
В Ozon поступают сотни тысяч заказов в день — при таком масштабе у пользователей неизбежно возникают очень разнообразные вопросы, которые они пишут в чат поддержки: как оплатить баллами «Спасибо», как вернуть не понравившуюся кофту или есть ли доставка в Норильск. При этом большинство вопросов в поддержку однотипны, а ответа пользователи ожидают мгновенно и в любое время суток.
Чтобы отвечать на все эти вопросы, в Ozon есть несколько тысяч сотрудников КЦ в Твери и Тамбове, но даже при таком количестве специалистов им нужна помощь, в первую очередь по ответам на часто повторяющиеся вопросы. И самое очевидное решение — автоматизация с помощью чат-бота.
Меня зовут Михаил Волков, и я руковожу разработкой платформы чат-ботов и сегодня расскажу, как мы измеряем их качество работы и улучшаем взаимодействие наших чат-ботов с пользователями. Посмотрим на это с нескольких разных сторон и постараемся понять, какой из существующих подходов более эффективный.

Автоматизация нам поможет
Чат-бот на службе коммерции — это не простой веб-чат, это больше коммуникационная платформа, которая автоматизирует общение между пользователем и КЦ. А любая автоматизация должна решать проблемы пользователя быстрее, точнее и удобнее, чем оператор. Правда, есть две задачи, которые чат-бот решить не может (да и не должен), потому что это задачи человека:
Когда люди пишут специально для того, чтобы поругаться. С ботом ругаться глупо, ведь намного интереснее — с человеком-оператором. Поэтому такие пользователи с чат-ботом не разговаривают.
Позвонить курьеру. Иногда пользователи хотят, чтобы оператор позвонил курьеру и что-то у него спросил или уточнил. Сам чат-бот, конечно, может позвонить курьеру, но объяснить, что от него нужно пользователю, пока не умеет.
Чат-бот знает про пользователя примерно то же самое, что оператор КЦ, то есть, фактически всё, что нужно для решения проблемы. Но мы поставили себе сверхзадачу — решать проблему пользователя до того, как он ее сформулировал. Допустим, уже 19:05, а до 19:00 к получателю должен был приехать курьер. Становится понятно, о чем будет вопрос, а значит — в чат-бота можно быстро подтянуть информацию о курьере и рассказать пользователю, что с ним случилось (если это записано в системе).
Как определить, насколько качественно чат-бот помогает нашим пользователям и как хорошо он в принципе работает?
Хорошо ли работает наш робот?
Если в среднестатистической IT-компании поспрашивать, кто у них отвечает за качество, то самым популярным ответом будет — тестировщики. В некоторых компаниях процент таких ответов дойдет до ста.
Согласно ISO/IEC TR 19759:2005 тестирование программного обеспечения — это процесс исследования и испытания программного продукта, чтобы проверить соответствие между реальным поведением программы и её ожидаемым поведением на конечном наборе тестов.
Ожидаемое поведение нашего бота: он должен быть живой, дружелюбный, но серьезный и ориентированный на решение бизнес-проблем. Должен отвечать быстро и по делу. Совершенно непонятно, насколько это можно протестировать и можно ли вообще обойтись тестированием, чтобы определить, насколько наш бот качественно работает.
