
Разработчики любят спорить о языках программирования и инструментах. Если опустить типичные претензии, обычно все сводится к тому, что люди просто защищают свой выбор. Это проявление тенденции оправдывать и защищать свои инвестиции - время потраченное на изучение используемых языка и инструментов. И в этом есть смысл. Но не всегда это поведение является рациональным.
(оригинал)
Эта запись, в основном, посвящена инструментам для таких платформ, как Zephyr (west) и ESP-IDF (idf.py). Но большинство замечаний справедливы и для многих других одноразовых и специальных инструментов.
Вложенные инвестиции
В отличие от того что нам порой говорят или продают, для уверенного владения языком программирования требуются годы. Обычно мне требуется 3-4 года применения языка программирования, прежде чем смогу сказать, что я знаю этот язык. Некоторым людям, вероятно, нужно меньше времени чтобы достичь того же уровня. Как бы то ни было, изучение языка программирования требует значительных затрат вашего личного времени.
И поскольку изучение языка программирования это затратно, весьма ожидаемо, что люди подсознательно стремятся защитить свой выбор. Если вы потратили 4-5 лет на язык X, потребуется немало времени чтобы убедить вас переключиться на язык Y. В такой ситуации легко стать жертвой заблуждения - соглашаясь, обесцениваю свои инвестиции.
Модные языки
Сегодня многие люди изучают Python. Python очень моден и часто можно услышать, что если вы изучите Python, вам будет легко найти работу. Вероятно, так оно и есть. Python предлагает низкий порог входа, богатый набор достойных библиотек для всего, от веб-программирования до машинного обучения, и не строгий язык, который позволит вам расслабиться и не задумываться о типах перемнных и многом другом. Или, если быть более точным: Python - язык, который позволяет вам быть чуть неряшливым.
Два с половиной десятилетия назад существовал язык, игравший аналогичную роль. Perl был Python своего времени. Какое-то время, большая часть интернет-индустрии работала на Perl. Для многих, Perl был предпочитаемым языком для веб-программирования и системного администрирования. Вы бы встретили много программистов Perl в таких местах, как финансовый сектор или развед. службы. Места, где у людей было много данных для обработки и анализа.
Если не обращать внимание на косметические различия, Perl мало чем отличался от Python с точки зрения практики разработки программного обеспечения. Он позволял быстро писать неряшливый код, и у него было масса плюсов для быстрого создания решений.
Perl и Python имеют одни и те же проблемы. Наиболее очевидным является то, что ни один из них не является компилируемым языком и не имеет статической типизации. Это не имеет большого значения, когда вы быстро склеиваете прототип, но становится серьезной проблемой, когда проект начинает расти в сложности, охватываемая аудитория увеличивается и люди начинают зависеть от вашего кода. Поддержка кода без помощи компилятора и отсутствие простого способа распространения программного решения имеют высокую цену при растущих масштабах.
Конечно, вы можете попытаться компенсировать это, написав тесты которые попытаются покрыть то, что вам дали бы статическая типизация и компилятор, но это скорее принятие желаемого за действительное. Признайтесь: вы не будете настолько скрупулезны. В противном случае, вероятно, вы бы изначально не стали использовать динамический язык.
Антисоциальное поведение
Этот параграф может спровоцировать разработчиков на Python, но Python — антисоциальный язык. Он фокусируется в первую очередь на потребностях разработчика, а не на пользователях программного обеспечения. Это, не очень красиво.. и если честно, то даже весьма высокомерно.
Вполне нормально чувствовать несогласие с подобными высказываниями. Как указывалось ранее: вы, вероятно, потратили много времени на Python. Вы будете склонны оправдывать и защищать вложенные инвестиции. Призываю вас обдумать написанное и постараться подавить немедленное желание выразить несогласие. Постарайтесь взглянуть на это с другой стороны - ведь именно так многие пользователи воспринимают программное обеспечение написанное на Python.
Итак, что же я имею в виду, когда говорю, что Python антисоциален?
Если вы используете язык, который может выдавать бинарные файлы, задача по установке всех зависимостей с правильными версиями является одноразовой: это происходит во время сборки. Это не происходит каждый раз при запуске программы. Более того: этот процесс можно автоматизировать, чтобы результат можно было распространять. Вы можете создать статически связанный бинарный файл, который просто нужно скачать и поместить в соответствующее место.
Это должно быть задачей разработчиков программного обеспечения, а не пользователей.
Каждый раз, когда вы запускаете программу на Python, все зависимости должны присутствовать. Если один из пакетов внезапно пропал, был обновлен или требуемая версия Python недоступна, ваша программа скорее всего не запустится. А что еще хуже, это может привести к неочевидным, на первый взгляд, последствиям и не очень внятным ошибкам.
Это случается нередко. На самом деле, каждый год мы теряем недели разработки из-за того, что программы на Python внезапно перестают работать. Каждое обновление в цепочке зависимостей любых из используемых нами инструментов, сопряжено со значительными рисками сломать нашу среду сборки. Нам приходится тратить время на починку нашего инструментария, прежде чем мы сможем вернуться к основным задачам. Если честно, все настолько плохо, что если я склонирую встраиваемый код через несколько недель после того как это было закоммичено, и попытаюсь собрать, вероятность того, что не соберется - примерно 50/50.
Многие встроенные зависимости неприемлемо хрупкие. Если вы профессиональный инженер-программист и вас это не беспокоит, вам, вероятно, следует пересмотреть свои стандарты качества. Воспроизводимость и повторяемость имеют огромное значение. Особенно, если вы считаете себя профессионалом.
Переосмысление инструментов
Понятно, что люди не особенно склонны отказываться от своего привычного языка программирования и не стремятся переписывать программное обеспечение, которое работает. Вы вложились в изучение языка, а затем в создание инструментов или приложений на этом языке. Это представляет собой инвестиции и часто значительные, невозвратные затраты. Начинать сначала, может показаться не очень привлекательным решением.
Но вам стоит рассмотреть этот вариант серьезней. Как вы хотите проводить время в долгосрочной перспективе? Хотите решать проблемы, возникшие из-за выбора Python? Выяснять, как заставить приложения на Python работать предсказуемо, надежно и без необходимости постоянных действий со стороны пользователя? Или все таки сосредоточиться на создании продукта?
Если вы используете Python сегодня, я думаю, что вы просто обязаны попробовать сделать несколько небольших проектов на языках, более подходящих для создания простых инструментов, которые работают независимо от того, как настроена ваша система. Начните с выбора современного компилируемого языка. Два отличных кандидата — Rust и Go. Но подойдет любой язык, который имеет статическую типизацию, достойную стандартную библиотеку и компилируется в (предпочтительно статически связанные) бинарные файлы.
В крайнем случае, даже Java представляет лучшую альтернативу, поскольку у вас есть возможность создавать файлы «jar», содержащие все зависимости. Не модный, но объективно куда менее хрупкий вариант.
Перепишите небольшое приложение или утилиту на один из таких языков. Возможно, придется сделать это пару раз: сначала просто повторить функционал, а затем посмотреть, есть ли более идиоматические способы структурирования кода. Основная цель – научиться создавать более качественные приложения и тулинг.
Когда вы начнете чувствовать себя более комфортно с любым языком, который вы выберете, начните думать о том, как вы можете создавать кодовые базы «двойного назначения»: постарайтесь структурировать любой код, который вы пишете, в виде библиотеки, которую можно использовать для создания новых инструментов, включающих эту функциональность. Попробуйте подумать о том, как вы можете повысить продуктивность других. (Если вы ищете возможности роста как программист, это именно то, как это достигается: начните помогать другим разработчикам своим вкладом).
Заключительные мысли
Иметь сочувствие к своим пользователям - важно. Написание кода может быть очень эгоцентричным занятием, когда легко сосредоточиться только на своих собственных потребностях. Если другим людям сложно использовать ваши программы, то это ваша вина. Не говорите им, что они используют его неправильно. Не тратьте время на выдумывание причудливых способов справиться с вашим ненадежным кодом. Не ждите, что они спокойно воспримут, то что вы не хотите упрощать им жизнь.
И вы можете быть совершенно эгоистичным в том что: если вы создадите что-то, что сделает ваших пользователей счастливее, это хорошо отразится и на вас.
Я понимаю, что просить людей не использовать Python — это провокация. Но я говорю это не назло или чтобы кого-то обидеть. Я говорю это, потому что потратил слишком много недель на то, чтобы заставить плохо продуманные инструменты работать, я не увидел значительных улучшений за последние годы, и я думаю, что пришло время начать относиться к этому немного серьезней.
Комментарии (266)

agoncharov
14.09.2022 09:44+27и не строгий язык, который позволит вам расслабиться и не задумываться о типах перемнных и многом другом. Или, если быть более точным: Python - язык, который позволяет вам быть чуть неряшливым
С точностью до наоборот. Не записывать тип не означает что программист должен перестать о нем задумываться, напротив, он должен задумываться о нем ещё больше. В какой-нибудь Java программист может быть «неряшливым» в отношении типов — IDE всегда подскажет где чего не так

Kanut
14.09.2022 10:13В какой-нибудь Java программист может быть «неряшливым» в отношении типов — IDE всегда подскажет где чего не так
Тогда уж компилятор. Потому что в теории IDE можно и для интерпретируемых языков настроить так чтобы она ругалась и подсказывала.

12rbah
14.09.2022 10:28+4Потому что в теории IDE можно и для интерпретируемых языков настроить так чтобы она ругалась и подсказывала.
Я не уверен на 100%, но для этого вроде нужна хорошая документация, где будут указаны типы, т.к. IDE сама просто можеть и не понять
Kanut
14.09.2022 10:31Это уже зависит. То есть пока это действительно обычно решается через доки/аннотации. Но в теории можно создать и достаточно "умную" IDE.
Просто IDЕ можно "обмануть". Компилятор не обманешь :)

klirichek
14.09.2022 10:45+5С компилятором скилл обмана просто переходит на другой уровень.
Там будет либо куча нюансов в самом языке, либо куча ub.

makkarpov
14.09.2022 12:50+8Но в теории можно создать и достаточно "умную" IDE.
Нельзя, потому как выведение типов в ЯП с динамической типизацией - это алгоритмически неразрешимая проблема в общем случае.

extroot
14.09.2022 18:58Если рассматривать Python, то сейчас многие говорят про type-hints (А точнее о проблеме их отсутствия). При их использовании IDE вполне подсказывает где и что не так. Однако это, безусловно, требует указания типов.

0xd34df00d
14.09.2022 18:28+4В теории как раз нельзя, по очень фундаментальным причинам. Либо с кучей false negatives.

vkni
15.09.2022 00:27Потому что в теории IDE можно и для интерпретируемых языков настроить так чтобы она ругалась и подсказывала.
Нельзя. Например, потому, что из спецификации Питона вы можете выдавать значения разного типа из функции. Соответственно, ваш анализатор должен анализировать тексты всех библиотек, а не просто иметь базу из сигнатур, как в ML/Haskell/Kotlin/Java/C(++)/D.
0xd34df00d
15.09.2022 00:38+1В современном хаскеле (с GADT, type families и вот этим всем) даже база сигнатур не поможет — вывод типов разрешим только для haskell98 (и, возможно, 2010, но там я уже не уверен).
По аналогичным причинам в каноническом ML не полный System F, а достаточно ограниченная его версия, чтобы вывод типов был разрешим. А он в полной System F неразрешим, даже если оставить компилятору подсказки о том, где именно надо применять термы к типам, и просто стереть сами типы-аргументы.
vkni
15.09.2022 01:01+1"Вы, горожанин, идите нафиг — лекция для колхозников!" :-)
Люди, вон, считают, что есть интерпретируемые и компилируемые языки, а тут разрешимость.
P.S.
С С++ тоже, очевидно, не совсем правда. ;-)

morijndael
15.09.2022 02:08Конкретно разные типы не проблема, для такого есть typing.Union
Проблема в том, что анализировать исходники можно долго и безрезультатно, а поддерживать с библиотекой ещё и файлы сигнатур мало кому не лень

Fenzales
14.09.2022 11:43+8По такой логике программист со строгими типами более неряшливый, чем тот, у кого везде в интерфейсах и сигнатуры сплошные nullable-типы .без повода

RH215
15.09.2022 01:36Здесь речь про другое, про то, что сам инструмент требует более строгой самодисциплины, хотя позиционируется как более лёгкий.
morijndael
14.09.2022 22:23+3Вы видимо не видели ужасов на питоне, раз такое говорите :'D
Проигнорировать возможный None? Да на здоровье
Возвращать из функции N разных типов в зависимости от ветки? Дайте
дваN+7!Ой, всё разваливается в продакшене? Затыкаем голым
except: return ""Про тайпхинты вообще молчу, зачем о таком думать вообще, слишком сложное, следующие программисты как нибудь и так разберутся. Ну или не разберутся, но это уже их проблема
На каком нибудь расте конечно тоже нет страховки от говнокода, но он хотя бы крашиться не будет по фантомным причинам (а если будет, можно грепать по unwrap). И раст как раз заставляет думать о всех возможных ветках кода. Питон думать не заставляет, ну и как следствие мозг при программировании не включается
0xd34df00d
14.09.2022 22:34Возвращать из функции N разных типов в зависимости от ветки? Дайте два N+7!
А это, кстати, прикольно. Правда, динамическая «типизация» для этого не нужна, это вполне выражается и в статически типизированных языках.
morijndael
14.09.2022 22:57Ну, формально там будет один конкретный тип. Либо enum над всеми возможными типами, который придётся даункастить (и рассмотреть все случаи), либо абстрагированный Box<dyn Trait>, который не даст использовать ничего кроме апишки конкретного Trait. Это если рассматривать раст, но подозреваю что в других сильно типизированных языках примерно так же
А в питоне можно и заб[ыи]ть, что там может быть что-то другое, и вспомнить только когда прод крашнется
0xd34df00d
14.09.2022 23:38+1Ну, формально там будет один конкретный тип.
В разных ветках будут разные типы. Без енамов, без
экзистенциальных типовdyn trait'ов, и так далее.Но да, это не во всех языках так можно.
0xd34df00d
15.09.2022 00:00+1Во, как иллюстрацию по-быстрому наваял классику — типобезопасный
printf. Его тип зависит от форматной строки, которую ему передали, и в разных ветках разный:Printf> :t printf "just a string" printf (fromString "just a string") : String Printf> :t printf "%d" printf ['%', 'd'] : Int -> String Printf> :t printf "%d meh %s %d!" printf (fromString "%d meh %s %d!") : Int -> String -> Int -> Stringи работает как ожидается:
Printf> printf "just a string" "just a string" Printf> printf "%d" 42 "42" Printf> printf "%d meh %s %d!" 42 "foobar" 6 "42 meh foobar 6!"а как не ожидается — не работает (и это полноценная ошибка типов в нормальном, статическом смысле):
Printf> printf "%d" 42 "foobar" 6 Error: When unifying: String and: ?argTy -> ?argTy -> ?retTy Mismatch between: String and ?argTy -> ?argTy -> ?retTy. (Interactive):1:1--1:26 1 | printf "%d" 42 "foobar" 6 ^^^^^^^^^^^^^^^^^^^^^^^^^Реализация довольно простаяСтрок 20, за вычетом всякой служебной ерунды:
%default total data PrintfFmt : Type where PFArg : (ty : Type) -> (argShow : ty -> String) -> (rest : PrintfFmt) -> PrintfFmt PFConst : (c : Char) -> (rest : PrintfFmt) -> PrintfFmt PFNil : PrintfFmt parse : List Char -> PrintfFmt parse ('%' :: 'd' :: s) = PFArg Int show $ parse s parse ('%' :: 's' :: s) = PFArg String id $ parse s parse (c :: s) = PFConst c $ parse s parse [] = PFNil PrintfTy : PrintfFmt -> Type PrintfTy (PFArg ty _ rest) = ty -> PrintfTy rest PrintfTy (PFConst _ rest) = PrintfTy rest PrintfTy PFNil = String printf : (xs : List Char) -> PrintfTy (parse xs) printf xs = go "" (parse xs) where go : String -> (fmt : PrintfFmt) -> PrintfTy fmt go acc (PFArg _ argShow rest) = \arg => go (acc ++ argShow arg) rest go acc (PFConst c rest) = go (acc ++ singleton c) rest go acc PFNil = acc
RH215
15.09.2022 01:45Не, ну за такое просто бить линейкой по пальцам нужно. Если игнорирование None я ещё могу понять - обычная проблема всех языков с null и часто бывает случайно. Но возврат разных типов или игнорирование ошибки без явной необходимости - это прямо явное вредительство.
Питон думать не заставляет
У меня обратный опыт. Если действительно есть какая-то ответственность за свой код, то на Питоне нужно думать больше, чем на других языках. :)
morijndael
15.09.2022 01:59это прямо явное вредительство.
Нет это
патрикфриланс :'DЕсли действительно есть какая-то ответственность за свой код
Ключевое слово "если"
RH215
15.09.2022 02:39Нет это фриланс :'D
Ну тут даже Haskell не поможет.
Ключевое слово "если"
В нормальных командах с этим проблем меньше. Ибо разработчик, если он достаточно опытен и не идиот, понимает, что код который он пишет, ему же и поддерживать потом. :)

iig
15.09.2022 13:44код который он пишет, ему же и поддерживать потом. :)
Без работы не останется. В чем подвох? ;)

