
2021 год в машинном обучении ознаменовался мультимодальностью — активно развиваются нейросети, работающие одновременно с изображениями, текстами, речью, музыкой. Правит балом, как обычно, OpenAI, но, несмотря на слово «open» в своём названии, не спешит выкладывать модели в открытый доступ. В начале года компания представила нейросеть DALL-E, генерирующую любые изображения размером 256×256 пикселей по текстовому описанию. В качестве опорного материала для сообщества были доступны статья на arxiv и примеры в блоге.
С момента выхода DALL-E к проблеме активно подключились китайские исследователи: открытый код нейросети CogView позволяет решать ту же задачу — получать изображения из текстов. Но что в России? Разобрать, понять, обучить — уже, можно сказать, наш инженерный девиз. Мы нырнули с головой в новый проект и сегодня рассказываем, как создали с нуля полный пайплайн для генерации изображений по описаниям на русском языке.
В проекте активно участвовали команды Sber AI, SberDevices, Самарского университета, AIRI и SberCloud.
Мы обучили две версии модели разного размера и дали им имена великих российских абстракционистов — Василия Кандинского и Казимира Малевича:
ruDALL-E Kandinsky (XXL) с 12 миллиардами параметров;
ruDALL-E Malevich (XL) c 1.3 миллиардами параметров.
Некоторые версии наших моделей доступны в open source уже сейчас:
ruDALL-E Malevich (XL) [GitHub, HuggingFace, Kaggle]
Sber VQ-GAN [GitHub, HuggingFace]
ruCLIP Small [GitHub, HuggingFace]
Super Resolution (Real ESRGAN) [GitHub, HuggingFace]
Две последние модели встроены в пайплайн генерации изображений по тексту (об этом расскажем ниже).
Потестировать ruDALL-E Malevich (XL) или посмотреть на результаты генерации можно здесь:
Версии моделей ruDALL-E Malevich (XL), ruDALL-E Kandinsky (XXL), ruCLIP Small уже доступны в DataHub. Модели ruCLIP Large и Super Resolution (Real ESRGAN) скоро будут доступны там же.
Обучение нейросети ruDALL-E на кластере Christofari стало самой большой вычислительной задачей в России:
Модель ruDALL-E Kandinsky (XXL) обучалась 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100 — всего 20 352 GPU-дней;
Модель ruDALL-E Malevich (XL) обучалась 8 дней на 128 GPU TESLA V100, а затем еще 15 дней на 192 GPU TESLA V100 — всего 3 904 GPU-дня.
Таким образом, суммарно обучение обеих моделей заняло 24 256 GPU-дней.
Разберём возможности наших генеративных моделей.
")
Почему Big Tech изучает генерацию изображений
Долгосрочная цель нового направления — создание «мультимодальных» нейронных сетей, которые выучивают концепции в нескольких модальностях, в первую очередь в текстовой и визуальной областях, чтобы «лучше понимать мир».
Генерация изображений может показаться достаточно избыточной задачей в век больших данных и доступа к поисковикам. Однако, она решает две важных потребности, которые пока не может решить информационный поиск:
Возможность точно описать желаемое — и получить персонализированное изображение, которое раньше не существовало.
В любой момент создавать необходимое количество licence-free иллюстраций в неограниченном объеме.
Первые очевидные применения генерации изображений:
Фото-иллюстрации для статей, копирайтинга, рекламы. Можно автоматически (а значит — быстрее и дешевле) создавать иллюстрации к статьям, генерировать концепты для рекламы по описанию:



-
Иллюстрации, свободные от лицензии фотостоков, тоже можно генерировать бесконечно:

«Векторная иллюстрация с розовыми цветами»
-
Визуализации дизайна интерьеров — можно проверять свои идеи для ремонта, играть с цветовыми решениями, формами и светом:

«Шикарная гостиная с зелеными креслами» 
«Современное кресло фиолетового цвета» -
Visual Art — источник визуальных концепций, соединений различных признаков и абстракций:

«Темная энергия»






Более подробно о самой модели и процессе обучения
В основе архитектуры DALL-E — так называемый трансформер, он состоит из энкодера и декодера. Общая идея состоит в том, чтобы вычислить embedding по входным данным с помощью энкодера, а затем с учетом известного выхода правильным образом декодировать этот embedding.

В трансформере энкодер и декодер состоят из ряда идентичных блоков.

Основу архитектуры трансформера составляет механизм Self-attention. Он позволяет модели понять, какие фрагменты входных данных важны и насколько важен каждый фрагмент входных данных для других фрагментов. Как и LSTM-модели, трансформер позволяет естественным образом моделировать связи «вдолгую». Однако, в отличие от LSTM-моделей, он подходит для распараллеливания и, следовательно, эффективных реализаций.
Первым шагом при вычислении Self-attention является создание трёх векторов для каждого входного вектора энкодера (для каждого элемента входной последовательности). То есть для каждого элемента создаются векторы Query, Key и Value. Эти векторы получаются путем перемножения embedding’а и трех матриц, которые мы получаем в процессе обучения. Далее мы используем полученные векторы для формирования Self-attention-представления каждого embedding’а, что дает возможность оценить возможные связи в элементах входных данных, а также определить степень «полезности» каждого элемента.
Трансформер также характеризует наличие словаря. Каждый элемент словаря — это токен. В зависимости от модели размер словаря может меняться. Таким образом, входные данные сначала превращаются в последовательность токенов, которая далее конвертируется в embedding с помощью энкодера. Для текста используется свой токенизатор, для изображения сначала вычисляются low-level-фичи, а затем в скользящем окне вычисляются визуальные токены. Применение механизма Self-attention позволяет извлечь контекст из входной последовательности токенов в ходе обучения. Следует отметить, что для обучения трансформера требуются большие объёмы (желательно «чистых») данных, о которых мы расскажем ниже.
Как устроен ruDALL-E
Глобальная идея состоит в том, чтобы обучить трансформер авторегрессивно моделировать токены текста и изображения как единый поток данных. Однако использование пикселей непосредственно в качестве признаков изображений потребует чрезмерного количества памяти, особенно для изображений с высоким разрешением. Чтобы не учить только краткосрочные зависимости между пикселями и текстами, а делать это более высокоуровнево, обучение модели проходит в 2 этапа:
Предварительно сжатые изображения с разрешением 256х256 поступают на вход автоэнкодера (мы обучили свой SBER VQ-GAN, улучшив метрики для генерации по некоторым доменам, и об этом как раз рассказывали тут, причем также поделились кодом), который учится сжимать изображение в матрицу токенов 32х32. Фактор сжатия 8 позволяет восстанавливать изображение с небольшой потерей качества: см. котика ниже.
-
Трансформер учится сопоставлять токены текста (у ruDALL-E их 128) и 32×32=1024 токена изображения (токены конкатенируются построчно в последовательность). Для токенизации текстов использовался токенизатор YTTM.

