

Модели распознавания печатного текста (например, с фотографий документов) дают довольно высокие результаты. Это происходит за счёт ограниченного набора шрифтов, цель которых – быть максимально понятными человеку, а также благодаря генерации простой синтетики в виде печати разнообразными шрифтами текста на каком-нибудь фоне.
С распознаванием рукописных материалов дело немного сложнее. У каждого человека свой почерк, который ещё и может меняться с течением времени. Причём вариативность почерков довольно существенная, и часто мы с трудом читаем то, что написал, скажем, врач или ребёнок. Человек с течением жизни может сформировать свои привычки писать ту или иную букву определённым образом (конкретной высоты, наклона, формы и др.), причем эта буква будет такой только у одного человека. Подобную синтетику уже нельзя сымитировать, накладывая печатные шрифты на фон.
Тут же возникает трудность и с разметкой (которой особенно мало на русском языке). Например, при работе с рукописями Петра I пришлось задействовать историков. Конечно, это особый случай документов начала XVIII века, но даже в простых датасетах важно иметь дублирующую разметку нескольких человек для исправления ошибок, которые нередко совершают разметчики при чтении рукописного текста.
Мы в Sber AI заинтересовались идеей генерации синтетических рукописных изображений с помощью GAN, и в этой статье предлагаю рассмотреть несколько таких моделей. А также попробуем сгенерировать синтетику, используя одну из архитектур, и посмотрим, как сильно дополнительные данные улучшают качество OCR-модели (Optical Character Recognition).
Обзор нескольких GAN для генерации рукописных текстов
TextStyleBrush
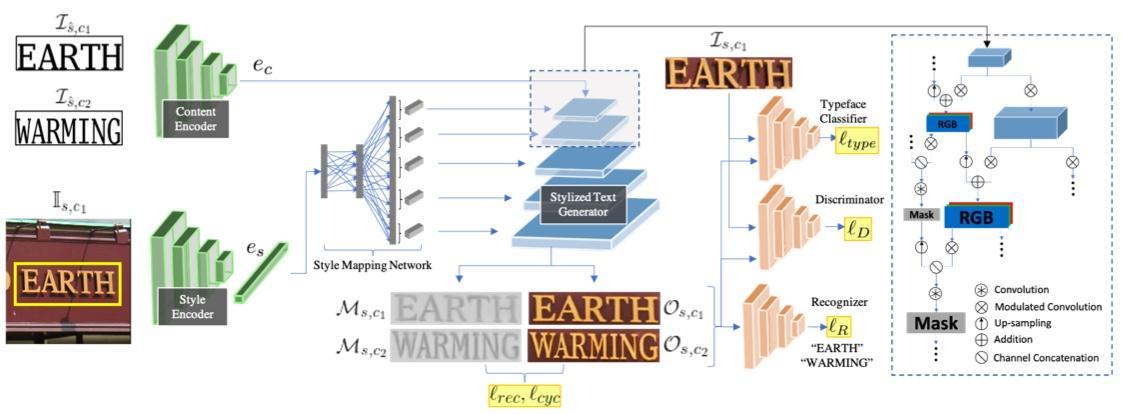
И начнём со свежей статьи от Facebook. TextStyleBrush – модель для замены текста на картинке (или переноса таргет-стиля на новый текст). На вход принимает картинку со стилем и новый текст для печати. Стиль – это цветовая гамма, текстура, шрифт или почерк и т. д. При этом для обучения не нужна разметка самих стилей, и это, несомненно, плюс: некоторые другие архитектуры требуют разметку почерков авторов (какому человеку принадлежит каждый рукописный текст).
Самое интересное то, что архитектура позволяет применять стили на новый текст в one-shot манере: можно взять на инференсе любую картинку и сразу же нанести на неё новый текст без необходимости дообучать модель. Из этого следует и другая особенность: мы можем контролировать стиль выходных картинок (он просто принимает стиль входной). Другие архитектуры GAN’ов принимают на вход только случайный шум, а с TextStyleBrush легко можно сгенерировать примеры одного заданного стиля.
Для обучения TextStyleBrush нужны:
Предобученная модель OCR.
Предобученный классификатор шрифтов (авторы обучали его заранее на синтетических картинках).