DirectoriX
15.09.2022 03:57Ваши бы слова, да разработчикам AWS SDK в уши…
У них один конструктор на все клиенты, в аргументе boto3.client() вы должны передать название службы (строкой, ага), а оно вам вернёт объект клиента для указанного сервиса. Разумеется, все клиенты имеют разные интерфейсы, просто с общим конструктором (фабрикой?)…

Suor
16.09.2022 02:58Вот именно поэтому питон требует большей дисциплины. Личной или организационной, вроде ревью кода.
vkni
16.09.2022 04:06Дисциплина — это время и силы. Спрашивается, зачем их тратить, если всё это может быть заменено Хиндли-Милнером + классами типов в стиле Хаскеля? Единственная проблема — язык должен быть энергичным, т.к. монады сложны для простого работяги.
0xd34df00d
16.09.2022 05:58+2Единственная проблема — язык должен быть энергичным, т.к. монады сложны для простого работяги.
А потом ты пишешь в [энергичном] идрисе
<|>в парсекоподобном парсере, и оно зависает, потому что энергично пытается идти в обе ветки, а у тебя где-тоLazyне хватает.Монады — это вообще не про энергичность, а про (помимо прочих вещей) упорядочивание вычислений и их эффектов. В энергичном чистом функциональном языке никто не мешает
let foo = ... bar = ... in ...вычислить сначала
bar, а потомfoo(еслиfooне используется вbar), или сделать прочие интересные преобразования. И это хорошее свойство, потому что компилятору в общем случае виднее, в каком порядке что вычислять. Может, терм под биндингомbarявляется субтермомfoo(и можно сделать common subexpression elimination). Может, компилятор знает, что вычислениеbarпередfooболее эффективно разогреет кеши/етц.Короче, поэтому написать
print "hello " print "world!"и быть уверенным в правильном порядке вывода без монад всё равно не получится (или без линейных типов, которые в данном контексте изоморфны
ST/IO). И поэтому монады, включаяIO, есть и в идрисе, который энергичный, да.vkni
16.09.2022 18:00А потом ты пишешь в [энергичном] идрисе
<|>в парсекоподобном парсере, и оно зависает, потому что энергично пытается идти в обе ветки, а у тебя где-тоLazyне хватает."Лекция для колхозников". Очень мало народу про вывод типов-то догадывается, а тут такое.
Кстати, очень странно — есть же Kotlin/Swift, относительно новые языки, а мы всё ещё воюем с питонистами.
Suor
16.09.2022 06:29Типы любые закрывают только один класс ошибок, тогда как дисциплина куда более универсальна. И то, и другое не бесплатно конечно.
Практика показывает что, чем более замороченная система типов в языке, тем более он нишевый. А практика - критерий истины. )
0xd34df00d
16.09.2022 07:33+1Достаточно выразительные типы закрывают и логические ошибки :]
Suor
16.09.2022 07:35Теорему можно в типах написать, работать только не будет. На практике +1 вместо -1 не один нормальный тип не поймает.
0xd34df00d
16.09.2022 07:45+1Смотря в каком контексте у вас там +1 и -1. Такие вещи вообще тяжело обсуждать в отрыве от контекста.
Кстати, к слову о практике — я тут пописываю модельку работы с битовыми операциями, и случайно реализовал сдвиг вправо на s бит не с той стороны — вместо зачёркивания s бит справа и дописывания нулей слева оно брало первые s бит слева и дописывало нули слева от них. Да, тип операции вроде
shiftR : Bit64 -> Fin 64 -> Bit64не ловит этот баг, но всё сломалось, когда я попытался доказать очевидно необходимую теорему, что сдвиг на 0 бит вправо ничего не меняет.
vkni
16.09.2022 17:59Когда я писал "все", я допустил известную небрежность. БольшУю часть ошибок. Ну так и экскаватор не выкапывает все ямы.
Тем не менее, автоматизация освобождает время и мыслительные силы на вылавливание других ошибок. Вообще, переход к динамически типизированным языкам в сложных системах — это какой-то неолуддизм. Он, конечно, обоснован — экономика уже 15 лет в кризисе, люди не нужны, поэтому дёшевы, но выдавать нужду за добродетель, кмк, не надо.

vadimr
14.09.2022 09:47+34Если вы используете язык, который может выдавать бинарные файлы, задача по установке всех зависимостей с правильными версиями является одноразовой: это происходит во время сборки. Это не происходит каждый раз при запуске программы.
В принципе, дальше можно и не читать, уровень погружения в вопрос понятен.

HemulGM
14.09.2022 11:53+3Предполагаю, что здесь речь идет о том, что "из коробки", работает именно с помощью интерпретатора, каждый раз выполняя поиск файлов используемых в проекте.
pyintsller и прочие ухищрения - это сторонние решения именно этой проблемы, о которой говорит автор. Разве нет?vadimr
14.09.2022 12:21+8А исполняемые файлы “из коробки“ каждый раз ищут динамические библиотеки нужных версий. Ухищрением для решения этой проблемы является статическая сборка, но с ней всё тоже не так просто.
Это даже если мы ещё не рассматриваем смену форматов исполняемых файлов – любимое занятие Apple.
HemulGM
14.09.2022 12:40+4"Из коробки" ни кто ничего не ищет. И не важно сколько было исходных файлов. На выходе мы получаем один файл. А динамические библиотеки касаются как компилируемых так и интерпретируемых, так что их можно опустить.
Динамических библиотек тоже касается формат исп. файлов. А питон их использует даже чаще, чем какой-либо другой язык.
qrKot
15.09.2022 08:02А динамические библиотеки касаются как компилируемых так и интерпретируемых, так что их можно опустить.
А я бы предложил не "опускать". Проблема зависимости для интерпретируемых языков: "для того, чтобы ЭТО работало, необходимо положить [список текстовых файлов] в [список мест, где должны лежать текстовые файлы] и [список бинарных файлов] в [список мест, где должны лежать бинарные файлы]". Чем отличается вариант проблемы для компилируемых языков? Тем, что пункт про текстовые файлы отсутствует? Дык, подавляющее количество инструментов управления зависимостями (если не все) текстовый файл от бинарного не отличают (совершенно справедливо, впрочем, не отличают, это совершенно одинаковые файлы). Т.е. проблема для обоих кейсов сводится к "для того, чтобы [интерпретируемое|скомпилированное] (нужное подчеркнуть) ОНО работало, необходимо положить [список файлов] в [список мест]".
Ну, т.е., проблема наличия и управления зависимостями ортогональна "компилируемости" языка. Да, "есть нюансы", но они специфичны для каждой языковой экосистемы в отдельности, а не являются общими для компилируемых/интерпретируемых языков.
HemulGM
15.09.2022 08:33+1Зависимость интерпретируемых языков от интерпретатора и исходных файлов - абсолютная. А зависимости от динамических библиотек - не обязательны.
У меня бОльшая часть проектов вообще не зависит от dll (не считая, конечно стандартных системных, от которых все зависят). Проект может быть огромным и совсем не зависеть от dll. Всё в одном ехе и работает на совершенно любой современной машине (winxp-win11).
Также, имеется статическая линковка, которая, должен заметить - не то же самое, что pyinstaller.

WASD1
14.09.2022 14:42+5Это просто разница подходов.
Когда "А" ломается в 10-100 раз чеще чем "Б".
Теоретику важно что и "А" и "Б" ломаются. Практику важно что одно ломается в десятки-сотни раз реже.vadimr
14.09.2022 14:57+4Не знаю, как у кого, но в моей практике ссылки исполняемых модулей на динамические библиотеки ломаются гораздо чаще, чем пропадают файлы из питоновских программ. Второго, честно говоря, я вообще не припомню. А зато неразрешённые ссылки на конфликтные версии динамических библиотек – это постоянная головная боль.
WASD1
14.09.2022 15:14+1Ломаются и конфликтуют (вторая программа не может быть установлена) это разные вещи. Как я понял автора статьи - был рассмотрен вариант именно "тихо сломалось". Конфликты разрешаются отдельно.
Вот я вообще не вспомню чтобы у меня пакеты ломались от несовместимости библиотек при штатной работе (за исключением случаев, когда я что-то руками через dpkg ставил или апгрейд Ubuntu 18.04 до 20.04).
-
А вот в python что-то типа "утилита работала 2 года назад на 3.5, сейчас на машине 3.7 - лови ошибку" случалось. У более опытных в Python коллег встречалось и много.
*) Update п.2. Я работаю под Ubuntu, пакеты, поставляемые не из официального репозитория можно перессчитать по пальцам (что-то типа QT4, как legacy и тому подобного).
Так вот соглашений о совместимости API между версиями ПО (продвижение каких версий какую совместимость ломает) и дисциплины мэйнтейнеров - как по мне при штатной работе хватает для того, чтобы у пользователей проблем "втихую сломалось" практически не возникало.
Проблема "несовместимости" (dll-hell, в мире Unix не заню термина) - существует, но это всё-таки другая проблема.vadimr
14.09.2022 15:25Я работаю под Ubuntu, пакеты, поставляемые не из официального репозитория можно перессчитать по пальцам
Ну вам просто по жизни повезло в таком случае.
Попробуйте, например, установить под Ubuntu ltfs, и станет ясно, о чём я.
А если работать в разработке ПО, то эти несовместимости становятся правилом жизни, а не исключением.
Я согласен, что python плохо обратно совместим, но он, к сожалению, отнюдь не один такой, и это не имеет никакого отношения к компилируемым и интерпретируемым языкам.
WASD1
14.09.2022 15:36Ну я разработчик.
По-моему это просто дисциплина относительно Fail Fast в соглашении об именовании пакетов и прописывании зависимостей.Несовместимость всегда приятнее править, чем падение.
Опять же при лечении несовместимости у меня есть (я надеюсь, что у меня есть) какие-то гарантии что "разрулил зависимости всё заработает", а при нарушении контракта API - вот это падение я полечил, а другие остались?vadimr
14.09.2022 15:39По-моему это просто дисциплина относительно Fail Fast в соглашении об именовании пакетов и прописывании зависимостей.
Меня-то не надо убеждать за всё хорошее против всего плохого. Но окружающий мир жесток и несправедлив.
WASD1
14.09.2022 15:44меня не надо убеждать
Какой-то крайне расплывчатый и нетехнический аргумент.
Если более конкретно, я вас правильно понял: "установка \ обновление deb-пакетов штатным образом у вас чаще `тихо ломает` существующие программы, чем установка библиотек \ обновление python" ?
vadimr
14.09.2022 15:47+1Установка/обновление deb-пакетов штатным образом – это такая рутинная операция, о которой не имеет смысла и говорить. Библиотеки python, кстати, тоже зачастую являются deb-пакетами.
Если вы волочёте в систему что-то, не предусмотренное дистрибутивом – могут возникнуть проблемы.
iig
15.09.2022 13:50Если вы волочёте в систему что-то, не предусмотренное дистрибутивом
pip install программа, в зависимостях у которой библиотека определённой версии, не та что уже установлена из .deb

thevlad
14.09.2022 20:15+1В бинарниках которые должные запускаться на каком-то спектре базовых систем(если это не виндоус) это тоже решается вполне логично, с собой тащатся все динамические зависимости, что ничем принципиально не отличается от статической линковки. В Python это решается virtualenv и его аналогами, так же вполне можно все даже прямо с дистрибутивом софта тащить. Да и не очень понятно, что считать "инструментальным", за счет "батареек внутри", можно много чего полезного писать даже на питоне из коробки.
RH215
15.09.2022 01:41В любом случае, это решается за счёт правильной настройки установки/деплоя или создания сборок и сценариев установки под конкретное окружение.

dakuan
14.09.2022 09:49+12Есть здравое зерно, конечно, но некоторые тезисы вызывают вопросы. Возможно, из-за того, что я не знаком с Zephyr (west) и ESP-IDF (idf.py).
Каждый раз, когда вы запускаете программу на Python, все зависимости должны присутствовать. Если один из них внезапно пропал, был обновлен или требуемая версия Python недоступна, ваша программа скорее всего не запустится
Логично. Но почему они должны вдруг пропасть? Пользователь удалил? Но он точно так же может удалить и какой-нибудь ms vc redistributable и это точно так же приведет к тому, что приложения, использующие эти библиотеки, перестанут запускаться. Но является ли это проблемой языка?
Каждое обновление в цепочке зависимостей любых из используемых нами инструментов, сопряжено со значительными рисками сломать нашу среду сборки
Бесконтрольное обновление зависимостей всегда несет риск что-то сломать, вне зависимоти от того, компилируемый язык или интерпретируемый. Для решения этой проблемы придумали версионирование.
Если честно, все настолько плохо, что если я склонирую встраиваемый код через несколько недель после того как это было закоммичено, и попытаюсь собрать, вероятность того, что не соберется - примерно 50/50.
Но почему? Зависимости никак не версионируются?
В крайнем случае, даже Java представляет лучшую альтернативу, поскольку у вас есть возможность создавать файлы «jar», содержащие все зависимости. Не модный, но объективно куда менее хрупкий вариант
Pyinstaller?

DistortNeo
14.09.2022 15:24Версионирование зависимостей — это зло, которое неизбежно будет приводить к раздуванию кода. А самое весёлое — это когда вам надо скрестить несколько проектов, каждый со своим уникальным набором зависимостей.
qrKot
15.09.2022 08:07+2Версионирование зависимостей — это зло, которое неизбежно
Вот на этом месте я бы остановился.

tandzan
14.09.2022 17:51+2Возможно, из-за того, что я не знаком с Zephyr (west) и ESP-IDF (idf.py).
Был опыт с esp-idf и горело у меня целый день. Питоновские установочные скрипты просто были плохие. На ровном месте оказались несовместимыми с win 7 и кириллицей в имени пользователя. Ушло несколько часов только на установку.

Anastasia_K
14.09.2022 09:55+44Вполне нормально чувствовать несогласие с подобными высказываниями. Как указывалось ранее: вы, вероятно, потратили много времени на Python. Вы будете склонны оправдывать и защищать вложенные инвестиции.
Очень удобно. Если вы со мной не согласны, значит вы неправы и просто защищаете свои инвестиции.Каждый раз, когда вы запускаете программу на Python, все зависимости должны присутствовать. Если один из них внезапно пропал, был обновлен или требуемая версия Python недоступна, ваша программа скорее всего не запустится.
Вы можете создать exe-файл со всеми зависимостями, если вы распространяете свой софт.
Вы можете дать контейнер
Вы можете указать нужные версии библиотек в requirements.txt и забыть про проблемы с зависимостями.
Вообще статья странная. Складывается впечатление, что автор долго писал на других языках, взял питон, написал пару скриптов, не понравилось. Теперь, на основании поверхностного впечатления пишет статьи.Призываю вас обдумать написанное и постараться подавить немедленное желание выразить несогласие.
призываю автора обдумать проблемы, которые он обозначил и подумать, как их решить. Уверяю, нет ничего смертельного из описанного в тексте, чего нельзя было бы решить малой кровью.

