

Собираетесь ли вы развертывать базу данных в кластере Kubernetes? Если так – то это отличный выбор. Kubernetes – это инструмент оркестрации контейнеров, который при помощи множества инструментов координирует эксплуатацию приложений в контейнерах (подах). Один из этих контроллеров называется StatefulSet и используется для эксплуатации приложений, сохраняющих состояние.
Развертывание приложений с сохранением состояния в кластере Kubernetes порой бывает утомительной задачей. Дело в том, что приложение, сохраняющее состояние ожидает, что придется работать с архитектурой «ведущий-ведомый» (primary-replica), а имя пода будет фиксированным. Контроллер StatefulSets решает эту проблему, развертывая в кластере Kubernetes приложение с сохранением состояния.
Из этой статьи вы подробнее узнаете, что представляют собой StatefulSet в кластере Kubernetes, и в каких ситуациях из использовать, а также как развернуть приложение с сохранением состояния при помощи контроллера StatefulSets. Все это будет рассмотрено в пошаговом примере, в который мы включим все файлы манифеста (YAML). Более того, концепция StatefulSets будет продемонстрирована при помощи базы данных MySQL, и мы заодно рассмотрим, как создать фиксированное имя пода для каждой репликации MySQL, а также как обращаться к реплицированным подам через объект Services.
❯ Что такое приложения с сохранением состояния?
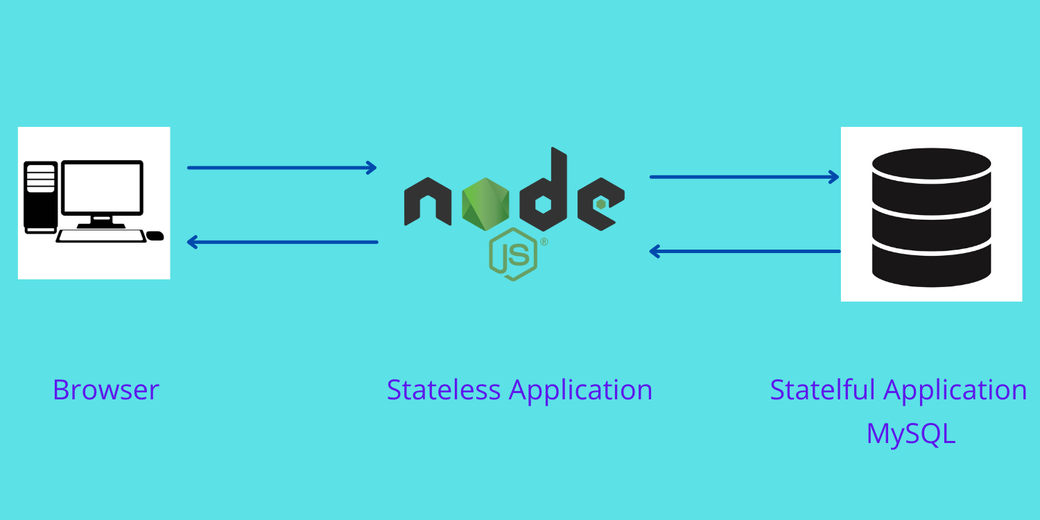
Это приложения, которые сохраняют данные и помогают их отслеживать. Все базы данных, в частности, MySQL, Oracle и PostgreSQL – это примеры приложений, сохраняющих состояние. С другой стороны, в приложениях без сохранения состояния данные долго не держатся. Примеры приложений без сохранения состояния — Node.js и Nginx. Если состояние в приложении не сохраняется, то на каждый запрос приложение будет получать новые данные и обрабатывать их.
В современных веб-приложениях такие приложения без сохранения состояния соединяются с приложениями, сохраняющими состояние, чтобы обслужить пользовательский запрос. Приложение Node.js не сохраняет состояние, оно получает новые данные при каждом запросе, поступающем от пользователя. Далее это приложение соединяется для обработки данных с другим, сохраняющим состояние, например, с базой данных MySQL. База данных MySQL сохраняет данные и продолжает их обновлять, исходя из пользовательского запроса.
Далее подробнее поговорим о структурах StatefulSet в кластере Kubernetes — что они собой представляют, как ими пользоваться, и каковы наилучшие практики обращения с ними.
