

Привет, Хабр!
На связи Руслан Остропольский, Директор по производству ИТ в СберЗдоровье. Он расскажет, как команда сэкономила кучу времени и денег и добилась колоссального роста производительности благодаря грамотному подходу к автоматизации UI-тестов.
Предпосылки
Всё началось с того, что бизнес пришёл к нам, сказал: «Нам нужна автоматизация тестирования задач разработки», и снабдил необходимыми ресурсами. На тот момент, лет 5 назад, мы запускали всего 2 релиза в неделю, причём на регрессию одного релиза у тестировщиков уходил ровно один рабочий день. То есть минимум два дня в неделю они занимались только этим. Бизнесу же был очень важен time-to-market — время, за которое мы могли доставить идею пользователю. Их совершенно не устраивало, если в пятницу они придумали какую-то идею, а в проде она появлялась только во вторник.
Кроме того, в то время у нас было много экспериментальной работы. Мы были, по сути, небольшим стартапом и тестировали идеи, чтобы понять, какие из них понравятся и будут нужны пользователю. Поэтому многое из того, что мы запускали тогда, было гипотезами.
Кроме того, мы одновременно стали развивать порядка 15 направлений. Если изначально мы занимались только сайтом, то чуть позже к нему добавились «партнёрка», SEO, маркетинг и многое другое. У всех были разные задачи, и проводить регрессию для каждой из них стало слишком долго и дорого.
Тогда всем стало понятно: нам необходимы UI-тесты.
Спойлер: к чему мы пришли
Чтобы было интереснее читать дальше, раскрою сразу некоторые результаты, к которым мы пришли.
Первое: научились реализовывать от 2500 до 3000 сценариев. Что такой сценарий в нашем понимании, расскажу чуть ниже.
Второе: если запустить все наши тесты в одном потоке, то завершены они будут примерно через 10 часов.
Третье: всё это создавалось и поддерживалось силами всего двух автоматизаторов. Команда с самого начала процесса не росла, так как в этом не было необходимости, мы достигли результата самим процессом.
Дальше разложу все наши процессы по полочкам и расскажу, как мы пришли к такому результату.
Инструменты
В компании не было собственной экспертизы в автоматизации. Зато у нас был фронтенд, который писал на JS, и мы тоже стали писать на нём. Наши самые первые UI-тесты создавались именно фронтендерами на Cucumber JS.
Кроме того, мы используем Gherkin — это язык описания сценариев автотестов, который позволяет писать на языке, понятном автоматизаторам. То есть ручной тестировщик может взять понятный и адекватный, написанный по-русски текст и перевести его на язык Gherkin.
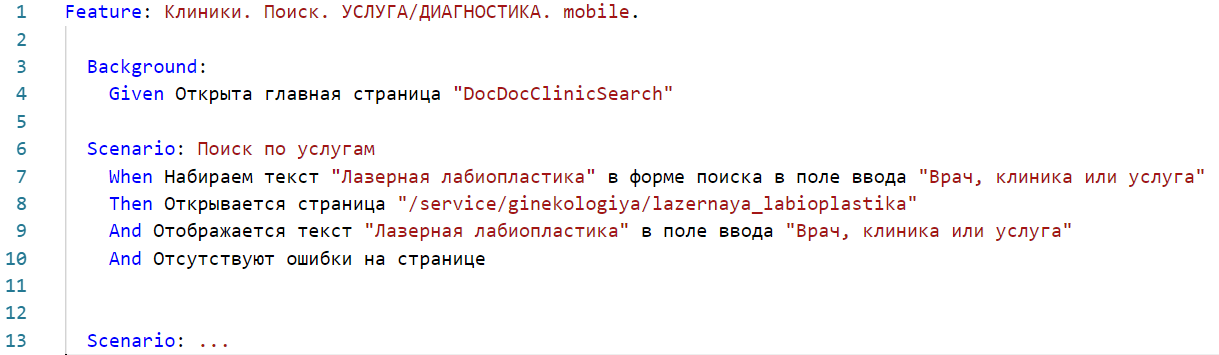
Из чего он состоит:
Feature File — по сути это небольшой suite, который объединяет в себе несколько сценариев. У него есть простое и понятное название на русском языке.
Background — стартовая точка, открытая страница или предисловие, одинаковое для всех сценариев в этом Feature File.
