

Несколько месяцев назад на моем пути возник GraphQL.
Это произошло, когда я присоединилась к одному из наших проектов, где был не только привычный REST, но и GraphQL API. Это было моё первое знакомство с ним. Я понятия не имела, что он собой представляет, в чем его особенности, а самое главное для меня, как QA инженера – не знала, как его тестировать.
Ниже я расскажу, что делала я, с какими проблемами сталкивалась, с чего можно начать и что важного и особенного надо знать про GraphQL для успешного тестирования как руками, так и с помощью автотестов. Вполне вероятно, что это поможет и вам разобраться в данном вопросе.
Что такое GraphQL
Прежде, чем вы приступите к тестированию, вам надо выяснить основы GraphQL. Для тех, кто совсем не знаком, советую прочитать официальную документацию, остальным кратко напомню самые базовые вещи и постараюсь уделить внимание именно тому, что необходимо для понимания QA инженерам.
Определение и архитектура
Итак, GraphQL — это язык запросов для API и среда выполнения этих запросов на стороне сервера. Он определяет контракт между клиентом и сервером.
Вот так может выглядеть архитектура приложения:
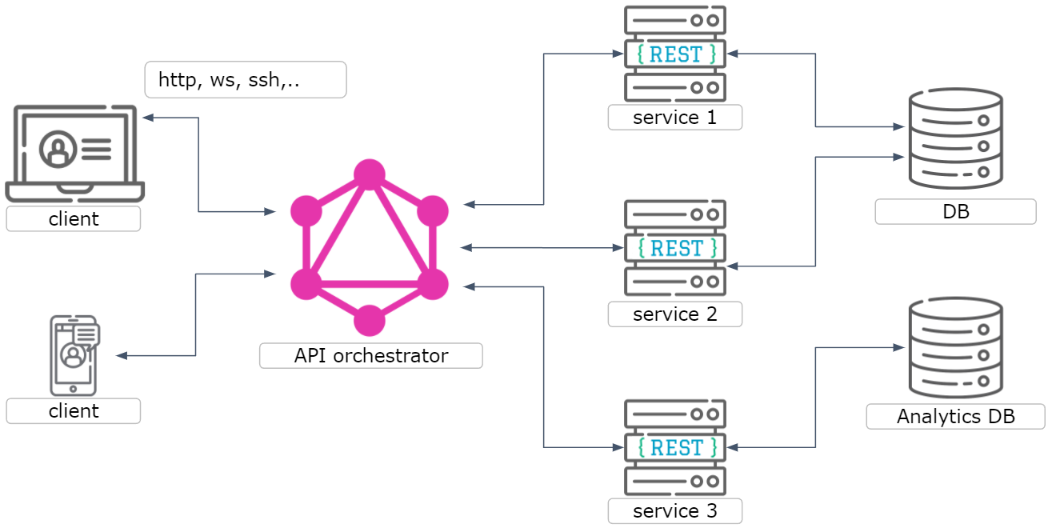
Здесь GraphQL является дополнительным слоем между клиентом и сервером и может служить для облегчения сбора данных из разных источников. По сути, это такой API оркестратор.
Транспорт данных между клиентом и сервером может осуществляться по http, но это не обязательно. Данные могут идти и по ssh, и по websocket. Но дальше на примерах мы будем рассматривать всё же вариант с http, как наиболее используемый.
GraphQL может взаимодействовать как с микросервисами этого же приложения, так и с сервисами третьесторонних систем.
Workflow
Клиент запрашивает данные у GraphQL сервера, используя свой декларативный синтаксис → сервер анализирует запрос и достает все нужные данные из соответствующих источников (других сервисов и баз данных) → генерирует payload с ответом в виде JSON → отправляет ответ со всеми данными обратно клиенту.
Тестовое приложение
Далее в тексте будут примеры, основанные на приложении Movies app с Github Евгения Ковальчука https://github.com/YauhenKavalchuk/graphql-tutorial/. Он его создавал в рамках своего курса по разработке GraphQL.