❯ О структурах StatefulSet
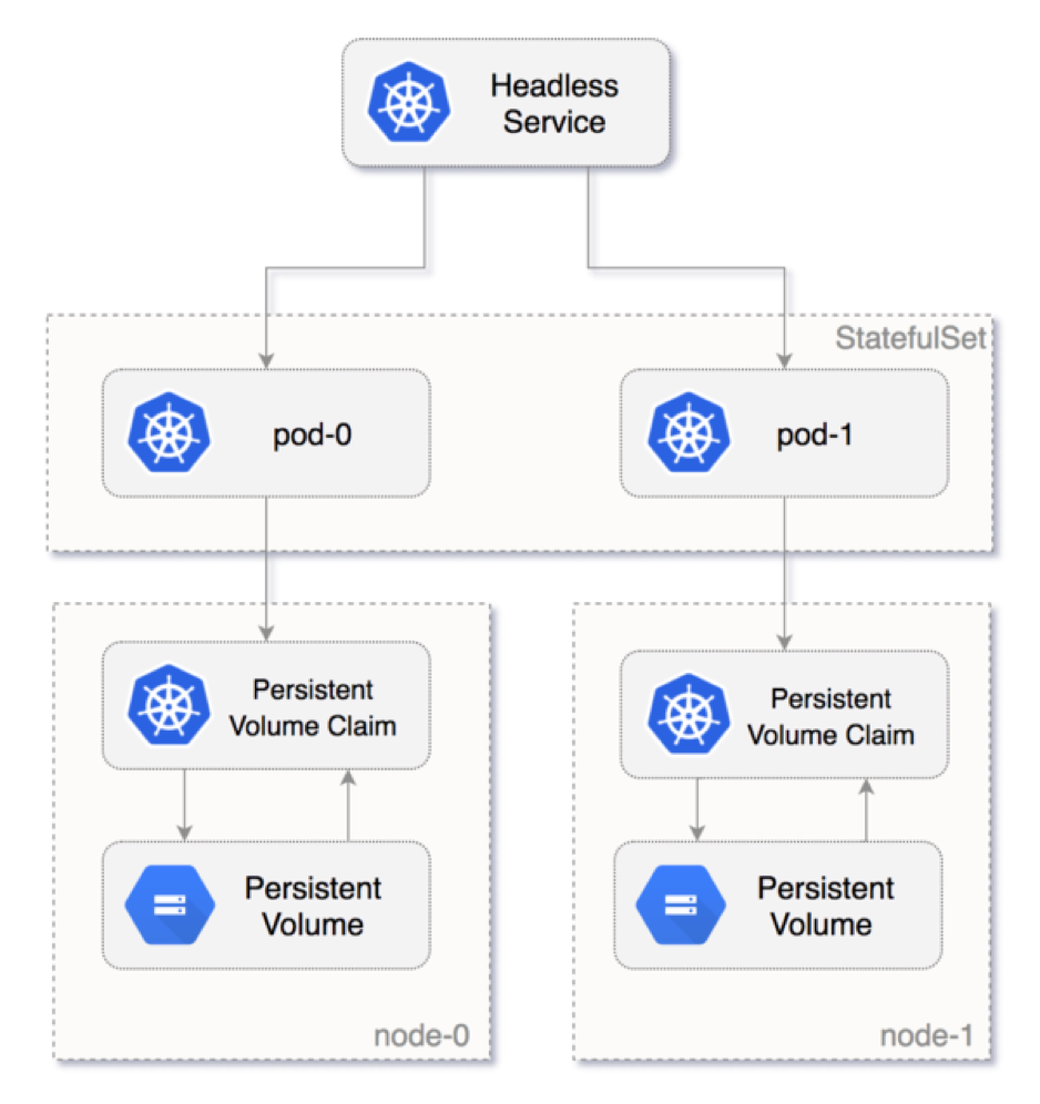
StatefulSet – это контроллер Kubernetes, применяемый для эксплуатации сохраняющих состояние приложений в виде контейнеров (подов) в кластере Kubernetes. StatefulSet присваивают каждому поду идентификатор-липучку (sticky identity) – порядковый номер начиная с нуля — а не случайные ID каждой реплике пода. Новый под создается клонированием данных уже существовавшего пода. Если ранее существовавший под находился в ожидающем состоянии, то новый под создан не будет. Удаление подов происходит в обратном порядке, а не в случайном. Например, если у вас было четыре реплики, и в результате масштабирования их количество было сокращено до трех, то под номер 3 будет удален.
На приведенной ниже схеме показано, как поды нумеруются, начиная с нуля, и как в StatefulSet к поду прикрепляется том долговременного хранения данных.
❯ Когда использовать StatefulSets
Есть несколько причин, по которым может быть целесообразно использовать StatefulSets. Рассмотрим два примера:
- Допустим, вы развернули базу данных MySQL в кластере Kubernetes и масштабировали ее до трех реплик, а клиентское приложение пытается получить доступ к кластеру MySQL, чтобы считывать и записывать данные. Запрос на считывание будет переадресовываться на три пода. Однако запрос на запись будет переадресовываться только на первый (ведущий) под, а записанные сюда данные будут синхронизироваться с другими подами. Это достижимо при помощи StatefulSets.