AlexZaharow
14.09.2022 11:06+10Ну а многие старые бинарные программы не запускаются по той же причине - смена апи системы. Так что в принципе поднятый вопрос - просто фича программирования. Программ, что бинарных, что интерпретируемых без зависимостей не бывает. А они всегда могут пропасть в будущем. Одни раньше, другие позже. Надо смириться с этим.

blind_oracle
14.09.2022 21:20Статические бинарники в большинстве случаев решают проблему. Можно, при желании, даже от LIBC отвязаться. Главное чтобы ядро поддерживало необходимые системные вызовы.
Но у статики свои минусы - размер, невозможно пофиксить баг или уязвимость в зависимости без пересборки и т.п.
DistortNeo
14.09.2022 21:35+2Статистические бинарники однозначно будут меньше места занимать, если следовать принципу "you only pay for what you use". Компилятор просто выкинет неиспользуемый код, чего не скажешь о Python, где либы приходится таскать с собой целиком.

Moraiatw
14.09.2022 21:46+3Есть понятие "обратная совместимость", по крайней мере в Windows. Вполне можно запустить программу, написанную во времена Windows 98.
RH215
15.09.2022 01:49+1А можно и не запустить. Или словить кучу багов. Причём, чем сложнее софт, тем большая вероятность не запустить.
Есть правило "если софт не писался под данное окружение, то и его работа в нём не гарантируется".Moraiatw
15.09.2022 08:25Я не знаю такого софта. Все API, которые были тогда, остались и сейчас, и для вызывающего кода работают точно так же.
Это не Linux, где функция сегодня deprecated, а завтра ее просто выкинули и плевать на софт, ее использующий, и пользователей этого софта.
12rbah
15.09.2022 10:02Это не Linux, где функция сегодня deprecated, а завтра ее просто
выкинули и плевать на софт, ее использующий, и пользователей этого
софта.Можно конкретный пример?

Stanislavvv
15.09.2022 12:48+1Это ошибка выжившего.
Году в 2001-м как раз наступал на подобное при переезде с win98 на win2k, из-за чего на работе пара машин с 98-й остались.
Да и теперь есть жалобы на переезд win7-win10 как раз из-за незапуска чего-то нужного (лично мне неактуально, работаю не в той области и виндов не имею уже давно, так что не скажу что именно).

Sklott
15.09.2022 13:28Запустите на любом современном Windows любую игру использующую WinG. Буду благодарен за рабочую инструкцию.
Moraiatw
15.09.2022 20:12Не знаю, что такое WinG. Но у меня сейчас в десятке вполне работает игра, в которую я играл еще на Windows 98 (3D шутер, Direct3D и OpenGL)

andreymal
15.09.2022 20:30+2Ну раз уж на то пошло — Linux-билд игры Unreal Tournament, собранный в 2003 году (если верить датам файлов), успешно запускается и работает на самом свежем Arch Linux, причём с использованием современного SDL2
Sklott
16.09.2022 10:51WinG - это такой предшественние DirectX, который выкинули с выходом последнего. Я это про то, что
Я не знаю такого софта. Все API, которые были тогда, остались и сейчас, и для вызывающего кода работают точно так же.
Не работает на практике...

Ndochp
16.09.2022 14:56Эмн… Star Wars Episode I: Racer, 1С:7.7 (установочный дистрибутив), Crimson Skies (от MS кстати), BP Win

stitrace
14.09.2022 11:16+3Этот параграф может спровоцировать разработчиков на Python, но Python — антисоциальный язык. Он фокусируется в первую очередь на потребностях разработчика, а не на пользователях программного обеспечения. Это, не очень красиво.. и если честно, то даже весьма высокомерно.
По моему, если язык не будет концентрироваться на потребностях разработчика, то пользователи рискуют вовсе не увидеть никакого ПО, которое бы, в отличной от нулевой степени, удовлетворяло их потребности. По разным причинам, по причине недоступности ПО из-за его стоимости, либо по причине отсутствия такого ПО вовсе.

znhv
14.09.2022 11:49+8Считаю, что язык нужно использовать отталкиваясь от задачи. Если в автоматизации не хватит баша, реализую на питоне за 5 минут, сохраню время и буду уверен, что это сработает.

koledennix
14.09.2022 11:50+3Поправьте меня, если я ошибаюсь. На текущий момент я убеждён, что частью "социальности" языка в том числе является и скорость с которой клиент получает нужные ему функции. Без привязки к питону, похоже что в каждом конкретном случае практично взвешивать реальные потребности клиентов и доступный набор инструментов. Социальность , на мой взгляд, вещь субъективная. Кому-то важна простота установки, а кому-то скорость разработки. У каждого инструмента есть преимущества и недостатки. Но что именно является недостатком определяется в контексте задачи и клиента.

TimsTims
14.09.2022 11:59+4На самом деле, каждый год мы теряем недели разработки из-за того, что программы на Python внезапно перестают работать.
Заменяем Python на любой другоя ЯП и утверждение остаётся верным. Но есть возвращаться к компилируемым языкам, то сколько времени разработчиков уходит на компиляцию?

Stanislavvv
14.09.2022 12:44+6А это без разницы - в случае распространения бинарников компилируется один раз у разработчика, а не как в virtualenv - при каждом развёртывании через pip install.
TimsTims
14.09.2022 13:31+2при каждом развёртывании через pip install.
Думаю каждое развертывание будет происходить гораздо реже (один раз у каждого разраба), чем разработчик будет запускать код (компилировать его) для проверки работоспособности.
Stanislavvv
14.09.2022 15:53+1Это уже проблемы разработчика/мантейнера - компилять на чём-то мощном. В проде код вполне может запускаться на чём-то совсем дохлом (урезанная по бюджету вдс, к примеру).

Starl1ght
14.09.2022 13:43+6сколько времени разработчиков уходит на компиляцию?
Секунды, для почти всех компилируемых языков, окромя С++

ikle
14.09.2022 17:14окромя С++
О, да, если перемудрили с шаблонами, то компилятор быстро может съесть больше 4G и долго думать. Впрочем, это проблема не только C++: функциональные языки со строгими типами, выводом типов и доказательством корректности могут очень долго думать — и это, чаще всего, фундаментальная проблема, но, при этом, мы получаем такую степень валидации кода, которой нам не даст C++, а уж тем более Python.
Секунды, для почти всех компилируемых языков
См. замечание в предыдущем параграфе. Ну и проекты бывают большими, сборка которых занимает часы на числодробилках. Впрочем, инкрементальная сборка в процессе разработки почти всегда спасает.
0xd34df00d
14.09.2022 18:35Впрочем, это проблема не только C++: функциональные языки со строгими типами, выводом типов и доказательством корректности могут очень долго думать
Релоад среднего модуля в агде при разработке — менее секунды для модулей на строк 50 до нескольких секунд на модули с парой-тройкой сотен строк.
0xd34df00d
14.09.2022 18:38Я почти не трачу время на компиляцию. Все выявляемые компилятором проблемы покажет IDE, а непосредственно запускать код для проверки при развитой системе типов нужно очень редко.

Areso
15.09.2022 11:58+1go проект небольшого размера компилируется мгновенно.
go проект средних размеров компилируется за секунды.
go проекта больших размеров у меня пока не было :)


Stanislavvv
14.09.2022 12:49+21) те же проблемы бинарников, собранных динамически - в системе может не быть нужных библиотек или, что ещё хуже, в системе есть библиотеки не той версии и они используются.
2) альтернативные проблемы И питона с virtualenv И бинарников собранных статически - уязвимости в библиотеках, используемых при pip install или при сборке могут быть пофикшены, но кто ж будет переразвёртывать то, что уже установлено и работает, если исходники/версия самой утилиты не менялись?
В общем, проблема именно питона преувеличена, точно такие же проблемы есть у перла, руби и других языков.Moraiatw
14.09.2022 22:48-1точно такие же проблемы есть у перла, руби и других скриптовых языков
Stanislavvv
15.09.2022 08:35Нет. Попробуйте запустить нестатический бинарник начала 2000-х на современной машине. Или соберите на свежем дистрибутиве и принесите на всё ещё работающий Debian 9.

vassabi
14.09.2022 13:28+6эх, жалко, что не перевели еще и постскриптум к оригиналу автора.
автор - embedded engineer, и я подозреваю, что там у него "в железе - всё хорошо". А вот когда он подсоединяет своё отличное и прекрасное железо к "большому компуктеру" - там "противный питон всё портит" :)Ну да, если бы софт "на компе юзера" разрабатывали так же быстро и так же специализированно, как и софт для embedded железа - то наверно таких проблем было меньше....
PS: тот, кто сделает работающую + удобную + надежную систему версионирования библиотек, модулей и пакетов - тот озолотится, об этом мечтают не только embedded engineer, но и любой кто писал код больше года. (и в очереди за таким чудесным чудом будут стоять не только питонисты с джаваскриптерами, а и джависты с сишарпистами, и даже сишники вместе с бородатыми админами)
Но если бы призывами и обвинениями в асоциальности это можно было бы решить - уже решили бы проблему давно ....

AlanRow
14.09.2022 13:47Признайтесь: вы не будете настолько скрупулезны. В противном случае, вероятно, вы бы изначально не стали использовать динамический язык.
Вот эта мысль немного противоречит предыдущему тексту, ведь из ранее написанного следует, что вы не используете другой язык, просто потому, что качественное изучение нового языка требует много времени, в то время как тот же питон уже хорошо известен. Ну, или автор имеет в виду, что все, кто изучает динамические языки заведомо безалаберны в плане строгости кода, но это уже как-то чересчур
WASD1
14.09.2022 15:41По-моему вполне понятная мысль:
Динамический язык берут для скорости (как минимум начальной разработки). Если вы это техническое решение уже приняли - то скорее всего time to delivery у вас в приоритете над корректностью было и скорее всего остаётся.
И это не имеет отношение к небрежности разработчика, а лишь к тех.решению какой из параметров для нас важнее.

NewSouth
14.09.2022 13:47+5Есть только одна очень серьёзная причина не использовать Python при разработке: отсутствие возможности защитить свой код. Не всегда это нужно, однако.
Эта же особенность приводит к огромному количеству открытых библиотек, в каждой из которых можно покопаться - посмотреть как сделано - перенять опыт.
Всё остальное, написанное в статье - высосано из пальца. Про зависимости и контейнеры до меня уже написали.
...Если вы используете Python сегодня, я думаю, что вы просто обязаны попробовать...
...Перепишите небольшое приложение или утилиту ...
...начните думать о том ...
Спасибо за советы, особенно про "начать думать" прекрасно

13werwolf13
14.09.2022 13:54-2все зависимости должны присутствовать. Если один из них внезапно пропал, был обновлен или требуемая версия Python недоступна, ваша программа скорее всего не запустится
не понял претензии.. это же проблема любого ЯП разве что кроме rust и go (и то при условии что мейнтейнер собрал в дефолтном варианте со статической линковкой). и эту проблему решает не юзер а пакетный менеджер благодаря прописанным зависимостям в пакете, ну а если вы ставите софт не через ПМ то ССЗБ.
andrey_ssh
14.09.2022 14:23+3Я вот вчера поставил софт через пакетный менеджер, и ...
ImportError: No module named 'numpy.testing.decorators'
13werwolf13
14.09.2022 14:42и на солнце бывают пятна. но такие вещи мейнтейнер после репорта правит за минуты две, а встречаются они крайне редко.

ainoneko
14.09.2022 19:05Такие проблемы везде встречаются.
Некоторое время назад пытался ставить Nextcloud через рекомендуемый "snap" -- типа, всё просто -- но не всё заработало. Оказалось, что в snap закаталили версию PHP (слишком новую), с которой этот баг проявляется.
С Golang: после очередного обновления языка перестали работать предыдущие упражнения с Еxercism.13werwolf13
14.09.2022 19:11Я говорил про системный пакетный менеджер, а когда в системе появляется второй пм (pip, snap, flatpack, etc) да ещё и с криворукими мейнтейнерами как в snap всегда начинается жопа. Не засоряйте систему.

nidalee
15.09.2022 07:40И в системном пакетном менеджере иногда пролезает всякая ересь, чего стоил широко известный в узких кругах снос DE с помощью установки Steam через apt install.
13werwolf13
15.09.2022 08:27<joke_mode>широко известный косяк среди пользователей малоизвестной ПОПоси?<\joke_mode>
честно говоря слабо представляю что там наворотили мейнтейнеры что так получилось (хотя вообще-то, чуть чуть подумав, хорошо представляю), особенно учитывая что стим поставляется не как нормальный пакет а как лоадер который тянет софт в хомяк юзера (что само по себе является дикой кривотой, но с проприетарным софтом иногда иначе не сделать). ну как я уже писал выше - и на солнце бывают пятна. я больше 10 лет пользуюсь одним дистрибутивом на своих личных устройствах и по работе постоянно связан с немалой пачкой других дистрибутивов и ОС. такие вот приколы я встречаю крайне редко, по сравнению с остальными проблемами вообще практически никогда. так что да- несмотря на существование таких косяков единый ПМ в системе всё ещё буду называть как правильное решение. и снова повторюсь - даже в конкретной проблеме всё что надо было сделать пользователям это написать один багрепорт мейнтейнеру пакета и подождать минут 5 (чуть больше если мейнтейнер живёт в другом часовом поясе и в данный момент времени спит).
гораздо хуже пользователям aarch64 устройств, мне несколько раз мейнтейнер отвечал в багрепорте что не может протестировать исправление так как для этого нужно железо а у него только виртуалка. но и это решаемо, было бы желание.
nidalee
15.09.2022 08:29даже в конкретной проблеме всё что надо было сделать пользователям это написать один багрепорт мейнтейнеру пакета и подождать минут 5 (чуть больше если мейнтейнер живёт в другом часовом поясе и в данный момент времени спит).
Все так, но писать багрепорты вообще в голову рядовому пользователю не придет. Он пойдет гуглить, и найдет ту саму команду для apt.13werwolf13
15.09.2022 08:37+1голову рядовому пользователю не придет
разве это претензия к ПМ или к ОС? да нет, это претензия в первую чередь к пользователю, а во вторую к менеджменту который не дал (либо дал но не показал) средство сообщения об ошибках. согласен, иногда отписывая багрепорт в багзиллу я ругаю её за то что она неудобна, некрасива, и вообще отстала от жизни на сто лет. но она работает. добавить в систему гуёвый способ быстро отправить багрепорт не проблема, сложнее научить пользователя его не игнорировать.
напомню что в винде такой способ был (а может и есть, я не сильно вкурсе что там сейчас), но на моём опыте, и опыте коллег, писать туда и отправлять отчёты бесполезно, ответа не будет никогда, ровно так же как и найти глубоко спрятанный на сайте майкрософт способ отписать ошибки, там ни ответа ни исправления тоже не дождёшься, скорее тебе ответит другой пользователь и в лучшем случае посоветует какой нибудь костыль с просторов интернета.
так что выбирая между двух зол я выберу неудобную багзиллу и реальное исправление чем игнор и ответ из гугла с сайта васянопочинкапека.орг. и опережая следующий вопрос "а что делать моей престарелой прабабушке в такой ситуации?" отвечу - "а вы собственно ей на что? помогите родственнику, а заодно и всему коммюнити.".
gluk47
14.09.2022 14:11+1Perl был Python своего времени
Perl: December 18, 1987
Python: 20 February 1991Не ровесники, конечно, но кажется, «своё время» у них одно и то же.
Sklott
14.09.2022 14:54Ну в свое время Perl был гораздо более известен и распространен, хотя Python уже как-бы был. Так что в этом смысле он написал все правильно.

