
Всем привет! Меня зовут Александр Токарев и на момент подготовки этого материала я возглавлял RnD в Сбертехе.
В статье я расскажу о частном облаке: какие существуют опенсорсные и не опенсорсные платформы биллинга для частных облаков, как выглядит референсная архитектура биллинга, что можно взять из опенсорса, чтобы построить свой биллинг и как все компоненты собрать в продукт.

Что такое lowcode?
Для меня lowcode – это не визуальная разработка, а автоматизация, построенная на базе конфигураций без использования языков разработки и на опенсорсных инструментах.
Прежде чем мы углубимся в технику, давайте вспомним, что такое FinOps.
FinOps, как и DevOps, это методология, которая декларирует, что девопсы и финансы должны работать вместе. Причина — прозрачность, которая позволяет добиться эффективного, прибыльного процесса разработки программного обеспечения без снижения скорости доставки фич.
С точки зрения IT, FinOps позволяет получать информацию от биллинговых систем в режиме практически реального времени, при этом дополненную бизнесовыми метриками на основе разделяемого облачного словаря.
Это возвращает доверие к IT, которое было утрачено, когда облака только появились и требовали колоссальных трат. FinOps же позволяет добиться баланса между скоростью изменений, доступностью сервисов и затрат на облака.
На докладе на конференции Saint Highload мы представили референсную архитектуру FinOps, которая позволяла осуществлять progressive delivery на основе финансовых метрик и работать с ценовыми дэшбордами.
Ключевым компонентом был Kubecost, который извлекал информацию из публичного облака. Но боль в том, что в частном облаке нет информации по ценам ни по PAAS продуктам, ни по SAAS:

Так происходит, потому что большинство опенсорсных продуктов по биллингу IAAS мертвы. А те, что не мертвы, уже deprecated.
Правда есть такие крутые продукты, как Fleio. Это реально крутой биллинг для Openstack, но все эти продукты – для облачных провайдеров, то есть на них можно строить FinOps, но в результате вы получите огромный кусок функционала, которым никогда не воспользуетесь.
Я решил погуглить и обнаружил, что для частного облака FinOps, продукты есть только на пятой ссылке Гугла, а для гибридного облака — на второй. А функционал таких продуктов, как CloudBolt и Virtana способен лишь собрать информацию по метрикам из Openstack или из VmWare и наложить на них квоты. А самый крутой инструмент мы можем обнаружить лишь на пятой странице – это Exivity:

Он позволяет подключаться к огромному количеству облачных и не облачных продуктов и загружать информацию о их потреблении в биллинг. И, самое главное, исходя из информации с биллинговых событий влиять на инфраструктуру – запускать ансиблы, тераформы и так далее. Полученную информацию он может отгрузить и в бухгалтерию.
Благодаря этому вы можете довольно быстро узнать сколько терабайт трафика в день потребляют ваши виртуалки, по какой цене, и настроить, например, стоимость бэкапа.
Exivity позволяет получать информацию для FinOps с облаков, средств виртуализации, с дисковых полок и бэкапных тулов. При этом они могут быть как опенсорсные, так и нет. Если же каких-то функций не хватит, вы всегда можете написать кастомный экстрактор и использовать его в биллинге.
Как для достойной финансовой тулы, есть возможность настроить организационные иерархии, задать цены на ваши внутренние финансовые ресурсы и реализовывать традиционные методологии в управлении бюджетом chargeback и shоwback. И, конечно же, интегрироваться с CMDB. В отчетнике Exivity есть возможность дриллдауниться от уровня организации до конкретной виртуальной машины. И, как принято, в таких энтерпрайзных инструментах, есть нормальная аутентификация и авторизация. Но команда разработки, судя по Linkedin, это 12 человек, и у них даже не хватает денег, чтобы оказаться на первой странице выдачи Гугла. А еще они не опенсорсные, поэтому, наверное, это не вариант для компаний вроде «Сбера».
Почему же так сложно?
Представьте, что у вас есть множество IAAS продуктов и PAAS продуктов. И для каждого из них вам необходимо отгружать информацию: по продукту и пользователям. Скорее всего, не напрямую в биллинг, а через какой-нибудь API Gateway. А ещё для каждого продукта вам нужно собирать события по биллингу, отгружать их в какую-то промежуточную базу данных и агрегировать их оттуда. Потому что, если вы начнете как есть записывать их напрямую в биллинг, то он может прилечь под нагрузкой:

Что такое биллинг?
Биллинг – это управление продуктовым каталогом, управление моделями ценообразования, политикой приостановки сервисов, балансами и так далее, но самое главное, что свойства биллинга сконцентрированы на расширяемости и на доказанной, а не мифической производительности. Поэтому у нас изначально не стоял вопрос написать свой биллинг с нуля.
Вместо этого мы построили матрицу выбора опенсорсных инструментов для биллинга. Мы её построили в разрезе языка разработки, лицензии, наличия коммьюнити, богатства фич, адекватности API и документации, и, конечно же, крупных пользователей:

Мы обнаружили, что во всем Интернете жив только один биллинг — это KillBill. А то, что принято называть биллингом – это, на самом деле, инвойсинг, то есть возможность отправки ваших платежных сообщений в какие-то внешние системы.
Что такое KillBill
Что из себя представляет KillBill:

Это Java-приложение, в котором есть базовые модули:
управление счетами;
продуктовый каталог;
учет;
инвойсинг;
оплата.
И, самое главное, каждый этот сервис предусматривает API для расширения.
Компоненты взаимодействуют между собой через внутреннюю очередь сообщений. Это позволяет нам деплоить нужное количество Stateless, то есть не зависящих от состояния, экземпляров сервера KillBill в кластерах Kubernetes. При этом KillBill для работы нужна база данных. Мы используем Postgres:

В KillBill есть очень важный функционал - это аналитический плагин, позволяющий поддерживать схему для быстрого получения отчетов, без которой все ваши запросы к биллингу будут очень медленными.
Если вы хотите установить тестовый биллинг на поиграться, то одного ядра на реплику и четырех ядер на базу хватит, чтобы получить работоспособную систему.
Что умеет KillBill?
KillBill умеет работать с плоскими и иерархическими счетами. Зачем нужны иерархические счета? Представьте, у вас огромная организация с департаментом информационных технологий, в котором есть сложная структура отделов. Всё это вы можете уложить в модели иерархических счетов и максимально точно аллоцировать затраты.
Есть возможность настраивать различные сложные модели ценообразования, версионирование планов и возможность запустить цену на ваш внутренний продукт с определенного момента времени.
Есть то, что не очень нужно для частного облака – prepaid биллинг, биллинг по подписке. Само собой в наличии то, что критично важно для частного облака - pay-as-you-go биллинг.
Казалось бы, зачем в энтерпрайзе биллинг по подписке? Но до недавних событий очень много компаний использовало вендорские продукты, в которых всё работало по подписке и это был очень нужный функционал.
Есть возможность выставлять инвойсы, работать с оплатами и блокировать счета, уведомлять о внутренних событиях, происходящих в биллинге.
Конечно, это важно помнить, каждый сервис может быть расширен через API. Мы используем у себя примерно половину функционала KillBill.
Как я уже говорил, у него очень адекватная документация по рекурентному биллингу, биллингу по подписке, usage биллинг:

Можно настраивать уведомления. Например, о том, что деньги на счету скоро закончатся, что счет надо заблокировать, что пользователя нужно полностью удалить в системе. Делается это в понятном XML и предусмотрено огромное количество случаев, которые биллинг может сделать самостоятельно. Огромный объем работы уже проделали за вас:


Что надо сделать, чтобы биллинг заработал у вас в компании?
Создать продуктовый каталог. Это то, что делается вместе с вашими финансами.
Далее необходимо обеспечить доставку метрик до вашего биллинга и предупреждать о превышении бюджета.
Наверное, блокировки в частном облаке не очень нужны.
Погрузимся в детали