- Если удалить StatefulSet или отмасштабировать вниз, то не будут удалены тома, связанные с приложением, сохраняющим состояние. Так вашим данным обеспечивается безопасность. Если удалить или перезапустить под с MySQL, то вы сможете обращаться к данным из все того же тома, что и раньше.
Объект Deployment и StatefulSets
Также можно создавать поды (контейнеры), используя в кластере Kubernetes объект Deployment. Так вы сможете с легкостью реплицировать поды и прикреплять к подам тома, служащие в качестве хранилищ данных. То же самое можно проделать и при помощи StatefulSets. В чем же тогда преимущество работы со StatefulSets?
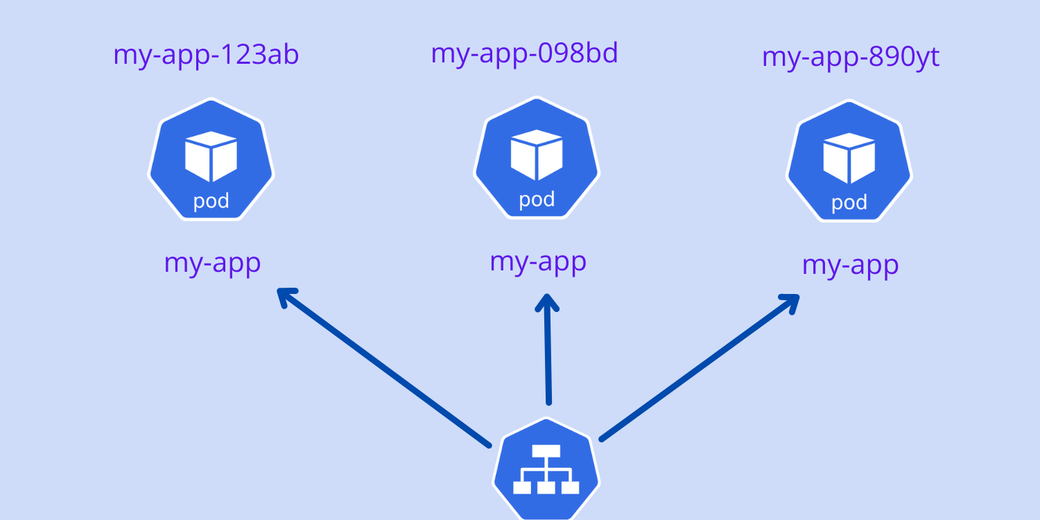
Дело в том, что подам, создаваемым при помощи объекта Deployment, присваиваются случайные ID. Например, вы создаете под с именем “my-app”, после чего расширяете его до трех реплик. Имена этих подов создаются примерно так:
my-app-123ab
my-app-098bd
my-app-890ytВслед за именем “my-app” добавляются случайные ID. Если под перезапускается, либо выполняется масштабирование вниз, то, опять же, объект Kubernetes Deployment присвоит иные случайные ID каждому поду. После перезапуска имена всех подов примут вид:
my-app-jk879
my-app-kl097
my-app-76hf7Все эти поды ассоциированы с одним сервисом, выполняющим балансировку нагрузки. Поэтому в приложении, не сохраняющем состояния, изменения в именах подов легко идентифицируются, а сервисный объект легко обрабатывает случайные ID подов и распределяет нагрузку. Такой тип развертывания очень хорош с приложениями, не сохраняющими состояние.
Но вот приложения, сохраняющие состояние, таким образом развертывать невозможно. Приложению, сохраняющему состояние, требуется липкий идентификатор для каждого пода, поскольку поды-реплики не идентичны.
Рассмотрим развернутый инстанс базы данных MySQL. Предположим, вы создаете поды для базы данных MySQL при помощи объекта Kubernetes Deployment и масштабируете поды. Если вы записываете данные в один под MySQL, то ни в коем случае не реплицируйте те же данные на другом поде MySQL, если под перезапускается. Это первая проблема с объектом Kubernetes Deployment применительно к приложениям, сохраняющим состояние.