Magn
14.09.2022 14:11-2Все проблемы решаются при необходимости. Есть pyinstaller, есть pyoxidizer. А можно вообще все зависимости в egg формате поставлять рядом со скриптом, если не охота изучать другие варианты (сработает не со всеми зависимостями, но со многими)
karambaso
14.09.2022 14:17+1В тексте приведён аргумент из спора типизированный против нетипизированного языка. Аргумент очень общий, но стоит заметить, что существует огромный мир JS, который сегодня занимает большую часть доли приложений в браузерах. И JS - нетипизтированный. Ну или слабо типизированный, если кому-то угодно. В связи с этим есть важный вопрос, ответ на который требует большого опыта возни со слабо типизированными языками.
Вопрос такой - как пишущие на JS побеждают рефакторинг? Это же страшная боль. Поменял структуру данных, например название поля изменил на одну букву, и всё, нужно искать обычным текстовым поиском, изучая все комментарии и строчные константы, выловленные таким поиском. А бывает ведь и очень распространённое название, вроде "name", которое встречается во множестве структур. И как больно рефакторить вот такое?
Как несчастные JS-developer-ы справляются с простейшими для строго типизированных языков задачами? Не оттого ли они массово бегут на TypeScript и ему подобные строго типизированные языки? Или?

Format-X22
14.09.2022 14:49Или на фронтенде у тебя не мильён строк на страничку и рефакторинг поиском справляется. А если мильён - добро пожаловать в TypeScript.

antonblockchain
14.09.2022 17:18ide рефакторит все включения САМО.
(vs,idea)
попробуйте нормальное ide.
rinat_crone
14.09.2022 18:32+2да с чего б вдруг? откуда у IDE информация о типах в нетипизированном языке? Как IDE различит `user.name` и `user.name`, если это объекты разных классов, но лежащие в переменных с одинаковыми именами?
И не думайте что вы такой один в белом пальто: если вы открыли для себя IDE месяц назад, то это не значит что другие не открыли совсем.antonblockchain
15.09.2022 09:28именно так это и работает уже как минимум 10 лет.
смотрите скрин рефакторинга.
там изменена только локальная переменная объект.
а глобальная переменная не рефакторится — так как ide КОНТРОЛИРУЕТ область видимости при рефакторинге.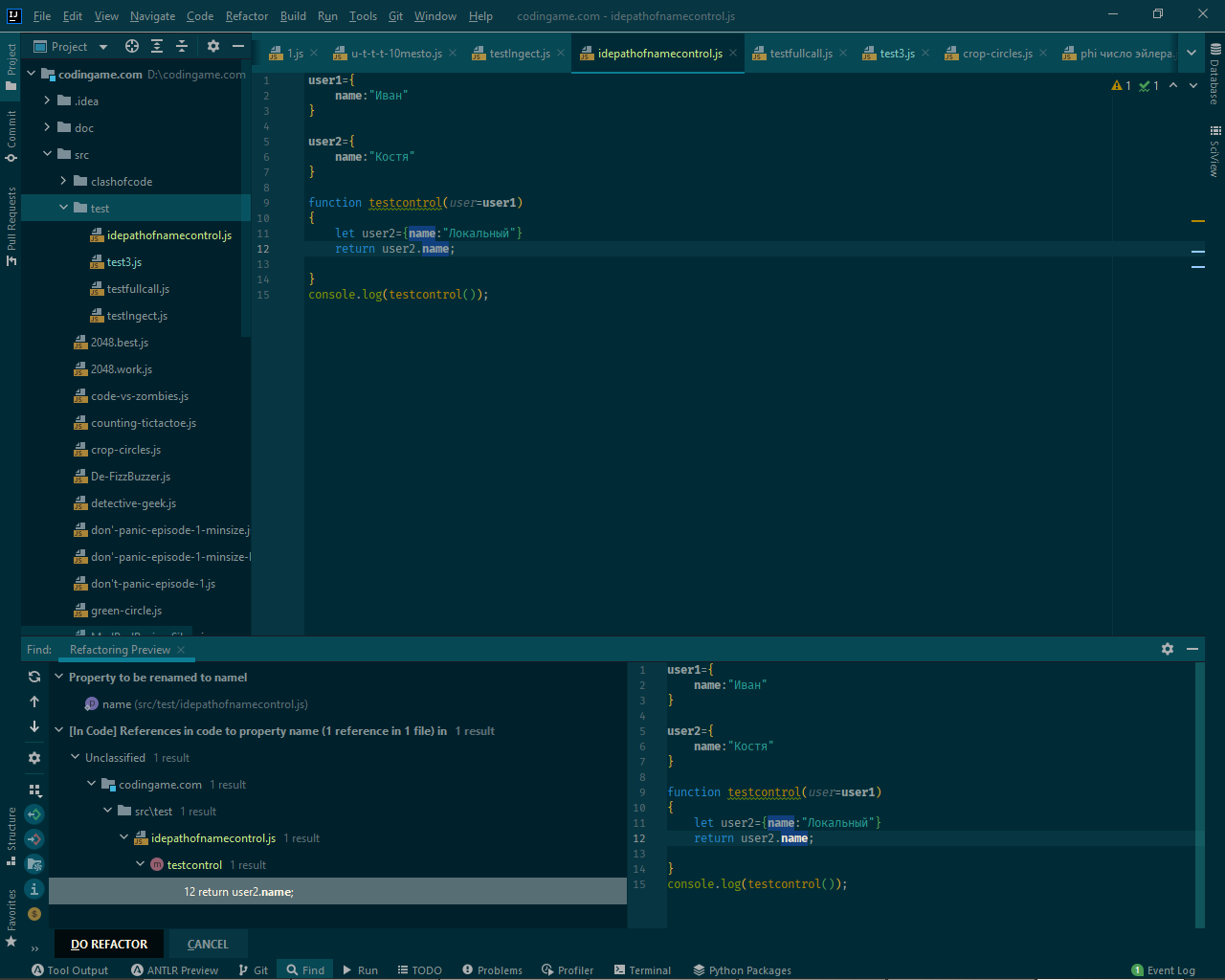
и ide я открыл в 1991 тогда это был turbo pascal 5 и turbo c в текстовом режиме.
и тогда, в 1991, так действительно ide не умели.
результат
с разморозкой)rinat_crone
15.09.2022 13:10Я немного не про область видимости говорю. Давайте попробуем вот такой (высосанный из пальца, но тем не менее, являющийся валидным JS) пример отрефакторить, переименовав поле `name` в объекте, возвращаемым под условием в функции (4 строка).
function get_user(param) { if (param >= 0.5) { return { name: 'test' }; } return { name: 'another' }; } user = get_user(0); console.log(user.name); user = get_user(1); console.log(user.name);
Кажется, что без понимания типов IDE прийдется выполнять наш код, чтобы понять что происходит.antonblockchain
15.09.2022 14:14-1Мой ответ был на вот этот вопрос изначально:
Вопрос такой — как пишущие на JS побеждают рефакторинг? Это же страшная боль. Поменял структуру данных, например название поля изменил на одну букву, и всё, нужно искать обычным текстовым поиском, изучая все комментарии и строчные константы, выловленные таким поиском. А бывает ведь и очень распространённое название, вроде «name», которое встречается во множестве структур. И как больно рефакторить вот такое?
см по треду.
что касается кода то можно требовать с разработчиков документировать типизацией.
//https://habr.com/ru/post/688108/#comment_24734302
// плюс пример документации которая будет вывешивать посдказки
// а еще можно через значение по умолчанию типизировать — очень рекомендую
//https://jsdoc.app/tags-param.html
/**
*
* param param {number} compare with 0.5 ru: сравниваем с 0.5
* @returns {{name: (string)}} обект с полем имени
*/
function get_user(param) {
return {
name: (param >= 0.5)?'test':'another'
}
}
user = get_user(0);
console.log(user.name);
user = get_user(1);
console.log(1+user.name);
а вот автоматическое подчеркивание
и автоматический список ВСЕХ таких мест в коде
где ошибка типизапции.
те-же варнинги что и в delphi ) чуть мягче
но все под контролем у ide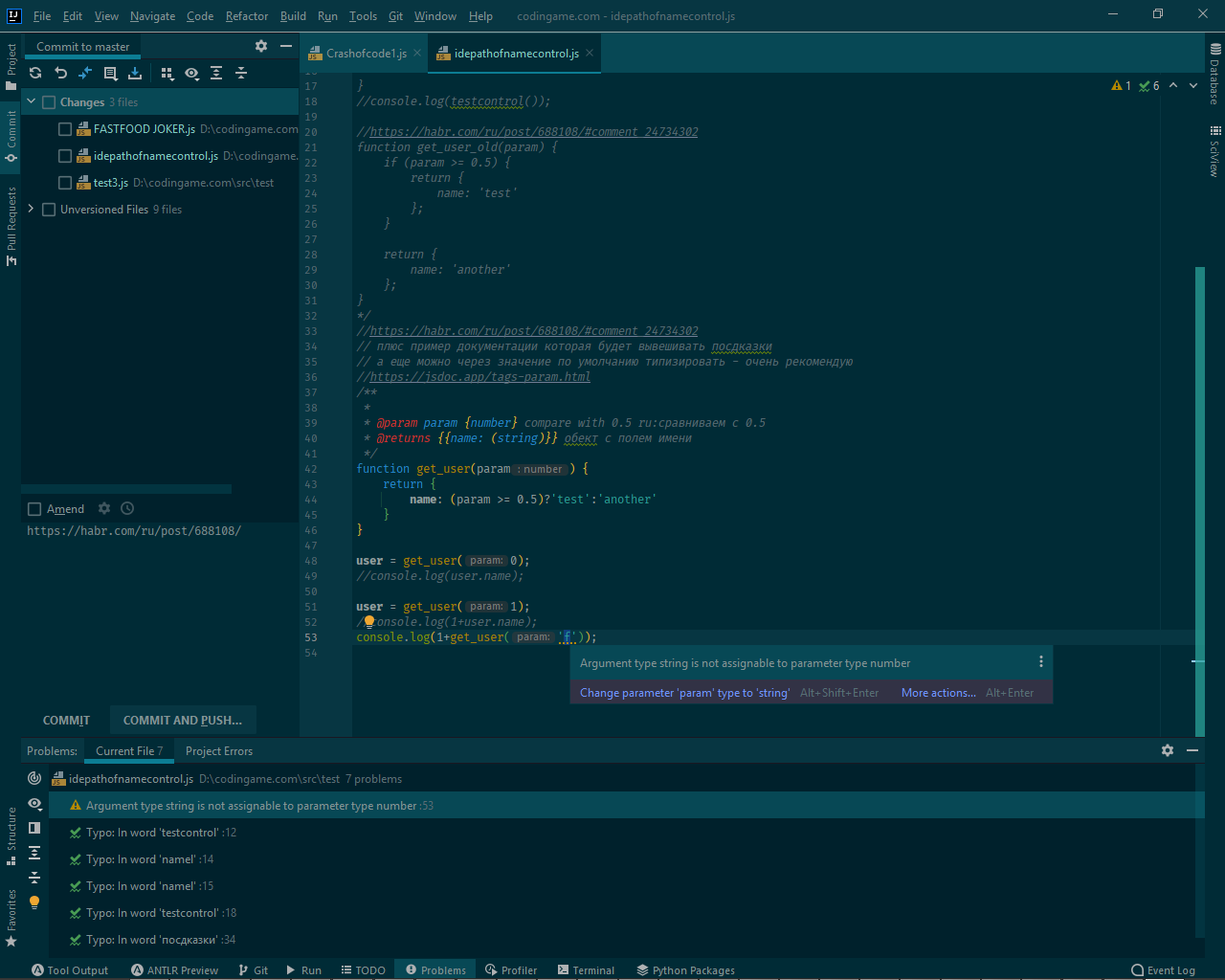
vkni
15.09.2022 18:17+1И это органично совмещает недостатки обоих подходов. Во-первых, требует от разработчиков дисциплины, совершенно ненужной для какого-нибудь Pascal'я, во-вторых вместо вывода типа заставляет его прописывать, что уменьшает гибкость.
antonblockchain
15.09.2022 20:20-1борьба с излишней типизацией это минус Delphi.
оттуда виртуальные методы.
постоянные перегрузки методов.
и интерфейсы вечные.
а еще по типу на каждое сингле представление данных.
бывает половина кода интерфейса или апи к библиотеки это усилия по обману излишней типизации языка.
и разных по этому выховов функций и перечисления параметров.
дописки stdcall… и прочие префиксы.
штук 10 разных типов строк.
которые совместимы между собой с трудом.
а учитывая что сравнение не перегружается все это превращается в списки функций сравнения разных типов представлющих по факту один и тот-же артефакт.
что серебряной пули нет.
последние 20 лет все качнулось в сторону более мягкой типизации.
как раз из-за возможностей ide и проверки при сброках.
даже в c++ появился тип auto.
auto requested_url = this->requestedUrl().toString();vkni
15.09.2022 20:39борьба с излишней типизацией это минус Delphi.
Вы ещё FORTRAN66 в пример приведите. В 84 году появился Standard ML, в котором статическая типизация и все типы выводятся.
И нет, это не "более мягкая типизация". Наоборот, она строже, чем в Delphi и C++ с Явой.
0xd34df00d
16.09.2022 05:58даже в c++ появился тип auto.
Нет в C++ такого типа, и к более мягкой типизации он не имеет никакого отношения.
antonblockchain
16.09.2022 14:18имеет, потому что позволяет программисту написать код из одних auto в коде вместо декларации типа.
а тип затем и придуман чтобы программист его декларировал.
«ожидаю получить значение этого типа.»
и да, я понимаю что при компиляции компилятором подставляется реальный тип.Kanut
16.09.2022 14:21+1Это же просто "сахар". Все эти var, auto и прочее. Вы всё равно не сможете сделать вещи вроде:
var i = 1; i = "1";
antonblockchain
16.09.2022 21:33отлично. но это дополняет с ХОРОШЕЙ стороны мой комментарий.
дополняет более детальным разбором механикой реализации.
а не противоречит.
0xd34df00d
17.09.2022 01:16+1Нет, тип не придуман, чтобы программист его декларировал, это неконструктивное и вредное представление о типах.
Тип придуман для того, чтобы компилятор (вернее, тайпчекер) мог проверить программу без её запуска на отсутствие некоторых нежелательных поведений и на наличие желательных.
HemulGM
16.09.2022 07:36Прошу прощения, а про дженерики вы слышали? Про Variant/TValue, про вывод типов?
Строки в Делфи одни - string и всегда так было (не считая shortstring). Строки типа WideString/AnsiString - это платформенные строки Windows.
Интерфейсы используются вообще для другого, уж точно не для обхода строгой типизации (например, для использования ARC или взаимодействия программы с другой).
Разные вызовы функций (stdcall/cdecl..) вообще используются, потому что существуют, внезапно, разные вызовы функций.
var Str := 'Hello world'; var f := function: integer begin Result := Random(10) end; var int := f(); for var i := 0 to 10 do for var Item in Items do var I := JSON.GetValue('count', 0); // integer var S := JSON.GetValue('name', ''); // string var B := JSON.GetValue('status.active', False); // boolean var MyObj := TJSON.FromJson<TMyObject>(JSON); // TMyObjectGetValue - тут не перегруженный метод, а дженерик метод. Тип определяется переданным вторым параметром default. Аналогичный код:
var I := JSON.GetValue<integer>('count', 0); // integer var S := JSON.GetValue<string>('name', ''); // string var B := JSON.GetValue<Boolean>('status.active', False); // booleanПерегрузка операторов тоже давно имеется.

anarchomeritocrat
15.09.2022 02:09Поменял структуру данных, например название поля изменил на одну букву, и всё, нужно искать обычным текстовым поиском, изучая все комментарии и строчные константы, выловленные таким поиском.
Есть у меня лайфхак )
во первых я использую однотипные шины данных, у которых структура и интерфейс унифицированы везде. В качестве примера можно рассмотреть мой велосипед (ну типа да, только ленивый не писал свой стейт менеджмент под реакт )) осторожно - бета, юзать на свой страх и риск, контрибьюторы велкам, но с одним условием - билд не должен превышать 999 байт, бзик у меня такой), в котором описана концепция SAS Bus (от State, Actions, Scripts)
во вторых я не пишу портянки и стараюсь поддерживать модульную структуру кода, типа один класс - один модуль, или там один компонент - один модуль, при этом если что то выделяется в компонент или класс, то в духе unix way - должен делать что то одно, но делать это максимально хорошо.
в третьих я не стесняюсь писать самодокументированный код и у меня навряд ли где то встретится просто name, а скорее будет нечто вроде someHrenovinaOfFigovinaName, разве что если это не код в пределах пары сотен строк, и то часто стараюсь не стесняться в именованиях, тут главное помнить, что Вам не надо работать вместо обфускации - она куда лучше Вас всё сократит потом )
При таком подходе рефакторинг сводится к поиску по имени шины всех использующих её модулей, а отрефакторить по сути небольшие модули на переименование скорее всего гарантированно уникального идентификатора уже дело техники - вообще не напряг




WASD1
14.09.2022 14:44+3Python даёт очень низкий CapEx и довольно высокий OpEx (что для человека, решившего "выучить язык программирования", что при разработке нового проекта).
Мне кажется, что именно в таком ключе обо всём написанном в статье и наждо думать. В частности: в какой момент наши "всё время чуть большие расходы по сопровождению \ доработке" перекроют выгоду от "более быстрого старта".
Лично для меня Python - программерская замена bash. И я пишу на нём скрипты до 1000 строк кода (разумеется при доработках эта 1000 бывает превращается в 2-3 тысячи, но это нормально).
А вот условные 5000 строк кода на Python - это уже многовато для меня, я просто понимаю, что будут проблемы в доработке \ поддержке и лучше изначально возьму что-то другое.

piratarusso
14.09.2022 14:57+1Крайне тенденциозная статья. Что впрочем типично, когда человек привязан к одной технологии и пытается её сравнивать с другой. Например, для статически типизированных яп известна проблема под названием dll hell. Так что если мы начинаем задумываться о проблемах зависимости модулей, то замена статически типизированного яп на динамически типизированный яп или наоборот эту проблему принципиально не решает вовсе. Кроме того, никакой яп не может помешать писать неряшливый код. Мне кажется, что применение python решает несколько другие проблемы it отрасли. В первую очередь проблему кадрового голода...

