

Первый код на Ruby я написал 14 лет назад и делаю это до сих пор. Но в основном я выполняю роль тимлида в командах разработки, то есть делаю все то, что другие не хотят или не могут делать. :) Последние несколько лет я с командой делаю в России инвестиционную платформу для онлайн-кредитования бизнеса — «Поток.Диджитал».
Изначально у нас был Ruby-монолит и несколько сервисов на Python. JavaScript только на фронте. Но однажды мы купили аж целый проект, написанный другой командой (не спрашивайте, зачем) на Node.js. Очень важный и нужный нам проект. И встала задача поддержки (in production) и развития (new business features) прямо сейчас. Так как мы хорошо знали бизнес-логику, то решили попробовать самостоятельно заняться кодингом на JavaScript. Сформировали команду героев из Ruby-бекендеров, усилились самураями Node.js, и достигли успеха (успешного, конечно же!). Но я расскажу о трудностях, с которыми мы столкнулись на этом пути, чтобы вы, дорогие читатели, понимали, к чему готовиться, если вдруг.
JavaScript vs. Ruby
Ruby-разработчики действительно умеют работать с JavaScript, это не миф. Любой бекенд-программист писал что-нибудь на JS для фронта. Уровень у всех разный, но переходить на Node.js в любом случае проще, чем в другую технологию.
Однако есть нюанс — асинхронность. К асинхронности придется привыкнуть, поскольку стандартный разработчик из Ruby-мира, скорее всего, сталкивался с ней нечасто.

Код на ноде испещрен async и await. Для неподготовленного зрителя их расположение может показаться хаотичным и не поддающимся логическому осмыслению. В будущем становится понятно, что логика все же есть. Но поначалу разработчики будут забывать их писать и получат множество плавающих багов (нет, код не упадет, но будет работать неожиданным образом, то есть из вызова функции вернется совсем не то, что ожидают, а так как язык не типизированный, то дальше это пойдет обрабатываться с различными эффектами). Если сразу подключить и настроить линтеры, проблему можно нивелировать. Но в консоли придется пострадать.
Следующая сложность, с которой придется столкнуться — это backtrace.