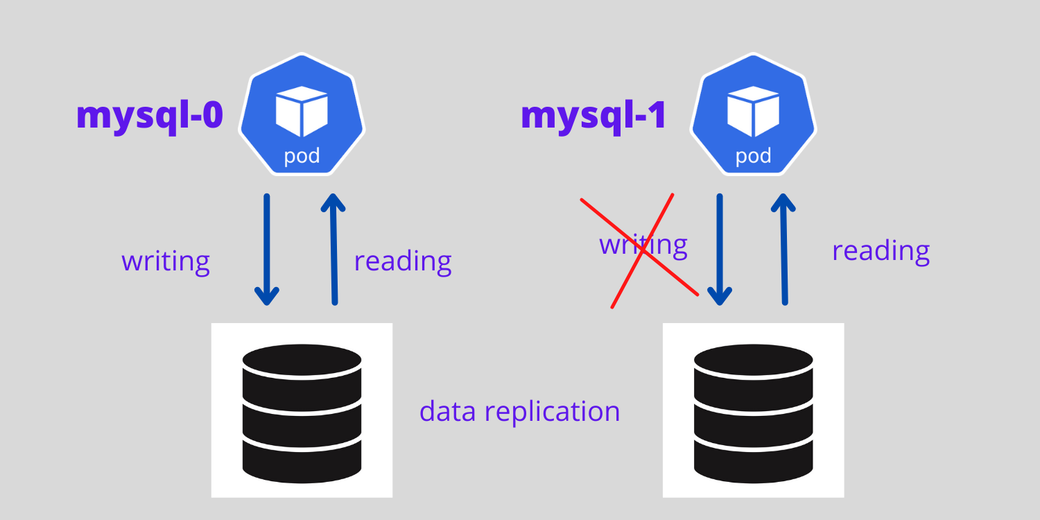
Приложениям, сохраняющим состояние, всегда нужен липкий идентификатор. Притом, что объект Kubernetes Deployment предлагает случайные ID для каждого пода, контроллер Kubernetes StatefulSets предлагает для каждого пода порядковый номер начиная с нуля, вида: mysql-0, mysql-1, mysql-2 и т. д.
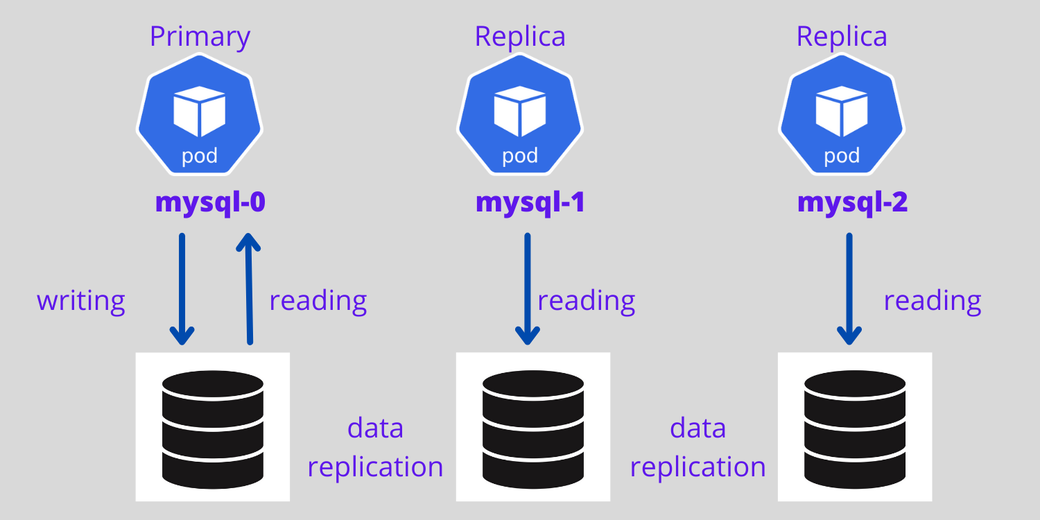
Для приложений, сохраняющих состояние и работающих с контроллером StatefulSet, можно задать первый под в качестве ведущего, а остальные поды сделать репликами ведущего. Первый под будет обрабатывать поступающие от пользователя как на чтение, так и на запись, а прочие поды будут всегда синхронизироваться с первым для репликации данных. Если под погибает, то создается одноименный ему новый под.
На следующей схеме показана архитектура с ведущим инстансом MySQL и репликами, где предусмотрен том для долговременного хранения данных и система репликации данных.
