
Уже больше 20 лет я пишу код на разных языках программирования. Так как многие из этих языков считаются мертвыми, то сегодня я буду говорить о высоком искусстве некромантии — о том, как якобы мертвые языки используются в больших и иногда высоконагруженных проектах. Обрабатывая тысячи веб-запросов в секунду и не порождая необходимости писать свой компилятор PHP или переходить на Go или Rust.
Я расскажу про специфику Ruby и Python при высоких нагрузках, про их мейнстрим, который вы можете встретить в выживших проектах. Я не буду и не хочу говорить про спортивное программирование, где делают миллион запросов в секунду на одной ноде, выжигая из Python или Ruby всё и оставляя голый С. Python и Ruby действительно медленные, у них есть GIL, но при правильном использовании это не проблема, а статья расходов — и я расскажу, что мы можем получить за эти деньги.
Если вы предпочитаете слушать или смотреть (у меня там забавные крылья!) — видео моего выступления на конференции HighLoad++ Весна 2021.

Мы в Evrone занимаемся заказной разработкой. Делаем бэкенд, веб, ERP, CRM с использованием широкого стека технологий: Python, Ruby, Go, Rust, фронтенд, даже Elixir иногда. Среди наших многочисленных клиентов мы обнаружили мнение, что для каждой задачи есть какой-то лучший инструмент. И если мы делаем highload, то, наверное, обязательно его писать на Си, или на худой конец на Rust. Или на Go, если у нас очень много микросервисов.
А потом люди неожиданно понимают, что мир не черно-белый. К примеру, приходят к руководству питонисты, все 20 человек, и говорят: «Знаете, мы уже давно делаем machine learning, вам всё нравится, но вообще мы же питонисты! Мы хотим делать не только machine learning! У нас есть Django, есть FastAPI — давайте мы вам немножко бэкендика забабахаем!» Руководство сидит и думает: «Но мы же highload. Как можно использовать Python в highload? Это же противоестественно» — и не знает, что ответить.
А бывают еще более страшные истории, когда молодые амбициозные разработчики говорят: «Мы посмотрели, как Дэвид Хейнемейер Ханссон с помощью фулстека Ruby сделал Hey.com вчера, и этот Hey.com держит сотни тысяч подключений, и Ruby прямо такой фулстечный! Давайте мы тоже зафигачим — будет быстро, качественно, недорого!»
Сидит руководство и думает: «Хм, быстро, качественно и недорого — ведь не бывает такого! А если на HeadHunter зайти, там питонистов 5 тысяч, а рубистов — всего жалкая тысяча. Как же можно писать большие проекты на Ruby? Непонятно».
Этим кто-нибудь пользуется?

Я не последний некромант. Если посмотреть на такие большие проекты, как Uber, Instagram, Reddit — все они написаны на Python. И они не просто написаны на Python. Разработчики этих компаний также, как и я, рассказывают, что они писали на Python, пишут на Python, будут писать на Python, что Python — это круто. Что им нравится, они реализуют highload, решают амбициозные задачи и быстро фигачат фичи.
А Shopify, Netflix или GitHub? Они — сюрприз! — написаны на Ruby. И разработчики из этих компаний также радостно докладывают о своих результатах. Например, в GitHub рассказывают, как они портировали GitHub со старой версии Rails на новые версии Rails, как они всё это превозмогали, но как им понравилось. И как они быстро пилят фичи и все отлично работает под большими нагрузками.
Посмотрим на топ-50 стартапов Y Combinator:

Что бы ни говорили про Y Combinator, но в их топе-50 стартапов за несколько лет, которые прибыльны и приносят миллиарды долларов, мы видим: Python, Ruby, Python, Ruby, Ruby, Ruby, Python.
Мейнстрим
Nginx
Python и Ruby проекты начинаются с Nginx. Это исторически сложившаяся защита мягкого подбрюшья «application servers».
Много лет назад, когда Nginx только создавался, сервера приложений Perl и PHP не могли быстро обрабатывать большое количество медленных запросов. Если тысяча клиентов набегали на бэкенд инфраструктуру и начинали по одному байтику что-то запрашивать, то бэкенд-инфраструктура на этом заканчивалась. Тогда был создан Nginx, который способен через себя проксировать все эти запросы, отсюда название — reverse proxy.
Потом Nginx начал решать CPU intensive задачи, брать на себя сертификаты, HTTP/2 (внутри современных Python и Ruby проектов вы часто можете встретить HTTP/1.1) и кэширование. Вовремя включенное кэширование способно ускорить бэкенд в 10, а если повезет, то и в 20 раз.
Nginx может общаться с application server по бинарному протоколу или по HTTP-протоколу. Как показал сервер uWSGI для Python — разницы особой нет. А вот если говорить о самом application сервер, пастухе стада питонов — там разница есть: он заботится о запущенных процессах Python.
Application сервер
Application серверов много. В 2020 году разработчиков Ruby спросили, какой application сервер они используют. Оказалось, что application сервер Puma стал лидером практически единогласно.