Разметка bounding box. Входная картинка-стиль вырезается с добавлением контекстного пространства вокруг обрамляющего прямоугольника (что, как утверждают авторы, улучшает качество).
И, конечно, разметка самого текста для картинок (то есть текст, который написан на картинках).
Далее чуть подробнее пройдёмся по архитектуре. TextStyleBrush состоит из 7 сеток, в том числе из 5 loss’ов.
Content encoder и style encoder – обе сетки ResNet34. Причём текст подаётся не в виде закодированных букв, а просто как отдельная картинка: он печатается на белом фоне с использованием стандартного шрифта.
Style mapping network – сетка преобразует выходной вектор style encoder’а во множество отдельных векторов. Затем они подаются на разных слоях на вход генератору как параметры в AdaIN-слои. Это позволяет генератору лучше схватить стиль картинки на разных её уровнях.
Генератор – это StyleGAN, который авторы статьи доработали таким образом, чтобы он принимал на вход результаты работы двух энкодеров: текста и стиля. Генератор на выходе, помимо картинки, предсказывает текстовую маску, которая затем используется в лоссах (для масок нет разметки, сетка сама учится их предсказывать). Такие маски помогают архитектуре лучше отделять текст от фона/стиля.
Далее вкратце про 5 лоссов в TextStyleBrush.
Typeface classifier loss – это классификатор шрифтов, заранее предобученный на синтетических картинках и замороженный во время обучения всей архитектуры. Классификатор даёт генератору градиенты во время обучения для лучшего понимания сущности шрифтов. Этот лосс стремится снизить разницу между шрифтом сгенерированной картинки и таргет-картинкой.
Дискриминатор GAN’а (предсказывает real/fake).
Recognizer loss – предобученная OCR-модель читает текст с масок и сгенерированных картинок. Она способствует тому, чтобы маски отражали текст на самих картинках, и генератор не сливал текст с фоном. А также отвечает за то, чтобы буквы, которые GAN пытается написать, были похожи на настоящие. Текст с сгенерированных картинок сравнивается с таргет-текстом через Cross Entropy loss. При этом OCR заморожена во время обучения всей архитектуры.
Reconstruction loss (l rec) – отражает разницу между сгенерированной картинкой Os,c1 и таргет-картинкой Is,c1 (которую мы вырезали по bbox’у из входной картинки-стиля) с помощью L1-расстояния.
Cycle consistency loss (l cyc) – по аналогии с CycleGAN, помогает сетке научиться восстанавливать из сгенерированной Os,c2 картинки обратно исходную.
Не могу не упомянуть отличное видео с разбором статьи TextStyleBrush.
В итоге TextStyleBrush генерирует отличные картинки! И хорошо справляется с заменой текста in the wild на каких-нибудь билбордах, чайниках, дорожных знаках и прочем. Также она умеет работать и с рукописным текстом.