Исходный и восстановленный котик
Важные аспекты обучения
На данный момент в открытом доступе нет кода модели DALL-E от OpenAI. Публикация описывает её общими словами, но обходит вниманием некоторые важные нюансы реализации. Мы взяли наш собственный код для обучения ruGPT-моделей и, опираясь на оригинальную статью, а также попытки воспроизведения кода DALL-E мировым ds-сообществом, написали свой код DALL-E-модели. Он включает такие детали, как позиционное кодирование блоков картинки, свёрточные и координатные маски Attention-слоёв, общее представление эмбеддингов текста и картинок, взвешенные лоссы для текстов и изображений, dropout-токенизатор.
-
Из-за огромных вычислительных требований эффективно обучать модель можно только в режиме точности fp16. Это в 5-7 раз быстрее, чем обучение в классическом fp32. Кроме того, модель с таким подходом занимает меньше места. Но ограничение точности представления чисел повлекло за собой множество сложностей для такой глубокой архитектуры:
a) иногда встречающиеся очень большие значения внутри сети приводят к вырождению лосса в Nan и прекращению обучения;
b) при малых значениях learning rate, помогающих избежать проблемы а), сеть перестает улучшаться и расходится из-за большого числа нулей в градиентах.
Для решения этих проблем мы имплементировали несколько идей из работы китайского университета Цинхуа CogView, а также провели свои исследования стабильности, с помощью которых нашли ещё несколько архитектурных идей, помогающих стабилизировать обучение. Так как делать это приходилось прямо в процессе обучения модели, путь тренировки вышел долгим и тернистым.
Для распределенного обучения на нескольких DGX мы используем DeepSpeed, как и в случае с ruGPT-3.
-
Сбор данных и их фильтрация: безусловно, когда мы говорим об архитектуре, нововведениях и других технических тонкостях, нельзя не упомянуть такой важный аспект как данные. Как известно, для обучения трансформеров их должно быть много, причем «чистых». Под «чистотой» мы понимали в первую очередь хорошие описания, которые потом нам придётся переводить на русский язык, и изображения с отношением сторон не хуже 1:2 или 2:1, чтобы при кропах не потерять содержательный контент изображений.
Первым делом мы взялись за те данные, которые использовали OpenAI (в статье указаны 250 млн. пар) и создатели CogView (30 млн пар): Conceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем мы добавили датасеты OpenImages, LAION-400m, WIT, Web2M и HowTo как источник данных о деятельности людей, и другие датасеты, которые покрывали бы интересующие нас домены. Ключевыми доменами стали люди, животные, знаменитости, интерьеры, достопримечательности и пейзажи, различные виды техники, деятельность людей, эмоции.
После сбора и фильтрации данных от слишком коротких описаний, маленьких изображений и изображений с непригодным отношением сторон, а также изображений, слабо соответствующих описаниям (мы использовали для этого англоязычную модель CLIP), перевода всех английских описаний на русский язык, был сформирован широкий спектр данных для обучения — около 120 млн. пар изображение-описание.
-
Кривая обучения ruDALL-E Kandinsky (XXL): как видно, обучение несколько раз приходилось возобновлять после ошибок и уходов в Nan.

Обучение модели ruDALL-E Kandinsky (XXL) происходило в 2 фазы: 37 дней на 512 GPU TESLA V100, а затем ещё 11 дней на 128 GPU TESLA V100.
-
Подробная информация об обучении ruDALL-E Malevich (XL):

Динамика loss на train-выборке 
Динамика loss на valid-выборке 
Динамика learning rate Обучение модели ruDALL-E Malevich (XL) происходило в 3 фазы: 8 дней на 128 GPU TESLA V100, а затем еще 6.5 и 8.5 дней на 192 GPU TESLA V100, но с немного отличающимися обучающими выборками.
Хочется отдельно упомянуть сложность выбора оптимальных режимов генерации для разных объектов и доменов. В ходе исследования генерации объектов мы начали с доказавших свою полезность в NLP-задачах подходов Nucleus Sampling и Top-K sampling, которые ограничивают пространство токенов, доступных для генерации. Эта тема хорошо исследована в применении к задачам создания текстов, но для изображений общепринятые настройки генерации оказались не самыми удачными. Серия экспериментов помогла нам определить приемлемые диапазоны параметров, но также указала на то, что для разных типов желаемых объектов эти диапазоны могут очень существенно отличаться. И неправильный их выбор может привести к существенной деградации качества получившегося изображения. Вопрос автоматического выбора диапазона параметров по теме генерации остаётся предметом будущих исследований.
Вот не совсем удачные генерации объектов на примере котиков, сгенерированные по запросу «Котик с красной лентой»:

А вот «Автомобиль на дороге среди красивых гор». Автомобиль слева въехал в какую-то трубу, а справа — странноватой формы.

Пайплайн генерации изображений
Сейчас генерация изображений представляет из себя пайплайн из 3 частей: генерация при помощи ruDALL-E — ранжирование результатов с помощью ruCLIP — и увеличение качества и разрешения картинок с помощью SuperResolution.
При этом на этапе генерации и ранжирования можно менять различные параметры, влияющие на количество генерируемых примеров, их отбор и абстрактность.

В Colab можно запускать инференс модели ruDALL-E Malevich (XL) с полным пайплайном: генерацией изображений, их автоматическим ранжированием и увеличением.
Рассмотрим его на примере с оленями выше.
Шаг 1. Сначала делаем импорт необходимых библиотек
git clone https://github.com/sberbank-ai/ru-dalle
pip install -r ru-dalle/requirements.txt > /dev/null
from rudalle import get_rudalle_model, get_tokenizer, get_vae, get_realesrgan, get_ruclip
from rudalle.pipelines import generate_images, show, super_resolution, cherry_pick_by_clip
from rudalle.utils import seed_everything
seed_everything(42)
device = 'cuda'
Шаг 2. Теперь генерируем необходимое количество изображений по тексту
text = 'озеро в горах, а рядом красивый олень пьет воду'
tokenizer = get_tokenizer()
dalle = get_rudalle_model('Malevich', pretrained=True, fp16=True, device=device)
vae = get_vae().to(device)
pil_images, _ = generate_images(text, tokenizer, dalle, vae, top_k=1024, top_p=0.99, images_num=24)
show(pil_images, 24)
Результат:

Шаг 3. Далее производим автоматическое ранжирование изображений и выбор лучших изображений
ruclip, ruclip_processor = get_ruclip('ruclip-vit-base-patch32-v5')
ruclip = ruclip.to(device)
top_images, _ = cherry_pick_by_clip(pil_images, text, ruclip, ruclip_processor, device=device, count=24)
show(top_images, 6)
")
Можно заметить, что один из оленей получился достаточно «улиточным». На этапе генерации можно делать перебор гиперпараметров для получения наиболее удачного результата именно под ваш домен. Опытным путем мы установили, что параметры top_p и top_k контролируют степень абстрактности изображения. Их общие рекомендуемые значения:
top_k=2048, top_p=0.995
top_k=1536, top_p=0.99
top_k=1024, top_p=0.99
Шаг 4. Делаем Super Resolution
realesrgan = get_realesrgan('x4', device=device)
sr_images = super_resolution(top_images, realesrgan)
show(sr_images, 6)

