

Компьютерное зрение – это увлекательная область искусственного интеллекта, имеющая огромное значение в реальном мире. Forbes ожидает, что к 2022 году рынок компьютерного зрения достигнет оборота 50 миллиардов долларов, а всех нас ждет новая волна стартапов в этой области [1]. В своей статье я хотел бы поделиться своим опытом и опытом Data Science-команды компании Accenture по созданию цифрового решения потоковой аналитики на базе компьютерного зрения.
Уже сейчас можно с уверенностью сказать, что системы на базе компьютерного зрения прочно закрепились среди самых эффективных и востребованных технологий XXI века [2]. Их применение повсеместно: в бытовой технике, на производстве, в системах безопасности, медицине и науке, от систем разблокировки телефона до сложнейших автопилотов автомобилей.
А ещё совсем недавно фантастический боевик Джеймса Кэмерона «Терминатор» будоражил наше сознание совершенством и вместе с тем нереальностью персонажей и технологий. Давайте вспомним кадры из этого фильма и сравним их с возможностями современных технологий компьютерного зрения.
")
Сегодня искусственный интеллект позволяет машинам видеть, распознавать, классифицировать и отслеживать увиденное. Компьютерное зрение сегодня – это наша реальность и помощник человеку.
")
В ряде задач требуется компьютерное зрение, работающее в режиме реального времени. Например, в системах безопасности на производстве, где необходима незамедлительная реакция на отклонение от производственного процесса, которое может привести к серьёзной аварии или несчастному случаю. Или компьютерное зрение является частью системы контроля качества на сборочном конвейере, где строго регламентировано время каждого этапа сборки.
Я хотел бы поделиться своим опытом и опытом нашей Data Science-команды в направлении Industry X.0 компании Accenture по созданию цифрового решения потоковой аналитики, работающей в режиме реального времени.
Также цель статьи - систематизировать и зафиксировать полученные знания и опыт реализации цифрового решения на платформе Deepstream от Nvidia, которая является в целом новой платформой и ранее не использовалась российской практикой Accenture, а может быть, и не только российской.
Забегая вперёд, скажу, что хочу разбить весь материал на несколько частей, чтобы содержание было не слишком концентрированным и в то же время изложено подробно и полноценно.
Итак, в первой части расскажу об общем подходе к реализации нашего цифрового решения на базе компьютерного зрения и его основном движке – платформе Deepstream.
Для начала в общих чертах представлю архитектуру решения, чтобы стало ясно, как всё это работает, а также были понятны роль и место в этой архитектуре платформы Deepstream. Итак, схематично архитектура выглядит следующим образом.

Конечно, это очень укрупнённая схема архитектуры цифрового решения, без глубокой детализации. Представил я её в таком виде для того, чтобы мы сейчас сфокусировались на основных её частях.
Давайте вместе пройдёмся по архитектуре решения и рассмотрим основные принципы функционирования её составных частей.
Видеоисточником являются IP-камеры, которые по протоколу RTSP передают видео на аналитическую систему на базе компьютерного зрения. В аналитической системе происходит предобработка видео, обнаружение объекта, определение признаков объекта и его классификация. Далее сформированные метаданные объекта записываются в базу данных (БД). Типовая аналитическая система на базе компьютерного зрения использует последовательность шагов, которая называется пайплайном компьютерного зрения [3].

Мозгом, если так можно выразиться, аналитической системы являются нейронные сети с различной архитектурой и назначением, каждая из которых выполняет свою задачу. Одни нейронные сети определяют, что изображение незамутнённое и резкое, другие обнаруживают необходимые объекты в кадре, третьи классифицируют их. Каким образом работают нейронные сети, как они решают столь сложные задачи, это отдельная история и наука, которой можно посвятить огромное количество страниц, но в рамках данной публикации я не буду подробно останавливаться на этом. Представлю лишь на рисунке ниже, как выглядят видеокадр и метаданные, полученные при помощи обработки видеокадра нейронными сетями.

