
Вы не используете очередь? Вы просто не умеете её готовить. Но прежде чем этому научиться, нужно разобраться, что это вообще такое и где это применяется. Потому что большинству достаточно 10 000 запросов в секунду, а это дает любой брокер. Но если вам нужно больше, придется погрузиться в очереди достаточно глубоко.
Расскажу, что такое очереди, зачем они нужны и как работают. На примере нескольких сценариев объясню, как устроены очереди и какие есть решения. Какие у очередей самые распространенные проблемы и как их избежать. В чем отличия брокеров, их плюсы и минусы, и как все это использовать в своих целях.
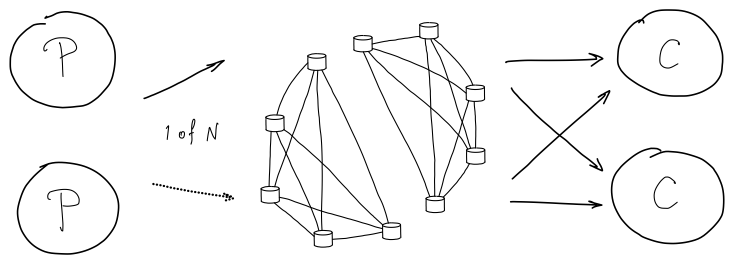
Зачем нужны очереди?
Я много знаю про очереди, умею их готовить и выбирать. Легче всего рассказывать, как устроены очереди на примере сценариев. Рассмотрим простейший сценарий: три сервера (слабый, мощный, нерабочий) и входящая нагрузка. Если взять классическую балансировку, которая равномерно распределяет нагрузки на эти сервера, мы получим следующую схему:

Слабый будет перегружен, сильный — недогружен, а на нерабочем сервере запросы будут фейлиться. Но если сложить входящие запросы в очередь, рабочие сервера заберут их в качестве задач на обработку.
Очереди также часто используются для планирования исполнения. Например, у вас классическая синусоида или другой волнообразный график нагрузки.

Для обслуживания такой нагрузки оборудование должно перекрывать ее пик. Но если отложить задачи превышающие ваш оптимум, вы сможете снизить количество ресурсов, которые предоставляете. А отложенные задачи сложить в очередь и обработать когда появится ресурс:

В результате нужно меньше оборудования. Так очереди обеспечивают распределение ресурсов, репликацию сообщений, отказоустойчивость, надёжность передачи, гарантию доставки и коммуникацию микросервисов. Поэтому очередей очень много и они много где применяются.
Например, по принципу очереди работает IRQ, NCQ и Hardware Buffers. Epoll/kqueue, networking и signal handling используют в ядре операционных систем, а Cross thread и IPC — в приложениях. Очереди полезны в сетевых взаимодействиях, распределённых системах и на стыке разных бизнесов. Фактически вы можете найти очередь в любом слое своей системы. Очереди — это своего рода клей между различными уровнями системы.
Что такое очередь?
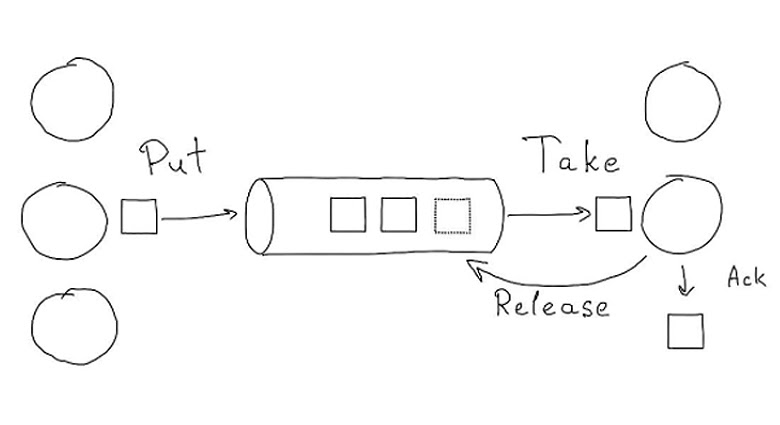
Простейшее определение очереди на уровне структур — это средство коммуникации при помощи сообщений. Мы кладем сообщение в очередь, а кто-то другой его оттуда достает:

Для распределенных систем есть другие подходы.
Подходы
Подход Put/Take: 1 → 1
Кладем задачу в очередь один раз и один раз ее забираем. Продюсеры кладут задачу в очередь, а консьюмеры забирает задачу. Они могут ее обработать, и тогда она считается исполненной и удаляется, либо ее возвращают обратно.
Подход Publish/Subscribe: 1 → * (Pub/Sub)
Продюсер доставляет сообщение один раз, а консьюмеров и сценариев может быть несколько. Если нет консьюмеров задача удаляется или остается для многократной обработки. Главное отличие от первого подхода в том, что на одного продюсера есть несколько консьюмеров.

Подход Request/Response: 1 ⇆ 1
Это редкий вариант похожий на классический Request/Response, как у серверов, только он выполняется при помощи сообщений. Мы отправляем сообщение Request, оно процессится и консьюмер возвращает его обратно (Response).
Протоколы
Если вы начнете гуглить про очереди, то найдете много протоколов, по которым они работают — AMQP (Advanced Message Queueing Protocol), MQTT (для оборудования), STOMP, NATS, ZeroMQ… Немного расскажу про протокол и их применение.
Облачные решения базируются на SQS (Simple Queue Service). Это и Amazon SQS, Mail.ru Cloud Queues, Yandex MQ, CloudAMQP...
Есть специализированные брокеры: RabbitMQ, Apache Kafka, ActiveMQ, Tarantool Queue, NATS, NSQ.
С помощью СУБД — например, PgQueue, Tarantool, Redis — можно приготовить очередь через кастомные решения.
Есть еще класс очередей, который часто называют сокетами на стероидах. Первым был ZeroMQ, позже появился NATS, который вырос в полноценный брокер. Они ничего не хранят, а просто дают некоторый интерфейс взаимодействия: с точки зрения одного узла он может публиковать сообщение, с точки зрения другого узла — подписываться на сообщение. По сути это небольшая надстройка над сокетом.
Основные платформы
Apache Kafka
Apache Kafka реплицированный шардированный лог сообщений для стриминга. Отправка организуется по принципу publish subscribe. Сообщения сохраняются на диск и записываются в один лог. У Kafka ограниченное количество консьюмеров, на одном логе (партиции) может быть строго один консьюмер из одной консьюмер-группы. В отличие от классических брокеров лог Kafka неизменен. В каком порядке сообщения записаны, в таком и остаются. Отсюда появляется строгая упорядоченность (FIFO). Сообщения не удаляются после обработки. Если часть сообщений в вашей системе была обработана некорректно, можно проиграть лог заново.
Kafka:
Чаще всего используют для анализа данных, логирования, метрики, аудита, производительного процессинга потоковых данных и репликации данных.
Прекрасно интегрируется со всей экосистемой Apache и горизонтально масштабируется
На ней сложно создавать обычные решения, типа роутинга.
Из-за сложной архитектуры ее долго поднимать.
RabbitMQ
RabbitMQ традиционный брокер очередей с поддержкой протокола AMQP, MQTT и STOMP. В отличие от Kafka у него нет ограничений на количество потребителей. К одной очереди можно подключить любое их количество, и они будут быстрее обрабатывать сообщения. Есть несколько вариантов хранения: память, диск, репликация. Можно даже использовать кворум для сохранения сообщений (кворумные очереди).
Основной сценарий: традиционный pub/sub брокер. Его часто используют в качестве слоя шины данных между разными микросервисами. RabbitMQ довольно прост в освоении, но сложен в настройке отказоустойчивых сценариев. Настроить гарантированное хранилище можно, но для создания надежной распределенной системы проще использовать другие инструменты.
Managed Cloud Queue
Managed Cloud Queue (SQS, MQ) — решение для создания облачных очередей. Провайдер облака берет на себя все задачи: вам не нужно ничего поднимать, настраивать и мониторить. Облако подходит для небольшого количества сообщений.
Основной сценарий использования: коммуникация между сервисами в облаке. Не нужно привязываться к конкретному брокеру — сегодня вы работаете на Амазоне, завтра в Mail.ru, послезавтра в Яндексе. Это хорошее связующее звено при использовании облачных сервисов S3 или Lambda. При отправке сообщений из одной системы в другую используется SQS.
NATS Messaging
NATS Messaging инструмент для соединения микросервисов между собой. Обеспечивает быстрый неперсистентный обмен сообщениями, высокую производительность и масштабируемость. Он заточен под любые сценарии (pub/sub, put/take, req/res), а благодаря движку JetStream может использовать потоковую обработку и надежное хранение RAFT cluster. Написан на Golang и довольно просто развертывается.
Tarantool
Tarantool платформа для произвольных очередей. Дает возможность создавать любые продукты поверх данных, в частности, очереди на базе готового брокера с репликацией (Tarantool Queue). У него есть интеграция со стриминговыми очередями, например, можно подключить к Kafka.
Если вам нужен кастом, вы можете написать свою собственную очередь с кастомным процессингом, с кастомными приоритетами, с любыми зависимостями. Построить сложные очереди с собственной логикой и использовать транзакционность в рамках одного брокера. Например, в Kafka нельзя перенести данные из одной очереди в другую, если у вас внешний консьюмер. А в Tarantool они объединяются в одну транзакцию, так как он транзакционная БД с кворумной репликацией.
Но он рассчитан не только на кастом. Его можно использовать как производительный брокер для традиционных сценариев. Мы тестировали пропускную способность различных брокеров, и на Tarantool нам удалось развить скорость сопоставимую с лидером по скорости Kafka.
Протоколы очередей и ограничения
При коммуникации с очередями есть два подхода: задача привязывается к соединению или привязки нет, то есть нет состояний HTTP/REST/SQS.
У каждого подхода есть свои плюсы и минусы. При привязке к соединению у задач низкая задержка и мгновенный возврат. При разрыве соединения, мы можем вернуть задачу обратно на обработку, но такую систему сложно масштабировать потому, что консьюмеры работают непосредственно с узлом очереди.
Систему без постоянного соединения легко масштабировать по принципу HTTP. Вы можете воспользоваться классической HTTP или TCP балансировкой. Но здесь обязательно нужно делать автовозврат сообщения, потому что если кто-то через соединение без состояния заберет задачу, она за ним зарезервируется. И если он упал и больше не вернется (или вообще его больше не существует), то задача залипнет навсегда. В системах типа SQS автовозврат сделан автоматически.
Теперь посмотрим, какие вообще бывают проблемы с очередями.
Проблемы очередей
Первый слой проблем
Даже когда все работает и ничего не ломается, в алгоритме очереди может быть заложено много проблем. Посмотрим, какие алгоритмы бывают.
FIFO (First In, First Out) — строгая упорядоченность сообщений:

LIFO (Last In, First Out) — это по сути стек, встречается редко
Best Effort — очередь, которая встречается чаще всего.
Она в основном FIFO, но при отказе консьюмера, который уже взял сообщение, оно возвращается обратно и сообщения снова упорядочиваются. Это подходит для большинства задач и позволяет не тормозить остальную очередь.
В очередях бывает нужна приоритизация сообщений. Например, в той же Kafka ее нет потому, что каждое сообщение автоматически помещается в конец топика и будет лежать на том месте, на которое пришло. Сообщения в Kafka нельзя переупорядочить.
Еще одна проблема — это организация подочередей, когда в большой системе создают огромное количество маленьких очередей, по одной на клиента.
Если брокер заточен на стриминг могут возникнуть проблемы с повторами и отложенными задачами. Если повтор не реализуется, вам придется брать задачу из очереди и класть ее заново.
Но в некоторых брокерах нельзя вернуть задачу обратно. Тогда нужно настроить dead letter queue и упорядочивание.
Но даже если задача возвращается, могут возникнуть проблемы со временем (TTL, TTR, Putback). Если задача не выполнилась за определенное время, значит консьюмер её не отработал и ее возвращают обратно.
Второй слой проблем
Второй слой проблем возникает из первого — из-за приоритезации может начаться голодание. Допустим, есть два потока сообщений: одни с высоким приоритетом, другие с низким. Если поток сообщений с высоким приоритетом достаточный, чтобы загрузить консьюмера, то задачи с низким приоритетом могут вообще никогда не добраться до консьюмера.
Также если у системы есть узкое место, которое никак не масштабируется — очередь может быть ограничена по пропускной способности (Throughput).
И, конечно, алгоритм может влиять на производительность (performance). Условно говоря, линейная запись на диск — это один perf, рандомный доступ к диску — это другой perf.
У вас также будут проблемы, если ваша очередь не учитывает возможность масштабирования (Scalability). Например, у single-узла с репликацией нет горизонтального масштабирования, поэтому при перенасыщении у вас будут проблемы.
И наконец, у нас нет бесконечных хранилищ, бесконечной памяти и бесконечного диска. Поэтому нужно всегда смотреть, как очередь ведет себя, когда всё это заканчивается (Capacity).
Третий слой проблем: сеть и диск
Очереди изначально придумывали на уровне железа и софта, когда никаких потерь нет, процесс работает и внутри этого процесса что-то происходит.
В случае сети есть undefined behavior, то есть мы отправили пакет и не знаем: он дошел и его получили, или этот пакет потерялся. Это классическая проблема двух генералов, когда между частями одной армии вражеская территория. Генералы должны договориться одновременно атаковать или не атаковать. Если один нападет, а другой — нет, армия проиграет. Они могут посылать друг другу сообщения, но гарантии, что сообщения будут получены — нет.

