

В SQL Server наименьшая единица хранения — это страница в 8 КБ с 96-байтовым заголовком, в котором хранится системная информация.
Данные в таблицах могут быть организованы двумя способами:
Кластерный индекс (clustered index)
Данные хранятся в виде B+ — дерева в соответствии с заданным ключом кластерного индекса. SQL Server сохраняет строки в правильной логической последовательности.
Куча (heap)
Куча — это таблица без кластерного индекса. Данные в куче хранятся без какого-либо логического порядка. Между страницами нет никакой связи. Хотя для кучи можно создать некластерный индекс, который будет содержать физический адрес исходных данных. В некластерном индексе для каждой записи содержится номер файла, номер страницы и номер слота внутри этой страницы.
Перед тем, как вставить новую запись в кучу, SQL Server читает PFS-страницу (Page Free Space). И если на странице достаточно свободного места, то сохраняет новую строку на данной странице. А если свободного места недостаточно, то выделяет экстент (восемь новых страниц данных — 64 КБ) и сохраняет данные на новой странице. PFS отслеживает место на страницах данных, используя два бита, указанные ниже:
0x00 | Пустая страница |
0x01 | Страница заполнена на 50% |
0x02 | Страница заполнена на 51 — 80% |
0x03 | Страница заполнена на 81 — 95% |
0x04 | Страница заполнена на 96 — 100% |
Демонстрация проблемы с forwarded-записями
Допустим, мы изменяем данные в куче и SQL Server не может разместить новые данные на существующей странице из-за их большого размера. В этом случае сами данные размещаются в другом месте, а на данной странице SQL Server вставляет Forwarded Record (запись о перенаправлении). Также в новом местоположении данных добавляется указатель в обратную сторону на созданную Forwarded Record для отслеживания цепочки forwarding-указателей в случае перемещения данных.
Давайте создадим кучу и воспроизведем создание forwarded-записей.
Создайте базу данных и таблицу Employees
CREATE DATABASE SQLShack;
GO
USE SQLShack;
GO
CREATE TABLE Employees
([EmpID] INT IDENTITY(1, 1),
[Name] NVARCHAR(100),
[BirthDate] DATETIME,
[Salary] INT
);Вставьте несколько строк.
INSERT INTO Employees
VALUES('Rajendra', '1986-03-16', 50000);
GO 2000
INSERT INTO Employees
VALUES ('Sonu', '1980-11-29', 50000);
GO 1000Таблицы-кучи можно найти с помощью системного представления sys.indexes, у куч index_id равен нулю. Следующая команда покажет необходимую информацию:
SELECT OBJECT_NAME(object_id) AS tablename,
index_id,
type_desc
FROM sys.indexes
WHERE object_id = OBJECT_ID('Employees');
Для просмотра дополнительной информации (процент фрагментации индекса, тип индекса, количество страниц и количество forwarded-записей) можно использовать динамическую административную функцию (Dynamic Management Function, DMF) sys.dm_db_index_physical_stats. Все эти данные доступны в DETAILED-режиме этого DMF:
SELECT
OBJECT_NAME(DIPS.object_id) as DBTableName,
DIPS.index_type_desc,
DIPS.avg_fragmentation_in_percent,
DIPS.forwarded_record_count,
DIPS.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS DIPS
WHERE OBJECT_NAME(DIPS.object_id) = 'Employees' AND forwarded_record_count is NOT NULL
Для таблицы Employees мы видим 17 страниц (page_count) и отсутствие forwarded-записей (forwarded_record_count).
Вставим еще несколько строк. Это должно увеличить количество страниц и фрагментацию индекса:
INSERT INTO Employees
VALUES ('Kusum', '1985-09-25', 60000);
GO 2000Запустим повторно указанный выше DMF-запрос и посмотрим на количество страниц и forwarded-записей:
Количество страниц увеличилось с 17 до 27.
Фрагментация увеличилась (
avg_fragmentation_in_percent) с 33 до 50%.Количество forwarded-записей все еще равно нулю.

Теперь изменим значение в колонке [Name] таблицы Employee:
UPDATE Employees
SET [Name] = 'Rajendra Kumar Gupta'
WHERE [Name] = 'Rajendra';Опять используем DMF и посмотрим количество forwarded-записей:
Количество страниц увеличилось с 27 до 35.
Количество forwarded-записей увеличилось с нуля до 747.

Давайте выполним еще несколько изменений, используя следующий запрос:
UPDATE Employees
SET [Name] = 'Kusum Kashish Agarwal'
WHERE [Name] = 'Kusum'В результате:
Количество страниц увеличилось с 35 до 46.
Количество forwarded-записей увеличилось с 747 до 1752.

