
Привет! Меня зовут Mons Anderson, я архитектор, разработчик, продакт-менеджер и евангелист Tarantool. В VK работаю уже больше 10 лет. Я постоянно нуждаюсь в базах данных, использую их и очень люблю. И в последнее время, когда я говорю про БД, я всё чаще говорю про Tarantool. Сегодня тоже хочу рассказать, что уникального в этой базе данных и что делает её практически универсальной.
Поговорим про базы данных в целом
Прежде чем переходить к Tarantool, стоит обсудить базы данных. На DB-Engines они отсортированы по популярности:
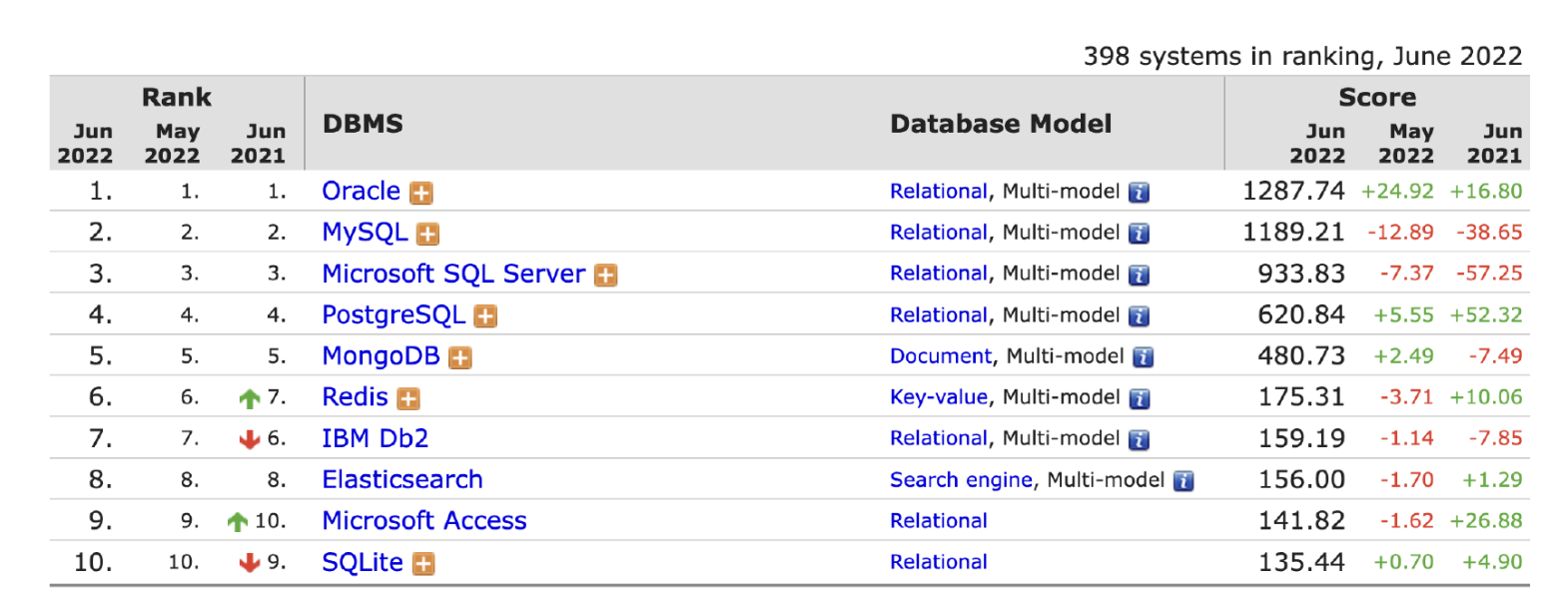
Сначала я вычеркнул базы данных, которые являются коммерческими — мне просто не хотелось рассматривать такие решения.
Дальше у нас есть MySQL и Postgres. В целом, более или менее равнозначные инструменты. Но MySQL постоянно падает в рейтингах, а Postgres растёт. Поэтому я выбрал эту тройку — Postgres, Mongo и Redis. Именно они хорошо отражают всё, что происходит с точки зрения использования базы данных: скорость, масштабируемость и реляционность.
Я специально не буду говорить про облака. На DB-Engines очень много облачных решений, но облако — такая штука, в которой проблемы уже кто-то решил за вас. Обсуждать их не стоит, мы сосредоточимся на решениях на своём железе и на их проблемах.