Ответ на этот вопрос спорный и не очевидный, хотя есть много известных подходов. Мы можем собрать фидбек. Например, прислать сообщение: «Оцените, как вы пообщались, всё ли было нормально?» после завершения диалога. Но есть нюанс. По опыту на это сообщение отвечает примерно 10% пользователей и, как правило, они не репрезентативны. Обычно человек не будет писать отзывы или оценивать после того, как уже решил свою проблему. Продолжают общение люди, которые настроены поругаться. Если ориентироваться только на таких пользователей, то мы быстро зайдём в тупик.
При этом не стоит забывать, что наши пользователи — это не только покупатели Ozon, которым мы помогаем решать проблемы, но и сама компания. Например, у менеджеров есть свои требования к боту.
Кроме того, наши пользователи — это операторы, которым мы тоже помогаем в их работе:
Уменьшаем рутину — снимаем с операторов однообразные вопросы.
Снижаем время обработки тикета: бот анкетирует клиента и оператор, посмотрев на переписку, сразу понимает в чём проблема и даёт однозначный ответ.
Улучшаем метрики оператора благодаря классификации и предклассификации. За счёт того, что мы в ходе диалога ставим метки, то в случае перевода чата на оператора мы можем отправить его сразу на нужного специалиста, который «шарит за определенную тему». Для бота это создаёт возможность дать релевантный ответ пользователю, если классификация была верная.
Понятно, что мы собираем фидбэк со всех трёх сфер, но анализировать его непросто. Например, операторы могут жаловаться, что «бот ворует оценки 24/7» (и операторы, и бот получают оценки от пользователей по итогам диалога, и иногда их сложно разделить) или что «ПВЗ — так не пишем!» (действительно, «пункт выдачи заказа» нужно писать без сокращений).
Обеспечение качества
Обеспечение качества в чат-боте похоже на слоёный пирог. У него есть несколько уровней.
Уровень 0: девопсы
Как только у нас разработчик деплоит заглушку абсолютно любого сервиса, он автоматически получает мониторинг, алертинг, трейсинг, централизованное логирование и непрерывную интеграцию:
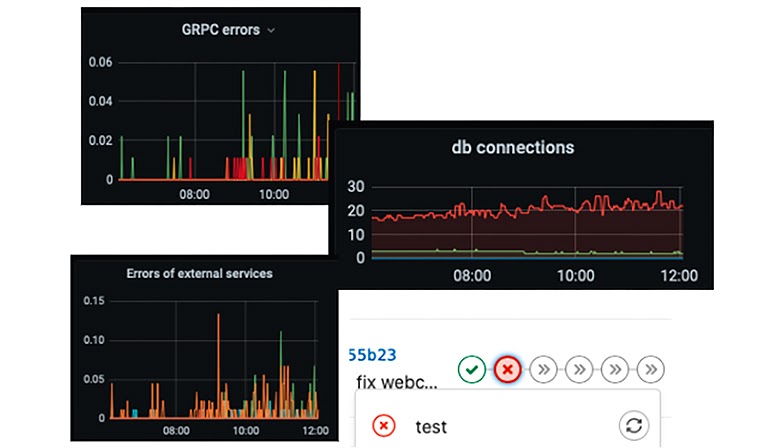
Такие графики показывают, что наш сервис запущен, отвечает пользователям, не слишком сильно грузит базу. Что тесты упали мы тут тоже увидим. Это действительно важная задача — понимать, что сервис в принципе работает и выдаёт ответы на запросы, допустим, в 95% случаев.
Вернёмся к тестированию: чтобы взглянуть на него изнутри, давайте обратимся к самим тестировщикам. Мы сейчас проводим много собеседований по этому направлению. Кроме простых задач: «Давайте напишем что-то на pytest и протестируем API», я стараюсь понять, как тестировщики понимают предназначение своей работы, каковы их функции, где они начинаются и заканчиваются.
Пример:
Вопрос: В чём вы видите смысл работы тестировщика?
Ответ кандидата: Тестировщик должен рассказать разработчикам, хорошо ли работает их код.
Я представил себе тестировщика, который приходит и рассказывает, что здесь плохо, здесь плохо, а здесь хорошо. В принципе, где-то это так и есть. Но интересно, можно ли сделать тестирование более эффективным?
Реплика кандидата: Тестировщик должен помогать разработчикам улучшать процесс работы и подсказывать пути оптимизации.
Вопрос-добивка: А расскажите о самом интересном случае, когда вы улучшили процесс разработки у себя в команде?
Кандидат: <вздыхает>
Так мы переходим к обеспечению качества следующего уровня.
Уровень 1: программисты
Программисты по идее должны писать качественный код. В конце концов, для этого их нанимают. Но что такое качественный код? Как понять, что Вася плохой кодер, а Петя — хороший? Для этого нужны качественные практики программирования.

