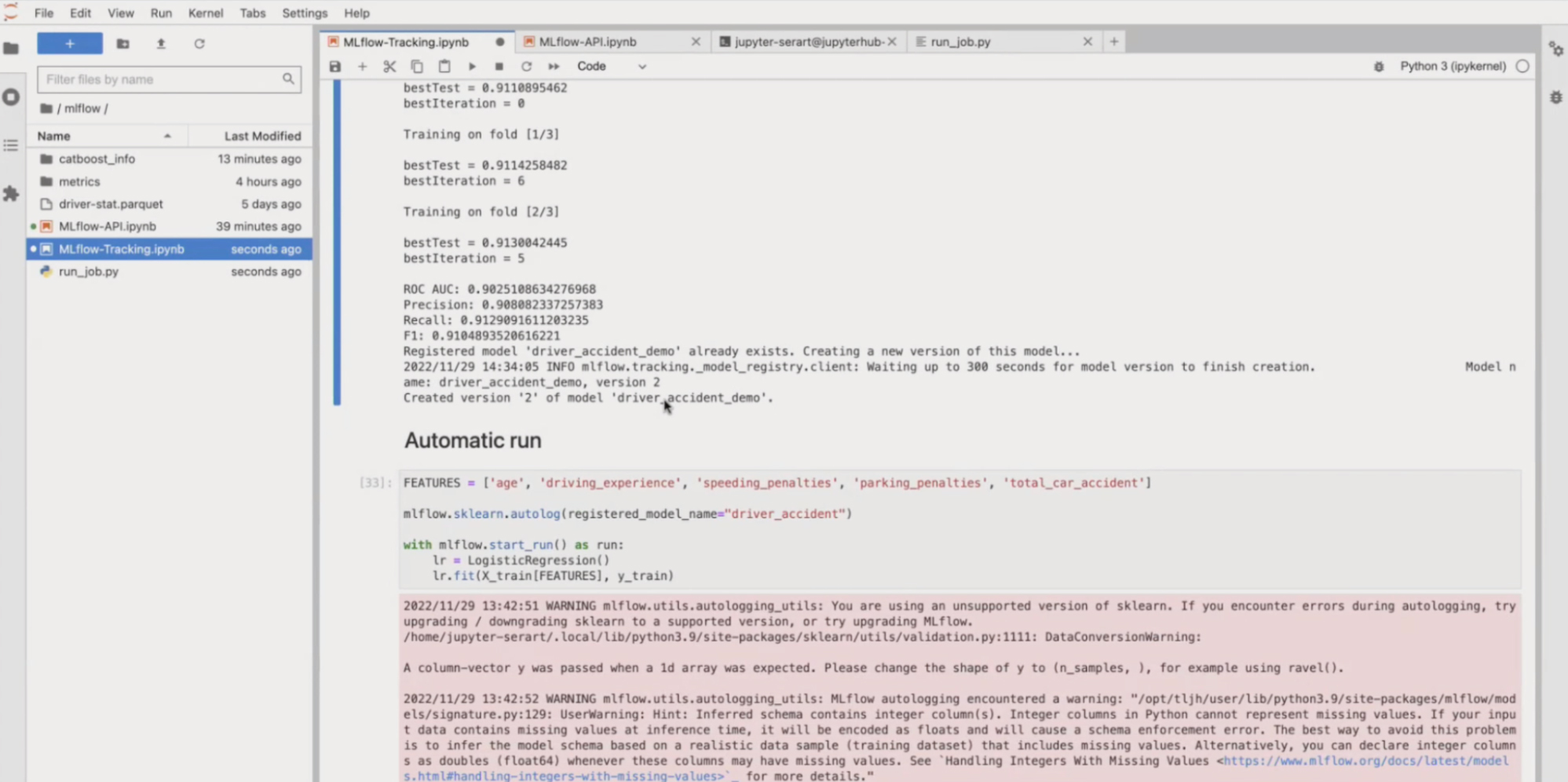
На скрине ниже видим параметры и метрики. Мы написали укороченный скрипт, поэтому там не было тегов и графиков, но при желании их можно добавить.

Внутри эксперимента мы видим две строки и номер каждой версии. Можно настроить фильтры по колонкам, метрикам и другим запросам. Это удобно, когда у вас больше 50 экспериментов: намного проще найти и сравнить то, что нужно.