Для запуска пайплайна с моделью ruDALL-E Kandinsky (XXL) или Malevich (XL) можно также использовать каталог моделей DataHub (ML Space Christofari).
Будущее мультимодальных моделей
Мультимодальные исследования становятся всё более популярны для самых разных задач: прежде всего, это задачи на стыке CV и NLP (о первой такой модели для русского языка, ruCLIP, мы рассказали ранее), а также на стыке NLP и Code. Хотя последнее время становятся популярными архитектуры, которые умеют обрабатывать много модальностей одновременно, например, AudioCLIP. Представляет отдельный интерес Foundation Model, которая совсем недавно была анонсирована исследователями из Стэнфордского университета.
И Сбер не остается в стороне - так в соревновании Fusion Brain Challenge конференции AI Journey предлагается создать единую архитектуру, с помощью которой можно решить 4 задачи:
С2С — перевод с Java на Python;
HTR — распознавание рукописного текста на фотографиях;
Zero-shot Object Detection — детекция на изображениях объектов, заданных на естественном языке;
VQA — ответы на вопросы по картинкам.
По условиям соревнования (которое продлится до 5 ноября) на общие веса нейросети должно приходиться как минимум 25% параметров! Совместное использование весов для разных задач делает модели более экономичными в сравнении с их мономодальными аналогами. Организаторами также был предоставлен бейзлайн решения, который можно найти на официальном GitHub соревнования.
И пока команды соревнуются за первые места, а компании наращивают вычислительные мощности для обучения закрытых моделей, нашим интересом остается open source и расширение сообщества. Будем рады вашим прототипам, неожиданным находкам, тестам и предложениям по улучшению моделей!
Самые важные ссылки:
Коллектив авторов: @rybolos, @shonenkov, @ollmer, @kuznetsoff87, @alexander-shustanov, @oulenspeigel, @mboyarkin, @achertok, @da0c, @boomb0om
Комментарии (182)



oulenspiegel
02.11.2021 14:46+13
Немного ещё примеров генерации)

iShrimp
02.11.2021 18:45+27Картинки и тексты как будто взяты из сна. На первый взгляд выглядят реалистично, но если присмотреться к деталям - это жуткий майндфак. Сон на этом этапе обычно "ломается". А картинки - нет, их можно продолжать разглядывать. Любопытный феномен :)

VPryadchenko
02.11.2021 18:54+7Ага, причем, тексты во снах примерно так и выглядят.

Anhal
03.11.2021 14:27И у вас так? Во сне иногда издалека ты вроде читаешь текст и даже вроде как понимаешь его смысл, но не всё тебе понятно и ты хочешь посмотреть поближе. И вот, приближаясь к нему, видишь.. вот именно то самое, что нагенерила эта сеть.
Удивительно.
Да и про картинки как из снов тоже согласен.
Еще одно подтверждение, что наш мозг в принципе не уникален, и когда-нибудь ИИ его догонит и, увы, перегонит.

JediPhilosopher
03.11.2021 14:46+5У всех так. Так же фигня с музыкой, например. Когда слышишь типа во сне какую-то мелодию, помнишь что она была прекрасной, пытаешься ее вспомнить - и не можешь.
Потому что по факту там нет ни текста, ни мелодии, есть какие-то образы, которым мозг пытается подобрать чувственные ощущения. Ну действительно похоже на эти вот картинки, в сюжете сна сказано "ты слышишь музыку", и тебе кажется что ты что-то слышишь, хотя никакой музыки на самом деле нет, есть какие-то случайные обрывки и ощущение что ты ее слышишь, поэтому и вспомнить ее не можешь.
В принципе, тест на "дважды прочитать один и тот же текст и сравнить, вышло ли одно и то же" - хороший тест для проверки что ты во сне, для любителей практиковать осознанные сны.

dmbreaker
03.11.2021 23:35Но это только во сне все кажется прекрасным
Однажды во сне я сочинил короткий стих и он был такой классный, что я очень захотел его запомнить и от того проснулся...
А текст в голове остался... Короче я разочаровался на яву :)
nibb13
05.11.2021 08:29А мне, вот, наоборот приснилось как-то четверостишие, которое я тут же записал в лежащий рядом планшет "на автомате" и снова вырубился. Утром прочёл - весьма неплохо!

perfect_genius
04.11.2021 11:23У всех так.
Похоже, не у всех. Удивлён, что кто-то видел во сне текст и слышал музыку.

kr12
05.11.2021 17:31+2Нормально во сне музыка придумывается, если иметь навык её запоминания и записи. Не редко встаю посреди ночи, чтоб наиграть приснившееся. А если навыка не иметь - то думаю всё очень сильно упрощается в памяти, если вспоминать под утро.
perfect_genius
05.11.2021 18:56Занимаетесь музыкой что ли?
kr12
06.11.2021 04:27На любительском уровне, вроде сыграть опенинг к любимому мультфильму. И генераторы, вроде тех, что на shadertoy интересно пробовать делать. Я написал это к тому, что вникнув в некоторую область творчества, смотришь на вещи совсем другими глазами. Те же аудиофилы отлавливают характерные недостатки сжатия при mp3 192kbps, которые не тренированный человек не поймёт. Чуть научившись рисовать, смотришь, где и как свет идёт, как это изобразить удачнее. Ещё интересное наблюдение: если не учится писать рукой, то освоив основы языка после нескольких месяцев обучения и умея узнавать сотню иероглифов на вид, попытка нарисовать их по памяти полностью проваливается, выдавая результат как у сабжевых нейросетей.

Sonikelf
10.11.2021 15:52//offtop on
За книги, тексты и вывески - да, есть такое.
Тоже самое кстати касается попыток посмотреть на часы во сне. Формально время там увидеть можно, но в большинстве случаев это будет или абсурд, или повторный взгляд через условную секунду, привет к абсолютно новому значению.
Феномен описан в книге "Практики Осознанных Сновидений" Стивена Лаберж. Это устойчивое явление, в числе прочего, используется как маячок понимания того, что Вы находитесь во сне в целях достижения осознанности.
По поводу того, что не у всех так - я об этом слышал и читал, но не уверен, что это не кажется таковым. Т.е Вы условно видели вывеску и проснувшись она кажется нормальной - но была всё таки абсурдной или нечитабельной.
Одно точно знаю на личной практике, что со временем, если практиковать ОС-ы например, то мозг словно тренируется периодически строить иллюзию того, что Вы не спите - т.е например вместо абсурда на часах Вы начинаете видеть вполне нормальное время, тексты на вывесках вроде бы тоже приходят в условную норму или начинаешь их так воспринимать, т.е условно маячки, которые раньше успешно работали и тренировались в состоянии бодрствования в целях развития критического мышления и проверки значения "сон-явь " начинают сбоить словно это делается мозгом специально. Насколько это так - большой вопрос, но например я неоднократно сталкивался с эффектом столь красиво показанном в известном фильме "Начало", а именно сон-во-сне и играешь с мозгом в игру проснулся ты или нет.
Вообще это тема отдельной статьи и сны штука интересная, но написать я её как-то не решаюсь из-за того, что многими тема изучения снов построенная вокруг ОС-ов воспринимается бредом и мистификацией из-за книг некоторых известных деятелей на К и клуба.. ммм.. мягко говоря странных людей, что возвели это в культ и чуть ли не религию.
Так меня что-то понесло.
//offtop off
VPryadchenko
10.11.2021 16:22+1К слову сказать, я использую руку (кисть) в качестве маркера сна - во сне у меня не бывает константного количества пальцев, их, во-первых, почти никогда не пять, а во вторых их вообще не посчитать, потому что их число меняется все время. Может, у Вас тоже так?
Рука, в отличае от часов и вывесок, как правило, есть всегда, вне зависимости от конекста)
Sonikelf
10.11.2021 18:49С количеством пальцев не обращал внимания никогда специально - но вроде всегда было нормально, насколько я могу припомнить. Скорее всего такая техника ближе к индивидуальной и вопрос тренировки. Насколько я помню тот же мануал Лабержа - у каждого могут быть свои маркеры, общие приводятся как наиболее часто выделенное и совпадающее множество - те же часы или текст и тд и тп.
С другой стороны, во ОСе лично я постоянно специально смотрю на ладони, если требуется удержать осознанность и чувствую, что сейчас проснусь или теряю саму осознанность. Техника вроде оттуда же - работает прекрасно. По идее это же можно подвязать под маркер - посмотрел на ладони - потом на мир вокруг - если картинка изменилась или странная - сплю. С другой стороны специфично.
Вообще с пальцами надо попробовать - это мысль. Не то чтобы я их считал каждый раз, но вижу их так часто, что наверное мозг смоделирует довольно точно :)