Первая группа проблем — это кеш. Его инвалидация, когерентность, холодность — он может быть почти тёплый. Кеш приносит проблем едва ли не больше, чем решает. К тому же он увеличивает время работы: сходи посмотри там, там нет — иди в базу, сохранили в кеш — там всё устарело. Кто пользовался, тот знаком с этими проблемами.
Ещё кеш решает проблему только чтений. Решить проблему записи мы не можем никак, кроме как с помощью шардирования, потому что запись не масштабируется таким образом. Мы не можем писать на реплики, они не принимают запись. Поэтому у нас появляется маршрутизация запросов, шардирование, отдельные наборы реплик. Ваш классический мир по умолчанию становится довольно сложным. В нём появляются различные нагромождения, кеши, шардирование, — но всё это не коробочное.
Большинство современных реляционных баз дисковые. А у дисков есть одно мерзкое свойство: они могут ломаться, рассыпаться, просто тормозить. Если вы много пишете в базу и у вас загружен диск или создаётся резервная копия, или вдруг много логов от операционки — чтение начинает тупить. Дисковая база данных довольно плохо прогнозируема с точки зрения нагрузки, потому что диск влияет на работу базы.
Поэтому давайте поговорим про нестандартный подход. У нас есть база данных, в ней масштабирование и кеш. Можно это собрать в одно решение, чтобы коробка решала все проблемы.
Tarantool и смешение разных продуктов
Если смешать Redis с Postgres, взять SQL-схему, но при этом сохранить резидентность (in-memory), то есть сделать из in-memory полноценную реляционную базу данных с различными индексами (primary, secondary, композитными и foreign key), то получится всё как в клёвом хорошем Postgres. Получится надёжно, хотя придётся отказаться от аналитических запросов. Во-первых, гонять их по памяти дорого, во-вторых, зачастую аналитические запросы гоняются по гораздо большим массивам данных. Аналитику мы отодвинем в сторону, потому что обычно реляционные базы данных захлёбываются на нагрузке другого характера. И теперь можно сказать, что Tarantool — это такая база данных, которая как Redis и Postgres: резидентная, быстрая и реляционная.
Можно зайти с другой стороны. Возьмём Redis и Mongo. Mongo хорошо масштабируется, но медленная. Redis хороший и быстрый, но у него нет таких инструментов масштабируемости. А у Tarantool есть. Tarantool — это хорошо масштабируемый in-memory, но, конечно, есть и минусы в сравнении с Mongo. Он всё хранит в памяти. Также у него менее богатые возможности индексации. У Mongo они действительно круче, потому что она ориентирована строго на индексирование документов. Tarantool тоже умеет их индексировать, но чуть послабее.
Рассмотрим последнее пересечение — Mongo и Postgres. Это поле, на котором сложно определить лучшего игрока. С одной стороны, это схема и реляционность. С другой — отсутствие схемы хранения документов, произвольных данных. Тут всё сложно. Postgres, в целом, тоже идёт в эту сторону: он учится хранить произвольные структуры данных, позволяет их индексировать. Tarantool занимает промежуточную позицию, потому что нет необходимости выбирать что-то одно, если ты можешь для одних данных сделать коллекцию и хранить в ней табличную информацию, в другой коллекции хранить документы. Tarantool позволяет и так, и так. У него есть инструменты для шардирования, схемы, индексы, возможность хранить документы. Где Tarantool не пересекается с Postgres и Mongo, это хранение на диске, потому что он строго in-memory.
Tarantool: что он не умеет и для чего подходит
Каждое перечисленное решение что-то умеет, а что-то — нет. Tarantool берёт от каждого решения то, что ему было нужно на разных этапах своего развития. Получилось решение, которое одновременно умеет всё (или очень многое) из перечисленного.

Но давайте посмотрим на то, что он не умеет. Для этого обратим внимание на наш способ выбора БД. Часто исходят из количества данных. Их может быть мало — хватит памяти одного сервера. Например, у магазина настольных игр данные прирастают медленно и точно влезут в один сервер, даже если бизнес успешный и раскрученный.
А бывает, что данных много, как, например, почти у любого UGC-сервиса, для которого пользователи постоянно генерируют контент. Очень много задач решается в сценариях, когда данных мало, потому что предметная область по своей сути ограничена.
Другой критерий — нагрузка. Она бывает высокая и низкая. Вряд ли нас интересует низкая нагрузка, потому что она никак не влияет на выбор решения, поэтому мы будем говорить сразу про высокую.
