
Искусственный интеллект (ИИ) имеет свойство не только помогать людям в бизнесе, творчестве и жизни в целом, но и вызвать всевозможные проблемы. Вопросы корректности, этичности и применение ИИ для угроз различным системам заставили людей серьезно относиться к исследованию способов сделать искусственный интеллект и машинное обучение (ML) более безопасными.
В данной статье я постараюсь кратко изложить некоторые из нерешённых проблем, связанных с кибербезопасностью, на которые исследователи в области машинного обучения советуют обратить внимание уже сейчас, во избежание рисков в будущем.

Мониторинг
Выявление злонамеренных использований, отслеживание прогнозов и обнаружение неожиданных функциональных возможностей модели.
Сложнейшие системы машинного обучения находят применение в сферах, где их небезопасность может привести к серьезным последствиям и человеческим жертвам, например, в медицине. Поэтому их развертывание требует высокой осторожности. Злоумышленники для достижения своих целей могут использовать системы ML для социального манипулирования, перепрофилировать их для создания новых видов оружия или кибератак. При этом они также заинтересованы в использовании новых стратегий нападения и развития своих инструментов, потому что всегда легче выявить известную угрозу, чем неизвестную. Решение этой проблемы необходимо начинать с обнаружения аномалий.
Детекторы аномалий являются важнейшим инструментом в системах высокого риска, они способны предупредить человека о потенциальных опасностях и, как правило, нацелены на максимально возможный низкий уровень ложного срабатывания. Детекторы способны запустить политику отказоустойчивости в системе, а также отметить пример для вмешательства человека. Главная проблема заключается в том, что существующие методы обучения испытывают трудности с обнаружением представлений, которые хорошо работают для ранее незамеченных аномалий. Классическим примером неспособности обнаружить аномалию, является воздействие на нейронную сеть, вызывающее ошибки в её результатах. Подмешивание аномального шума к изображению панды, заставляет нейросеть распознавать картинку, как изображение гиббона.

Подобные атаки можно произвести без особых усилий, например, с помощью библиотеки foolbox языка программирования python. Ниже представлен пример атаки на нейронную сеть ResNet.
# Загружаем необходимые библиотеки
import numpy as np
import matplotlib.pyplot as plt
import tensorflow
import foolbox as fb
from tensorflow.keras.preprocessing.image import load_img, img_to_array
from tensorflow.keras.applications.resnet_v2 import preprocess_input, decode_predictions
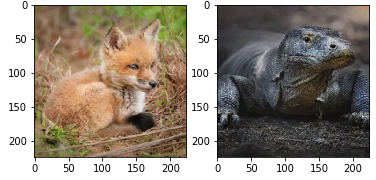
# Загружаем изображения, соответствующие случайно выбранным классам, которые классификатор должен предсказывать. 48 – варан, 248 – китовая лиса.
img_varan = load_img(r'/content/drive/MyDrive/varan.png', target_size=(224, 224))
img_fox = load_img(r'/content/drive/MyDrive/kit_fox.png', target_size=(224, 224))
labels = np.array([278, 48])
plt.figure()
f, ax = plt.subplots(1,2)
ax[0].imshow(img_fox)
ax[1].imshow(img_varan)
plt.show()
# Создаём экземпляр предобученной модели
model = tensorflow.keras.applications.ResNet50V2(weights="imagenet")
fmodel = foolbox.TensorFlowModel(model, bounds=(-1, 1))
# Подготавливаем изображения для работы с моделью и смотрим на результат классификации до атаки.
images = np.array([img_to_array(img_fox), img_to_array(img_varan)])
prep_images = preprocess_input(images.copy())
img = tensorflow.convert_to_tensor(prep_images, dtype=np.float32)
labels = tensorflow.convert_to_tensor(labels, dtype=np.int64)
pred = model.predict(prep_images)
pred_lables = np.argmax(pred, axis=1)
print("Китовая лиса: %r, Варан: %r" % (pred_lables[0], pred_lables[1]))
print("Модель прдесказывает, что китовая лиса это - %r c вероятностью %r" % (decode_predictions(pred)[0][0][1], decode_predictions(pred)[0][0][2]))
print("Модель прдесказывает, что варан это - %r c вероятностью %r" % (decode_predictions(pred)[1][0][1], decode_predictions(pred)[1][0][2]))

Как видно, классификатор верно распознает оба изображения с достаточно высокой долей уверенности.
# Производим простую и быструю атаку на основе градиента (подробнее можете прочитать по ссылке внизу.) и смотрим результат
attack = foolbox.attacks.LinfDeepFoolAttack()
raw, _, success = attack(fmodel, img, labels, epsilons=0.05)
pred = model.predict(raw)
pred_lables = np.argmax(pred, axis=1)
print("Китовая лиса: %r, Варан: %r" % (pred_lables[0], pred_lables[1]))
print("Модель предсказывает, что китовая лиса это - %r c вероятностью %r" % (decode_predictions(pred)[0][0][1], decode_predictions(pred)[0][0][2]))
print("Модель предсказывает, что варан это - %r c вероятностью %r" % (decode_predictions(pred)[1][0][1], decode_predictions(pred)[1][0][2]))

