
О чём это всё?
Всем привет! Наконец дошли руки описать то как я проверял на практике знания, полученные в ходе написания трёх статей об избыточном кодировании по методу Рида-Соломона (раз, два, три). Если лень клацать по ссылкам, то вкратце: передаём данные, к которым мы добавили некоторый оверхед, они по пути бьются, на другом конце мы их восстанавливаем, используя этот оверхед. Соль кода Рида Соломона в том, что в качестве оверхеда не нужно дублировать сообщение. Если мы добавили всего два байта, то мы можем восстановить любой испорченный байт (подробнее в статьях). Но просто написать тесты (закодировать-побить-восстановить) это ну вот совсем не интересно. Да, конечно, я написал эти тесты, они успешно прошли, но подсознательно сам себя я не убедил, что в этом может быть какая-нибудь польза. Циферки на экране. Скучно!
Как будем проверять?
И вот думаю я думаю, что бы такого интересного передать чтобы и побиться могло и была хорошо заметна разница с коррекцией и без коррекции ошибок. И тут мне подруга присылает ссылку на видосик, говорит прикольно было бы поиграться:
Смотрю я и вижу: там модулируют свет лазерной указки звуком и в качестве приёмника используют солнечную панельку. Думаю, ну что за детский сад! Я ещё в пятом классе догадался приделать солнечную батарейку от поломанного калькулятора к микрофонному входу батиного усилка. А модулировал свет лазерной указки отражая его от мыльной плёнки. Говоришь в мыльный пузырь и слышишь свой голос. Даже на кассету записал - звучит смешно, высокие частоты сильно срезаны. В ту же солнечную батарейку ещё пультом от телевизора светил. Прекрасно помню тот звук цифровых данный на аудиотракте. И тут снизошло озарение. А что, если звук оцифровать, избыточно закодировать по Риду-Соломону, передать через лазерную указку, на приёмнике раскодировать и вернуть в аналог? Вот это уже интересненько. Во-первых, люблю лазеры, во-вторых, нравится ковыряться со звуком и, собственно, главное – проверим написанный алгоритм!
Как будем цифровать звук?
Ну тут, думаю, для большинства читателей не будет большой тайны как волну превратить в отсчёты. Но я не пошёл очевидным путём – использовать АЦП, встроенный в микроконтроллер. Да, надо сделать оговорку. Реализовано всё будет на стм32, самых дешёвых (когда-то, боль!) stm32f103c8, распаянных на минимальной плате, в народе её ещё называют как известные таблетки: Blue pill. Также будет использован ещё один относительно дешёвый МК stm32f411ce. Почему именно они? Да потому, что они есть в коробочке распаянные и готовые воткнуться в бредборд. Генерировать звук я решил с помощью МК. Точнее не генерировать, а воспроизводить с флешки. Не той, что USB или SD, а той, что Winbond 25q64 - микросхемка восьминогая, 4Мб, интерфейс SPI. На прекрасный способ воспроизводить звук на эстээмках меня натолкнула статья о работе с пиксельной лентой ws2812b:
Там интервалы для битовых последовательностей формируются аппаратно с использованием таймера и DMA: то есть, по окончании счёта таймера до установленного предела (регистр ARR) срабатывает DMA и загружает в регистр ширины импульса (CCR) значение из памяти, с инкрементом адреса памяти. Получается, что МК сам, без участия ЦП выдаёт импульсы и длина каждого импульса пропорциональна значению, записанному в массиве памяти. Для управления лентой там записаны длины для нулей и единиц, то есть, короткий импульс - ноль, длинный - единица. Для передачи одного бита в ленту в памяти лежит целый байт. Расточительство!
А что, если в память положить отчёты для звука? Надо произвести маленький рассчётик. И так, у нас есть частота работы ЦП 72000000 Гц. Чтобы получился звук нужно чтобы частота отсчётов была вдвое выше максимальной частоты для звука 20000 Гц, это по теореме сами-знаете-кого (не Волан-де-Морта). Часто при кодировании эту частоту берут равной 44100 Гц. И так, делим 72000000/44100. Получаем 1632 с копейками. Это такое максимальное значение мы можем использовать для амплитуды. Возьмём логарифм по основанию 2 и получим 10 бит на отсчёт. Обычно используют 16 бит, но у нас-то нет ЦАП на борту МК, так что придётся довольствоваться восьмибитным звуком (нет, это не звук как из денди), ведь дма не может 10 бит. Либо 8 либо 16 либо 32.
На выходе получится ЦАП, построенный на ШИМ. Частота ШИМ слышна не будет, ведь 44100 Гц мало того, что не слышны ухом, так ещё и обычный динамик так колебаться просто не сможет.
Чтобы всё получилось, в память нужно положить содержимое wav файла с частотой дискретизации 44100 и разрешением 8 бит на отсчёт (аудиофилы закрыли статью). Так как мы делаем испытание алгоритма, а не систему S/PDIF через TOSLINK, то хватит моно звука. Но памяти ОЗУ в stm32f103c8 всего лишь 20 Кб, этого хватит не всем. Примерно на полсекунды музыки. Надо выкручиваться. Тут-то я впервые применил прерывание на половине передачи DMA. Трюк в том, чтобы пока проигрывается первая половина буфера (а его размер может быть небольшим, даже 100 байт хватит) мы заполняем вторую половину, как только проигралась первая половина (а этот момент мы отлавливаем в прерывании половины транзакции) мы начинаем её заполнять новыми данными, ведь в данный момент передаётся вторая половина. В DMA мы включим циклический режим и вуаля! Вполне сносное звучание (точно все аудиофилы ушли?). В конце статьи будет небольшой видосик с демонстрацией.
Как будем передавать данные?
На физическом уровне у меня была пачка китайских лазерных модулей фирмы нонаме, что-то вроде этого (никакой рекламы и реферамы, первая, ладно третья ссылка из гугла по запросу laser diode aliexpress): Лазерные диоды. Подключать их будем через n-канальный мосфет AO3400A. Классные, кстати транзисторы. В корпусе sot23 могут через себя 5 ампер тягать, при этом стоят по рублю. Как же хорошо в современном мире!
Теперь мы можем включать и выключать лазер из программы в контроллере, что ж, никогда не думал, что напишу это на хабре, но пришло время помигать диодом! Мигать будем с использованием USART. В стм32 в усарте есть режим IrDA. Не особо много информации по этому режиму в рефмане, но, по сути, это просто усарт с другим способом кодирования нулей и единиц. И так, нам надо 44100 раз в секунду отправлять по 8 бит, это 352.8 килобит в секунду как минимум, плюс надо ещё оверхеда добавить (алгоритм же), плюс хотелось бы иметь запасик. Короче я остановился на круглом числе в 1 Мбит для усарта. CubeIDE ругается на такую частоту, и не даёт её выставить для stm32f103c8 в режиме IrDA, но он ошибается. Если руками прописать этот бодрейт в коде, то всё прекрасно заводится. При этом, кстати, для stm32f411 это, по мнению куба, вполне нормальная частота.
Метод Рида-Соломона позволяет взять некую конечную последовательность байт, добавить к ней несколько дополнительных избыточных, попортить пару, а затем восстановить. Тут нет описания потоковой передачи. Придётся городить свой метод. Я, кстати, много езжу на велосипедах ну и испытываю некую склонность к их изобретению.
Самый прямой, в лоб, метод – это разбить данные на блоки, закодировать каждый блок и слать их один за одним. если потеряется один или несколько (мало) байт, то они восстановятся. Но если в одном блоке потеряется слишком много данных, или блок будет не принят целиком, то всё, его не восстановить. Когда-то в универе нам рассказывали, и я читал где-то что в CD данные как-то режут перемешивают, и если потеряется какая-то часть подряд, то всё равно всё будет восстановлено. Потому и можно CD поцарапать, а он всё равно будет работать. Чуть-чуть подумав, я решил реализовать такую схему: допустим, у нас есть последовательность байт:

