
Данный текст является авторским переводом поста A Scalable Approach for Partially Local Federated Learning.
Примечания:
Меня довольно сильно интересует тема распределенного обучения ML моделей и в свободное время стараюсь изучать материалы, связанные с этой темой. Материалов не так уж и много, на самом деле, поэтому любая новая публикация на эту тему привлекает внимание. И 16 декабря в блоге Google AI был опубликован новый пост на эту тему, в котором авторы описывают новый подход к Федеративному обучению и я решил перевести его на русский язык, надеясь, что кому-нибудь этот материал так же может показаться интересным.
Для тех, кто не сильно знаком с этом темой, хочется сделать несколько вводных пояснений. Federated Learning (далее FL для сокращения) (так называется совокупность методов обучения ML моделей на распределённых данных) в общем то изначально драйвится Google и поддерживается в наборе инструментов TensorFlow. Почему именно Google? Дело в том, что FL решает следующую проблему: в стандартных подходах ML все базируется на том, что все данные, необходимые для обучения, доступны в рамках единого пространства памяти (централизованы на одном сервере/кластере), но есть много случаев, когда по соображениям конфиденциальности (связанными как с коммерческой тайной, так и с вопросами privacy и защиты пользовательских данных) мы не можем все данные скопировать в единое хранилище. Вот FL и предлагает различные методики обучения, которые позволяют натренировать модель без централизации данных. Google с этой проблематикой сталкивается потому что является разработчиком мобильной операционной системы Android, многие функции которой требуют применения ML подходов. В частности, у них есть приложение GBoard - это мобильная клавиатура, которая подсказывает пользователю следующее слово в набираемой фразе, тем самым позволяя экономить время пользователю при наборе текста. Для того, что бы натренировать предсказательную модель, требуется обработка текстов, которые пользователи вводят в рамках переписки в мессенджерах и т.п., и тут как раз и возникает проблема работы с приватными данными. Поэтому надо еще раз подчеркнуть, что текст ниже и прочие публикации Google на эту тему следует воспринимать в контексте именно этой проблематики, хотя подобные методы можно применять и в большом количестве других кейсов.
Так же должен отметить, что в данном тексте не в полной мере раскрываются особенности самих предлагаемых методов. Для того, чтобы детально с ними ознакомиться, надо уже погружаться в публикации, которые указаны в ссылках в тексте. Данные публикации, думаю, изучить отдельно и, по возможности, подготовить отдельные переводы, поэтому оставляю текст в общем-то так, как его написали авторы - краткий обзор и анонс данных методов.
Собственно “Масштабируемый подход к частично локальному федеративному обучению“
Проблематика
FL позволяет пользователям обучать ML модели без централизации всех исходных данных на одном сервере, что позволяет избежать необходимости сбора и обработки приватных и персональных данных. При классическом подходе FL проводится обучением единой (глобальной) модели для всех пользователей, даже в случае, если у разных пользователей разное распределение (distribution) в данных. Например, пользователи приложений типа “мобильная клавиатура” могут участвовать в обучении единой модели, которая предсказывает следующее слово, но иметь разные варианты для таких предсказаний. Имеется ввиду, что каждый пользователь немного по-разному выражает в тексте одну и ту же мысль и использует разный словарный запас. Отражение этих различий требует от алгоритма предсказания возможности персонализации глобальной модели для каждого отдельного пользователя (см статью Federated Evaluation of On-device Personalization https://arxiv.org/pdf/1910.10252.pdf).
Тем не менее настройки приватности на стороне каждого пользователя могут препятствовать обучению полностью глобальной единой ML модели. Например модели, работающие с пользовательскими embeddings (я так пока и не придумал достойного перевода этому термину, поэтому буду надеяться, что он знаком читателю и буду писать его в оригинале), такие как matrix factorization models для рекомендательных систем, для обучения единой глобальной ML модели требуют отсылку на сервер пользовательских embeddings, которые потенциально могут быть декодированы, что может привести к раскрытию какой-то чувствительной информации о пользователе. Даже для моделей, которые не используют пользовательские embeddings, остается проблема персонализации параметров модели (https://towardsdatascience.com/parameters-and-hyperparameters-aa609601a9ac) которая должна быть полностью локальна и выполняться на устройстве пользователя, что, одновременно, приводит к минимизации обмена данными между пользовательским устройством и сервером (ну поскольку мы реже передаем полный набор параметров модели от сервера к клиенту и обратно, после их модификации на клиенте) и позволяет персонализировать эти параметры для каждого отдельного пользователя (см Communication-Efficient Learning of Deep Networks from Decentralized Data https://arxiv.org/abs/1602.05629).