copperfox777
12.11.2021 12:18+1Случайно прочитал ваш комментарий. Сегодня пытался прочитать надпись на упаковке с лекарством. Сначала оно показалось адекватным, но почему то я решил вчитаться и вдруг понял что только что надпись была другой, попытался вглядеться еще раз и опять что-то новое и тогда я точно понял, что во сне.
А тема с "сон во сне" раньше была вообще постоянно, когда сны были ярче. Думаешь что проснулся. Радуешься, ан нет - это опять сон.Sonikelf
14.11.2021 11:50Ну да, оно как-то так и работает. Нюанс в том, что по сути всё во сне кажется нормальным, хотя зачастую какие-то элементы переходят грань абсурдности (для меня это чаще всего люди, которых я не видел 100 лет и/или которые в принципе в моем кругу друг с другом никогда не пересекались, за умерших вообще молчу), а понимаешь это только, когда просыпаешься (если запомнилось).
Поэтому при практике ОСов как раз учишься всегда проводить критическую оценку реальности и искать условные странности или перепроверять. Без тренировки осознание, что спишь встречается настолько редко, что почти наверное никогда.
За сны во сне как у большинства сказать не могу - судя по Вашему комментарию бывают и может даже не редко. Но когда я практиковал ОСы попадал пару раз в цикл максимум в 6 (шесть) просыпаний внутри сна и каждый раз мне приходилось проверять сплю или нет и искать проснулся я или нет в собственной же комнате и каждый раз какой-то новый неочевидный момент не совпадал. Честно говоря, я не очень понимаю чем и зачем вызван такой феномен работы мозга, но игры в поиск реальности с одной стороны тогда вызывали интерес - с другой стороны несколько пугали.
iShrimp
02.11.2021 19:13+4А ведь некоторые из этих "мемов", если их удачно запостить, вполне могут составить конкуренцию реальным мемам! Это даже может стать темой для исследования - как нейросеть может хакнуть массовое сознание :)

Alex_ME
03.11.2021 12:26Все картинки несуществующие, но картинка с Дауни младшим (второй ряд, четвертая картинка) неотличима от оригинала.
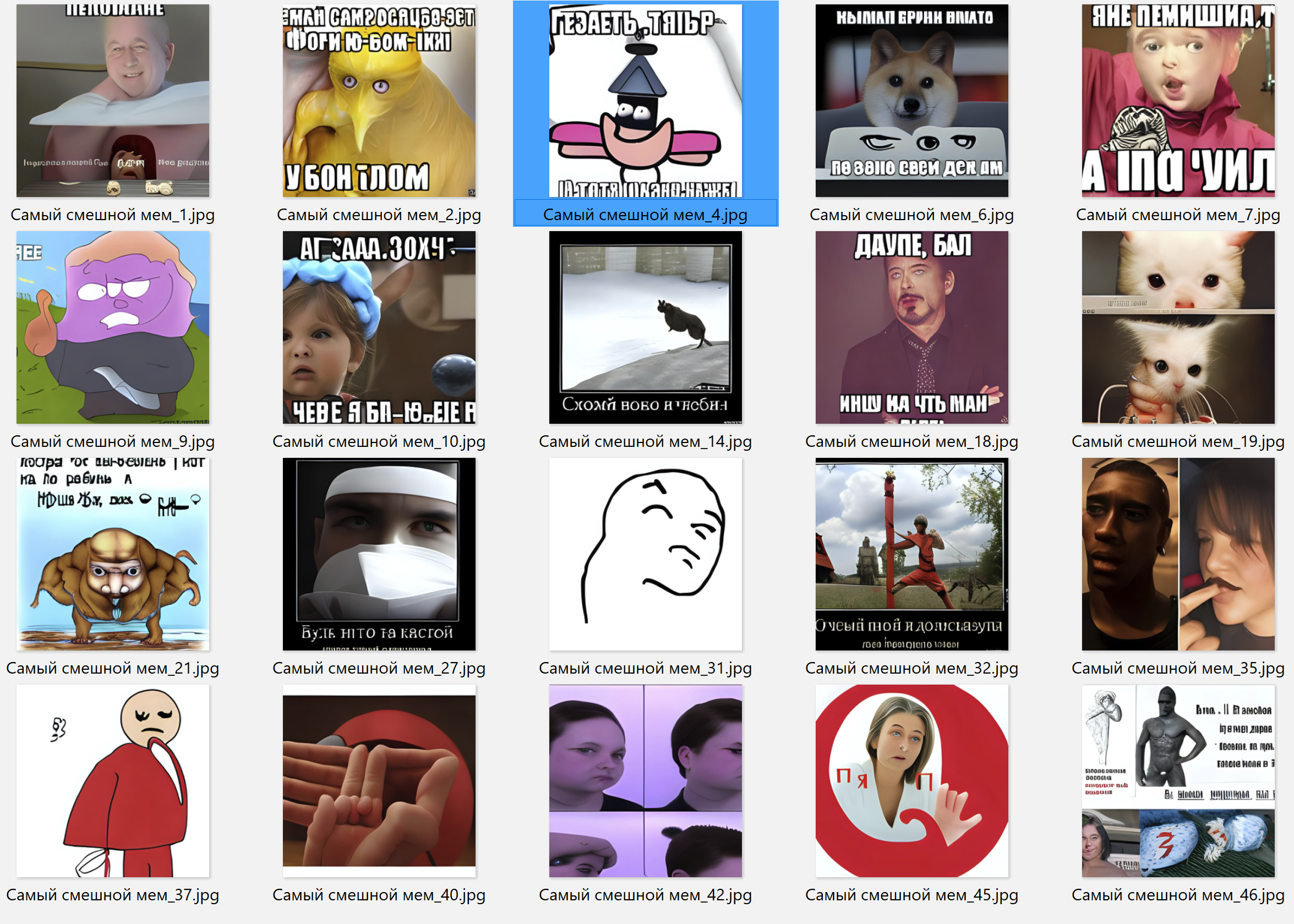






oulenspiegel
02.11.2021 14:49+5Немного ещё примеров генерации)

da0c
02.11.2021 15:43+2Ну все равно модель больше в стилистику Брейгеля и голландцев тянет, чем к Репину)))
oulenspiegel
02.11.2021 15:50Мне кажется, что это отчасти из-за особенностей сетки для SuperResolution.