Теперь модель классифицирует изображения неверно. Видно, что предсказанные метки классов не соответствуют оригинальным. Однако, если Вас не впечатляет возможность подмены одной лисы на другую, а варана на игуану, можно заставить модель думать, что лиса – это варан, а варан – лиса.
# Указываем метки, которые хотим получить от классификатора после атаки и воспроизводим атаку.
target_classes = labels[::-1]
criterion = foolbox.criteria.TargetedMisclassification(target_classes)
attack = foolbox.attacks.L2CarliniWagnerAttack(steps=300)
advs, _, success = attack(fmodel, img, criterion, epsilons=0.05)
# Смотрим на предсказание модели после атаки и на полученные изображения
pred = model.predict(advs)
pred_lables = np.argmax(pred, axis=1)
print("Китовая лиса: %r, Варан: %r" % (pred_lables[0], pred_lables[1]))
print("Модель предсказывает, что китовая лиса это -", decode_predictions(pred)[0][0][1])
print("Модель предсказывает, что варан это -", decode_predictions(pred)[1][0][1])

foolbox.plot.images(advs, bounds=(-1,1), figsize=(5,5))
Полученные изображения не отличаются на взгляд от оригинальных, но теперь заставляют модель неверно их классифицировать, принимая изображения друг за друга. При этом, обнаружение злонамеренных аномалий может стать очень сложной задачей, когда злоумышленники используют возможности машинного обучения. Обнаружение аномалий является необходимой частью повышения надежности и предотвращения злоупотребления. Однако, существует множество ситуаций, требующих дополнительного изучения, таких как обнаружение изменений в окружающей среде, разработка детекторов, работающих в реальных условиях для обнаружения вторжений, обнаружение вредоносных программ или биобезопасности.
Например, про вариант обнаружения вредоносных программ вы можете почитать в опубликованной в 2019 году статье исследователей из университета Плимута и университета Пелопоннеса. Вкратце, они показали, что при визуализации безопасных и вредоносных файлов можно заметить шаблоны, которые бы не заметили классические методы обнаружения вредоносных программ.

Согласно статье, безопасные файлы имеют более четкие и сглаженные изображения, в отличие от резких изображений вредоносных. Аналогично, визуализируя разметки и исходный код фишинговых и настоящих сайтов(рис 3 и 4), выявляются уникальные закономерности, а когда у вас есть такие видимые шаблоны, можно применить ML для различия подобных отличий.


Внешняя безопасность
Использование ML для устранения рисков, связанных с обработкой систем ML таких, как кибератаки.
Системы машинного обучения существуют не обособленно от внешнего окружения, поэтому безопасность внешнего контекста может влиять на то, как машинное обучение обрабатывается, а также на безопасность самого машинного обучения. Системы машинного обучения скорее потерпят неудачу или будут неправильно направлены, если внешний контекст, в котором они работают, небезопасен или нестабилен.
В то же время риски кибербезопасности могут сделать системы машинного обучения небезопасными, поскольку эти системы работают вместе с традиционным ПО и часто реализуются как киберфизическая система. Это даёт возможность злоумышленникам использовать уязвимости традиционного программного обеспечения для перехвата контроля автономных ML систем. Кроме того, машинное обучение может усилить будущие кибератаки и позволит злоумышленникам не только скрыть свои нападения, но и увеличить доступность, скорость и шанс на успех своих автоматизированных атак. А при точно заточенных на взлом ML-моделях ещё и снизит порог вхождения в преступную деятельность. И поскольку кибератаки могут уничтожить ценную информацию и даже разрушить критически важную инфраструктуру, например, такую как электросети, то эти атаки представляют собой надвигающуюся угрозу для международной безопасности.
Поэтому рекомендуется сфокусировать исследования на методах, которые явно носят оборонительный характер. Нейронные сети сейчас быстро обретают способность писать код и взаимодействовать с внешней средой, в то время как исследований в области глубокого обучения для кибербезопасности очень мало.
В заключение хочу сказать, что упомянутые проблемы - лишь малая часть нерешённых исследовательских задач, которая имеет цепочку взаимосвязанных и взаимозависимых проблем. Система машинного обучения, несогласующаяся с человеческими ценностями, может воспроизвести небезопасное последствие, но даже если есть возможность создать согласованную цель для системы, может произойти событие типа «Чёрный лебедь», что может привести к неверной цели. Злоумышленники могут запустить свои атаки или воспользоваться уязвимостью ПО, на котором работает система ML.
Людям необходимо комплексно исследовать все связанные проблемы, следить за всеми уровнями угроз безопасности, создать культуру безопасности и повысить свои стандарты. Наше внимание должно быть сосредоточено не только на точности, скорости и масштабируемости, но и на безопасности как главном приоритете, если мы хотим использовать системы машинного обучения в критически важных ситуациях.
Ссылки на использованную литературу:
A Novel Malware Detection System Based On Machine Learning and Binary Visualization
Unsolved Problems in ML Safety
DeepFool: a simple and accurate method to fool deep neural networks