У наших программистов минимальная задача по обеспечению качества чат-бота в том, чтобы код делал то, что написано в таске в Jira. Но это не всегда просто, поэтому есть большой соблазн поручить контроль над программистами роботам: цифрам и метрикам. Например, ввести метрики качества кода:
покрытие тестами;
цикломатическая сложность;
количественные метрики разного рода, которые позволяют цифровизировать впечатление, что код просто читать и модифицировать.
Каждая из этих метрик — отдельное минное поле, пространство для непрекращающихся холиваров о том, нужны ли они, или что некоторые разработчики будут их подделывать.
В Ozon мы многое разрабатываем на Go — это язык, который сфокусирован на простоте: открыл код, прочитал его, всё понятно, дописал отличную фичу. Для этого мы пишем юнит-тесты, следя за тем, чтобы покрытие тестами кода не падало ниже какого-то разумного уровня, а с остальным — не заморачиваемся. Но есть команды, которые измеряют всё, и у них тоже всё отлично.
Также мы много времени уделяем линтерам, чтобы написать неправильно было сложнее, чем написать правильно. Должен оставаться единственный путь с хорошей производительностью и читаемостью. А плохие пути линтер будет подсвечивать красным. Это сверхзадача, к которой мы стремимся.
К следующей части нас подводит очередная история собеседования.
Реплика кандидата: Если я отправляю один и тот же запрос, то я должен получать один и тот же ответ, ведь так?
В случае ML — это не так.
Уровень 2: ML-инженеры
Один из больших столпов компьютерных вычислений — это повторяемость. По идее, если мы сложили 2 и 2, и получили 4, то завтра тоже должны получить 4. Понятно, что если мы оперируем числами с плавающей точкой, это не всегда так, тем не менее, люди ожидают повторяемости от компьютерных систем. Но для систем, которые имеют большую ML-часть, это может быть не так.

В чат-боте есть ML-часть — это может быть, например, нейросеть, которой мы на вход подаём некий input и на выход получаем некий output. Отдельный вопрос, как проверить, что input и output хорошие? Если мы просто тасуем параметры нейросети и input до тех пор, пока output не начнёт нам нравиться — это вообще нормальный подход к тестированию по обеспечению качества? Или все-таки можно сделать лучше? Кроме того, в чат-боте есть более прогнозируемая часть кода, где API на вопрос «Когда мне деньги вернутся?», берёт из огромной контентной части подходящий ответ: «Смотря как вы платили».
Machine Learning — это все-таки часть прикладной математики. Мы можем взять формулу, которая покажет, что всё хорошо или не очень. Бот в своей ML-части — это классификатор текстовых запросов. У нас есть неограниченное поле запросов от пользователей и ограниченное поле классов, на которые мы хотим классифицировать вопросы от пользователей, например:

В зависимости от присвоенного класса, мы отдаем заранее написанный ответ из системы контента. И на запрос «Я хочу изменить заказ» отвечаем: «Вам надо пойти туда-то и нажать такую-то кнопку. Или вы хотите, чтобы вам помогли?», предлагая повести пользователя по сценарию диалога бота.
Теоретически это делается так: берем вопрос пользователя, кладём в самую модную на сегодня нейросеть и получаем классификацию. По опыту, самые хорошие системы классификации в ботах замечательны не своими крутыми нейросетями, а количеством костылей из предметной области, которые подложены под эту нейросеть.
Потому что в распознавании классификации есть много проблем, не очевидных для нейросети, которая обучалась, допустим, на Википедии. Например, «Спасибо вам большое» — хороший ответ, и мы на него можем ответить «Пожалуйста». Но если человек переформулирует вопрос или начнет иронизировать: «Отменили мой заказ — ну, спасибо!», то будет странно ответить: «Вам спасибо, мы тоже очень рады». Может быть, лучше посочувствовать? Или надо направить пользователя к оператору?
Другой пример: баллы «Спасибо от Сбербанка», которые стали кошмаром для всех классификаторов и чат-ботов. Люди запросто могут написать: «Спасибо, я хочу расплатиться баллами Спасибо».
Но поскольку ML — это всё-таки прикладная математика, то она сможет сказать, насколько качественно мы обучили модель, которая классифицирует. Есть очень большое количество метрик, я приведу самые простые.
Accuracy — самая интуитивная метрика. Мы берём общее число предсказаний (угадываний), которые делает бот, и считаем долю правильно угаданных. Это отличная метрика системной ошибки:

Precision — метрика случайной ошибки (вариабельности). Это не системная ошибка, а ошибка отвечающая за рандомные процессы, например, в нейросети:

Recall — метрика полноты, то есть насколько мы правильно исчерпали все случаи классификации:

F1 score — это среднее гармоническое:

LogarithmicLoss — чтобы задать, что не все классы классификации одинаково важны, и вознаграждать наш классификатор за то, что он угадывает больше важных классов, чем неважных. Понятно, что раз появляются логарифмы, значит, что-то усредняется и сглаживается:

Confusion-матрица для классификатора — это наглядная возможность проверить наш классификатор, доступная даже менеджеру:
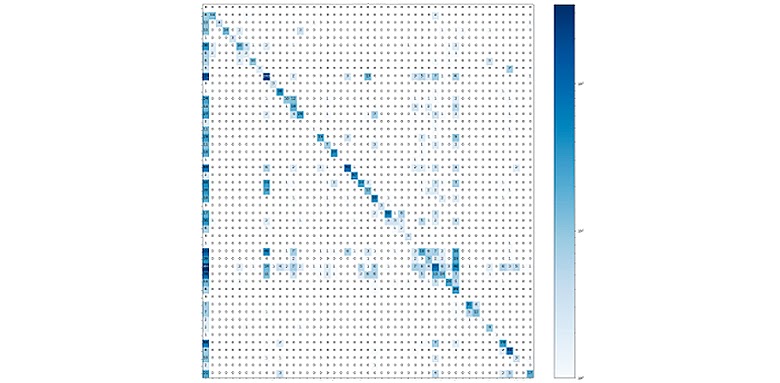
По вертикали видим предсказанные классы, предсказанные ботом. По горизонтали — реальные классы. Чем больше мы попадаем, тем квадрат более синий. В идеале должна быть закрашена только главная диагональ. Если иначе, то что-то пошло не так.
На изображении как раз такой пример. Можно посмотреть, какие классы наш чат-бот путает, и сделать два разных вывода: чат-бот может работать плохо или это может быть один и тот же класс. На самом деле на классы разбивает человек, может быть, он сделал это неправильно и нам нужны совсем другие классы, а от этих нужно отказаться?
Важный вопрос про метрики качества: когда их измерять? При обучении модели мы их измеряем на предразмеченной тестовой выборке. Как правило, у нас разметкой тестовой выборки занимаются люди с Толоки — человек пробегает по различным вопросам и классифицирует их. Например, вопрос: «Я хочу отменить» — это класс annul, а «Я хочу поменять размер кофты» — это класс change size.
После этого мы выделяем в предразмеченной выборке обучающую, валидационную и тестовую части. Соответственно, учимся мы на обучающей части, валидируемся на валидационной, и так — несколько раз. В результате получаем для нашей обученной модели цифру и интерпретируем ее.
Кроме того, мы можем измерять производительность модели постфактум, по итогам работы. В конце концов, даже оператор, когда к нему приходит тикет, проставляет категорию запроса. Мы можем взять запросы пользователя, категории запросов от операторов, предположения бота (который, очевидно, ошибся, раз тикет перешел к оператору), померить и получить какую-то цифру. Это тоже измерение качества.