Архитектура у этого приложения простая и выглядит следующим образом:
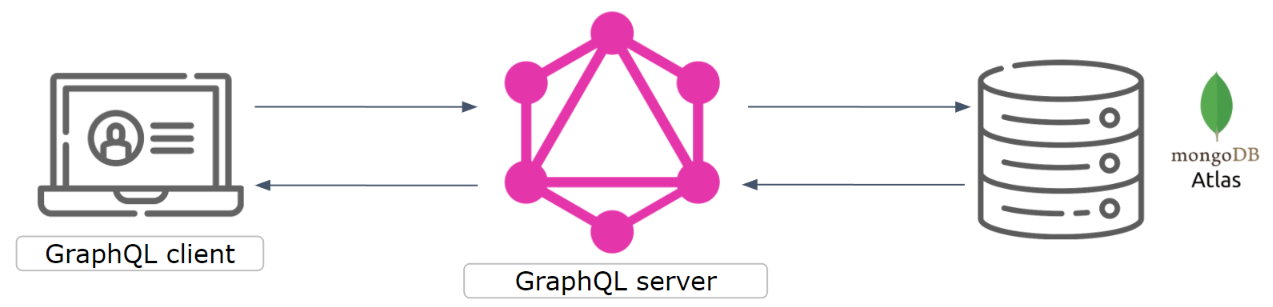
В двух словах расскажу о самом приложении, чтобы дальнейшие примеры были понятны: на UI есть две вкладки – Movies (фильмы) и Directors (режиссеры).
На вкладке Movies содержится список фильмов, данные о которых включают в себя название фильма, его жанр, рейтинг, режиссера и галочку о просмотре. Данные можно редактировать, можно добавлять новые фильмы, удалять их. Аналогично на вкладке Directors — данные о режиссере включают в себя его имя, возраст и фильмы, которые он снял.
Особенности GraphQL
Давайте посмотрим на особенности GraphQL. Проще всего это сделать, сравнивая его со всем знакомым REST API. Но я буду делать это не в контексте "что лучше или хуже", а в контексте “зачем это знать тестировщику”.
Типы запросов
И REST, и GraphQL реализуют все четыре CRUD операции. Однако REST использует разные типы http запросов (GET, POST, PUT, DELETE,..), чтобы реализовать эти CRUD функции. A GraphQL использует всегда POST, но у него есть 2 своих типа запроса в SDL (schema definition language) — Query и Mutation. Query отвечает за чтение данных, а Mutation за все остальные операции, связанные с изменениями.
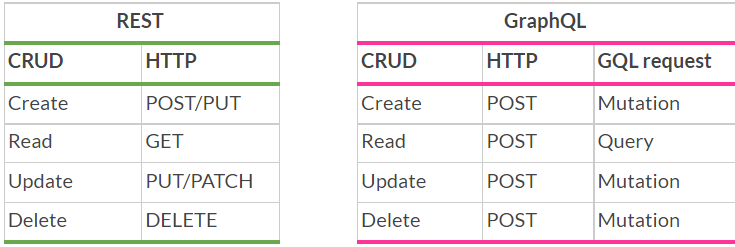
Что это значит для тестирования? Тут все просто: зафиксировали, что тип запроса всегда будем использовать POST, и запомнили зарезервированные слова Query и Mutation, т.к. их мы будем использовать при составлении самих запросов.
Получение данных
Получение данных или data fetching — это, пожалуй, самая существенная разница между REST и GraphQL, о которой я буду говорить.
Так вот, REST стиль предполагает множество эндпоинтов, которые отвечают за возвращение данных из различных источников. И когда говорят о сравнении REST и GraphQL, то всегда упоминают о таких проблемах, как overfetching и underfetching.

Overfetching — когда эндпоинт возвращает лишние данные. Например, нам надо вернуть только название фильма. Но эндпоинт спроектирован так, что возвращает нам еще и его жанр, и рейтинг, и вообще всё, что знает про фильм.