Разобьём их на блоки по 4, добавим к каждому блоку по 2 байта оверхеда и расположим их как таблицу, затем пронумеруем столбцы. Получится вот так:

Теперь мы транспонируем полученную таблицу и опять расположим данные в ряд:

В таком виде и будем слать данные внутри лазерного луча. Теперь если из такого ряда данных пропадёт даже значительная часть подряд, например начиная с D9 и заканчивая D6 то для каждого изначального блока это будет потеря одного или двух байт:


Нумерация новых блоков (столбцов) нужна для того, чтобы на принимающей стороне можно было бы понять какой из столбцов пропал, ведь если мы знаем номер пропавшего столбца, то мы знаем номер символа в блоке данных с избыточным кодом, а это облегчает жизнь алгоритму - можно восстановить больше данных. В аппаратной реализации я использовал блоки по 32 байта плюс 16 байт избыточного кодирования. Эти цифры были подобраны экспериментально чтобы быстродействия процессоров хватало на кодирование-раскодирование-исправление, а также на всю дополнительную работу вроде чтения из флэш и проигрывания звука.
Для того чтобы понимать, что блок (можно называть такие блоки кадрами) принят целиком, я выбрал времннОе разделение кадров. Пауза на время двух байт. Это позволяет приёмнику не путаться, где какой кадр, и собрать назад всю таблицу - назовём её "пакетом". Также можно использовать прерывание USART IDL на приёмнике. Так код писать проще.
Как будем принимать данные?
Здесь в лоб не получилось. У меня не было никаких фотоприёмников в коробочке. Попробовал светодиод приспособить для этих целей – он не справился. Амплитуда микроскопическая на выходе и сигнал сильно смазан. Быстродействия не хватает. Сбегал в местный ЧипДип, купил всё, что у них было в наличии на тему фотоприёмников видимого света: пара разных фототранзисторов и всё. Неудача. Быстродействия не хватает (мегабит, ведь, помним?). Купил фотодиод для инфракрасного света, вот такой. Не обманули. Для инфракрасного излучения работает как положено. На прямой свет красного лазерного диода не реагирует от слова совсем. Но это достигается за счёт пластикового корпуса, который задерживает видимый и пропускает ближний инфракрасный. Хм, у меня ведь есть напильник! Сточил часть корпуса, которая со стороны кристалла,