Но с метриками качества ML есть проблема. Например, если мы повысим Precision на несколько пунктов, то это будет огромным достижением, но как это повысит качество работы бота и сколько это стоит в деньгах — непонятно. К сожалению, ML-метрики интерпретируются хуже всего. Зачастую это прямо вещь в себе. Но это не значит, что их не нужно измерять.
Вот, что ещё говорят тестировщики на собеседовании:
Вопрос: Как мы узнаем, когда пора закончить тестирование? Сколько багов можно оставить?
Ответ кандидата: Когда в проекте не останется багов.
Вопрос: Совсем-совсем?
Ответ: Не, ну чуть-чуть можно.
Некоторые говорят, что надо тестировать до конца, пока 0 critical, некоторые упоминают известные крупные компании, у которых огромное количество багов, но они не парятся.
К тестировщикам мы ещё вернемся, а пока перейдём к следующему уровню качества — нашим аналитикам.
Уровень 3: Аналитики
У нас аналитическая система Power BI: в ней анализируются все цифры, которые можно вытащить из всех сообщений нашего чата. Понятно, что теоретически в ней можно найти ответы на все вопросы, но понять, какая цифра за что отвечает — невозможно. Поэтому наши аналитики отвечают за преобразование цифр в знания и инсайты.
Самые популярные и наглядные метрики аналитики — это воронка и дерево декомпозиции. Они отвечают на вопрос на каком конкретно этапе какого сценария бот не справился:
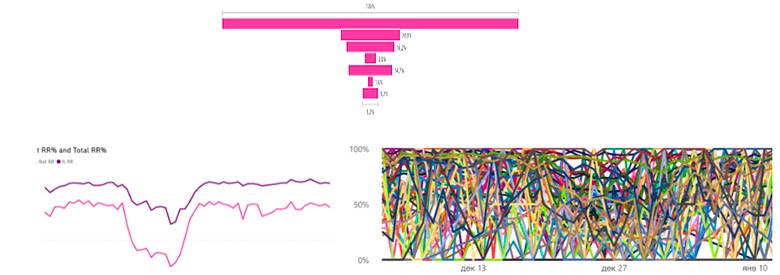
Допустим, к нам в чат пришло 100 человек, из них мы решили проблемы у 30. Остальные 70 на каком-то этапе отвалились. Мы всем задавали некоторое количество вопросов, и кто-то отвалился на первом, кто-то на третьем, а кто-то на пятом. Соответственно, мы можем видеть, на каком этапе кто отваливается — эти этапы представляют собой дерево декомпозиции.
Благодаря этому дереву можно увидеть, что мы задаём не тот вопрос или не можем понять ответ. Допустим, мы спрашиваем, какой заказ вы имеете в виду, и люди отвечают: «Вот этот». Понятно, что для человека это имеет смысл, но для бота понять, какой «вот этот» — невозможно. Обнаружение «плохого» вопроса позволяет закостылить серьёзную логику, чтобы бот попытался разобраться, какой «вот этот» — последний, первый или второй.
Проанализировав метрики, аналитики получили важный инсайт: бот — это такой же оператор, как человек, а значит, к нему можно применить все метрики из теории массового обслуживания.
Теория массового обслуживания — это математика, раздел теории вероятностей, который говорит нам, что будет, если 100 человек встанут в 10 очередей, или если какой-то человек на почте медленно выдает посылки, или если люди будут переходить из одной очереди в другую. Благодаря этой теории нам доступна огромная библиотека метрик, которые мы можем использовать: например, время ожидания, время обслуживания и другие.
Эта же теория отвечает на вопрос, как мы поймём, что решили проблему пользователя. Как правило, в клиентском сервисе есть идея, что если клиент не отвечает несколько минут в чате, то он удовлетворён. Многие операторы так получают плюсик в систему аналитики (вопрос засчитывается как решённый).
Тут мы приближаемся к последнему уровню нашего «пирога» — менеджерам.
Уровень 4: Менеджеры
В конце концов, менеджеры отвечают за то, чтобы мы не забывали, что проект — это деньги и нужно, чтобы он двигался вперёд и приносил прибыль. Если не забывать, что всё это можно посчитать в деньгах, то возникают неожиданные инсайты. Например, мы пробовали посчитать эффективность простого бота, который ищет в запросе пользователя слово «Спасибо» и отвечает на него: «Пожалуйста! Мы работаем для вас». Бот максимально простой, но оказалось, что в масштабах Ozon он сэкономил достаточно денег, чтобы содержать небольшую команду разработки.
Менеджеры у нас тоже в основном опираются на метрики. Например, есть метрика закрытия тикетов — это, упрощенно говоря, один диалог с пользователем и в идеале одна решенная проблема. Или метрика удовлетворенности пользователя, которая показывает насколько пользователь остался доволен ботом.
Эти метрики противоположны и балансируют друг друга, но можно и затянуть одну из них. Например, мы бы хотели максимизировать метрику закрытия тикетов, потому что надо выполнить KPI закрытия на 80%. Все понимают, как это сделать (и многие компании так и делают) — просто не отпускать пользователя. Просим его переформулировать вопрос, сказать как-нибудь по-другому. Так продолжается до тех пор, пока ему не надоест, либо он все-таки не попадет в ту фразу, которую распознает бот. Это позволяет достичь фантастических цифр закрытия тикетов — 80, 90, 95%!
С другой стороны, предположим, мы бы хотели повысить метрику удовлетворённости пользователей — так, как мы её понимаем. Это тоже делается очень просто. Когда пользователь заходит в чат, ему говорят: «У вас проблема? Отлично, вот вам 400 бонусных баллов!». Счастливый пользователь их забирает, ставит пять или пишет хороший отзыв. Но завышение метрик не обеспечит нам качество и не повысит скорость обслуживания, а может дать только обманчивое чувство того, что никаких проблем нет.
Мы вроде бы прошли по всем уровням обеспечения качества, но среди них не было тестировщиков. Они упоминались то там, то тут, но своего отдельного места не заняли. Почему? Потому что, пользуясь все той же кулинарной метафорой, у нас тестировщики, как сироп в слоеном пироге, участвуют на каждом этапе. И конечно, сами измеряют и влияют на качество.
А как ещё можно потестировать?
У нас есть бот, который принимает input, обрабатывает его и что-то отвечает. Это реальный скриншот редактора бота, его дерево сценариев:

Отсюда возникает идея — а давайте сделаем еще одного бота, который принимает input от первого бота и выдает ответ в духе: «Братишка, ты всё правильно сказал» или «Братишка, ты сказал всё неправильно». Пусть бот тестирует бота. Так мы сможем протестировать большое количество сценариев на технологической базе, которая у нас уже есть.
Собрать ещё одного бота-контроллера, когда их уже 5 — несложно. Такой бот должен сидеть на очереди сообщений, читая их, и когда это нужно, матчить их с шаблонами, описанными на yaml'е. Например, если было два подряд сообщения от бота, то это, скорее всего, неправильно? Или если пользователь начал ругаться, а чат-бот его не успокаивает.
Мы можем брать более или менее формальные характеристики. А поскольку у нас уже 2022 год и все боты должны писать в Slack, то так и до ChatOps’ов недалеко!
Заключение
Ответ чат-бота — это сочетание большого количества параметров. Мы можем вернуть практически любой товар, но если он электронный или это лекарство, то будут свои тонкости. А обращения премиум-пользователей получают приоритет в обработке. То есть существует огромное количество сценариев взаимодействия, протестировать которые — отдельная большая задача.
Конечно, есть определенные сложности (они же и интересности) в обеспечении качества чат-бота:
Недетерминированный вывод. Сегодня мы получили какой-то один вывод от чат-бота, но не можем его зафиксировать, положить в JSON и сравнивать с завтрашним и послезавтрашним, посчитав его эталонным. Потому что завтра мы переобучим модель, немножко подправим в ней любой параметр, и чат-бот будет отвечать по-другому.
Неопределённые требования. Требования, конечно, простые — чат-бот должен помогать решать проблему. А что такое «решать проблему» — это вопрос, который мы обсуждаем целыми днями.
Множество сценариев взаимодействия. Чат-бот должен помогать пользователю с любым вопросом — от доставки в Норильск до получения сертификатов на товар.
Словом, работы проделано много, но и впереди еще немало — улучшать качество чат-бота можно бесконечно.
Конференция об автоматизации тестирования TestDriven Conf 2022 пройдёт в Москве, 28-29 апреля 2022 года. Кроме хардкора об автоматизации и разработке в тестировании, будут и вещи, полезные в обычной работе. Расписание уже готово, а купить билет можно здесь.
Комментарии (6)

