
Когда речь идёт о технологиях, позволяющих компьютеру написать часть кода за человека, разговор вечно соскальзывает в гадания на кофейной гуще. Уволят через десять лет всех программистов или нет?
Но вообще-то тут есть о чём поговорить помимо этих спекуляций, причём разговор может быть куда предметнее. Как все эти разнообразные «copilot» вообще работают (вот сейчас, а не через десять лет)? Какие сложности возникают при их создании? Где эти сложности можно преодолеть, а где есть принципиальные ограничения формата?
На конференции Joker об этом рассказывали Никита Поваров allfather и Роман Поборчий p0b0rchy. На момент доклада оба работали в JetBrains, так что получилось не просто абстрактное описание вопроса, а «взгляд изнутри» со стороны тех, кто делает инструменты для разработчиков.

Чего сегодня не будет, а что будет
Никита: Некоторые люди периодически объявляют, что айтишники скоро исчезнут, потому что будут не нужны. Мы сегодня об этом не будем говорить, потому что такие люди в итоге обычно оказываются неправыми, и мы не хотим попадать в их ряды.
Вместо этого мы хотим обсудить, как меняется или может измениться наша профессия по канонам того, что говорил Ричард Хэмминг:

Его в основном знают по коду Хэмминга, но он ещё много всего делал, в том числе связанного с искусственным интеллектом. И один из его тезисов — «мне интереснее, что машины и человек могут сделать вместе, чем в соревновании».
Есть три основных барьера на пути к тому, чтобы мы с машиной были как можно лучше, выше и сильнее:
- Нет данных для обучения.
- Нужны вычислительные ресурсы.
- Непонятно, как правильно выстраивать интерфейс между человеком и машиной.
Сегодня мы хотим поговорить про них. Как у нас ставятся и преодолеваются задачи с точки зрения этих барьеров? Где нам не хватает данных, а где вычислительных ресурсов? Как выглядят проблемы с интерфейсами?
Славное прошлое
Роман: Начнём с истории. Как только люди вообще начали программировать, сразу задумались о том, чтобы машины сами писали код. Мы не станем забираться совсем далеко и пытаться вспомнить, что на эту тему думали Чарльз Беббидж и Ада Лавлейс, а посмотрим, что примерно 40 лет назад написал Эдсгер Дейкстра.

Дейкстра тогда в своей статье утверждал, что естественный язык плохо подходит для постановки задачи компьютеру. Он ссылался на древнегреческих математиков, которые не смогли развивать науку из-за того, что занимались математикой на естественном языке. Важно здесь вот что: если 43 года назад даже Дейкстра написал статью с критикой некой идеи, то эта идея тогда уже была.
Примечание редактора: узнав из этого доклада про статью Дейкстры, мы перевели её для Хабра.
В качестве одного из ярких примеров посмотрим на работу двух специалистов из MIT, Чарльза Рича и Ричарда Уотерса, которые в 1987 году опубликовали работу The Programmer’s Apprentice Project: A Research Overview («Подмастерье программиста»).
Там было три блока:
- Implementation — пишет кусочки кода.
- Design — это не про UI/UX, а скорее про дизайн-паттерны и использование очередей и прочего.
- Requirements — это для работы с требованиями к программе.
Там уже можно было на естественном языке ставить машине задачи, а она с чем-то тебе помогала.
Что было «под капотом»:
- Универсальное внутреннее представление, из которого потом можно было генерировать код на всех поддерживаемых тогда языках.
- Библиотека клише (сниппетов), и эта техника в некоторой степени жива до сих пор. Полезно иметь небольшие фрагменты кода, которые подходят по делу, могут быть параметризованы, и их переиспользуют.
- Метод резолюций.
Метод резолюций
Тогда не были распространены современные методы машинного обучения. А метод резолюций работает на формальной логике. Посмотрим на коротком примере, как это устроено. Есть такая задача:
Малыш спрятал от Карлсона банку с вареньем в одну из трёх разноцветных коробок. На коробках Малыш сделал надписи:
- на красной: «Здесь варенья нет»;
- на зелёной: «Варенье в синей коробке»;
- на синей: «Варенье — здесь».
Только одна из надписей правдива. В какой коробке Малыш спрятал варенье?
Для её записи в виде формальных предикатов, так называемых дизъюнктов, которые нужны для метода резолюций, нам нужно определить булевские переменные — литералы.
Три литерала R, G и B определяют, есть или нет внутри коробки соответствующего цвета варенье:
R: варенье в красной коробке
G: варенье в зелёной коробке
B: варенье в синей коробке
Ещё три определяют, правда или неправда написана на соответствующей коробке.
TR (truth red): на красной коробке правда
TG (truth green): на зелёной коробке правда
TB (truth blue): на синей коробке правда
Давайте смотреть, как это всё записывается. Напишем, что у нас только в одной коробке варенье, то есть только один из первых трёх литералов истинный, в виде четырёх дизъюнктов.
¬R∨¬G, ¬R∨¬B, ¬G∨¬B, R∨G∨B
Хотя бы один из каждой пары должен быть неверен и хотя бы один из трёх верен.
Теперь то же самое для «только одна из надписей правдива»:
¬R∨¬G, ¬R∨¬B, ¬G∨¬B, R∨G∨B,
¬TR∨¬TG, ¬TR∨¬TB, ¬TG∨¬TB, TR∨TG∨TB
Надо записать, что есть на коробках. Из того, что на красной коробке написана правда, следует, что варенья в красной коробке нет. Соответственно, по логике, это «не А или В»: либо там неправда, либо там нет варенья. То же самое для зелёной и синей коробок.
¬R∨¬G, ¬R∨¬B, ¬G∨¬B, R∨G∨B,
¬TR∨¬TG , ¬TR∨¬TB, ¬TG∨¬TB, TR∨TG∨TB,
¬TR∨¬R, ¬TG∨¬B, ¬TB∨¬B
Кроме того, метод резолюций предполагает, что мы добавляем в набор проверяемое утверждение, точнее, его отрицание, и пытаемся вывести противоречие. Соответственно, нам надо проверить три гипотезы. Значит, в конце надо ещё поочередно добавить ¬R, ¬G и ¬B, и после каждого раза проверить.
В общем виде это NP-полная задача. Там есть оптимизации, которые, кажется, позволяют в частных случаях свести её к кубу. Но это совсем не легко, и если попробовать дойти до этого вывода вручную, то можно в этом убедиться. Дочитывайте до конца, чтобы узнать, в какой коробке варенье!
Важно понимать, что метод позволяет нам двигаться обратно, и мы всегда знаем, из каких двух утверждений вывелось третье. Если мы нашли противоречие, то можем полностью восстановить логическую цепочку, которая к нему приводит.
Давайте посмотрим, как это работает. Поскольку писать код на Ada мы сейчас не хотим, а на Java они тогда не писали, то приведём пример из The Requirements Apprentice, то есть из работы с требованиями.
Люди пишут это примерно так:

Человек вводит «хочу написать систему "LIBDB"». LIBDB — это tracking system, и это requirements cliché. Скорее всего, там под капотом есть параметризованный код, который написал ещё «муравей-программист». И «repository» — это тоже клише, но это не тот репозиторий, к каким мы привыкли, а настоящий склад книг, которые оттуда можно забирать.
Дальше описываем параметры книги: заглавие, автор и ISBN. Пишем, какие есть транзакции: «check out», «return» и «add».

И тут машина пишет: «есть потенциальная проблема, "add" — это то же самое, что "return"».

Мы ей: «Ну-ка объясни».

И она отвечает: The add transaction is exactly the same as the return transaction, и вот почему…

Смотрите, тут мы как раз идём обратно по выводу метода резолюции.
Add transaction трекает добавление книги, а return transaction тоже трекает добавление книги. Вот почему: check out трекает removal, а return — это действие, обратное check out. Если один трекает removal, то другой трекает addition. Мы велим убрать (4) и пишем: «check out» теперь трекает «borrowing».