смотрю на осциллограф - Всё именно так, как и хотелось бы. Амплитуда маленькая, но форма сигнала вполне себе норм. Можно было бы заказать фотодиод для видимого света, конечно же. Но хочется здесь и сейчас. А это напильник.
Дальше. Амплитуда маленькая, а надо, чтобы было 0 и 3.3 В для того, чтобы это подать на ножку контроллера. Плюс смещение, которое меняется в зависимости от внешнего освещения. Придётся аналогово схемотехничить. Если аналогово, то ОУ. Если ОУ, то LM358. Не я это придумал, так повелось испокон веков. Подсоединяю... Ага. Граничная частота единичного усиления 1 МГц. Единичного. А надо в 300 раз увеличивать. Не годится. Чуть получше NE5532P 10 МГц единичного усиления. Пробую, не работает как надо. Пришлось купить подороже LM6172IN. 100 МГц единичного усиления. Уже получше. Для наглядности: форма сигнала на двух последних:
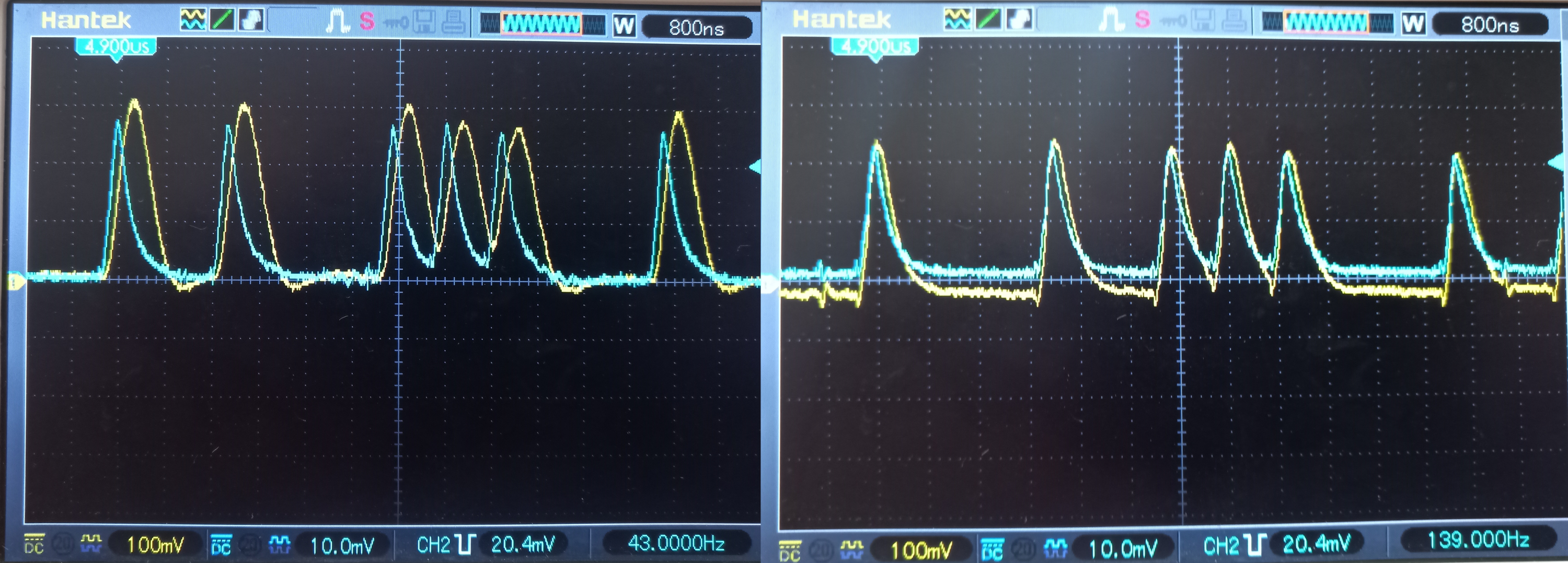
Синий луч – это входной сигнал, жёлтый – выходной после усиления в 10 раз. Слева медленный ОУ, справа быстрый. Ещё в 30 раз усиливает второй каскад. Получаются очень даже прямоугольные, красивые импульсы. Их я не заснял. Также, между каскадами поставил дифференцирующую RC цепочку. Она прекрасно компенсирует внешнее освещение. Работает и в темноте, и на солнце. Ещё нюанс: Этому ОУ нужно двухполярное питание. Его я организовал с использованием ОУ. LM358 опять не справился. Пришлось поставить NE5532P. Схема всего этого безобразия получилась такая:
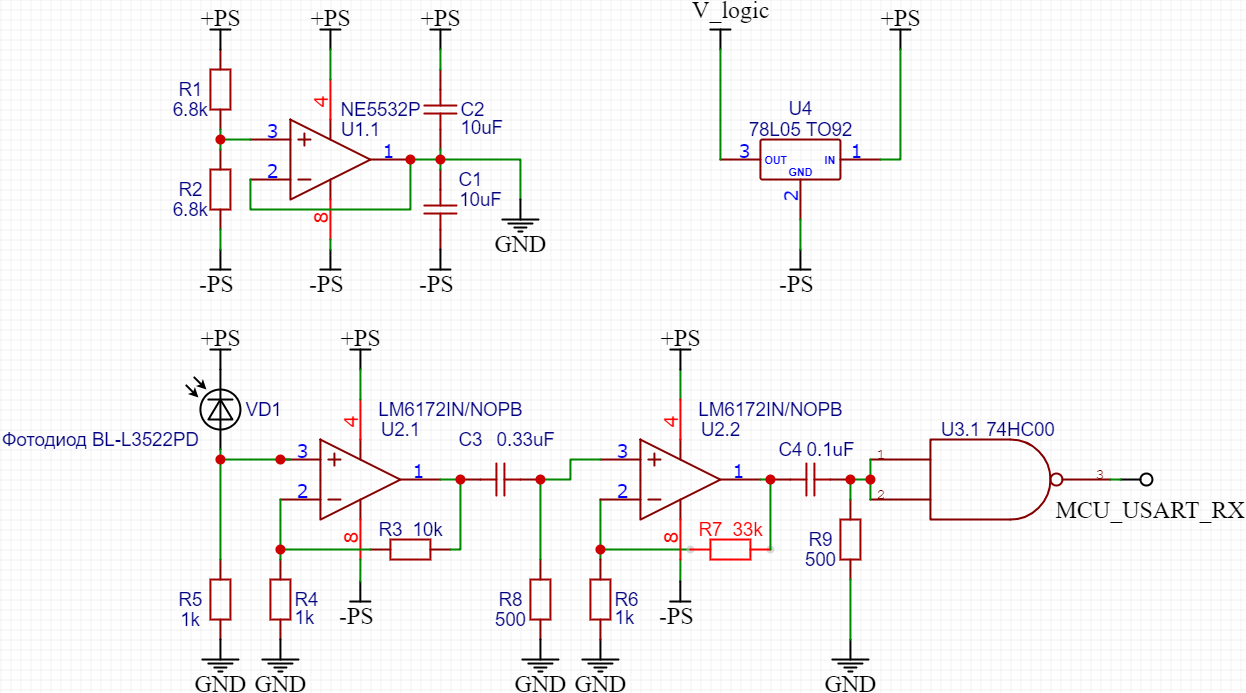
Инвертер на выходе нужен для того, чтобы работал USART в режиме IrDA. Там требуется инверсный сигнал. Для питания логики используется LDO, чтобы согласовать уровни пришлось ещё одну RC цепочку поставить. Конечно, можно было бы соорудить намного более совершенную схему, но эта собралась из того, что есть в коробочке, на бредборде и со своей задачей справляется.
Как будем раскодировать?
