

Привет! Продолжаю рассказ про интеграционную платформу на базе Apache Kafka и про то, как мы постарались гармонично вписать ее в непростую ИТ инфраструктуру группы НЛМК.
Напомню, что в первой части статьи были описаны соглашения об именовании топиков, подход к реализации ролевой модели и соглашение по базовой схеме данных. Здесь расскажу, как сделали универсальное охлаждение для всех данных из Kafka в корпоративное хранилище на базе Hadoop, про сервис доставки сообщений в ИС и про разработанные сервисы, доступные на нашем Self-Serves портале.
Сервис по доставке сообщений из Kafka в базы данных
В НЛМК, как наверное и во многих компаниях, есть системы, которые не умеют читать из Kafka напрямую. Для них мы и сделали на NiFi сервис по доставке сообщений напрямую в базу данных.
Мы условились об одинаковом имени таблиц и обязательных колонках в них, чтобы сервис можно было переиспользовать.
Соглашение по колонкам:
Наименование |
Тип (PostgreSQL) |
Описание |
meta_timestamp |
timestamp without time zone |
время отправки сообщения в Kafka (заполняется клиентом при отправке) |
meta_offset |
bigint |
внутреннее смещение в партиции |
meta_partition |
int |
номер партиции |
meta_key_schema_id |
int |
номер версии схемы Key |
meta_value_schema_id |
int |
номер версии схемы Value |
topic |
text |
имя топика |
key |
text |
ключ сообщения (если указан) |
message |
text, json, jsonb |
Тело сообщения в JSON |
Данные в Kafka изначально находятся в Avro-формате. Несмотря на то, что мы передаем тело сообщения в JSON-формате и, кажется, теряем преимущество Avro - типизацию, использование Schema Registry и ее гарантий эволюции схем позволяет быть уверенным, что тип поля не изменится.
Передача и сохранение метаданных сообщений Kafka в БД очень важно, т.к. позволяет проверить сообщения на дубли или пропуски данных.
Например, таким запросом можно проверить, что у нас не было пропусков данных за последние сутки (количество уникальных offset в рамках партици и топика равно разности максимального и минимального offset, минус один)
with stat as (
select topic, meta_partition, min(meta_offset) as _min, max(meta_offset) as _max, count(distinct(meta_offset)) as n_msg
from etl.kafka_data
where created_at > now()- '1 day'::interval
group by opic, meta_partition
)
select *,n_msg-(_max - _min)-1 as delta from stat where n_msg-(_max - _min) <> 1;Сам шаблон NiFi представляет из себя два консьюмера: к продуктивной и тестовой Kafka, и цепочки процессоров до продуктивной БД и тестовой, соответственно. В связи с различными случаями, когда надо было передать тестовый поток на продуктивную БД или наоборот (например, есть только продуктивная БД), предусмотрена возможность задать правило со списком топиков для передачи в другую среду.
В новых версиях NiFi появилась отличная концепция - Parameter Contexts и все настройки мы выполняем через них:
задаем список топиков для передачи;
указываем параметры подключения к базе;
определяем правила передачи данных между средами.
Мы планируем предоставить управления Parameter Contexts владельцам Информационных Систем через наш Портал Самообслуживания НЛМК (про него скоро напишем), чтобы уйти от заявок в Self-Service.
Инструкция Администратора по созданию новой группы выглядит так:
1. переименовать
2. создать parameters такой же, как имя группы
3. добавить в PARAMETER INHERITANCE:
_postgresql_db | _oracle_db - тип целевой базы
kafka-clusters
4. Заполнить переменные в Parameters:
000_0_group_id: имя группы (service-prod.nifi-000-0.sre.<group_name>)000_0_topic_name_format: names000_0_topic_names: список топиков000_1_group_id: имя группы (service-prod.nifi-000-0.sre.<group_name>)000_1_topic_names: список топиковprod_database_connection_url: jdbc:oracle:thin:@<hostname>:1521/<service_name>test_database_connection_url: jdbc:postgresql://<hostanme>:5432/<db>?ApplicationName=nifi-000-0-<group_name>test_to_prod_topics_re: ^$ - маска для передачи топиков с теста на продprod_to_test_topics_re: ^$ - маска для передачи топиков с прода на тест
И сама группа в NIFI:

Так же, в качестве получателей есть системы с REST интерфейсом (например 1С). Мы аналогичным образом доставляем данные из Kafka в эти системы, за исключением: все атрибуты, кроме сообщения(message), мы добавляем в Headers POST запроса, а само сообщение кладем в body.