Эта проблема не имеет алгоритмического решения. Один генерал отправляет гонца и ему нужно подтверждение с той стороны, что гонец дошел. Но гонец с подтверждением тоже может потеряться или его перехватят. Можно отправить десятки гонцов и увеличивать поток до бесконечности, но 100% гарантии, что генералы договорятся — не существует.
При этом в распределенных системах мы имеем строгий порядок сообщений и доставку строго один раз (exactly once). Последнее — частный случай проблемы двух генералов, и, несмотря на весь опыт, такая доставка мне не встречалась долгое время.
Но потом я столкнулся с системой, в которой этот принцип был реализован. В ней решение оказалось очень простым. В системы был консьюмер, который как-то коммуницировал с другой стороной. Если возникала неопределенность — сообщение отправлено, но непонятно дошло оно или нет, — оно попадало в dead letter queue. И дальше в очередь смотрел человек и разгребал сообщения. То есть он выполнял роль божественной сущности, которая стояла над генералами и сообщала им, когда пора атаковать.

В исходном решении системы такое не предусмотрено, но в реальности, когда очень нужно, мы можем прибегнуть к такому подходу.
Помимо сети, у нас еще есть диск, который тоже влияет на пропускную способность (Throughput) и задержку в обработке (Latency). В зависимости от того, какое оборудование используется, задержка может быть предсказуемая или не предсказуемая.
Последний слой проблем: отказы оборудования
Напоследок приходим к ситуации, когда у нас что-то сломалось. Бывают временные и постоянные поломки.
В вопросе сохранности данных всегда много заблуждений. Например RAID спасает только от самого нижнего случая, когда вылетает один диск, тогда как может вылететь целый хост. В моей практике был сценарий, когда машину с 16 дисками не защитил блок питания. Она получила разряд по сети и сгорело всё, кроме двух дисков.
Временные отказы, когда пропало питание или порвалась сеть, приводят к Split brain. Обе части системы живы, но не знают об этом и не могут договориться.
Постоянным отказ становится, если сгорел диск, сервер или дата-центр. Считается, что дата-центр не должен гореть, но иногда это случается. Поэтому всегда нужно планировать масштаб отказа вплоть до отказа дата-центра.
Отказы влияют на две основные метрики в системе. На доступность (Availability), то есть возможность сохранения сообщений — она важна для продюсера. И надёжность (Durability), когда мы даем гарантию сохранности и доставки сообщения.
Топологии очередей
Single instance
Рассмотрим как достигается надежность и доступность в распределенной среде, если есть брокер очередей. Самый простой и, к сожалению, чаще всего использующийся подход — это single instance: один брокер, одна очередь: продюсер и консьюмер.
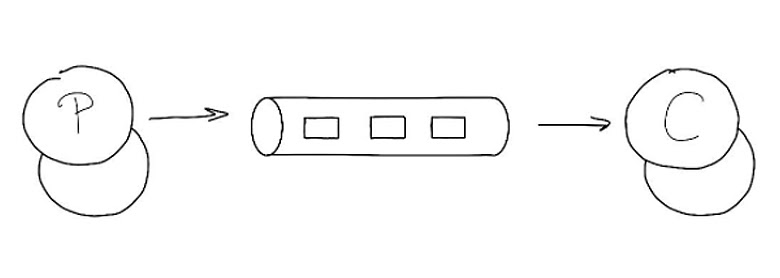
Минусы этого подхода в том, что нет масштабируемости. Когда брокер закончится, ваша система перестанет принимать сообщения. У нее низкие доступность и надёжность. Если что-то сломается или сервер уйдет в ребут, вы скорее всего потеряете сообщения.