Underfetching — эндпоинт не в состоянии вернуть все необходимые данные. То есть, эндпоинт спроектирован таким образом, что он может вернуть только совершенно конкретные данные, относящиеся к фильму. Но если нам еще надо знать его режиссера и всех главных актеров, то придется дергать 3 разных эндпоинта.
GraphQL же — это один эндпоинт и через него посылается запрос, в котором можно дальше кастомизировать набор запрашиваемых полей.
То есть в GraphQL вся информация может быть получена одним запросом, конечно, при условии, что разработчики API указали взаимосвязи между сущностями в схеме GraphQL. В нашем примере между фильмами, актерами и режиссерами.
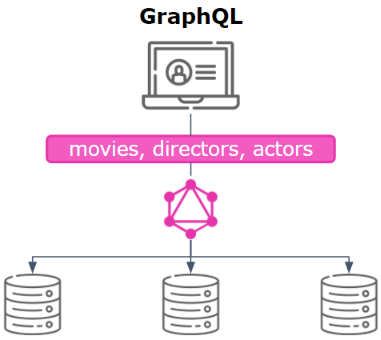
Т.е. GraphQL и разрабатывался в частности для того, чтобы решить эти проблемы (когда он только задумывался Facebook).
Например, если у нас есть разные клиенты — веб и мобильные, то для мобильных клиентов может возникать задача для более мелкого экранчика отображать меньше информации, чем для экрана монитора. Это сложно сделать, если у нас эндпоинт спроектирован таким образом, что он все равно возвращает много чего лишнего. Однако в GraphQL предполагается, что именно клиент правит балом и может запрашивать ровно то, что необходимо, ни больше ни меньше.
Итак, кастомизированный запрос…
Что это значит для тестирования?
Значит ли это, что нам придется делать полный перебор всех возможных вариантов запроса? Особенно, если разработчики спроектировали и разработали все таким образом, что взаимосвязи между сущностями представляют собой чуть ли не полный граф. Звучит жутко. Это ж потребует дико много времени и других ресурсов, чтобы все протестировать.
Но спешу успокоить. Практика показывает, что нет, не надо делать полный перебор. Лучше опирайтесь на ваши бизнес-требования.
Мы ж тестировщики, мы помним 7 принципов тестирования, 2 из которых говорят нам, что исчерпывающее тестирование недостижимо и что тестирование зависит от контекста. Так давайте от контекста и отталкиваться. Например, при наличии UI, если есть требование, что вот такие-то данные должны показываться пользователю, то и рассматриваем только этот кейс с запросом и совершенно конкретным набором полей.
Обработка ошибок
Довольно заметная вещь для тестирования.
В REST все просто. Есть HTTP статус-коды. И это первое, на что мы обращаем внимание, когда тестируем API.

И зная только эти статус-коды, мы уже можем верхнеуровнево определить, все ли в порядке или же есть какие-то ошибки на стороне клиента/сервера.
С GraphQL другая история. Там вы всегда получите статус 200 SUCCESS. Всегда. Это всё потому что GQL спецификация не привязана к какому-то конкретному протоколу. И так как нет этой жесткой привязки к протоколу, то ошибки все унесли в тело ответа.
Ниже представлен синтаксис, как это выглядит:
{
data: {}, // возврат данных
errors: [...], // массив для ошибок
extensions: {}, // объект для пользовательских данных
}Может, конечно, нам вернуться 500, если приключилась какая-то серьезная вещь, например, кончилась память или есть грубая синтаксическая ошибка в коде. Однако при этом дело просто не доходит до обработки GraphQL запроса.
Что это значит для тестирования? Тут очевидно. Не смотрим на статус, а лезем глубже в тело ответа и ищем ошибки там.
Документирование и базовые инструменты
Следующая особенность будет влиять не на то, КАК мы тестируем, а на то, ГДЕ тестируем и где берем документацию для тестирования.
