
Добрый день, сегодня мы развернем serverless инфраструктуру на базе AWS lambda для загрузки изображений (или любых файлов) с хранением в приватном AWS S3 bucket. Использовать мы будем terraform скрипты, залитые и доступные в моем репозитории kompotkot/hatchery на GitHub.
У изложенного подхода следующие преимущества:
lambda вызывается по запросу и если данный функционал не является ключевым для вашего приложения, то позволяет экономить на содержании сервера
у функций lambda изолированная среда работы, что идеально подходит для задач обработки загружаемых файлов. В случае загрузки вредоносного кода, атакующий не сможет выйти за пределы песочницы, сессия которой, в свою очередь, будет принудительно завершена спустя определенное время
хранение файлов на S3 bucket крайне дешевое удовольствие
Структура проекта
Для примера мы будем использовать абстрактное приложение для ведения заметок с API. В каждую заметку мы можем загрузить картинку, а структура аналогична директории с файлами:
- journal_1
- entry_1
- image_1
- entry_2
- image_1
- image_n
- entry_n
- journal_nУ нашего гипотетического API имеется эндпоинт для получения заметки (entry) в журнале (journal):
curl \
--request GET \
--url 'https://api.example.com/journals/{journal_id}/entries/{entries_id}'
--header 'Authorization: {token_id}'Если в ответ на этот эндпоинт status_code равен 200, значит пользователь авторизован и имеет доступ к данному журналу. Соответственно мы позволим ему сохранить картинки для этой заметки.
Регистрация приложения на Bugout.dev
Во избежание добавления дополнительной таблицы в БД, которая нам обязательно потребуется для хранения записей о том, какой заметке, какая картинка принадлежит, мы воспользуемся resources от Bugout.dev.
Данный подход использован в целях упрощения нашей инфраструктуры, но если необходимо, то данный шаг можно заменить на создание новой таблицы в вашей БД и написание API для сохранения, изменения и удаления записей о сохраняемых картинках. Код Bugout.dev открыт и вы можете ознакомиться документацией API ресурсов в репозитории на GitHub.
Нам понадобится аккаунт и группа под названием myapp (название может быть любым в зависимости от вашего проекта) на странице Bugout.dev Teams и сохраним ID этой группы для следующего шага (в нашем случае, это e6006d97-0551-4ec9-aabd-da51ee437909):

Далее создадим Bugout.dev Application под нашу группу myappс помощью curl запроса, токен можно сгенерировать на странице Bugout.dev Tokens, и сохраним его под переменной BUGOUT_ACCESS_TOKEN:
curl \
--request POST \
--url 'https://auth.bugout.dev/applications' \
--header "Authorization: Bearer $BUGOUT_ACCESS_TOKEN" \
--form 'group_id=e6006d97-0551-4ec9-aabd-da51ee437909' \
--form 'name=myapp-images' \
--form 'description=Image uploader for myapp notes' \
| jq .В ответ мы получим подтверждение, об успешно созданном приложении:
{
"id": "f0a1672d-4659-49f6-bc51-8a0aad17e979",
"group_id": "e6006d97-0551-4ec9-aabd-da51ee437909",
"name": "myapp-images",
"description": "Image uploader for myapp notes"
}Данный ID f0a1672d-4659-49f6-bc51-8a0aad17e979 мы будем использовать для хранения resources, где каждый ресурс - это метаданные загружаемой картинки. Структура задается в произвольной форме в зависимости от необходимых ключей, в нашем случае она будет выглядеть следующим образом:
{
"id": "a6423cd1-317b-4f71-a756-dc92eead185c",
"application_id": "f0a1672d-4659-49f6-bc51-8a0aad17e979",
"resource_data": {
"id": "d573fab2-beb1-4915-91ce-c356236768a4",
"name": "random-image-name",
"entry_id": "51113e7d-39eb-4f68-bf99-54de5892314b",
"extension": "png",
"created_at": "2021-09-19 15:15:00.437163",
"journal_id": "2821951d-70a4-419b-a968-14e056b49b71"
},
"created_at": "2021-09-19T15:15:00.957809+00:00",
"updated_at": "2021-09-19T15:15:00.957809+00:00"
}Итого мы получаем своего рода удаленную БД, где мы будем каждый раз писать во время загрузки картинки в S3 bucket о том в какой журнал (journal_id) и в какую заметку (entry_id) была добавлена картинка с каким ID, названием и расширением.