SQL Server не смог разместить измененные значения на существующих страницах и создал forwarded-записи, которые увеличили page_count и forwarded_record_count.
Вопрос: возникают ли проблемы с forwarded-записями?
Да, мы можем увидеть их влияние на производительность. Давайте выполним запрос для поиска в столбце [Name]. Также включим STATISTICS IO для сбора необходимой статистики:
SET STATISTICS IO ON;
SELECT *
FROM dbo.Employees
WHERE name LIKE 'Rajendra%';В плане выполнения мы видим оператор Table Scan для кучи:

Ниже на рисунке показано, как SQL Server использует IAM-страницу для поиска необходимых страниц и экстентов. Он анализирует экстенты, принадлежащие куче, и обрабатывает их в порядке их распределения:
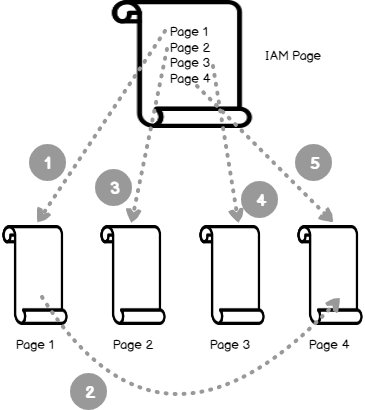
При изменении распределения страниц также изменяется порядок, в котором страницы должны быть прочитаны. В данном случае из-за их распределения сначала читается страница 3 (Page 3), а потом страница 2 (Page 2):

В статистике выполнения запроса мы видим 1798 логических чтений:

В случае большой таблицы можно увидеть значительное увеличение количества логических чтений, что может вызывать проблемы с производительностью при выборке данных и DML.
Исправление проблем с forwarded-записями
Используйте типы данных фиксированной длины
Иногда кучи используются для промежуточных таблиц (staging tables). И лучший способ исправить проблемы с forwarded-записями и избежать большого количества логических чтений — это использовать типы с фиксированной длиной. Не используйте типы переменной длины, если этого не требуется.
Используйте кластерный индекс
Добавьте кластерный индекс в таблицу: он отсортирует данные и будет хранить их в соответствии с выбранным ключом кластерного индекса. В идеале в таблице всегда нужно определять первичный ключ, поскольку он по умолчанию создает кластерный индекс и является ключом этого индекса.
Мониторинг и перестроение кучи
Если в связи с каким-либо специфическим требованием вы не можете использовать типы фиксированной длины или создать кластерный индекс в таблице, тогда лучший способ — это просто мониторить таблицы на наличие Forwarded Records, используя скрипты, приведенные выше. Начиная с SQL Server 2008 для перестроения кучи можно использовать команду ALTER TABLE ... REBUILD. Она также обновляет соответствующие некластерные индексы.
Логические чтения до перестроения таблицы

Перестраиваем кучу
Выполните следующую команду, чтобы перестроить таблицу Employee:
ALTER TABLE Employees REBUILD;
Смотрим логические чтения после REBUILD

Можно заметить следующие изменения:
Логических чтений до REBUILD: 1798
Логических чтений после REBUILD: 40
Команда ALTER TABLE ... REBUILD полностью перестраивает кучу и убирает все forwarded-записи. После перестроения forwarded-записи отсутствуют. Давайте проверим это:
Количество страниц уменьшилось с 46 до 40.
Количество forwarded-записей стало равным нулю (было 1752).
Средняя фрагментация кучи также уменьшилась до нуля с предыдущих 33%.

Выводы
Грамотное проектирование баз данных очень важно как с точки зрения разработчика, так и с точки зрения администратора, чтобы избежать проблем с производительностью, связанных со структурой базы. В этой статье мы рассмотрели проблемы с большим количеством логических чтений из-за forwarded-записей в heap-таблицах. Также из-за forwarded-записей тратятся впустую страницы и появляются проблемы с производительностью ввода-вывода для больших таблиц. Старайтесь избегать создания куч и при необходимости предпринимайте необходимые шаги, описанные выше.
В преддверии старта курса MS SQL Server приглашаем всех желающих посетить бесплатный демо-урок по теме: "Графовые базы данных в SQL Server"

andreyverbin
В чем преимущество heap перед кластерным индексом? Я не могу ничего придумать, но PG и, оказывается, MS SQL используют этот метод.
ialexander
Записи фиксированной длины эффективнее и индексировать, и искать. Поэтому, в heap выгоднее сбрасывать излишне большие данные (varchar больше определенной длина и тп).
Плюс в heap быстрее запись, не нужно тратить время на индекс, можно просто сбросить данные. Поэтому, если данные записал и забыл, то лучше heap.