Так вот, документация генерируется напрямую из graphql схемы. Дефолтные инструменты из экосистемы GraphQL, с которыми сталкиваются все — GraphIQL и GraphQL Playground. Эти инструменты хоть и совсем не похожи визуально на Swagger, но выполняют примерно те же функции: документация API и возможность прямо там делать запросы. Для быстрой проверки чего-то конкретного самое оно.
Что это значит для тестирования? То, что, хотим мы или нет, нам придется использовать другие инструменты и привыкнуть к ним. Как бы вы ни любили, например, Swagger.
Однако, если вы очень любите, например, Postman, то можете продолжать использовать, создавать коллекции, запускать их, писать тесты. Более того, там есть возможность подтянуть схему GraphQL и так же, как и в GraphiQL и Playground, будет доступна вся нужная документация, будет подсвечиваться синтаксис, есть автокомплит, линтинг и вообще можно автоматически сгенерировать всю коллекцию на основе схемы.
Кстати о схеме
Разберем еще пару терминов, которые будут нам полезны. А в частности, схема и типы.
Схема — это основа GraphQL. Спецификация GraphQL определяет язык schema definition language (или SDL), который и используют для определения схемы и сохранения ее в виде строки.
В GraphQL используется система типов для описания данных. И, чтобы протестировать GraphQL API, вы должны иметь некоторое базовое понимание его схемы. Например, какой тип данных используется для какого поля переменной. Да и вообще, чтобы понимать, какие поля и каких типов можно вернуть в запросе.
Вот так схема выглядит для нашего тестового приложения про фильмы:
type Director {
age: Int!
id: ID
movies: [Movie]
name: String!
}
type Movie {
director: Director
genre: String!
id: ID
name: String!
rate: Int
watched: Boolean!
}
type Mutation {
addDirector(age: Int!, name: String!): Director
addMovie(directorId: ID, genre: String!, name: String!, rate: Int, watched: Boolean!): Movie
deleteDirector(id: ID): Director
deleteMovie(id: ID): Movie
updateDirector(age: Int!, id: ID, name: String!): Director
updateMovie(directorId: ID, genre: String!, id: ID, name: String!, rate: Int, watched: Boolean!): Movie
}
type Query {
director(id: ID): Director
directors(name: String): [Director]
movie(id: ID): Movie
movies(name: String): [Movie]
}В GraphQL поля могут быть представлены как базовыми, так и пользовательскими типами. Например, название фильма, жанр — String, boolean для отметки о просмотре фильма. Но сами фильмы и режиссеры уже имеют пользовательские типы — Movie и Director.
Как составлять запросы
Здесь вам будет полезно понимание анатомии типичного запроса GraphQL.

Query
Вот так могут выглядеть одинаковые queries с разной формой записи. Сверху вариант записи, где прямо в самой query передается и аргумент со своим значением. Снизу — вид параметризированного запроса, когда переменная выносится отдельно. При этом во второй записи слово query обязательное, а в первом можно обойтись без него.
И стоит обратить внимание, что запрос — это не JSON, хоть и похож на него, а вот ответ — JSON. Это осознание нам пригодится, когда дело дойдет до автоматизации.

В этом же примере видно, что в одном запросе мы вернули данные и по фильму, и по режиссеру, т.к. в приложении установлены эти связи по id.