Гарантии: X ≤ 1, X ≥ 1. Эту систему можно очень просто усовершенствовать, поставив несколько очередей и положив сообщения в любую из доступных.
У multi-instance системы показатели намного лучше. Ее можно масштабировать: то есть ставить столько очередей, сколько вам нужно. У нее высокая доступность: если одна из очередей умерла, есть другие. Но надежность средняя и гарантии все еще малы: X ≤ 1, X ≥ 1

Серьезный недостаток этой системы в том, что сообщение принадлежит только одной очереди. Если что-то случиться с машиной, вы потеряете данные. Проблему можно решать несколькими способами, например, мы можем дублировать в несколько очередей.

В этом случае у нас получается высокая доступность и надёжность. Какая-то из очередей сообщение обязательно довезет. Но появится другое неудобство. При многократной доставке сообщений их делают идемпотентными, либо проверяют, что сообщение уже применяли.
Если воспользоваться подходом репликации БД, можно решить эту проблему репликацией. То есть продюсер и консьюмер работают только с лидером. Тогда реплики будут ждать, а если лидер пропадет, они примут на себя роль нового лидера и продолжат работу.

Если вместо каждой одиночной очереди поставить реплика-сеты, то получится более совершенная система с высокой масштабируемостью, доступностью, надежностью и гарантией X ≈ 1 (X ≥ 1):
")
В такой системе execution одной задачи будет стремиться к 1 и никогда не упадет меньше 1.
Еще можно взять за основу кворумные базы данных. Там все то же самое, только за выбор отвечает не классическая, а кворумная репликация.
Кворумная запись защищает от потерь данных. Если мы прислали сообщение и кворум его подтвердил, то оно надежно сохранилось. У кворума высокие гарантии X → 1 (X ≥ 1), но пониженная пропускная способность потому, что узел обязательно подтверждает сообщение.

Иногда кто-нибудь добавляет к кворумному брокеру еще одного консьюмера, рассчитывая, что в кластерной системе это будет работать. Когда эту систему распартиционируют — работать она не будет. Да, надёжность её высокая, а гарантии: X ≈ 1 (X ≥ 1). Но сообщения процессит один лидер, реплики эти сообщения у себя держат, подтверждают, поэтому масштабируемости здесь нет. Доступность при этом ограничена: в той части, где не хватило узлов, вы не сможете производить сообщения и складывать их. Поэтому в случае partitioning ваша система просядет по доступности.

Но если применить подход БД с обычной репликацией на кворумную, то получим хорошие показатели: масштабируемость, высокие доступность и надежность и гарантии: X ≈ 1 (X ≥ 1):

Если у нас более одного кворума, нам нужно их грамотно распределить. Мы должны распределить узлы так, чтобы кворум одного кластера был в одной availability зоне, а кворум другого кластера — в другой.