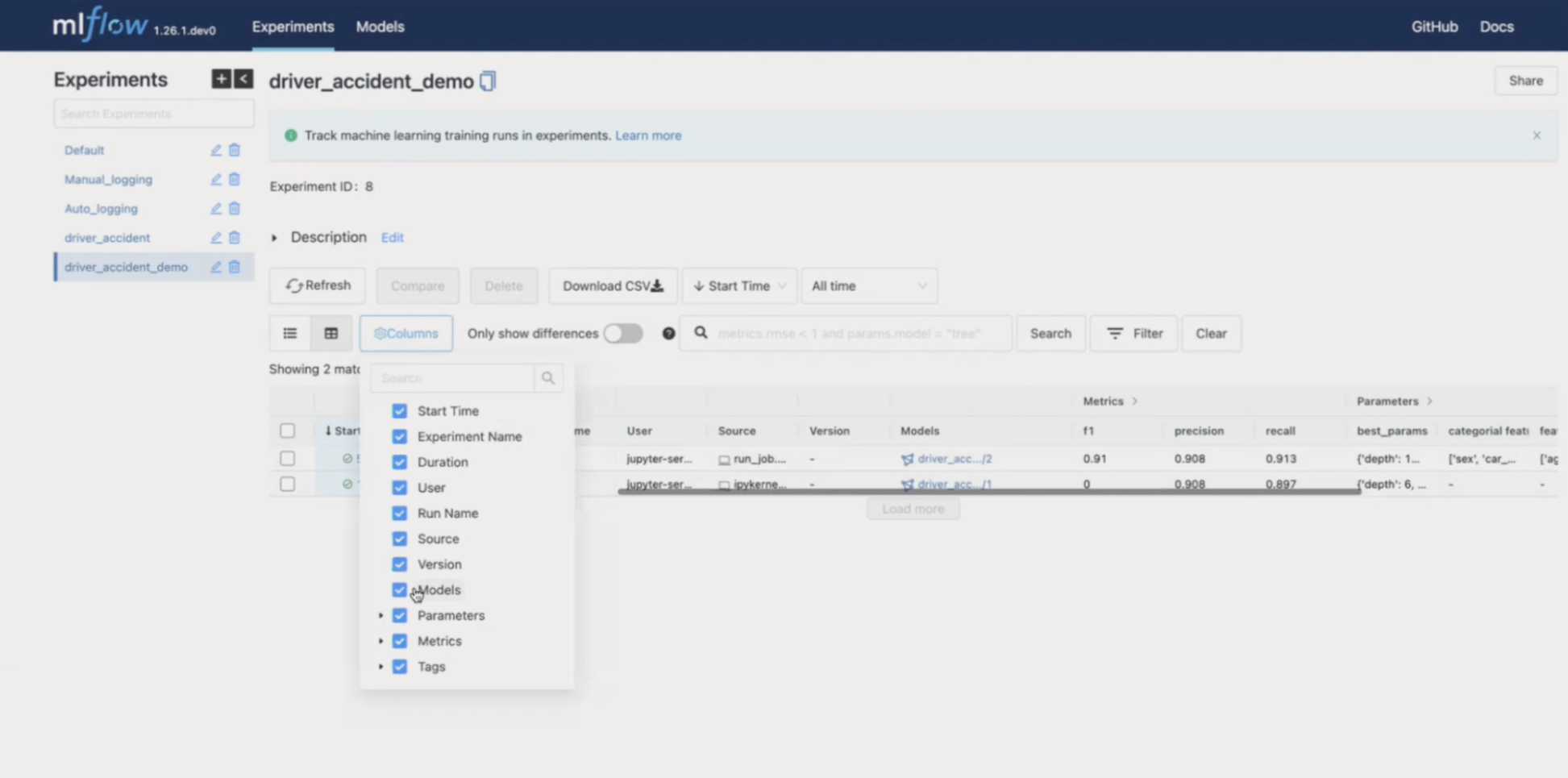
Еще одна фича — автологирование. Перед стартом важно вызвать автологирование и указать название модели. Если этого не сделать и просто запустить, то в колонке Models не будет ссылки на последнюю версию. Будет просто ссылка на run, а это уже не очень.