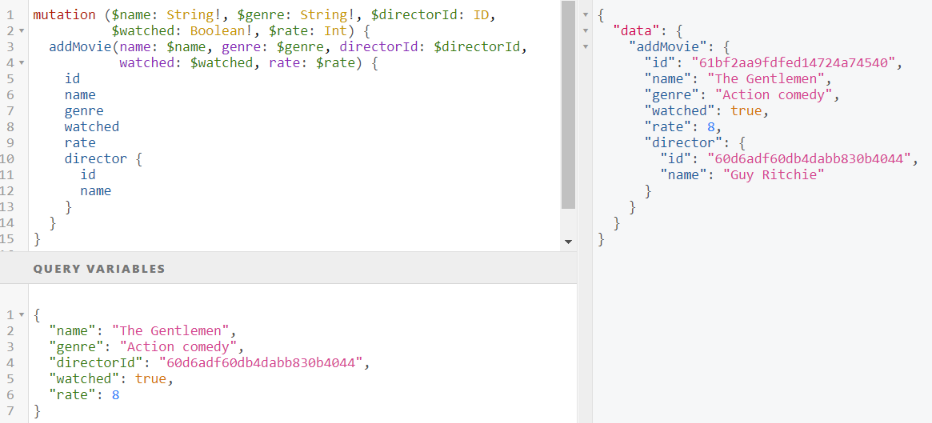
Mutation
А вот пример mutation на добавление нового фильма. Обратите внимание, что этот же запрос возвращает и только что созданный фильм с данными по нему. Довольно удобно.
Как вообще тестируют API
Теперь давайте посмотрим, абстрагируясь от GraphQL, как мы в своей повседневной практике тестируем API.
Цели тестирования API — проверить, что:
API работает. Проверяем, что новый эндпоинт выполняет то, что надо.
API соответствует требованиям – похожий пункт на первый, но здесь именно сверяемся с требованиями по методам, форматам данных, обязательным и необязательным полям. Здесь же могут быть проверки на соответствие нефункциональным требованиям по производительности, безопасности, юзабилити и т.д.
API ничего не ломает – это про интеграционное тестирование с другими сервисами и компонентами системы и, конечно же, про регрессию. Все имеющееся в системе должно продолжать корректно работать и с новым API.
С целями понятно, давайте разберемся, на каких уровнях может проходить тестирование. Назовем это test flows:
По отдельным компонентам: выполнение одного запроса API и соответствующая проверка ответа. Этим мы удостоверимся, что минимальные модули находятся в рабочем состоянии.
По сценариям использования: тестирование серии взаимосвязанных запросов, которые являются обычными действиями конечного пользователя в приложении. Например, для интернет-магазина это может быть такая цепочка: поиск товара, его выбор, помещение в корзину, оформление заказа и покупка.
Комбинированные: DB + API, API + UI, DB + API + UI – проверка целостности данных и согласованности между пользовательским интерфейсом, API и базами данных.
А конкретно мы проверяем статус код, тело ответа, отдельно заголовки ответа, в целом состояние приложения и некоторую базовую производительность.
И есть несколько базовых тестовых сценариев, коротко покажу их в таблице:

А что нам мешает использовать такие же подходы и к тестированию GraphQL? Да ничего. Отсечем лишь проверки на статус код, т.к. они будут для нас совсем неинформативными.
Итак, основу мы разобрали, для ручного тестирования знаний уже достаточно. Идём дальше.
Давайте заавтоматизируем
Когда я заходила на проект, от меня требовалось покрыть автотестами GraphQL оркестратор. Но не было никаких требований по инструментам. Однако было время подумать и поисследовать.
За это время я смогла попробовать несколько инструментов для тестирования:
Karate
Pytest + Requests
Cypress
Rest Assured
Все они отлично справляются с тестированием GraphQL. И если вы знаете какой-то из этих инструментов, то можете смело брать в работу. Ниже я покажу примеры, как будет выглядеть один и тот же тест для каждого из четырёх инструментов.
Тест будет следующим: проверить, что имя фильма по конкретному ID соответствует “Pulp Fiction”.
Query для этого теста будет такой:
query ($id: ID) {
movie(id: $id) {
name
}
}
{
"id": "60d6aab20db4dabb830b403f"
}Karate
Karate — это легкий в освоении и удобный в использовании фреймворк, использующий BDD подход. Вполне подходит для тестирования GraphQL API, поскольку у него есть такие фичи, как встроенный text-manipulation и JsonPath.