Borrowing — это другая операция, которая предполагает последующий возврат. Система говорит: принято. И обратите внимание, что поменялся тип репозитория, то есть теперь у него не просто «repository», а «lending repository» — он отдаёт и ожидает возврата. Мы написали вот такие требования, и можно переходить к генерации кода.
Шесть трудностей
Авторы работы обнаружили, что неформальность в общении с человеком очень важна, и в связи с ней есть шесть проблем:
- Жаргон;
- Неоднозначности в речи;
- Плохой порядок (говорю не так, как удобно понимать, а так, как мне пришло в голову);
- Неполнота;
- Противоречия в нашей системе;
- Ошибки.
Никита: Они выделяли что-то как самое значимое?
Роман: Вот они ещё не выделяли. Позже до этого вопроса дойдем, но у этих авторов они равноценны.
Фантастическое настоящее
Стало больше мощностей, развитие науки, и появились методы машинного обучения в уже более или менее современном виде, которые, конечно, тоже можно приспособить к генерации кода.
Первое и самое простое, с чего начнём.
Автодополнение (оно же Code Completion)
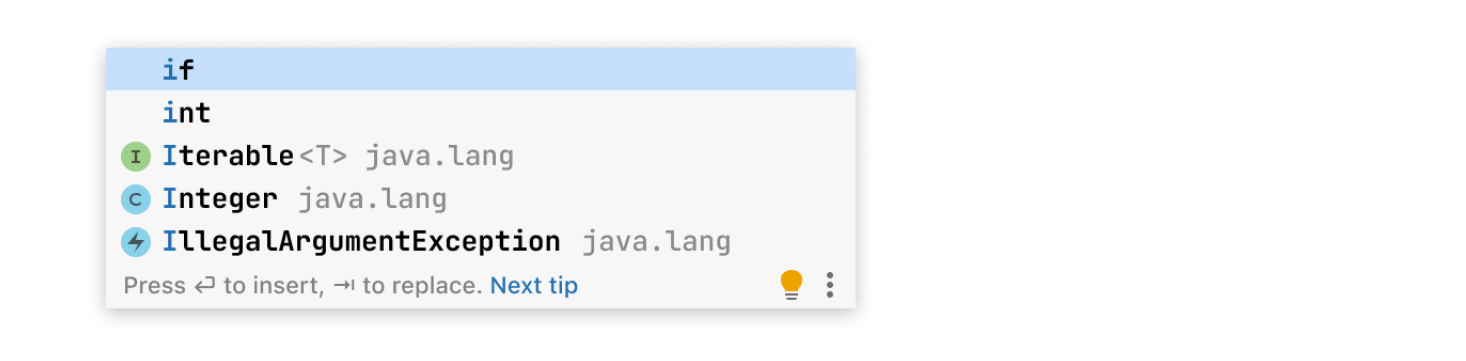
Тут задача вроде бы несложная — надо откуда-то взять варианты и отсортировать их. Кажется, что взять несложно, потому что у нас есть блок кода, в котором сейчас находится разработчик. Этот блок определён: допустим, он находится в методе, метод — в классе, класс — в файле. Также там есть импорты, способные добавлять ещё какие-то классы или другие вещи.
У нас есть статический анализ, который ходит по всему этому и может найти всё, что имеет смысл и что корректно подставить в подсказку.
Никита: Ну, корректность может быть нужна не всегда.
Роман: Да, такая проблема есть, и она одна из самых сложных в автодополнении. Смотрите. Допустим, мы определяем класс Parent, в котором есть приватный метод doSomething, и определяем от него наследника, в котором приватный метод не виден, но явно же разработчик хотел его там вызвать.
public class Parent {
private void doSomething() {
...
}
}
public class Child extends Parent {
public void enhanceSomething() {
doS
}
}И он, наверное, хочет его здесь вызвать, а потом увидеть, что код покраснел, и private заменить на protected. Скорее всего, так будет быстрее. Но если мы будем честно действовать, то мы его здесь не покажем, это будет ошибка.
Ну, и ещё один пример — это слова «extends» и «implements» в Java. Мы расширяем абстрактные классы, а имплементируем интерфейсы. Но когда разработчики пишут код, то часто не помнят, кто у них абстрактный класс, а кто интерфейс. Наши наблюдения говорят такое: если разработчик не уверен, он обычно пишет «extends», после чего ожидает увидеть в подсказках и имена абстрактных классов, и имена интерфейсов. А если он уверен, что интерфейс, то пишет «implements».
В общем, там приходится подумать, похитрить. Но, допустим, мы эти варианты собрали, и теперь их надо отсортировать.
Дискриминативные и генеративные модели
Никита: Отсортируем мы их с помощью дискриминативной модели. Объясним это определение на таком примере.
Предположим, у нас есть рукописные цифры, и мы знаем, что имел в виду написавший их человек (они снабжены соответствующими лейблами). И мы хотим получить модель, которая при подаче уже другого рукописного изображения цифры определит лейбл.
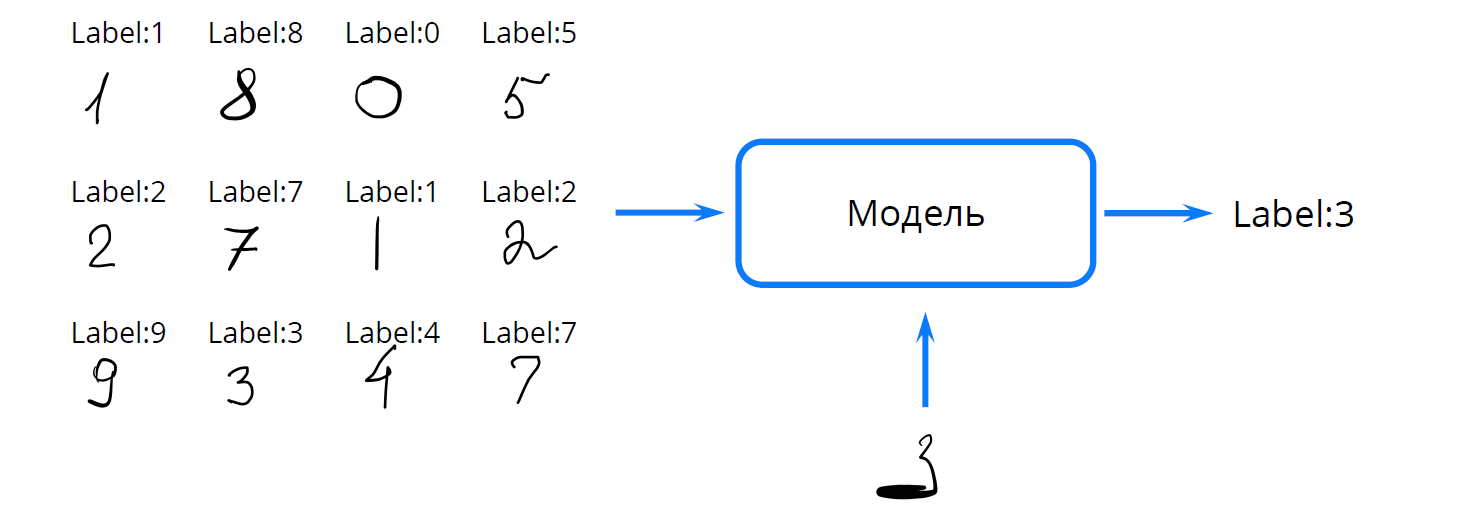
Это называется дискриминативной моделью. Она выбирает самый подходящий из имеющихся вариантов (в данном случае от 0 до 10) и говорит, что остальные подходят хуже. То есть дискриминирует остальные варианты. Иногда она может и ошибиться. Для этого там вводятся метрики качества, loss-ы.
А в генеративных моделях у нас есть только сами объекты реального мира. В данном случае — кем-то нарисованные цифры. Когда мы подаём в модель изображение, это всего лишь затравка (prompt). Мы хотим, чтобы модель дорисовала. Вот в этом случае — передано загогулиной на изображении — она, кажется, рисует цифру 8.

Но это мы только так воспринимаем: ведь она возвращает нам не лейбл, а сам объект. Говорит: «Кажется, тут имелся в виду вот такой объект из реального мира». Так что может нарисовать непонятную загогулину, которую кто-то распознает как «тройку», а кто-то как «это вообще не цифра».
И в автодополнении мы сортируем подсказки дискриминативной моделью. В таком случае нам нужно знать, что здесь будет лейблом, что такое «хорошо», что должна вернуть модель. Она должна определить «лучшие» среди данных ей вариантов из подсказок, но вопрос — на что опираться.
Код с GitHub
Роман: Кажется, что к нашим услугам весь GitHub. Возьмём случайный файл из опенсорсного проекта (например, из IntelliJ IDEA Community Edition), выберем случайную точку в нём:
private static AnalysisScope getInspectionScopeImpl(
DataContext dataContext,
Project project,
Boolean acceptNonProjectDirectories) {
// possible scopes: file, directory, package, project, module.
Project projectContext =
PlatformCoreDataKeys.PROJECT_CONTEXT.getData(dataContext);
if (projectContext != null) {
return new AnalysisScope(projectContext);
}
AnalysisScope analysisScope = AnalysisScopeUtil.KEY.getData(dataContext);
if (analysisScope != null) {
return analysisScope;
}
PsiFile psiFile = CommonDataKeys.PSI_FILE.getData(dataContext);
if (psiFile != null && psiFile.getManager().isInProject(psiFile)){
VirtualFile file = psiFile.getVirtualFile();В данном случае она разрывает токен getData. Удалим хвост метода и остаток токена. А потом потребуем от нашей модели, чтобы она именно этот токен предсказывала как хороший. Тo есть здесь дополнение должно поставить этот метод getData(dataContext) на первое место. И тогда оно молодец.
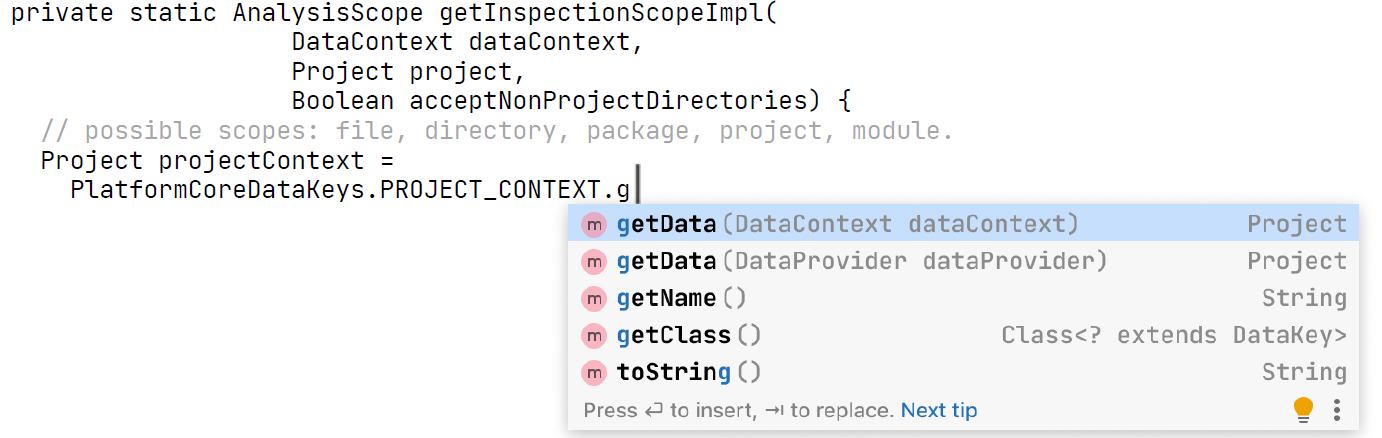
Никита: Но, кажется, с GitHub здесь есть некоторые проблемы. Обычный код, который мы коммитим, складываем в репозиторий, компилируется и проходит какие-то тесты. Перед отсылкой мы избавили его от совсем позорных дублей, сами порефакторили, хотя бы в рамках файла. Убрали отладочную печать (ну или хотя бы закомментировали).
И лейблы о том, что вот такой код писать хорошо, мы можем получить не из того состояния кода, в котором реально вызываем code completion, а из другого. Мы вряд ли заходим в готовый код, удаляем кусок или весь конец файла и пытаемся с этого места его продолжить. Это не та постановка задачи.
Роман: Тут есть вторая проблема: нет поведенческих факторов. Если представить, что пользователь где-то вызвал дополнение и потом, некоторое время думая, переключается туда-сюда между вариантами и пытается мучительно выбрать, то важна информация о том, как быстро он принял решение. Конечно, файл из опенсорсного репозитория этой информации не содержит. Поэтому нужны настоящие данные.
Никита: Да, но их собирать по понятным причинам нельзя. Мы не можем послать себе код и поведение пользователя. И это один из наших барьеров. У нас, на самом деле, нет хороших данных для обучения.
Что можно собирать
Роман: Можно посылать не код, а некоторые агрегированные статистические данные, анонимизированные описания этого кода. Например, можем запомнить, сколько символов в подсказке совпало с префиксом, который набрал пользователь. Обратите внимание: сами символы мы никуда не посылаем.
Никита: Причём можно послать как количество, так и долю от итогового метода или класса, который мы пытаемся подставить. Это тоже отдельная информация: «совпало три, и это 50%» или «совпало три, и это 10%».
Роман: Еще один вид информации — в начале или середине произошло совпадение.
Ещё оказывается полезно знать, если у вас, например, в другой вкладке в редакторе открыт файл с соответствующей декларацией. Например, подсказка — это имя метода, а у вас он открыт прямо в редакторе. Это, оказывается, очень полезный фактор, значит, велики шансы, что это правильная подсказка.
Ну, и тип подсказки, например, можно помнить: это метод, переменная или ключевое слово языка.
Дальше есть всё окно подсказок целиком. И про окно, и про то место в коде, из которого оно вызвано, тоже можно что-то запоминать:
- Вызвалось оно само или при помощи Ctrl + пробел?
- Какой отступ в этом месте был? Это особенно критично для тех, кто пишет на Python, но, в принципе, важно для всех языков.
- Как быстро пользователь принял решение?
- Принял или отклонил подсказку? Человек же не всегда действительно выбирает один из предложенных вариантов.
- Какой размер префикса был? В подсказке мы считаем, сколько совпало, а в окне запоминаем, сколько было в принципе.
- Родительский элемент в дереве.
- До или после точки.
Всё это важно. Что интересно, можно ещё и сохранять информацию про пользователя. При этом, понятно, имя и другие персональные данные мы не знаем и никогда не должны узнать, но мы можем узнать, часто ли этот пользователь нажимает на подсказки, как много он в принципе пишет кода и, например, не включена ли у него алфавитная сортировка. Если включена, то поведение очень сильно меняется.
Никита: Напомню еще раз: если всё это и пишется, то в анонимном виде. Непосредственно код не отсылается ни в одной версии IntelliJ IDEA — ни в платной, ни в бесплатной.
Роман: Просто сбор таких данных — довольно содержательная организационная задача, нам показалось, что интересно об этом сказать.
Самый сильный фактор
Никита: Это, как ни странно, — есть ли уже в файле похожий кусок кода. Если выше что-то такое уже написано, то здесь подставить то, что там было, очень полезно и очень часто пригодится пользователю прямо в полёте.
Роман: В общем, всплакнём на могиле принципа «Don’t repeat yourself».
Пользователи IntelliJ IDEA Ultimate Edition используют операцию Paste 78 раз в день (медианное значение). То есть мы что-то копипастим в код 78 раз в день.
Никита: Возможно, ещё более интересно взглянуть на соотношение Copy и Paste. Один раз Copy и 78 раз Paste, или, например, пятнадцать.
Роман: Тут не могу сказать, потому что это заранее не посчитал.
Кроме кода и факторов есть ещё внешние библиотеки, про которые тоже хотелось бы что-то знать и правильно с ними работать в подсказках. Это целый отдельный класс задач. Наверное, любой Java-программист хотя бы раз ругался вот на это:
Когда мы пытаемся начать писать List, нам всё время импортируется java.awt.List (видимо, потому что он первый по алфавиту), а java.util.List не выдаётся. Тогда как на самом деле никому, конечно же, awt-версия не нужна. И вроде бы все это исправляют всю жизнь, но если погуглить, то видим соответствующие тикеты про IDEA, причём с большой разницей в номерах (то есть первый был давно):
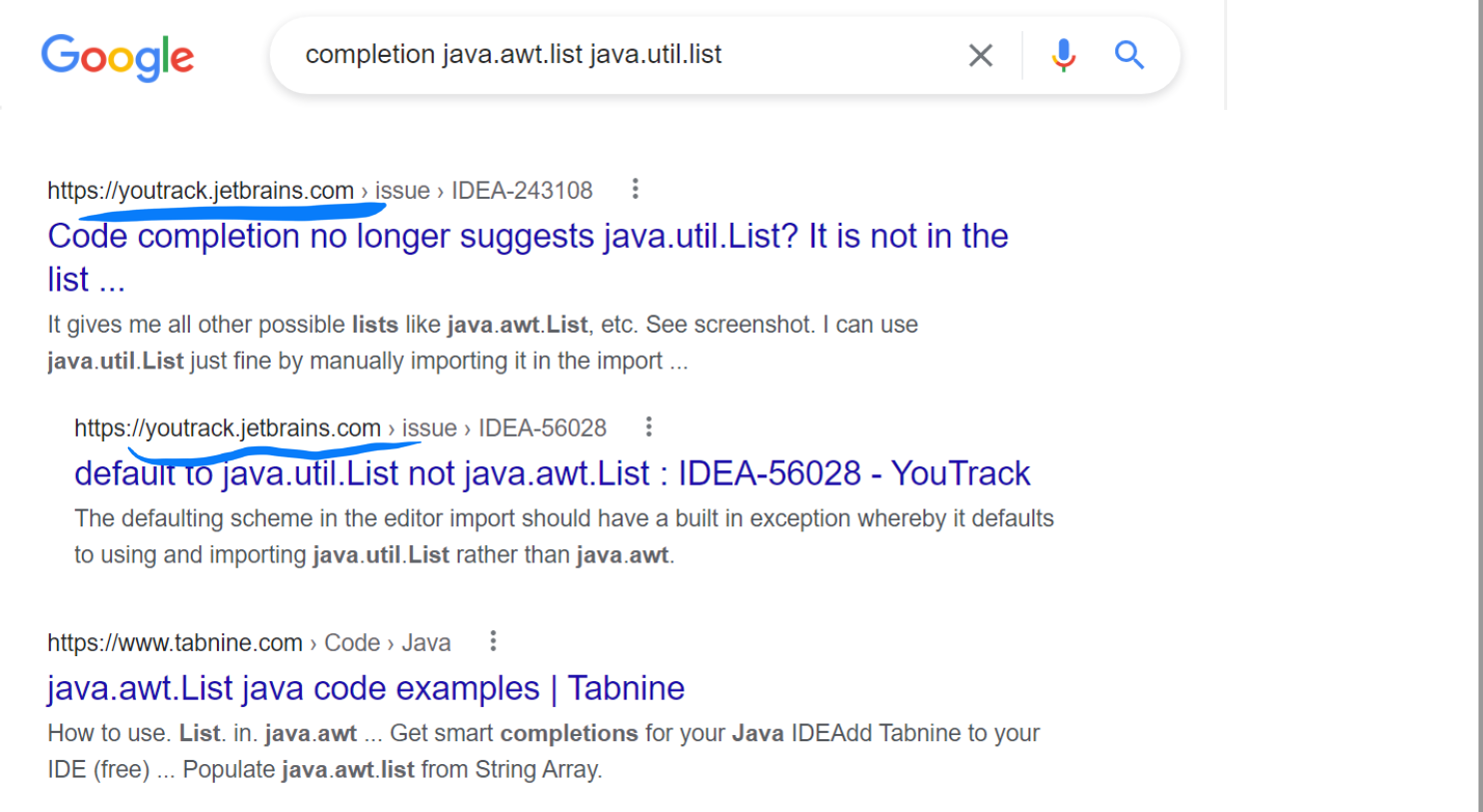
Но если посмотреть поисковую выдачу чуть дальше, то можно заметить, что та же самая проблема есть практически в любых IDE:

Для того, чтобы IDE могла подсказывать разумно, нам ещё нужно пользоваться статистикой, которую мы должны откуда-то собирать: статистика использования внешних библиотек или core-библиотек языка.
Статистика комбинаций
Допустим, мы создали новый StringBuilder, и что мы сразу же хотим с ним сделать? Если посмотреть статистику того, что на StringBuilder вызывают сразу после создания, то она выглядит примерно так:

Очевидно, что здесь надо подсказывать метод append(String str).
Интересно, что вообще второй по популярности вызова у StringBuilder метод — это toString(). Но это обычно происходит не сразу же после того, как мы его конструируем, поэтому здесь он не нужен.
Такая статистика добывается из разных источников, надо анализировать проекты соответствующего языка на GitHub, Java можно парсить на Maven Central Repository, ну и так далее. Само собой оно не получится. Не пойти ли нам на шаг дальше после этого и не просто выбирать токен, а…
Никита: …закончить строку. До этого момента мы обсуждали наше фантастическое настоящее про самопишущийся код, такое как «давайте подскажем ещё один токен кода по имеющемуся коду». А теперь давайте попытаемся закончить целую строку кода, «заказывая» её с помощью имеющегося кода.
Понятно, в этом случае мы уже вряд ли можем создать откуда-то большой список, из которого нам должна подсказать дискриминативная модель. Поэтому здесь мы уже начинаем работать генеративной моделью, потому что надо сколько-то слов, токенов предсказать вперёд, до конца строки.
Но почему мы сразу не использовали какие-то более сложные модели, чем сортировка? Это связано с тем, что тут надо было в принципе научиться работать с текстами, кодировать и переводить их в численный вид.
Пишем текст генеративной моделью
One-Hot Encoding
Исходно человечество додумалось до One-Hot Encoding. Вот у нас есть словарь всех слов на свете, к примеру, слово «man» — мужчина, человек. Давайте его закодируем так: наш вектор длины всех слов на свете, а единицей мы обозначаем, что вот это в этом векторе то самое слово. У других слов единица будет стоять в другом месте вектора.
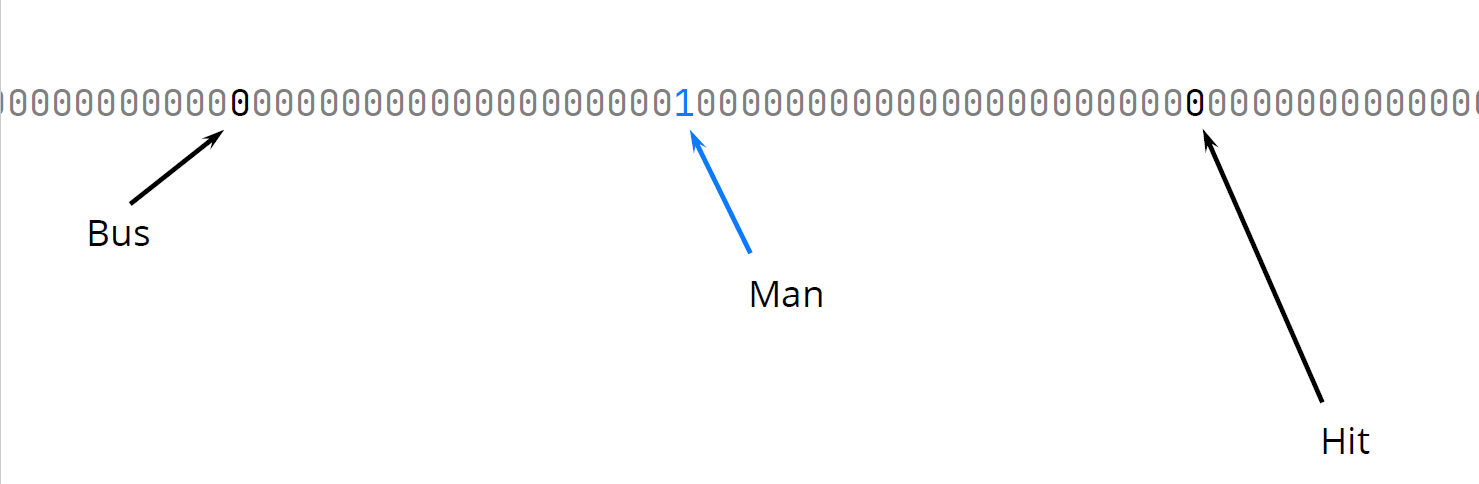
В такой системе, когда у нас гигантские sparse vectors, тяжело научиться предсказывать следующее слово. Как из одного sparse vector запомнить, что следует другой, — непонятно. Вот здесь в тексте видно, что есть слова «man», «hit», «bus», но как это выучить — непонятно:

Можно понемногу перейти к тому, что называли Bag of Words. Давайте в тексте просто сложим векторы всех слов. Получим вектор текста, который будет уже не такой sparse, там не одинокая единица болтается среди почти бесконечного числа нулей, попадаются какие-то числа.