mlflow.sklearn.autolog(registered_model_name="driver_accident_demo")
with mlflow.start_run() as run:
lr = LogisticRegression()
lr.fit(X_train[FEATURES], y_train)
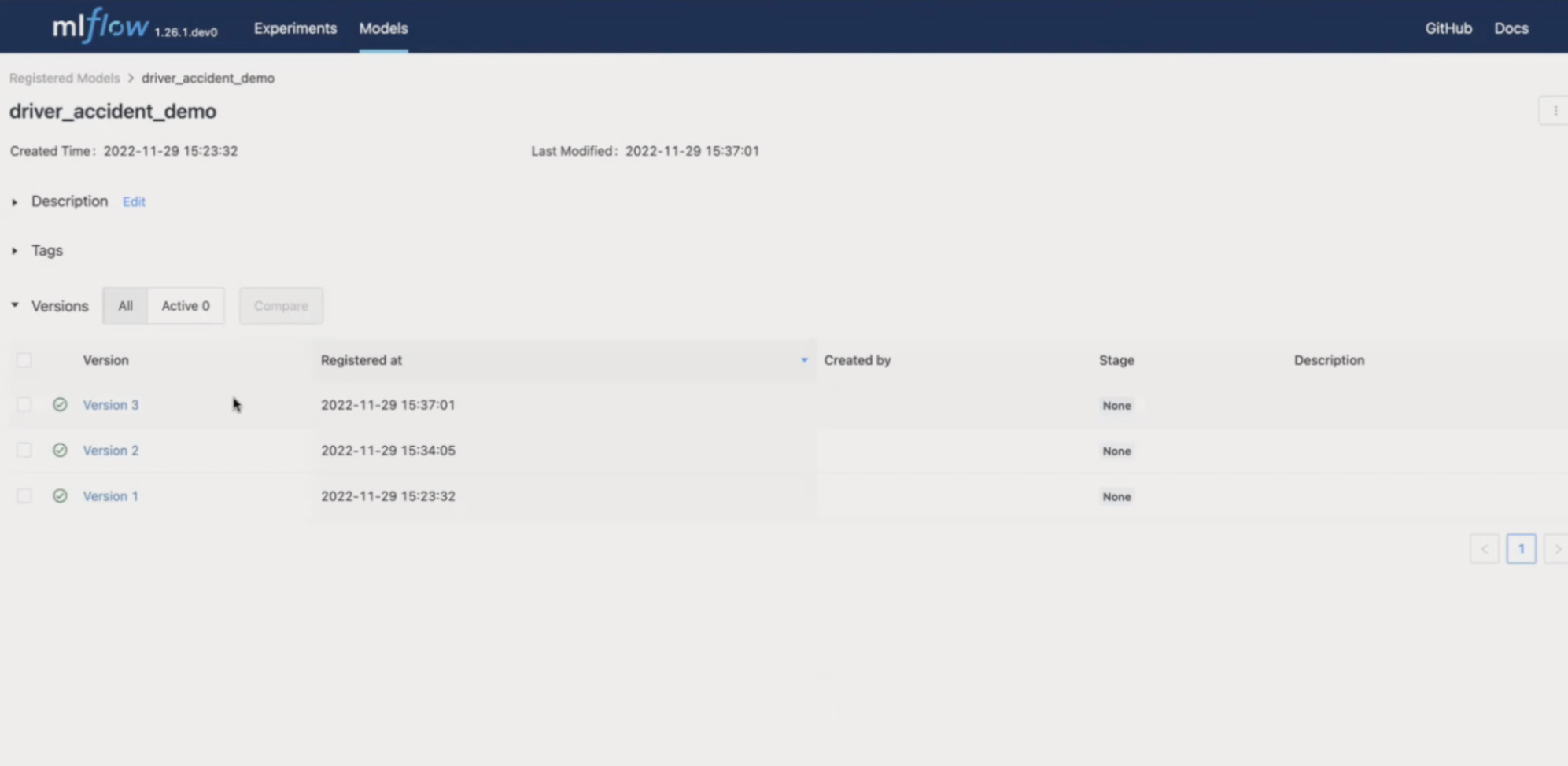
MLflow API
Теперь расскажем, как настроить MLflow, чтобы обращаться к нему через API.