Тест будет выглядеть так:
Feature: Movie GraphQL query
Background:
* url 'http://localhost:3005/graphql'
Scenario: Get movie name
Given text query =
"""
query {
movie(id: "60d6aab20db4dabb830b403f") {
name
}
}
"""
And request {query: #(query)}
When method POST
Then match response.data.movie.name == "Pulp Fiction"Читаемый, интуитивно-понятный синтаксис, да и запрос можно вставлять просто как мульти-строку. Работает. Для приверженцев BDD стиля рекомендую.
Cypress
Cypress — широко известный open-source фреймворк для тестирования, который чаще используют для UI тестов. Но он также годится и для API автоматизации.
Давайте посмотрим, как сделать GraphQL запрос при помощи cy.request команды.
describe('GraphQL Simple Test', () => {
it('check movie name', () => {
const movieName = `
query movie(id: "60d6aab20db4dabb830b403f") {
name
}
`;
cy.request({
url: 'http://localhost:3005/graphql',
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: {query: movieName}
}).then(response => {
expect(response.body.data.movie.name).to.be.eq("Pulp Fiction");
});
});В этом примере мы прям локально определяли query, чтобы сделать запрос для теста. Но, конечно, можно улучшить тест, например, вынести запрос отдельно, чтобы потом было проще поддерживать. Но главное — мы проверили, что Cypress вполне применим для тестирования GraphQL.
Pytest + Requests
Аналогично с предыдущими примерами покажу самый простой способ создать и отправить запрос GraphQL и для Python. Давайте просто захардкодим query в виде строки. И все, что еще останется сделать, это создать JSON запрос с нашей query-строкой. Собственно, всё.
А так как тело ответа GraphQL приходит в виде JSON, то тут ничего выдумывать не надо. Просто применяем метод json(), чтобы преобразовать ответ в Python словарь, а далее уже делаем проверку интересующего нас элемента — названия фильма.
query_movie_name = """
{
movie(id: "60d6aab20db4dabb830b403f") {
name
}
}
"""
def test_get_movie_name():
response = requests.post("http://localhost:3005/graphql/", json={'query': query_movie_name})
response_body = response.json()
assert response_body['data']['movie']['name'] == 'Pulp Fiction'В этой статье можно более подробно почитать про тестирование GraphQL API при помощи Python.
Rest Assured
Это тот инструмент, который мы выбрали у себя на проекте — Java + Rest Assured. Хотя он предназначен для тестирования REST API, его также можно использовать и для GraphQL. А вообще выбор был сделан, исходя из нескольких вещей:
бэкенд проекта тоже разрабатывался на Java. И ни для кого не секрет, что очень выгодно писать тесты на одном языке с разработчиками. В случае чего могут помочь с кодом;
ещё java-разработчики могут делать код-ревью, что в разы повышает качество нашего фреймворка и стабильность тестов;
а Rest Assured выбрали, потому что он же используется и на других под-проектах нашего заказчика и гораздо удобнее иметь одинаковый инструментарий на случай ротаций разных QA между проектами.
Ниже представлена простая реализация, в которой запрос GraphQL был преобразован в строковый JSON формат и передан прямо в .body.
Пример:
@Test
public void getMovieName() {
given()
.contentType(ContentType.JSON)
.body("{\"query\":\"query movie ($id: ID) {\\n movie (id: $id) {\\n name\\n }\\n}\",
\"variables\":{\"id\":\"60d6aab20db4dabb830b403f\"}}")
.when()
.post("http://localhost:3005/graphql/")
.then().assertThat()
.body("data.movie.name", equalTo("Pulp Fiction"));
}Проверили, работает. Но понятно, если в таком виде писать тесты, то будет сложно их поддерживать.
Первое, что можно сделать, так это позволить Rest Assured самому позаботиться о создании Json payload. Для этого создадим простой POJO для запроса, который и будет представлять нашу GraphQL query. А Rest Assured сериализует этот POJO в Json. Затем передадим готовую query в теле запроса.