Given — буквально «дано», как в задачах по математике.
Scenario — сценарий. Естественно, у него есть понятный заголовок на русском.
When — описание нашего действия.
Then — последствие этого действия.
And — дополнения к ним.
В одном Feature File может быть много сценариев, которые в свою очередь могут включать в себя ещё и табличные части. Благодаря таблицам в сценарии можно задавать переменные. Например, в строке When значение «Лазерная биопластика» можно заменить на любую другую медицинскую услугу, врача или клинику. Все значения этой переменной можно занести в таблицу, и сценарий будет их по очереди перебирать. Для нас это было очень важно из-за специфики продукта: даже если говорить только о специализации врача, то их будет порядка 70, и просто необходимо уметь тестировать сразу несколько, а лучше вообще все.
Правила и стандарты
Первым делом мы сделали глоссарий и стилистику элементов сценария. Мы определили, как и что должно называться, чтобы ручные тестировщики, автоматизаторы и разработчики работали в едином контексте. До этого кто-то один мог использовать слово «футер», кто-то другой — «подвал» и так далее. Мы зафиксировали все подобные стандарты в глоссарии.
После этого мы занялись схожей стандартизацией для всех наших шагов given, when, then и and. Например, для описания действия нажатия на кнопку можно использовать множество разных синонимов: нажать, кликнуть, тэпнуть и так далее. На этом этапе мы решили, что все будут писать «кликнуть», и зафиксировали это.
Эта стандартизация отлично ложится на наш инструментарий. Мы используем Sublime Text и Visual Studio Code — для обоих этих инструментов есть плагины под язык Gherkin. В первом случае это Gherkin Auto-Complete Plus, который распознаёт шаги. Во втором — Cucumber Full Language Support, который парсит все имеющиеся сценарии. То есть в любом сценарии можно ввести слово «кликнуть», и плагины предложат вам текст сценария, который написал, например, другой автоматизатор в своём Feature File. Благодаря этому работа идёт раз в 10 быстрее.
Скорость важнее всего
Сейчас мы держим на Dev- и Demo-окружениях скорость в 25 минут, это примерно 16 потоков. В Release — до 40 потоков за 5, максимум 9 минут и то в редких случаях.
Зачем нам нужна такая скорость? Когда мы только настраивали свои автотесты и давали их разработчикам, они, мягко говоря, не горели желанием их запускать: тесты длились около часа. Вполне логично, что разработка не хотела ждать, этим тестам было невозможно доверять, и они были нестабильными. Вспоминаем про задачу уменьшения time-to-market: бизнес хотел, чтобы мы могли релизиться хотя бы один раз в день. Сейчас мы спокойно релизимся по 30 раз в день, а вот с теми долгими тестами и один-то раз не всегда удавался.
С какими проблемами мы столкнулись на старте
Тесты, которые мы написали за первые 3 месяца, получились медленными и нестабильными.
Около 50% времени тратилось на поддержку того, что мы уже написали.
Тесты было очень сложно анализировать. Все результаты просто падали в консоль, там очень не хватало какой-то истории, да и не каждый мог эту консоль прочитать.
Мы начали разбираться в причинах.
Почему так медленно?
Основная причина — долгие сценарии. Наш первоначальный подход заключался в том, что мы взяли тесты, которые написали ручные тестировщики, и попытались сделать из них эталонный формат для автоматизаторов. Другая причина нас довольно сильно удивила — это был отклик браузера. А самая прозаичная из них — ресурсы. Для тестов требовались достаточно мощные серверы, а они закупались не так быстро, как нам бы хотелось.
Почему так нестабильно?
Много данных. У нас достаточно сложный продукт с кучей зависимостей. Например, у одного врача может быть 15 вариаций форм записи, другой может принимать сразу в нескольких клиниках. Selenium Grid работает нестабильно, а Flacky-тест только что работал, через две сборки обязательно упадёт, ещё через две сборки снова начнёт работать. При этом ничего не менялось, а он всё равно продолжает вот так произвольно падать.
Почему так много времени уходило на поддержку?
Как я уже писал, всю систему тестов ставило и поднимало два автоматизатора.
Процессы разработки, которые на тот момент не позволяли нам как-то пушить в ветку разработчикам, то есть нам приходилось отдельно писать тесты, отдельно ставить задачи. Разработка тоже шла отдельно.