Рассмотрим схему:
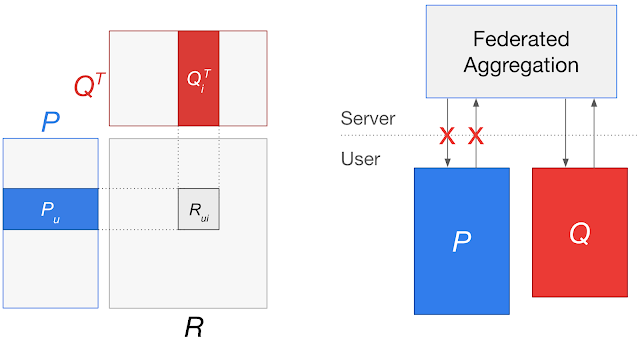
На данной схеме:
Слева - matrix factorization model между матрицами пользователей P и матрицей рекомендуемых элементов Q. Модель для каждого embedding пользователя и embedding элемента определяет рейтинг соответствия элемента пользователю R.
Справа - В случае использования подхода федеративного обучения для обучения единой глобальной модели требуется передача пользовательских embeddings на сервер, что может привести к утечке пользовательских данных.
В работе “Federated Reconstruction: Partially Local Federated Learning” (https://arxiv.org/abs/2102.03448), которая была представлена на конференции NeurIPS 2021, авторы представили новый подход к частично локальному федеративному обучению Federated Reconstruction, при котором параметры модели не агрегируются на едином сервере в рамках обучения единой глобальной модели. Для matrix factorization этот подход позволяет обучить рекомендательную модель сохраняя каждый пользовательский embeddings локально на устройстве каждого конкретного пользователя. Для других типов моделей этот подход позволяет частично обучать модель локально, без передачи чувствительных параметров на сервер. Авторы встроили данные подходы в приложение GBoard, в котором делается предсказание следующего слова для сотен миллионов пользователя мобильной клавиатуры, а также выпустили TensorFlow Federated tutorial с демонстрацией примера использования подхода Federated Reconstruction (https://arxiv.org/pdf/2102.03448.pdf).
Federated Reconstruction
Предыдущие подходы в частично локальном федеративном обучении использовали алгоритмы с сохранением состояния, которые требовали использования устройства для сохранения состояния между раундами федеративного обучения. Конкретно, требовалось сохранять значения параметров модели между раундами. В дополнение, эти алгоритмы имели тенденцию к деградации на больших масштабах федеративного обучения. В этих случаях большинство пользователей по факту не участвовало в процессе обучения модели, а те пользователи, которые участвовали, принимали участие только ограниченное количество раз (а то и единожды), что приводит к состоянию параметров, которое вряд ли отражает пользовательские предпочтения и может быстро устаревать в раундах обучения. Таким образом пользователи, которые не участвовали в обучении модели, остаются без натренированных параметров, что в общем то не очень полезно в сточки зрения практического применения натренированной модели (Adaptive Federated Optimization https://arxiv.org/abs/2003.00295).
Federated Reconstruction это алгоритм без сохранения состояния который не требует использования пользовательского устройства для хранения значений параметров модели, реконструируя их в момент необходимости. Когда пользователь принимает участие в обучении, перед тем как изменить любые глобальные параметры модели они случайным образом инициализируют и тренируют свои локальные параметры с использованием алгоритма градиентного спуска при неизменных глобальных параметрах. Затем они могут рассчитать обновления глобальных параметров с замороженными локальными параметрами. Раунд обучения федеративной реконструкции изображен ниже.

Модели подразделяются на модели с глобальными и локальными параметрами. Для каждого раунда федеративного реконструктивного обучения:
Сервер отсылает глобальные параметры g модели каждому пользователю i
Каждый пользователь i фиксирует глобальные параметры g и реконструирует свои локальные параметры li
Каждый пользователь i фиксирует свои локальные параметры li и проводит апдейт глобальных параметров g, получая новый сет глобальных параметров gi
Все пользовательские глобальные параметры gi усредняются для получения новых единых глобальных параметров g, которые используются в следующем раунде обучения
При этом шаги 2 и 3 выполняются для локальных данных пользователя
Этот простой подход позволяет избежать проблем, которыми страдают предыдущие методы FL. Он не предполагает, что у пользователей есть сохраненное состояние параметров из предыдущих раундов обучения, что позволяет проводить крупномасштабное обучение на большом количестве пользователей, а локальные параметры всегда заново восстанавливаются, предотвращая необходимость сохранения состояния параметров между раундами. Пользователи, “скрытые” во время обучения, по-прежнему могут получать обученные модели и делать инференс, просто реконструируя локальные параметры, используя свои локальные данные.