Предсказывать с помощью этой штуки что-то по тексту, опять же, тяжело, но можно, к примеру, искать близкие или далёкие тексты и говорить, что здесь тоже, кажется, говорили о том, что кого-то сбили или не сбили. И это всё ещё дискриминативная модель над текстами, а генеративной над словами не появилось.
Word Embedding
Дальше додумались до штуки под названием Word Embedding: «Давайте попытаемся сократить размер вектора с бесконечного до фиксированной длины». К примеру, 10 или 30. Говорим: «Каждое слово кодируется набором чисел». Опять же, предположим, 10. Выписываем про каждое слово, где оно попадалось, в каком окружении слов.
Используем контексты для всех слов
A man was hit by a bus.
A man was hit by a red bus.
A woman was hit by a grey truck.
A young woman was hit by a bicycle.
An old man was struck by lightning.
Вот здесь мы видим текст, где постоянно кого-то сбивали — то с помощью автобуса, то велосипеда, то мужчину, то женщину. И вот мы можем начать потихоньку обучать эти векторы, говорить: «Давайте удалим вектор, соответствующий слову "hit", и попытаемся его предсказать на основе окружающего. Угадать, какое слово должно было быть в середине: "A man was … by a bus"».
Там идёт несколько этапов обучения, но в итоге у нас появляется для каждого слова вектор определённой длины, в котором закодирована, как ни странно, семантика. То есть мы умудрились выразить слово через контекст: возле слова «man» часто попадается «hit», возле «hit» — «man». Но не понимаем, как это произошло, потому что всё, что у нас есть, — это вектор из этих десяти цифр.
Но если на них посмотреть, то внезапно мы получаем, может быть, надоевший пример. Если из вектора, соответствующего слову «король», вычесть вектор, соответствующий слову «мужчина», и прибавить вектор, соответствующий слову «женщина», то получим вектор слова, ближайшее к которому, судя по всему, «королева»:
King – Man + Woman = Queen
А это очень большое достижение. Это значит, что мы сильно ограничили размер вектора, который кодирует слово, и при этом внесли в него семантику на тему, какие слова встречаются рядом и что они в принципе означают. Но словарь всё ещё огромный — миллионы слов.
Byte-Pair Encoding
Поэтому человечество пошло дальше и придумало Byte-Pair Encoding — способ сделать словарь поменьше. Берём весь текст как есть — с пробелами, с табами, со всем на свете и говорим, что мы начинаем его кодировать в словарь какого-то размера. Мы даже задаём этот размер — говорим, что есть лимит:
for byte in [0, 255] dictionary.add(byte);
while dictionary.size() < LIMIT {
word = mostFrequentConcat(inputData, dictionary);
dictionary.add(word);
}И мы в этот словарь сначала складываем каждый байт, который у нас есть, каждую букву — чтобы была возможность закодить всё вплоть до египетских иероглифов.
Роман: Любой юникод, который нам пришёл.
Никита: Да, любой юникод мы теперь сможем превратить в какое-то из слов нашего словаря. Пусть это слово «байт». А дальше ищем самые частые комбинации, встречающиеся во всех наших текстах, которые мы видим. И тоже их складываем в этот словарь. В итоге, если мы попадаемся на какое-то частое слово или комбинацию слов, к примеру, public static void main, мы можем это закодировать одним словом в нашем словаре. А если у нас что-то редкое, какое-то слово, которое мы не видим, типа «тензодифманометр», то можно его разбить на отдельные тензо-диф-ман-о-метр. Оно там само собой разобьётся, и у нас точно не останется нераспознанных слов, потому что у нас по минимуму байты присутствуют в нашем словаре. И мы можем сами задавать размеры того словаря, с которым работаем. К примеру, сказать, что он размером 10, 15 или 25 тысяч.
Autoregression
После этого вокруг текстов начали появляться модели, которые называются авторегрессионными. Авторегрессия — это когда у нас есть затравка, контекст. Например, «между принтером и дверью» — четыре слова. И мы предсказываем на слово вперёд, говорим: «Скажи что там дальше будет», получаем в ответ токен: «Восседает».
А затем предсказываем дальше. Все ещё используем контекст в четыре слова, но теперь подставляем в него последние четыре слова, которые у нас есть («принтером и дверью восседает»). Так идём дальше и дальше.
И в какой-то момент уходим от затравки. То есть от «между принтером и дверью» мы дошли до «восседает суперюзер кибердемону подобный». Этих слов не было исходно. И то, на чём мы будем дальше предсказывать, — это контекст, которого мы раньше не видели.
До появления ограниченных словарей, авторегрессия, понятно, была как идея. Теперь нам, как человечеству, надо было научиться создавать модели, которые могут учитывать как можно больше контекста — чтобы эффективно предсказывать вперёд. И одной из самых известных первых моделей стала GPT-2, сделанная OpenAI. Она умудрялась учитывать 1024 токена в длину в контексте как затравку, как prompt.
Роман: То есть это предыдущий текст, по которому надо предсказать следующее слово?
Никита: Да, следующий токен, и продолжать, сдвигая эти 1024 токена контекста. При этом токены не в терминах натурального языка или кода, а те, которые накодили с помощью Byte-Pair Encoding. И, чтобы эффективно работать с таким контекстом, оказалось, что надо полтора миллиарда параметров. Это количество чисел, констант, которые, скажем так, надо помнить, чтобы эффективно работать с такой длиной контекста, более или менее корректно предсказывать слова.
Роман: Давайте посмотрим на некоторые инструменты, которые пользуются этой техникой. Например, довольно известный плагин Tabnine пытается закончить строчку, которую пишет программист. Давайте посмотрим, как это работает, и немного разберёмся в том, какие фундаментальные трудности есть в этой деятельности. Будем писать код, который создаёт амазоновский Bucket.
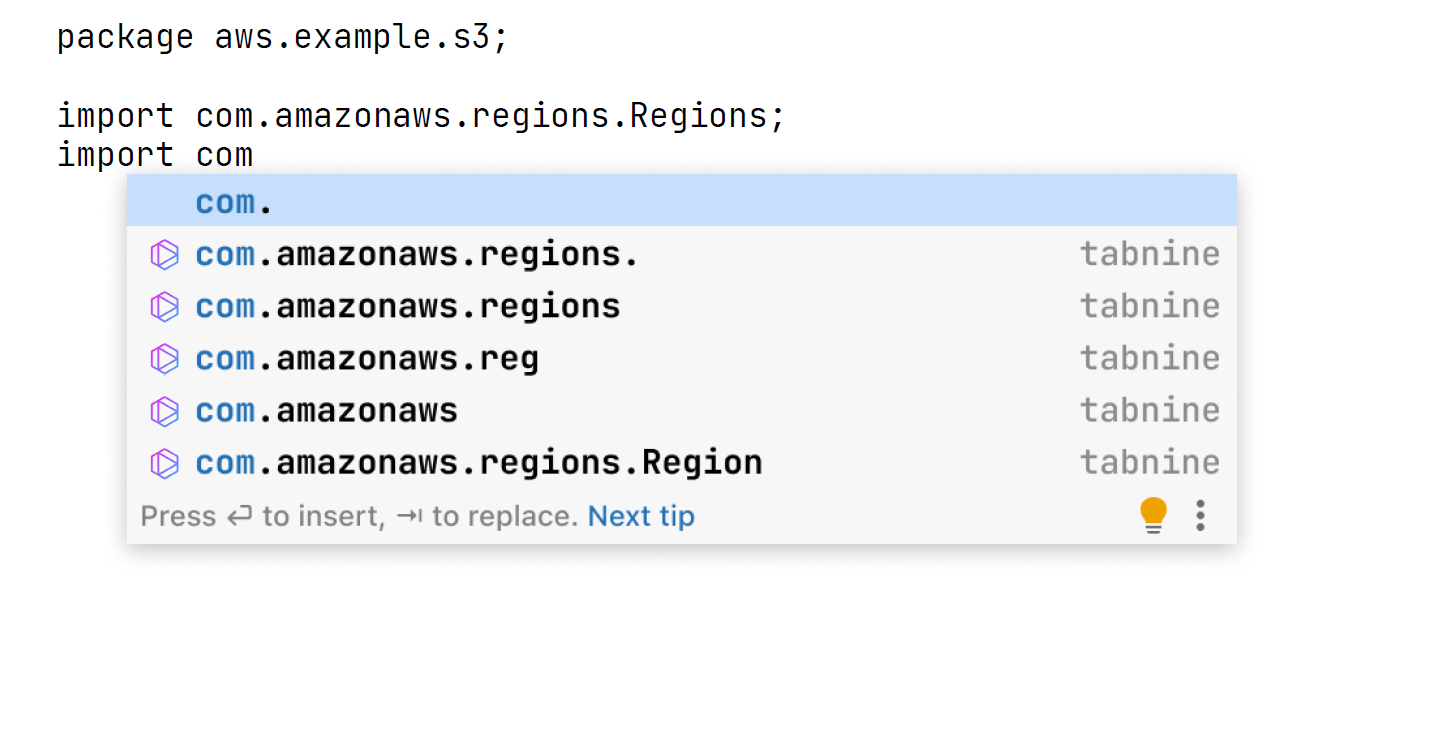
Видно, что родная подсказка из IDE на первой строке предлагает продолжить точкой, и это верно, но не особенно полезно. А есть подсказки от Tabnine, которые дают на самом деле хорошие варианты для человека. Мне кажется, что это очень классно, то есть это победа и улучшение жизни программиста. Но это же и иллюстрирует некоторые трудности, которые есть в этих моделях.
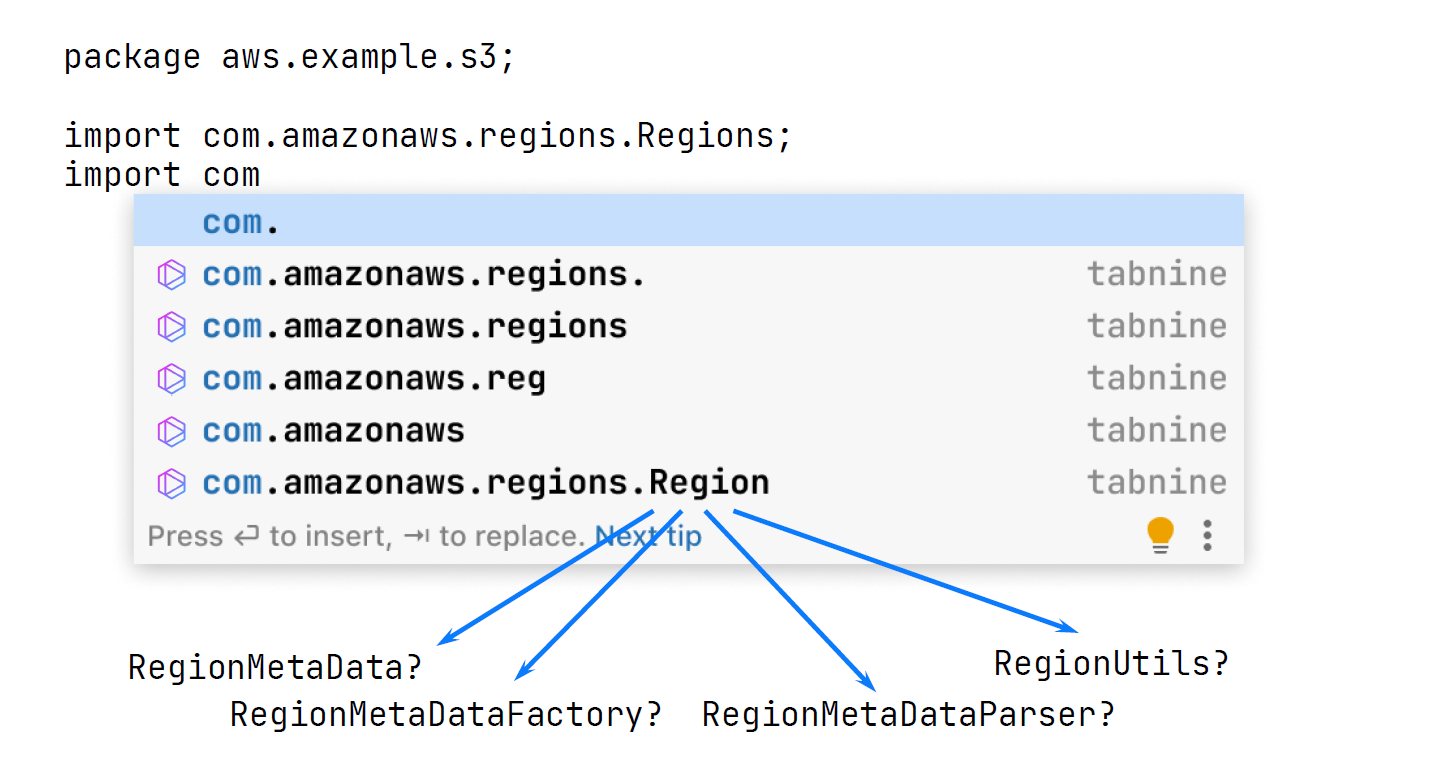
В частности, в пакете есть четыре класса, которые начинаются со слова Region: RegionMetaData, RegionMetaDataFactory, RegionMetaDataParser и RegionUtils. И почему бы не пойти дальше?
Трудности генеративных моделей
Когда пора остановиться?
Никита: Есть некоторая проблема. Если наивно имплементировать генерацию, делать просто авторегрессию с помощью нейронных сетей, то непонятно, когда остановиться. Потому что как это наивным образом пишется: вот пока вероятность того, что мы предсказываем, большая — выводи, как только вероятность резко упала — давайте перестанем выводить. В этом примере так и работает: дошли до Region — до Region всё вероятно, точно надо. А вот после этого непонятно — то ли MetaData, то ли DataFactory, то ли Utils, давайте остановимся. Здесь нужна доработка напильником. В базовой наивной имплементации не работает.
Роман: Да, но тем не менее, мы что-то выбрали и пишем дальше.