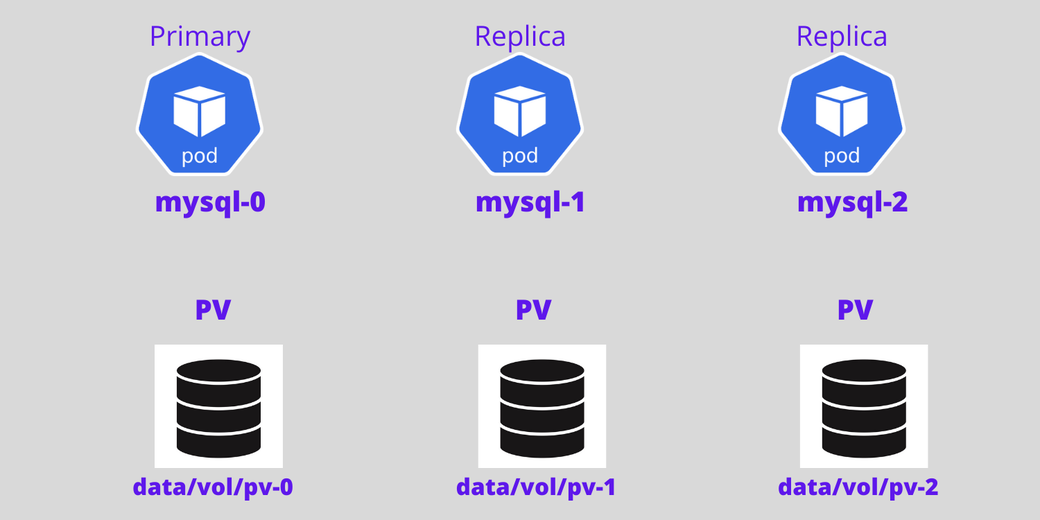
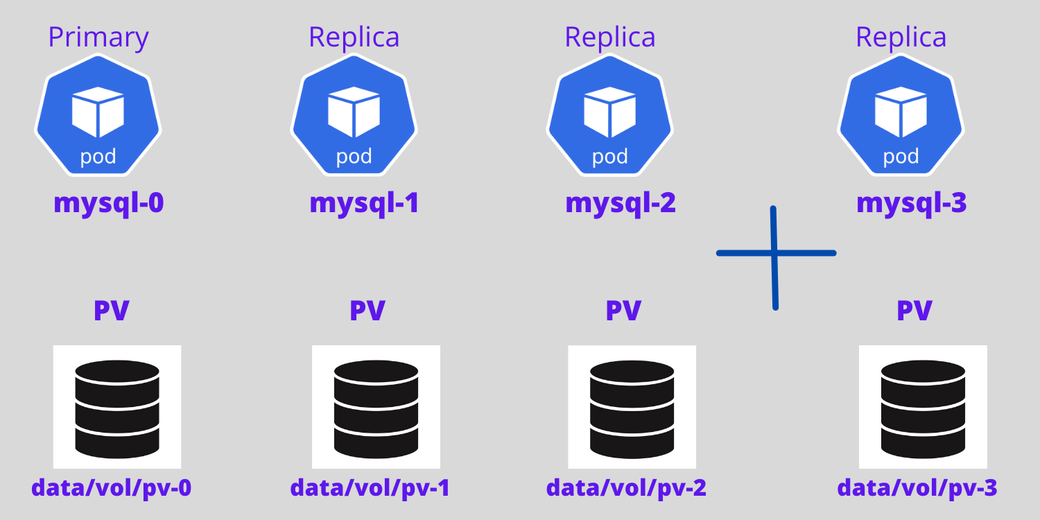
Теперь добавим сюда еще один под. Четвертый под будет создан лишь в случае, если третий под активен и работает, и на четвертый под будут склонированы данные с существовавшего ранее пода.
Резюмируя, обозначим, что StatefulSets обеспечивают следующие преимущества по сравнению с объектами Deployment:
- Порядковые номера для каждого из подов.
- Первый под может выступать в качестве ведущего, благодаря чему хорошо подходит для подготовки конфигурации с реплицируемой базой данных – такая конфигурация позволяет обрабатывать как чтение, так и запись.
- Другие поды действуют в качестве реплик.
- Новые поды будут создаваться лишь в случае, если более ранний под сейчас действует, причем, данные более раннего пода клонируются.
- Поды удаляются в порядке, обратном тому, в котором создавались.
❯ Как создать StatefulSet в Kubernetes
В этом разделе будет рассказано, как создать под для базы данных MySQL, воспользовавшись для этого контроллером StatefulSets.
Создаем секрет
Сперва нужно создать для приложения MySQL секрет, в котором будет храниться конфиденциальная информация, в частности, имена пользователей и пароли. Здесь я создаю простой секрет. Но при работе в продакшене рекомендуется использовать хранилище Vault от HashiCorp. Секрет для MySQL создается при помощи следующего кода:
apiVersion: v1
kind: Secret
metadata:
name: mysql-password
type: opaque
stringData:
MYSQL_ROOT_PASSWORD: passwordСохраните код в файле, который будет называться
mysql-secret.yaml, и выполните код в вашем кластере Kubernetes при помощи следующего кода: kubectl apply -f mysql-secret.yamlПолучите список секретов:
kubectl get secretsСоздаем приложение StatefulSet для MySQL
Прежде, чем создать приложение StatefulSet, проверьте ваши тома – для этого просто выведите список томов долговременного хранения:
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM STATUS
pvc-e0567 10Gi RWO Retain BoundДалее выведите список заявок на тома долговременного хранения:
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS
mysql-store-mysql-set-0 Bound pvc-e0567d43ffc6405b 10Gi RWOНаконец, получим список классов хранилища:
kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY
linode-block-storage linodebs.csi.linode.com Delete
linode-block-storage-retain (default) linodebs.csi.linode.com Retain Затем при помощи следующего кода создадим для MySQL приложение StatefulSet в кластере Kubernetes:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql-set
spec:
selector:
matchLabels:
app: mysql
serviceName: "mysql"
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
terminationGracePeriodSeconds: 10
containers:
- name: mysql
image: mysql:5.7
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-store
mountPath: /var/lib/mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-password
key: MYSQL_ROOT_PASSWORD
volumeClaimTemplates:
- metadata:
name: mysql-store
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "linode-block-storage-retain"
resources:
requests:
storage: 5GiЗдесь нужно отметить несколько вещей:
-
kind– это StatefulSet.kindприказывает Kubernetes создать приложение MySQL с возможностью сохранения состояния - Пароль берется из объекта Secret при помощи
secretKeyRef. - Блоковое хранилище Linode использовалось в
volumeClaimTemplates. Если здесь не упомянуть имени никакого класса хранилища, то для вашего кластера будет выбрано то хранилище, что задано по умолчанию. - Количество реплик здесь равно 3 (указывается в параметре replica), поэтому будет создано три пода с именами
mysql-set-0,mysql-set-1иmysql-set-2.