Делаем нужные импорты и создаем клиент, который будет общаться с MLflow:
import mlflow
import os
import datetime
import mlflow
from mlflow.tracking import MlflowClient
import pandas as pd
from sklearn.metrics import roc_auc_score, precision_score, recall_score, f1_score
client = MlflowClient()
Затем выводим список экспериментов со всеми ID
client.list_experiments()

На скриншоте видно, что в списке нет эксперимента с id = 7. До этого мы удалили его, но нумерация не продолжилась. Если вы хотите, чтобы номера ID присваивались по порядку, несмотря на удаление, то нужно очистить базу данных — подробнее о том, как это сделать, описали на GitHub.
Самый удобный способ запросить информацию об эксперименте — вызвать его по имени.
exp = client.get_experiment_by_name('driver_accident_demo')
exp
После этого выводим список всех run.
client.list_run_infos(exp.experiment_id)
Затем узнаем информацию о последнем эксперименте.
run_info = client.list_run_infos(exp.experiment_id)[-1]
run_info
С помощью ID эксперимента можно получить о нем всю информацию: параметры, метрики, время и так далее. Это полезно для того, чтобы переиспользовать артефакты в других задачах.
run_id = run_info.run_id
run_id
run = client.get_run(run_id)
run

Также можно вывести весь список моделей после вызова функции:
client.list_registered_models():
last_models = client.list_registered_models()
reg_model = last_models[2]
reg_model
Если нужно получить информацию о второй версии, то устанавливаем параметр 2:
last_models = client.list_registered_models()
reg_model = last_models[2]
reg_model
Еще внутри объекта можно вызвать последнюю версию модели, которая находится в продакшене:
reg_model.latest_versions
def get_last_prod_model(model_name: str):
last_models = client.get_registered_model(model_name).latest_versions
models = list(filter(lambda x: x.current_stage == 'Production', last_models))
if len(models) == 0:
return None
else:
return models[0]
С помощью команды ниже можно узнать последнюю версию:
m_version = model_version.version
m_version
Загрузка модели
Есть два способа загрузить модель:
- Написать путь через model.
- Запустить через run.
В каждом случае важно правильно указать, какую версию использовать. Если загружать через model, то команда будет выглядеть следующим образом:
logged_model = f'models:/driver_accident_demo/{m_version}
loaded_model = mlflow.pyfunc.load_model(logged_model)
import pandas as pd
predict = loaded_model.predict(test_df)
Если хотите загружать через run, то укажите адрес run и название модели:
logged_model = 'runs:/26b40e069ae34d82b35999f81671b606/driver_accident_demo
В обоих случаях используется сабмодуль pyfunc, в котором есть метод load_model — он может загрузить любую модель в объект и сделать предсказание на наших данных.
Сервировка моделей
На этом этапе мы запускаем локальный сервер, в котором MLflow разворачивает модель на основе всех полученных файлов. Здесь будет использоваться порт, который нужно дополнительно открыть в VK Cloud. Чтобы избежать ошибок в работе, лучше сделать это заранее.
!mlflow models serve -m models:/driver_accident_demo/1 --port 10201
После этого можно обращаться к модели через консоль Jupyter. Мы посылаем запрос, а JSON репрезентует одну строку из дата-сета.
curl
"dataframe_records": [{"age":18, "sex":"male", "car_class":"A", "driving_experience":5, "speeding_penalties":5, "parking_penalties":1, "total_car_accident":0}]
}'```
В нашем случае это возраст, пол, описание машины, опыт водителя и так далее. После этого получаем предсказание для одной строчки, в нашем случае значение class = 0, а значит, водитель не попадал в ДТП. А если изменить количество ДТП на пять, то предсказание изменится на class = 1. Таким образом можно понарошку тестировать модели или демонстрировать их на хакатоне.
Полный листинг по работе с API
Недавно в Cloud ML Platform появился модуль MLflow Deploy, упаковывающий ML-модели в Docker-контейнеры, которые автоматически разворачиваются в облаке. Модуль делает модели доступными по REST API для решения задач Real-Time Serving.
Новым пользователям VK Cloud после регистрации мы автоматически начислим грант 3000 рублей на работу с Cloud ML Platform.