Сама архитектура тестов, с которой мы начали, была далека от идеала.
А что с аналитикой?
Ответ прост: слишком много данных. В консоли было ничего не понятно, нам не хватало истории запусков для тех же Flacky-тестов (а это очень важно: сразу понять, действительно ли это Flacky-тест или он упал в первый раз, и нам надо его чинить). Кроме того, без нормальной аналитики мы просто не могли ничего планировать наперёд, не могли считать наше покрытие и по сути не понимали, куда действительно нужно перенаправить ресурсы. Запусков тестов было очень много, соответственно, и результатов тоже — разбирать из вручную было практически невозможно. Поэтому для этих целей мы внедрили ReportPortal, который сам ставил лейблы по известным ему ошибкам.
Решаем проблемы по мере их поступления
Начали со скорости.
Первое, за что мы взялись, — архитектура серверов. Проблема была в большом образе базы данных, который весил порядка 20 Гб. Получалось так, что собирать его нужно было минут 15 ещё до того, как тесты вообще могли запуститься. Решили мы эту проблему просто: стали готовить тесты заранее.
После этого мы запустили параллельные старты окружения и деплоя, то есть один сервер мы отвели для сборки приложения, а на втором разворачивались стартеры этих тестов.
Кроме этого, мы разработали скрипт для умного распределения мощности. Небольшое отступление. Есть тесты, которые проходят быстро на лёгких страницах, и для них не нужен мощный сервер. А есть заметно более долгие сценарии на тяжёлых страницах (например, список врачей). Такие тесты периодически начинают загибаться — им нужно больше оперативной памяти. Собственно, мы смогли автоматизировать увеличение оперативной памяти при определённых параметрах. Как только тест отрабатывался, оперативная память сразу уменьшалась до стандартных значений. Так мы начали экономить деньги.
Чтобы добавить ещё скорости, мы пошли в распараллеливание.
Знаю, что некоторые с этого начинают, но тут есть несколько подводных камней, на которые стоит обратить внимание. На самом деле это только кажется нетривиальной задачей.

В первом потоке слева всё понятно: у вас есть один бэкенд-стенд, есть развёрнутый на нём Selenium Hub, который стартует уже ноды, и стартер тестов.
В множестве потоков также есть основной стенд под Selenium Hub, а дальше мы «игрались» с этими цифрами: сколько потоков может выдержать бэкенд-сервер и сколько потоков выдерживает одна нода. Игрались долго — либо теряли в скорости, либо в стабильности. В итоге пришли к таким цифрам: нода выдерживает 8 потоков, а бэкенд-сервер выдерживает 30 потоков. Наращивать их мы можем достаточно легко.
При этом возникает новая проблема: стабильность падает, а стоимость возрастает. Снизить стоимость нам удалось переводом тестов на облачные серверы. Раньше у нас был выделенный под автотесты сервер, и если нам нужен был новый, нам приходилось идти в отдел эксплуатации и просить их добавить нам ресурсов. Это дорого и долго. В этом смысле облачные серверы гораздо удобней для нас: как только стартуют тесты, под них открываются серверное облако и облако деплоя с приложением. Как только тесты заканчиваются, облака закрываются. То есть сейчас мы вообще не платим за простои серверов. Если учитывать, что на ночь они у нас автоматически выключаются, стоимость хостинга для нас упала в 3 раза, при этом наши серверы стали в 2 раза мощнее.
Стабильность же мы смогли поднять путём экспериментов. Оказалось, что разные версии Selenium Hub и браузера дружат между собой по-разному. Мы довольно долго подбирали версию Selenium Hub, которая подойдёт к нужной версии браузера, а в итоге просто решили использовать на релизном окружении только один браузер и вынести все кросс-браузерные проверки в ежедневный утренний запуск.
Чтобы добавить ещё больше скорости, мы решили разобраться с долгими тестовыми сценариями. Во-первых, мы сделали их атомарными, чтобы избежать возможных проблем с их зависимостью от данных. После этого мы провели рефакторинг и ограничили время выполнения сценария. Мы сделали их гораздо короче, и они стали заметно стабильнее. Сейчас наш эталон — 1 минута.