Далее сохраняем код в файле под именем
mysql.yaml и выполняем его при помощи следующей команды:kubectl apply -f mysql.yaml
Теперь, когда поды MySQL созданы, получаем список подов:
kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-set-0 1/1 Running 0 142s
mysql-set-1 1/1 Running 0 132s
mysql-set-2 1/1 Running 0 120sСоздаем сервис для приложения со StatefulSet
Теперь создаем сервис для пода MySQL. С приложением, сохраняющим состояние, нельзя использовать балансировщик нагрузки. Вместо этого создадим для приложения MySQL «безголовый» сервис, воспользовавшись следующим кодом:
apiVersion: v1
kind: Service
metadata:
name: mysql
labels:
app: mysql
spec:
ports:
- port: 3306
clusterIP: None
selector:
app: mysqlСохраняем этот код в файле под именем
mysql-service.yaml и выполняем при помощи следующей команды:kubectl apply -f mysql-service.yamlПолучаем список работающих сервисов:
kubectl get svcСоздаем клиент для MySQL
Если вы хотите обращаться к MySQL, то вам понадобится клиентский инструмент для работы с MySQL. Разверните клиент MySQL, воспользовавшись следующим кодом манифеста:
apiVersion: v1
kind: Pod
metadata:
name: mysql-client
spec:
containers:
- name: mysql-container
image: alpine
command: ['sh','-c', "sleep 1800m"]
imagePullPolicy: IfNotPresentСохраните этот код в файле под именем
mysql-client.yaml и выполните при помощи следующей команды:kubectl apply -f mysql-client.yamlЗатем введите в клиент MySQL следующий код:
kubectl exec --stdin --tty mysql-client -- shНаконец, установите клиентский инструмент для работы с MySQL:
apk add mysql-clientОбратитесь к приложению MySQL через клиент MySQL
Далее будем обращаться к приложению MySQL через клиент MySQL и создавать базы данных в подах.
Если вы еще не зашли в под с клиентом MySQL, введите следующий код:
kubectl exec -it mysql-client /bin/sh
Чтобы обратиться к MySQL, можно воспользоваться все той же стандартной командой MySQL, чтобы подключиться к серверу MySQL:
mysql -u root -p -h host-server-nameДля доступа вам понадобится имя сервера MySQL. Синтаксис сервера MySQL в кластере Kubernetes приведен ниже:
stateful_name-ordinal_number.mysql.default.svc.cluster.local
#Example
mysql-set-0.mysql.default.svc.cluster.localПодключитесь к ведущему поду MySQL при помощи следующей команды. Когда система запросит пароль, введите тот, который вы подобрали в предыдущем разделе о создании секрета.
mysql -u root -p -h mysql-set-0.mysql.default.svc.cluster.localДалее создайте базу данных в ведущем поде с MySQL, после этого выйдите:
create database erp;
exit;Теперь подключайтесь к другим подам и создайте базу данных так, как показано выше:
mysql -u root -p -h mysql-set-1.mysql.default.svc.cluster.localmysql -u root -p -h mysql-set-2.mysql.default.svc.cluster.localНе забывайте, что, конечно, Kubernetes помогает настроить приложение с сохранением состояния, но клонирование и синхронизацию данных вы должны настроить самостоятельно. StatefulSets сами этого сделать не смогут.
❯ Наилучшие практики
Если вы планируете развертывать приложения, работающие с сохранением состояния, например, Oracle, MySQL, Elasticsearch и MongoDB, то StatefulSets – отличный вариант для вас.
Создавая приложения с сохранением состояния, учитывайте следующие факторы:
- Создайте для баз данных отдельное пространство имен.
- Все компоненты, необходимые для приложений с сохранением состояния, например, ConfigMaps, секреты и сервисы, размещайте в конкретном пространстве имен.