Федеративная реконструкция позволяет обучать более эффективные модели для “скрытых” пользователей, по сравнению с другими подходами. Для задачи матричной факторизации со “скрытыми” пользователями подход значительно превосходит как централизованное обучение, так и базовое федеративное усреднение (Communication-Efficient Learning of Deep Networks from Decentralized Data https://arxiv.org/abs/1602.05629).

Среднеквадратическая ошибка (чем меньше, тем лучше) и точность для задачи матричной факторизации с невидимыми пользователями. И централизованное обучение, и федеративное усреднение (FedAvg) отправляют чувствительные к конфиденциальности пользовательские embeddings на центральный сервер, в то время как федеративная реконструкция (FedRecon) позволяет этого избежать.
Эти результаты можно объяснить связью с метаобучением (т. е. обучением обучению); Федеративная реконструкция обучает глобальные параметры, что приводит к быстрой и точной реконструкции локальных параметров для невидимых пользователей. То есть Federated Reconstruction “учится обучать” локальные параметры. На практике мы наблюдаем, что всего один шаг градиентного спуска может привести к успешной реконструкции даже для моделей с примерно миллионом локальных параметров.
Федеративная реконструкция также позволяет персонализировать модели для разнородных пользователей, одновременно уменьшая передачу параметров модели — даже для моделей без пользовательских embeddings. Чтобы оценить это, авторы применили федеративную реконструкцию для персонализации языковой модели предсказания следующего слова и наблюдали существенное повышение качества предсказания модели, достигая точности наравне с другими методами персонализации, несмотря на сокращение коммуникации между клиентами и серверами в процессе обучения. Федеративная реконструкция также превосходит другие методы персонализации при выполнении на фиксированном уровне коммуникации (я так понимаю имеется ввиду полная передача всех параметров между сервером и всеми пользователями).

Точность и уровень коммуникации между сервером и клиентом для задачи прогнозирования следующего слова без пользовательских embeddings. FedYogi сообщает все параметры модели, в то время как FedRecon избегает этого.
Реальное развертывание в Gboard
Чтобы проверить практичность федеративной реконструкции на больших масштабах, авторы реализовали данный алгоритм непосредственно в приложении Gboard - мобильном приложении клавиатуры с сотнями миллионов пользователей. Пользователи Gboard используют “выражения” (например, GIF-файлы, стикеры) для общения с другими пользователями. Пользователи имеют очень разнородные предпочтения для этих “выражений”, что делает этот параметр подходящим для прогнозирования с помощью матричной факторизации.

Авторы обучили модель матричной факторизации на совпадениях пользовательских выражений с помощью федеративной реконструкции, сохраняя пользовательские embeddings локальными для каждого пользователя Gboard, что привело к увеличению CTR на 29,3 % для рекомендаций по выражениям. Поскольку большинство пользователей Gboard были “скрыты” во время федеративного обучения, федеративная реконструкция сыграла ключевую роль в этом развертывании.
Дальнейшие исследования
Авторы представили федеративную реконструкцию, метод частично локального федеративного обучения. Федеративная реконструкция обеспечивает персонализацию для разнородных пользователей, сокращая при этом передачу конфиденциальных параметров. Они расширили функциональность Gboard в соответствии с положениями “Принципов искусственного интеллекта” Google, улучшив рекомендации для сотен миллионов пользователей.
Для погружения в технические детали федеративной реконструкции для матричной факторизации смотрите руководство по TensorFlow Federated Tutorial (TensorFlow Federated tutorial). Авторы также выпустили библиотеки TensorFlow Federated общего назначения (general-purpose TensorFlow Federated libraries) в открытый доступ с исходным кодом для проведения экспериментов (open-source code for running experiments).
Авторы:
Karan Singhal, Hakim Sidahmed, Zachary Garrett, Shanshan Wu, Keith Rush, and Sushant Prakash co-authored the paper. Thanks to Wei Li, Matt Newton, and Yang Lu for their partnership on Gboard deployment. We’d also like to thank Brendan McMahan, Lin Ning, Zachary Charles, Warren Morningstar, Daniel Ramage, Jakub Konecný, Alex Ingerman, Blaise Agüera y Arcas, Jay Yagnik, Bradley Green, and Ewa Dominowska for their helpful comments and support.
Отдельное спасибо Вадиму Татарницеву за вычитку и дополнения материала :)
AzIdeaL
Прикосновение к таинствам CDO: волшебство, очень трудно заходящее. Очень.