Итак, обсудим и некоторые проблемы TextStyleBrush:
Можно заметить, что архитектура сети кажется переусложнённой, и если понадобится что-то поправить, то придётся тюнить сетку с поправкой на большое количество компонентов внутри.
Вследствие своей архитектуры TextStyleBrush может сгенерировать только стили/почерки, примеры которых уже есть, и не сможет создать совершенно новые примеры или же некое «усреднение» из имеющегося. Только одна картинка в качестве входного стиля, и одна картинка на выходе с таким же стилем и новым текстом.
Генератор на вход принимает текст как картинку, напечатанную простым шрифтом на белом фоне, и далее апскейлит её. Также в качестве одного из лоссов выступает классификатор стандартных печатных шрифтов. Такая архитектура более приспособлена к генерации картинок с печатным текстом, чем с рукописным. Впрочем, картинки из статьи демонстрируют хороший результат и с рукописью.
Для тестирования TextStyleBrush ждём, когда авторы выложат код к статье.
GANwriting

Следующая статья 2020-го года – GANwriting. Это также GAN по генерации рукописных картинок. Как и в TextStyleBrush, на вход модели мы подаём текст, который хотим напечатать, но вместо одной картинки со стилем в GANwriting необходимо предоставить сразу несколько (авторы использовали 15). И это существенное отличие: это уже не замена текста на картинке, а создание нового шрифта в усреднённом стиле/почерке из 15 входных примеров.
Немного об архитектуре GANwriting. Как и в TextStyleBrush, здесь есть энкодеры для картинок-стилей и текста.
Style encoder принимает на вход 15 изображений и выдаёт тензор, кодирующий стиль (авторы добавляют ещё случайный шум к тензору для искусственного создания вариативности).
Content encoder принимает текст в виде one-hot матрицы (в отличие от TextStyleBrush, который рендерил текст стандартным шрифтом на белом фоне), далее энкодер делится на две головы g1 и g2. Выход g1 коннектится к выходу style encoder и такой объединённый тензор уже подаётся на вход генератору, который затем апскейлит его в результирующую картинку. Выходные контент-векторы головы g2 подаются генератору на четырёх его уровнях в AdaIN слои (тогда как в TextStyleBrush в генератор пробрасывали стиль).
В качестве лоссов используется дискриминатор, классификатор авторов/стилей и OCR-модель. Роль writer classifier в целом похожа на роль классификатора шрифтов из TextStyleBrush: дать генератору дополнительную информацию о типах/особенностях почерков. Однако там мы могли этот классификатор заранее обучить на синтетических данных, в GANwriting же для датасета потребуется разметка автора для каждой картинки, что, конечно же, не всегда можно легко получить. Такую разметку необходимо планировать заранее во время сбора и разметки данных, так как в процессе доразметки понять автора текста по картинке будет уже невозможно. Также создатели GANwriting пишут, что writerclassifier помогает в предотвращении mode collapse.
Все сетки модели учатся с нуля: разработчики получили лучшие результаты именно при таком подходе, чем при создании предобученных сеток какой-либо из частей архитектуры.
Также авторы приводят примеры генерации, используя в качестве входных параметров текст или изображения, которых не было во время обучения. Это очень здорово, ведь модель можно использовать для генерации синтетического датасета, имея всего несколько настоящих примеров почерка одного человека, – без необходимости дообучения.

Ещё одной интересной демонстрацией GANwriting является смешение стилей разных авторов. Ведь не обязательно на инференсе использовать 15 входных изображений одного человека. Можно смешивать почерки разных людей, и тем самым разнообразить синтетический датасет. На картинке ниже видно, как модель плавно меняет почерк в зависимости от того, сколько изображений из 15 было от одного человека и сколько от другого.

Авторы статьи также поделились своим кодом, и было интересно попробовать обучить модель самостоятельно. Но, к сожалению, после множества экспериментов так и не удалось получить такие же красивые результаты, какие мы видим в статье. Картинки получаются довольно синтетическими на вид:
ScrabbleGAN