oulenspiegel
02.11.2021 15:25+1Собаченьки




oulenspiegel
02.11.2021 15:40Пейзажи
VPryadchenko
02.11.2021 17:22+1А если запрашивать "некрасивое" всякое?)
oulenspiegel
02.11.2021 18:08+2Порно из датасетов постарались вычистить, но, конечно, совсем идеально это не получилось. Но вообще самый страшный крип это не порно, а то, что моделька генерирует на запросы типа «элитный педикюр». Потому что считать-то (что пальцы, что другие предметы) она особо не умеет, разве что до трёх...
VPryadchenko
02.11.2021 18:15Оу, я как-то и не подумал про порно - просто заметил, что во многих примерах есть эпитет "красивый/ое/ая"... Но я Вас понял :)

Alexey2005
03.11.2021 14:08Это похоже общее для всех нейронок. Когда экспериментировал со StyleGAN, то самым проблемным местом оказались руки. Персонажи вроде нормально генерируются, а вот с руками всё плохо. Потому что сетка первым делом выхватывает самые общие (повторяющиеся) черты, а руки обладают просто чудовищной вариативностью, при этом на рисунке занимая буквально считанные пиксели. Для нейронки эта информация — почти фоновый шум.
perfect_genius
04.11.2021 11:29Порно для вас ассоциируется с "некрасивым"?
Или нейросеть его выдавала, и вам пришлось вычищать?

Vilgelm
07.11.2021 00:15Я попробовал:
Красивая кошка
Некрасивая кошка
Мне лысые кошки конечно тоже не очень нравятся, но что на первой картинке вообще? Наверное не стоило включать в датасет фото с ватермарками.
PereslavlFoto
07.11.2021 00:43+1На первой картинке можно разобрать слова koska и hvost. Словно бы намекают, что при изготовлении фотоснимка использованы части кошек.






BelBES
02.11.2021 15:52+4Судя по семплам из комментариев и моих экспериментов с этой сеткой, складывается ощущение, что сеть серьезно страдает проблемой меморизации...Есть ли какой-то анализ полученной модели? Какие значения FID оно показывает на валидационной выборке, как соотносится с DALL-E, CogView на COCO etc.?

northzen
03.11.2021 02:26+4Аналогичное ощущение. Словно сеть просто нашла способ упаковать все разнообразие данных, на которых обучалась и выплевывает с дорисовкой то, что сохранено под определленными словами или ембеддингами этих слов.
Выглядит как скорее неудача, чем успех. Сеть достаточно откровенно выдает картинки, на которых она обучалась. Это видно невооруженным глазом. И это плохо, ИМХО.etoropov
03.11.2021 04:48Я так понимаю, это общая проблема автоэнкодеров. Интересно, как с этим можно бороться, если можно вообще.
northzen
03.11.2021 05:02+5Проблема в том, что эту разработку подают как сеть, понимающей смыслы, а по смыслам понимающую изображения. По факту же, сеть просто занимается сжатием картинок, которые индексирует по словам. Выход этой сети -- просто распаковка значений, лежащих близко к примитивной упаковке предложения в вектор.
Грубо говоря, ее работа на данный момент хуже простого поиска в гугле, ибо выдает она тоже самое, что поиск, только отягощенное сжатием-расжатием.
BelBES
03.11.2021 12:38+1В целом это проблема не только автоэнкодеров, а вообще всех нейронных сетей (да и других тренируемых моделей тоже). В первую очередь модель же пытается заучить все, что ей показывают (т.к. методы обучения от нее именно этого и хотят обычно в явном или не очень виде), а обобщать начинает уже от безысходности, когда емкости не хватает для заучивания.
Тут скорей вопрос в том, насколько конкретная модель заучила трейн и является ли это проблемой конкретного пайплайна, или другие large scale сети для text-to-image (в частности CogView, который публично доступен и с которым можно как-то сравниваться) тоже склонны к меморизаци в +/- той-же степени. Ну т.е. очень круто, что Сбер тратит ресурсы на тренировку гигантских сетей и выкладывает это в паблик под свободной лицензией, но хотелось бы, чтобы модели были действительно полезными, а не только "самыми большими") А без хоть каких-то метрик и анализа не понятно, насколько оно полезно.
Alexey2005
03.11.2021 14:52обобщать начинает уже от безысходности, когда емкости не хватает для заучивания.
Не совсем такТо есть, как видим, если ёмкости сети не хватает для заучивания, то вполне очевидно происходит обобщение. Но вопреки тому, что подсказывает нам интуиция, когда ёмкость сети в несколько раз (в 4 и выше) больше «интерполяционного порога», то сеть тоже склонна к обобщению, а не запоминанию. Хотя памяти вроде бы многократный избыток.

Nehc
03.11.2021 15:28>>> Но вопреки тому, что подсказывает нам интуиция, когда ёмкость сети в несколько раз (в 4 и выше) больше «интерполяционного порога», то сеть тоже склонна к обобщению, а не запоминанию
А есть какое-то внятное объяснение, как это может работать? Чет ничего в голову не приходит… Разве что за счет именно глубоких архитектур, когда сеть все-таки не может выделить внутри себя отдельные «подсети», и в любом случае что-то как-то обобщает на входных слоях, что бы уже дальше разобраться в нюансах…Alexey2005
03.11.2021 18:01+3Существует несколько гипотез, но общепринятой среди них нет. Наиболее часто упоминается гипотеза лотерейного билета (Lottery Ticket Hypothesis). Суть которой в том, что когда сетка обладает многократным избытком ёмкости, то во время обучения там образуется несколько конкурирующих участков небольшого размера. Те из них, которые выдают лучшие результаты, побеждают в конкурентной борьбе, подавляя неудачные варианты, которые в итоге разваливаются, а их веса либо поглощаются удачными, либо переходят в «мёртвый» субстрат, сигнал от которого просто не доходит до верха.
Гипотеза подтверждается экспериментами по прореживанию таких избыточных сеток. Если ранжировать все их веса по вкладу в выходной сигнал и начать обнулять наименее значимые, то оказывается возможным занулить до 90% всех весов тренированной сетки, прежде чем начнётся заметное просаживание качества. Т.е. всю реальную работу выполняет «выигрышный лотерейный билет» — небольшой участок (или пара-тройка таких), победивший в жёсткой конкурентной борьбе на этапе тренировки.
BelBES
03.11.2021 15:29Согласен, я умышленно загрубил свое высказывание, чтобы не вдаваться в подробности ;) На графике, на самом деле, можно предположить и корреляцию между трейн/тест как один из факторов, благодаря которому точность в ноль не падает на тесте и другие причины такого поведения.