У питонистов почему-то такое не спрашивают. Я несколько месяцев выяснял это в тусовке питонистов, и многие говорят, что используют традиционный исторический uWSGI, но у кого-то в ходу и современный хипстерский Gunicorn, и асинхронный Waitress. Согласия в мире питонистов нет, но в целом мы видим, что подавляющее большинство питонистов и рубистов application сервера используют.
Application сервер в мире Python и Ruby разработки играет фундаментальную роль. Он загружает Python, указывает ему запустить некоторое количество потоков, в каждый поток загрузить приложение и по входящим запросам вызывает код этих приложений.
Именно Application сервер контролирует количество процессов и потоков, может их автоматически масштабировать и ограничивать ресурсы (процессор, память, диск).
Он следит за запущенными процессами Python, его не просто так называют пастухом. Если какой-то из процессов начал слишком медленно отвечать на запросы или использовать слишком много CPU, то именно application сервер убьет и вновь подымет его из мертвых.
Раньше Application сервера использовались и для того, чтобы перезапускать веб-приложения без обрыва соединений и перезапуска всего. Но сейчас Docker и Kubernetes подходят для этого гораздо лучше, да и решается такая задача там проще.
Еще Application сервера собирают метрики и разнообразные логи в бэкенды, предоставляют API для ваших плагинов. Например, написав плагин к Puma или к uWSGI, можно указать, что точно является критерием того, что приложение работает плохо. А потом покопаться у него внутри и узнать подробности.
Application сервера обеспечивают выполнение фоновых задач, потому что в популярных протоколах общения application серверов и бэкендов в принципе не было такой возможности. Например, самый популярный протокол общения с Ruby — Rack, а с Python — WSGI, и там просто не предусмотрено функциональности фоновых задач. Конечно, сейчас всё это уже есть, но пока новьё можно встретить только на очень новых проектах.
Application сервера реализуют очереди, таймеры, локи, RPC, WebSockets, у них свой собственный уровень роутинга и кэширования, как в Nginx. И это на самом деле не просто так.
Application сервера для Python и Ruby разработчиков позволяют распределить сложность: часть роутинга и кэширования отдать Nginx, другую часть поместить в application сервер, а что-то реализовать на уровне приложения. Распределение сложности по проекту позволяет делать большие проекты более читаемыми и писать читаемый код.
Современные application сервера делают много всего, но главное — они запускают процессы, потоки и в этих потоках выполняют код бэкенд-приложения.
Процессы, потоки, GIL и GC
Приведу аналогию трёх стульев. Она технически некорректная, но позволяет очень просто, «на пальцах» объяснить разницу между языками и работает для большинства случаев. Авторы большинства известных мне современных мейнстрим-языков программирования хотят реализовать три штуки:
Скорость — чтобы написанные на этом языке программы быстро выполнялись;
Совместимость по памяти — чтобы из этого языка можно было вызвать OpenSSL или другую библиотеку, передать ей огромный буфер в несколько десятков или сотен мегабайт, и библиотека смогла бы с этим буфером работать.