Ещё больше скорости: мы стали подготавливать данные с помощью API
Это было удобно, так как у нас уже были Rest API, которые использовали наши партнёры. Мы брали методы, которые есть у них (например, получить код через смс) и вставляли их в свои сценарии. Нам было очень важно подготавливать, изменять и получать данные. Для примера можно взять условного врача. У него могут быть, например, вот такие вариации:
Расписание приёмов.
Активность.
Оплаченные его клиникой счета в биллинге.
Вскоре мы начали делать свои универсальные API специально под автотесты. Мы сделали так, чтобы они могли создавать, получать и отдалять записи, а также отдельно добавили очистку кэшей. Вот как это выглядит в сценарии:

В этом сценарии у нас есть условный врач, который должен принимать, например, детей. Прямо в сценарии мы вставляем слово «детей», даты, свободные слоты и так далее. Все эти данные вставляются в табличную часть ещё и через API. То есть вместо того, чтобы каждый раз писать новую таблицу, можно просто использовать API.
Добавляем стабильности: боремся с Flacky-тестами с помощью перезапусков. На первых порах с перезапусками мы допустили несколько ошибок. Например, с самого начала мы сделали трёхкратные перезапуски для всех тестов, потому что некоторые из них упорно продолжали падать до магического третьего перезапуска. Такой подход обеспечил стабильность тестов, но увеличил время их выполнения практически в два раза. Нас это не устраивало.
Мы стали разбираться, почему так происходит, и через какое-то время поняли, что далеко не всем тестам нужно три перезапуска. Некоторым достаточно одного, другим — двух. В итоге мы сформировали светофорную систему: от одного до трёх перезапусков для разных типов тестов. Это вернуло время выполнения тестов в норму.
Ещё больше стабильности через умное ожидание от элементов. На ранних стадиях мы просто вставляли какие-то слипы и пытались сделать так, чтобы страничка загрузилась полностью. Спустя какое-то время мы научились привязываться прямо к нужным нам элементам. То есть стало неважно, подгрузилась ли вся страница, важен стал только элемент, на который мы сейчас хотим кликнуть. Как только он появляется, таймер сбрасывается, и мы можем спокойно с ним работать.
Делаем ещё стабильней через новые процессы. После устранения базовых проблем со стабильностью мы были готовы к комплексным решениям. Например, взяли и добавили автозапуск тестов при переводе к ревью, после чего у нас отпала необходимость бегать к разработке и просить ребят запустить тесты. Теперь они запускаются автоматически, как только задача переводится в ревью. Когда она доходит до тестировщика или даже до ревьюера, сразу видны результаты тестов.
После этого мы попробовали поставить автоматический деджект и отправление теста в дефект при падении, но это не зашло, потому что всё-таки встречаются тесты, которые нужно поправлять.
Далее мы вынесли в ночной запуск ежедневные запуски кросс-браузерных проверок и просто тестов, которые сейчас есть. Это позволяет, придя утром на работу, сразу же увидеть проблемы, которые у нас сейчас есть, поменять тесты и быть уверенными в том, что к моменту выгрузки релизов они будут зелёными. Сюда же мы прикрутили оповещалки в Jira и другие мессенджеры, которыми мы пользуемся. В Jira прямо в таске пишется, что тесты запустились, сколько они будут продолжаться, там же есть ссылки на сборку и результаты тестов и обязательно отображается статус теста: он упал или прошёл успешно.
Задача ручного тестировщика на этом этапе — разобраться в этих падениях и поправить тесты. Только после этого он может передавать задачу дальше. В мессенджере у нас есть специальная дежурная группа, которая просто следит за тестами и реагирует на их падения.
Кроме того, мы добавили возможность скиповать тесты — как итог мы всегда знаем процент пропущенных тестов, и у нас есть цифра, выше которой этот процент подниматься не должен.