Megadeth77
14.09.2022 15:12-4В эпоху контейнеров наяривать на бинарники? Ну ок. Аннотации типов, MyPy? Не, не слышал. Т.е. опять малограмотный мимокрокодил попадает в свою же ловушку обозначенную в самом начале статьи. Прелесть "неряшлевых" языков в том что на таких можно писать хорошо, а можно неряшливо, когда это необходимо. Это зависит от программиста, инструмент его тут не ограничивает, не хватает за руки и ни к чему не принуждает.

DeepFakescovery
14.09.2022 15:30-4честно какой-то бред. Написано какими-то абстракциями. Очевидно у автора возникли проблемы с питоном и сборкой софта для конечного пользователя, но вместо того чтобы найти решения, которые 100% есть, он решил накатать статью, призывающую не разрабатывать на питоне...

economist75
14.09.2022 15:45+4Немного в защиту лежачего. Возьмем, к примеру, реальный завод с 2 тыс. работников и 30 млрд. выручки в год. Статистика локального GitLab сервера говорит мне о том что 70% нашего кода написано на Python, и что это DS/ML-код и админ-утилиты или web-приложения "по требованию". Этот код постоянно дописывается, буквально ежедневно. Админ-утилиты, DS-утилиты, MVP-продукты - это тоже "инструментарий", против которого озаглавлена статья. Но позвольте, если что-то постоянно дописывается - компилируемый язык будет хуже интерпретируемого. Статический будет хуже динамического. И да, простой requirements.txt на сетевой шаре достаточен для 99% рабочих мест. Даже виртуальное окружение тут избыточно. Даже при ежедневном бездумном каскадном обновлении всех либ - поломка случается пару раз в год. Windows BSOD-ит и то чаще.
Если ваш py-код нужно защитить на уровне 80% других защищенных программ - есть готовые либы для этого. Для оставшихся 20% есть вынос функций в зашифрованные С-либы/exe. Или да, используйте другие языки программирования. Правда это почти никого никогда ни от чего не спасло. Но я охотно приведу примеры серийных, тиражных, общеизвестных дорогостоящих платных программ (стоимостью 800-3500 евро), которые десяток лет кряду(!) никто не смог взломать. По странному стечению обстоятельств это музыкальные программы/DAW: Steinberg Cubase/Nuendo и Propellerhead Reason Studio. Их перестали ломать после того как заметную часть двух хакерских группировок... взяли на работу в эти самые компании, для защиты ПО от себе подобных. Это сработало, но стоило компаниям очень дорого - их на рынке сильно потеснили более дешевые альтернативы. А часть халявщиков, исчислявшаяся миллионами - отвернулась, утратив возможность крякать свежие версии. Одним словом, защита ПО невероятно сложна и решаема она экзотическими, часто неповторимыми более методами. Ставить в укор Python-у то что его код слишком открыт - некрасиво.
Типизация, как и проблема смешивания табуляции и пробелов в Python-коде - абсолютно надуманы. Их давно, лет уже как пять, нет. Современные IDE могут навсегда вам запретить присваивать переменные без указания типа. Любая попытка отладки/запуска - даcт ошибку линтера. Сразу. Это ничем не отличается от поведения компилируемых языков, разве что в Python выдаст сбой мгновенно, а в других нужно секунды подождать.
Символ табуляции вы при всем желании не введете в IDE (он будет заменен на 4 пробела). Но эти две страшилки (про типизацию и табуляцию) - мы с уверенностью обнаружим в каждой анти-змеиной статье или ее обсуждении. Становится просто смешно. И страшно за молодежь, принимающую такие страшилки за чистую монету. Приходится уговаривать людей проверить самим такое поведение в IDE.Питон есть за что ругать - за медлительность, за вариативность путей достижения целей, не по дзену, и еще раз за медлительность. Но ругать его за массово признаваемые его же плюсы - несерьезно.
inferrna
14.09.2022 16:29+2Скажите, пожалуйста, а со статической типизацией стало бы сильно хуже?
economist75
14.09.2022 17:07Да, стало бы значительно дольше писать тот же код, мучительно сложно придумывать созвучные типу имена. И скорости Питону это не прибавило бы нисколько.
Выбирая динамический язык - мы клянемся себе в аккуратности в обмен на быстрое прототипирование. А в статическом языке, пока пропишешь все объявления - запал пропадает, вплоть до нехоти. Питон не даёт простоя идеям. В утилитах, DataScience и админ-скриптах на страничку - это важно. В больших программах и для команд в 5+ разрабов - стоит подумать ещё раз о смене языка на статический компилируемый
vkni
15.09.2022 01:14+1Да, стало бы значительно дольше писать тот же код, мучительно сложно придумывать созвучные типу имена.
А зачем вы это делаете?
А в статическом языке, пока пропишешь все объявления
Вывод типов Хиндли-Милнера открыли до моего рождения. И, скорее всего, даже до вашего.
Кмк, на 2к пользователей писать что-то на Питоне достаточно страшно.
Sklott
14.09.2022 17:40Как бы если есть желание, то на питоне можно писать со статической типизацией. Но для каких-то проектов - это просто лишний оверхеад не приносящий никакой практической ценности.

voidMan
15.09.2022 13:21в PHP статическая типизация сейчас это норма, стало только лучше, ошибки проще и быстрее отлавливать.