Трудности начинаются здесь, потому что не очень хорошо, мне кажется, показывать множество вариантов, из которых почти все для человека выглядят примерно одинаково.
Что делать с дублями?
Никита: Дубли возникают по такой же причине — они все одинаково вероятны между собой. В наивной имплементации непонятно, как их различать. Public static void main — ну, кажется, вероятен, как и всё, что на него похоже, и надо показывать новые вероятные варианты. То есть в наивной имплементации не учитывается разнообразие всей выдачи, а только то, насколько хорош каждый отдельный вариант. В связи с этим попадает куча очень похожих вариантов. Но опять же, это то, что надо понемногу дорабатывать, а не мегафундаментальная проблема.
Роман: Давайте дальше писать. Досоздадим этот Bucket, и в процессе возникает ещё одно место с фанфарами, ради чего эти штуки и затеваются. Когда оно вдруг раз — и может нам подсказать прямо целую строку, достаточно длинную, с несколькими токенами, причём ровно такую, какую мы хотели:

В общем, время от времени это бывает, и это очень классно.
Так примерно можно на GPT-2 дополнять строки, но можно пойти ещё дальше.
Никита: Можно попытаться учитывать контекст побольше, взять вообще все тексты на свете, которые когда-либо были, взять контекст, удвоить шаг. Но вот количество параметров, которые пришлось делать, выросло гораздо больше, примерно в 100 раз. К этому добавили GitHub и получили то, что мы сейчас называем GitHub Copilot, за которым прячется модель под названием Codex.
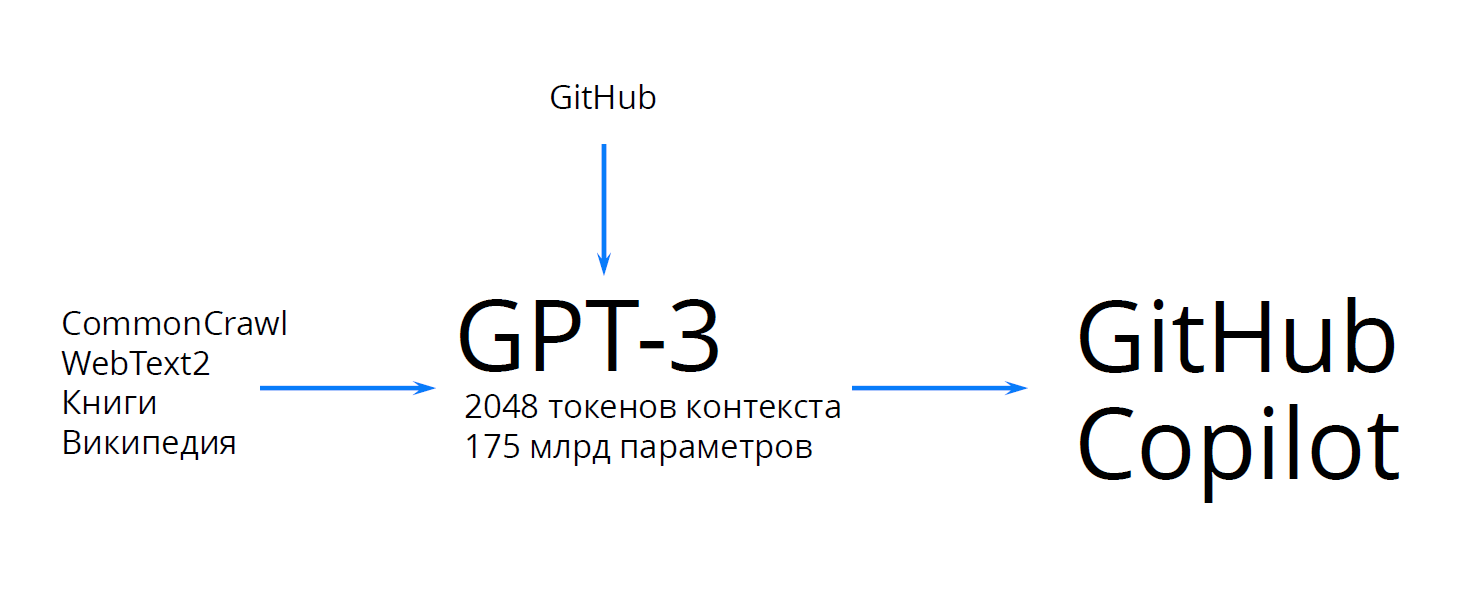
Она уже решает задачу самопишущегося кода не в виде «вот у нас есть сколько-то кода и мы даём токен или строчку кода дальше», и можно заказывать уже прямо c помощью нативного языка — тот самый подход, который критиковал Дейкстра.
Сколько же это стоит?
Внезапно сделать такую систему дорого. Теоретически можно ограничиться 5 миллионами долларов, но тогда на обучение с текущими скоростями потребуется больше 300 лет (и непонятно, когда оно удешевится). Или, чтобы сделать это в более разумный срок, надо потратить в районе 12 миллионов долларов. При этом это обучение не на весь проект с нуля, скажем так, как если бы мы сегодня решили сделать Codex — потратим 12 миллионов, нет. Это на одну итерацию полного обучения готовой архитектуры, и её надо ещё найти, а это стоит уже гораздо дороже.
Роман: Много-много раз по те же самые 12 миллионов.
Никита: Ну, в какой-то момент чуть меньше, может быть, 2-6, а потом, когда проект подрастет, то много раз по 12. По оценкам разных людей, OpenAI вложил несколько сотен миллионов долларов в то, чтобы сделать Codex для нас, за что им честь и хвала. Но при этом сам CEO OpenAI Сэм Альтман в одном из интервью говорит, что создание GPT-3 при текущих планирующихся ценах на Copilot на Codex никогда не окупится. Надо бежать дальше.
Это вторая большая проблема. До этого мы вечно говорили «нет данных для обучения», и это было когда просто добавить следующий код, следующий токен.
А теперь, когда мы хотим заканчивать больше, чем строку, то внезапно начинаем упираться в нехватку вычислительных ресурсов, которую, тем не менее, кто-то может устранить, но за большую сумму денег.
Роман: Когда проблема решается деньгами, это не проблема, а расходы.
Никита: Надо посмотреть внутрь штуки, которой мы можем ставить задачи с помощью нативного языка, как говорил Дейкстра.
Ставим задачи
Пришло ли время для восстания машин? Мы попытались захватить мир старым способом из научной фантастики. Мы заказали: «Давай, SkyNet, захватывай для нас мир!»: сделали метод класс SkyNet с методом launchRockets(). Что предложит машина в качестве тела такого метода?
package com.awesome.project;
public class SkyNet {
void launchRockets() {
System.out.println(“Launching rockets”);
}
}Видимо, он над нами пошутил.
Роман: А что мы ждали? Давайте попробуем ещё. Так мир захватить не удалось, давайте по-другому, через Матрицу. Дадим такую затравку:
package com.awesome.project;
public class Matrix {
private Morpheus morpheus;
private TheOracle theoracle;
public static class Zion {
}
}И спросим, что он будет делать с Зионом:
public static class Zion {
public void destroy() {
}
}Он будет его разрушать! Мне кажется, что это очень круто, потому что он знает, что в мире «Матрицы» надо делать с Зионом. Откуда?
Никита: Потому что сначала всё было предобучено на всём интернете. Во всём интернете благодаря сёстрам Вачовски знают, что надо делать с Зионом.
Роман: То есть он не просто про код, код — это надстройка сверху, а он очень много знает про нашу культуру, мемы, и это очень круто! Но давайте к делу — искать Нео.
package com.awesome.project;
public class Matrix {
private Morpheus morpheus;
private TheOracle theoracle;
public Location findNeo() {
return morpheus.findNeo();
}
}Ещё одна интересная мысль здесь. Он совершенно спокойно вызывает методы, которые ещё нигде не определил. Он их вызывает, остановился, молодец. Как он это делает?
Никита: Примерно так же, как во всём мире, на котором он обучался: иногда код попадается до того, как его определили. Он же не завязан на статическое существование, достижимость и прочее. Может позволить себе.
Роман: Тем не менее, он умеет останавливаться где надо. Останавливается он в определённых, хороших местах.
Никита: Это как раз та самая доработка напильником. Есть наивные проблемы, но их можно решить.
Роман: Пойдём дальше. Вот он нам говорит, что у Морфеуса есть метод findNeo(), мы говорим: «Расскажи нам, пожалуйста, что делает Морфеус в этом месте?»
public Location findNeo() {
return morpheus.findNeo();
}
public static class Morpheus {
public Location findNeo() {
return new Location(1, 2);
}
}
}И тут суровые сибирские мужики говорят: «Ну, сломалась машинка! Выдаёт какую-то ерунду».
Как избежать глупостей?
Никита: Ерунда всегда будет, особенно если мы сами пытаемся заказывать бессмыслицу. Потому что дайте нам любую бензопилу, и мы начнём сначала подсовывать ей всё более толстое дерево, а потом, как в анекдоте, подсунем рельс и скажем: «Ну всё, надо писать в Vim, как вчера».
Роман: Позавчера.
Никита: Позавчера. Тем не менее, в таких местах, где пытаются спровоцировать, можно либо как SkyNet пошутить в ответ, либо, если пытаются спровоцировать, скажем так, на скандал, даже случайно, то можно сделать так: банить конкретные предзаданные слова и выражения, чтобы нечаянно не получить какое-нибудь забавное социальное выражение, которое нас сейчас и, в общем-то, никогда не устраивает.
Баловаться «давайте подразним то, что пытаются называть искусственным интеллектом», прикольно, но хочется нормальных задач.
Ладно, несите нормальные задачи
Роман: Давайте попросим Фибоначчи.
package com.awesome.project;
public class NumericalUtil {
public static int fibonacci(int n) {
if (n == 0) {
return 0;
} else if (n == 1) {
return 1;
} else {
return fibonacci(n - 1) + fibonacci(n - 2);
}
}
}Что ты видишь здесь, Никита?
Никита: Ну, я это уже видел, так что мне проще увидеть, но тем не менее. Отрицательные числа мы тут не обрабатываем.
Где-то это обычно работает как учебный пример. Фибоначчи так писать нельзя, потому что будет запредельная сложность из-за рекурсии. Так обычно изображают, что, вот, выучите мемоизацию. Пока в Java её встроенной, готовой, простой, выданной кем-то нет. Может быть, это потом исправится, и наш доклад устареет.
Роман: Но он мог бы, раз такое пишет, и сам сделать мемоизацию, но не сделал. Тем не менее, тут можно, кажется, попробовать ещё раз.
Никита: Попробовать ещё раз — это вообще забавная концепция. Андрей Карпатый — один из тех, кто стоял у истоков OpenAI. Много чем известен, но тем не менее, он когда-то активно пропагандировал идею Software 2.0, говоря, что теперь софт надо писать не вбивая куда-то код, а меняя датасеты, на которых уже учить машинное обучение, которое само по себе Soft 2.0.
Роман: Раньше были просто требования, но сейчас мы никакого ТЗ не пишем, а просто выдаём датасет и набор правильных ответов, и дальше оно должно само.
Никита: И в зависимости от данного набора ответов или датасета может поменяться наша программа.