На этом мы, естественно, не остановились и решили поправить выгрузку деплоя. Мы поставили в приоритет задачи, призванные «озеленить» автотесты. То есть в Continuous буквально открывается зелёный коридор, в котором тесты выгружаются первее всех остальных задач. И загружаются они тоже по упрощённой схеме, по сути, это Merge Master. Схематично это выглядит так:
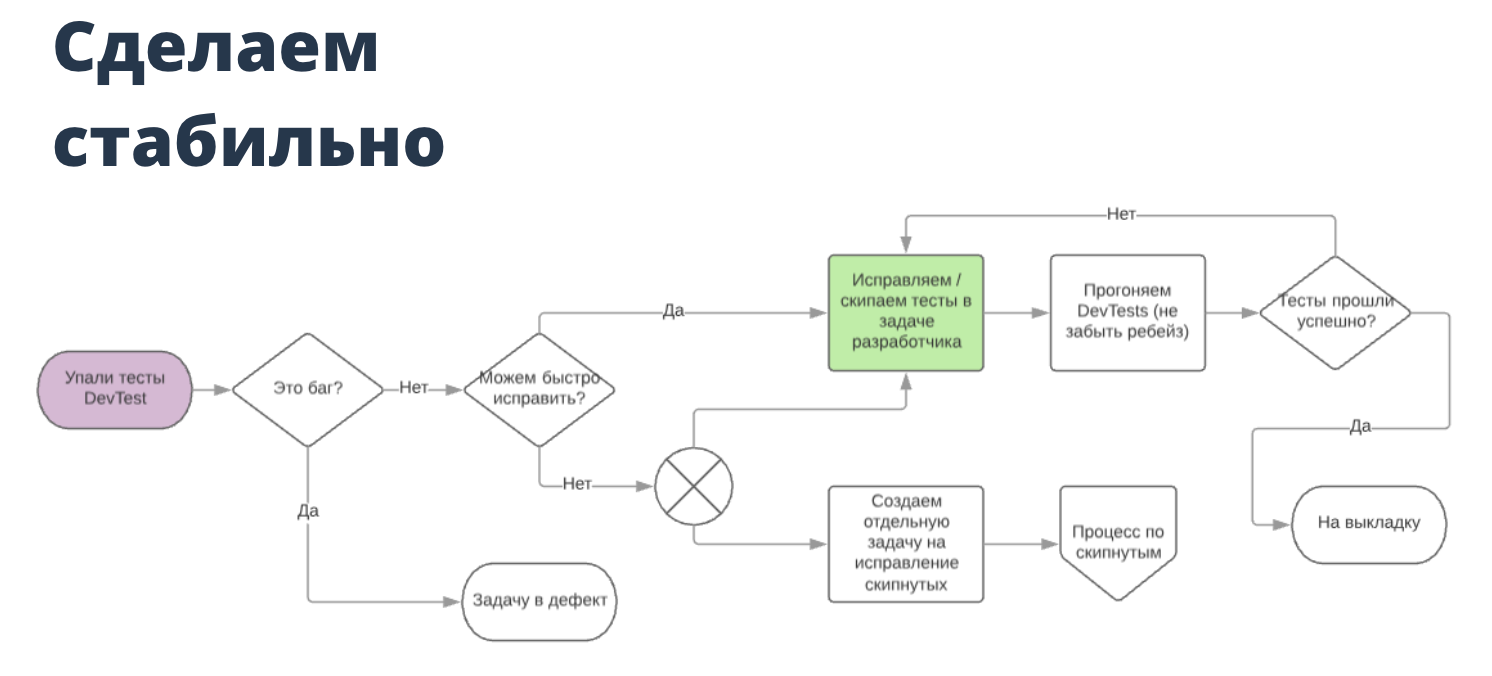
Надо сказать, что это сильно упрощённая схема — о большой сложно рассказать кратко и доходчиво. На схеме изображён пример падения теста на Dev-окружении (в релизе всё несколько сложнее).
Итак, что здесь происходит? Когда падает тест, разработчик или тестировщик смотрит, баг это или нет. Если баг, то задача летит в дефект. Если нет, то он прикидывает, сможет ли он исправить тест за 10 минут — это верхняя граница того, что мы называем «исправить быстро». Исправленный тест потом снова отправляется на выкладку и прогоняется заново. Чуть более сложные задачи, которые нельзя поправить быстро, скипуются. Затем мы можем буквально по одной кнопке в Jira поставить задачу по исправлению этих тестов автоматизатору.
Выстраиваем грамотную поддержку тестов. Достаточно быстро мы поняли, что силами двух автоматизаторов поддерживать тесты практически невозможно, поэтому мы начали привлекать для этого ручных тестировщиков. Это сработало: читать и поправлять упавший тест гораздо легче, чем научиться полностью автоматизировать сценарии. Нам же не пришлось искать и нанимать новых автоматизаторов. При этом для ручных тестировщиков это стало хорошей тренировочной площадкой и возможностью роста или перехода в автоматизацию. Автоматизаторам такой подход дал возможность вообще полностью избавиться от поддержки и заниматься только написанием новых тестов и продумыванием общей архитектуры.