Сырой слой в Hadoop или «первый блин комом»
Прорабатывая построение Stage слоя в Hadoop мы хотели:
предоставить возможность работать с данными из Hive;
сохранять метаданные из Kafka для сообщений;
поддержать концепцию эволюции схем.
Мы попробовали сначала сложить сообщения из Kafka в Avro формате в Hbase, а метаданные в таблицу в Impala. Создав представление в Hive над таблицей в Hbase и соединив ее с метаданными из таблицы в Impala, мы получали бы представление, удовлетворяющее исходным требованиям. Сначала показалось, что все работает...
Для истории, исходный flow в NiFi и описание таблиц
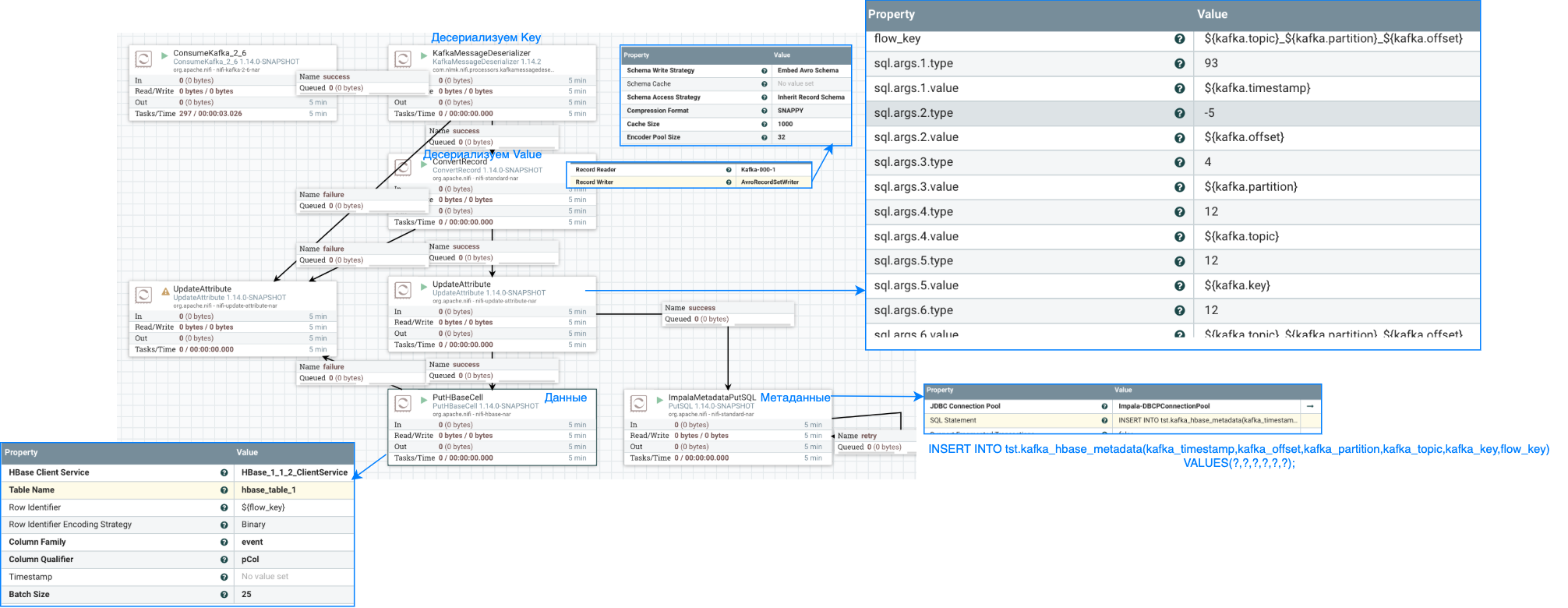
Таблица в Hbase с данными(kafka.value в Avro), и ключом:
${kafka.topic}_${kafka.partition}_${kafka.offset}.-
Внешняя таблица в Hive над ней
CREATE EXTERNAL TABLE tst.hbase_table_1 ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe' STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( "hbase.columns.mapping" = ":key,event:pCol", "event.pCol.serialization.type" = "avro", "event.pCol.avro.schema.url" = "https://schema-registry-000-1.dp.nlmk.com/subjects/000-1.dwh.db.avro-evolution-hdfs.0-value/versions/latest/schema" ) TBLPROPERTIES ( "hbase.table.name" = "hbase_table_1", "hbase.mapred.output.outputtable" = "hbase_table_1", "hbase.struct.autogenerate" = "true" ); -
Таблица в Impala, где для этого же ключа лежат метаданные и kafka.key.