Про что еще нужно подумать?
Мониторинг
Если мы вводим в эксплуатацию новую систему, надо понимать, как ее правильно мониторить. Любая очередь лимитирована, даже если вы не выставили ей лимиты. Нормальное состояние очереди — пустое. Вы присылаете сообщения и они должны обрабатываться. Если очередь начала расти, значит в системе что-то не так. Поэтому размер очереди — первый показатель, который нужно мониторить.
Второй показатель — время — пригодится, когда ваша очередь начнет расти. Можно измерять полную обработку сообщения (QoS) от момента, когда вы его положили, до момента, когда обработали. И время обработки между тем, когда консьюмер взял и вернул сообщение. Замеры покажут, где у вас проблема.
Третий показатель — количество повторов и потерь (отказов). За размером очереди и временем не всегда получается уследить. За секунду может пройти 10 тысяч сообщений, и вы обнаружите, что очередь начала расти. А почему — непонятно, так как размер очереди и время — моментальные показатели. Мониторинг количества повторов и потерь (отказов), а также самого потока сообщений помогает понимать, что с вашей очередью происходит.
Если вы можете логировать сообщение, когда кладете его в очередь, — делайте это. Логов будет много, но в случае аварии, лучше доставать и искать сообщения из логов, чем обнаружить, что сообщений нет.
Эксплуатация
Настраивайте политики отказа. Например, не принимайте новые сообщения в случае возникновения проблем. Если такой возможности нет, можете начать уничтожать старые сообщения, если они не важны, но продолжать принимать новые.
Иногда бывают сценарии, когда часть сообщений в очереди еще живая, а часть уже совсем старая (дедлайн давно прошел). Можно сначала обрабатывать еще живые, а уже потом вернуться к старым.
Всегда планируйте отказ. Система обязательно упадет. И от вас зависит, как именно она упадет, и как именно вы будете подниматься.
Если вы не знаете, как ваша система падает и как поднимается, вы ее не поднимите. По крайней мере так быстро, как вам бы хотелось.
Как говорил Конфуций: «Не тот велик, кто никогда не падал, а тот велик — кто падал и вставал!». Поэтому очень важно знать, как ваша система будет подниматься.
Что же взять?
Подытожим, какие у нас есть варианты и что нам брать, когда нужна очередь.
Если у вашего сервиса толерантность к потерям сообщений (не страшно потерять 1-2 сообщения на миллион), вам нужно организовать передачу сообщений между сервисами и нужны высокая пропускная способность и масштабируемость, возьмите NATS. Он простой, развивается, плюс у него есть эволюционная точка для persistence. Можно еще взять NSQ, но у него хуже характеристики, или ZeroMQ, но он вообще ничего не персистит.
Если вы хотите быстро попробовать очереди, находитесь в облаке и у вас микросервисы — возьмите облачную очередь SQS (Simple Queue Service) от любого провайдера, в котором хоститесь (Amazon, Mail.ru Cloud Solutions, Yandex).
Для знакомства с очередями можно попробовать простые брокеры RabbitMQ или NATS. Но обязательно следите за надёжностью и настройками своей системы.
Если вам нужен стриминг — у вас есть поток сообщений, вы хотите его обрабатывать и перекладывать в big-data, вам нужна высокая сохранность сообщений или строгий FIFO возьмите Apache Kafka. Она задизайнена под этот подход, у нее есть все необходимые механизмы для обработки сообщений и перепроигрывания. Можно ещё взять JetStream от NATS или Tarantool Enterprise. У них тоже есть механизмы для потоковой архитектуры.
Если у вас сложные сценарии очередей и вы хотите класть в очередь отложенные сообщения или настроить сложный пайплайн, когда сообщения разделяются и сливаются, у вас два варианта. Простой это RabbitMQ, если посложнее — Tarantool Queue. С помощью Tarantool можно построить любую произвольную конфигурацию очереди.
В Москве 25 и 26 ноября нас ждет конференция HighLoad++ 2021. До повышения цены осталось 8 дней! Какие будут доклады, можно посмотреть здесь.
Комментарии (2)

ggo
06.10.2021 11:18Но потом я столкнулся с системой, в которой этот принцип был реализован. В ней решение оказалось очень простым. В системы был консьюмер, который как-то коммуницировал с другой стороной. Если возникала неопределенность — сообщение отправлено, но непонятно дошло оно или нет, — оно попадало в dead letter queue. И дальше в очередь смотрел человек и разгребал сообщения. То есть он выполнял роль божественной сущности, которая стояла над генералами и сообщала им, когда пора атаковать.
непонятно как человек будет принимать решение, нужна ли повторная доставка или нет.
Valien
Отличная статья, спасибо.