Выше пример реального бектрейса из нашего баг-трекера. Произошла ошибка в каком-то запросе к БД, но что это за запрос и где он был вызван, остается полностью неизвестным. В качестве бонуса мы узнаем, как устроен Sequelize (ORM, аналог ActiveRecord) внутри, но как нам это поможет? Дело в том, что код выполняется асинхронно, и в том месте, где он выполняется (обработчик задач), о том, откуда и зачем он пришел, уже неизвестно. Это стреляет в разных местах, но с Sequelize это особая боль, и как с этим бороться, на момент написания статьи неясно.
Однако, в защиту Node.js надо сказать, что с такой же точно проблемой мы столкнемся и в Ruby, если будем использовать Ruby Fibers.
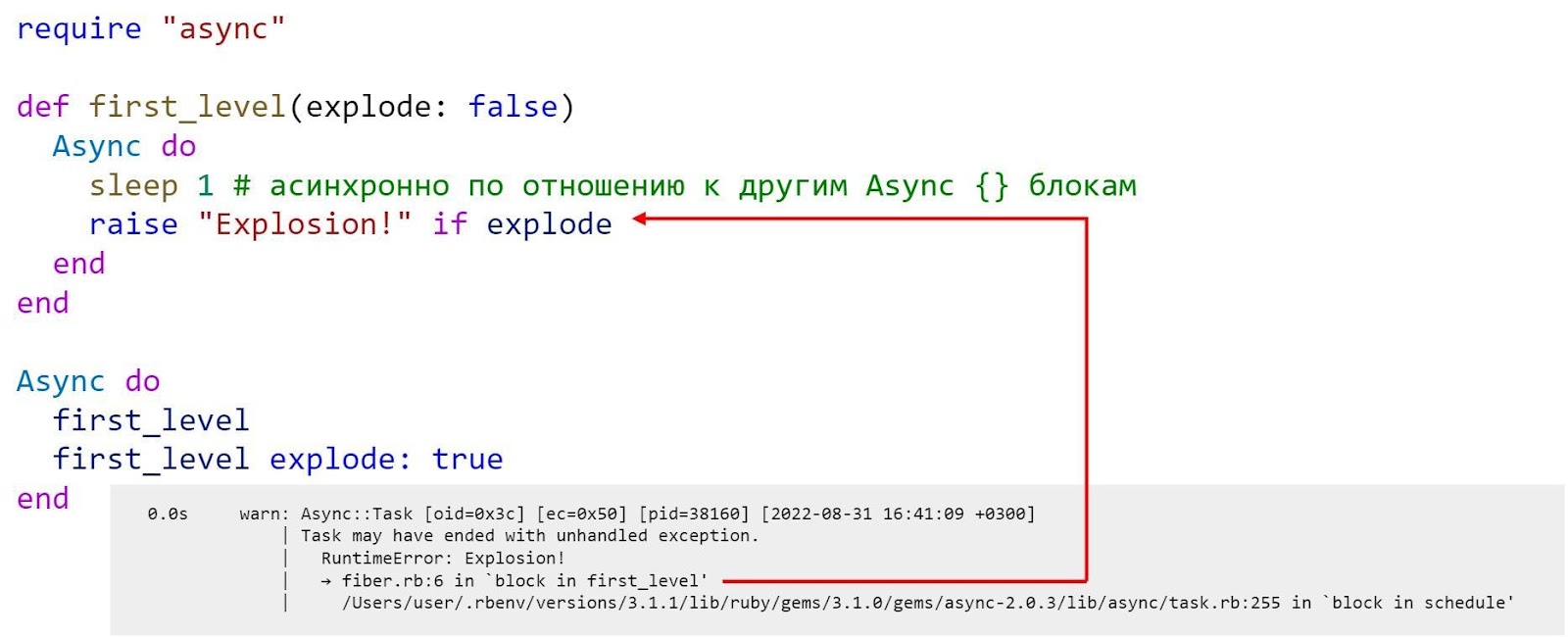
Тут с первого взгляда все ок, мы видим, что упало в 6 строке кода в функции first_level, но если переставить строку explode: true в блоке Async, то backtrace вообще не изменится! То есть мы знаем, где упало, но не знаем, откуда это было вызвано.
Экосистема. Фреймворки
В мире Node.js есть много веб-фреймворков. Один из самых популярных — Express (и его наследник — Koa). Это аналог Sinatra и главная проблема с ним, на мой взгляд, в том, что в Ruby-мире не принято на Синатре строить большой монолит, а в мире JS это происходит сплошь и рядом. Что приводит к многообразию самописных велосипедов, призванных заменить стандартные функции больших веб-фреймворков, которых в Экспрессе просто нет. На нашем проекте использовался Koa и мы всецело прочувствовали на себе этот эффект. Например, вместо стандартного роутинга, который крепится к дефолтному логированию и профайлерам, например, NewRelic или DataDog, мы имеем что-то кастомное, что при любых интеграциях работает как квадрат, который пытаются засунуть в круглое отверстие (как в детской игре с кубиками разной формы и домиком, куда их все надо запихать).
Для монолитов в Node.js есть фреймворк Nest.js и сейчас наблюдается тенденция использовать его по назначению, что, на мой взгляд, хорошо. Но для legacy проектов проблема, описанная выше, остается актуальной. В связи с этим хочется написать небольшой мотивационный текст, который надо прочитать всем, кто при слове «велосипед» не испытывает неприятных ощущений: доверяйте сообществу, переиспользуйте код. Мы живем в мире open source и для большинства проблем уже существуют решения. Код, написанный сообществом (а большинство больших open source проектов, таких, как Ruby on Rails, пишется усилиями сотен людей), с вероятностью 99% будет лучше, чем код, написанный одним, даже самым гениальным программистом. Лучше в данном случае может означать: покрывает больше edge cases, более безопасный, более быстрый, более гибкий и т.д. Коллективный разум имеет мощность, намного превышающую возможности одного человека. Поэтому не будьте наивны и самонадеянны, если на кону бизнес и его деньги, используйте стандартные решения.