- Ваши собственные скрипты размещайте в ConfigMaps.
- При создании объектов «сервис» пользуйтесь безголовым сервисом, а не сервисом для балансировки нагрузки.
- Секреты храните в Vault или HashiCorp.
- Данные храните только в томе для долговременного хранения. В таком случае ваши данные не будут удалены, если под погибнет или аварийно завершит работу.
Объекты Deployment – это самые ходовые контроллеры, используемые для создания подов в Kubernetes. Эти поды легко масштабировать, для этого достаточно указать в файле манифеста количество реплик. Например, допустим, вы планируете развернуть приложение Node.js, после чего собираетесь распространить его на пять реплик. В таком случае вам хорошо подойдет объект Deployment.
На следующей схеме показано, как Deployment и StatefulSets присваивают имена подам.

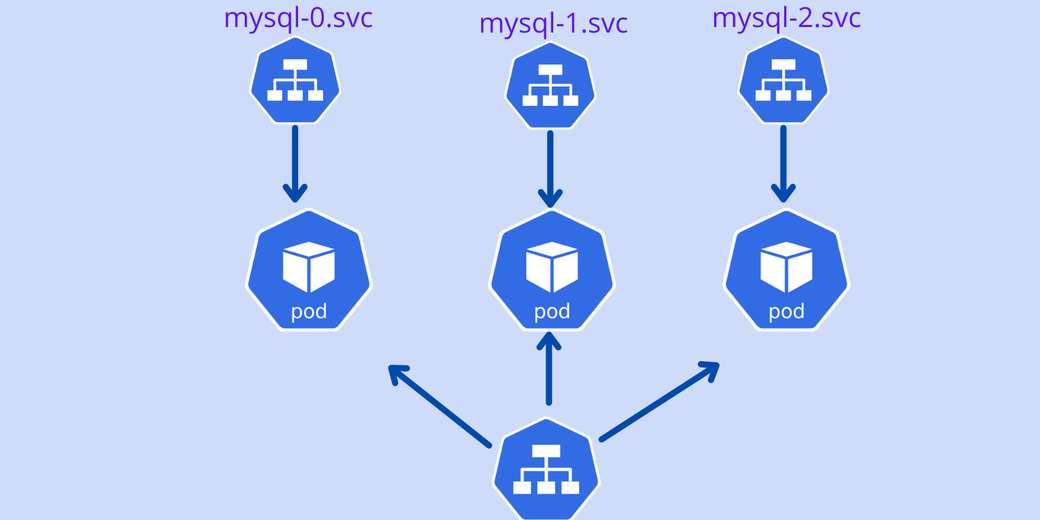
StatefulSets создают пронумерованные по порядку конечные точки сервисов для каждого пода, созданного путем репликации. На следующей схеме показано, как создаются конечные точки сохраняющих состояние подов (пронумерованные по порядку), и как они обмениваются информацией друг с другом.
❯ Заключение
В этой статье было рассказано о двух главных контроллерах, используемых в Kubernetes для создания подов: Deployment и StatefulSet. Объект Deployment очень хорош для работы с приложениями, не сохраняющими состояние, а StatefulSets – с сохраняющими. Если вы планируете развертывать приложения, сохраняющие состояние, например, MySQL и Oracle, следует воспользоваться контроллером StatefulSets, а не объектом Deployment.
Контроллер StatefulSets предоставляет возможность пронумеровать все поды по порядку, начиная с нуля. Поэтому при работе с приложениями, сохраняющими состояние, легко обустроить архитектуру, в которой один под является ведущим, а остальные – его репликами. Если один из подов погибнет, то заново создается одноименный ему новый под. Эта возможность очень полезна и не нарушает цепочку кластеров с приложениями, сохраняющими состояние. Если же вы масштабируетесь вниз, то избыточные поды удаляются в обратном порядке.
Пользуйтесь контроллером StatefulSets в кластере Kubernetes, если нужно развертывать приложения, сохраняющие состояние, например, Oracle, MySQL, Elasticsearch и MongoDB. Притом, что клонирование и синхронизацию данных все равно потребуется обеспечивать вручную, StatefulSets в значительной степени упрощают развертывание приложений, сохраняющих состояние.

Комментарии (18)

sloniki
05.12.2022 23:42Секреты храните в Vault или HashiCorp.
Имелось ввиду наверное
HashiCorp Vault.И да, как уже верно заметили, если есть stateful аппликуха, то нужно сразу искать уже готовый оператор. В большинстве случаев он уже есть. Это cloud-native подход, когда есть управление полным циклом.



indestructable
07.12.2022 17:00mysql -u root -p -h mysql-set-0.mysql.default.svc.cluster.local - вот эта строчка подключается напрямую к контейнеру? Или сервис создает "подсервисы" для каждого пода стейтфул сета?