mgearr
15.09.2022 04:39+1Для примера, C++, Rust и Haskell - все статически типизированные, но во всех трёх это сделано по-разному. Какой подход правильнее? А какой удобнее в работе? Оба вопроса, разумеется, риторические
Статическая типизация - средство, а не цель. Где-то она помогает, а где-то, наоборот, мешает. Если б только помогала, то все языки были бы типизированными
Очевидно, что типизация помогает ловить ошибки, но так же очевидно, что помогает не бесплатно: и писанины вообще становится больше, и некоторые концепции становятся весьма трудноописуемыми
Да и потом, если б типизация была панацеей, так ведь нет, ошибки содержатся в программах, написанных на любых ЯП
0xd34df00d
15.09.2022 16:22+1Да и потом, если б типизация была панацеей, так ведь нет, ошибки содержатся в программах, написанных на любых ЯП
Только на расте их в среднем меньше, чем на плюсах, а на хаскеле меньше, чем на расте.
mgearr
16.09.2022 02:00-1Для простоты рассуждений соглашусь, что именно так дела и обстоят, но ведь безошибочность программ не является целью их написания. Программы нужны для выполнения задач. И вот тут (внезапно) выясняется, что абсолютно всё определяется сроками и стоимостью написания минимально рабочего кода, затем дополнения функционала и правки ошибок. При этом знаменитая Строгая Типизация ©, как ни странно, не особо-то и спасает отцов русских демократий
Любые программы глюкуют. Все к этому привыкли, смирились и научились с этим жить. Проблема не в самом факте наличия глюка, а в том, насколько сильно он мешает выполнению производственных задач. Выгодно ли его исправлять. Потому что исправление - оно ж не бесплатное ни разу
Вот сказ о том, как одни и те же люди пишут на питонах и на хаскелях. Выводы достаточно неочевидные
Haskell в продакте: Отчёт менеджера проекта
баги в программе на Хаскеле фиксить сложнее, чем в языках с динамической типизацией
программа на Haskell равно так же не защищена от сегфолтов
поиск программистов является проблемой
проекты на Хаскеле пишутся медленнее, чем на Питоне
сложное прототипирование
Это я, конечно, не к тому, что надо бегом бежать всё переписывать на языки с динамической типизацией, а к тому, что ни фига нет ничего идеального в этом, блин, несовершенном мире
DirectoriX
16.09.2022 02:32+2баги в программе на Хаскеле фиксить сложнее, чем в языках с динамической типизацией
По вашей же ссылке:По опыту разборов найденных ошибок я могу сказать, что большая часть ошибок, с которыми мы сталкивались — это либо ошибка в ТЗ (то есть ошибка вашего покорного слуги), либо неправильно понятое ТЗ программистами. Но не локальная ошибка или забывчивость.
Из этого вытекает парадоксальный вывод: баги в программе на Хаскеле фиксить сложнее, чем в языках с динамической типизацией, потому что в языке с динамической типизацией очередное место, где вдруг внезапно вылез NoneType, поправил и ладушки, а на Хаскеле надо с алгоритмом разбираться да по повводу неясности ТЗ с другими людьми ругаться.
Простите, но это то, что называют cherry picking — выборочное цитирование только того, что подтверждает вашу мысль, в отрыве от контекста.
Разумеется, если в проекте на Haskell 100 логических ошибок, а точно таком же функционально проекте на Python те же самые 100 логических + 1000 «ой, забыли сделать проверку/приведение типа и оно внезапно упало во время выполнения ))0)» — на Python в среднем ошибки будут исправляться проще. А то, что их будет сильно больше — вы, почему-то, умолчали…mgearr
16.09.2022 03:09Прощаю с лёгким сердцем, потому что я как раз и цитировал выборочно. Про недостатки питона знают чуть более, чем все, но при этом, наверное, не меньше народу почему-то уверены, что в хаскеле (и прочих типизированных языках) мёдом намазано
А суровая правда состоит, что там, как и везде, местами намазано мёдом, а местами не совсем тем, чем хотелось бы, чтобы было намазано
Вообще, лёгкость применения инструмента бывает обратно пропорциональна степени защиты. Простой пример: межкомнатная дверь и дверь сейфового хранилища. Понятно, что сейфовая безопаснее, но и ходить сковозь неё геморройнее. И тысячу человек в час она сквозь себя не пропустит, если каждый раз открывать-закрывать. И из этого же сравнения становится примерно понятно, почему питона в природе намного больше, чем хаскеля
Ни сейфовые, ни межкомнатные двери не ставят везде, где нужна дверь, поскольку универсальных дверей не существует и не может существовать. Но межкомнатные двери не ругают за то, что они не сейфовые, а питон ругают за то, что он не хаскель. Не посчитать ли нам с вами это явление странным?
0xd34df00d
16.09.2022 06:21+1что в хаскеле (и прочих типизированных языках) мёдом намазано
Нет. От окамля, например, я плююсь (там не чистое ФП, по взгляду на тип не понять, что делает функция), и про хаскель мне есть что плохого сказать, вроде, навскидку:
- Кривая стандартная Prelude по историческим причинам. Есть
map, а естьfmap. Или есть кривойFoldableдля туплов, когдаlength (foo, bar)равно единице, аmaximum (42, 6)равно6. - Отсутствие инстанса в духе
MonadError String (Either String). Мелочь, но аштрисёт. - Отсутствие завтипов. Ну это я после всяких идрисов-агд зажрался, впрочем, и не в треде про питон это упоминать.
- Зато вместо завтипов есть эпическая куча расширений — DataKinds, PolyKinds, TypeFamilies, InjectiveTypeFamilies, QuantiifedConstraints, иногда с нетривиальным взаимодействием. Богатый на вычисления на уровне типов код проще писать на идрисе или агде.
- Язык логически консистентным не будет никогда. В доказательстве выполнения условных монадических законов для моего типа на хаскеле я не буду уверен так же, как в доказательстве на идрисе (а в нём — меньше, чем в доказательстве на агде). Впрочем, никто не мешает ключевые моменты писать на той же агде со всеми доказательствами и экстрагировать результат в хаскель. Люди так даже делают.
Короче, да, в хаскеле есть проблемы, но это
- не сегфолты (в сишных либах, ага, которые использовать совсем не обязательно),
- не тяжесть отладки (забыли нормировать на уровень багов, когда в питоне забыли named parameter переименовать, а в хаскеле проект по символьному вычислению после переписывания построения бесконечного дерева путей символьного вычисления программ на System Fω на ана/катаморфизмы начал в некоторых случаях вести себя по другому… на питоне он бы просто никогда не был бы написан),
- не более долгое время разработки (потому что после окончания разработки степень вашей уверенности куда выше, а если вам хватает питона и «ну вроде SyntaxError нету, фигачим в прод!», то, ну, я бы не смог так работать).
Программистов вот тяжелее искать, чем на питоне, это факт. Но тут тоже есть некоторые тонкости, начиная от знакомства с предметной областью (рандомный хаскелист куда вероятнее осилит движок символьных вычислений или понятие operational monad, чем рандомный питонист, равно как и рандомный шарящий в символьном вычислении чувак скорее будет охотно писать на хаскеле, чем на питоне) и заканчивая неким ореолом башни из слоновой кости, который, увы, поддерживается людьми, желающими погреть своё ЧСВ за счёт выучивания того самого определения монады и рассказывающими, что в хаскеле без теорката делать нечего.
И нет, я не слепой фанат хаскеля. Просто питон несравнимо хуже.
Прощаю с лёгким сердцем, потому что я как раз и цитировал выборочно.
Выборочное цитирование — это ну такое, так можно очень далеко зайти. Смотрите, по вашей же ссылке пишут
в питоновском коде — шайтан-арба
в Питоне всё равно получается медленнееmgearr
16.09.2022 10:36Ну вот, опять это "медленнее ". Top1 претензия к питону. Или top1 - это "нет многопоточности"? Всё время путаю, которая из них топовее
Скока ж можно-то? Ну медленнее, да. Как будто бы с этим кто-то спорит. Оно ведь и телефон медленнее компьютера, и отвёртка медленнее шуруповёрта, и лопата медленнее экскаватора, и велосипед медленнее космического корабля. Все примеры перечислять, где что-то медленнее чего-то - тысячи жизней не хватит
О! Идея! А давайте все лопаты запретим? Ну медленно же ж. И отвёртки заодно. И велосипеды, само собой
А ведь это те же самые люди, которые уверяют, что выборочно цитировать нехорошо...
0xd34df00d
17.09.2022 01:17А ведь это те же самые люди, которые уверяют, что выборочно цитировать нехорошо...
Я вообще-то как раз и проиллюстрировал, что выборочное цитирование до добра не доводит.
- Кривая стандартная Prelude по историческим причинам. Есть
0xd34df00d
16.09.2022 06:04+1При этом знаменитая Строгая Типизация ©, как ни странно, не особо-то и спасает отцов русских демократий
Ага, поэтому компиляторы при прочих равных скорее выбирают писать на хаскеле или прочих ML-языках, а не на питоне.
Питон хорош как клей, для этакого шелл-скриптинга, когда текстового формата шелла не хватает. Точно так же, как я не буду переписывать свой скрипт бекапов моей машины (вызывающий rsync несколько раз для разных директорий) с шелла на хаскель, я не буду переписывать условный скрипт на питоне, который вызывает тензорфлоу несколько раз и указывает, какие матрицы куда и как перекладывать. При этом ни rsync, ни tensorflow не написаны на шелле или питоне, и никогда не будут на них написаны.
Выводы достаточно неочевидные
Вы очень фигурно цитируете.
mgearr
16.09.2022 10:50Вы очень фигурно цитируете
Спс, я старалсо
Питон хорош как клей, для этакого шелл-скриптинга
Лично я вообще не в восторге от его использования в качестве "баша на стероидах". Слишком много бойлерплейта на каждый чох
andreymal
14.09.2022 18:06+4Современные IDE могут навсегда вам запретить присваивать переменные без указания типа
Этого недостаточно для нормальной работы типизации. Из проблем, с которыми столкнулся лично я:
- проблемы с рекурсивными типами в mypy (issue закрыли месяц назад, но это всё ещё «experimental feature»)
- нет нормальной поддержки sentinel в том же mypy
- без exhaustive matching использовать enum'ы по сути бессмысленно
- нет поддержки прокси-объектов, которые активно используются, например, в Django и Flask
- нет поддержки добавления атрибутов к функциям, хотя в том же Django на этом построена половина админки
- при сложных манипуляциях с дженериками mypy может выпадать в осадок. Я сейчас сходу не приведу конкретных примеров (потому что они сложные, хех), но у mypy есть много открытых issues на тему дженериков
- полнейший бардак в аннотациях объектов ввода-вывода (нет разделений на read/write, seekable/non-seekable и т.п.), а ещё нужно каким-то чудом понять, чем различаются IO[bytes] и BytesIO например
- атрибуты в python-объектах могут создаваться и удаляться на лету, что позволяет выстрелить себе в ногу, когда проверка типов успешно проходит, а в рантайме всё падает
- всё ещё есть множество библиотек, для которых нет аннотаций и/или для которых написать аннотации невозможно (или в лучшем случае очень затруднительно) из-за злоупотребления метапрограммированием (тот же django-stubs обмазан кучей Any, например)
- даже для стандартной библиотеки аннотации попадаются некорректные или неполные. Вот из того, на что я на прошлой неделе напоролся: create_datagram_endpoint по аннотациям возвращает экземпляр класса BaseTransport, а в реальности возвращается экземпляр какого-то приватного класса-потомка. И проблема в том, что мне нужно использовать метод sendto, который в реальности есть, а в аннотациях нет — из-за этого получается ложноположительное срабатывание в mypy и приходится обмазывать код в
# type: ignore(ну или наверное можно навелосипедить какой-нибудь Protocol, но с какого перепуга этим должен заниматься я?) - самый заплюсованный открытый issue в репозитории mypy — int это не число, лол
И это я ещё ничего не понимаю в теории типов — если вдруг в этот пост заглянут те, кто понимает, они полностью разнесут систему типов питона
Sklott
14.09.2022 18:16Как бы не специалист в типах питона, но вот это
атрибуты в python-объектах могут создаваться и удаляться на лету, что позволяет выстрелить себе в ногу, когда проверка типов успешно проходит, а в рантайме всё падает
выглядит примерно как: а в C++ можно сделать так
ObjA *objA = new ObjA; auto *objB = static_cast<ObjB>(ObjA); objB->NonExistingInAFunction();что позволяет выстрелить себе в ногу, когда проверка типов успешно проходит, а в рантайме всё падает.
Ну в том смысле, что да, языки часто позволяют много чего, в том числе стрелять себе в ноги/голову/и т.п., но при чем тут сам язык?
andreymal
14.09.2022 18:25+1Вот примерно поэтому я C++ ненавижу и стремлюсь уничтожить :)
при чем тут сам язык?
При том, что язык не должен позволять так делать. В каком-нибудь Rust вы так сделать не сможете. (Ну или если очень хочется, то сможете в блоке unsafe, но в прикладных программах unsafe-блоки не используют)
andreymal
15.09.2022 17:00Ещё вдогонку поною: хочется различать naive/aware datetime в типах, а то вот только что напоролся, случайно передав naive datetime в функцию, которая ожидает aware datetime
0xd34df00d
14.09.2022 18:42Но позвольте, если что-то постоянно дописывается - компилируемый язык будет хуже интерпретируемого. Статический будет хуже динамического.
Почему?
economist75
14.09.2022 20:24Время на компиляцию. Нет той глубины интроспекции кода из библиотек. Не та отладка. В DataScience, где итерация не просто часты, а необходимы - код который компилится быстро утомит.
0xd34df00d
14.09.2022 20:32+2Время на компиляцию.
Вам нужно сильно реже запускать код, если у вас развитая система типов.
Нет той глубины интроспекции кода из библиотек.
Эмм, можно пример? Я не уверен, что мы под интроспекцией понимаем одно и то же.
Не та отладка.
Как отладка связана с компилируемостью и с типизацией?
С одной стороны, статическая типизация тоже существенно уменьшает потребность в отладке (я серьёзно не помню, когда мне потребовалось бы запускать отладчик — это бывает, но очень редко). С другой — какой-нибудь репл, чтобы поиграться с кодом вживую, бывает и в компилируемых языках.
В DataScience, где итерация не просто часты, а необходимы — код который компилится быстро утомит.
Куда больше утомит код, который ломается где-то посередине пайплайна из-за несовпадающих
типоврантайм-меток.Я поэтому DS перестал заниматься, когда туда пришло много питонистов, не желающих тратить время на изучение прочих технологий, но желающих тратить десятки минут, если не часы, на борьбу с тем, что в нормальных языках ловит компилятор.
mgearr
15.09.2022 04:07Но ведь в современном питоне можно использовать типы, и можно настроить среду так, что соответствие будет проверяться сразу при написании. Это почти полноценный аналог ловли компилятором несовпадений типов. Другое дело, что типизация опциональна, но если СИЛЬНО бить по рукам, когда разраб использует нетипизированные переменные, то он быстренько привыкнет, что так делать низзя
Можно даже делать приведение типов (typecast)
Примерчик:
def myfunc(int_var: int, complex_var: MyComplexType) -> MyComplexType2:
... do something ...
myint: int = 2
mystr: str = cast(str, myint)
... do something more ...
return complex2_valueТам есть некоторые подводные камни, но в целом ситуация на тему проверки типов уже значительно улучшилась и продолжает улучшаться
0xd34df00d
15.09.2022 16:10+1Только в современном питоне эта самая система типов довольно слабая, и вообще непонятно, зачем тогда писать на питоне, а не на других языках, где типизация изначально адекватная, а не прикручена потом, сбоку и на костылях.
Sklott
15.09.2022 17:32Потому что не обязательно использовать их там, где их использовать не обязательно?
В C++ ведь тоже не спроста появился
auto, но он к сожалению спасает не всегда...0xd34df00d
15.09.2022 18:24+1Не обязательно кого использовать, типы?
autoв плюсах не отменяет использование типов, оно вообще очень тупое и лишь говорит «выведи мне тип согласно правой части присваивания» (и дажеauto x; x = 42;не сработает).
mgearr
15.09.2022 19:15Так она во всех языках прикручена сбоку. В 100% случаев имеется возможность ругань компилятора обойти и прогу с ошибками запустить на исполнение. Например, typecast-ов понапихать везде, где оно ругается. Уверен, что есть over9000 программ, где именно так ошибки несовпадения типов и "исправлены"
0xd34df00d
15.09.2022 19:22+1В хаскеле я могу включить safe haskell, и все небезопасные приведения типов отключатся, вместе с прочими небезопасными вещами.
В агде — аналогично, есть safe agda.mgearr
15.09.2022 20:08Любые ограничения безопасности можно как-то обойти. Это ж классическое противостояние брони и снаряда
Как говорил Квай-Гон Джинн, всегда найдётся рыба крупнее
0xd34df00d
15.09.2022 20:20+1Safe agda невозможно обойти. Это самые строгие математические гарантии из возможных.
Да и в коде на хаскеле без всяких unsafe тайпкаст (любой, даже безопасный) — это сразу большой вопрос к пуллреквесту, зачем оно так сделано. И их сразу там видно.
mgearr
15.09.2022 20:39Можно рассуждать "как надо" или смотреть "как оно на самом деле". От первого подхода на душе приятнее, зато второй позволяет находиться немножко ближе к суровой реальности
Так вот, из статистики известно, что на хаскеле почти никто не пишет. Видимо, он всё же не настолько хорош, несмотря на мощную систему типов
Выходит, от языков мало, что требуется ещё что-то, кроме безопасности типов, так безопасность типов ещё и располагается где-то в хвосте списка требований, судя по тому, что на первых местах - JS, SQL и Python
Например, это можно объяснить тем, что эти языки ЛУЧШЕ хаскеля приспособлены решать НАСУЩНЫЕ задачи. А можно никак не объяснять и просто принять как факт, нравится он или нет. Ведь даже если не нравится, он не перестанет быть фактом
0xd34df00d
16.09.2022 06:22+1Что такое насущные задачи?
Вот мне интересно делать компиляторы и тайпчекеры. JS, SQL и Python ЛУЧШЕ хаскеля приспособлены делать компиляторы и тайпчекеры?
mgearr
16.09.2022 10:13Захотелось вначале ответить на второй вопрос
Ключевое слово - мне. Не?
Лично мне кажется, что решить делать коммерческий компилер на SQL не смог бы человек, разделяющий доминирующую точку зрения на выбор языка для написания компилеров. То же, вероятно, касается жс и питона
Тем не менее, и для питона есть разные библиотеки на эту тему, например,
Python Lex-Yacc. Почему бы им и не быть? Не всегда нужна производительность парсинга офиглиард знаков в наносекундуО, вспомнил. Я ведь и сам когда-то начинал переписывать некую антикварную тулзу на питоне с использованием pyparsing. Прототип умел разбирать управляющие инструкции со скоростью во много раз выше приемлемой. То есть, даже и компилять было не надо, хватало интерпретации. Правда, дальше прототипа дело не пошло, но вовсе не из-за медлительности рантайма
The pyparsing module is an alternative approach to creating and executing simple grammars, vs. the traditional lex/yacc approach
Перехожу к ответу на первый
Сильно подозреваю, что для разных заказчиков оценка насущности одной и той же задачи будет разной. Например, можно предположить, что для некоторых заказчиков написание компилеров имеет насущность, стремящуюся к нулю.
Одно из доказательств см. выше. Я-то поначалу думал, что коэффициент насущности задачи написания компилера высокий, но потом он устремился к нулю и где-то там уже который год бултыхается
0xd34df00d
17.09.2022 01:20+1Не всегда нужна производительность парсинга офиглиард знаков в наносекунду
Дело не в производительности, а в том, что на питоне это делать просто неудобно. И на lex/yacc это делать неудобно. На PEG'ах грамматики описывать проще, беготня по деревьям куда лучше реализуется через вещи вроде uniplate, паттерн-матчинг рулит и педалит, и так далее.
Сильно подозреваю, что для разных заказчиков оценка насущности одной и той же задачи будет разной. Например, можно предположить, что для некоторых заказчиков написание компилеров имеет насущность, стремящуюся к нулю.
Абсолютно верно. Если заказчику нужен сайт-визитка, то компилятор ему совершенно не за чем.
Я как бы намекал, что нет глобально насущных задач, и вы вольны выбирать то, чем хотите заниматься.
mgearr
17.09.2022 04:43В свежих питонах сделали достаточно идейно выдержанный pattern matching. Навряд ли это поможет занять рынок тулзей для написания компиляторов, но, скорее всего, такого и не было в планах
Правда, эти шаблоны сделаны на обвязке из match/case, то есть, выглядят не так изящно, как хотелось бы, но всё же теперь они есть
economist75
15.09.2022 10:31Вы обиделись на питонистов? В DS пришли не питонисты, а DS-ты, от которых требуют не код, а идеи, решения, выводы, графики, презентации, ML-модели. Времени у них, поверьте, чуть меньше чем у кодеров, сидящих "на техзадании+Git", потому что DS-ники работают на виду у руководства, часто это топ-менеджер. Динамический Python-интерпретатор позволяет ему быстрее писать как код с ошибками, так и код без ошибок. Но время - важнее.
Этим объясняется успех IPython, Jupyter/Lab и ipynb-блокнотов в бизнес-среде. Сейчас проникновение этих технологий сравнимо с пришествием в бизнес Excel, породившем такое понятие как personal computer.
Прямо во время совещания DS-ник "за минуту" на нотубуке в блокноте на Python готов ответить на любой вопрос вида "Сколько у нас в отделе разработки уволилось за время царствования г-на Петрова по сравнению с другими начальниками? " или "Почем мы покупали в прошлом квартале известь у всех, кроме ООО Ромашка и поставщиков от Петрова?
На статическом компилируемом языке - вы за эту минуту не объявите даже все переменные. 1C таких ответов не даст вообще или даст за 20 минут. А DS-ник на Python таки-выдаст ответы на эти вопросы, поймав 2-3 раза ошибку. Но результат он даст.
Cekory
15.09.2022 11:53Прямо во время совещания DS-ник "за минуту" на нотубуке в блокноте на Python готов ответить на любой вопрос вида "Сколько у нас в отделе разработки уволилось за время царствования г-на Петрова по сравнению с другими начальниками? " или "Почем мы покупали в прошлом квартале известь у всех, кроме ООО Ромашка и поставщиков от Петрова?
Справедливости ради, это все вопросы не для DS с Питоном, а для аналитика с SQL.
economist75
15.09.2022 14:30DS - те же аналитики, только толще. Нет разницы на чем запрашивать - на SQL или в Pandas. Но Pandas из-за RAM будет быстрее в десятки раз чем RDBMS. И да, она реальна на совещании. Не верю что кому-то по wifi из переговорки дают стучаться в прод-базу, с ноута, SELECT-ом с оконными функциями. Я бы и сам этого не стал делать. А вот в локальный 20 мегабайтный PKL - стучусь. Он вмещает 40-гигабайтную базу 1С.
Лицензия запрещает работать с БД напрямую, минуя оболочки 1С. Да и причем тут 1С - в ней нет всех данных. Приходится объединять c CSV/Excel-файлами, и Pandas тут "рулит".
Переиспользование кода в случае с SQL почти невозможно. Сравнивать журнал запросов, скажем, dBeaver и Jupyter-блокнот, не теряющим значения переменных для вычисленных ячеек - несерьезно.
Cekory
15.09.2022 15:17DS - это про модели, ML и математику. И в последнюю пару лет еще хотят, чтобы DS доводил свой код до прода. То есть это уже ближе к разработчику.
Вообще, конечно, стучатся не в прод из DBeaver, а в витрины, допустим, в Clickhouse из, например, metabase. И в metabase будет автокомплит по полям таблицы и результат запроса можно сразу же визуализировать и расшарить всем заинтересованным людям и он сам будет обновляться. Все это с минимальными усилиями, во многих случаях даже запрос не надо писать. Понятно дело, это немного надо настроить, но потом окупится многократно.
Если у вас CSV и Excel, то есть волшебный мир Excel и PowerPivot, где все в пару кликов со страшной скоростью над данными в миллионы строк.
Да, и в моем мире никто бы не отдал базу 1С файлом на чей-нибудь ноут - это ну совсем как-то несекьюрно.
Я тоже когда-то думал, что только хардкор, только кодить, и это оптимальный путь. Но жизнь показала, что нет. Так что для разных описательных вещей нанимать DS с Питоном, как выше заметили - просто тратить больше денег.
P. S. Про быстроту Пандаса: вот здесь есть бенчмарки. Сравните Пандас с Кликхаузом.
economist75
15.09.2022 17:05Clickhouse мощен, спору нет. И витрины хороши, когда их кто-то для вас сделал. Но не на совещании всем этим заниматься - там действительно идет счет на секунды. Туда же лесом идут DAX и PowerPivot: только их одних - недостаточно, а платность - сильно против массовости. Своих детей я учить им не буду. Парой кликов там связь не создать, и сравнивать их с Pandas, пожалуй, уже поздно.
Очень люблю бенчмарки, и ссылку, конечно же, читал. "Однокотловый" Pandas медленный, но отвечает на любой мой запрос по бухучету по базе за 20 лет со скоростью 0,1-1 секунда. Да, индексы упорядочены, типа категоризованы и оптимальны, но раз это основной инструмент - почему бы и нет? Кликхауз это время не улучшает, а если и улучшит - то неосязаемо. Polars - еще быстрей, тот же Pandas, но и в нем нет потребности, когда и так результат - "сразу".
0xd34df00d
15.09.2022 16:19+1На статическом компилируемом языке — вы за эту минуту не объявите даже все переменные.
Не понял, зачем их объявлять?
1C таких ответов не даст вообще или даст за 20 минут.
Причём тут вообще 1C?
Вы обиделись на питонистов? В DS пришли не питонисты, а DS-ты, от которых требуют не код, а идеи, решения, выводы, графики, презентации, ML-модели. Времени у них, поверьте, чуть меньше чем у кодеров, сидящих "на техзадании+Git", потому что DS-ники работают на виду у руководства, часто это топ-менеджер.
Я никогда не был кодером на техзадании + git. Хотя просто git был, да.
В DS пришли… или, вернее, DS как ветвь создали люди, которые не умеют ни в программирование, ни в математику. До DS был ML, и там люди хотя бы понимали второе. А что там в DS?
Софтваре инжиниринг практики? Не умею, не знаю. Писать производительный код? Не умею. А толку с tensorflow на плюсах в кишках питонобиблиотек, если код по парсингу жсонов написан так, что занимает час, и разваливается от дуновения ветерка? А хз. Переписать прототип на более быстром языке и вывалить в прод? Не умею.
Математика (очень халявная в ML на фоне того, что вообще бывает)? Отбор и порождение признаков? Не умею. Всякие там информационные критерии, оценки обобщающей способности? Не знаю. F1-скор посчитать — это уже большой успех. Знать, что именно означает единичка в «F1» — это прям задача со звёздочкой, бонусные баллы, экзамен автоматом. Понимать, как работает какой-нибудь SVM, lasso там всякие, прочая классика — а нафиг это надо? Просто стекаем слои нейросеточек, пока не получим что надо.
Не, конечно, так не все. В отрасли есть люди, которые и код писать умеют, и немножко понимают математику. Но почему-то у них нет проблем и с более продвинутыми инструментами, и от питона они часто плюются.
economist75
15.09.2022 17:11Да и питонисты плюются от питона. Нет идеальных инструментов, есть любимые. И почти все умеют в несколько языков, просто не всегда в этом охотно признаются.
vkni
15.09.2022 01:18Время на компиляцию.
40 секунд на компиляцию всего Ocaml на хорошей машине (20+ ядер).
Нет той глубины интроспекции кода из библиотек.
Зато есть другая — подсказка полного типа любого выражения (Merlin).
В DataScience, где итерация не просто часты, а необходимы - код который компилится быстро утомит.
Наоборот, компиляция позволяет проверить всё значительно быстрее, чем тестовый прогон.
economist75
15.09.2022 10:41Осталось всех DS-тов пересадить с Python на стат/компиляторы и мощные десктопы - и заживем! Тут показателен пример с языком Julia: она все никак не убьет питон в DS.
И еще один парадокс - заметный рост числа и доли проектов для микроконтроллеров и realtime-проектов на MicroPython (и еще двух его клонах). Казалось бы - зачем он тут? Но люди упорно выбирают именно понравившийся инструмент вместо того, который навязывают. Значит плюсы таки-есть.
Areso
15.09.2022 12:34Значит плюсы таки-есть.
Нижайший порог входа. Сравните помигать светодиодами, двинуть серву, считать датчик на Ассемблере, С++ и МикроПитоне, и вопрос "почему" отпадёт сам собой.
iig
15.09.2022 14:10С++
DigitalWrite();
Sleep();
DigitalWrite();
Sleep();
Правильно реализованные абстракции, вынесенные в библиотеку, здорово упрощают жизнь.
Areso
15.09.2022 14:48Да, в целом неплохо, если такая библиотека есть, и интерфейс у неё достаточно человечный.
А теперь нужно добавить немного текста (за рамками латиницы) и всё, приехали.