Подготовка окружения под проект на AWS
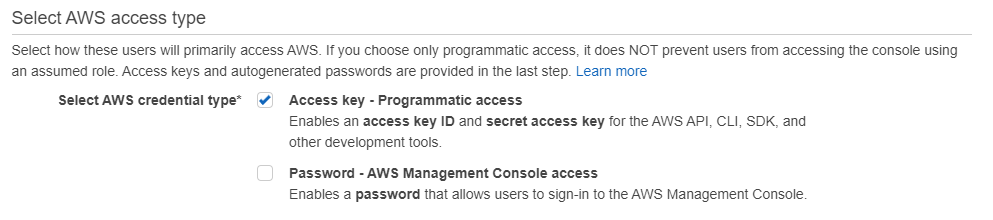
На AWS будут храниться картинки в S3 bucket и функционировать сервер на lambda для манипуляций с картинками. Нам понадобиться аккаунт AWS и настроенный IAM пользователь для terraform. Это аккаунт типа Programmatic access с доступом ко всем ресурсам без возможно работы с веб консолью:
Нам понадобятся ключи, для этого добавьте в свое окружение следующие переменные:
export AWS_ACCESS_KEY_ID=<your_aws_terraform_account_access_key>
export AWS_SECRET_ACCESS_KEY=<your_aws_terraform_account_secret_key>Также развернем свою VPC с подсетями:
2 приватного доступа
2 публичного доступа
Они пригодятся для настройки AWS Load Balancer. Код данного модуля находится в files_distributor/network, отредактировав переменные в файле variables.tf запустим скрипт:
terraform applyИз вывода добавьте в переменные окружения значения для AWS_HATCHERY_VPC_ID, AWS_HATCHERY_SUBNET_PUBLIC_A_ID и AWS_HATCHERY_SUBNET_PUBLIC_B_ID.
Код сервера
В нашем проекте мы будем использовать простую AWS lambda функцию. По опыту использования, я заметил, что при превышении размера пакета с кодом свыше 10МБ, резко падает скорость загрузки кода на AWS. Даже при предварительной заливке на S3 bucket и последующем создании lambda из него, AWS может подвистуть на продолжительный срок. Поэтому если вам необходимы сторонние библиотеки, то имеет смысл воспользоваться lambda layers. Так же, если вы планируете обойтись без сторонних библиотек с легковесным кодом в связке с CloudFront, то имеет смысл присмотреться к lambda@edge.
Полная версия кода представлена в файле lambda_function.py в репозитории. На мой взгляд, эффективнее работать на nodejs, но для детальной работы с файлами мы воспользуемся python. Код состоит из основных блоков:
MY_APP_JOURNALS_URL = "https://api.example.com" # API эндпоинт для доступа к нашему приложению с заметками
BUGOUT_AUTH_URL = "https://auth.bugout.dev" # Bugout.dev эндпоинт для записи ресурсов (метаданных картинок)
FILES_S3_BUCKET_NAME = "hatchery-files" # Название S3 bucket, где мы будем хранить картинки
FILES_S3_BUCKET_PREFIX = "dev" # Префикс S3 bucket, где мы будем хранить картинки
BUGOUT_APPLICATION_ID = os.environ.get("BUGOUT_FILES_APPLICATION_ID") # Bugout.dev application ID созданный ранееРасширим базовое исключение, чтобы проксировать ответ от Bugout.dev Resources. Например, если картинки не существует, то при запросе необходимого ресурса, нам вернется 404 ошибка, что мы в свою очередь и вернем клиенту, как ответ на запрос о несуществующей картинке.
class BugoutResponseException(Exception):
def __init__(self, message, status_code, detail=None) -> None:
super().__init__(message)
self.status_code = status_code
if detail is not None:
self.detail = detailДля сохранения картинки в S3 bucket воспользуемся стандартной библиотекой cgi, позволяющей нам распарсить тело запроса переданное в формате multipart/<image_type>. И сохранять картинки будем с указанием пути {journal_id}/entries/{entry_id}/images/{image_id} без указания расширения и названия файла.
def put_image_to_bucket(
journal_id: str,
entry_id: str,
image_id: UUID,
content_type: str,
content_length: int,
decoded_body: bytes,
) -> None:
_, c_data = parse_header(content_type)
c_data["boundary"] = bytes(c_data["boundary"], "utf-8")
c_data["CONTENT-LENGTH"] = content_length
form_data = parse_multipart(BytesIO(decoded_body), c_data)
for image_str in form_data["file"]:
image_path = f"{FILES_S3_BUCKET_PREFIX}/{journal_id}/entries/{entry_id}/images/{str(image_id)}"
s3.put_object(
Body=image_str, Bucket=FILES_S3_BUCKET_NAME, Key=image_path
)Во время извлечения картинки из S3 bucket нам потребуется закодировать в base64 для корректной передачи.