Метаданные записываются в БД, к которой, в свою очередь, подключается сервис постобработки метаданных, где на основании сопоставления производится вывод о происходящем в кадре. Результат постобработки систематизируется и также записывается в БД, а необходимая информация выводится на интерфейс пользователя для оперативного просмотра. Одним из результатов постобработки может являться сигнал-триггер для совершения какого-либо действия. Например, в случае системы безопасности это может быть сигнал экстренного отключение оборудования, остановка работы станка или производственного агрегата для предотвращения аварии.
Как я уже писал выше, зачастую необходимо, чтобы система на базе компьютерного зрения работала неотрывно от происходящего в реальности. И в этом случае к такой системе предъявляются весьма высокие требования по вычислительной производительности. Центральное место, где требуется высокая производительность, является аналитическая система. Сейчас попробую на пальцах объяснить, почему.
Итак, поехали. Современные нейронные сети для компьютерного зрения могут состоять из десятков миллионов нейронов, которые организованы в сотни слоёв нейронной сети. Базовой вычислительной операцией в каждом слое является операция свёртки, которая в частном случае является скалярным произведением векторов или в общем - скалярным произведением матриц. Именно поэтому такой класс нейронных сетей, которые чаще всего используются для компьютерного зрения, получил название свёрточных нейронных сетей.
Если свёртку разложить на элементарные математические операции, то это будут операции умножения и сложения. То есть для обработки одного кадра видеопотока одной нейронной сетью требуется выполнение десятков миллионов умножений и сложений. Если в нашей аналитической системе кадр обрабатывают несколько нейронных сетей, то количество умножений и сложений будет исчисляться сотнями миллионов. Также зачастую аналитическая система должна уметь обрабатывать параллельно несколько источников видеопотока, что ещё увеличивает количество вычислений.
Такую задачку с вычислением сотен миллионов однотипных операций в единицу времени на сегодняшний день очень хорошо решают например видеокарты (GPU), построенные на базе многопроцессорной архитектуры с применением технологии CUDA и специализированными вычислительными ядрами [4]. Также отдельные операции с видеокадрами могут производиться на центральном процессоре (CPU) с использованием специализированных библиотек типа OpenCV.
Вот мы и добрались до самого главного, на чём же построить такую высокопроизводительную аналитическую систему, которая отвечала бы следующим требованиям: 1) под капотом имела видеокарту, а лучше несколько; 2) умела принимать видеопоток от нескольких источников; 3) имела возможность интегрировать в пайплайн обработки нейронные сети; 4) имела внешний стандартный интерфейс ввода-вывода данных. Также для высокопроизводительной системы, работающей в реалтайм-режиме, необходимо иметь в качестве базового языка разработки что-то си-плюс-плюсное и компилируемое.
В таких случаях всегда возникает дилемма. Разрабатывать из «кирпичиков» с высокой прозрачностью, максимальной гибкостью и полным контролем содеянного, но высокой трудоёмкостью и вероятностью изобретения велосипеда в конечном счёте или взять готовую систему «черный ящик» с кучей настроек и конфигураций, интерфейсом и попытаться приспособить её к своей конкретной задаче? Тут могут появиться вопросы с гибкостью такой системы, а также временными затратам на освоение такой специализированной системы, и скорее всего, она окажется дорогостоящей для сопровождения и поддержки со стороны заказчика. Компромисс как всегда находится где-то посередине. По всей совокупности требований нашей команде подошла платформа Deepstream от Nvidia. Что же такое платформа Deepstream?
Deepstream – это набор инструментов потоковой аналитики для создания приложений на базе искусственного интеллекта, который является неотъемлемой частью NVIDIA Metropolis, платформы для создания комплексных сервисов и решений для обработки изображений и данных датчиков. Deepstream организован по принципу строительных блоков-плагинов с аппаратным ускорением (GPU или CPU), которые реализуют нейронные сети, декодеры видеоизображения, различные фильтры и другие сложные функциональные элементы обработки входных данных. Deepstream поддерживает разработку приложений на C / C ++ и Python и построена с использованием платформы GStreamer с открытым исходным кодом. Схематично пайплайн решения видеоаналитики в Deepstream может выглядеть как на картинке ниже.