И у автоматизаторов, и у ручных тестировщиков есть дежурства. Эти дежурные — те самые люди, которые мониторят мессенджер и реагируют на падения тестов. Они знают, что именно им нужно смотреть этот чат, а остальные сотрудники на него не отвлекаются.
Далее мы договорились с разработкой о том, что начнём делать правки прямо в их задаче. По сути, это позволило нам делать атомарно зелёные задачи — теперь тестировщик может просто проверить её и поправить тест, и он будет уверен, что на релизе с этой задачей всё будет хорошо.
Ну и как финальный штрих в выстраивании системы поддержки мы добавили простой перезапуск тестов. Теперь никуда не надо лезть: кнопки запуска и перезапуска тестов есть прямо в Jira.
Как мы выстроили нашу аналитику. Сейчас упрощённая схема нашей аналитики тестов выглядит следующим образом.

Jira — абсолютно всё проходит через неё, из неё стартуют тесты по ветке в задачи и падают в Jenkins.
Jenkins — к нему мы добавили Allure-плагин, который позволяет читать тесты в достаточно понятном и простом виде. В них может разобраться любой человек в компании благодаря в том числе и Gherkin-сценариям. В Allure чётко видно, на каком шаге упал тест, там же можно хранить и прослеживать историю, туда же сыпятся скриншоты, ссылки и так далее.
Rocket Chat — сюда дублируются все результаты тестов. То же самое можно настроить и для Slack, и для других мессенджеров.
Report Portal — нужен нам для более глубокой и долгой аналитики, которой нам не хватает в Allure. Им пользуются уже исключительно автоматизаторы, он не очень простой в чтении, но он очень нужен нам для автоматического сбора статистики.
TestRail — здесь мы ведём наши ручные тесты, и из него мы вытягиваем данные о покрытии.
Google BigQuery — все данные тащатся сюда.
Chart.io — а затем сюда. Здесь мы выстраиваем красивые и понятные графики. Сейчас у нас есть более 100 метрик для ручных тестировщиков и около 50 для автоматизаторов. Вот, например, кусочек дашборда.
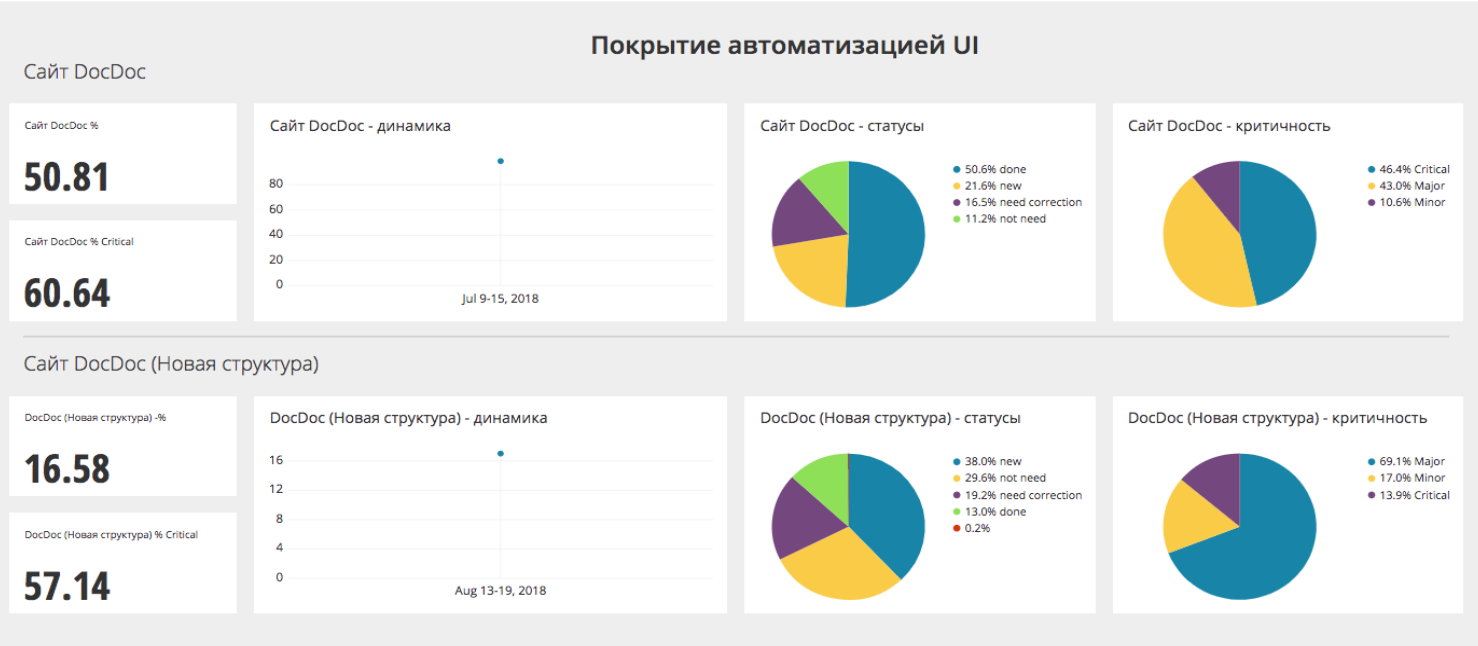
Здесь можно видеть количество пропущенных тестов, цифры количества пропущенных и критических тестов, тренд их роста или падения, есть процент фэйлов в количественных изменениях. Здесь же мы очень чётко можем увидеть, какая из сборок была наиболее проблемная.
Подводим итоги: что мы изменили?
Во-первых, мы начали со стилистики, правил и инструментов. Пожалуй, это самое простое и базовое изменение, но именно оно может ускорить все ваши процессы сильнее всего прочего, особенно на первых порах. Никаких нереальных ресурсов вам для этого не потребуется.