Тут всё довольно-таки просто. USART в режиме DMA складывает данные в буфер. По прерыванию IDL данные из этого буфера, согласно своему порядковому номеру (блоки пронумерованы), помещаются в нужное место в пакете. Если вместо номера кадра там какое-нибудь непонятное значение, мы запоминаем номер этого кадра как битый. Как только пакет принят полностью мы его транспонируем и проверяем алгоритмом каждую строку на предмет целостности. Если синдром не нулевой, то исправляем используя всю мощь алгоритма Рида-Соломона. Затем копируем данные без оверхеда в буфер для проигрывания.
Тут возникает небольшая проблемка. Частоты приёмника и передатчика ну никак не совпадают. Обязательно будет небольшая разница. Для разрешения этой проблемы я сочинил такой механизм: Пакеты на передатчике отправляются по мере заполнения. На нём данные идут одновременно и в проигрывание (это при разработке я сначала проигрывание в передатчике организовал) а также в буфер для передачи. Как только набирается целый пакет он кодируется и отправляется. В приёмнике я контролирую, на каком моменте проигрывания буфера приходит новый пакет. При полном совпадении частоты это был бы один и тот же момент для каждого пакета. В грубом и несовершенном мире момент плывёт во времени. Вот эту разницу я задал как вход П-регулятора (софтверного, конечно же). А выход – это скорость воспроизведения на приёмнике. Её можно чуть-чуть регулировать, слегка изменяя период ШИМ, это тот который должен быть с частотой 44100 Гц. Прикольный эффект от этого. Если пакет целиком теряется, то П-регулятор сбивается и начинает ускорять или замедлять звук ненадолго. Эффект похож, как когда в магнитофоне моторчик механизма притормаживаешь чуть-чуть.
Как воспроизводить?
В главе про оцифровку я рассказал метод генерации звука на STM32. На выходе получается ШИМ сигнал с частотой 44100. Его можно просто подключить к динамику или наушнику и там будет вполне себе слышно то, что нужно. Если сильно хочется, то можно поставить RC ФНЧ и развязывающий конденсатор. Дальше делителем можно привести к амплитуде в 1В и отправить на вход усилителя. Мне хочется, чтобы без внешнего усилителя и всё работало. Преимущество такого сигнала в том, что его можно усиливать в ключевом режиме. Вроде бы это называется усилитель D-типа, но это неточно. К выходу усилителя я прицепил опять AO3400A через оптопару (звук опять передаётся через оптику) по такой схеме:

Без оптопары шли помехи на усилитель приёмника. А так работает всё.
Для передающей части у меня бредборда не нашлось, так что она получилась в таком виде:

На принимающей части ещё есть дисплей для отображения статуса приёма. Было сложно сочинить как информативно в реальном времени отображать статус приёма. Остановился на количестве принятых пакетов всего, количестве битых пакетов и количестве битых кадров в последнем битом пакете. Демо видео:
И к чему это всё?
Две пользы. Показать широкой (ага, прям мильёнам) публике, что можно сделать с помощью недорогих, относительно современных микроконтроллеров, и, конечно же, получить бесценный опыт. Довольно-таки много разных технологий задействовано в этом проекте. Исходный код... Да. Вот бывает стыдно позвать гостей в квартиру, когда не прибрано. Так и с исходным кодом этого проекта. Делалось ведь не по работе и не в коммерческих целях, так что извините. Исходники кодировщика Рида-Соломона есть в статьях об алгоритме (ссылки в самом начале). Там на Си шарп, но очень легко портировать на C++. Всё. Спасибо!
Комментарии (32)

VaalKIA
08.01.2022 06:52+2Отличная демонстрация, ещё бы в живую посмотреть модуляцию через шарик.
По поводу последовательности: корректирующие коды расположены целым блоком, и если именно они испорчены, то зафейлится очень большой кусок данных, в этом случае, вы данные выкидываете или играете как есть? Возможно, корректирующие коды тоже надо как-то распределить?
Второй момент, поскольку речь идёт о звуке, а в нём важна скорость изменения, а не абсолютные значения, то, возможно, имеет смысл кодировать уровни кодом, при котором соседние значения изменяются на 1 бит (в обычном счёте 1000 и 0111 соседи, но отличаются на 4 бита), тогда лёгкие помехи не будут сильно искажать амплитуду.
Ну и третий момент: восстановление с помощью корректирующих кодов, тоже может давать ложные данные, хотелось бы статистику, то есть записать принятые данные, а потом сравнить с первоисточником и показать реальную эффективность не только восстановления, но и искажения. Собственно, иначе не было бы такого класса как контрольные суммы, их бы просто вытеснили корректирующие коды, ан нет, не всё так просто.
Ну и ещё один момент, как вы справедливо заметили тайминги приёмника не совпадают с таймингами отправителя, кроме того, среда так же может растягивать или спрессовывать во времени сигнал, поэтому отправив 1111 такое, просто посчитав длительность этого монолитного сигнала, в общем случае, нельзя сказать 111 или 11111 было изначально, для этого каждый бит передаётся сигналом, переходящим через ноль, не зависимо от того, еденица это или ноль, таким образом, обходятся фундаментальные проблемы, которые на первый взгляд не видны.
ruomserg
08.01.2022 07:59+1восстановление с помощью корректирующих кодов, тоже может давать ложные данные, хотелось бы статистику, то есть записать принятые данные, а потом сравнить с первоисточником и показать реальную эффективность не только восстановления, но и искажения
До тех пор, пока интенсивность помехи не превосходит восстанавливающую способность кода — ложные данные получить невозможно. Мы же введением кодов — расширили пространство передаваемых сообщений, при этом большУю часть точек вновь созданного пространства объявили запрещенными. И если принятое сообщение попало в запретную область — то мы своей функцией расстояния на вновь введенном пространстве определим ближайшее корректное сообщение — и к нему скорректируемся.
А если помеха смогла перевести одну корректную точку пространства расширенных состояний — в другую, то у нас либо неправильная модель помехи, либо недостаточна заложенная под модель помехи избыточность кода… Но уж эту проблему довольно легко решить — добавление хеша сообщения (в простейшем случае — CRC16/32) до применения избыточного кода и проверка — после декодирования. Это очень дешевый способ отбрасывать испорченные сообщения (и свалить проблему на протоколы высших уровней...), но никак не помогающий их таки-передавать. А помехоустойчивые коды дают возможность именно протолкнуть сообщение по физическому каналу связи с любыми (!) наперед заданными помехами — при условии, что вы готовы оплатить накладные расходы в виде дополнительных бит данных…
N-Cube
08.01.2022 08:58-3Как выше заметили, в передаче самого кода вероятны ошибки - притом настолько же вероятны, как и в исходном сообщении, так что пользы в данной реализации от кода восстановления немного. Например, если длина кода совпадает с длиной сообщения, то их вероятности повреждения равны, а поскольку хэш суммы в данной реализации нет, то добавление кода удваивает размер сообщения и тем увеличивает вероятность повреждения сообщения с кодом (если вероятность передачи без ошибки исходного сообщения 0.5, то для удвоенного сообщения эта вероятность равна лишь 0.5*0.5=0.25). Автор не посчитал помехоустойчивость для варианта с его кодом восстановления и без него для разной вероятности ошибки, в итоге эта реализация бесполезна и вредна - простое дублирование сообщений с хэш суммой будет работать надежнее (и намного быстрее обрабатываться на передатчике и приемнике). И, кстати, при помехе типа пролетевшей птицы (как в статье предложено) опять же оптимальным будет именно простое дублирование.
ruomserg
08.01.2022 16:54+3Я соглашусь в том смысле, что в задаче-демонстраторе которая решалась — можно обойтись без помехоустойчивого кодирования. Более того, эту задачу можно вообще не решать — и ничего страшного не случится. Если бы автор занялся решением задачи на коммерчески-пригодном уровне — оно было бы намного сложнее: появилась модуляция/демодуляция сигнала, АРУ на приемнике, какое-нибудь квадратурное кодирование для более полного использования пропускной способности канала связи, и тому подобное. И все эти элементы тоже могли бы вносить ошибки в передаваемую информацию. Соответственно, если делать «по-взрослому», то пришлось бы делать мат.модель канала связи и задаваться (или собирать из реальных измерений) модель помехи. И только после этого можно было бы начинать ставить вопрос о способе кодирования…
Однако, бОльшая часть подобных кодов родилась из радиосвязи (или передаче сигнала по проводам) — и имеет в качестве модели помехи статические разряды (молния где-то ударила, рубильник поближе включили и т.д.). Этот вид помех характеризуется малым временем действия, но широким спектром, от которого практически невозможно отстроиться стандартными способами фильтрации сигнала. Собственно, под это вам коды и даны — крайне редкое (по сравнению с временем передачи пакета) событие, необратимо меняющее некоторое количество бит в одном пакете. Соответственно, вы задаетесь средней длительностью static event, делите ее на скорость передачи — и получаете количество бит, которые будут испорчены. И выбираете код с нужной корректирующей способностью.
Если же вы полагаете, что увеличение длины сообщения увеличивает и вероятность его повреждения, и поэтому коды в пределе перестают работать — то это заблуждение. Теорема Шеннона утверждает, что для канала с помехами всегда можно найти такую систему кодирования, чтобы снизить веротяность ошибочного декодирования передаваемой информации до любой бесконечно малой величины. Потому что добавление одного бита избыточности — увеличивает длину сообщения, собственно, на один бит — но удваивает размерность пространства сообщений. В пределе — размерность пространства (и восстанавливающая способность) будет расти невообразимо быстрее, чем вероятность появления второго static event во время передачи удлиненного пакета.
Также, нельзя считать, что обнаружение и исправление ошибок всегда можно переложить на протоколы верхних уровней. В некоторых случаях, на объекте вообще может быть только приемник. Или, как в дальнем космосе — передатчик есть, но использовать его дорого с точки зрения расхода бортовых ресурсов, да и задержка… Или цена неправильной дешифровки сильно велика (например, у военных). Или верхний протокол уже не может учесть особенности канала связи…
В общем, мое мнение — коды коррекции ошибок нужно уметь для общего развития. И осваивать их легче на игрушечных задачах. Собственно, про уровень лабораторной работы в комментариях уже неоднократно говорилось. Я склонен такое творчество поддерживать — оно дает понимание не на уровне прочтенного учебника, и не на уровне списанной методички, а реально через руки. И это уже надолго…