А дальше он пошутил (надеемся, что пошутил), что Software 3.0 — это совсем новая штука, в которой надо уже не подтаскивать новые датасеты, а пытаться изобрести строку, с которой надо обращаться к «о, великому» трансформеру или искусственному интеллекту, чтоб он выдал тот самый код или нужный ответ.
Ящик водки и всех обратно
Роман: Оказывается, что с Copilot даже не обязательно менять затравку, можно повторить, и он может выдать нам другой результат.
public class NumericalUtil {
public static int fibonacci(int n) {
if (n < 0)
throw new IllegalArgumentException(“n must be positive”);
if (n == 0 || n == 1) return n;
int a = 0;
int b = 1;
for (int i = 2; i <= n; i++) {
int c = a + b;
a = b;
b = c;
}
return b;
}
}Что мы видим здесь? Во-первых, отрицательные значения теперь у нас обрабатываются, ура. Вот так бы я бы никогда в жизни не написал:
If (n == 0 || n ==1) return n;
Это правильно и хорошо, мне не приходит в голову написать это условие в одну строчку так, как это делает нейросеть.
Разберемся, как работает написанная здесь арифметика:
Сначала мы определяем a (int a = 0) и b (int b = 1).
Создаём c, в которое мы складываем сумму (int c = a + b).
Потом мы b перетаскиваем в a (a = b), а затем сумму перетаскиваем обратно в b.
Ну, и в конце можем вернуть b.
И кажется, что это, вроде бы, правильно. На первый взгляд, здесь не видны баги, вроде бы так и должно быть.
Никита: Важно, что нам пришлось подумать. Мы не просто заказали код, один раз мы его заказали, получили тот, который нас не устроил, заказали ещё раз, получили и проделали умственные усилия, чтобы проверить, что он нас устраивает.
Роман: И это именно в написании кода. Хочется немного поговорить о том, что это, может быть, не самая эффективная трата наших сил.
Держать в голове связи между сущностями
Смотрите, этот кружочек символизирует наш 8-часовой рабочий день. У нас есть статистика по пользователям IntelliJ IDEA Ultimate Edition. Это профессиональные программисты, у которых есть профессиональная лицензия на IDE. Так вот, из этих людей половина работает в IDE меньше 50 минут в день.

Работают в IDE — это значит, IDE у них в foreground находится. Ладно, пусть не половина, давайте возьмём 95%.
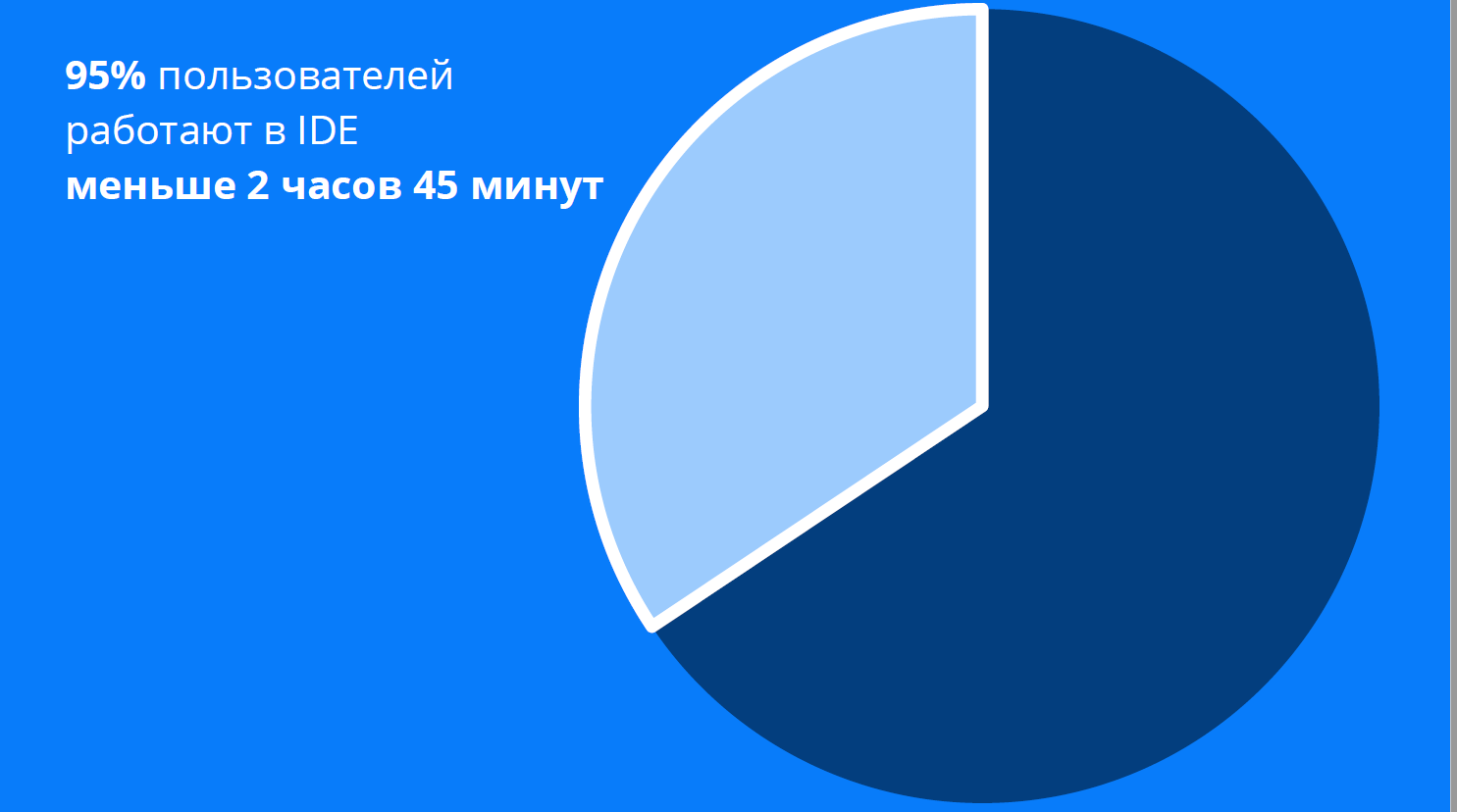
95% пользователей работают меньше 2 часов 45 минут, и только 5% — больше. Возьмём этого продуктивного пользователя, который как раз работает примерно три часа в день. При этом у него IDE открыта в foreground, но он печатает код 8,2% этого времени, то есть примерно 14 минут в день.
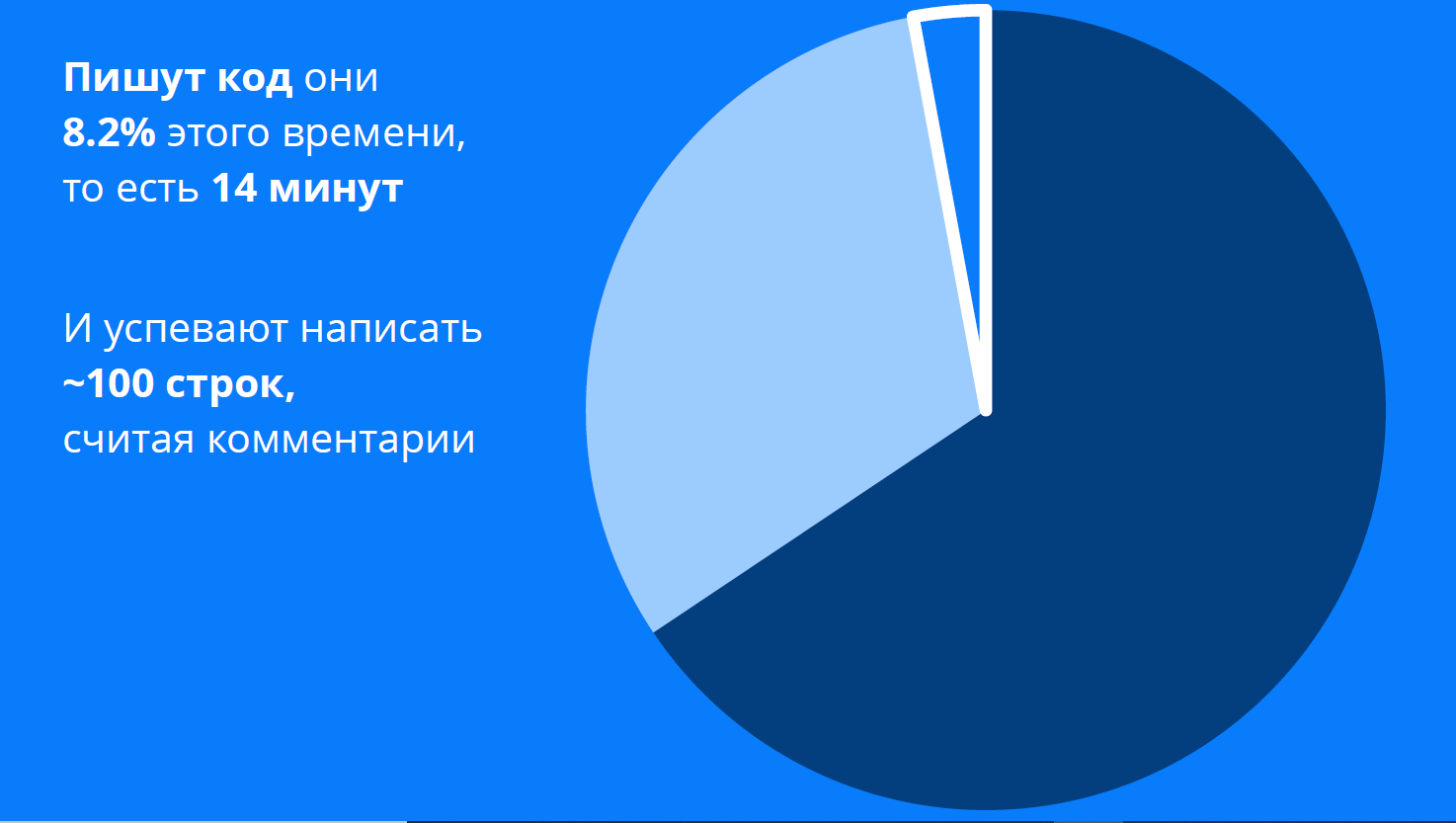
И этот продуктивный пользователь с 95% за день успевает написать примерно 100 строк кода, считая комментарии. Всё остальное время программист изучает код, пытается понять, что происходит.
Никита: Держит все связи, сущности или, по крайней мере, ту часть архитектуры, программы, которая нужна, чтобы провести над ней изменения, понять, где можно перестроить связи, создать новые сущности так, чтобы всё работало как надо. Сам процесс написания кода в этом занимает не очень много времени, и это не самая profitable часть. Видимо, основная часть того, что мы делаем, происходит не в момент, когда пальцы касаются клавиш, а когда мы смотрим на код и крутим его в голове.
Основная теорема генерации кода звучит так: если мы внезапно начинаем заказывать код натуральным языком, то это оказывается для нас выгодно, если поставить задачу и проверить результат для нас дешевле, чем сделать самому.