Высокоуровневый синтаксис, который не заставляет программиста заботиться о памяти, но позволяет использовать «резиновые» массивы и словари. Чтобы о памяти вместо программиста думал язык программирования.
Когда любой язык программирования выбирает два любых стула, третий становится очень сложным.
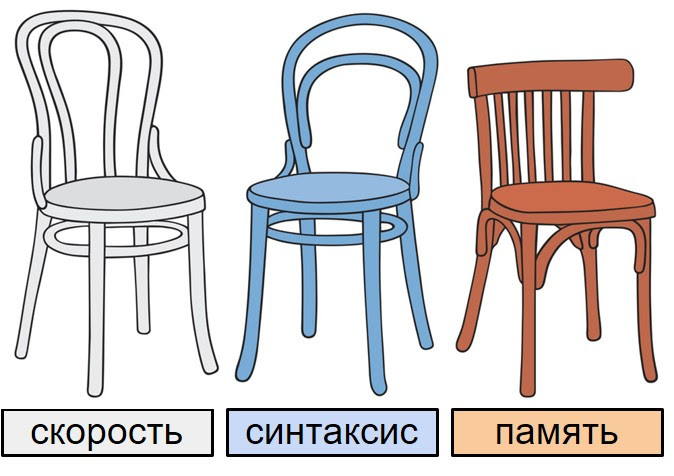
Если язык программирования хочет быть быстрым и совместимым по памяти, то код должен быть перемолот в очень мелкую кашицу, размазан по регистрам, по кэшам первого, второго и даже третьего уровня — чтобы он максимально быстро раскладывался по памяти. Потому что у современных процессоров обращение к памяти примерно в 100 раз медленнее, чем другие операции. Получаем компилируемый код — C, Rust, Go, C++. Но синтаксис такого языка вынуждает разработчика самому заботиться о памяти.
Если язык программирования хочет быть быстрым, и чтобы программист не заботился о памяти, чтобы он писал высокоуровневый код, то такой язык сам перемелет этот код в очень мелкую кашицу. Это быстрые высокоуровневые языки Java, C#, JavaScript, но сделать к ним нативное расширение будет болью. Потому что в любой момент за каждым куском памяти может прийти Compacting Garbage Collector и сказать: «Отдай мне эту память, мне ее надо переложить». Тяжело писать расширения к Java. К JavaScript полегче, но там отдельная история.
Наконец, если язык хочет быть совместим со всем огромным количеством нативного кода, который уже написан и он хочет предложить программистам высокоуровневый, удобный, приятный синтаксис, чтобы программистам не надо было заботиться о памяти, о слайсах, о времени жизни объектов — то такой язык будет медленным.
Поэтому, размножаясь процессами и потоками, Python, Ruby и PHP используют GIL (Global Interpreter Lock) для простого управления памятью. Его боятся все питонисты (так же как рубисты боятся GVL, Global Virtual Machine Lock). Это страшная штука не позволяет больше, чем одному потоку работать одновременно в рамках запущенного процесса Python или Ruby.
И GIL сделан не просто так. Он нужен, чтобы языки реализовывали «резиновые» контейнеры, списки и ассоциативные массивы, которые могут расти невозбранно в любую сторону. А также чтобы в этих языках были быстрые сборщики мусора — цена, которую Python и Ruby платят за крутой, удобный, высокоуровневый синтаксис и за расширяемость по памяти.
«Поднять» Global Interpreter Lock для многопоточности помогают нативные расширения. Тогда Python или Ruby, которые запустили 16 потоков, в каждом из них смогут отправить данные по сети одновременно. Правда, первый же вернувшийся обратно в виртуальную машину высокоуровневый код заставит остальные потоки подождать.
Garbage collector при этом можно отключить. Например, в Wargaming пишут всю бизнес-логику танков на Python и отключают garbage collector. Но не тот garbage collector, который reference counting, а mark-and-sweep — и стараются писать код, который не делает циклических зависимостей, то есть не течет по памяти.
Если говорить про Ruby, то, к примеру, в очень больших монолитах, которые обслуживают десятки или сотни тысяч запросов в секунду, большой garbage collector приходит примерно на один запрос из ста и тормозит весь этот балаган на 100 мс. А маленький garbage collector приходит раз в 10 запросов, но всего на 10 мс — и это не критично, если мы делаем бизнес-логику, а не числодробилки.