Экосистема. База данных
База данных — это фундамент веб-приложения. В Ruby-мире обычно выбирают gem ActiveRecord, чтобы не выдумывать странного. В мире Node.js есть несколько решений. Хвалят TypeOrm, но он обычно идет в комплекте с Nest.js, а у нас был Sequelize. Это близкий аналог ActiveRecord и достаточно популярный (27K stars Sequelize VS 30K stars Typeorm on Github).
Не сказать, что он совсем плох, достаточно быстро привыкаешь и начинаешь уверенно с ним работать, а некоторые решения (например, возможность гибко настраивать поля, извлекаемые из joined таблиц), кажутся даже удобнее Active Record. Но на последней код намного лаконичней. Вот пример кода на Sequelize:

Аналог на ActiveRecord:

Если вместо хардкода в select вставить хеш users: :all, accounts: %i[type number], ... было бы еще лучше, но почему-то эта возможность до сих пор не реализована даже в Ruby on Rails.
Есть еще одна потенциальная проблема в Sequelize — это отсутствие scope в ранних версиях. Сейчас scopes в библиотеку уже внедрили, но если у вас legacy на старой версии, получите огромные портянки кода, которые будут либо копипастить по всему проекту, либо оборачивать в функции (с метапрограммированием, конечно!) в попытках сделать DRY и настраивать параметры для похожих запросов. Я такой код видел и на себе прочувствовал, как важны scopes на самом деле.
Также мелочь, но неудобно — в Sequelize отсутствует pluck. Вместо него приходится писать map:

Экосистема. Тестирование
А как там в Node.js с тестами, спросите вы. И будете правы, ведь писать код без тестов (в первую очередь я имею в виду unit тесты и TDD) в настоящее время моветон. Для тестов мы используем фреймворк Mocha. Это одно из самых популярных в JS мире решений, поэтому большинство разработчиков с ним знакомы, что хорошо. Но, как всегда, есть нюансы. Удивительно, что из коробки не предлагается поддержка транзакционных тестов, которые в RSpec уже лет 10 как все используют по умолчанию. Транзакционный тест — это когда сначала открывается транзакция, выполняются действия, изменяющие данные в БД, и потом транзакция откатывается. Таким образом все работает очень быстро и не приходится чистить базу данных. В Mocha такого нет, можно написать самостоятельно, но не для всех ORM. Для Sequelize, например, это сделать затруднительно, из-за особенностей работы с транзакциями (в Sequelize приходится передавать транзакцию явно в каждый вызов методов библиотеки, и нет способа обернуть код в транзакцию снаружи). Нам данная конструкция досталась в наследство, при старте же нового проекта мой совет — используйте транзакционные тесты, это дает существенный прирост скорости их выполнения, особенно на больших объемах.
Поговорим о фабриках. В JavaScript есть аналог factory_bot — Fishery, разработанный той же командой Thoughtbot, которая написала factory_bot для Ruby. Но в Fishery, как это ни странно, тоже нет поддержки Sequelize из коробки. Их можно подружить, но код получается довольно тяжеловесным.