На втором примере с Фибоначчи мы увидели, что, проверка результата тоже занимает время. Может, и самостоятельное написание кода могло занять больше времени, но, тем не менее, надо понимать, что здесь нужно не только поставить задачу и получить результат, а есть ещё процесс проверки.
Счастливое будущее
Перейдем к кодогенерации, которая будет в дальнейшем. Кажется, мы ожидаем, что потихоньку будем заказывать всё больше и больше кода с помощью обычного языка и куда-то двигаться. Что мы про это сейчас знаем?

Вот Сэм Альтман на одном из митапов сказал, что GPT-4 на подходе, она не будет сложнее именно по размерам, по числу параметров, но будет потреблять больше контекста, брать строку большего размера в работу. И при этом будет сосредоточена на коде — ура, кто-то ещё решил выкинуть кучу денег на то, чтобы нам было ещё удобнее писать код. Это очень круто. Тем не менее, когда мы начинаем двигаться в сторону с блоками большего размера, то вместе с этим движемся в сторону «большого» искусственного интеллекта, про который до нас уже рассуждали известные люди. К примеру, есть Элиезер Юдковский.
Роман: Большей части из нас он известен как автор книги «Гарри Поттер и методы рационального мышления».
Никита: Центральная фигура сообщества рационалистов, LessWrong, CFAR и прочие. Но, тем не менее, он один из основателей и лидеров института MIRI, который занимается безопасностью искусственного интеллекта. И он в рамках этого пытается придумать методы обезопаситься от того искусственного интеллекта, который мы можем внезапно изобрести.

Он говорит следующее: если у нас внезапно появится бесконечно мощный джинн, у него достаточно тяжело попросить вечную жизнь так, чтобы потом не пожалеть.
Роман: Да у него вообще что угодно тяжело попросить. Но на примере вечной жизни можно посмотреть.
Попросим у джинна вечную жизнь?
Никита: Да, есть такой проект «Желание» (The Open-Source Wish Project). Попробуем попросить вечную жизнь, богатство, счастье, так, чтобы ни на что не нарваться. И вот до чего ребята додумались на примере вечной жизни. Хочется жить не в качестве камня. Они предусмотрели, что не надо жить вечным стариком, надо возвращаться в более молодой возраст, а для этого надо назвать какое-то число между «one and two hundred» — и вот здесь уже может быть ошибка.
I wish to live in the locations of my choice, in a physically healthy, uninjured, and apparently normal version of my current body containing my current mental state, a body which will heal from all injuries at a rate three sigmas faster than the average given the medical technology available to me, and which will be protected from any diseases, injuries or illnesses causing disability, pain, or degraded functionality or any sense, organ, or bodily function for more than ten days consecutively or fifteen days in any year; at any time I may rejuvenate my body to a younger age, by saying a phrase matching this pattern five times without interruption, and with conscious intent: 'I wish to be age,’ followed by a number between one and two hundred, followed by ‘years old,’ at which point the pattern ends — after saying a phrase matching that pattern, my body will revert to an age matching the number of years I started and I will commence to age normally from that stage, with all of my memories intact; at any time I may die, by saying five times without interruption, and with conscious intent, 'I wish to be dead’; the terms 'year' and 'day' in this wish shall be interpreted as the ISO standard definitions of the Earth year and day as of 2006.
Здесь уже джинн может решить, что имеется в виду возраст между 100 и 200 годами, а не 1 и 200 годами.
Понятно, что не хочется пережить тепловую смерть Вселенной, поэтому ребята предусмотрели в своей просьбе джинну возможность программировать момент смерти. Для этого надо пять раз произнести что-то, при этом «произнести» — само по себе опасно. В том смысле, что оказался в вакууме — уже ничего не произнесёшь, потому что воздуха нет, звуковые волны не распространяются.
То есть они, вроде бы в попытке задать очень узкие условия джинну, чтобы тот дал им ту самую длину жизни, которую они хотят, всё равно оставили, кажется, до сих пор слишком много свободы — на наш взгляд программистов. При этом они попытались задать что-то в терминах ISO, где-то очень свободно, а где-то — давайте думать, что такое ISO. Непонятно, как объяснить джинну, что это такое, но тем не менее.
Создадим эволюционное давление на жуков, чтобы ограничить их размножение
Другой пример, который приводят исследователи будущего «общего искусственного интеллекта» (general AI) и Элиезер — это известный эксперимент 1976 года с жуками.
Периодически человечество задумывается, как бы не вырасти по экспоненте и не съесть все ресурсы на планете. Захотелось разобраться, а как бы научиться жить меньшей популяцией — решили попробовать создать эволюционное давление на определённый вид жуков, чтобы они научились ограничивать своё размножение.
Роман: Жуки называются «малый булавоусый хрущак».
Никита: Зная такое, надо гордиться, что знаешь.
Логика была такая: сделаем несколько популяций, живущих отдельно, и всех, в которых получилось слишком много особей, уберём, а продолжим размножать тех, которых мало. И так много раз. У жуков поколения меняются достаточно быстро, их сколько-то раз прогнали и получили популяцию, которая действительно ограничивает свой размер — не размножение, а размер. Давление-то мы через размер оказываем. Получились такие популяции, и дальше стало интересно посмотреть, а что они делают: рожают поменьше, вынашивают подольше, заводят семьи странного размера?
Обнаружили такое, что ужаснулись. Выяснилось, что наилучший способ ограничить популяцию с точки зрения эволюции (то, к чему эволюционно пришли жучки) — поедание чужих детей, в первую очередь девочек. Тогда популяция будет маленькой, ещё и не будет вхолостую расходоваться полезный белок. С точки зрения эволюции как джинна, которому мы заказали маленькую популяцию, всё очень эффективно. С точки зрения людей, которые проводили этот эксперимент, всё ужасно, потому что они не такого хотели.
Сейчас понятно, что во вселенной Marvel повезло, что Танос оказался достаточно умным, чтобы «всего лишь» заказать гибель половины всех существующих видов и людей. Если бы он заказал: «Сделайте так, чтобы популяции были маленькие и им хватало ресурсов», то «Война бесконечности» могла закончиться не столь «мирно», как всего лишь превращением в пыль половины всех цивилизаций.
Собственно, к чему это? Эволюция выступает в роли джинна, бесконечно мощной штуки, которой мы что-то заказываем и внезапно выясняем…
Роман: …что нам очень трудно сделать полный заказ. Нам кажется, что из перечисленных ранее шести проблем в общении с человеком самый существенный пункт — неполнота, потому что мы вроде бы заказали что хотим, но забыли описать этические или прочие условия, которые на самом деле есть у нас в голове.
Как выглядит этот «интерфейс»?
Никита: Если мы сами дальше будем что-то заказывать у машины, которая станет всё более и более умной, то нам надо будет научиться её ограничивать с точки зрения финального результата. Здесь мы, действительно, можем столкнуться с тем, что описывать задачу станет дороже, чем сделать самим, если поставим ограничения по памяти, ЦПУ и платформе. И мы, наверное, не можем предусмотреть всех возможных отрицательных последствий того кода, который мы закажем и, может быть, не сможем проверить.
Когда мы заказываем код на уровне небольшого метода, то примерно представляем, как его сделать и проверить, как увидеть там проблемы Фибоначчи. Но если переходить к заказу фрагментов кода побольше, на уровне написания всей программы, то это уже оказывается не просто задача работы с кодом, а стандартная задача, над которой мучаются все создатели искусственного интеллекта. Сейчас, кажется, человечество не очень представляет, как выглядит этот интерфейс для заказа глобальных вещей.
Собственно, тут мы упёрлись примерно в то же самое. Кажется, что есть штука, которая нам хорошо отсортировывает и подсказывает один токен, есть в каком-то виде строка кода; есть, даже пусть за кучу денег, что-то предсказывающее метод. Но с точки зрения интерфейса непонятно, как пойти дальше.
Роман: То есть речь идёт не про визуальный, а про концептуальный интерфейс. Интерфейс того, как вообще человек может передать своё желание в эфир.
Никита: Как туда добавить весь контекст человека со всеми ограничениями вида «не убить всех человеков на земле».
Роман: Да, поэтому, скорее всего, мы в самое ближайшее время фундаментальной трансформации индустрии не ждём.
Если кому-то интересно — варенье было в зелёной коробке!
И закончить наше выступление хотелось бы цитатой сооснователя Яндекса Ильи Сегаловича, которая, пусть в шуточной форме, но достаточно точно резюмирует происходящее.

