
С момента первой же хабрапубликации о возможностях нашего сервиса визуализации планов запросов PostgreSQL explain.tensor.ru (а было это уже больше 2 лет назад) пользователи задавали резонный вопрос: "Все у вас круто, но у нас в запросах и планах есть коммерческая инфа, которую отправлять куда-то наружу низзя... Можно как-то ваш сервис развернуть на своей площадке?"
Ну, а почему бы и нет, подумали мы - тем более, некоторые пользователи уже интересовались возможностью интеграции нашего сервиса в свои системы.

Зеркало на Amazon
И начать этот путь мы решили с подготовки сборки для AWS и разворота там зеркала сервиса (explain-postgresql.com), чем помогли некоторым пользователям оперативно обойти обратные блокировки (когда с рабочего места в "забугорье" закрыт доступ к части RU-ресурсов) после начала известных событий.
Self-hosted версия
Ну а теперь мы сделали и выложили полноценные сборки для установки на RHEL/Debian, Docker Linux/Win/MacOS, k8s и AWS - можно свободно попробовать для тестов, отладки и личного использования, а вот корпоративные инсталляции, поддержка и расширенные возможности - на отдельных условиях.
Визуальные улучшения
Но основная цель нашего сервиса - наглядно показать узкие места в плане любой сложности, поэтому вот - некоторые новые возможности, которые облегчат вам анализ планов.
Навигатор
Мгновенно визуально оцениваем с помощью полоски-навигатора, сколько времени занял каждый узел. Клик - и мы стоим на нужном узле:

Если доминируют красные сегменты - вы тратите много времени на чтение данных (Seq Scan, Index Scan, Bitmap Heap Scan, ...), если желтые - на их обработку (Aggregate, Unique, ...), а зеленых Join должно быть не слишком много.
Average IO
Если в вашем плане присутствуют показатели времени, затраченного на операции ввода-вывода (атрибут I/O Timings при включенном параметре track_io_timing), то теперь в строке итогов можно мгновенно оценить усредненные показатели скорости доступа к диску при последовательном и случайном чтении или записи.

Если вы видите тут цифры в единицы MB/s, хотя база находится на SSD, то где-то в работе дисковой подсистемы явно есть проблема.
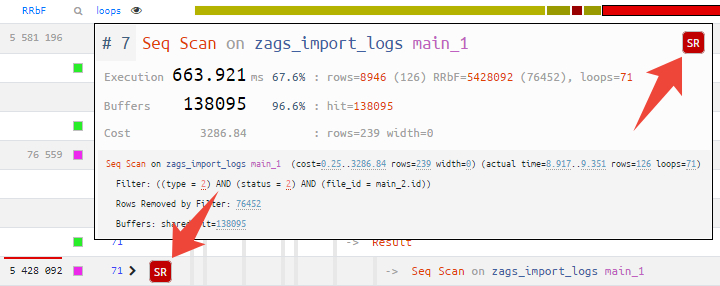
Дерево rows/RRbF
На tilemap-диаграмме плана появился новый режим rows - в нем вы можете мгновенно оценить, в каком сегменте плана генерируется или фильтруется чересчур много записей.
В этом режиме подсвечиваются те узлы, на которых было отброшено из-за несоответствия условию (Rows Removed by ...) наибольшее количество записей, а "ширина" связи пропорциональна количеству записей, которые были переданы вверх по дереву.
Чем ярче узел и толще его "ветви", тем более пристально стоит к нему присмотреться:

Тултип узла
Наводя курсор на узел в навигаторе или любой другой диаграмме, вы сразу видите все иконки рекомендаций, которые советует наш сервис:
Если это подсказка об индексе, то простого клика по ней достаточно, чтобы перейти к предлагаемым вариантам подходящих индексов.
Также для всех больших чисел в тексте узла добавлены разделители разрядов, чтобы сходу воспринимать порядок величин.

edo1h
не удобнее ли было бы для случайного чтения указывать iops?
Kilor Автор
В плане нет информации об этом. То есть мы не знаем, сколько операций требуется конкретному хранилищу для вычитки одной страницы, или наоборот - может, оно позволяет несколько физически последовательных страниц за одну операцию получить.
edo1h
не понял
вы про то, что данные могут быть «размазаны» с помощью какого-нибудь raid 5 и чтение одной страницы может идти с нескольких физических накопителей? ну так iops обычно считаются на уровне верхнего блочного устройства, так что это нам неинтересно
опять же не страшно. если мы запустим
fioсrw=readвместоrw=randreadмы тоже получим много iops, никто же этим не возмущается.то, что последовательное чтение оптимизируется, никак не отменяет того факта, что дисковая подсистема выдала нам столько-то страниц в секунду.
Kilor Автор
Так речь про страниц/сек или операций/сек? Первую величину можно посчитать, но она "нечеловеческая", на нее никак не опереться.
Если я скажу, что Seq Scan шел со скоростью 1MB/s - сразу понятно, что это жуть как плохо, а если 128 страниц/сек - то непонятно.
edo1h
seqscan понятно, что в мегабайтах в секунду считать удобнее. а вот random мне бы было удобнее видеть в страницах в секунду, это можно в первом приближении принять за iops
Kilor Автор
А к чему эту величину привязывать, как оценивать?
edo1h
типичное время доступа у ssd — 60-100 мкс, то есть 10-15к iops при qd=1.
на вашем скриншоте 8 мегабайт в секунду, это примерно 1000 iops, то есть или дисковая не очень хорошая, или узкое место не в обращении к диску
Kilor Автор
Обычно первого значения уже достаточно, чтобы понять хорошо/плохо, даже не обладая, знанием о спеках СХД. А переводить его в iops - зачем?
edo1h
честно говоря, не представляю, как можно не переводя в iops понять 8 мегабайт в секунду — это много или мало для случайного доступа.