CREATE TABLE tst.kafka_hbase_metadata ( kafka_timestamp TIMESTAMP, kafka_offset BIGINT, kafka_partition INT, kafka_topic STRING, kafka_key STRING, flow_key STRING ) STORED AS PARQUET;
Запрос на соединение выглядел так:
select * from tst.kafka_hbase_metadata left join tst.hbase_table_2 ON (flow_key = key);На маленьком объеме данных решение казалось рабочим, но с ростом количества данных мы заметили деградацию в производительности. Проблема была с неработающим Predicate Pushdown для HBase таблиц, из HBase забирались все ключи, а не только те, что были в левой таблице.
Нам пришлось от этой схемы отказаться. Мы пришли к следующему подходу:
добавили в схему сообщений структуру
metatadataпод метаданные Kafka и заполняем ее на NiFi после чтения (описано в первой части, Требования к AVRO схеме);решение с HBase оставили как экспериментальное, из Hive обращения к hbase не используются;
хранилище сделано на HDFS, сохраняем в Avro, из Hive создаем внешние таблицы.
HDFS, Avro и Hive
Приземление данных из Kafka в HDFS также сделано на NiFi. Обогатив исходное сообщение метаданными из Kafka (структура metatadata), NiFi склеивает сообщения по атрибуту в пачки:
${kafka.topic}_${kafka.timestamp:format("yyyy-MM-dd")}_${kafka.schema_id.value}и сохраняет в HDFS по пути:
/dwh/${env}/stage/kafka-${cluster_name}/${kafka.topic}/dwh_dt=${now():format("yyyy-MM-dd", "GMT+3")}/Данные партицированы по дате записи, чтобы позже обрабатывать именно пришедшую дельту. Формат данных: Avro со схемой.
Внешние таблицы мы создаем задачей в Airflow. По умолчанию создается таблица в latest версией схемы и каждую ночь мы обновляем схему из Schema Registry.
Пример Airflow DAG
hive_scheme = f"{env}_stage"
topic_list = [...]
for topic in topic_list:
@task(task_id=topic)
def hive_hook_test(topic_name):
nlmk_topic = NLMKKafkaTopic(topic_name)
table_name = "kafka_{}".format(topic_name.replace('.','_').replace('-','_'))
hdfs_path = f"/dwh/{env}/stage/kafka-{nlmk_topic.get_naming_attr('cluster_name')}/{topic_name}/"
topic_scheme = nlmk_topic.get_value_scheme(include_meta=True)
table_ddl = f"""CREATE EXTERNAL TABLE IF NOT EXISTS
{table_name}
PARTITIONED BY (dwh_dt string)
STORED AS AVRO
LOCATION '{hdfs_path}'
TBLPROPERTIES (
'avro.schema.literal'='{topic_scheme}'
)
"""
alter_ddl = f"""ALTER TABLE {table_name} SET TBLPROPERTIES (
'avro.schema.literal'='{topic_scheme}'
)
"""
hh = NLMKHiveServer2Hook(hiveserver2_conn_id=conn_id)
with closing(hh.get_conn(hive_scheme)) as conn, closing(conn.cursor()) as cur:
cur.execute(table_ddl)
cur.execute(alter_ddl)
cur.execute(f'MSCK REPAIR TABLE {table_name} SYNC PARTITIONS')
cur.execute(f'MSCK REPAIR TABLE {table_name}')HBase
В HBase на каждый кластер Kafka мы создаем по две таблицы: одна - для всех "публичных" топиков, и вторая для топиков типа cdc (compaction) (HBase повторяет логику работы compaction в Kafka и оставляет только последнее значение по ключу). Эти таблицы различаются только ключом (Row Identifier).