antonblockchain
14.09.2022 16:14-1из питона тоже можно получать один НЕЗАВИСИМЫЙ exe файл.
который не зависит от настроек ровно так-же как на go и c++.
(хранит все зависимости внутри себя)
hwschool.online/ru/docs/python/exe
habr.com/ru/company/vdsina/blog/557316
это может сделать обычный аникей с любой питон программой.
в поставке может быть сразу и exe и исходник.

Barnaby
14.09.2022 16:21+8Если вы используете язык, который может выдавать бинарные файлы, задача по установке всех зависимостей с правильными версиями является одноразовой: это происходит во время сборки.
А потому выясняется, что у пользователя процессор не той архитектуры, ос не та или нужной разделяемой библиотеки не существует. Питон же идет по дефолту в линуксе, автоматический ставится начиная с вин 10, и даже нерабочий скрипт можно всегда поправить ручками не ломая голову над тем, где найти исходники и как их собрать.
Автор видимо долго учил С++ и теперь оправдывает и защищает свои инвестиции :)

Jubilus
14.09.2022 16:25+2На всякий случай лучше вообще не использовать Питон, если не разбираешься.))

VictorFilimonov
14.09.2022 17:58+2Зря. Питон удобен. Даже в том, что он интерпретируемый. Линуксоиды - у них многое завязано на питоне, он там предустановлен, под виндой тоже всё прекрасно - берёшь embedded версию, добавляешь нужные пакеты с помощью pip, потом его стираешь, добавляешь исполняемый файлик и пишешь батник. Всё - всё прекрасно работает. Если умелые руки - заставляешь innosetup установиться питон и запускаешь pip - все счастливы.

xfenix
14.09.2022 20:14+4Если вы используете язык, который может выдавать бинарные файлы, задача по установке всех зависимостей с правильными версиями является одноразовой: это происходит во время сборки. Это не происходит каждый раз при запуске программы. Более того: этот процесс можно автоматизировать, чтобы результат можно было распространять.
Нет, это не так. Ты код обновляешь от раза к разу, и точно так же собираешь его.
«В питоне» есть прекрасная альтернатива процессу компиляции — докер! И ровно все тоже самое получается, только артефакты чуть жирнее получаются, зато уже везде под это готовые системы доставки и оркестрации есть. Т.е. вполне есть себе сборка. А до этого люди и rpm не стеснялись делать.Каждый раз, когда вы запускаете программу на Python, все зависимости должны присутствовать
Как и в любой другой программе. Например, so/dll библиотеки тоже должны быть часто.
Если один из них внезапно пропал, был обновлен или требуемая версия Python недоступна, ваша программа скорее всего не запустится
Так любой софт работает.
Каждое обновление в цепочке зависимостей любых из используемых нами инструментов, сопряжено со значительными рисками сломать нашу среду сборки
У новых версий появляются несовместимости. Опять же, не питон это придумал, в любом другом языке у тебя есть зависимости от внешних библиотек, которые тоже имеют свойство меняться и ломаться время от времени.
Многие встроенные зависимости неприемлемо хрупкие
Увы, но это спекуляция пока не приведены примеры (многие примеры).
Хотите решать проблемы, возникшие из-за выбора Python?
Если я не хочу, то тогда мне придется решать проблемы, возникшие из-за выбора %LanguageName%.
Если вы используете Python сегодня, я думаю, что вы просто обязаны попробовать сделать несколько небольших проектов на языках, более подходящих для создания простых инструментов, которые работают независимо от того, как настроена ваша система
Пользовался и языки норм. Но когда тебе спустя пару лет надо вернуться к своему проекту на Go, ты внезапно обнаруживаешь, что все зависимости сломались и дико поменялись. У меня от момента первого написания до возврата к таким проектам в язык успели втащить систему модулей, например. Пойду ли я писать о том, что Go не надо использовать? Конечно нет! Потому что все абсолютно нормально.
В крайнем случае, даже Java представляет лучшую альтернативу, поскольку у вас есть возможность создавать файлы «jar», содержащие все зависимости. Не модный, но объективно куда менее хрупкий вариант.
И всё ещё обращу внимание на docker.
Я говорю это, потому что потратил слишком много недель на то, чтобы заставить плохо продуманные инструменты работать, я не увидел значительных улучшений за последние годы
Надо обсуждать конкретные примеры. Пока это звучит как «у меня что-то сломалось, не используйте python».

GBR-613
14.09.2022 20:43+6Претензия по поводу антисоциальности вообще звучит смешно. Я понимаю, что удобство пассажиров надо учитывать при выборе автобуса, но почему его надо учитывать при выборе отвёртки, гаечного ключа?? Гаечный ключ делается для удобства слесарей и механиков.
Наоборот, Питон самый социальный язык из тех, с которыми мне приходилось иметь дело: с точки зрения того, что я могу скачать чужую библиотеку и начать использовать её с минимальными усилиями.
Вот в хвалебной Java я скачиваю хвалёный jar... и тут выясняется, что он откомпилирован несовместимой версией JDK. A ещё он использует другой jar, который непонятно где брать. Ох спасибо Java за её социальность :-)
mgearr
15.09.2022 04:44Почему-то никто не упомянул poetry, а ведь, по слухам, оно помогает решать проблемы с ломающимися зависимостями
economist75
15.09.2022 10:58-1Poetry сложнее чем venv-ы, до нее тоже надо "дорасти", либо сразу родиться большим. Poetry тоже не решает проблему до конца, как не решает ее ни один из подобных инструментов. Проблема pip-зависимостей - сильно преувеличена, хотя не скрою: по-первой она обескураживает до чертиков.
Но решения есть, о них написано всюду. Причиной отказа от сабжа - "проблема" может быть лишь в крайне заангажироанных или токсичных случаях, разобраться в которых часто не удается никому.
Языки программирования - да, меняют. Но это тоже "шок", имеющий свою цену. В любом крупном офисе найдется старое, полуживое ПО, которое не трогают, потому что оно работает. Это тоже неплохая, а главное простая тактика обеспечения работоспособности систем. Вот живет у нас на Python 2 на сервере под Vista с 4Гб RAM настоящая CRM/EDM-система уже 13 лет и не дохнет. Поменяем? - Да. Завтра? - Нет. И так уже 10 лет с окончания техподдержки. Думаю такой случай не единичен.
mgearr
15.09.2022 19:54+1У меня на conda зависимости ломались. Еле починил. Причём requirements.txt не особо помогал. Вроде, и назад откатился, а всё равно не работало. Возможно, под старыми именами в репах валялись пересобранные пакеты, но не уверен
А по поводу "нетипизированные языки - зло, типизированные языки - добро" мне кажется, что это сравнимо с "город - зло, деревня - добро", "мясо - зло, овощи - добро" и так далее
По сути, какие объективные критерии существуют при выборе инструмента разработки?
стоимость разработки
сроки разработки
отсутствие критических задержек в исполнения кода
отсутствие критических ошибок в исполнении кода
стоимость сопровождения
При этом, очевидно, в разных бизнесах "критическими" будут считаться разные задержки и ошибки
Имеет ли смысл добавлять в список пункт "поддержка статической типизации"? Не думаю так, пока не увижу убедительной статистики, что типизация ускоряет и удешевляет разработку и сопровождение ПРИ ПРОЧИХ РАВНЫХ УСЛОВИЯХ. Тем более, что совершенно непонятно, как обеспечивать эти самые "прочие равные"

easimonenko
15.09.2022 10:55-1Основная цель – научиться создавать более качественные приложения и тулинг.
Слово tooling имеет перевод на русский язык: набор инструментов или просто инструменты.
vlamitin
15.09.2022 12:34позволит вам расслабиться и не задумываться о типах перемнных и многом другом
так наоборот же - читая код в языках без статической типизации, постоянно думаешь (угадывешь) о том, какой же тут тип
Areso
15.09.2022 14:50как вам поможет объявление типа где-то вверху файла на 1000 строчек?)
iig
15.09.2022 15:39Ну, можно открыть 1 файл в 2 окнах, или в 2 областях IDE. Go to definition должно работать.
0xd34df00d
15.09.2022 16:27+1IDE поможет. Я просто навожу курсор на интересующий символ и нажимаю \gh:

Если документация написана, то заодно и она покажется.