Мейнстрим в Python и Ruby использует процессы для размножения CPU intensive tasks, а потоки для асинхронности — база данных, диск, сетка.
В данный момент я не знаю хорошего способа сесть сразу на три стула. Либо вручную заботимся о памяти, либо ее за нас превратят в несовместимую ни с чем кашицу. Поэтому на практике используются высокоуровневые, но неторопливые Python и Ruby вместе с нативными расширениями на Rust или C++. Конечно, это не серебряная пуля, и во многих highload-случаях такая интеграция не пройдет. Но для бизнес-логики этого достаточно.
Процессы и потоки в Python
Процессы и потоки выполняют код. Рассмотрим, как это организовано в Python. Запустился Python, ему подложили 5 Мб сорцов, и дальше компилятор Python скомпилирует эти сорцы в байткод.
Компилятор => байткод => VM для памяти и семантики
Да, Python компилирует сорцы, как и Ruby. Подавляющее большинство мейнстримовых языков сейчас компилируются. Python и Ruby — компилируются в байткод, и дальше этот байткод выполняется виртуальной машиной. А, например, в Java, сначала компилируется байткод, который потом выполняется виртуальной машиной и перекомпилируется в машинный код.
На Web Framework Benchmarks можно посмотреть, как себя ведет Python под нагрузкой. Очень крутое железо с повышенным количеством ксеонов, памяти, ядер, дисков и всего остального на голом Python выполняет чуть меньше миллиона запросов в секунду. Но если подключить Django, то количество запросов сразу падает в 10 раз и бэкенд начинает «тормозить».