av-86 Автор
08.01.2022 10:52По поводу первого пункта: если портятся коды коррекции то алгоритм работает также, как если бы портились сами данные - в статьях про это есть.
По поводу способа передачи, то была важна не передача звука, а проверка-демонстрация работы алгоритма
По поводу ложных восстановлений - в статьях о кодировании есть расчёт вероятности такого события. Она ничтожна. Корректирующие коды в отличии от контрольных сумм требуют довольно-таки немалого вычислительного ресурса.
По поводу NRZI, о котором вы упомянули, эта мысль мне тоже пришла в голову. Только вот реализация подкачала. В STM32 нет NRZI выхода. Я попробовал сфтверно его реализовать, но скорости выше 100КБит таким способом не добьёшься, а надо Мегабит.
N-Cube
08.01.2022 11:40-3Вы никак не поймете, что вероятность повреждения данных пропорциональна их размеру, так что эта вероятность для последовательности из данных плюс (в статье - почти такой же длины) кодов восстановления намного выше, чем вероятность порчи только данных. Поскольку без хэш суммы нельзя определить, что именно повреждено, то применение поврежденных данных и/или кодов восстановления в любом случае портит результат. Это и есть причина, почему на практике не делают длинных кодов восстановления и добавляют хэш сумму данных. Еще раз - посчитайте помехоустойчивость в зависимости от длины кода восстановления и сравните с помехоустойчивостью без кодов и с дублированием сообщения при наличии хэш суммы.

Sun-ami
08.01.2022 09:54-1Остался без ответа важный вопрос — сколько нужно выделить МГц stm32f103 и stm32f411 для кодирования и декодирования такого аудиопотока в 41кбайт/с? В статьях про кодирование Рида-Соломона, на которые в этой статье есть ссылки, тоже нет ответа на этот вопрос. И почему применены параметры кодирования с такой большой избыточностью, аж 75%, что не намного лучше, чем простой простой повтор пакета с CRC — метод, который, конечно даст корректирующую способность похуже, но при этом намного проще? Интересно было бы посмотреть на измерения вычислительной нагрузки на STM32 для кода Рида-Соломона и избыточностью около 30%.

nixtonixto
08.01.2022 11:30+1Инвертер на выходе нужен для того, чтобы работал USART в режиме IrDA
Поменяйте местами VD1 и R5, и инвертор с ЛДО станет не нужен. Или подавайте сигнал на инверсный вход второго операционника.
Serge78rus
08.01.2022 13:26+3А еще лучше анод фотодиода подключить к инвертирующему входу ОУ, неинвертирующий вход заземлить, а R4 и R5 выкинуть, тем самым превратив этот каскад усилителя в преобразователь тока в напряжение. Это значительно улучшит АЧХ фотодиода. Возможно при этом потребуется подобрать R3, чтобы ОУ не входил в ограничение при максимальной освещенности фотодиода.

belav
08.01.2022 15:45Да и не понятно, зачем в каждом каскаде усиливать постоянную составляющую, что бы её потом срезать разделительным конденсатором?
av-86 Автор
08.01.2022 15:55Это я попробую, спасибо! Ведь точно знаю, что усиление можно сделать намного более эффективным, ведь в системах с инфракрасным пультом всё работает с намного более слабыми сигналами, а не направленным лучом.
Serge78rus
08.01.2022 20:19В пультах ДУ используется не прямая модуляция ИК сигнала передаваемой информацией, а дополнительная несущая (обычно 38 кГц), которая уже в свою очередь модулируется кодом Манчестера (или чем нибудь подобным) с самосинхронизацией и подавлением постоянной составляющей. Но и скорость передачи информации там примерно на три порядка ниже, чем у Вас.