Следующая статья 2020-го года от Amazon – ScrabbleGAN. Архитектура проще, чем те, что мы рассмотрели ранее. Есть только генератор, дискриминатор и OCR. На вход модели мы подаём текст, а генератор уже создаёт изображение. В разметке не требуется классификатор почерков или шрифтов, или же разметка bbox’ов, – нужны только картинки с текстом и аннотации для него.
Немного об архитектуре: one-hot-текст умножается на вектор случайного шума, проходит через linear-слои и далее апскейлится генератором (BigGAN-модель). Вектор шума отвечает за стиль букв: почерк/толщину/курсив и прочее. На инференсе, если не менять шум, то картинки, соответственно, все будут в одном стиле. И основной недостаток ScrabbleGAN: на стиль генерации можно повлиять только с помощью вектора случайного шума.
Сгенерированная картинка подаётся на вход дискриминатору, который помогает улучшить общее качество изображения, и рекогнайзеру (OCR), который делает текст читаемым.
Авторы статьи оставили в OCR-модели только конволюционные слои по той причине, что рекуррентные могут выучивать неявную языковую модель датасета и предсказывать правильное написание слова, тогда как на картинке оно написано ошибочно (Implicit Language Model in LSTM for OCR). Это может помешать в случае, когда OCR используется как часть архитектуры GAN, ведь здесь OCR должна читать именно тот текст, который написал генератор, без додумывания. Что также интересно, авторы статьи выбрали как можно более простую OCR-модель, так как в их экспериментах усложнение ухудшало общие результаты.
Любопытно видеть результаты обучения при разных коэффициентах альфа, отвечающего за вес OCR-лосса во время обучения. При a=∞ GAN обучается фактически без дискриминатора (и это видно по качеству картинок в левой колонке), а при a=0 GAN обучается без рекогнайзера (правая колонка) – и картинки выглядят реалистично, но вместо текста мы видим каракули.

Также авторы статьи провели интересный эксперимент: обучили OCR-модель на IAM-датасете и тестировали на CVL (наблюдая при этом невысокое качество распознавания на тесте в силу большого различия доменов датасетов).
В качестве трейна к IAM-датасету добавили синту от ScrabbleGAN. При этом дискриминатор ScrabbleGAN можно отдельно дообучить на неразмеченных данных (т. к. дискриминатор предсказывает только два класса – real/fake, – можно использовать unlabeled данные). И, соответственно, мы можем дообучить дискриминатор на CVL-стилях: в генерируемых изображениях тогда сымитируем стиль CVL-датасета. Результаты авторов:

В первой строке в качестве бейзлайна OCR обучена только на IAM без синты – видим процент ошибок на уровне 40% на CVL-датасете. И снижение ошибок до 30% (вторая снизу строка) мы получаем при добавлении синты от ScrabbleGAN, дообученого на неразмеченных CVL-картинках и с использованием CVL-текстов для генерации синты. Правильно подобранный лексикон при обучении OCR даёт хорошие результаты – это говорит о том, что полезно понимать словарный домен, который модель будет читать в бою. То есть если модель будет использоваться на каких-то медицинских документах, то хорошо бы и обучать её на лексиконе из медицинских терминов. Последняя строка в таблице – OCR, обученный сразу на CVL-данных (для понимания, где потолок у этих экспериментов, – 23% WER).
Результаты ScrabbleGAN на русскоязычном OCR
Хорошая новость со ScrabbleGAN в том, что авторы выложили свой код. Однако эта реализация мне показалось более приятной (отрефакторенная версия ребят из Amazon). Также можете попробовать наш форк (удобнее запускать из Docker и обучать цветные картинки).
Попробуем повторить результаты авторов ScrabbleGAN, но для экспериментов будем использовать русскоязычные рукописные датасеты: HKR в качестве трейна и наш внутренний датасет Forms для тестов (часть этого датасета открыта, и вы можете взять его здесь). Это достаточно разные датасеты как по стилям (условия фотографирования, разные почерки, текстура и цвет бумаги), так и по лексикону. Forms – это фотографии заполнения различных бланков, и тексты там, соответственно, формальные (названия городов, индексы, имена, даты, время и т. д.). Тогда как в HKR лексикон более «обычный», литературный. Основная цель экспериментов – проверить, что генерация рукописки с помощью GAN'ов будет давать прирост качества OCR-моделей на новых доменах.
Также к трейн-датасету мы можем добавить простую синтетику: фон + текст на основе ttf-шрифтов. Такие шрифты обычно печатные, и те из них, что якобы являются рукописными, скорее имитируют курсив. Но тем не менее, мы для сравнения обучим и на такой синте. Примеры картинок, слева направо - HKR, Forms и синта на основе шрифтов:

И давайте взглянем на синту от ScrabbleGAN, обученного на русскоязычном HKR-датасете. Здорово посмотреть, как ScrabbleGAN меняет стили почерка в зависимости от вектора случайного шума (справа):

Итак, результаты экспериментов:
Параметры трейн-датасета |
Accuracy, тестовый Forms-датасет |
HKR (naive) |
0,5% |
HKR + TTF |
13,9% |
HKR + GAN |
12,3% |
HKR + TTF + GAN |
24,1% |
HKR + Forms (для понимания максимального качества) |
66,5% |
Первая строка – в качестве обучающего датасета HKR без какой-либо дополнительной синты (но используются обычные аугментации для картинок), и на Forms-тесте такая модель дает не впечатляющие результаты в полпроцента (здесь accuracy – когда предсказанный текст для строки полностью совпадает с таргетом). Такая низкая точность потому, что датасеты отличаются как по стилю, так и по лексикону (плюс маленький объем трейн-датасета).
Второй эксперимент – добавили простую синту на ttf-шрифтах, и точность модели на тесте возросла до 13,9%. Но когда к обучающей выборке мы вместе с ttf-синтой добавляем картинки от ScrabbleGAN (предпоследняя строка), получаем точность уже 24,1%.
Это говорит о том, что добавление синтетики от ScrabbleGAN улучшает качество OCR-модели при чтении текста на новых доменах. При этом рост точности при добавлении синты от GAN сопоставим с обычной синтой на ttf-шрифтах: 9–13% accuracy на новых доменах. При объединении синтетики от GAN и на основе ttf-шрифтов качество OCR-модели на новых доменах возрастает еще сильнее – до 23–24% (видимо, эти синтетические датасеты дают разные фичи для OCR-модели). В процессе экспериментов я пробовал различные параметры обучения GAN (обученной на рандомном лексиконе, на лексиконе от Forms и дообученной на неразмеченных картинках Forms), но результаты получались сопоставимые с тем, как если ScrabbleGAN обучать только на HKR-датасете.
Результаты StackMIX
StackMix – работа наших коллег, о которой подробнее можно почитать в статье, и сам код находится здесь. Идея состоит в создании новых изображений с текстом из уже имеющегося датасета:
Обучаем базовую OCR-модель с CTC loss’ом на датасете.
Далее используем эту модель для нарезки каждой картинки из датасета по отдельным буквам/n-граммам. Чтобы нарезать её по словам, используем координаты букв, которые можем вытащить из CTC лосса. По итогу у нас получится очень много маленьких картинок по отдельным буквам / последовательностям букв (например, из одного изображения с текстом «кошка» мы накропаем несколько картинок с текстами «к», «ош», «ка»).
Далее мы можем собрать новые слова как конструктор из кропов отдельных букв.