def get_image_from_bucket(journal_id: str, entry_id: str, image_id: str) -> bytes:
image_path = f"{FILES_S3_BUCKET_PREFIX}/{journal_id}/entries/{entry_id}/images/{image_id}"
response = s3.get_object(Bucket=FILES_S3_BUCKET_NAME, Key=image_path)
image = response["Body"].read()
encoded_image = base64.b64encode(image)
return encoded_imageКод функции lambda_handler(event,context) доступен на GitHub по ссылке, где происходит следующее:
В начале мы проверяем, что запрос правильного формата и содержит
journal_idиentry_idВыполняем запрос к API нашего гипотетического приложения
https://api.example.com/journals/{journal_id}/entries/{entry_id}с заголовком авторизацииheaders={"authorization": auth_bearer_header}Далее в зависимости от метода запроса:
GET,POSTилиDELETEмы читаем, загружаем или удаляем картинку для заметки в журналеВо время добавления файла в S3 bucket, мы проверяем расширение и размер файла. Данный функционал можно расширить проверкой хэша, чтобы избежать загрузки одинаковых файлов и тд.
Далее нам потребуется упаковать в lambda библиотеку requests, к счастью boto3 для работы с AWS функционалом доступна из коробки lambda функции. Создадим пустое python окружение, установим библиотеку и упакуем содержимое site-packages:
python3 -m venv .venv
source .venv/bin/activate
pip install requests
cd .venv/lib/python3.8/site-packages
zip -r9 "lambda_function.zip" .Поместим созданный архив lambda_function.zip в директорию files_distributor/bucket/modules/s3_bucket/files и добавим код самой lambda функции:
zip -g lambda_function.zip -r lambda_function.pyНаш сервер готов, теперь можно загружать код на AWS и разворачивать lambda сервер, для чего воспользуемся скриптом в files_distributor/bucket:
terraform applyВ итоге мы получим:
Приватный AWS S3 bucket
hatchery-sources, где хранится код для lambda функцииПриватный AWS S3 bucket
hatchery-filesкуда мы будем сохранять наши картинки с префиксомdevAWS lambda функцию с рабочим кодом сервера
IAM роль для lambda, позволяющий писать в конкретный S3 bucket и логи
Правила для IAM роли находятся в files_distributor/bucket/modules/iam/files/iam_role_lambda_inline_policy.json. Другой файл iam_role_lambda_policy.json необходим для корректного функционирования lambda функции.
Для дебага lambda достаточно добавить print необходимых значений или воспользоваться стандартным пакетом logging в python. Вывод выполнения каждого вызова функции доступен в AWS CloudWatch:

После создания функции добавьте переменную BUGOUT_FILES_APPLICATION_ID из нашего кода в lambda окружение, что можно сделать во вкладке Configuration/Environment variables.
Для последнего шага сохраните AWS lambda arn в переменную AWS_HATCHERY_LAMBDA_ARN.
Настройка AWS Load Balancer и выход в мир
Теперь остался один шаг, создать AWS Security Group, где мы создадим порт на котором будет слушать AWS Load Balancer для последующей передачи данных в lambda функцию (в нашем случае это 80 и 443).
terraform apply \
-var hatchery_vpc_id=$AWS_HATCHERY_VPC_ID \
-var hatchery_sbn_public_a_id=$AWS_HATCHERY_SUBNET_PUBLIC_A_ID \
-var hatchery_sbn_public_b_id=$AWS_HATCHERY_SUBNET_PUBLIC_B_ID \
-var hatchery_lambda_arn=$AWS_HATCHERY_LAMBDA_ARNПоздравляю, наша AWS lambda функция открыта миру и готова загружать и отдавать картинки для нашего приложения с заметками!
Комментарии (28)

Shatun
20.09.2021 17:51+1Несколько дополнений:
Если вам нужно только хранение файлов то S3 гораздо проще использовать без лямбды.
Если нужно еще сохранение метадату то как вариант повесить триггер на S3, который вызывается при добавлении туда объекта.
Оба варианта неуниверсальны, но для определнных юзкейсов будут удобнее, чем сохранение через лямбду.

KompotKot Автор
20.09.2021 21:16Ваш подход имеет место быть при одном условии, если S3 bucket имеет публичный доступ, в противном случае без прослойки в виде сервера не обойтись. Иначе не получится организовать аутентификацию.