Высокая нагрузка бывает двух видов: OLAP (Online Analytical Processing) и OLTP (Online Transaction Processing), нагрузка на чтение. OLTP — это когда мы делаем маленькие точечные запросы. В качестве примера можно привести объектное хранилище (S3), у которого точечная нагрузка, которая строго ограничена конкретными объектами. Там практически отсутствуют запросы ко всем данным, как и необходимость выбирать их большими списками. А OLAP — это практически всегда какая-нибудь аналитика. Мы берём здоровенный массив данных, который нужно просканировать, просуммировать, что-нибудь с этим сделать. В качестве примера — та же Google Analytics.
И с другой стороны. кроме чтения бывает и запись. Это такая нагрузка, которая «убивает» очень многие базы. Они обычно предназначены для чтения и редко оптимизированы под очень высокую нагрузку на запись.
Теперь давайте посмотрим, какие продукты могут закрывать разные задачи в зависимости от количества данных и нагрузки:
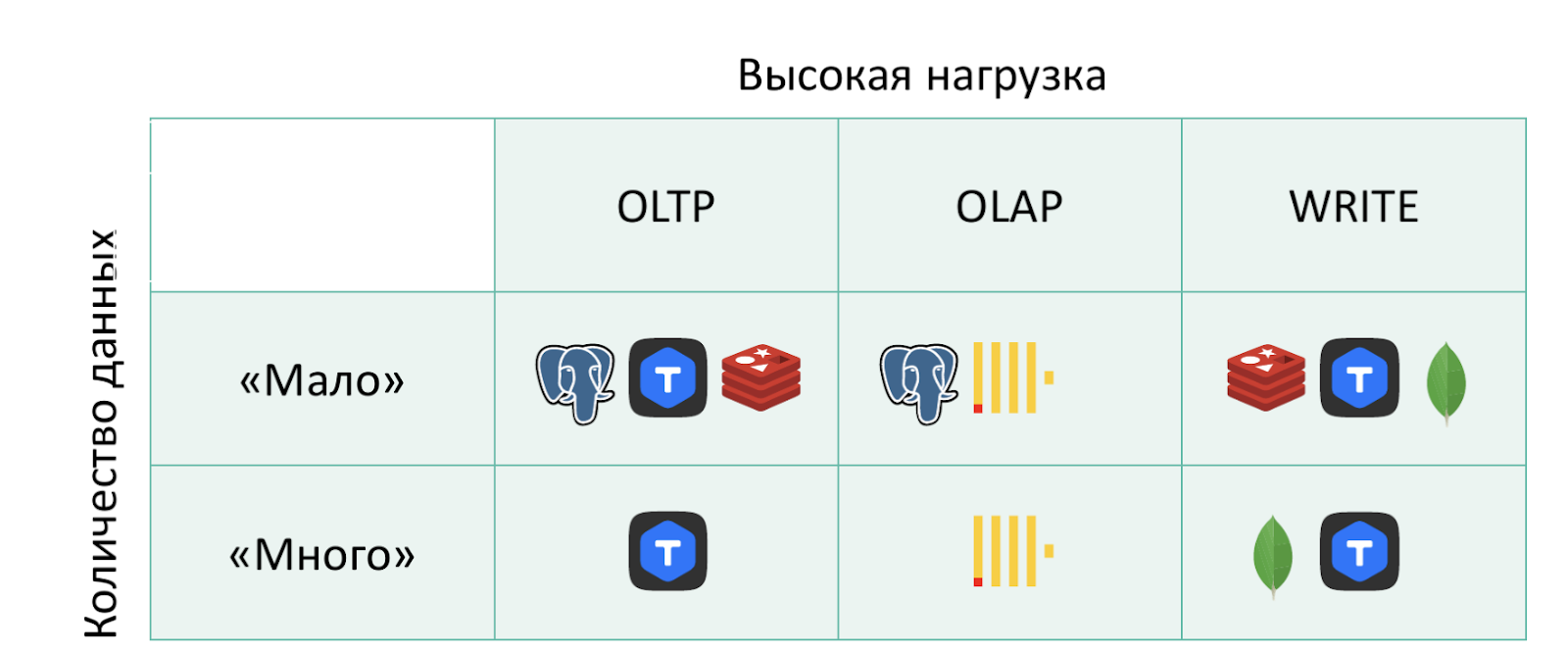
Мало данных, OLTP-нагрузка. До определенного момента может хватить Postgres, он хорошо вывозит точечные запросы. Также для такой нагрузки вполне хорошо пойдёт Redis и уже озвученный мной Tarantool, который здесь, по сути, имитирует первого и второго. То есть он способен обрабатывать OLTP в режиме «мало», причём очень удобно, с SQL и прочими прелестями.