Кстати, если в этом коде забыть await, то получится плавающий тест (heisentest). Не забываем про линтеры.
Экосистема. Логи
Мне очень нравится, как сделано логирование в рельсах. Они задали стандарт логирования с момента возникновения фреймворка, и этот стандарт в своей сути изменился незначительно. В логах rails-приложения можно найти почти все, что нужно знать о работе системы: запросы к БД, вызов внешних API, рендеринг, входящие параметры, код ответа. Есть встроенный механизм trace_id, который «склеивает» логи для каждого отдельного запроса (ключевая вещь в системах, поддерживающих concurency, а это Puma и Sidekiq, а также в микросервисных системах, хотя это уже другая история). Таким образом, когда используешь рельсы, вопрос что и как логировать не встает — за вас уже подумало сообщество.
В нашем проекте на Koa мы обнаружили вручную написанное логирование для веб-запросов, так как стандартного нет. То есть как сам функционал, когда и как писать в лог, так и формат сообщений — все переизобреталось заново. Это логирование оказалось гораздо менее удобным, чем предлагаемое в Rails из коробки. Нам пришлось потратить время, чтобы улучшить его, но этот велосипед, я уверен, еще потребует ручного вмешательства. А это деньги компании, которые хотелось бы тратить на создание новых функций для пользователей, а не на написание давно известных в мире решений.
Экосистема: background jobs
В Ruby-мире самый зеленый новичок знает, что долгую работу не нужно выполнять во время обработки веб-запросов, а ее нужно передавать на исполнение в бекграунд. В Ruby для этого сначала был delayed_job, потом Resque и теперь стандартом является Sidekiq. В мире Node.js есть аналоги Sidekiq — библиотеки Bull и Faktory, причем Faktory написана авторами Sidekiq. Faktory — достаточно мощное решение. Это целый сервер, на котором можно выполнять background jobs на разных языках программирования.
Но, как я выяснил на практике, многие JavaScript-разработчики не знают о существовании таких инструментов для бэкграунда, поэтому они начинают изобретать велосипеды: запускают тяжелые задачи по расписанию из планировщика (cron) или, в самых тяжелых случаях, внедряют очередь сообщений (например, Kafka) и микросервисы. Хотя асинхронные микросервисы — это не то, чтобы плохо, но выполнение функций в бекграунде — не самая веская причина для их появления в проекте.
Мой совет — использовать библиотеки для выполнения background jobs и не использовать более тяжеловесные архитектурные решения без необходимости.
Вторая проблема, на мой взгляд, заключается в том, что имея быстрый и асинхронный фреймворк, появляется искушение все делать быстро и асинхронно... непосредственно во время обработки веб запросов:
await Promise.all(…do your long work here in parallel chunks…)Это не масштабируется горизонтально и решает проблему только на небольших объемах данных. В любом случае необходимо выносить потенциально долгие задачи в background, где они перестают быть критичными по времени выполнения, а также исполняются параллельно, и важно сделать этот процесс максимально простым для разработчика.
TypeScript. Типизация
Все JavaScript-разработчики, с которыми я встречался, хотят писать на TypeScript. После обсуждения с командой, одной из первых наших задач по техдолгу стал перевод проекта на TypeScript. Меня порадовало, что этот переход удалось осуществить эволюционно, то есть постепенно, без больших разовых затрат времени и без негативного влияния на скорость доставки фич для бизнеса. Про то, что типизация — это хорошо, сейчас говорят из каждого утюга, а я расскажу о том, почему это может быть не совсем хорошо. :)
TypeScript — это уже не так просто для разработчика на других языках, как JavaScript, придется привыкать к новому синтаксису.
Появляется процесс компиляции и усложняется процесс развертывания и тестирования, поскольку шаг компиляции нужно встроить в CI/CD.
Если происходит ошибка, она происходит в автоматически сгенерированном JavaScript-коде, и backtrace будет вести именно в этот код, а вы будете искать ошибку в исходниках на TypeScript. Чтобы сопоставить одно с другим необходимы дополнительные инструменты.
Могут возникнуть проблемы со сторонними библиотеками, написанными на JS. Например, как это ни странно, с Sequelize. Придется тратить время на их интеграцию.
Избыточность интерфейсов и типов. Типы не всегда так полезны, как считается. И на этом вопросе хочется остановиться подробнее.

Сначала код был без типов, потом типы в него добавили. Пока все идет хорошо... Но не всегда добавление типов понимают именно так. Ниже приведен пример кода, в котором в проект добавлялись типы, но на самом деле притащили ряд паттернов, которые в данном случае не особо нужны.