Можно конечно генерировать временные ссылки на объект, но они имеют ограниченный период действия, точно не помню 24 часа или 3 дня..
lair
20.09.2021 21:28+1Ваш подход имеет место быть при одном условии, если S3 bucket имеет публичный доступ, в противном случае без прослойки в виде сервера не обойтись. Иначе не получится организовать аутентификацию.
API Gateway прекрасно решает эту проблему.
Shatun
20.09.2021 21:31+1Доступ в S3 можно ограничивать по IAM. Или например использовать Api Gateway+S3. Lambda для этого ненужна.
KompotKot Автор
20.09.2021 21:43Доступ извне вы не ограничите по IAM, когда клиенты приходят из разных уголков мира и доступ к entries (заметкам в журнале) в которые вы планируете сохранять картинки через lambda хранятся в виде зарегистрированных юзеров в вашем приложении, к которому необходимо постоянно обращаться, можно ли сохранять или отдавать картинку конкретному пользователю.
Думаю, я не достаточно развернуто описал usecase в статье. :)lair
20.09.2021 21:50+3Проблема вашего подхода в том, что у вас код авторизации написан прямо внутри лямбды. Это значит, что (а) его придется дублировать из лямбды в лямбду, если у вас много обработчиков и (б) на неавторизованный запрос все равно будет подниматься вся прикладная лямбда (со всем телом запроса), что невыгодно.
lair
20.09.2021 18:50+3А зачем вам вообще VPC?
Ну и да, прогонять через лямбду тело файла, которое вам надо просто положить в S3 — плохая идея, зачем память-то лишний раз тратить?
KompotKot Автор
20.09.2021 21:22Без VPC вы не создадите subnet, без subnet вы не создадите TargetGroup и LoadBalancer и в свою очередь сможете настроить Alias в Route53 во время создания записи с красивым uri формата images.myapp.com.
Не соглашусь, что это плохая идея, в зависимости от того какие цели преследуете, например как вы убедитесь, что картинка не та же самая, что уже была загружена для данной заметки? Тут нам нужно посчитать хэш и без сервера не обойтись. Тут конечно, можно рассчитать, что будет выгоднее, хранение одинаковых файлов в S3 bucket или лишний раз загрузить файл в lambda.
И конечно, функционал может быть расширен очень сильно - вычищать метаданные картинки (что делают все уважающие себя соц сети), сжимать и тд.lair
20.09.2021 21:27+2Без VPC вы не создадите subnet, без subnet вы не создадите TargetGroup и LoadBalancer и в свою очередь сможете настроить Alias в Route53 во время создания записи с красивым uri формата images.myapp.com.
Если цель — сделать красивый адрес, то API Gateway + Custom Domain прекрасно решают задачу без создания лоадбалансера.
Не соглашусь, что это плохая идея, в зависимости от того какие цели преследуете,
Я же специально написал: просто положить в S3.
И конечно, функционал может быть расширен очень сильно — вычищать метаданные картинки (что делают все уважающие себя соц сети), сжимать и тд.
Вот только может так оказаться, что намного эффективнее это делать не в лямбде при загрузке, а в лямбде, которая обрабатывает уже загруженный файл по событию — потому что она может читать файл из S3 чанками, а не обязана съесть все, что пришло в HTTP-запросе.
KompotKot Автор
20.09.2021 21:39Если цель — сделать красивый адрес, то API Gateway + Custom Domain прекрасно решают задачу без создания лоадбалансера.
API Gateway + Custom Domain известный подход, думаю тут нужно отталкиваться от инфраструктуры. Аналогов данной статьи я не встречал, где мы имеем VPC с двумя подсетями. Конкретно это подход можно развивать уже далее, размещая сервера в приватную сеть, организовывая доступ через бастион хост и тд.
Вот только может так оказаться, что намного эффективнее это делать не в лямбде при загрузке, а в лямбде, которая обрабатывает уже загруженный файл по событию — потому что она может читать файл из S3 чанками, а не обязана съесть все, что пришло в HTTP-запросе.
Да, как вариант, если нам не нужна авторизация (можно ли сохранять картинку или нет)
lair
20.09.2021 21:42+1Аналогов данной статьи я не встречал, где мы имеем VPC с двумя подсетями.
Так непонятно, зачем это, учитывая, что у вас заявленная задача — "serverless хранение файлов в S3", а S3, насколько я помню, плевать хотел VPC.
Конкретно это подход можно развивать уже далее, размещая сервера в приватную сеть, организовывая доступ через бастион хост и тд.