logran
02.11.2021 16:18+2Апскейл, как мне кажется, только портит и мылит изображения. И на примерах из статьи видно (растительность, текстуры земли и гор — в кашу), и на собственном примере с пушистыми объектами проверил.
Пример
P.S. На Tesla P100 в колабе оно конечно жесть как долго генерирует в сравнении с Clip+VQGAN.BelBES
02.11.2021 16:54Там время линейно скейлится относительно числа параллельно генерируемых картинок, если использовать images_num=1, то на 1x1080Ti выходит вполне терпимые ~4 минуты на запрос

Nehc
02.11.2021 17:03+10>>> Векторные иллюстрации, свободные от лицензии фотостоков, тоже можно генерировать бесконечно
Только они будут растровые по определению. ;)
А еще встречаются очень интересные экземпляры генерации, содержащие надписи, природу которых я не понимал, пока не прочитал вашу реплику про «свободные от лицензии фотостоков»:
Видимо в обучающих выборках были и не совсем свободные? ;)oulenspiegel
02.11.2021 17:57+1Ну растровые ещё прогоним через трассировщик — и вот у нас уже куча всратых векторных иллюстраций :) В выборку картинки тянули краулеры, понятно, что попало в датасеты всё, что было не закрыто — из двух сотен миллионов картинок отсеять те, что без ватермарков, не совсем просто, но это постепенно поправим.
Alexey2005
04.11.2021 01:51+1Обычно нейронки сами успешно отсеивают «редкую» информацию. Если на 200 миллионов картинок данный копирайт встретился только однажды, нейронка его никак не запомнит. Если у каждой картинки свой уникальный копирайт, запоминания тоже не будет. Поэтому когда к примеру StyleGAN обучается на картинках с имиджбордов и deviantart'а, копирайты в результаты генерации не «протекают» — они слишком разнообразны, чтоб запомниться. Слишком мало повторов.
А вот когда в выборке картинки с одинаковым копирайтом составляют заметный процент, вот тогда нейронка этот копирайт успешно ухватит.


ginbor
02.11.2021 17:21Почему так важно создавать изображения на основе именно русского языка? Сегодня уже довольно хорошо работают переводчики. Ведь можно перевести фразу на английский и пользоваться обычной DALL-E. Согласен, наверно будут проблемы с генерацией типа "лучшая картина Васи Ложкина", но тем не менее, зачем бороться за язык исходной фразы?
oulenspiegel
02.11.2021 17:58+4Любая дополнительная модель in the middle снижает качество всего пайплайна. Ну и, конечно, нам важно иметь модель, которая учитывает отечественные реалии — она всё-таки для русскоязычных сервисов, в первую очередь.

peterpro
05.11.2021 11:47+1
А вот зачем. Понятно, почему это "большие сиськи"? :) Если нет - переведите "tit" на английский.


Sincous
02.11.2021 18:17+1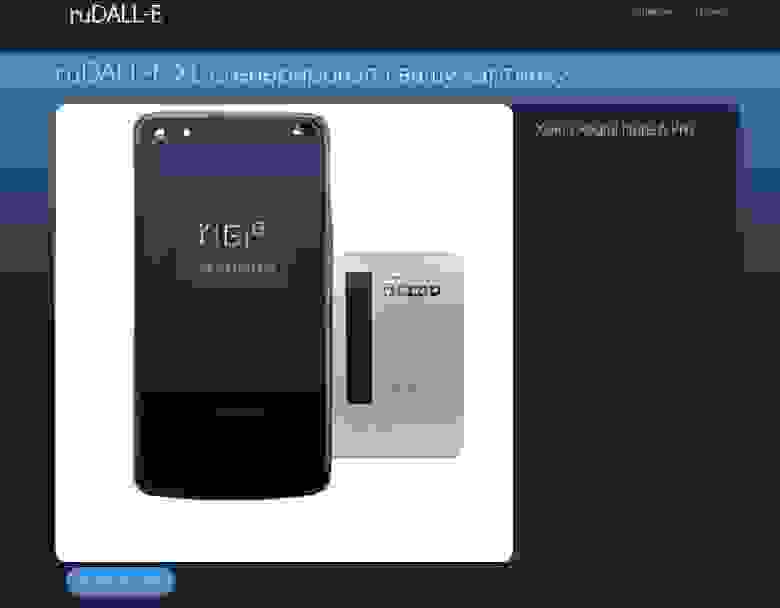
Просто похлопаю. Я ещё не отошёл от вашего прошлого мегауспешного проекта https://habr.com/ru/company/sberbank/blog/584068/
Я так и не понял, зачем мне генератор воображаемых характеристик (указываю название реальных товаров и мне в тексте вписывают несуществующие характеристики).


Alexey_mosc
02.11.2021 20:05+3Ждал этого 30 минут.

oulenspiegel
02.11.2021 20:29+1:( Не всегда получается хорошо, увы. А сейчас 5000 запросов в очереди на генерацию, и даже 150 карт Nvidia V100 не вывозят быстрее...

victoriously
02.11.2021 20:57+1Хотел уже попробовать запустить локально, но увы — на windows у меня(и судя по issue на гитхабе — не только у меня) падает компиляция youtokentome :(

DistortNeo
02.11.2021 21:00+1У меня под Linux успешно запустилось, но в самом конце упало по причине нехватки видеопамяти (GTX 1080 8 GB).

KiddingBanana
03.11.2021 03:09+1А подтюнить там ничего нельзя? У самого 8ГБ видеопамяти, дико хотелось бы поиграться
DistortNeo
03.11.2021 12:48Можно. Например, выгрузить KDE и браузер. Тогда влезает и ждёт чуть больше 7 гигов. Но считает охренительно долго: порядка 10-15 минут на 1 картинку. Отсутствие tensor cores даёт о себе знать.
Nehc
03.11.2021 11:42Это лечится. Там часть пакетов надо проставить отдельно…
youtokentome, кажется, падает из-за cython.
В общем, я на винде запустил.victoriously
03.11.2021 11:50Да, Cython я поставил отдельно, после этого пропала ошибка невозможности разрешения зависимостей, но теперь оно падает из-за visual c++ 14, который у меня стоит. Здесь и здесь описано подробнее.
victoriously
03.11.2021 12:23fix: первый issue не совсем то, имел ввиду этот
Nehc
03.11.2021 15:15Ну я «сварщик не настоящий»(с), поэтому дальше уже не подскажу… ) У меня после фикса с cython — завелось…

Aniro
03.11.2021 20:15У меня нормально запустилось на win10, просто часть зависимостей, включая cython для youtokentome пришлось ставить вручную. Но проблем в этот раз значительно меньше чем обычно.
По недостатку видеопамяти вылетает апскейл, рекомендую для домашних эксперементов его убрать, также как и черипикинг, который можно и самостоятельно провести. Кроме того, если поэксперементировать с параметрами, качество генерации можно и подтянуть.