BkmzSpb
20.01.2022 18:55"order_want_change" - первый раз прочитал как "заказ хочет перемен (изменения)" (но с очепяткой), затем как "заказ хочет разменять денег", потом (т.к. want и won't звучат немного похоже, и won't здесь грамматически подходит) - "заказ не будет меняться".

slavashock
20.01.2022 19:47Мы можем собрать фидбек. Например, прислать сообщение: «Оцените, как вы пообщались, всё ли было нормально?» после завершения диалога. Но есть нюанс. По опыту на это сообщение отвечает примерно 10% пользователей и, как правило, они не репрезентативны. Обычно человек не будет писать отзывы или оценивать после того, как уже решил свою проблему. Продолжают общение люди, которые настроены поругаться. Если ориентироваться только на таких пользователей, то мы быстро зайдём в тупик.
Есть вагон и маленькая тележка методик работы с обратной связью. Вы сейчас в трех предложениях написали: CSI, NPS и прочие ведут в тупик.
MikVolkov Автор
21.01.2022 13:05Есть вагон и маленькая тележка методик работы с обратной связью
Да, безусловно. В целом, углубление в эти методики немножко выходит за рамки этого обзора, но тут важно понимать, что основная обратная связь от пользователя - это его действия, а не то, как он отвечает на какие-либо опросники.
Допустим, человек обратился к боту, чтобу уточнить информацию по заказу и, после того как поговорил с ботом, не ругался, может быть даже поблагодарил, повторно с тем же вопросом не обращался, заказ нормально получил, а потом продолжил покупать на озоне, то видимо мы можем поставить боту плюсик в графе "хорошо пообщались", даже если пользователь не пишет "Порекомендую друзьям вашего бота на 10 баллов из 10".
Полностью эту цепочку померять сложно, но отдельные звенья поддаются измерению и превращению в метрики.
Тем не менее CSAT, мы, конечно же, измеряем и смотрим на его изменения.

ymishta
20.01.2022 20:12Уменьшаем рутину — снимаем с операторов однообразные вопросы.
Угу, убираем опреаторов совсем и оставляем одного робота Кузю, с которым только по скрипту и можно поговорить. Шаг вправо-влево - все, "я вас не понял" и снова здорово. И нехай убогий со своей внескриптовой проблемой носится где-то там, за пределами нашего мирка. Как по мне, так все эти роботы - это просто плевок в лицо клиентам, нынешним и будущим. равно как и попытка оправдать эту мерзость всем этим наукообразным набором слов.
slavashock
21.01.2022 07:33+4Не соглашусь, тут вопрос компромиссов, на поддержку в больших компаниях тратятся огромные деньги, если вы ещё добавите требование чтобы поддержка была не просто живая, но и отвечала в течение 10 - 20 - 30 секунд - это уже умножение ОРЕХа на полтора, если вы хотите чтобы в поддержке работали не студенты по скриптам, а профессионалы и эксперты, то ОРЕХ мы умножаем ещё на 1,5 - 2.
Кто за это будет платить? Вы. Но вы же не хотите покупать тотже товар, который есть везде (рынки высококонкурентные) за ценник + 10 - 30%?
Elepse
Спасибо за статью!