Зачем это для описанной в посте задачи?
Да, как вариант, если нам не нужна авторизация (можно ли сохранять картинку или нет)
Да нет, эта авторизация прекрасно делается на API Gateway (и, что характерно, она будет униформной для лямбды и для S3).
KompotKot Автор
20.09.2021 21:50Зачем это для описанной в посте задачи?
Методы решения задачи могут любые, в данном примере решено через Load Balancer, можно через CloudFront, можно через API Gateway.
lair
20.09.2021 21:51+1Я пытаюсь до вас донести (точнее, не столько до вас, сколько до будущих читателей статьи), что создавать VPC для реализации поставленной в посте задачи — избыточно.

random1st
21.09.2021 10:38Во-первых, в начале статьи надо поместить дисклаймер "Глаза!". Во-вторых, правильным способом загрузки файлов является генерация подписанных ссылок - ни API Gateway из-за лимита 10Мб/30с, ни короткоживущая лямбда, тем более еще тратящая деньги на трафик в S3 (тут насколько я понял лямбда вообще грузит файл даже через public endpoint) не подходят. Дальше можно не читать.
KompotKot Автор
21.09.2021 11:14Предложенный вами подход с генерацией presign url не подходит, так как у них ограниченное время жизни ссылок (как я уже отвечал выше). Допустим для заметки вы загрузили картинку, вставили на нее ссылку в эту заметку, а через 36 часов она не валидна и не отображается.
random1st
21.09.2021 11:16ссылки генерятся на загрузку, а не отдачу, раздача идет через Cloudfront. У Cloudfront другой механизм генерации ссылок (если он вообще нужен).
KompotKot Автор
21.09.2021 11:48ссылки генерятся на загрузку, а не отдачу, раздача идет через Cloudfront. У Cloudfront другой механизм генерации ссылок (если он вообще нужен).
Но в таком случае доступен только функционал загрузки, но как отдать конечному юзеру файл, в вашем варианте? У Signed URLs необходимо задать публичный ключ, для верификации, это удобно для взаимодействия между сервисами, но не с тысячами пользователей.
random1st
21.09.2021 14:49Еще раз - совсем не обязательно подписывать урлы на отдачу. Отдать их можно и публично. Кмк вы просто плохо ориентируетесь в AWS, тот механизм который у вас в статье описан от best practices находится примерно напротив.
К тому же подписанный Cloudfront URL вовсе не означает что каждому потребителю нужен сертификат. И никакого отношения к межсервисному взаимодействию не имеет - не тот сервис. RTFM
KompotKot Автор
21.09.2021 15:32Во-первых, best practices - это общепринятые решения, потрудитесь мне привести аналог решения моей задачи, либо это голословные утверждения.
Во-вторых, я не AWS архитектор, я могу признать, что решение не оптимальное, но если выше @lair расписал подробно и объяснил его точку зрения. То вы даже не потрудились привести примерный пайплайн решения проблемы, при чем я скинул ссылку на доки где указано, что генератор CloudFront URL требует публичный ключ.
Особенно после следующего утверждения:ни API Gateway из-за лимита 10Мб/30с, ни короткоживущая лямбда ... не подходят
Интересно послушать как выполнить аутентификацию на стороннем API api.myapp.com, обработать (сжать, конвертировать) изображение и сохранить его в S3 bucket.
random1st
21.09.2021 16:05Послушайте, задача в принципе тривиальная - хотя вы сами никоим образом картинки не обрабатываете. Я мог бы расписать примерное решение, но, как бы ни расписывал есть два ключевых момента 1) грузить файлы надо напрямую в S3 2) отдавать файлы надо через Cloudfront. Все остальное уже плюс-минус индифферентно. Почему - читайте мануалы, считайте прайсы, думайте о безопасности.
lair
21.09.2021 21:20Выдать короткоживущую ссылку на загрузку с помощью лямбды (которая за api gateway), потом обработать по событию S3 чем угодно.
darkneo
А чем это лучше AWS SAM?
KompotKot Автор
AWS SAM прекрасный инструмент, просто другой подход, в отличии от использования terraform, который конкретно мне ближе. :)
darkneo
Спасибо. Для меня подход с Terraform выглядит как стрельба из пушки по воробьям, да и много операций приходится выполнять руками. С AWS SAM подобная задача решилась бы двумя ресурсами (собственно, функцией и S3 бакетом) и не потребывала прописывания переменных окружения через UI.
Но с Terraform тоже, конечно, вариант.
Stas911
Посоветую заодно посмотреть CDK, если еще не.