Что же такое делает Django, что тормозит Python в 10 раз? Я очень внимательно посмотрел на сорцы, на документацию, на стек, на отладчик и обнаружил — вы не поверите! — Django выполняет код. Он выполняет много-много питоновского кода, который реализует фичи.
Так как это фреймворк, то в самом Django реализуется много всего. Это и ORM, и Routing, и работа с шаблонами. Да, мы любим React, Vue и Server-Side Rendering, но очень много проектов не настолько сложны. Они используют шаблоны и формочки, чтобы за 20 минут сделать интерфейс ERP.
Внутри Django есть Middleware API для плагинов, который на каждый запрос съедает чуть-чуть (несколько десятков) байткодов. И, конечно, в Django есть развесистые механизмы кэширования, логирования и тестирования.
Есть еще миллион мелочей, которые используются в больших проектах: sessions, auth, forms, security, cfg, notify, email, files, i18n и CLI. В довесок в Django есть командный интерфейс для разработчиков, с помощью которого они способны наскаффолдить (от английского scaffold) себе приложение за 10-15 минут.
То есть современный фреймворк делает много всего, позволяя Python-разработчикам быть продуктивными и очень быстро выкатывать бизнес-фичи. Но ценой скорости. Это опять же подходит для бизнес-логики, но не подходит для числодробилок.
Процессы и потоки в Ruby
А как обстоят дела с Ruby? Собственно, точно так же. Ruby тоже берет исходники, компилирует их в байткод, а затем виртуальная машина байткод выполняет, чтобы обеспечить богатую семантику и заботу о памяти — чтобы разработчики могли писать высокоуровневый код и не париться.
Компилятор => байткод => VM для памяти и семантики
А еще Ruby — сама неторопливость (на видео я в этот момент картинно развожу руки и еще глубже опускаю капюшон). Он в 4 раза медленнее Python на тех же бэкенд-задачах. Хотя можно найти некую закономерность. Голый Ruby дает 200 с небольшим тысяч запросов в секунду, а как только мы ставим его на рельсы — скорость падает в 10 раз:

Ruby фреймворк тормозит ровно по тем же причинам. Я сравнил полторы тысячи страниц документации Django, и несколько сотен страниц документации Ruby on Rails. Количество фичей, которые фреймфорки предлагают разработчикам, очень похоже. Каждая из них съедает по чуть-чуть байткода — и в результате вся система позволяет очень быстро фигачить код, но работает в 10 раз медленнее.
Хорошо, вот есть JavaScript — точно такой же высокоуровневый язык программирования, который точно также компилируется в байткод виртуальной машины, а потом перекомпилируется с помощью JIT в машинные коды, и все очень-очень быстро. Давайте добавим JIT в Ruby!
Несколько версий назад это сделали, но оказалось, что ускорение возможно только на синтетических задачах. Например, на задаче трех тел, когда есть несколько планет и мы много раз в секунду считаем гравитационное взаимодействие между ними. Автор Юкихиро Мацумото назвал такие задачи «синтетическими бенчмарками»яя. Они действительно ускорились в 10 раз, но Ruby on Rails немножко затормозил. То есть JIT не помогает.
Почему? Потому что Ruby on Rails большой, а код начинает тормозить в современных процессорах, когда не укладывается в кэши. Движок V8 для JavaScript создан для того, чтобы компилировать код в мелкую кашицу, размазывая его по кэшам процессора. Чтобы код выполнялся быстро, они принесли в жертву совместимость по памяти (на самом деле нет, но там отдельная, сложная и печальная история. Тяжело сидеть на трех стульях).
А Python и Ruby хотят использовать OpenSSL и сишные extension’ы и не хотят Compacting Garbage Collector. Поэтому компиляция кусочков кода с существующим рантаймом языка, с существующей семантикой работы памяти не приведет к ускорению огромного rails-приложения. Rails-приложение просто не влезает в кеши, использует слишком много динамического кода рантайма и нативные расширения. И отказывается работать быстрее.
Выводы
Как один из организаторов сообщества разработчиков Moscow Python, на митапах и Python-завтраках я много рассказываю про асинхронность. Но если говорить про выжившие Python и Ruby проекты, что делались несколько лет назад, то async мы там, скорее всего, не встретим, как и FastAPI. Там будет Django, Flask, Ruby on Rails, Hanami. Стоять они будут за Nginx, на котором, к примеру, если включить кэш, можно их ускорить в 10-20-30 раз.
Бизнес-логику в современных бэкендах можно писать на чем угодно. Балансировка между нодами слабо зависит от того, на каком именно языке реализовано бэкенд-приложение, крутящееся на этих нодах. CPU-bound масштабировался и масштабируется процессами. А базу, память, сеть, диск, процессор уже оптимизировали за нас. Во все остальные места можно вставить Rust или С.
Поэтому современный стек (Python или Ruby) позволяют разработчикам быстро выкатывать фичи, но ценой того, что код может «тормозить» в странных местах. К примеру, у нас может тормозить не наша бизнес-логика, не база, а — неожиданно — ORM, к которому обратились не тем заклинанием. Современные ORM позволяют легко делать много разных крутых штук, но также легко можно выстрелить себе в ногу.
Поэтому от Python и Ruby разработчиков требуется высокая квалификация, чтобы при той скорости, с которой они выкатывают фичи, их код не тормозил. Чтобы начать использовать SQLAlchemy, нужно прочитать несколько сотен страниц документации и несколько лет учиться. К сожалению, не все это делают.
На предстоящей конференции Python Conf++ 2021 я расскажу почему "простой" Python скатывается в неподдерживаемый ужас, в котором уже через год не могут разобраться ни сам автор, ни его коллеги.
27-28 сентября впервые за два года мы встречаемся офлайн. Приходите, нам есть, что обсудить. Билеты, расписание и тезисы докладов.
Комментарии (29)