booger_man
08.12.2022 11:03Почему в статье не описаны стандартные сценарии отказоустойчивости?
Что будет с приложением и кластером бд если упадетmysql-set-0?
Что будет при проблемах с сетью по типу splitbrain (мастер недоступен ля приложения)?
Понятно что между Deployment и StatefulSet есть разница но отказоустойчивость они обеспечивают примерно одинаковую.
DikSoft
Был бы признателен, если кто-то смог бы аргументированно рассказать про преимущества подхода, когда СУБД размещается в контейнерах.
Кроме банальных: "ну, круто же, сейчас всё в контейнерах".
saboteur_kiev
да нет никаких аргументов.
Просто если у тебя уже есть кластер типа кубера или опенщифта, то вместо клепания виртуалок, можно уже и субд в контейнер запустить, чтобы все было в одном месте.
Но если ты в облаке, то проще заказать готовую базу.
А если у тебя не слишком много всего в кубере/опенщифте, и нет требования стандартизировать все, можно делать так, как тебе удобно.
JuriM
Если используется k8s и gitops, то быстрее и удобнее создавать кластера через k8s оператора+helm/kustomize, чем переключаться на ансибл, терраформ
DikSoft
Ок, а во что в результате обходится это вот "удобнее" если база более-менее серьёзная?
JuriM
Не совсем понял вопрос. Если отказоустойчивость и бэкапы, то это обеспечивает оператор. Если размер базы и сохранность файлов, то это обеспечивает сторадж контроллер и файловая система
sgjurano
Требуется разбираться в другом стеке технологий, k8s operator + контейнеры против условных lxc + puppet.
Это никогда не было бесплатно, но на больших масштабах (от сотен баз) экономия уже заметна.
berendiaev
Оператор придётся выбирать, тренировать бэкапирование и восстановление, писать доки по типовым операциям типа масштабирования во все стороны.
Это, кстати, может потребовать разбирательств в сорцах оператора. Кроме того, часто даже широко используемые операторы содержат серьёзные баги.
Инфраструктурный код, кстати, тоже тестировать придётся. Видел как кликхаус инсталляция пересоздалась к чертовой матери вместе с данными, из-за бага в версии кубернетес провайдера в терраформе. Проблема тут не в операторе, но тем не менее.
SaaS сервисы не требуют такого вдумчивого подхода - как правило, облачный провайдер уже написал всю документацию, а саппорт поможет с проблемами. В случае с проблемами операторов вам никто в срочном порядке помогать не станет.
vitaly_il1
+1 - У меня очень похожие мысли:
- всегда рекомендую DBaaS
- поднять надежный сервер БД непросто - нужно знать БД, репликацию, performance tuning, backups, HA и т.п. А если мы это делаем под K8S - то дополнительно нужно еще разбираться с K8S и оператором.
gto
Как насчёт бюджета? DBaaS всё-таки ощютимее дороже.
vitaly_il1
Как насчет надежности, производительности, scalability, возможности восстановления? За это мы и платим больше.
Я меня большой опыт с MySQL и я хорошо знаю, что поддерживать production-ready кластер очень непросто. А в DBaaS мы получаем это, плюс каждая кухарка может восстановить базу включая Point-in-Time Recovery. А админ может сделать scale up \ scale down одной кнопкой и это будет работать.
gto
Ни в коем разе не сомневаюсь в Вашей компетентности. Но всё-таки надёжность, масштабируемость и возможность востановления это всё очень субъективно. Про производительность даже не говорю. Любое приложение на железке будет производительней (может так же, но точно не хуже) чем в облаке. А уменьшение сложности управления может сыграть злую шутку, когда кухарка решит, что можно начать оптимизировать базу просто выкручивая параметры.
vitaly_il1
Я имел в виду что поддерживать базу и так непросто, а K8S добавляет свои заморочки.
Я не сомневаюсь, что инсталлировать базу с помощью "helm install" в K8S может любой студент курса DevOps. Но чтобы быть уверенным, что есть возможность восстановления, и чтобы знать что делать когда "все упало" нужен очень серьезный уровень и в DBA и в K8S. То есть дорогой человек или группа. Наверно это окупается когда есть десятки-сотни production баз.
Для небольших фирм я всегда советую оутсорсить все это платя за DBaaS.
gto
Преимущества те же, что и размещение любого приложения в контейнере. Изолированность среды. Данные-то всё равно в контейнер пихать не стоит. А так бегает себе движок в контейнере со своими либами, надо обновить - старый новым образом заменил и готово (конечно + миграция и т.п. ). Опять же дебажить удобно. Образ на десктоп поднял и уверен, что все либы те же. Если вопрос в прозводительности, то контейнеры её точно не прибавят.