charoduke
17.09.2022 00:55Автору статьи видимо ещё надо пару лет покурить тему, у меня было десятки лет опыта с С, С++, pascal, delphi, vbs, java, php, js, matlab.... всего и не упомнишь
можно типизировать если очень надо, mypy, cython и тд, но обычно хватает просто анотаций
если сильно захотеть то можно и закомпилить например cython, numba, а если варианты не работают можно просто взять и узкое место написать на си
зависимости можно четко зафиксировать версии или использовать правила например pipenv и собирается все нормально
-
неудобный для пользователя? буквально сегодня я просто взял и запаковал приложение с помощью auto py to exe, это конвертор для внутренней надобности переводит бинарные данные в "мат" файл, показывает окно в которое можно перетащить файлы и запустить конвертацию кнопкой
в других случаях скрипты или серверные для веб, или для администраторов которые могут использовать командную строку чтобы запустить. А для всего остального есть docker, собрал образ отдал клиенту он запустил на сервере и доволен
для фронта js, ts
для окон c++ (qt, gtk), но при большом желании можно использовать их обертку на питон например приложение cherrytree
для мобильной java, c++, swift
там где большая команда и корпорация используют java или go для сервера.
для встройки c, c++, (а так же есть micropython)
для гейм дева с++, с#, или можно godot (смесь js и python), а так же есть гибридные варианты например "цивилизация" использует питон для некоторой логики
ну а питон идеален для разработки в небольших и средних компаниях, скриптах для автоматизации, для математики так как это быстро и дешевле получается с какой стороны не смотри
Используйте питон там, где его нужно использовать, в остальных случаях не используйте.
cheshircat
IMHO это общая проблема всех интерпретаторов, Python можно заменить на любой интерпретируемый язык. Что касается Python, не заметил чтобы автор упоминал virtualenv, в большинстве случаев он решает проблему.
В целом согласен с автором текста, бинарники на много удобнее в использовании. Но скорость разработки обычно заметно ниже, чем на Python. Поэтому однозначно правильный выбор вряд ли существует.
alexyr
если нужен бинарник, не берите питон. если нужна скорость разработки вот прям сейчас, (условная) кроссплатформенность, нужные вам модули уже есть в питоне — тогда можно! часть профессионального опыта — умение выбирать инструмент! иногда проще и эффективнее batch файл на 2 строки написать и не изобретать велосипед
sunlynx
В целом опыт C/C++ команд показывает что скорость разработки бинарика умелой командой вообще ничем не отличается от скорости разработки командой под интерпретаторы. При условии того, что команда уже есть.
Отличие тут только одно - скорость найма разработчиков.
ИМХО поиск оптимальности здесь на уровне следующих требований: инструментарий в любом случае должна разрабатывать имеющаяся команда погруженная в остальное окружение. Не так важно "где именно имеющаяся" - внутри компании или на рынке, главное это погруженность в текущие потребности.
Что можно сказать именно о Python - со то стороны заказчика этот язык я вижу как боль по следующей основной причине: достаточно специалистов, которые о нем говорят, мало тех, кто может отлаживать код написанный на нем быстро и эффективно. А с инструментарием потом нужно будет жить и его чинить.
Из побочных проблем языка - они точно такие же как у Golang и ruby, преимуществ с точки зрения разработки инструментов практически никаких: что у go, что у python, что у ruby. Последний давал плюсы в районе 2015-2016 годов, но сейчас ими обзавелись и другие языки. Главный минус всех интерпретаторов в плане работы с инструментарием - низкий уровень интеграции с ОС, как итог невозможность или сложность реализации части функционала.
Выводы к которым я пришел при разработке инструментов - когда команда C/C++ готова делать инструменты - это бесспорный выбор в их пользу. Когда не готова - не так важно на чем прототипировать: python, golang, ruby, десяток инструментов на PHP - в любом случае проблемы будут близкие (на php конечно их будет больше количественно :-) ).
Virviil
Как golang попал у вас в список интерпретируемых языков для прототипирования?
DeepHill
Это вот такая "глубина экспертизы" автора комментария)
bombe
В целом, я согласен с тем, о чём Вы говорите, но
разве это проблема языка? В PHP есть строгая типизация, есть PHAR*. Допустим, если Вам в руки попадётся инструмент, написанный на PHP8, с включенным strict_types, и в CI выполняются проверки статическим анализатором (к примеру, phpstan с уровнем 9), и тестами (в идеале может даже мутационное) - количественно проблем будет около нуля.
mivlad
PHAR — это всё-таки ещё довольно далеко от статической линковки. Чуть-чуть не в тему, но вспомнилось, как у меня в проекте на php валились тесты, потому что не было установлено расширение mbstring. Но какая-то из зависимостей великодушно предоставила polyfill. Но polyfill оказался с отличиями от нативного mbstring :-) Хорошо, что тесты были, без них такое можно было бы довольно долго дебажить.
evgenyk
Странное заявление, по крайней мере для python.
Moraiatw
Возможно имеется ввиду, взаимодействие с системным API.
morijndael
В таких случаях прослойку для работы с системным API просто выносят в нативный слой, и подключают через C FFI
le2
слышал от участника событий байку, как их международный проект накрылся с официальной причиной что код писали на C++, когда конкуренты писали на Java. (с российским подразделением до сих пор все в порядке) Проект просто не успевал масштабироваться, серверная архитектура не отвечала требованиям. То есть "программисты были нормальные", но они тупо не успевали. Бизнес готов был платить любые деньги, но платных инструментов под С++ не существовало.
Мораль - есть понятие мейнстрима. Язык не несет самостоятельной ценности, ценность представляют библиотеки и инструменты которые уже имеются под эту технологию (платные и бесплатные). Если ты выбрал не мейнстримовскую технологию, то, возможно, ты что-то делаешь не так.
anonymous
НЛО прилетело и опубликовало эту надпись здесь
shnicolai
Некогда над архитектурой думать в C++, там более важные проблемы есть, выбрать между unique_ptr или указателем; auto, const auto& или auto&& для переменной цикла; передавать строку через std::string_view или std::string или const std::string&; ++i или i++ и т.д., и т.п.
12rbah
К сожалению проблема не только в этом. На Java есть надежные инструменты для разработки сервера, в которых ты уверен. На c++ я писал простой веб сервер на бусте, и я там словил странный баг, при получении url запроса, в конце иногда возвращалось несколько лишних символов, ковыряться в исходниках буста и смотреть почему это происходит желания особого не было, т.к. можно утонуть в слове template, после этого, использовать эту либу желания не было. Бусту уже более 20 лет, оттуда часто тащат, что-то в стандарт, и неприятно ловить такие банальные баги. Я уверен, что есть разрабы, которые могут написать хороший сервер на плюсах, но их в разы меньше тех, кто может написать хороший сервер на java/go/ruby.
Paskin
Я участвовал в таком проекте - большая распределенная телеком-система. Хотя там вышло как раз наоборот - отцы-основатели, обеспокоенные ростом стоимости новых фич и вообще поддержки этого счастья, вовремя продали контору и мы получили свои проценты по опционам. С появлением iPhone и переходе от телеком- к Интернет-стандартам, рынок исчез и фирма закрылась.
domix32
Cо сборкой бинарника для сборки бинарника получается ровно та же проблема, только чутка проще по сложности - С++ бинарник тоже надо собирать, а с усложнением сборочных фич усложняется и состав сборочного бинарника, и его тоже в какой-то момент захочется делить. Для других языков конечно сборку сделали попроще, но в среднем проблема не сказать чтобы исчезает совсем.
iig
Интересно, что имеется в виду под прототипированием? Есть люди, пишущие код на python (с всеми этими генераторами, итераторами, конструкторами списков и динамической типизацией), а если получилось - потом переписывают на С++?
Kanut
У нас инженеры когда с желeзом играются, то у них всё на питоне. Им так проще. А когда потом уже под готовый продукт софт пишется, то берутся другие ЯП и пишут его совсем другие люди..
DistortNeo
Да, так и есть. Есть ещё промежуточный вариант: написать код на C++, оформить в виде либы и цеплять его из Python.
andrey_ssh
le2
недавно убил полтора дня в попытках запустить tensorflow и кучу прочего на ubuntu 20.04. (года полтора назад все у меня получалось успешно). В итоге оказалось что у virtualenv странный python, который имеет не все системные вызовы для работы с файлами (судя по ошибкам, причем в разных версиях python). Установив python без virtualenv эта проблема решилась, но вылезли другие.
В итоге пришлось решать задачу на docker'е.
slonoten
Для задач DS и DL conda (anaconda, miniconda) - стандарт дефакто, с кондой аналогичных проблем не помню.
DistortNeo
Ну вот только что решил попробовать вот это:
https://github.com/saic-mdal/lama
По инструкции через конду всё хорошо установилось, вот только накачало 20 гигов файлов и не смогло запуститься на видеокарте (слишком старые версии пакетов в requirements.txt).
Плюнул и решил попробовать запустить напрямую, просто устанавливая нужные пакеты по мере вываливания ошибок, либо удаляя импорты, если они не нужны для инференса. Десять минут, десяток мегабайт на отсутствующие пакеты — и всё работает в лучшем виде.
nonickname227
Если про системные вызовы, то больше похоже на проблему убунты (наличие нужных системных либ, к которым биндятся питономодули) плюс какая-то путаница с системным и виртуальным питоном. В любом случае тензорфлоу - не какая-то редкая редкость, чтоб с ней на ровном месте были проблемы, тем более в убунте...
evgs89
Приобрёл стойкую аллергию на убунту, когда понял, что они питоновские модули в репах зачем-то патчат так, что те иногда теряют всякую связь с реальностью. Лично мне это стоило пары дней.
Zhekuson
чисто из интереса - а проблема точно была в самом venv? по моему опыту проблемы возникали скорее в совершенно сломанной совместимости разных пакетов tensorflow
Paskin
Я уже давно не пытаюсь, тем более если речь идет о работе с GPU. Пять-десять минут на написание соответствующего compose - и все работает, вместо часов "развлечений" с CUDA и прочими зависимостями с неочевидным результатом.
nmrulin
Ну когда Паскаль/Дельфи был популярен, разработка на нём была ещё быстрее за счёт возможности "накидать формочек" , но это его не спасло.
rg_software
Думаю, не более, чем следствие безумной политики Borland / Inprise / Embarcadero, да и общего раздрая в компании. Печальная история.
Moraiatw
Кстати, Делфи, в отличии от - полностью компилируемый язык без зависимостей.
Siemargl
Да конечно, там ад несовместимых между версиями D компонентов и их лицензий.
Moraiatw
Причем здесь компоненты с лицензиями? Речь идет от программной совместимости скомпилированных файлов.
Siemargl
Когда другой человек, ну или ты сам пересобираешь проект на новом месте.
Об этом же речь в статье.
HemulGM
Это касается только компонентов, которые ты регистрируешь в среде (устанавливаешь) для работы в дизайнтайме. Ты можешь и не устанавливать их в среду, подключая модули к проекту сам и создавая компоненты кодом. И тогда ни кому не нужно будет устанавливать эти компоненты себе в среду для сборки.
А для решения этой проблемы есть штатный менеджер пакетов - GetIt с системой зависимостей. При открытии такого проекта, среда предложит автоматически установить пакет в среду.
Siemargl
А может все же почитать статью? В Питоне тоже есть штатный менеджер пакетов.
И да, "*.bpl is missing" не знакомо что ли?
HemulGM
Речь сейчас не о питоне или статье. Я говорю именно о Делфи. Говорю о вашей проблеме, которая не актуальна.
И нет, никогда (за 10 лет) я не встречал такой ошибки.
Повторяю, если не устанавливать пакет в среду, то ни каких зависимостей при сборке не будет. Будёт всё так же как с питоном. Только поймите, что речь в посте идёт не о СБОРКЕ, а о выполнении. Питон всегда "собирается" и выполняется как в первый раз. И в этом суть поста. Компилируемые же языки собираются один раз и дальше, развалиться просто напросто не могут, если нет отдельных зависимостей от дин. библиотек.
iig
Если не использовать сторонних компонентов. И запускать там где собираешь ;)
Moraiatw
Нет.
Alexey2005
С такими безумными ценами на лицензию популярным он мог стать разве только среди пиратов.
HemulGM
Разработка на нем и сейчас куда быстрее, чем на чем-либо. Многие просто не знают, считая что "Делфи - всё". Я за 3 дня создал кроссплатформенное приложение для просмотра 3D панорам для компании Leroy Merlin.
s207883
Делфи - все не потому, что на нем нельзя что-то быстро запрограммировать, а потому что этим мало кто занимается.
nmrulin
Только проблема, что Fmx очень глючный , а хорошо разбираются и могут что-то подсказать на форуме Крапоткин и ещё пара человек. Раньше подсказывал и сам создатель fmx но потом прочухал, что можно создать платное решение и подсказывать уже не бесплатно. Кроме того в fmx по ряду причин скорость разработки ниже чем в vcl. Что-то не инициализировал и всё привет в разных ОС работает по разному . Правда ради справедливости в том же xamarin для сравнения тоже всё не идеально.
HemulGM
Мой опыт работы с FMX прошел места, которые могут казаться глючными. После того, как я разобрался как FMX работает, эти глюки уже не кажутся глюками, а вполне ожидаемая реакция на не верные действия. Зачастую, потому что они не очевидны. Сейчас я почти не испытываю проблем с FMX и пишу софт куда быстрее, чем на VCL. Нет какого-то особого контрола - через стиль сделал себе особый контрол. Не нужно искать его по сети или делать самому через ручную отрисовку. Вся визуальная составляющая моих проектов работает на штатных контролах. При этом сами контролы могут быть совершенно уникальными.
По fmx я часто подсказываю, но не на форму, а в тг чате (там около 400 участников). Там же, обитает и один из создателей FMX, он же создатель FGX). И он не стесняется помогать по FMX, при чем он всё ещё работает и над FMX.
DistortNeo
До Python никто не писал настолько масштабных проектов, и эти проблемы попросту не вылезали.
Главная проблема Python — отвратительная ситуация с обратной совместимостью. Причём как в самом языке, так и в библиотеках. Поэтому программисты зачастую не заморачиваются и фиксируют версии всех зависимостей так, на всякий случай.
Да, virtualenv и conda решают проблему с зависимостями, но приводят к другим проблемам:
Дичайшее раздувание размера проекта. В случае ML-проектов это порядка 3-5 гигов на каждый проект.
Сложность с одновременным использованием нескольких проектов. Нельзя обойтись по-простому парой импортов.
Старые зависимости могут просто пропасть.
Невозможность запустить проект из-за несовместимости старых библиотек с операционной системой (тут поможет docker) или железом (тут docker уже не поможет).
Например, старая версия pytorch тянет за собой старую версию CUDA, а старая CUDA не совместима с новой видеокартой. При этом с более новыми версиями библиотек проект не запускается, причём проблема не в основной части проекта (инференс), а в какой-то там вспомогательной обвязке, которую можно было безжалостно вырезать.
odiemius
Вот только что проверил проект, который упомянули здесь в комментах:
Если что, это было под Fedora 36:
И команды я запускал, прямо copy-paste из «Environment setup» из github.com/saic-mdal/lama
Что я делаю не так?
Довольно странно, но с питоном у меня больше было отрицательного опыта работы, так как постоянно что-то отваливается, какие-то версии несовместимы, а по ошибкам фиг так просто докопаешься что случилось и где чинить. И даже хвалёный virtualenv не спасает, как показывает практика. Может потому, что я подхожу к питону с практической позиции, когда цель — программа, которая работает, а не написание или исправление кода. Я пишу в основном на perl, там у меня куда меньше было проблем с совместимостями пакетов и версий, даже без докеров и kvm, под старым добрым CentOS 6 и потом 7. Про С я вообще молчу, там вообще всё хорошо, но в статье речь именно об интерпретируемом языке.
brownfox
virtualenv сам по себе вообще не спасает от разброда с версиями модулей. Есть более высокоуровневые средства вроде poetry, существенно облегчающие задачу дистрибуции питоновского кода.
Справедливости ради, при раздаче бинарников на C++, собранных с динамическими библиотеками, можно налететь на те же самые проблемы совместимости, что и с интерпретаторами. Характерный пример - версии boost-а. Просить заказчика доставить в его дебиан boost 1.78, так как в 1.61 из репы нет модуля json - не самая хорошая практика.
Paskin
В docker-версии вроде как CUDA находится внутри образа, а от хоста используется только драйвер видеокарты.
DistortNeo
Это нисколько не поможет от ошибок вида:
Старые версии PyTorch и CUDA не могут работать с новой видеокартой и драйвером.
Paskin
У меня рабочий комп с 3080 и я с таким пока не сталкивался. Но опять же - при правильном использовании Docker (когда все данные и код примонтированы как volume), поменять версию Pytorch и CUDA можно за те же пару минут, и держать столько вариантов, на сколько хватит диска.
Jian
Идут той же дорогой, что и Delphi, который начал умирать, когда убили обратную совместимость.
HemulGM
Ничего не убрали. Убрали деприкейтед, который нужно было убрать. Если открыть проекты после перехода с Ansi на Wide, то всё открывается нормально. Вся совместимость имеется.
0xd34df00d
Скорость разработки непонятно как измерять. Выдать что-то в продакшн, что худо-бедно работает, на питоне действительно быстрее. Выдать что-то, работающее надёжно, и что легко поддерживать, лично мне проще на каком-нибудь хаскеле.
Но лично мне вообще питон сложный, после нескольких десятков строк я начинаю путаться.
vkni
Мы это неоднократно обсуждали — "скорость разработки чего?" :-)
0xd34df00d
Скорость разработки мышки при перетаскивании тикетов в джире, конечно.
Didimus
Во. Я думал это только у меня. Он абсолютно нечитаемый после того же Паскаля, например
mgearr
Вот ведь как мозги-то по-разному у всех устроены. Для меня он читаемый как раз лучше паскаля, хотя до питона паскаль считал эталоном читабельности
vkni
Разница между интерпретируемыми и компилируемыми языками несколько надумана:
По-науке, семантика языка задаётся "каноническим интерпретатором".
Интерпретаторы есть для C++ и Ocaml'а.
Компиляторы есть для, скажем lua или Питона.
Areso
virtualenv + замарозка зависимостей (pip freeze) + Docker.
в сумме дадут желаемый результат.
DistortNeo
Ага. А через год будет так:
Areso
с этой магией не работал, и даже не интересовался.
Последние пару лет провёл далеко от домашнего компьютера с CUDA-видеокартой.
Ну и тут большой вопрос WTF к авторам PyTorch, которые поддерживают железо как попало.
DistortNeo
Тут дело не в PyTorch, а в том, что новые видеокарты не поддерживаются старыми версиями CUDA. Старую версию PyTorch вполне можно скомпилировать с поддержкой новой версии CUDA, и всё будет прекрасно работать.
Suor
Со скомпилированной программой это тоже случится, так что это выходит за пределы сравнения.