OLAP. Для OLAP с «мало» также вполне подойдёт Postgres. У него есть хорошие возможности для аналитических запросов. Но нельзя не отметить довольно популярного игрока — ClickHouse, хотя ранее я его не называл, так как это вообще отдельный класс баз данных — колоночные. Он прекрасно подходит под аналитическую нагрузку любого масштаба.
Нагрузка на запись. У нас резко отваливаются Postgres, да и много других реляционных баз данных — они не вывезут активную запись. Здесь работают либо in-memory, которые хорошо и линейно пишут на диск, либо LSM-деревья, например, Mongo. Она хорошо и прекрасно пишет.
В итоге:
Когда данных много и OLTP-нагрузка, из перечисленных ранее подходит только Tarantool, потому что он умеет масштабироваться и хорошо подходит под OLTP. Redis и Postgres не справятся с ростом нагрузки, потому что у них из коробки нет шардирования.
Под OLAP у нас остаётся ClickHouse
Под большую нагрузку на запись — всё тот же MongoDB, который хорошо пишет, и Tarantool, потому что он толерантен к такой нагрузке.
Если говорить о Tarantool, то аналитику можно сразу отметать — сценариев, когда его можно использовать для аналитики, исчезающе мало. К тому же есть другое решение, которое хорошо его дополняет. А вот для всех остальных сценариев Tarantool практически идеален.
По прошествии времени я понял, что для решения большинства задач с высокой нагрузкой мне хорошо подходит Tarantool. А ту нишу, где он не подходит, хорошо закрывает ClickHouse.
Итог: главное о Tarantool
Почему Tarantool такой особенный? Он даёт выбор. Это плохо и больно, люди не любят выбирать. Есть даже исследования: покупателям гораздо проще, если в магазине будет два вида товара одной категории, а не 30. Tarantool — это конструктор, из которого можно собрать себе шардированную или не шардированную базу данных, с SQL или без, под разные задачи. И это я ещё не говорил о других задачах, не связанных с БД — IoT-сервисах или брокерах очередей.
Большинству разработчиков гораздо проще взять готовое решение. Если тебе нужен просто резидентный кеш, то достаточно взять Redis, запустить — и всё заработает. А если брать Tarantool, то придётся его настраивать, шагов на начальном этапе будет больше.
Но если в самом начале ошибиться с другой БД и не понять, что понадобится масштабирование или реляционные запросы, то потом будет сложнее перестроиться. А с Tarantool это легко можно сделать на лету. Он упрощает смену парадигмы без смены технологии или платформы. Из личного опыта: во время раннего запуска сервиса S3 (VK Cloud Storage) предполагали один характер данных и нагрузки, а со временем они менялись. Сервис рос, я спокойно менял схему данных и горизонтально масштабировал базу, не меняя слоя приложения.
Tarantool — это конструктор, который можно правильно собрать, прикрутить что-то сбоку. Или его можно собрать неправильно, не так, как это делают другие. В целом, он поможет вам решить задачу. Это надёжный, хороший базовый кубик для построения различных приложений, связанных с базами данных.
Скачать Tarantool можно на официальном сайте, а получить помощь — в Telegram-чате.
Комментарии (3)

vagon333
09.12.2022 20:29Критерий шустрости не всегда основной.
В моей практике надежность наиболее важна. Также, важна поддержка языками, ORM.
А шустрость допиливаем кешированием: на сервере (ex. Redis), на клиенте (ex. IndexedDB).
sergeyns
ведь никто не может гарантировать, что владелец VK или mail (за чей счет он щас делевелопиться? ) вдруг не решит, что неплохо бы сделать бесплатный тарантул платным.... Ну а иностранные компании принципиально будут избегать продуктов под такими брендами. Стоит ли осваивать продукт с такими ограничениями?
hard_sign
Ну тогда и PostgreSQL не надо рассматривать – а вдруг?
Так-то Tarantool выпущен под BSD-лицензией, и всё, что надо некорпоративному пользователю, там есть. Мало того, vk – не единственная компания, предлагающая поддержку Тарантула.