Каждый элемент в схеме — это плагин, который выполняет свою отдельную функциональную задачу в общем пайплайне решения видеоаналитики. Как видно из схемы, это достаточно самостоятельные блоки обработки изображения: видеодекодер (например, H.264) DECODE, блок масштабирования изображения IMAGE PROCESSING.
Разработчику предлагается построение пайплайна на функциональном уровне, иными словами, построение цепочки связных плагинов. При этом разработчики платформы Deepstream уже позаботились о реализации более низкоуровневых процессов, из которых можно выделить следующие:
эффективное использование графического процессора для ускоренной обработки и вывода данных;
эффективная обработка данных сразу из нескольких видеопотоков;
формирование и отслеживание метаданных, связанных с каждым кадром видео, полученных от нескольких источников;
оптимизация пайплайна для максимальной производительности;
оптимизация плагинов нейронных сетей для высокоскоростного вывода результатов.
Теперь разберёмся, что представляет собой отдельный плагин. По сути, плагин представляет собой набор API для его создания, конфигурации и подключения к другим плагинам.
Покажу на примере плагина мультиплексора (Gst-nvstreammux), который формирует пакет, или батч, из кадров отдельных источников видеосигнала. Схематично он выглядит как на картинке ниже.
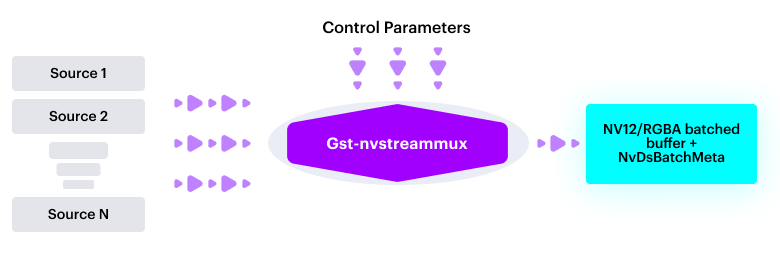
Плагин имеет входные сигналы (Inputs) от источников видео (Source 1, Source 2… Source N), установочные параметры (Control Parameters), задающие режим работы плагина, и выходные сигналы – упакованный батч входных кадров и метаданные источников входных сигналов. Чтобы плагин работал в пайплайне, необходимо выполнить четыре основные действия:
создание плагина;
установка режима работы плагина;
добавление плагина в пайплайн;
линковка с другими плагинами пайплайна.
Итак, по порядку. Проделаем действия для включения в пайплайн плагина мультиплексора с использованием синтаксиса С/С++. Для создания плагина необходимо выполнить следующую команду:
Создание плагина.
streammux = gst_element_factory_make ("nvstreammux", "stream-muxer");Для установки режима работы плагина, например, задания размера обрабатываемого пакета (батча) равным количеству источников видеосигнала, необходимо выполнить следующую команду:
Установка режима работы плагина.
g_object_set (G_OBJECT (streammux), "batch-size", num_sources, NULL);У данного плагина есть ещё целый ряд настраиваемых параметров, но, по сути, пример выше отражает принцип установки любого из них.
Для добавления плагина в пайплайн необходимо выполнить следующую команду:
Добавление плагина в пайплайн.
gst_bin_add (GST_BIN (pipeline), streammux);Чтобы соединить плагины в единую цепочку и задать последовательность выполнения пайплайна, необходимо сделать их линковку:
Линковка с другими плагинами пайплайна.
gst_element_link_many (streammux, queue, NULL);Здесь описанный ранее мультиплексор (streammux) соединяется с плагином очереди (queue) для буферизации сообщений.
Как видно из примера выше, построение пайплайна интуитивно понятно, реализация выполняется на уровне функционального программирования. Для большего понимания работы с плагинами есть примеры готовых пайплайнов от Nvidia, есть даже небольшой курс, который призван научить основам работы с Deepstream.
Однако не всё так просто, иначе я не затевал бы эту статью. Как говорится, дьявол кроется в деталях. Как и в большинстве функционально ёмких и гибких платформ, здесь всегда есть нюансы и подводные камни, которые зачастую являются ключевыми и выявляются, когда берёшься за непосредственное выполнение конкретной задачи.
Об особенностях работы с платформой Deepstream на примере построения полного пайплайна от начала до конца для конкретной бизнес-задачи я расскажу в следующей части своей статьи.
Литература, ссылки
https://medium.com/bitgrit-data-science-publication/5-computer-vision-trends-for-2021-96fd18d5596c;
Deep Learning for Vision Systems, Mohamed Elgendy, Manning Publications Co. PO Box 761 Shelter Island, NY 11964, ISBN: 9781617296192];
https://vksegfault.github.io//posts/gentle-intro-gpu-inner-workings.