permeakra
13.09.2021 13:27+4Если честно, не понял, в чем смысл статьи. Текст проговаривает самоочевидные вещи, но при этом объяснение им дается переупрощенное до неправильности.



Paskin
15.09.2021 08:58+1Мне кажется, что для реальной коммерческой разработки нужно еще учитывать "выразительность" языка/платформы.
Потому что лишний день, потраченный на написание кода, глубокую оптимизацию и поиск утечек памяти - равен по стоимости пяти, а то и больше приличным по мощности серверам в облаке. При всем уважении к Грете Тунберг...

sedyh
21.11.2021 03:06Я бы не стал приписывать Go к группе C и Rust, где «синтаксис языка вынуждает разработчика самому заботиться о памяти».
zoryamba
Если не ошибаюсь, rust таки успешно сидит на всех 3-х стульях. Единственный недостаток - это время компиляции. Но, думаю, это цена, которую не жалко заплатить за гарантии, которые он дает.
grigoryvp Автор
Скорее JavaScript пытается) Раст требует от разработчика заботиться о памяти. Жестко требует: семантика владения, borrow checker, ручное разделение на стек с кучей, вот это вот все.
zoryamba
Мне кажется, что "заботиться" о памяти нужно в С. В rust-е о ней заботится компилятор. Если оно скомпилилось - значит оно не течет(unsafe не в счет :)). При этом даёт очень внятные объяснения о том, что в коде не так. А владение и заимствование - можно принять как особенности языка.
phtaran
заботиться о памяти в Раст по прежнему нужно, изменился только способ. Нужно постоянно учитывать владение, и время жизни объектов. Компилятор только говорит ошибки, код вместо программиста он не пишет.
Sulerad
И утечки памяти Rust не находит. Они не приводят к UB, так что с точки зрения языка в этом ничего страшного нет. Можно легко получить утечку при помощи метода
Box::leak, ну или просто создав цикл изRefCountzoryamba
А можно вопрос, что именно javascript пытается? Все тот же GC и все тот же GIL. Единственное, что до недавнего времени отличало js от python - это non-blocking IO. Но asyncio тут всех уравнял. И хоть асинхронная экосистема в python-е еще не совсем зрелая, принципиального отличия между python+asyncio и js я не вижу. Оно есть?
grigoryvp Автор
Он одновременно предлагает высокоуровневый синтаксис не требующий заботы о памяти, хорошую совместимость с нативным кодом (с оговорками, но не идет ни в какое сравнение с JNI) и компиляцию в нативный код. JavaScript - быстрый:
https://benchmarksgame-team.pages.debian.net/benchmarksgame/performance/nbody.html
DirectoriX
Источник — ваша ссылка
grigoryvp Автор
JIT это и есть компиляция в нативный код.
bromzh
Ну тогда питон тоже в нативный код может компилироваться с помощью pypy. Почему вы выделяете js отдельно?
Кстати, стоит ещё упомянуть lua + luajit - отличная интеграция с Си, отличная скорость с jit-компилятором, нет ручного управления памятью.
grigoryvp Автор
https://benchmarksgame-team.pages.debian.net/benchmarksgame/performance/nbody.html - у JS несколько лучше получается. Подробнее тут: https://youtu.be/39XNklRQJI4 (дисклеймер - в части про ядра и тайминги адовое упрощение)
bromzh
Ну да, где-то получается лучше (хотя этот бенчмарк всегда вызывал очень много вопросов в плане адекватности). Я даже знаю, что почти всегда лучше. А на некоторых задачах pypy быстрее сишки.
Но раз вы считаете, что js компилируется в нативный код из-за jit, то и питон давайте туда же.
permeakra
AFAIK, Ruby и Python дают прямой доступ к словарям методов класса в рантайме для модификации. В JS даже такого понятия нет, весь код очень локальный.
zoryamba
Ок, в скорости python проигрывает, даже на порядки. Но все-равно, в критических ситуациях GC и "single-threaded by design" делают js непригодным к "сидению на 3-х стульях." (ситуациях, как эта, например: https://blog.discord.com/why-discord-is-switching-from-go-to-rust-a190bbca2b1f). Да и весь интернет полон статей о том, как избавиться от утечек в node.js, так что говорить, что он не требует заботы о памяти тоже не совсем корректно.
Так что в целом я считаю, что rust, все же, лучший кандидат на этот пост. Со скоростью, близкой к С, без GC и с минимальной болью от контроля памяти :)
grigoryvp Автор
Вот насчет "минимальной боли" я не оч согласен. Раст прямо таки требует о памяти заботиться.
zoryamba
Конечно требует. GC то нет :) Если бы не требовал - была бы боль как в С. Но как по мне, делает это самым вразумительным и элегантным способом :)
К стати, а что на счет go? мне кажется он, как минимум, не хуже ноды по всем трем параметрам. Дополнительным бонусом еще и полноценная многопоточность. Разве нет?
grigoryvp Автор
Go интересен тем, что у него GC есть, а о памяти заботиться все равно надо! Что показывает, что "высокоуровневый синтаксис" и "garbage collection" - это штуки часто связанные, но не одно и то же. Аллокация на стеке, куче, array фиксированного размера, слайсы - все это требует от разработчика заботиться о памяти в том же объеме, что в C++ или Rust. Меняются только подходы - как именно мы о памяти заботимся ????
phtaran
хз, может я не в теме, есть какие-то примеры подводных камней, связанных с тем что вы назвали? Утечку можно и в java сделать, скорее всего в Го тоже, но уровень мороки мне кажется меньше
DirectoriX
Rust «всего лишь» не даёт придерживаться подхода «тяп-ляп и в продакшен», т.к. заставляет лишний раз подумать, а почему же вот эта вот проблема с borrow-checker'ом вообще возникла. Если памятью (в каждый конкретный момент времени) никто не владеет — это утечка, а если владелец есть — borrow-checker порадуется вместе с вами.


Кстати, об утечках памяти в JS/V8:
Проявляется исключительно в случаях, когда JS многократно вызывает обработчики сообщений из WebSocket, перестраивая DOM. GC срабатывает когда у ОС уже (почти) не остаётся памяти, при этом в воспроизводящемся в Chrome видео пропадает звук. Да, вина не только JS/V8, но в основном.
0xd34df00d
Тогда хаскель возьмите. Очень приятный FFI в C, никаких GIL, никаких борроу чекеров, даже понятия стека нет, все заботы при FFI сводятся к «значится, надо взять для куска данных тип
ByteString».insecto
Только нет приличных способов to reason about performance and memory. То есть, стулья не надо выбирать, стульев вообще нет.
0xd34df00d
Пишете в начале модуля
{-# LANGUAGE Strict #-}и дальше живёте как в энергичном языке (помня, конечно, что условный прелюдовый[]от этого строгим не становится).permeakra
Если писать код через задницу, его ни в одном языке нет. В хаскеле для производительности требуется писать код с использованием определенных идиом и расставлять восклицательные знаки в стратегических местах, да, но это не так сложно.