Во-вторых, серверы и многопоточность. Облачные серверы экономят огромное количество денег: мы стали тратить на хостинг в три раза меньше, при этом стали использовать серверы вдвое мощнее. Не забываем и про многопоточность, а особенно про то, что чем больше потоков, тем меньше стабильности.
В-третьих, API и базы данных для стабильности запусков. Можно использовать и перезапуски, но постарайтесь избегать наших ошибок и не ставить по три перезапуска на каждый тест.
В-четвёртых, поддержка тестов вполне удобно отдаётся ручным тестировщикам.
В-пятых, использование аналитики поможет вам понять, где конкретно у вас проблемы и куда вам нужно копать.
Все эти изменения лучше использовать вместе. Можно двигаться небольшими шагами (мы так и делали): отталкивались от боли и проблем, которые возникали перед нами, и постепенно решали их.
Комментарии (3)

azzas
14.04.2022 14:25+4Не могу сказать что я видео много реализаций тест-кейсов на Кукумбере, но в этом дополнительном слое абстракции не проще разобраться чем в коде и делает это все равно разработчик, и если уж так, то нафига этот Кукумбер нужен? А уж править подобные кейсы не смотря в код? Для читабельности на презентации начальству? Не могу представить что это действительно удобно и хоть сколько нибудь юзабельно. ИМХО.
Tyusha
Я не имею отношения к коммерческому программированию, и наверняка просто чего-то не догоняю. Но просветите меня, зачем бизнесу надо 30 релизов в день? Какой в этом смысл, и почему их недостаточно, как вы писали, двух в неделю (что по мне тоже довольно часто)? Со стороны выглядит, что в погоне за скоростью, вы потеряли здравый смысл, что это технологии ради технологий. Не лучше ли подкрутить что-то в "бизнесе", чтобы ему не нужно было получение обновлений, как из пулемёта? Выглядит, как погоня менеджеров за каким-то люто-бешенным KPI, оторванным от реальности, вопреки реальной пользе. Почему это пользователи не могут подождать новой фичи со вторника до пятницы, а могут только с 13:30 до 14:00?
DD174
Речь же про web, а не standalone приложение. Веб-сервисы можно релизить в любой момент по требованию, главное чтобы поставка умела сине-зеленые релизы под нагрузкой.
Поверьте, бизнесу куда выгоднее иметь непрерывный цикл поставки, чем кумулятивные релизы по расписанию. Что легче тестировать, релиз с одной фичей, или десяток фич в релизе? А откат или фикс бага? Как говорится "удачной отладки", чтобы найти причину в релизи с десятком фич