Мы не создаем новые изображения (так как картинки всё-таки состоят из частей старых), это что-то среднее между аугментацией и синтетикой. Концепция Stackmix похожа на такие аугментации, как, например, Cutout, которые заставляют сетку обращать внимание на важные фичи для распознавания, мешая оверфититься под определённые особенности датасета. Ну и конечно, StackMix позволяет расширить датасет новым лексиконом, что не менее важно. Примеры генерации слева. Теперь попробуем обучить OCR-модель на HKR с добавлением StackMix-синты (сгенерированной из HKR-картинок).
Параметры трейн-датасета |
Accuracy, тестовый Forms-датасет |
HKR (naive) |
0,5% |
HKR + S-MIX |
27% |
HKR + S-MIX + TTF |
35,1% |
HKR + S-MIX + TTF + GAN |
38,1% |
Как видим, одно только добавление синты StackMix даёт точность распознавания в 27% на тестовом Forms-датасете. И если объединить все три типа синтетики – от StackMix, обычную на ttf-шрифтах и синту от ScrabbleGAN – то мы получаем точность в 38,1% на тесте Forms (напомню, что домены трейна и теста отличаются). И это очень и очень здорово. Фактически, без использования дополнительных размеченных датасетов нам удалось повысить точность распознавания на новых доменах с 0,5% до 38% за счёт генерации синтетических изображений.
Примеры генерации синты ScrabbleGAN на других датасетах
Интересно посмотреть на сгенерированный почерк Петра I. Здесь, кажется, GAN не так просто имитировать столь витиеватый и неразборчивый текст. Хоть датасет состоит из текстов только Петра I, в зависимости от вектора случайного шума GAN немного меняет почерк генерируемой картинки. Ведь человек одну букву каждый раз пишет как-нибудь иначе, что позволяет сети выучить некоторую вариативность в стилях генерации:

Скачать датасет Петра I вы можете здесь.
Также мы выложили в открытый доступ датасет школьных тетрадей.

Это довольно большой датасет, представляет собой фотографии тетрадей и состоит из двух частей: разметки сегментации (полигоны для каждого слова) и разметки токенов (пары картинка с текстом и перевод). Слева несколько примеров слов из датасета.
Ну и конечно, примеры синтетических картинок от ScrabbleGAN:

Здесь видно, как вектор случайного шума особенно сильно влияет на почерк генерируемых картинок, так как датасет собирался из довольно большого количества тетрадей разных учеников.
Итоги
Интересно, что GAN-синтетика не даёт самый большой вклад в общую точность OCR-модели, несмотря на то что выглядит наиболее реалистично. Я бы предложил этому следующее объяснение. Во всех трёх GAN-архитектурах, которые мы рассмотрели, есть OCR-голова, которая помогает генератору учиться рисовать читаемые буквы. Но, возможно, генератор в процессе обучения, помимо нормального текста, также закладывает в картинке в каком-то неявном виде кодировку (шумы, цветопередача), таким образом быстрее и легче обманывая OCR-голову. И когда мы подаём такую синтетику в финальную OCR-модель, то она тоже будет выучивать кодировку текста от генератора, которая бесполезна в реальных данных. Но это предположение требует более детальных экспериментов.
Что же, мы посмотрели с вами три статьи по генерации рукописных картинок и попробовали применить одну из них – ScrabbleGAN – на русскоязычных датасетах. Причем для усложнения задачи в качестве тестового датасета взяли примеры со стилями/почерками, которых нет в трейне. И провели эксперименты, чтобы понять, как сильно докидывает в точности распознавания синтетика от GAN по сравнению с основанной на ttf-шрифтах синтетикой, а также по сравнению с методом StackMix. В итоге, что, наверное, не так и удивительно, лучше всего работает модель, объединяющая все три типа синтетических данных.
Надеюсь, получилось интересно, и мы ещё вернёмся со статьями и экспериментами по OCR для рукописных изображений. Спасибо за внимание!
Ссылки из статьи:
Датасеты - здесь можно скачать датаеты тетрадей, Forms, Петра
OCR модель - CRNN для чтения текста, с простым запуском для экспериментов
Форк ScrabbleGAN с более понятным запуском обучения и генерации картинок
При поддержке команд SberAI и SberIDP
Коллектив авторов: @ddimitrov, @shonenkov, @markpotanin, @gazizovmarat
AigizK
А есть готовый скрипт, модель, который умеет вычленять слова из фото с тетрадей? А то есть 30K+ фото разных почерков рукописного текста с кириллицей и сам текст(диктант).
Мог бы потом с датасетом с вами поделиться то же.
befuddle Автор
Добрый! Моделью для детекции, к сожалению, поделиться не можем, пока только для внутренней работы.