POJO:
@Data //Lombok annotation for creating getters and setters
public class GraphQLQuery {
private String query;
private Object variables;
}Давайте сразу еще учтем, что у нас еще есть переменные, которые бы хотелось не хардкодить прям в самом запросе, а выносить их куда-то отдельно. Создадим еще один POJO для переменной, в нашем примере для id:
@Data
public class Movie {
private String id;
}Посмотрим, как будет выглядеть сам тест:
@Test
public void getMovieName1() {
GraphQLQuery query = new GraphQLQuery();
query.setQuery("query ($id: ID) { movie(id: $id) { name } }");
Movie id = new Movie();
id.setId("60d6aab20db4dabb830b403f");
query.setVariables(id);
given()
.contentType(ContentType.JSON)
.body(query)
.when().post("http://localhost:3005/graphql/")
.then().assertThat()
.body("data.movie.name", equalTo("Pulp Fiction"));
}Однако, писать запросы прям в тесте не лучшая идея, они могут быть огромными, в конце концов. Помним же, что в GraphQL можно в одном запросе получить все, что угодно, при условии установления необходимых взаимосвязей между сущностями. Так вот, можно сами запросы, queries и mutations, выносить в отдельные файлы. Например, есть такой JS GraphQL plugin, который подсвечивает синтаксис запросов, можно прям в IDEA слать запросы, и еще есть много всяких фич для удобства работы с GraphQL. Но самое главное, можно делать интроспекцию схемы и подтягивать ее автоматически, а не копировать руками.
Так вот, чтобы работать с этим плагином, надо настроить .graphqlconfig файл, где необходимо указать эндпоинт и поставить true для introspect.
{
"name": "Movies GraphQL Schema",
"schemaPath": "schema.graphql",
"extensions": {
"endpoints": {
"Default GraphQL Endpoint": {
"url": "http://localhost:3005/graphql",
"headers": {
"user-agent": "JS GraphQL"
},
"introspect": true
}
}
}
}И уже в отдельных файлах с расширением .graphql хранить запросы.
Взглянем на последнюю реализацию нашего теста.
private static String generateStringFromResource(String path) throws IOException {
return new String(Files.readAllBytes(Paths.get(path)));
}
@Test
public void getMovieName2() throws IOException {
String file = generateStringFromResource("src/test/resources/movie.graphql");
GraphQLQuery query = new GraphQLQuery();
query.setQuery(file);
Movie id = new Movie();
id.setId("60d6aab20db4dabb830b403f");
query.setVariables(id);
given()
.contentType(ContentType.JSON)
.body(query)
.when().post("http://localhost:3005/graphql/")
.then().assertThat()
.body("data.movie.name", equalTo("Pulp Fiction"));
}Здесь мы написали отдельно метод для генерации строки из файла, сгенерировали строку из movie.graphql и передали это, как нашу query.
Ну вот, теперь тест выглядит более по-взрослому. Понятно, что дальше для порядка вы вытащите значения переменных из самих тестов и сделаете нормальную параметризацию, если надо. И еще вынесите всякие Request/Response спецификации, как полагается. Но это уже другая история, не касающаяся напрямую GraphQL.
Заключение
Что ж, не так и много отличий у нас получилось при тестировании GraphQL. Даже излюбленные инструменты можем продолжать использовать. А так, всего-то нужно немного адаптировать подход, который мы привычно применяем для REST API.
А именно:
всегда используем тип запроса Post,
ловим ошибки без статус-кодов,
кастомизируем запросы в тестах исходя из бизнес-требований,
учитываем при автоматизации, что пейлоад запроса не JSON,
а также используем дополнительные инструменты и плагины, упрощающие работу с GraphQL.
ermadmi78
А вот пример того, как GraphQL API можно тестировать на Kotlin ;)
olga_ipp Автор
Класс, спасибо за ссылку)