VT100
09.01.2022 13:35И, до кучи, — ещё по схемотехнике:
Для питания логики используется LDO
FTGJ — 78L05 ни разу не LDO.
К выходу усилителя я прицепил опять AO3400A через оптопару (звук опять передаётся через оптику) по такой схеме:
Без оптопары шли помехи на усилитель приёмника.Странная схема…
ШИМ — без фильтра. Может поэтому и помехи? Или из-за самоиндукции на обмотке динамика?
Затвор N-канального(?) полевика намертво на плюсе. Но что-то пытается на него податься через оптрон и резистор аж в 1 кОм.av-86 Автор
09.01.2022 14:16+1Про затвор - это результат подхода "сначала макетка - потом схема")) Ошибся, когда картинку рисовал Это я поправлю. LDO, конечно же, означает в первую очередь Low drop, но сейчас эту аббревиатуру используют для любого линейного понижающего модуля.

xael
08.01.2022 12:45В передаче данных с помощью (А)DSL точно такой же трюк - транспонирование матрицы с данными дополненной кодами, используется.

belav
08.01.2022 15:39Идея статьи интересна, хоть и не нова. Но все портит то, что суть статьи не подтвердить/опровергнуть теорию, а изобретение велосипеда и ходьба по граблям.
Хотя бы для интереса посмотрите как реализовано это в обычных cd проигрывателях. Начиная от кодирования, заканчивая схемотехникой.

vlad-ss
08.01.2022 15:43Интересный макет. Действительно, как лабораторная был бы интересен. :)
Как я понимаю, вы использовали код (6, 4) над полем GF(2^8) и перемежение при передаче?
Ну и ещё несколько вопросов/комментариев для уточнения:
1. Почему был выбран именно (6, 4)?
2. Я правильно понимаю, что для декодирования вы использовали Берлекемпа из предыдущей статьи? Не думали про Питерсона (ПГЦ, PGZ)? Для кода, исправляющего одну ошибку, он, как мне кажется, проще и быстрее.
3. Раз уж вы всё равно собираете данные в таблицу, можно было бы использовать каскадный код — кодируем и по строкам, и по столбцам.
4. Не думали про коды над более коротким полем? Тем же GF(2^4). При том же общем битовом размере получился бы код (12, 8) с исправлением не одной 8-битовой, а двух 4-битовых ошибок (символьных, конечно же, а не произвольных). Декодер и кодер чуть сложнее (надо дополнительно бить каждый байт на два символа), зато умножитель проще.av-86 Автор
08.01.2022 16:06Не совсем так. (6, 4) - это для наглядности в статье. Реально использую (48, 32) это максимум, на который хватает быстродействия. Для декодирования - да. Берлекэмп. Какая-то из эффективных реализаций. Если делать блоки меньше, то пропадает выигрыш от использования dma при приеме-передаче. Так или иначе у меня теперь есть код, который можно применить, если вдруг понадобится что-нибудь избыточно закодировать. Например rs485 между какими-нибудь промышленными блоками. Там резкая случайная помеха не редкость.
vlad-ss
08.01.2022 18:14Реально использую (48, 32) это максимум, на который хватает быстродействия.
Тогда не очень понял. Вы сейчас рассматриваете код как битовый, т.е. n=(6*8=48 бит) и k=(4*8=32 бита), или символьный, т.е. n=48 байт (символов конечного поля GF(2^8)) и k=32 байта?av-86 Автор
08.01.2022 18:26Второй вариант, 32 полезных, 16 избыточных, всего 48.
vlad-ss
08.01.2022 18:35Понял. Ну тогда вполне серьёзный код с исправлением 8 ошибок получается. Тут действительно лучше всего Берлекемп.
Хм. Даже не думал, что STM такой код потянет с приличной производительностью.
А умножитель делали логарифмический табличный через два предварительно рассчитанных массива и операции с памятью?av-86 Автор
08.01.2022 18:51Логарифмы, естественно. Конечно можно было бы 65536 байт выделить и ещё чуть ускорить. Память f411 позволяет. И да, не 8 ошибок, а больше, ведь я могу ещё ориентироваться на номер битого кадра, если, например, мне приходит кадр с номером 21, а за ним номер 25, то я могу стопроцентно сказать, что во всех кадрах после транспонирования байты с 22 по 24 битые
vlad-ss
08.01.2022 18:59Логарифмы, естественно.
Понял. Если память позволяет — удобно, да. Ещё, если будет интересно, обратите внимание на алгоритмы Рейхани-Мазолеха и Карацубы. При дефиците аппаратной памяти для программы могут быть полезны.не 8 ошибок, а больше...
Это да. Я чисто по коду имел в виду.
mister_pibodi
08.01.2022 16:04ещё в пятом классе догадался приделать солнечную батарейку от поломанного калькулятора к микрофонному входу батиного усилка. А модулировал свет лазерной указки отражая его от мыльной плёнки. Говоришь в мыльный пузырь и слышишь свой голос
А вот про это можете поподробнее рассказать, пожалуйста? Там лазер отражается от пузыря, который колеблется от звука голоса? Полностью отражается на солнечную панель или часть проходит/преломляется через пузырь, вот эту часть не могу представить. У этого есть какое то название чтобы можно было найти в интернетах или чисто Ваша детская забава?
av-86 Автор
08.01.2022 16:16+1К сожалению, мой пятый класс был довольно-таки давно. Тогда не было у меня ни интернета не компа -- развлекался чем мог)) Из-за того, что поверхность мыльной плёнки искажается под действием звука, то меняется форма и площадь отраженного пятна лазера, а так как меняется площадь, то меняется и интенсивность. Работает всё тем лучше, чем дальше детектор от пузыря. Но сколько-нибудь заметно плёнку искажают лишь низкие частоты потому и звук получался как из .. ну неважно. Похожий трюк проделывал Дастин с канала smarter every day. Там он снимал колебание чего-то лёгкого на очень высокоскоростную камеру, а затем из видео звук извлекал.