Во первых, тут вход и выход из сервиса обернули в интерфейсы, и по сути — это паттерн value object. Но в данном случае он является излишним.
Результат функции превратился в result-монаду. В целом это хорошо, если такой паттерн применяется во всем проекте и это сделано осознанно. Но это история вообще не про типизацию.
Автор языка руби, Матц, считает, что даже добавление типов переменных в описание функций, как в первом примере, может быть излишним. Именно поэтому в Ruby сделали типы в отдельных файлах, а не добавили их в код, поскольку добавление типов — дополнительная работа для человека. Но большинство типов может вычислить машина (компилятор), поэтому в лишней работе для программиста нет необходимости.
Итоги
Наш проект на Node.js успешно работает в продакшене и развивается. Гипотеза о быстром переходе с руби на JS/TS разработку нашла свое подтверждение на практике. Однако мое личное мнение о том, что Ruby — язык более удобный и эффективный (с точки зрения скорости написания и качества кода), чем JS/TS, не изменилось после года работы с этими технологиями. Новые сервисы нам больше нравится писать на руби. Однако и у Node.js есть свои хорошие стороны.
Асинхронность
Повсеместная асинхронность имеет как свои плюсы, так и свои минусы, причем достаточно существенные.
Проблема в том, что в реальном мире большая часть бизнес-логики линейна. Соответственно, часто программист сражается с асинхронностью, а не извлекает пользу из нее. Асинхронность и concurency/параллелизм нужны для горизонтального масштабирования, для эффективной утилизации ресурсов процессора (в обмен на больший расход памяти). На практике важно иметь возможность запускать линейную бизнес-логику параллельно во многих копиях. Но сама бизнес-логика должна оставаться максимально простой, так как именно на ее изменение и доработки будут тратится усилия разработчиков — а значит и деньги компании.
Можно условно разделить задачи на два типа:
бизнес логика. Ключевые требования: простота, быстрота и предсказуемость изменений.
серверная логика. Ключевые требования: горизонтальное масштабирование, скорость работы, утилизация ресурсов.
В идеальном мире для первого асинхронность (в большинстве случаев) не нужна, но она нужна для второго. Причем второе — это написание библиотек для запуска и эксплуатации первого.
Мне нравится концепция Ruby в том, что можно написать простой код, но запускать его с помощью инструментов, поддерживающих асинхронность: Puma, Sidekiq, Falcon, и т.д. При необходимости, можно использовать асинхронность и в бизнес логике, например, с помощью Fibers. Но в повседневной деятельности это не мешает.
Да, Ruby медленный, как, впрочем, и Python. Но есть нюанс. Даже на Go или на C++ можно легко написать медленный код. Например, запустить медленный запрос к БД. Или вызвать синхронно долгий запрос во внешний сервис (а любой запрос во внешний сервис иногда бывает долгим). То есть, использование более быстрой технологии — не серебряная пуля и не гарантия того, что ваш сервис будет работать быстро.
В Node.js есть еще одна особенность, о который важно упомянуть. Есть возможность полностью заблокировать event loop и по сути остановить все приложение целиком. На практике это выглядит так: пользователи получают 502, процессы приложения запущены, ошибок нет, и приложение полностью перестает писать логи! Мы пару раз сталкивались с таким эффектом и это очень неприятно. Чтобы почитать об этом подробнее, достаточно набрать в google: «how to block event loop».
Правильный инструмент для задачи
Не стоит использовать микрофреймворки для монолитов, поскольку это приведет к написанию велосипедов.
Не стоит писать велосипеды там, где можно использовать готовое решение от сообщества. Оно с вероятностью 99% будет лучше, чем ваше собственное. Чем более стандартный ваш проект — тем меньше ваш бас-фактор и тем быстрее проходит адаптация новых участников команды.
Не стоит считать типизацию серебряной пулей. «У нас будет меньше ошибок» — это достаточно абстрактный критерий, ведь не все ошибки можно нивелировать типизацией. Многие действительно серьезные ошибки легко делаются в любом типизированном языке (ошибки в алгоритмах, долгие операции в real time функциях, пренебрежение тестированием).
Счастливый конец
Эффективной работа бывает тогда, когда она приносит радость. Давайте работать с теми технологиями, которые нам нравятся, если мы уверены в том, что эти технологии решают наши задачи эффективно. :)
Pastoral
"Первый код на Ruby я написал 14 лет назад и делаю это до сих пор." - А сколько булочек Вы можете съесть натощак?
dmitry_matveyev Автор
Несколько штук, наверное, смогу, а что?
Pastoral
Значит у Вас равномерный подход в обоих случаях. Это был, если что, шутка вопрос с советского телевидения - одну, остальные будут уже не натощак. Как и первый код не будет первым даже раньше чем на второй год, не говоря о четырнадцетом.
dmitry_matveyev Автор
Отличная шутка! Только какое это имеет отношение к теме статьи?
Pastoral
Не к теме, к фразе про писание первого кода 14 лет.
dmitry_matveyev Автор
Фраза получилось не очень изящной, согласен. Имелось в виду, что я продолжаю писать код на руби и сейчас. Я протестировал на нескольких людях и все поняли ее именно так. Поэтому она осталась. :)