Рассмотрим компоненты продуктового каталога:
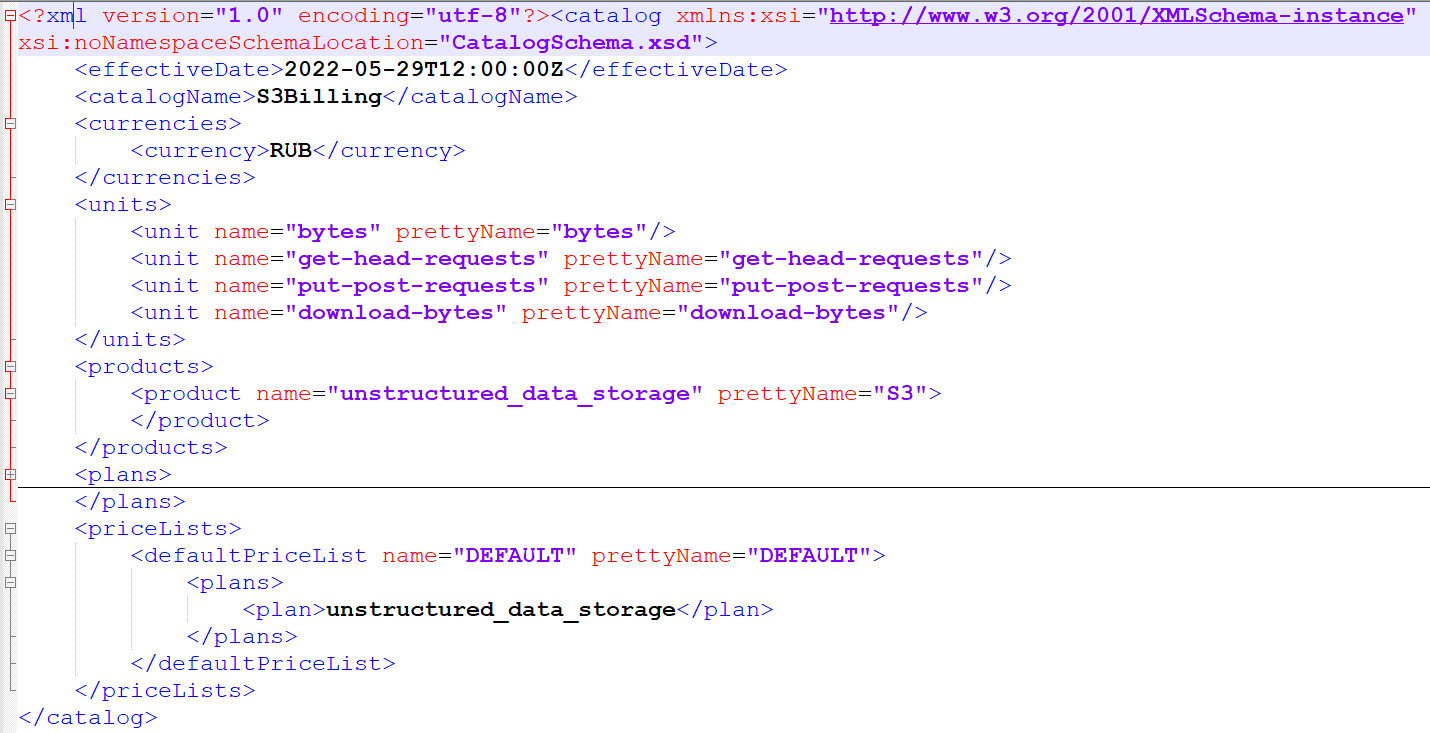
Начнем с продуктового каталога и набора валют, в которых вы будете чаржить ваших внутренних пользователей.
Далее определяем список величин, за которые будем брать с пользователя деньги. В нашем примере мы будем брать деньги за объем трафика, за GET/HEAD, PUT/POST запросы и количество хранимой информации. Одновременно с этим определим ступени ценообразования и режим работы с ними:

Это так называемый набор тиров - tier. Фактически вы можете обозначить цену для каждого промежутка отдельно. Есть режим all_tier, когда вы чаржите вашего клиента за каждую ступеньку цены. Есть режим top_tier — когда вы чаржите клиента при достижении максимальной величины.
Прописываем денежную составляющую:

Например, мы обозначаем, что с нуля до 1 гигабайта не будем брать деньги с пользователя за исходящий трафик. С 1 до 5 гигабайт будем чаржить пользователя за 1 рубль, и с 5 до бесконечного числа будем брать 0,7 рублей.
Цены, понятно дело, я указал условные.
При попытке написать такой биллинг самостоятельно, вы один компонент по настройке Tier-планов будете писать месяца два.
Какие нужны API, чтобы заработал биллинг?
Нам нужны следующие методы API:
Создание биллингового счета
Установка продукта
Отправка метрик по потреблению
Удаление продукта
Давайте посмотрим детально, как заводить пользователя. Это очень просто. Нужен простейший REST API, в котором указываем валюту оплаты и пользователя:

Как зарегистрировать продукт? Тоже просто:

Мы даем ссылку на заведенный на предыдущем шаге аккаунт, но указываем тот самый тарифный план, за который будем чаржить нашего пользователя. Потому что подписка уже не в вакууме, а привязывает конкретный продукт к конкретному пользователю и служит для отправки событий.
Давайте отправим информацию по потреблению:

Отправляем массив массивов с помощью заведенной на предыдущем шаге подписки. В этом массиве массивов вы сможете отправлять метрики по определённым датам. Например, мы экономим обращение к нашему биллингу и за один момент времени по одному продукту отправляем все измерения. Для объектного хранилища это объем хранимых байт, запросы get/head, запросы put/post и затраченный трафик.
Так у нас появляется первый lowcode-компонент нашей системы. Это KillBill с XML-планами:

Что приходит в голову любому девопсу, когда он вспоминает метрики? Конечно, timeseries база данных — VictoriaMetrics:

Давайте разберём, что такое метрика. Метрики – это timeseries данные, где значение метрики – это величина потребления. Но чтобы биллинг работал, метрику необходимо разметить лейблами. Какие нужны лейблы? Например, RN — уникальный идентификатор облачного ресурса, который использует каждый облачный провайдер. Это то, на что будут аллоцироваться деньги.

Например, у Амазона в RN есть регионы, зона доступности, тип сервиса, его id. У одних провайдеров в RN есть номер проекта, а у других — абсолютно произвольное число. Что будет в RN у вас, решаете вы сами. Далее мы указываем тип метрики — например, Counter or Gauge. Counter это метрика, которая постоянно растёт. Например, количество вызовов. А gauge это метрика, которая учитывает мгновенное потребление, как в случае объектного хранилища текущий объем места.
Обязательно в метке мы указываем единицу измерения из плана KillBill.
В примере выше мы видим строчку в Prometheus Exposition Format, в котором указаны метки и, конечно же, само значение метрики.
Как выставлять метрики из приложения? Для работы с Prometheus есть бесконечное количество библиотек для любого языка:
На самом деле, большинство людей никогда не пишут сами ничего в Prometheus, потому что Prometheus это pull модель. У Victoria есть компонент VM Agent, который скрапит метрики и помещает их в Victoria. Так у нас появляется второй lowcode-компонент — конфигурация скрапинга ваших метрик. В нем указаны лейбл, по которым мы идентифицируем, какие сервисы в Kubernetes надо проскрапить на наличие в них цен:

На самом деле, у нас две Victoria. Мы не любим создавать себе проблемы на ровном месте, поэтому одна хранит информацию всего лишь один месяц, чтобы не столкнуться с проблемами производительности. А вторая нужна для разрешения споров и хранит информацию два года. В ней можно посмотреть, почему сформировалась та или иная цена:

Как формировать метрики
Изначально была гипотеза сделать endpoint с метриками, чтобы Victoria забирала все данные, так как если вы будете пушить метрики в сам биллинг, то вам придется обучать команды API биллинга, которые будут от этого страдать:

Однако при реализации такого endpoint надо научиться как переживать его рестарт и бороться с несколькими репликами сервиса, реализующего endpoint.
Если все же заморачиваться с вызовами API биллинга, то придется делать еще и некий буфферизирующий слой:

Итого командам ничего не нравилось, поэтому они просили им сделать некий Generic Exporter. Но обычно, когда что-то начинают со слова «единый» или со слова Generic, это заканчивается провалом примерно через год:

Но на самом деле мы его написали для базовых кейсов. Можно сделать generic exporter, потому что большинство облачных PAAS сервисов, например, от Amazon, выставляют наружу всего лишь три метрики — входящий трафик, исходящий трафик и количество вызовов.
Если у нас все живет в Kubernetes, откуда это взять? Самое простое - с Ingress:

Более того, метрики в Ingress уже размечены необходимыми лейблами, и мы можем очень четко аллоцировать их куда надо, если предварительно договорились о формате создания Ingress:

Например, что у нас в пути всегда находится RN. Если команда хочет воспользоваться нашим универсальным Exporter, она просто в path пишет свой обязательный RN. Профит!
Как это выглядит с точки зрения кода?
Наш универсальный Exporter сканирует все Ingress, которые помечены для отправки цен, извлекает RN из пути по Ingress и вытаскивает необходимые метрики:

На самом деле, без колдунства с Ingress это, конечно же, не заработает. Поэтому вам надо подпатчить ваш Ingress настройками, чтобы эти метрики передавались.
Далее код размечает метрики тем самым RN из path, единицей измерения из плана KillBill и типом метрики. В данному случае параметры тарифа нарастающие, поэтому тип метрики у них Counter.
Далее мы пишем необходимую информацию в логи и отправляем всё в Prometheus Exposition Format. 105 строк кода, команде больше делать ничего не надо.
Как отдавать данные в биллинг?
Во-первых, надо учиться переживать сбои, поэтому извлекаем информацию из Victoria, когда последний раз загружали что-то в KillBill. На основе этой информации вычисляем оттуда дельту через PromQL. Мы схлопываем информацию подневно, потому что у нас такая договорённость с бизнесом, и записываем дельту. Причем эту дельту мы записываем тем приёмом через массив массивов, чтобы экономить количество вызовов. В принципе, у Victoria есть функция increase, которая просто превосходно позволяет вычислять дельту. Приписываем информацию для селф хиллинга, пишем логи, повторяем каждые 60 секунд, чтобы не было слишком больших разрывов в той самой Victoria. Получилось всего 112 строк кода.
Мы написали этот импортер восемь месяцев назад, и вообще его больше не трогали. Он просто работает. В принципе, это довольно простой кусок кода.
Также у нас есть микросервис, который работает с порталом самообслуживания. Он вычитывает из Kafka события создания тенантов и добавления продукта. Мы создаем при их появлении аккаунты и подписки в KillBill и пишем логи. Код занимает 90 строк. Этот код мы тоже написали один раз и уже восемь месяцев не трогаем. Он просто работает.
Таким образом, абстрактная архитектура биллинга уже начинает приобретать конкретные формы:

У нас появляется портал самообслуживания с Kafks, которою заполняет сообщениями портал. Мы перехватываем эти события и заводим их в биллинге. Мы перехватываем метрики Ingress, чтобы чаржить нашего пользователя. Получая детальные метрики, мы отправляем в KillBill агрегированные метрики.
Но есть гораздо более сложные продукты, поэтому такой кейс не всегда возможен. Есть, например, мое любимое объектное хранилище.
Продукт S3 делает абсолютно другая продуктовая команда и исторически сложилось, что RN находится в имени namespace, который создается при создании тенанта сервиса S3. Еще в нем есть свой личный endpoint /metrics и в нем лежат отдельно метрики по get, head, put, delete, post запросам.
Вытаскиваем из Ingress только метрику по исходящему трафику, потому что для S3 продукта интересна оплата только за исходящий трафик. Оптимальным с точки зрения производительности для получения информации об объеме занятого места у команды разработки S3 был CLI. Кастомный Exporter для объектного хранилища просто вытаскивал информацию из CLI, и размечал их метриками и типами из KillBill, писал логи и отдавал в Prometheus. Получалось 112 строк – опять-таки мизер.
В терминах биллинга, это так называемый mediation микросервис. Команда разработки сервиса S3 ни разу не меняла свой сервис ради того, чтобы поддержать биллинг. Был написан маленький, гордый, независимый микросервис, который фактически решил все вопросы. Его писала команда владельца сервиса объектного хранилища, что позволяет грамотно настроить процессы разработки и онбордить биллинг в вашу инфраструктуру не меняя paas/saas продукты. Таким образом, мы получаем кейс с архитектурой для кастомных продуктов:

Это всё равно нас напрягало, хотя бы потому, что доклад называется «lowcode биллинг»:

Мы стали смотреть и поняли, что большая часть кода наших экспортеров это взять данные из логов, эндпоинтов, трансформировать их в метрики потребления и отдать их в Prometheus.
Мы решили, что можно с этим что-то сделать с помощью каких-либо коллекторов логов. Для этого мы выбрали продукт Vector. Vector может взять данные из рандомного места и преобразовать их во внутренний формат, применить свой язык преобразования и переместить их в нужное место:

Давайте посмотрим как это работает применительно к биллингу.
Итак, у нас есть источники Vector и у Vector-а есть специальный тип – Prometheus, то есть сам Vector может взять и присоединиться к Prometheus:

Отправка данных
Данные надо отправлять. Мы отправляем данные, внимание, в Prometheus. Для этого тоже не надо ничего писать. Всё работает абсолютно самостоятельно как мы любим - просто используем компонент Prometheus exporter. Vector сам умеет им прикидываться и это очень удобно. Не нужно писать HTTP клиента, не надо ни о чем думать:

Дальше пойдёт речь о преобразованиях. У Vectorа есть огромный набор встроенных преобразований. Мы использовали чаще всего преобразовании Remap. Оно позволяет использовать язык VRL - Vector Remap Language для описание логики трансформации:

Также мы использовали преобразования Filter, который позволяет выкидывать ненужные метрики и преобразование log to metrics, который высчитывает наши логи и превращает их в метрики.
VRL очень мощный и простой язык, но из-за того, что он fail-safe, это приводит к многословности. То, что можно написать одной строкой, на Vector будет в три строки, но зато это позволяет быстро онбордить команды.
Я люблю Vector ещё и за то, что в нём есть прекрасный веб-плейграунд. Вы можете очень быстро проверить свою гипотезу, не ставя никакие плагины:

Рассмотрим код универсального Exporter на Vector:

Тут есть немножко кода на языке VRL, но он посвящен тому, чтобы просто красиво назвать метрики, проставить их типы, поставить RN и извлечь путь, тот самый RN, из Ingress.
Убираем ненужные метрики с Ingress и всё, готово.
Было 105 строчек Python, стало 57 строчек TOML. Если применять грязную уличную магию, этих строчек может стать 40, но я просто не стал вас пугать. Но суть абсолютно не в количестве строчек, а в том, что когда используете данный подход, вы получаете встроенное логирование, встроенную трассировку, встроенный мониторинг, высокую надежность и фреймворк для юнит-тестов вашего mediation layer. Потому что если вы думаете, что биллинг надо делать без юнит-тестов, вы глубоко не правы.
Таким образом, от кастомного, полукустарного процесса биллинга для каждого продукта мы получили уже в целом неплохой lowcode фреймворк, где есть, как в классическом биллинге, mediation layer на TOML, с использование которого можете взять информацию для метрик биллинга с любых источников:

Очень важный момент для биллинга– это квоты, так они позволяют управлять тратами ваших пользователей. И, конечно же, для этого мы использовали другое lowcode-решение и другой DSL.
У нас появился еще один lowcode-компонент на базе YAML. Наверное, вы догадались, что это за язык, который мы используем для квотирования - это PromQL и конфиг Victoria для prometheus alert manager!
Смотрите, вот наши итоговые lowcode-компоненты:

Это KillBill с тарифным планом, это YAML Victoria Scrape конфига для вычитки финансовых метрик, это DSL для задания квот и это почти lowcode в виде TOML на Mediation layer. Итого кода, который написала команда биллинга, совсем немного.
Этот код вообще не меняется.
На самом деле, всё не так гладко:
Во-первых, мы очень жестко зависим от инфраструктуры Kubernetes и generic exporter работает на его сущностях и особенностях nginx ingress контроллера.
Если вы не разберетесь с аналитическими отчетами KillBill, то будете получать баланс по 2-3 секунды. И хотя в частном облаке это не очень критично, всё равно воспринимается пользователями нервно.
В агрегируемых метриках есть перерывы, которые равны скрейп-интервалу и они вызывают вопросы.
VRL не настолько универсально космический, насколько хочется и в процессе реализации нашего продукта мы добавили немножко issue разработчикам.
Тем не менее на нашем подходе можно создать generic биллинг и generic exporter, и командам вообще не надо напрягаться. Они просто ставят exporter себе в кластер Kubernetes и получают биллинг их продуктов.
В 2022 году все уже знакомы, по меньшей мере, с двумя опенсорсными продуктами, кроме KillBill. 80% конфигурирования – это YAML, XML и TOML. И комьюнити KillBill, на самом деле, очень живое. Да, оно немного старомодное, живет без слака в Гугл-группах, но там действительно отвечают на вопросы и помогают.
Итак, прошло какое-то время и мы захотели сравнить то что получилось с Exivity.

И мы поняли, что таким простейшим решением, которое некоторые люди называют скриптами, а не кодом, мы сделали биллинг, метринг и возможность подключать к биллингу любые сервисы. А если вы возьмете модули KillBill overdue и Killbill entitlement, то можете точно так же вызывать Terraform и управлять вашей инфраструктурой исходя из событий биллинга. Если вы хотите отражать это во внутренних учетных системах - используйте KillBill Payment и напишите свой плагин.
Выводы
Возможна разработка generic биллинга на основе pull подхода.
Данный продукт сделали два SRE за один месяц, причем не полностью посвящая себя ему.
Было использовано три опенрсорс продукта, из которых два широко известны.
Написали всего 400 строк кода на Python-e.
Если команде надо занести новый продукт в биллинг, она пишет кусочек XML, YAML и TOML только если не желает использовать Generic Exporter.
Мы не трогали код KillBill.
Да, это не полный lowcode, но я считаю, что использование DSL для гибкой настройки mediation layer вполне оправдано.
Хотите стать спикером конференции DevOpsConf 2023?
Нужны реальные истории и находки ваших команд.
Прием заявок до 1 декабря 2022, подробности.Настоящее формирование программы конференций начинается со встречи с сообществом!
Уже завтра, 10 ноября в 16:00, пройдет онлайн-встреча Программного комитета DevOpsConf 2023 с потенциальными спикерами и активистами.Все интересующие вопросы можно задать прямо там, вживую. Обсудим текущее состояние отрасли и ваши темы для выступлений.
Участие свободное. Но регистрация обязательна!
А 17 ноября пройдет офлайн встреча с 19:00 до 21:00 по адресу г. Москва, улица Льва Толстого, д. 16. Офис Яндекса, Конференц-зал "Экстрополис" (рядом с конём).
Время сбора гостей - 18:30 - регистрация.