В первом случае используется выражение: ${kafka.topic}_${kafka.timestamp}_${kafka.partition}_${kafka.offset}
А во втором, просто ключ сообщения в Kafka: ${kafka.topic}_${kafka.key}.
Сами таблицы имеют две CF (column family): под метаданные и под Avro (schema less) объект. Таблицы предварительно создаются в HBase:
create 'kafka_stage_000-0', {NAME => 'metadata', COMPRESSION => 'SNAPPY', VERSIONS => 1}, {NAME => 'data', IS_MOB => true, COMPRESSION => 'SNAPPY', VERSIONS => 1};
create 'kafka_cdc_000-0', {NAME => 'metadata', COMPRESSION => 'SNAPPY', VERSIONS => 3}, {NAME => 'data', IS_MOB => true, COMPRESSION => 'SNAPPY', VERSIONS => 3};Обратите внимание, что в отличие от Hive, где Avro объект сохраняется со схемой, в HBase хранится Avro без схемы.
Пример, как читать такие таблицы из pyspark
from pyspark import SparkConf, SparkContext
import json
sc.addPyFile("hdfs://dwh-prod/user/makarov_ia/sr_wrapper2.py")
from sr_wrapper2 import ORGNAMEKafkaTopic
topic_name = '000-0.l3-c.db.melt-steel-operation.1'
# Обертка для получения схемы из SR
org_name_topic = ORGNAMEKafkaTopic(topic_name)
value_avro_schema = org_name_topic.get_value_scheme(include_meta=False,clean_docs=True)
catalog = json.dumps(
{
"table":{"namespace":"default", "name":"kafka_stage_000-0"},
"rowkey":"key",
"columns":{
"key": {"cf": "rowkey", "col": "key", "type": "string"},
"kafkaKey": {"cf": "metadata", "col": "kafka_key", "type": "string"},
"kafkaTopic": {"cf": "metadata", "col": "kafka_topic", "type": "string"},
"kafkaSIDValue": {"cf": "metadata", "col": "kafka_schema_id_value", "type": "string"},
"value": {"cf": "data", "col": "msg", "avro": "avroSchema"}
}
})
df = spark.read
.options(avroSchema=value_avro_schema)
.options(catalog=catalog)
.format("org.apache.hadoop.hbase.spark")
.option("hbase.spark.use.hbasecontext", False)
.load()
df.createOrReplaceTempView("tmp_1")
results = spark.sql("SELECT count(*) FROM tmp_1 WHERE key like '000-0.l3-c.db.melt-steel-operation.1%' LIMIT 1")
#results.explain(extended=True)
results.show(10, False)
#print(value_avro_schema)
spark.catalog.dropTempView("tmp_1")
Self-Service Портал
Сервис проверки схем
Как выше говорилось, наша цель - полностью автоматизировать работу пользователей с интеграционной платформой НЛМК и Kafka. Также нам важно, сделать как можно больше проверок пользовательских запросов в автоматическом режиме.
Мы сделали сервис для Портала, который умеет:
генерировать базовую схему для топика;
проверять схему на соответствие стандартам;
проверять схему на совместимость;
проверять на типовые ошибки с Avro (тип default значения должен быть таким же, как и первый тип в перечислении type, генерируемость Java классов и схем без ошибок) и качество схем (отсутствие документации у полей, орфографию).
Пример работы с сервисом

Также этот сервис предоставляет REST API для возможности автоматизаций на стороне отправителя, и мы сделали docker образ для возможности встраивания в CI или локальных проверок.
Мы планируем уйти от регистрации схем через Kafka REST. Регистрация и эволюция схем будет возможна только через наш сервис.
Так же мы движемся в сторону Self Service и уже готово:
регистрация namespace за информационной системой;
выпуск сертификата для ИС на чтение и запись;
запросы доступа на чтение и запись для сертификата;
управление consumer group: добавлять новые (мы ограничиваем количество consumer group на один сертификат), управлять смещением.