Earthsea
03.11.2021 10:32:( Не всегда получается хорошо, увы. А сейчас 5000 запросов в очереди на генерацию, и даже 150 карт Nvidia V100 не вывозят быстрее...
Хабраэффект в 2021 году




VPryadchenko
02.11.2021 20:35+2
olsowolso
03.11.2021 16:06А вот это интересный запрос.
Возникают фантазии на тему самоосознания алгоритмов :)




zamboga
02.11.2021 21:29+14oulenspiegel
02.11.2021 23:18+1Мы бы рады, если бы модель была выложена в открытый доступ))) Просто какое-то подмножество кэпшнов в обучающем датасете генерировалось при помощи машинного перевода. Этим грешат русскоязычные стоки, например.




speshuric
03.11.2021 01:05+4




makondo
03.11.2021 01:38
"Пурпурная пульсирующая сущность в пространстве". Что-то я не вкурил, что он хотел сказать этим..

id_potassium_chloride
03.11.2021 03:16Кстати, текстоквадраты она часто выдаёт на просьбу нарисовать "нечто" и "пространство"




romancelover
03.11.2021 03:01Пробую разные запросы, чаще всего вылезает что-то абстрактное, похожее на текст со сильно смазанными буквами.
Хотя иногда что-то похожее вылезает, но не совсем точно.Певица с очень большой грудью

На певицу она похожа, вот только грудь у неё не очень-то и большая.

etoropov
03.11.2021 04:57Я так понял, что на графике training loss. Видно, что loss меняется с 5.25 до 5.0 ооооочень долго. Интересно, как различаются качество картинок при loss=5.25 и при loss=5. Вообще, насколько в принципе (не)возможно, чтобы loss упал до нуля в этой модели?

Kaputmaher
03.11.2021 05:29+2Как когда-то заметил Денис Ширяев, добавление к тексту запроса слов
unreal engineи/илиrtx mode onделает результат немного качественнее

maxlilt
03.11.2021 09:24Простейший вопрос для ИИ "зеленый цилиндр стоит на двух серых кубиках" выдал 2 зеленых квадрата. Печаль...



RiseOfDeath
03.11.2021 09:42+4Мне кажется или вчера под этой статьей была куча комментариев с «неудачными» картинками (зачастую с совершенно негодными), от которых даже следа не осталось?

Sber
10.11.2021 13:56Здравствуйте! Удалить опубликованный комментарий могут только модераторы и только в случае выявления факта нарушения правил сайта.




plm
03.11.2021 11:47-1...переводчик поверх модели OpenAI...
Если я использую прилагательное "кошачий", тупо получаю кошку во всю картинку. Несолидно.
Опытным путем мы установили, что параметры top_p и top_k контролируют степень абстрактности изображения
А вот это вообще меня убило. "...большая машина "воин-купол" пришла в движение от пальца в отверстии пятом и от пальца в отверстии сорок седьмом, и движение было неодолимое, быстрое и прямое."
Короче, общее впечатление - дети дорвались до мощной техники.



HellWalk
03.11.2021 12:16+4Как пет-проект сделанный по фану, чисто по приколу - было бы вполне неплохо.
Но когда проект с таким количеством треша в результатах так помпезно презентуется... мне не понять.
P.S. Сама идея интересная, и думаю лет через 10-20 появятся вполне хорошие генераторы изображений. Но пока - это больше похоже на генератор треша.
Nehc
03.11.2021 16:03+5А мне кажется наоборот — это очень правильно!
Т.е. вот у сбера есть команда, которая проводит некие изыскания в области основных проектов машинного обучения. Получается по-разному. Иногда прям вот круто. Иногда — не очень. Но они выкатывают результаты как есть — со всеми недостатками и что важно — исходниками!
Было бы гораздо хуже, если бы выкатывались только однозначно выверенные готовые пойти в прод модели. Да и где помпа-то? Ну да — по телеграм-каналам и разным лентам новостным разошлось, но так… Стиль подачи скорее именно как у пэт-проекта (правда с нефиговым техническим ресурсом!).
Я двумя руками за то, что в сбере есть такая команда, что они это делают, что выкладывают — пусть и дальше продолжают в том же духе! Я использую их GPT2/3 модель и скрипты для фантюнинга для своих изысканий — до них это было бы сильно сложнее.





dlinyj
03.11.2021 14:02+6Это невероятно круто! Просто фантастика, я бы сидел и сидел, экспериментировал. Есть прям суровая наркомания, но есть и крутые картинки.

«Зелёные бутылки на красном фоне»Остальная наркомания
«Мультфильм Крокодил гена и Черномырдин»
«Бог»
«Бутылка вина, бокал с вином, на зелёном фоне картина маслом»
«Айвазовский, мазки квадрата Малевича»

Wesha
10.11.2021 18:13У меня скорее впечатление, что у Вас синдром посетителя музея абстракционизма: нейросеть сгенерила нечто, а уже Вы рационализируете, как это нечто в принципе может ну хоть как-то соотноситься с тем, что Вы вообще-то заказывали.
dlinyj
12.11.2021 16:38Мне кажется, что вы вы нашли подтекст в моих словах, сами же на него ответили.
Я сказал, что меня позабавило то что выдала нейронка. И вот изображения, которые я привёл, они мне понравились и позабавили меня.





Anhal
03.11.2021 14:10+6Очень круто.
В комментах пишут типа "проект с таким количеством треша в результатах".
Но в этом же и крутость! Конкретную картинку по тексту легко найти в любом поисковике. А тут такой полет фантазии! Столько материала для вдохновения собственных нейронных сетей (которые, как его там, мозг)!
Работало бы только побыстрее, но это, очевидно, дело наживное.
Ребята, понятно, что со временем вы научитесь генерить картинки без такого количества нелепицы и абсурда, но, пожалуйста, оставьте возможность синтеза таких вот странных изображений. Или сделайте "регулятор абсурдности", от 0 до 100%.
Sber
10.11.2021 13:55Спасибо! Над скоростью генерации уже работаем. Про "регулятор абсурдности" интересная идея, подумаем ????
Anhal
03.11.2021 14:18А Николай Иронов - родственник Далли? По такому же принципу работает?
Просто не понятно, как удалось Артемию Лебедеву, при всем уважении, создать собственного (?) ИИ-дизайнера, очевидно не обладая такими колоссальными технологическими и финансовыми ресурсами, как у Сбера.
Nehc
03.11.2021 15:32У Николая Иронова довольно простенькая, насколько я понимаю, архитектура, но при этом довольно неплохой нишевый датасет. ;) Он не умеет визуализировать слова по семантическому признаку — только создавать графические паттерны. Это тоже хорошо и правильно в прикладном смысле, но вот прям совсем другое.
Это как говорить, если цепи Маркова тоже синтезируют текст, то зачем нужны GPT2/3?

wadeg
22.11.2021 02:41Кандидаты и джуны на испытательном сроке
за едувообще нахаляву — чудовищно эффективное и при этом масштабируемое решение.












sswwssww
03.11.2021 14:55У кого-нибудь получилось запустить на 6gb vram карточке?
Nehc
03.11.2021 15:33Запускайте тогда уж в Collab… Там хоть 12. Только ОООчень долго.
sswwssww
03.11.2021 16:08В этом и суть, что в Collab ОООчень долго. Хотел узнать смог ли кто-то оптимизировать потребление памяти в угоду скорости. У меня GTX 1660 SUPER, а тут вижу что ребята запускают на более слабых картах, но с большими VRAM.
victoriously
03.11.2021 16:37Сами авторы на гитхабе обещают выпустить уменьшенную модель к новому году
sswwssww
03.11.2021 17:09Ага, видел. Но там кто-то уже пулл реквест создал на оптимизацию, пойду пробовать.
p.s.: Действительно, с этим форком стало генерировать в РАЗЫ(10x) быстрее, но проблема с памятью у меня все еще актуальна.
Alexey2005
03.11.2021 17:48Похоже, спецам из Сбера проще подключить к расчётам дополнительную тысячу GPU, чем потратить пару дней на оптимизацию кода.

order227
07.11.2021 01:11+1Зачем? В опен сорс выкладывают как раз для того, чтобы комьюнити допилило все за тебя. Взаимовыгода такая)



aokoroko
03.11.2021 17:10Сплошное разочарование. Это вот разве "Много разных маленьких финтифлюшек, плавающих в тазике с синими чернилами"?


arthin
03.11.2021 20:10+1Ривенделл
А вот "Имладрис" уже явно не понимает. Корпус богатый, но не на столько.
На каггле ругается на зависимости: "allennlp 2.7.0 requires transformers<4.10,>=4.1, but you have transformers 4.10.3 which is incompatible". Но работает.