nnstepan
08.01.2022 22:00Спасибо, вспомнил детство, когда брал в библиотеке радиоежегодники и читал про устройство CD и DAT.

sim2q
09.01.2022 03:47А раньше линки на указках между домами поднимали. В связи с новыми реалиями, копеешные mesh сети из окна в окно.
fk01
09.01.2022 17:53+1Вот именно звук не слишком чувствителен к единичным ошибкам, если его передавать не в PCM (Pulse Code Modulation), а в унарном коде PDM (Pulse Density Modulation), что используется практически всеми цифровыми микрофонами сейчас. Единичные сбойные единички, а в унарном коде весь любой единички одинаков (в отличии от PCM) не будут слышны на слух (а в PCM вес отдельных битов очень высок, так что ошибка прослушивается как щелчок). И собственно получается, помехоустойчивое кодирование не очень-то и нужно. Равно как не нужны сложные ЦАП и АЦП, достаточно дельта-сигма преобразования, и при этом обеспечивается очень высокое качество звучания. Если вообще стояла бы задача обеспечения лазерной связи для передачи звука -- стоило бы выбрать PDM, а не FEC (Forward Error Correction) и PCM. Да, частота модуляции порядка единиц МГц. И такую систему можно построить без микроконтроллера вообще!
Однако если говорить о занимаемой ширине полосы, то конечно PDM -- это сильная избыточность. И PCM + FEC тут смотрятся гораздо лучше (нужны не мегабиты в секунду, а всего лишь сотни килобит). И кроме того, FEC может помогать от условно длительных помех. Но здесь скорей нужен скорей не BCH-код, а код Соломона-Рида вычисляемый для относительно больших блоков памяти. Либо фонтанное кодирование и попросту контрольная сумма для блоков.
И совершенно зря N-Cube забанили, это факт приводимый в любой литературе, что сколько-нибудь длинные коды действительно бесполезны, т.к. вероятность ошибки растёт пропорционально длине блока. И есть так называемый предел Шеннона, который не позволит передать никакую информацию при соотношении Eb/N0 (отношение энергетики бита к шуму) менее чем -1.6дБ, хоть как ни кодируй. И это очень теоретический предел, практические каналы связи редко опускаются ниже 10dB. Не следует только путать Eb/N0 и SNR, так как последний измеряет амплитуду несущей к уровню шума, и она может быть много ниже уровня шума по-амплитуде, но не по энергетике бита (почему GPS работает с такими слабыми сигналами -- они на самом деле не слабые, но размазанные по широкому спектру, и слаба только амплитуда, а энергия, как интеграл, за счет ширины спектра там больше 10дБ).
Кодом достаточно близко приближающимся к пределу Шеннона является так называемый код Голея, используемый в космических аппаратах "Вояджер".
И выше кто-то в комментариях заметил, и мне тоже хочется подчеркнуть, что в таких системах встаёт задача синхронизация потоков, либо тактовых генераторов, передатчика и приёмника. Потому, что если каждый из них работает от своего, не синхронизированного тактового генератора, то приёмник будет воспроизводить чуть медленей, или чуть быстрей передатчика, и за несколько минут это опустошит и переполнит буфер, и начнутся заикания. Вслучае приёмника на микроконтроллере, наверное проще всего подстроить генератор приёмника под скорость входящего потока. Если такое невозможно, то нужна передискретизация принятого PCM-кода с частоты дискретизации передатчика на частоту дискретизации приёмника. Это может быть, условно, 44101 и 43099 герц, но эта мельчайшая разница, если передискретизацию не делать, накопится и начнутся заикания. Смешно сказать, но часто программисты этой проблемы не понимают и в таких продуктах как ALSA и/или mplayer эта проблема местами присутствует во всей красе.
ru_vlad
Неплохо. Можно в качестве лабораторной для студентов или старших школьников прменить, возьму на воружение.
VioletGiraffe
Эх, были бы у меня в универе такие лабораторки… А специальность была как раз такого профиля, как и весь ВУЗ.