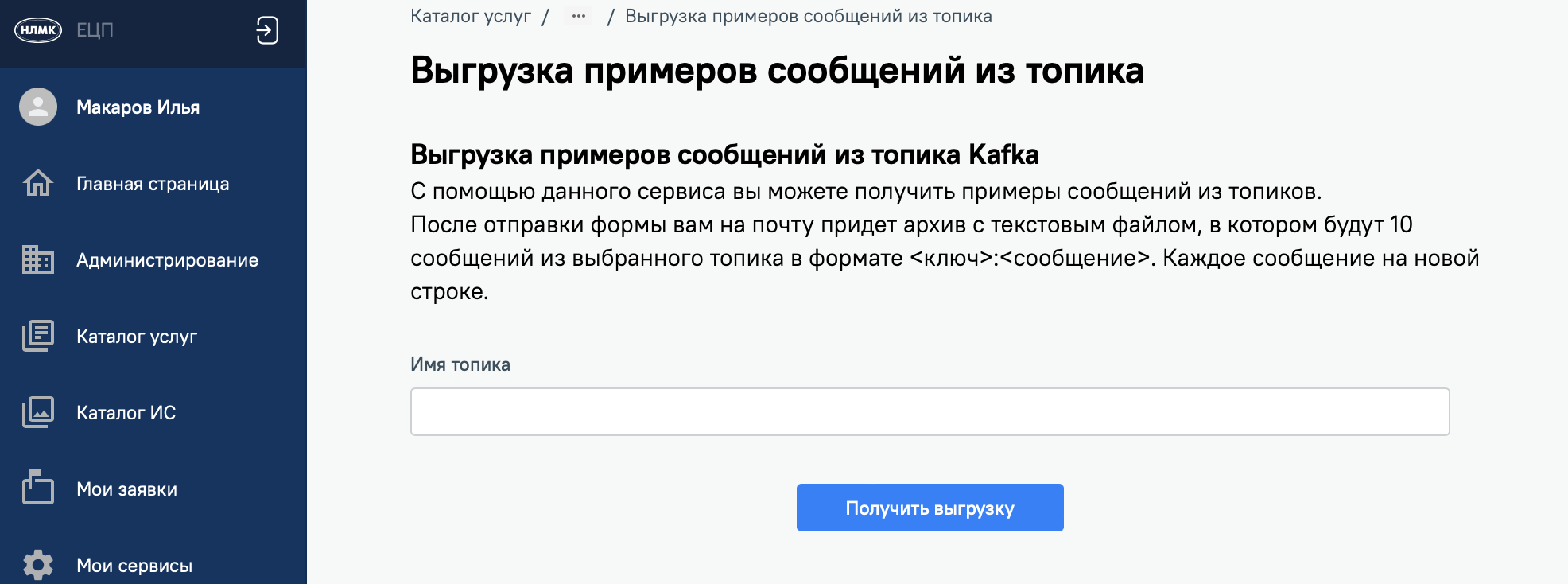
Сервис по выгрузке семплов
В компании много систем, которые не умеют напрямую работать с Kafka, например Oracle или 1С. Для таких систем мы централизованно предоставляем сервис по доставке сообщений: кладем напрямую в БД или через REST. И одним из частых запросов было "выгрузите нам примеры сообщений". Для решения этой задачи мы на нашем портале сделали сервис по выгрузке семплов, он позволяет для заданных по маске топиков делать выгрузки семплов сообщений. Запросить можно топики с типом MessageType "Публичный".
Планы
Гибкое управление настройками топиков на основании статистики (резкий рост количества получаемых сообщений - выставить ограничение на объем партиции с учетом текущей утилизации места кластера). Текущий скрипт обладает только базовыми функциями: kafka-mgm;
Cruise Control. С ростом кластера это становится все более актуальным;
Полностью автоматический перевыпуск сертификатов с помощью Vault и доставкой в приложения.
А выводы
Качественное внедрение и адаптация под компанию любой системы - длительный процесс: вы автоматизируете все что возможно, пишете документацию, примеры кода, нарабатываете экспертизу, постоянно дорабатывая методологию и подходы. Понимание, как это сделано в других компаниях, позволяет двигаться быстрее и делать более удобные информационные системы. Я горжусь тем, как мы сделали и что у нас получилось. Ну а совершенству нет предела!