Panzerschrek
04.11.2021 10:06
"Мем про парня и двух девушек"
Я имел в виду этот:
и композиционно оно даже как-то похоже.



un7ikc
04.11.2021 10:57+2Осталось сделать нейросеть переводчик:
Alexey2005
04.11.2021 12:30+1А что, если манускрипт Войнича на самом деле был сгенерирован с помощью нейронки? Потому до сих пор и расшифровать не могут, при том что все частотные характеристики как у естественных языков.



PereslavlFoto
04.11.2021 18:45+1ddimitrov Вы писали, что «векторные иллюстрации, свободные от лицензии фотостоков, тоже можно генерировать бесконечно».
Ваша программа выдаёт мне файл. Эта программа работает без моей власти, по вашей воле. Следовательно, результат её работы является вашим произведением. Эти иллюстрации закрыты вашим авторским правом. И отсюда вопрос.
Скажите пожалуйста, по какой лицензии вы разрешаете использовать произведения, созданные этим сайтом, этой нейросетью?
Спасибо.oulenspiegel
05.11.2021 04:03Если следовать этой логике, то молоток работает по воле создавшего его мастера, MS Word по воле Microsoft. Нейронка это просто инструмент — сложный, но и только. Все лицензии указаны и в github'е и на сайте rudalle.ru

rPman
05.11.2021 07:25я думаю что лицензия на результат как минимум должна зависеть от лицензии на исходные данные (обучающую выборку)
а то так можно брать чужие меди файлы, к примеру из компьютерных игр, делать программу, которая эти файлы будет слегка модифицировать (уменьшать размер на 1 пиксел например) с помощью опенсорс приложения и на их основе делать новую игру, и говорить результат лицензионно чист, вон открытая лицензия используется.Alexey2005
05.11.2021 10:21+2В таком случае и любой результат работы художника принадлежит тому, на чьих картинах этот художник учился.
А то понаберут рефов, прокрутят в своей межушной нейросети и на их основе делают новый рисунок.
Ну, а если серьёзно, то нейронки — это потенциально огромный вызов всей системе авторских прав. Даже больший, чем распространение Интернета. Потому что при простом копировании контента хотя бы можно понять, что перед вами копия, а когда контент пропущен через нейронки, то в большинстве случаев совершенно невозможно доказать, что использовались закопирайченные данные, причём принадлежащие именно данному правообладателю.


rrust
05.11.2021 22:38страшная грета тунберг
Заголовок спойлераа идея была примерно такая
Заголовок спойлера





kr12
06.11.2021 03:25наиболее удачные из около 20 попыток

Столкновение повозки о пяти колёсах с поездом 2ТЭ10 
Открылась бездна звезд полна; Звездам числа нет, бездне дна. 
Бездны черные, бездны чужие, Звезды – капли сверкающих слез... Где просторы пустынь ледяные... – Там теперь задымил паровоз Сперва попытки получить что-то релевантное провалились. "Мику играет на пианино", "Рин и Лен седлают коня", "девочка на коте в осенних джунглях" - выдают мусор, грубую мазню. Очень не хватает ускоренного промежуточного результата, чтоб оценить примерно, что там оно наколдовало и продолжить или отвергнуть/переделать, ведь каждый раз оно генерирует по-разному. Ночью считает быстро 2-3 мин.





isNikita
07.11.2021 14:50Мне напомнило Гугл начало 00х. Когда нужно было правильный запрос писать, что бы найти нужный ответ. Так и тут, при правильном тексте может выдать просто жемчужину. Но все же это криповые, психоделические, фантазийные картинки. Неплохо кстати эмитирует работы Пикассо, Мунка, Малевича и др. Достаточно написать "картина пикассо" например.




GypsyBluesMan
08.11.2021 10:11Хочу спросить, а кто-нибудь пробовал подкрутить параметры в коде?
Например, в ячейке Generation, seed_everything(42) - на что-нибудь влияет это число?


vivatrici
08.11.2021 10:14За безусловный технологический прорыв - РЕСПЕКТ! Одна из единиц интегрального парсинга стала вполне годной иллюстрацией к околотехническому контенту. Кстати, лицензия на использование уже определена?
За ответственность исследователя мысли обратные. Кто-то думал на ответом на вопрос: готово ли не самое передовое в плане психологической устойчивости общество к потоку образов, смелости которых позавидовал бы сам Генрих Роршар?
Будущее покажет.
kr12
08.11.2021 19:35Запретные и неполиткорректные картинки и описания в базу же не попадают, так что напротив это будет рафинированное искусство, не знающее альтернативных точек зрения

chatter
09.11.2021 10:06+2Очень неплохо работает с запросом "шарж".
Например по запросу "Весёлый "Иосиф Виссарионович Сталин шарж карандашный рисунок" - получился весьма обаятельный Виссарионыч.

chatter
09.11.2021 10:23+1Так-же сеть умеет работать с логотипами (разумеется при правильном запросе). Это уже прямая конкуренция Лебедевскому Н.Иронову за сто тысяч рублей. Причём нужно конечно посидеть, погенерить. Но результаты не хуже Лебедевских. А порой и интересней.






{kind=link}
{kind=link}
ddsl
13.11.2021 18:04Я видимо где-то туплю но при попытке установить себе на винду (pip install -r ru-dalle/requirements.txt) выдает конфликт версий в исходниках:
ERROR: Cannot install -r ru-dalle/requirements.txt (line 1), -r ru-dalle/require ments.txt (line 3) and -r ru-dalle/requirements.txt (line 9) because these packa ge versions have conflicting dependencies.
The conflict is caused by:
taming-transformers 0.0.1 depends on tqdm
transformers 4.10.2 depends on tqdm>=4.27
torchvision 0.2.2 depends on tqdm==4.19.9
To fix this you could try to:
loosen the range of package versions you've specified
remove package versions to allow pip attempt to solve the dependency conflict
ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/user_g uide/#fixing-conflicting-dependencies
Подскажите как поправить.
Kovot
15.11.2021 07:49+1Сделайте систему оценок изображения, мы бы могли помочь нейросети генерировать изображения более адекватные некоторым запросам.
oulenspiegel
Немного ещё примеров генерации)