Пункт первый: прогресс неостановим.
Пункт второй: работать всё равно ничего не будет.
Статья Дейкстры с критикой идеи программирования на естественном языке
Лекции Хэмминга об искусственном интеллекте: раз и два
Статья Чарлза Рича и Ричарда Уотерса A Programmer’s Apprentice
Оценка стоимости обучения GPT-3
О фильтрах слов в Github Copilot
Программная статья Элиезера Юдковского о рисках искусственного интеллекта
Одна из версий проекта «Желание»
Статья Майкла Уэйда о бесчеловечных экспериментах над жуками
Это был доклад с Joker 2021 — а мы тем временем уже вовсю готовим Joker 2022, где тоже будет много контента для Java-разработчиков. А если вы не джавист, можете посмотреть на список всех наших конференций сезона: там много всего от .NET и JavaScript до дата-инжиниринга и видеотехнологий.
Комментарии (13)

PastorGL
16.08.2022 17:33+3Написание любой сколько-нибудь развитой системы равносильно по мощности проектированию отдельного искусственного языка. Классы являются существительными, методы — глаголами, атрибуты и аргументы — прилагательными, и так далее. И чем сложнее система, чем больше у неё внутренних правил, тем более развит её DSL.
Соответственно, код большого проекта с какого-то момента превращается в набор предложений на таком внутреннем языке, где инстансы классов, вызовы методов, и т.п. выступают различными частями речи в зависимости от контекста, и платформенный язык превращается в низкоуровневый слой. В проекте на полмиллиона строк кода на Java новые куски пишутся не вовсе на Java на самом-то деле, а скорее на существующем API.
Так что задача генерации кода at large scale на самом деле не является задачей сгенерировать что-то внятное на каком-то языке программирования, а скорее задачей сгенерировать самостоятельный язык, и перевести уже этот DSL в облик языка программирования.
И вот почему-то лично мне кажется, что разработчики assistive tools на таком уровне мыслить всё ещё не научились, от чего и особенного прогресса в этой области (равно как и большой пользы от самих инструментов) не видно.

leventov
16.08.2022 21:56Любые большие рабочие системы (на полмиллиона строк) выросли из небольших рабочих систем (закон Галла). Задача с кондачка написать систему на полмиллиона строк в любом случае в большинстве ситуаций - абсурдна, вне зависимости от того, пишет ее команда людей или ИИ (проекты типа программирование Боинга или Спейс-Шаттла предлагаю вывести за скобки, иначе обсуждение слишком большое будет). Поэтому ИИ сначала сделает что-то совсем невнятное из короткого описания концепции системы и пары ключевых функций. Потом, если ИИ сразу сделал не то, что хотел системный дизайнер - последний уточнит описание (требования/ТЗ/документацию), чтобы ИИ выдал нужный результат. Потом проверка прототипа в продакшене, фидбек от пользователей, добавление новых функций - все можно оформить как дополнения документации, юз-кейсы. И система органически растет. Если архитектура неэффективна - тоже можно оформить это как архитектурное требование, типа скормить ИИ architecture decisioin record, на основании которого оно сделает рефакторинг архитектуры.
Поэтому роль системного дизайнера и архитектора не уходит, пока нет AGI. Но роль программиста уходит полностью. Это ровно то, про что говорит Karpathy
PastorGL
16.08.2022 23:27Позволю себе не согласиться. В энтерпрайзе системы часто сразу создаются большими, а вовсе не вырастают из маленьких.
Я пару раз участвовал в разработке нескольких программных комплексов, у которых только эскизный архитектурный дизайн занимает сотни страниц (а частные ТЗ на модули и вовсе измеряются тысячами), и хорошо знаю, как там что. Так что простите, но вы говорите ерунду. В промышленном программировании никакого «органического роста» не бывает.
Система сразу проектируется на своём «птичьем» языке, и один только глоссарий, описывающий терминологию прикладной матмодели, может занимать десятки страниц. И ведь каждому из терминов может соответствовать несколько интерфейсов, эндпоинтов, структур данных в хранилище, и прочей требухи, представляющей его в коде.
Так вот, assistive tools по идее должны бы приносить наибольшую пользу именно в тех случаях, когда трудозатраты измеряются многими тысячами часов десятков разработчиков, но на практике ни фига подобного не происходит: инструменты не умеют понимать внутренние системные DSL.
Попытки кодогенерации на основе описаний (BPMN, UML, и т.д.) существуют, но большой пользы от них, опять же, не чувствуется.
leventov
17.08.2022 08:11+1Даже если система сразу планируется большой, она не проектируется обычно сразу "от и до", то есть, в момент начала кодирования, ещё не до конца понятно, что там будет за требуха, понадобится несколько баз или можно будет ограничиться одной, в какой момент данные будут архивироваться, и т.д. Исключение - строго top-down проектирование и кодирование вроде Спейс-Шаттла, когда до начала кодирование системная архитектура уже разработана полностью, в мельчайших деталях. Если ваши системы были именно такого типа - ок, хотя в моем представлении о мире, такое встречается действительно редко, потому что это очень дорого.
Поэтому вы все равно начинаете с некоторой болванки, набора интерфейсов без реализаций, чтобы понять, удобно ли в них кодить или нет, настраиваете CI, и итерируете оттуда. Разница с тем, что я описал в предыдущем комментарии только в том, что это не публичные итерации.
То, что система сразу проектируется в некотором DSL, я не вижу проблемой: ну скормить глоссарий ИИ можно будет точно так же. Сейчас это кажется фантастикой, потому что few-shot learning ещё не настолько мощный, чтобы ИИ понял, что надо писать, по одному описанию. Но это вопрос исключительно скалирования, глубины модели.

powerman
16.08.2022 18:26Возьмём этого продуктивного пользователя, который как раз работает примерно три часа в день. ... И этот продуктивный пользователь с 95% за день успевает написать примерно 100 строк кода, считая комментарии.
А если взять не этого "продуктивного" пользователя, а менее продуктивного: среднее значение из первой половины, которые работают в IDE меньше 50 мин./день - сколько тогда строк кода в день получится?

Nialpe
16.08.2022 18:59Плюс придется вводить коэффициент лаконичности языка))) Бытует мнение, что одни языки более многословны, чем другие.
powerman
16.08.2022 19:28+1На практике это не настолько принципиально, как кажется на первый взгляд. Как верно отметил@PastorGLчуть выше - вне зависимости от языка в любом нетривиальном проекте появляются собственные, более высокоуровневые, абстракции, и дальше код пишется в значительной степени на них, в результате чего количество строк в большей степени определяется выбором абстракций, нежели языком. Есть, конечно, крайние случаи вроде ассемблера или языков разработанных для определённого типа задач, но для популярных современных языков общего назначения большой разницы не будет.

H737
16.08.2022 22:02+3"Уволят через десять лет всех программистов или нет?"
Такие байки пишут и про водителей и про бухгалтеров и про кассиров, но что-то светлое будущее все не наступает.
Водителей автопилот вроде как может заменить, но что-то не складывается пока у Илона Маска.
Кассирам уже вроде как есть альтернатива в виде терминалов самообслуживания. Пользовался терминалами с 2020 г, чтобы маску в магазинах не одевать.
Как так?
ksbes
17.08.2022 11:35Прямая, наивная роботризация («робот-кассир») — всегда невыгодна. Человек — дешевле робота.
Просто потому что бог-батюшка и/или природа-матушка уже о многом позаботились в плане ремонта и приспособления под конретную задачу — только калорий подкидывай. А тоже самое у роботов приходится делать человеческими же ручками.
Т.е. прямая бездумная робо-замена человека только увеличивает потребность в человеческом труде.
Кассы самообслуживания тут как раз пример хорошей «роботризации» — надо менять процесс так, чтоб от роботов была польза.
В плане сабжа статьи — это должен быть, например, умный кодогенератор бойлейрплейтов из схем (для последушей ручной дописки), очень умный линт/оптимизатор (способный преписать сортировку пузырком на быструю), умный поисковик по библиотекам и пакетам и т.п. инструментарий
А писать готовые программы просто по словестному описанию — это потом тратить кучу времени на переделку, а потом тратить ещё раз, когда заказчик попросил добавить маленькую фичу.

Groramar
17.08.2022 17:40У нас в магазинах одной торговой сети уже примерно половина кассиров заменена кассами самообслуживания. И это даже без всякого ИИ. Думаю что вопрос недалекого времени когда плавно заменят перечисленных.

allter
17.08.2022 11:59+2Вместо дополнений бойлерплейтов лучше бы занимались автоверификаторами. Нафига мне джуны, которые на пару с ИИ-джунами будут писать код, который потом вручную придется проверять на рейсы/дедлоки/кривую обработку исключений (в т.ч. с учетом взаимодействия с внешним миром)?
leventov
Спасибо что уже не глухое отрицание в стиле "программистов никогда не заменят, и через 100 лет", которое было популярно (и, возможно, до сих пор популярно) на Хабре год-два назад.
У кодовых/программерских/оптимизационных моделей очень большое будущее и прогресс будет быстрее, чем все ожидают. Помимо наличия "финальных" данных (Гитхаб, но не забываем еще про извлечение данных о системной архитектуре: terraform-шаблоны, у Амазона есть данные CloudFormation), есть еще очень полезная история изменений Гита, вкупе с данными из CI о том, больше или меньше прошло тестов в результате изменения, не было ли регрессий по каким-то тестам, возможно даже данные производительности: как грубое прокси можно взять общее время прохождения CI, либо, если есть, специализированные тесты производительности типа JMH.
Есть еще документация проекта.
Есть скриншоты интерфейсов из браузеров или смартфонов, которые можно брать/генерить автоматически в CI, давать их как prompt в мультимодальную модель, пусть генерит layout в CSS или что там сейчас популярно в мобилках.
По поводу большого интерфейса: документация проекта может служить как prompt (в мультимодальную модель - там же в документацию часто вставляют скриншоты! как раз то, что надо), на выходе генерим целиком системную архитектуру (terraform) и код. Мне кажется, это вполне реалистично для простых приложений или сайтов (кажется, примеры с приложением "счетчик" были уже два года назад с GPT-3). Генерация еще больших проектов - это уже вопрос скалирования, а не вопрос квантового скачка на новые возможности.
dopusteam
А есть какие то пруфы или примеры? Кроме copilot, который может предложить дропнуть БД, например?
Вы представляете как это всё использовать и анализировать? Там человек то не всегда разберётся
С простыми сайтами - да, а с большими проектами - тут вопрос не скалирования, имхо. Это как в случае с современными "ИИ" - довести их до человеческого уровня - это вопрос не скалирования, а именно, что качественного скачка.
Ну и плюсом сюда разные инструменты, типа dreamviewer, которые позволяют делать примерно то, что Вы описали, но немного сложнее - почему такого рода инструменты очень ограниченно используются (если используются вообще)? Код, генерируемый по условной картинке или истории коммитов (или по всему сразу), будет содержать слишком много неоднозначных\излишних вещей. Да, люди пишут тоже много такого, но это и читают\правят потом люди. А кто будет править код за "генератором" кода? Кто сможет разобраться в нём?